Why typed? In a distributed environment, an application may be installed on heterogeneous systems that communicate across multiple networks using different protocols. Different types of buffers require different routines to initialize, send and receive messages, and encode and decode data. Each buffer is designated as a specific type so that the appropriate routines can be called automatically without programmer intervention.
Table 2‑1 lists the typed buffers supported by the Oracle Tuxedo system and indicates whether or not:
|
•
|
The buffer is self-describing; in other words, the buffer data type and length can be determined simply by (a) knowing the type and subtype, and (b) looking at the data.
|
All buffer types are defined in a file called tmtypesw.c in the
$TUXDIR/lib directory. Only buffer types defined in
tmtypesw.c are known to your client and server programs. You can edit the
tmtypesw.c file to add or remove buffer types. In addition, you can use the
BUFTYPE parameter (in
UBBCONFIG) to restrict the types and subtypes that can be processed by a given service.
The tmtypesw.c file is used to build a shared object or dynamic link library. This object is dynamically loaded by both Oracle Tuxedo administrative servers, and application clients and servers.
|
•
|
tuxtypes(5) in Oracle Tuxedo File Formats, Data Descriptions, MIBs, and System Processes Reference
|
|
•
|
UBBCONFIG(5) in Oracle Tuxedo File Formats, Data Descriptions, MIBs, and System Processes Reference
|
char*
tpalloc(char *type, char *subtype, long size)
Table 2‑2 describes the arguments to the
tpalloc() function.
|
|
|
|
|
|
|
|
In the cases where a subtype is not relevant, assign the NULL value to this argument.
|
|
|
The Oracle Tuxedo system automatically associates a default buffer size with all typed buffers except CARRAY, X_OCTET, and XML, which require that you specify a size, so that the end of the buffer can be identified.
For all typed buffers other than CARRAY, X_OCTET, and XML, if you specify a value of zero, the Oracle Tuxedo system uses the default associated with that typed buffer. If you specify a size, the Oracle Tuxedo system assigns the larger of the following two values: the specified size or the default size associated with that typed buffer.
The default size for all typed buffers other than STRING, CARRAY, X_OCTET, and XML is 1024 bytes. The default size for STRING typed buffers is 512 bytes. There is no default value for CARRAY, X_OCTET, and XML; for these typed buffers you must specify a size value greater than zero. If you do not specify a size, the argument defaults to 0. As a result, the tpalloc() function returns a NULL pointer and sets tperrno to TPEINVAL.
|
The VIEW,
VIEW32,
X_C_TYPE, and
X_COMMON typed buffers require the
subtype argument, as shown in
Listing 2‑1.
Listing 2‑2 shows how to allocate an FML typed buffer. Note that a value of NULL is assigned to the
subtype argument.
Listing 2‑3 shows how to allocate a
CARRAY typed buffer, which requires that a
size value be specified.
Upon success, the tpalloc() function returns a pointer of type
char. For types other than
STRING and
CARRAY, you should cast the pointer to the proper C structure or FML pointer.
If the tpalloc() function encounters an error, it returns the NULL pointer. The following list provides examples of error conditions:
Listing 2‑4 shows how to allocate a
STRING typed buffer. In this example, the associated default size is used as the value of the
size argument to
tpalloc().
Listing 2‑5 shows how to allocate a RECORD typed buffer. In this example, the size is retrieved from
Frneeded(). RECORD typed buffers requires the subtype argument.
In Listing 2‑6, a
VIEW typed buffer called
aud is created with three members (fields). The three members are
b_id, the branch identifier taken from the command line (if provided);
balance, used to return the requested balance; and
ermsg, used to return a message to the status line for the user. When
audit is used to request a specific branch balance, the value of the
b_id member is set to the branch identifier to which the request is being sent, and the
balance and
ermsg members are set to zero and the NULL string, respectively.
When audit is used to query the total bank balance, the total balance at each site is obtained by a call to the
BAL server. To run a query on each site, a representative branch identifier is specified. Representative branch identifiers are stored in an array named
sitelist[]. Hence, the
aud structure is set up as shown in
Listing 2‑7.
Table 2‑3 describes the arguments to the
tprealloc() function.
