检查 mttest 的同步跟踪实验
本节介绍如何了解通过上一节中 mttest 样例代码创建的实验中的数据。
从 mttest 目录启动性能分析器并按如下所示装入第一个实验:
% analyzer test.1.er
实验打开时,性能分析器将显示 "Overview"(概述)页面。
页面")
"Clock Profiling"(时钟分析)度量第一个显示并包含带颜色的条。大多数线程时间花费在 "User CPU Time"(用户 CPU 时间)中。一些时间花费在 "Sleep Time'(休眠时间)或 "User Lock Time"(用户锁定时间)中。
"Synchronization Tracing"(同步跟踪)度量显示在另一组中,其中包括两个度量:"Sync Wait Time"(同步等待时间)和 "Sync Wait Count"(同步等待计数)。
注 - 如果没有看到 "Sync Wait Time"(同步等待时间)和 "Sync Wait Count"(同步等待计数)度量,您可能需要滚动至右侧查看相关列。您可以将任意列移动至更便于查看的位置,具体方法是右键单击度量列标题,选择 "Move This Metric(将此度量移至),然后相对其他度量选择一个更便于查看的位置。
以下示例将 "Name"(名称)列移动至 "Sync Wait Count"(同步等待计数)度量之后。
列的顺序重新排列到 “Sync Wait Count“(同步等待计数)度量之后")
您可以在本教程的以下各节中了解这些度量及其解释。
了解同步跟踪
本节介绍同步跟踪数据并说明如何将其与时钟分析数据相关联。
-
转至 "Functions"(函数)视图并单击列标题 "Inclusive Total CPU"(包含总 CPU 时间)来根据包含 "Total CPU Time"(总 CPU 时间)进行排序。
-
选择列表顶部的 do_work() 函数。
视图")
-
查看 "Functions"(函数)视图底部的 "Called-by/Calls"(调用方/调用)面板,并注意从两个位置调用 do_work(),并且其调用十个函数。
通常情况下,创建处理数据的线程时会调用 do_work(),并在从 _lwp_start() 调用时显示它。在一种情况下,从 locktest() 被调用后,do_work() 调用名为 nothreads() 的单线程任务。
do_work() 调用的十个函数表示十个不同任务,每个任务使用程序执行的一个不同的同步方法。在从 mttest 创建的一些实验中,您可能会看到第十一个函数,该函数使用相对较少的时间获取其他任务的工作块。函数 fetch_work() 显示在前面屏幕抓图中的 "Calls"(调用)面板中。
请注意,除了 "Calls"(调用)面板中的前两个被调用方,所有被调用方都显示大约相同的 "Attributed Total CPU"(归属总 CPU)时间量(约为 10.6 秒)。
-
切换到 "Callers-Callees"(调用方-被调用方)视图。
视图")
"Callers-Callees"(调用方-被调用方)视图显示与 "Called-by/Calls"(调用方/调用)面板相同的调用方和被调用方,但是还显示 "Overview"(概述)页面中选择的其他度量,包括 "Attributed Sync Wait Time"(归属同步等待时间)。
查找 lock_global() 和 lock_local() 两个函数,并注意它们显示大约相同的 "Attributed Total CPU"(归属总 CPU)时间量,但是非常不同的 "Attributed Sync Wait Time"(归属同步等待时间)量。
-
选择 lock_global() 函数并切换到 "Source"(源)视图。
视图")
请注意,所有 "Sync Wait"(同步等待)时间都位于包含对 pthread_mutex_lock(&global_lock) 的调用的行上,其 "Total CPU Time"(CPU 总时间)为 0。正如您可以从函数名称猜测到的,执行此任务的四个线程都在获取全局锁时执行其工作,它们逐个获取全局锁。
-
转回 "Functions"(函数)视图并选择 lock_global(),然后单击 "Filter"(过滤器)图标
 并选择 "Add Filter: Include only stacks containing the selected functions"(添加过滤器:仅包括含有所选函数的堆栈)。
并选择 "Add Filter: Include only stacks containing the selected functions"(添加过滤器:仅包括含有所选函数的堆栈)。 -
选择 "Timeline"(时间线)视图,您应该看到四个线程。
-
突出显示时间线中发生事件的区域,右键单击后选择 "Zoom"(缩放)-> "Zoom to Selected Time Range"(缩放至所选的时间范围),以此来放大感兴趣的区域。
-
检查四个线程并比较等待时间与计算时间。
视图显示四个任务线程")
注 - 您在自己的实验中可能会看到不同的线程执行和等待时间。获取锁的第一个线程(屏幕抓图中的 T:15)工作 ~2.97 秒,然后放弃该锁。您可以看到该线程的状态条为绿色,表示其所有时间都花费在 "User CPU Time"(用户 CPU 时间),没有任何时间花费在 "User Lock Time"(用户锁定时间)。还请注意,使用
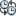 标记的 "Synchronization Tracing Call Stacks"(同步跟踪调用堆栈)的第二个条未显示此线程的调用堆栈。
