| Oracle® Fusion Middleware Oracle Business Intelligence Publisherデータ・モデリング・ガイド 12c (12.2.1) E70035-01 |
|

 前へ |
| Oracle® Fusion Middleware Oracle Business Intelligence Publisherデータ・モデリング・ガイド 12c (12.2.1) E70035-01 |
|
前へ |
不必要に複雑なデータ・セットを使用すると、データ・モデリングの実行時のパフォーマンスが低下します。この章では、効率的なデータ・モデルを作成するヒントを示します。
WebLogic Serverでは、1つのリクエストにかかるデフォルトのタイムアウトは、それぞれのスレッドに対して600秒です。時間が600秒を超えると、WebLogic Serverはスレッドに「スタック」と印を付けます。スタック・スレッドの数が25に達すると、サーバーはシャットダウンします。
この問題を回避するためには、SQL実行時間がWebLogic Serverの設定を超えないようにします。
次のヒントを考慮に入れると、より効率的なSQLデータ・セットを作成できます。
問合せは、レポートに必要なデータのみを返すようにします。超過したデータを返すと、OutOfMemory例外が発生する可能性があります。
たとえば、次のようなすべての列を返す指定を使用しないようにします。
SELECT * FROM EMPLOYEES;
*を使用しないようにします。
返されるデータを制限する2つのベスト・プラクティスは次のとおりです。
必要な列のみを選択する
次に例を示します。
SELECT DEPARTMENT_ID, DEPARTMENT_NAME FROM EMPLOYEES;
可能なかぎりWHERE句およびバインド・パラメータを使用し、返されるデータをより厳密に制限する。
この例では、必要な列のみおよびパラメータの値に一致する列のみを選択します。
SELECT DEPARTMENT_ID, DEPARTMENT_NAME FROM EMPLOYEES WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
列名を短縮すると、得られるXMLファイルも小さくなり、システムによる解析も速くなります。別名を使用して列名を短縮して、I/O処理時間を短縮し、レポートの効率を改善します。
この例では、DEPARTMENT_IDが"id"に短縮され、DEPARTMENT_NAMEが"name"に短縮されます。
SELECT DEPARTMENT_ID id, DEPARTMENT_NAME nameFROM EMPLOYEES WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
データ・モデル・グループ機能を使用すると、問合せで取得したレコードを削除できますが、これは中間層で処理されるため、データベース層よりも効率が低下します。
WHERE句条件を使用して、問合せで不要なレコードを削除することが、ベスト・プラクティスです。
WHERE句でのPL/SQL関数のコールは、複数の実行を伴います。これらの関数のコールは、一致するデータベースで見つかったすべての行で実行されます。また、この構造ではPL/SQLからSQLへのコンテキストの変換が必要なため、効率が低下します。
ベスト・プラクティスとして、PL/SQLコールをWHERE句では実行せず、ベース表を結合してフィルタを追加してください。
システムのDUAL表を使用してsysdateまたはその他の定数を返すことは、効率的ではないため、必要な場合以外は使用しないでください。
たとえば、次のかわりに:
SELECT DEPARTMENT_ID ID, (SELECT SYSDATE FROM DUAL) TODAYS_DATE FROM DEPARTMENTS WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
考慮事項:
SELECT DEPARTMENT_ID ID, SYSDATE TODAYS_DATE FROM DEPARTMENTS WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
最初の例では、DUALは必要ではありません。SYSDATEに直接アクセスできます。
要素(グループ内)レベルまたは行レベルで、パッケージ関数はコールできません。ただし、これらの関数はデータ・モデルを実行するリクエストごとに1回のみ実行されるため、パッケージ関数コールをグローバル要素レベルで含めることができます。