The pointer returned by tprealloc() points to a buffer of the same type as the original buffer. You must use the returned pointer to reference the resized buffer because the location of the buffer may have changed.
When you call the tprealloc() function to increase the size of the buffer, the Oracle Tuxedo system makes new space available to the buffer. When you call the
tprealloc() function to make a buffer smaller, the system does not actually resize the buffer; instead, it renders the space beyond the specified size unusable. The actual content of the typed buffer remains unchanged. If you want to free up unused space, it is recommended that you copy the data into a buffer of the desired size and then
free the larger buffer.
On error, the tprealloc() function returns the NULL pointer and sets
tperrno to an appropriate value. Refer to
tpalloc(3c) in
Oracle Tuxedo ATMI C Function Reference for information on error codes.
|
WARNING:
|
If the tprealloc() function returns the NULL pointer, the contents of the buffer passed to it may have been altered and may be no longer valid.
|
Listing 2‑8 shows how to reallocate space for a
STRING buffer.
#include <stdio.h>
#include “atmi.h”
char instr[100]; /* string to capture stdin input strings */
long s1len, s2len; /* string 1 and string 2 lengths */
char *s1ptr, *s2ptr; /* string 1 and string 2 pointers */
main()
{
(void)gets(instr); /* get line from stdin */
s1len = (long)strlen(instr)+1; /* determine its length */
join application
if ((s1ptr = tpalloc(“STRING”, NULL, s1len)) == NULL) {
fprintf(stderr, “tpalloc failed for echo of: %s\n”, instr);
leave application
exit(1);
}
(void)strcpy(s1ptr, instr);
make communication call with buffer pointed to by s1ptr
(void)gets(instr); /* get another line from stdin */
s2len = (long)strlen(instr)+1; /* determine its length */
if ((s2ptr = tprealloc(s1ptr, s2len)) == NULL) {
fprintf(stderr, “tprealloc failed for echo of: %s\n”, instr);
free s1ptr's buffer
leave application
exit(1);
}
(void)strcpy(s2ptr, instr);
make communication call with buffer pointed to by s2ptr
. . .
}
Listing 2‑9 (an expanded version of the previous example) shows how to check for occurrences of all possible error codes.
. . .
if ((s2ptr=tprealloc(s1ptr, s2len)) == NULL)
switch(tperrno) {
case TPEINVAL:
fprintf(stderr, "given invalid arguments\n");
fprintf(stderr, "will do tpalloc instead\n");
tpfree(s1ptr);
if ((s2ptr=tpalloc("STRING", NULL, s2len)) == NULL) {
fprintf(stderr, "tpalloc failed for echo of: %s\n", instr);
leave application
exit(1);
}
break;
case TPEPROTO:
fprintf(stderr, "tried to tprealloc before tpinit;\n");
fprintf(stderr, "program error; contact product support\n");
leave application
exit(1);
case TPESYSTEM:
fprintf(stderr,
"BEA Tuxedo error occurred; consult today's userlog file\n");
leave application
exit(1);
case TPEOS:
fprintf(stderr, "Operating System error %d occurred\n",Uunixerr);
leave application
exit(1);
default:
fprintf(stderr,
"Error from tpalloc: %s\n", tpstrerror(tperrno));
break;
}
The tptypes(3c) function returns the type and subtype (if one exists) of a buffer. The
tptypes() function signature is as follows:
long
tptypes(char *ptr, char *
type, char *
subtype)
Table 2‑4 describes the arguments to the
tptypes() function.
Upon success, the tptypes() function returns the length of the buffer in the form of a long integer.
In the event of an error, tptypes() returns a value of
-1 and sets
tperrno(5) to the appropriate error code. For a list of these error codes, refer to the
“Introduction to the C Language Application-to-Transaction Monitor Interface” and
tpalloc(3c) in the
Oracle Tuxedo ATMI C Function Reference.
The tpfree(3c) function frees a buffer allocated by
tpalloc() or reallocated by
tprealloc(). The
tpfree() function signature is as follows:
The tpfree() function takes only one argument,
ptr, which is described in
Listing 2‑5.
When freeing an FML32 buffer using
tpfree(), the routine recursively frees all embedded buffers to prevent memory leaks. In order to preserve the embedded buffers, you should assign the associated pointer to NULL before issuing the
tpfree() routine. When
ptr is NULL, no action occurs.