标记的 "Synchronization Tracing Call Stacks"(同步跟踪调用堆栈)的第二个条未显示此线程的调用堆栈。第二个线程(屏幕抓图中的 T:17)已经在 "User Lock Time"(用户锁定时间)等待了 2.99 秒,然后计算了 ~2.90 秒并放弃该锁。"Synchronization Tracing Call Stacks"(同步跟踪调用堆栈)与 "User Lock Time"(用户锁定时间)一致。
第三个线程 (T:14) 已经在 "User Lock Time"(用户锁定时间)等待了 5.98 秒,然后计算了 ~2.95 秒并放弃该锁。
最后一个线程 (T:16) 已经在 "User Lock Time"(用户锁定时间)等待了 8.98 秒,然后计算了 2.84 秒。总计算时间为 2.97+2.90+2.95+2.84 或大约 11.7 秒。
总同步等待时间为 2.99 + 5.98 + 8.98 或大约 17.95 秒,这可以在 "Function"(函数)视图中确认(该视图中报告的值为 17.954 秒)。
-
通过单击 "Active Filters"(活动过滤器)面板中的 X 来删除过滤器。
-
转回 "Function"(函数)视图,选择函数 lock_local(),然后切换到 "Source"(源)视图。
视图显示 lock_local 代码")
请注意,包含对 pthread_mutex_lock(&array->lock) 的调用的行(屏幕抓图中的行 1043)上的 "Sync Wait Time"(同步等待时间)为 0。这是因为锁对于工作块来说是本地的,所以不存在争用,所有四个线程可以同时进行计算。
您查看的实验是使用校准阈值记录的。在下一节中,您将与另一个实验进行比较,您运行 make 命令时使用零阈值记录该实验。
使用同步跟踪比较两个实验
在本节中将比较两个实验。使用用于记录事件的校准的阈值记录 test.1.er 实验,使用零阈值记录 test.2.er 实验以包括 mttest 程序执行中发生的所有同步事件。
-
单击工具栏上的 "Compare Experiments"(比较实验)按钮
 ,或选择 "File"(文件)-> "Compare Experiments"(比较实验)。
,或选择 "File"(文件)-> "Compare Experiments"(比较实验)。 此时将打开 "Compare Experiments"(比较实验)对话框。
对话框。")
您已经打开的 test.1.er 实验列在 "Baseline"(基线)组中。必须添加实验以便与 "Comparison Group"(比较组)面板中的基线实验进行比较。
有关比较实验以及添加多个实验与基线进行比较的更多信息,请单击对话框中的 "Help"(帮助)按钮。
-
单击 "Comparison Experiment 1"(比较实验 1)旁边的 ... 按钮,然后在 "Select Experiment"(选择实验)对话框中打开 test.2.er 实验。
-
在 "Compare Experiments"(比较实验)对话框中单击 "OK"(确定)以装入第二个实验。
此时将重新打开 "Overview"(概述)页面,其中包括两个实验的数据。
屏幕")
"Clock Profiling"(时钟分析)度量对每个度量显示两个带颜色的条,每个实验对应一个条。test.1.er "Baseline"(基线)实验中的数据位于上面。
如果在数据条上移动鼠标光标,弹出文本显示 "Baseline"(基线)和 "Comparison"(比较)组的数据以及它们之间的差异(以数值和百分比表示)。
请注意,这里记录的 CPU 总时间要比第二个实验中的时间长一点,但几乎是 "Sync Wait Counts"(同步等待计数)的三倍。
-
切换至 "Functions"(函数)视图,单击 "Inclusive Sync Wait Time Count"(包括同步等待时间计数)列下标有 "Baseline"(基线)的子列标题,按第一个实验中的事件数对函数进行排序。

test.1.er 和 test.2.er 的最大差异位于 do_work() 中,这包括来自其直接或间接调用的所有函数的差异,包括 lock_global() 和 lock_local()。
提示 - 如果更改比较格式,甚至可以更容易地比较差异。单击工具栏中的 "Settings"(按钮),选择 "Formats"(格式)标签,然后为 "Comparison Style"(比较样式)选择 "Deltas"(增量)。应用更改后,test.2.er 的度量显示为与 test.1.er 中的度量的 + 或 - 差异。在前面的屏幕抓图中,选择的 pthread_mutex_lock() 函数在 "test.2.er Incl Sync Wait Count"(test.2.er 包含同步等待计数)列中将显示 +88。 -
选择 "Callers-Callees"(调用方-被调用方)视图。
屏幕")
查看其中两个调用方,lock_global() 和 lock_local()。
lock_global() 函数在 test.1.er 中对 "Attributed Sync Wait Count"(归属同步等待计数)显示 3 个事件,但是在 test.2.er 中显示 4 个事件。原因是获取 test.1.er 中的锁的第一个线程未停止,所以未记录该事件。在 test.2.er 实验中,阈值设置为记录所有事件,所以甚至记录了第一个线程的锁获取。
同样,在第一个实验中,lock_local() 没有记录的事件,因为不存在锁争用。第二个实验中有 4 个事件,即使总的来说它们具有极小的延迟。