例:
<dataStructure>
<group name="G_order_short_text" dataType="xsd:string" source="Q_ORDER_ATTACH">
<element name="order_attach_desc" dataType="xsd:string" value="ORDER_ATTACH_DESC"/>
<element name="order_attach_pk" dataType="xsd:string" value="ORDER_ATTACH_PK"/>
<element name="ORDER_TOTAL _FORMAT" dataType="xsd:string" value=" WSH_WSHRDPIK_XMLP_PKG.ORDER_TOTAL _FORMAT "/> <!-- This is wrong should not be called within group.-->
</group>
<element name="S_BATCH_COUNT" function="sum" dataType="xsd:double" value="G_mo_number.pick_slip_number"/>
</dataStructure>
複数のレポートを処理するために、データ・モデルを複数のデータ・セットで作成することが望ましいように思われることがありますが、これによりパフォーマンスは非常に低下します。レポートの実行時に、データ・プロセッサは、最終出力にそのデータが使用されるかどうかにかかわらず、すべてのデータ・セットを実行します。
レポートのパフォーマンスおよびメモリー効率の向上のため、単一のデータ・モデルを使用して複数のレポートをサポートする前に、十分に検討してください。
データ・モデルでは、親子階層を作成するメカニズムが提供され、1つのデータ・セットが別のデータ・セットにリンクされます。実行時、データ・プロセッサは、親問合せを実行し、親問合せのそれぞれの行に対して子問合せを実行します。データ・モデルに複数のネストされた親子関係があると、処理の速度が低下します。
データ・セットをネストしないようにするには、複数のデータ・セット問合せを、WITH句を使用して単一のデータ・セット問合せに結合します。
複数のデータ・セットを1つのデータ・セットに結合する際の、一般的なヒントを次に示します。
親および子が1対1の関係、つまり1つの親行に必ず1つの子行がある場合、親および子のデータ・セットを単一の問合せにマージします。
親問合せに、子問合せよりも多くの行がある場合。たとえば、請求書配布表が請求書表にリンクされている場合、分布表には請求書表に比べると膨大な数の行があります。個々の子問合せは1秒もかかりませんが、子問合せに該当する分布表ではスタック・スレッドが発生します。
次のような場合に、WITH句を使用します。
Query Q1: SELECT DEPARTMENT_ID EDID,EMPLOYEE_ID EID,FIRST_NAME FNAME,LAST_NAME LNAME,SALARY SAL,COMMISSION_PCT COMMFROM EMPLOYEES Query Q2: SELECT DEPARTMENT_ID DID,DEPARTMENT_NAME DNAME,LOCATION_ID LOCFROM DEPARTMENTS
WITH句を使用し、これらの問合せを1つに結合するには、次のようにします。
WITH Q1 as (SELECT DEPARTMENT_ID DID,DEPARTMENT_NAME DNAME,LOCATION_ID LOC FROM DEPARTMENTS), Q2 as (SELECT DEPARTMENT_ID EDID,EMPLOYEE_ID EID,FIRST_NAME FNAME,LAST_NAME LNAME,SALARY SAL,COMMISSION_PCT COMM FROM EMPLOYEES) SELECT Q1.*, Q2.* FROM Q1 LEFT JOIN Q2 ON Q1.DID=Q2.EDID
インライン問合せは、1行に対して1つの列を実行します。たとえば、主問合せに100列あり、1000行を伴う場合、列問合せはそれぞれ1000回実行されます。つまり、100を1000回繰り返します。これはスケーラブルではなく、パフォーマンスがよくありません。インライン・サブ問合せは、可能なかぎり避けてください。