Listing 2‑11 shows how to use the
tpfree() function to free a buffer.
|
•
|
tpfree(3c) in Oracle Tuxedo ATMI C Function Reference
|
There are two kinds of VIEW typed buffers. The first,
FML VIEW, is a C structure generated from an
FML buffer. The second is simply an independent C structure.
The reason for converting FML buffers into C structures and back again (and the purpose of the
FML VIEW typed buffers) is that while
FML buffers provide data-independence and convenience, they incur processing overhead because they must be manipulated using
FML function calls. C structures, while not providing flexibility, offer the performance required for lengthy manipulations of buffer data. If you need to perform a significant amount of data manipulation, you can improve performance by transferring fielded buffer data to C structures, operating on the data using normal C functions, and then converting the data back to the FML buffer for storage or message transmission.
To use VIEW typed buffers, you must perform the following steps:
To use a VIEW typed buffer in an application, you must set the following environment variables shown in
Table 2‑6.
To use a VIEW typed buffer, you must define the C record in a view description file. The view description file includes, a view for each entry, a view that describes the characteristic C structure mapping and the potential
FML conversion pattern. The name of the view corresponds to the name of the C language structure.
Table 2‑7 describes the fields that must be specified in the view description file for each C structure.
|
|
|
|
|
Data type of the field. Can be set to short, long, float, double, char, string, or carray.
|
|
|
|
|
|
If you will be using the FML-to- VIEW or VIEW-to- FML conversion functions, this field must be included to indicate the corresponding FML name. This field name must also appear in the FML field table file. This field is not required for FML-independent VIEWs.
|
|
|
|
|
|
|
•
|
P—change the interpretation of the NULL value
|
|
•
|
S—one-way mapping from fielded buffer to structure
|
|
•
|
F—one-way mapping from structure to fielded buffer
|
|
•
|
C—generate additional field for associated count member (ACM)
|
|
•
|
L—hold number of bytes transferred for STRING, CARRAY, and MBSTRING
|
|
Note:
|
The view32 command automatically adds the L option flag for MBSTRING typed buffers
|
|
|
|
For STRING and CARRAY buffer types, specifies the maximum length of the value. This field is ignored for all other buffer types.
|
|
|
User-specified NULL value, or minus sign (-) to indicate the default value for a field. NULL values are used in VIEW typed buffers to indicate empty C structure members.
The default NULL value for all numeric types is 0 (0.0 for dec_t). For character types, the default NULL value is ‘ \0’. For STRING, CARRAY, and MBSTRING types, the default NULL value is “ ”.
Constants used, by convention, as escape characters can also be used to specify a NULL value. The view compiler recognizes the following escape constants: \ddd (where d is an octal digit), \0, \n, \t, \v, \r, \f, \\, \’, and \”.
You may enclose STRING, CARRAY, MBSTRING, and char NULL values in double or single quotes. The view compiler does not accept unescaped quotes within a user-specified NULL value.
|
Listing 2‑12 is an excerpt from an example view description file based on an
FML buffer. In this case, the
fbname field must be specified and match that which appears in the corresponding
field table file. Note that the
CARRAY1 field includes an occurrence count of
2 and sets the
C flag to indicate that an additional count element should be created. In addition, the
L flag is set to establish a length element that indicates the number of characters with which the application populates the
CARRAY1 field.
Listing 2‑13 illustrates the same view description file for an independent
VIEW.
Note that the format is similar to the FML-dependent view, except that the
fbname and
null fields are not relevant and are ignored by the
viewc compiler. You must include a value (for example, a dash) as a placeholder in these fields.
To compile a VIEW typed buffer, run the
viewc command, specifying the name of the view description file as an argument. To specify an independent
VIEW, use the
-n option. You can optionally specify a directory in which the resulting output file should be written. By default, the output file is written to the current directory.
Listing 2‑14 provides an example of the header file created by
viewc.
In order to use a VIEW typed buffer in client programs or service subroutines, you must specify the header file in the application
#include statements.
To use RECORD typed buffers, you must perform the following steps:
To use a RECORD typed buffer in an application, you must set the following environment variables.
