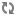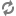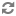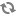There are three ways to map input records to output (or aggregated) records.
If a list of properties and/or dimensions is given, all input records containing identical values for those properties map to (group to) the same output record.
If only GROUP is specified, all input records are mapped to a single output record.
The absence of a GROUP BY clause is taken to mean that each input record is mapped to a unique output record.
<GroupBy> ::= GROUP
::= GROUP BY <Groupings>
<Groupings> ::= <Grouping> [, <Groupings>]
<Grouping> ::= <Key>
::= <Key>:<int>
Note
Colon operator requests grouping by dimension values at a specified depth.
If an input record contains multiple values corresponding to the same grouping key, the default behavior is that the record maps to all possible output records. An optional ORDER BY clause can be used to order the records in the resulting record set. An element in the ORDER BY clause specifies a property or dimension to sort (or break ties) by and in what direction: (growing values = ASCending; shrinking values = DESCending). The default order is ascending.
<OrderBy> ::= ORDER BY <OrderList> <OrderList> ::= <Order> [, <OrderList>] <Order> ::= <Key> [ASC | DESC]
The PAGE(i,n) operator allows the returned record set to be limited to n records starting with the record at index i. The 'Page' clause can be used with or without a preceding ORDER BY clause. If the ORDER BY clause is omitted, records are returned in arbitrary but consistent order.
<Page> ::= PAGE(<int>,<int>)
Expressions define the derived values that can be computed for result records:
<Expr> ::= <AggrExpr>
::= <Expr>[+|-|*|/]<Expr>
::= UnaryFunc(<Expr>)
::= BinaryFunc(<Expr>, <Expr>)
::= COALESCE(<Expr>, <Expr>,...)
<AggrExpr> ::= <SimpleExpr>
::= <AggrFunc>(<SimpleExpr>) [<Where>]
<SimpleExpr> ::= <Key>
::= <Literal>
::= <SimpleExpr> [+|-|*|/] <SimpleExpr>
::= <UnaryFunc>(<SimpleExpr>)
::= <BinaryFunc>(<SimpleExpr>, <SimpleExpr>)
::= <TimeDateFunc>(<SimpleExpr>,<DateTimeUnit>)
::= <LookupExpr>
<AggrFunc> ::= ARB | AVG | COUNT | COUNTDISTINCT | MAX |
MEDIAN | MIN | STDDEV | SUM | VARIANCE
<UnaryFunc> ::= ABS | CEIL | COS | EXP | FLOOR | LN |
ROUND | SIGN | SIN | SQRT |
TAN | TO_DURATION | TRUNC
<BinaryFunc> ::= DIVIDE | LOG | MINUS | MOD | MULTIPLY |
PLUS | POWER | ROUND | TRUNC
<TimeDateFunc> ::= EXTRACT | TRUNC
<DateTimeUnit> ::= SECOND | MINUTE | HOUR | DAY_OF_MONTH |
DAY_OF_WEEK | DAY_OF_YEAR | DATE | WEEK |
MONTH | QUARTER | YEAROptionally, a WHERE clause may be specified after an aggregation function. As in SQL, the Analytics API WHERE clause expresses record filtering. But in addition to per-statement WHERE clauses, the Analytics API allows WHERE clauses to be specified at the expression level, allowing filtering of aggregate members for the computation of derived values on member subsets. SQL requires join operations to achieve a similar effect, with additional generality, but at the cost of efficiency and overall query execution complexity.
Lookup expressions provide the ability to refer to values in record sets that have been previously computed (possibly different from the current and FROM record set). Lookups can only refer to record sets that were grouped (non-empty GROUP BY clause) and the LookupList must match the GROUP BY fields of the lookup record set.
<LookupExpr> ::= <Key>[<LookupList>].<Key>
<LookupList> ::= <empty>
::= <SimpleExpr> [,<LookupList>]
Note
For a specific example of a lookup expression in action, see the topic "Inter-statement references".
Filters provide basic comparison, range, membership and Boolean filtering capabilities, for use in WHERE and HAVING clauses.
<Filter> ::= DVAL(DvalID)
::= <Key> <Compare> <Literal>
::= <Key> IS [NOT] NULL
::= <Filter> AND <Filter>
::= <Filter> OR <Filter> | NOT <Filter>
::= [<KeyList>] IN <Key>
<Compare> ::= = | <> | < | > | <= | >=
<KeyList> ::= <Key> [, <KeyList>]
<DvalID> ::= <int>
The IN filter can be used to filter data based on membership in a group or based on membership in another statement. It can only refer to previously computed record sets based on a non-empty GROUP BY. The number and type of keys in the KeyList must match the number and type of keys used in the statement referenced by the IN clause.
This query shows how the IN filter can be used to populate a pie chart showing sales divided into six segments: one segment for each of the five largest customers, and one segment showing the aggregate sales for all other customers. The first statement gathers the sales for the top five customers, and the second statement aggregates the sales for all customers not in the top five.
RETURN Top5 AS SELECT SUM(Sale) AS Sales GROUP BY Customer ORDER BY Sales DESC PAGE(0,5); RETURN Others AS SELECT SUM(Sale) AS Sales WHERE NOT [Customer] IN Top5 GROUP
The WHERE IN clause does not respect multi-assign properties. In particular, the WHERE clause considers only a single value from a set of values in the multi-assign property. Therefore, if you want to filter on a property that is multi-assign, consider using the HAVING clause with the IN filter, instead of the WHERE IN clause. The following examples illustrates this case.
The following query uses the WHERE IN clause:
The original DEFINE Top100Terms AS SELECT COUNT(1) AS Total GROUP BY Terms ORDER BY Total DESC PAGE(0,100); RETURN DateTerms AS SELECT COUNT(1) AS Total WHERE [Terms] IN Top100Terms GROUP BY Terms, Month
This query (above) considers only a single value from a set of values in the multi-assign property. Therefore, if you want to filter on a property that is multi-assign, consider using the following query, as a workaround (this workaround has a performance impact since the MDEX Engine will filters calculated results rather than performing filtering before computation):
DEFINE Top100Terms AS SELECT COUNT(1) AS Total GROUP BY Terms ORDER BY Total DESC PAGE(0,100); RETURN DateTerms AS SELECT COUNT(1) AS Total GROUP BY Terms, Month HAVING [Terms] IN Top100Terms
Related links