次のようなインライン問合せの使用を避けます。この問合せで返される行が少量の場合、このアプローチは効果的に機能しますが、問合せが10000行を返す場合、サブ・インライン問合せが10000回実行され、問合せの結果がスタック・スレッドになる可能性があります。
SELECT NATIONAL_IDENTIFIERS,NATIONAL_IDENTIFIER, PERSON_NUMBER, PERSON_ID, STATE_CODE FROM (select pprd.person_id,(select REPLACE(national_identifier_number,'-') from per_ national_identifiers pni where pni.person_id = pprd.person_id and rownum<2) national_identifiers,(select national_identifier_number from per_national identifiers pni where pni.person_id = pprd.person_id and rownum<2) national_ identifier,(select person_number from per_all_people_f ppf where ppf.person_id = pprd.person_id and :p_effective_start_date between ppf.effective_start_date and ppf.effective_ end_date) PERSON_NUMBER (Select hg.geography_code from hz_geographies hg where hg.GEOGRAPHY_NAME = paddr.region_2 and hg.geography_type = 'STATE') state_code
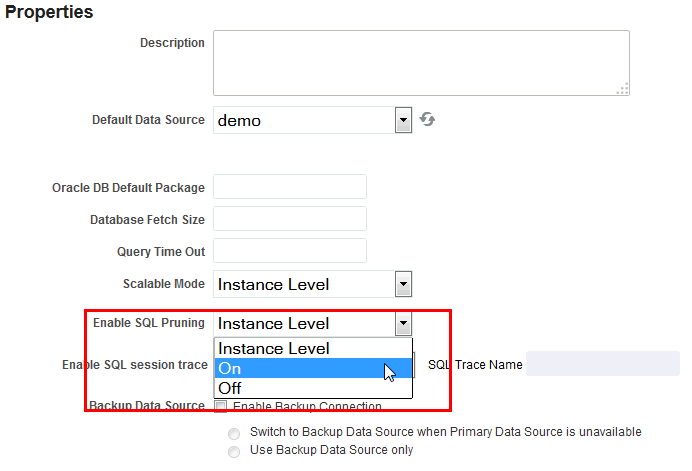
Oracleデータベースでは、パラメータ当たり最大1000のバインド値が使用できます。大量のパラメータ値のバインドは、非効率的です。パラメータに対して100より多い値をバインドしないでください。
メニュー・タイプのパラメータを作成し、値のリストに多数の値が含まれる場合、「複数選択」および「全選択可能」オプションの両方を有効化し、大量の値が渡されないように「NULL値が渡されました」を選択する必要があります。
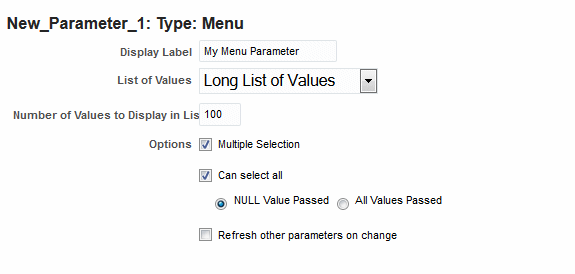
レポート利用者は、多くの場合、次の条件をサポートするレポートを実行する必要があります。
パラメータが選択されない(null)と、すべてが返される。
複数パラメータの値の選択が可能である
これらの場合、NVL()は使用できないため、次を使用します
COALESCE()。(Oracle Databaseに対する問合せの場合)
CASE / WHEN。(Oracle BI EE (論理)問合せの場合)
例:
SELECT EMPLOYEE_ID ID, FIRST_NAME FNAME, LAST_NAME LNAME FROM EMPLOYEES WHERE DEPARTMENT_ID = NVL(:P_DEPT_ID, DEPARTMENT_ID
この問合せ構文は、P_DEPT_IDの値が単一値またはnullの場合のみ、正常に機能します。複数値を渡すと、この構文は機能しません。
複数値をサポートするには、次の構文を使用します。
Oracleデータベースの場合:
SELECT EMPLOYEE_ID ID, FIRST_NAME FNAME, LAST_NAME LNAME FROM EMPLOYEES WHERE (DEPARTMENT_ID IN (:P_DEPT_ID) OR COALESCE (:P_DEPT_ID, null) is NULL)
Oracle BI EEデータ・ソースの場合:
(CASE WHEN ('null') in (:P_YEAR) THEN 1 END =1 OR "Time"."Per Name Year" in (:P_YEAR))
Oracle BI EEでは、パラメータのデータ・タイプは文字列です。数値および日付データ・タイプはサポートされていません。