To use a RECORD typed buffer, you must define the record in a COBOL copybook file. The copybook file includes a
RECORD for each entry. The name of the
RECORD corresponds to the name of the COBOL language field. For more information about COBOL copybook, please see COBOL language reference.
02 BALANCE PIC S9(9) COMP-5.
To generate RECORD description file, run
cpy2record command, specifying the name of the
copybook file as an argument. You can optionally specify a directory in which the resulting output file should be written. By default, the output file is written to the current directory.
The output of the cpy2record command is the binary version of the
RECORD description file, for example,
abc.R.
To use FML typed buffers, you must perform the following steps:
|
•
|
Create an FML header file and specify the header file in a #include statement in the application.
|
FML functions are used to manipulate typed buffers, including those that convert fielded buffers to C structures and vice versa. By using these functions, you can access and update data values without having to know how data is structured and stored. For more information on
FML functions, see
Oracle Tuxedo ATMI FML Function Reference.
To use an FML typed buffer in an application program, you must set the following environment variables shown in
Table 2‑9.
$ /* FML structure */
*base value
name number type flags comments
Table 2‑10 describes the fields that must be specified in the
FML field table file for each
FML field.
Listing 2‑15 illustrates a field table file that may be used with the
FML-dependent VIEW example.
In order to use an FML typed buffer in client programs or service subroutines, you must create an
FML header file and specify it in the application
#include statements.
To create an FML header file from a field table file, use the
mkfldhdr(1) command. For example, to create a file called
myview.flds.h, enter the following command:
For FML32 typed buffers, use the
mkfldhdr32 command.
Listing 2‑16 shows the
myview.flds.h header file that is created by the
mkfldhdr command.
The programming model for the XML buffer type is similar to that for the
CARRAY buffer type: you must specify the length of the buffer with the
tpalloc() function. The maximum supported size of an XML document is 4 GB.
|
•
|
Use the rtag argument to specify the input/output XML root tag for the buffer type conversion in the function call (optional)
|
|
•
|
Set the flag argument to select Xerces parser options (optional)
|
Services using the BUFTYPECONV parameter allow clients or other services to send and receive XML buffers without changing how the existing service handles FML/FML32 buffers.
|
•
|
When a service uses the BUFTYPECONV parameter, all output FML/FML32 buffers are converted to XML. Creating a new service name using the BUFTYPECONV parameter allows you to output XML and keep the original service name to output FML/FML32 buffers.
|
|
•
|
Automatic XML to FML/FML32 buffers conversion only takes action on input XML data. All other input buffers are not converted even if specified in BUFTYPECONV.
|
|
•
|
If a service using the BUFTYPECONV parameter acts as a client, conversion does not take place. For example, a service with the BUFTYPECONV parameter using tpcall() on another service.
|
|
•
|
In /Q messaging mode, TMQFORWARD uses tpcall() to call a service. If the called service uses the BUFTYPECONV parameter, automatic conversion will take place.
|
|
•
|
Add the BUFTYPECONV parameter specifying either XML2FML or XML2FML32, as appropriate.
|
|
•
|
Use TPXPARSFILE environment variable to control Xerces parser attributes and settings (optional).
|
|
•
|
Use tmloadcf -y to compile and load the UBBCONFIG file.
|
|
•
|
Use tmboot -y to boot the server
|
The TPXPARSFILE environment variable designates the fully qualified path to a text file that contains the XercesDOMParser class attribute settings you want to modify.
The <parser attribute> can be any or all of the 14 parser attributes in the following table, where (D) denotes the default setting.
Listing 2‑17 is a sample input plain text file for the
TPXPARSFILE environment variable.
|
|
|
|
|
|
The FLD_SHORT, FLD_LONG, FLD_CHAR, FLD_FLOAT, FLD_DOUBLE, and FLD_STRING fields are simple conversions to and from the XML string values.
|
|
|
|
During FLD_CARRAY field conversion, the XML byte stream value is converted from two alphanumeric characters in XML to one byte value in Tuxedo. That is, each XML pair of characters represents a hex byte value.
|
|
|
|
During conversion to XML, the FLD_PTR fieldname points to one of the following valid Tuxedo buffer types: STRING, MBSTRING, CARRAY, FML, FML32, and VIEW32 and ignores any invalid buffer types. When the buffer content is converted to XML, the BUFTYPE attribute is included in the buffer type tag (see example 1).
During conversion to FML32, the BUFTYPE attribute must be included in the buffer type tag. The only valid values are Tuxedo buffer types: STRING, MBSTRING, CARRAY, FML, FML32, and VIEW32. If the BUFTYPE attribute is not specified or an invalid value is used, the element is ignored in FML32.
|
|
|
|
The FLD_FML32 fieldname is supported with the opening and closing tags based upon the FML field name. This XML document includes multiple descriptions of <fieldname>value</fieldname> for each field contained in the buffer.
|
Note:
|
An optional attribute, Tpmbenc, can be used to specify the encoding for the entire MBSTRING field of FML32 buffers during XML to FML32 conversion
|
|
Example 1:
<ACCT Tpmbenc="EUC"><NM>Smith</NM><TRAN>OPEN</TRAN></ACCT>
Example 2: <BANK><BID>001</BID><ID><NM>Jones</NM><AC>001</AC></ID>
</BANK>
|
|
|
The FLD_VIEW32 fieldname is supported, and therefore, the FLD_INT and FLD_DECIMAL fields are also recognized. FLD_INT is treated like FLD_LONG.
The start and end tag is based on the FLD_VIEW32 field name. It will take a Vname attribute for specifying the view name to use. This XML document includes multiple descriptions of
where fbname is the buffer name of the view member field.
|
|
|
|
The FLD_MBSTRING field conversion uses the Encoding attribute and the field data to describe the FML32 field. This conversion is similar to Fmbpack32 usage. Please note the following conditions:
|
1.
|
If the Encoding attribute is present and the value is specified, the data values are used to create the FLD_MBSTRING value.
|
|
2.
|
If the Encoding attribute is not present and Tpmbenc has been set for the full FML32 buffer, then the FLD_MBSTRING adopts the Tpmbenc value.
|
|
3.
|
If the Encoding attribute is not present and Tpmbenc is not specified, then an attempt is made to get the process environment TPMBENC ( all caps) and use that encoding as the FLD_MBSTRING value in place of the attribute definition.
|
|
|
|
•
|
Conversion between XML and FML/FML32 buffers does not necessarily create the exact same XML document as which you started. Tuxedo FML/FML32 buffers group equivalent field types within a buffer and bases output order on that grouping; therefore, specific element ordering based on input XML is lost. The Xerces parser cannot track FML/FML32 field input order, or control FML/FML32 field output order.
|
|
•
|
tuxenv(5)and UBBCONFIG(5)in Oracle Tuxedo File Formats, Data Descriptions, MIBs, and System Processes Reference
|
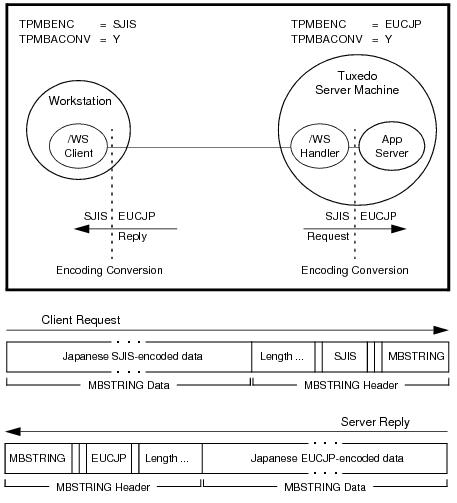
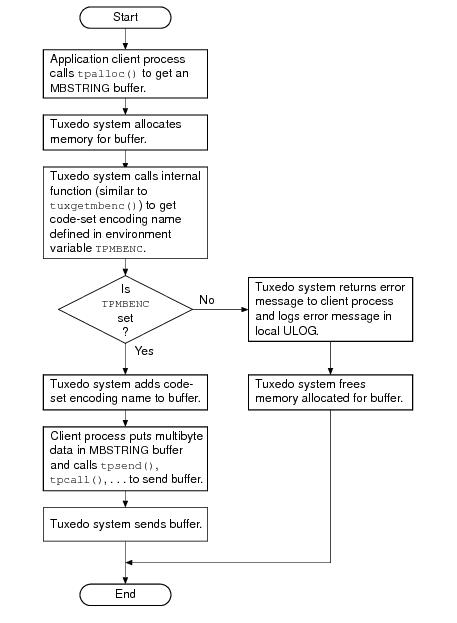
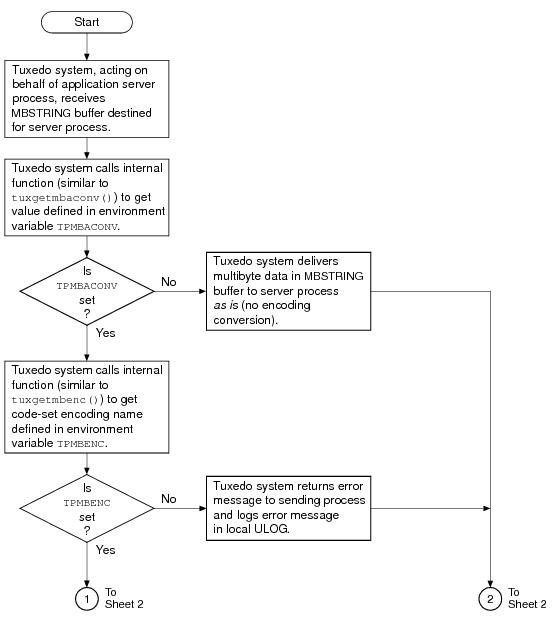
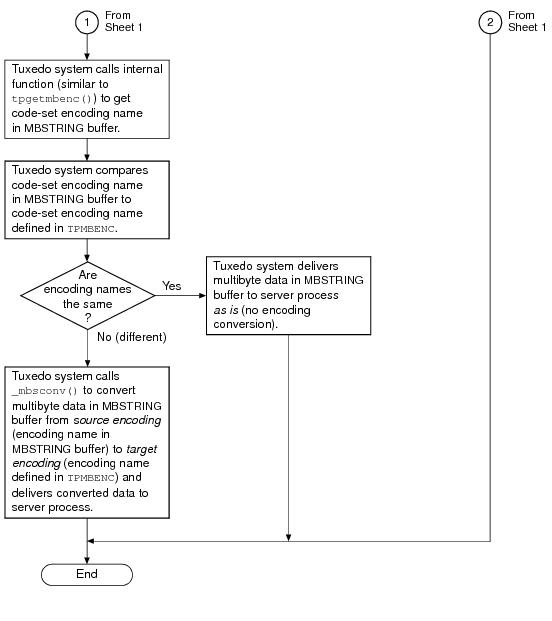
As indicated in the example, the MBSTRING typed buffer is capable of carrying information identifying the code-set character encoding, or simply
encoding, of its user data. In the example, the client-request MBSTRING buffer holds Japanese user data represented by the Shift-JIS (SJIS) encoding, while the server-reply MBSTRING buffer holds Japanese user data represented by the Extended UNIX Code (EUC) encoding. The multibyte character encoding feature reads environment variables
TPMBENC and
TPMBACONV to determine the source encoding, the target encoding, and the state (on or off) of automatic encoding conversion.
MBSTRING can be self-describing if
sendlen is set to zero. Some Tuxedo buffers provide a capability for the buffer to determine its own length if the user does not provide it. This self-describing behavior is triggered when an application sets the
sendlen argument of a Tuxedo function call (for example,
tpcall()) to zero.
|
•
|
_mbspresend() function to the MBSTRING typeswitch function list
|
|
•
|
A protective file, $TUXDIR/udataobj/sendlen0_unsafe_tpmbenc, containing the names of the codeset encoding names which are considered unsafe to use with the feature.
|
The _mbspresend() addition requires any user who customizes Tuxedo buffers to rebuild their applications.
The idea of safe or unsafe encoding names specified by TPMBENC comes from whether or not the multibyte character data for these encodings can contain embedded NULLs. Because the
_mbspresend() function uses
strlen() to determine the length of the data, an embedded NULL causes the length to be incorrectly set and the wrong number of data bytes are sent.
The default list in sendlen0_unsafe_tpmbenc has the multibyte Unicode encoding names (in uppercase and lowercase, for convenience) which can contain embedded NULLs. You should modify this list as application administration or performance is considered.
libiconv, an encoding conversion library that provides support for many coded character sets and encodings, is included with the Oracle Tuxedo 8.1 or later software distribution. The multibyte character encoding feature uses the character conversion functions in this library to convert from any of the supported character encodings to any other supported character encoding, through Unicode conversion.
libiconv provides support for the following encodings:
|
•
|
ASCII, ISO-8859-{1,2,3,4,5,7,9,10,13,14,15,16},
|
You may find that the buffer types supplied by the Oracle Tuxedo system do not meet your needs. For example, perhaps your application uses a data structure that is not flat, but has pointers to other data structures, such as a parse tree for an SQL database query. To accommodate unique application requirements, the Oracle Tuxedo system supports customized buffers.
Table 2‑12 defines the list of routines that you may need to specify for each buffer type. If a particular routine is not applicable, you can simply provide a NULL pointer; the Oracle Tuxedo system uses default processing, as necessary.
struct tmtype_sw_t tm_typesw[] = {
{
"CARRAY", /* type */
"*", /* subtype */
0 /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
NULL, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
NULL, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"STRING", /* type */
"*", /* subtype */
512, /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
_strpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_strencdec, /* encdec */
NULL, /* route */
_sfilter, /* filter */
_sformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"FML", /* type */
"*", /* subtype */
1024, /* dfltsize */
_finit, /* initbuf */
_freinit, /* reinitbuf */
_funinit, /* uninitbuf */
_fpresend, /* presend */
_fpostsend, /* postsend */
_fpostrecv, /* postrecv */
_fencdec, /* encdec */
_froute, /* route */
_ffilter, /* filter */
_fformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"VIEW", /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
/* XATMI - identical to CARRAY */
"X_OCTET", /* type */
"*", /* subtype */
0 /* dfltsize */
},
{ /* XATMI - identical to VIEW */
{'X','_','C','_','T','Y','P','E'}, /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
/* XATMI - identical to VIEW */
{'X','_','C','O','M','M','O','N'}, /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"FML32", /* type */
"*", /* subtype */
1024, /* dfltsize */
_finit32, /* initbuf */
_freinit32, /* reinitbuf */
_funinit32, /* uninitbuf */
_fpresend32, /* presend */
_fpostsend32, /* postsend */
_fpostrecv32, /* postrecv */
_fencdec32, /* encdec */
_froute32, /* route */
_ffilter32, /* filter */
_fformat32, /* format */
_fpresend232, /* presend2 */
_fmbconv32 /* multibyte code-set encoding conversion */
},
{
"VIEW32", /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit32, /* initbuf */
_vreinit32, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend32, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec32, /* encdec */
_vroute32, /* route */
_vfilter32, /* filter */
_vformat32, /* format */
NULL, /* presend2 */
_vmbconv32, /* multibyte code-set encoding conversion */
},
{
"XML", /* type */
"*", /* subtype */
0, /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
NULL, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
_xroute, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"MBSTRING", /* type */
"*", /* subtype */
0, /* dfltsize */
_mbsinit, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
_mbspresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
NULL, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
_mbsconv /* multibyte code-set encoding conversion */
},
/*
* The following definitions are in $TUXDIR/include/tmtypes.h
*/
#define TMTYPELEN ED_TYPELEN
#define TMSTYPELEN ED_STYPELEN
struct tmtype_sw_t {
char type[TMTYPELEN]; /* type of buffer */
char subtype[TMSTYPELEN]; /* subtype of buffer */
long dfltsize; /* default size of buffer */
/* buffer initialization function pointer */
int (_TMDLLENTRY *initbuf) _((char _TM_FAR *, long));
/* buffer reinitialization function pointer */
int (_TMDLLENTRY *reinitbuf) _((char _TM_FAR *, long));
/* buffer un-initialization function pointer */
int (_TMDLLENTRY *uninitbuf) _((char _TM_FAR *, long));
/* pre-send buffer manipulation func pointer */
long (_TMDLLENTRY *presend) _((char _TM_FAR *, long, long));
/* post-send buffer manipulation func pointer */
void (_TMDLLENTRY *postsend) _((char _TM_FAR *, long, long));
/* post-receive buffer manipulation func pointer*/
long (_TMDLLENTRY *postrecv) _((char _TM_FAR *, long, long));
/* XDR encode/decode function pointer */
long (_TMDLLENTRY *encdec) _((int, char _TM_FAR *, long, char _TM_FAR *, long));
/* routing function pointer */
int (_TMDLLENTRY *route) _((char _TM_FAR *, char _TM_FAR *, char _TM_FAR *,
long, char _TM_FAR *));
/* buffer filtering function pointer */
int (_TMDLLENTRY *filter) _((char _TM_FAR *, long, char _TM_FAR *, long));
/* buffer formatting function pointer */
int (_TMDLLENTRY *format) _((char _TM_FAR *, long, char _TM_FAR *,
char _TM_FAR *, long));
/* process buffer before sending, possibly generating copy */
long (_TMDLLENTRY *presend2) _((char _TM_FAR *, long,
long, char _TM_FAR *, long, long _TM_FAR *));
/* Multibyte code-set encoding conversion function pointer*/
long (_TMDLLENTRY *mbconv) _((char _TM_FAR *, long,
char _TM_FAR *, char _TM_FAR *, long, long _TM_FAR *));
/* this space reserved for future expansion */
void (_TMDLLENTRY *reserved[8]) _((void));
};
/*
* application types switch pointer
* always use this pointer when accessing the table
*/
extern struct tmtype_sw_t *tm_typeswp;
|
•
|
ptr is a pointer to the application data buffer.
|
|
•
|
dlen is the length of the data as passed into the routine.
|
|
•
|
mdlen is the size of the buffer in which the data resides.
|
If you use our _mypresend compression routine, you will probably also need a corresponding
_mypostrecv routine to decompress the data at the receiving end. Follow the template shown in the
buffer(3c) entry in the
Oracle Tuxedo C Function Reference.
#include <stdio.h>
#include <tmtypes.h>
/* Customized the buffer type switch */
static struct tmtype_sw_t tm_typesw[] = {
{
"SOUND", /* type */
“", /* subtype */
50000, /* dfltsize */
snd_init, /* initbuf */
snd_init, /* reinitbuf */
NULL, /* uninitbuf */
snd_cmprs, /* presend */
snd_uncmprs, /* postsend */
snd_uncmprs /* postrecv */
},
{
"FML", /* type */
"", /* subtype */
1024, /* dfltsize */
_finit, /* initbuf */
_freinit, /* reinitbuf */
_funinit, /* uninitbuf */
_fpresend, /* presend */
_fpostsend, /* postsend */
_fpostrecv, /* postrecv */
_fencdec, /* encdec */
_froute, /* route */
_ffilter, /* filter */
_fformat /* format */
},
{
""
}
};
In the previous listing, we added a new type: SOUND. We also removed the entries for
VIEW,
X_OCTET,
X_COMMON, and
X_C_TYPE, to demonstrate that you can remove any entries that are not needed in the default switch. Note that the array still ends with the NULL entry.
|
2.
|
Compile tmtypesw.c with the flags required for shared objects.
|
|
4.
|
Copy libbuft.so.71 from the current directory to a directory in which it will be visible to applications, and processed before the default shared object supplied by the Oracle Tuxedo system. We recommend using one of the following directories: $APPDIR, $TUXDIR/lib, or $TUXDIR/bin (on a Windows 2003 platform).
|
The purpose of the TYPE parameter in the
MACHINES section of the configuration file is to group together machines that have the same form of data representation (and use the same compiler) so that data conversion is done on messages going between machines of different
TYPEs. For the default buffer types, data conversion between unlike machines is transparent to the user (and to the administrator and programmer, for that matter).
|
•
|
You should use the semantics of the _tmencdec routine shown on reference page buffer(3c) in Oracle Tuxedo ATMI C Function Reference; that is, you should code your routine so that it uses the same arguments and returns the same values on success or failure as the _tmencdec routine. When defining new buffer types, follow the procedure provided in “Defining Your Own Buffer Types” on page 2‑56 for building servers with services that will use your new buffer type.
|