データ・モデルでは、グループをブレークする、およびデータをソートする機能を使用できます。ソートは、親グループのブレーク列に対してのみサポートされます。たとえば、従業員のデータ・セットが部門と管理職でグループ化されている場合は、部門によってXMLデータをソートできます。最終的なレポートまたはテンプレートで、どのようにデータをソートしておく必要があるかがわかっている場合は、データ生成時にソートを指定するとドキュメント生成が最適化されます。SELECT句で指定された列順序は、データ構造内の要素の順序に正確に一致する必要があります。そうしないと、グループのブレークおよびデータのソートは実行されません。複雑になるため、異なるレベルで複数のソートを伴う複数のグループ化は実行しないでください。
例: 次に示す例では、ソートおよびグループ・ブレークは、親グループ、G_1にのみ適用されます。問合せ、データ・セット・ダイアログおよびデータ構造内の列順序に注目してください。SQL列順序は、データ構成要素のフィールドの順序に完全に一致します。一致しない場合、データが破損することがあります。
例:
SELECT d.DEPARTMENT_ID DEPT_ID, d.DEPARTMENT_NAME DNAME,
E.FIRST_NAME FNAME,E.LAST_NAME LNAME,E.JOB_ID JOB,E.MANAGER_ID
FROM EMPLOYEES E,DEPARTMENTS D
WHERE D.DEPARTMENT_ID = E.DEPARTMENT_ID
ORDER BY d.DEPARTMENT_ID, d.DEPARTMENT_NAME
問合せを定義すると、次のように、データ・モデル・デザイナを使用して、データ要素の選択、およびグループ・ブレークの作成が可能になります。
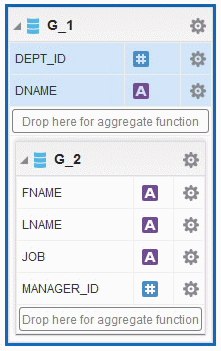
グループ・ブレークのあるデータ構造を次に示します。
<output rootName="DATA_DS" uniqueRowName="false"> <nodeList name="data-structure"> <dataStructure tagName="DATA_DS"> <group name="G_1" label="G_1" source="q1"> <element name="DEPT_ID" value="DEPT_ID" label="DEPT_ID" fieldOrder="1"/> <element name="DNAME" value="DNAME" label="DNAME" fieldOrder="2"/> <group name="G_2" label="G_2" source="q1"> <element name="FNAME" value="FNAME" label="FNAME" fieldOrder="3"/> <element name="LNAME" value="LNAME" label="LNAME" fieldOrder="4"/> <element name="JOB" value="JOB" label="JOB" fieldOrder="5"/> <element name="MANAGER_ID" value="MANAGER_ID" label="MANAGER_ID" fieldOrder="6"/> </group> </group> </dataStructure> </nodeList> </output>
SQL問合せの値リストの制限は、1000行までです。ブラインド・ランナウェイ問合せを値リストに追加すると、OutOfMemory例外が発生します。LOVで返される行の数はメモリーに格納されるため、行数が多ければ多いほど、メモリー使用量が増加します。
Oracle BI Publisherでは、Oracle Fusion ApplicationsおよびOracle E-Business Suiteの字句パラメータをサポートしています。字句パラメータを使用すると、動的問合せを作成できます。
BI Publisherでは、字句パラメータは次のように定義されます。
字句 - データ・モデル・パラメータとして定義されたPL/SQLパッケージ化された変数。
キー・フレックスフィールド(KFF) – データ・セット問合せ内の字句トークン。KFFは、意味のあるセグメント値からなるコードを作成し、単一値をコード結合IDとして格納します。キー・フレックスフィールドは、WHERE句の中でSELECT / SEGMENT METADATAタイプまたは条件で使用された場合、常に単一の列を返します。キー・フレックスフィールドは、実行時に字句定義を抽出し、SQL問合せ内で置き換えられます。
付加フレックスフィールド(DFF) - ビジネスで重要かつ固有の追加情報を追跡するためのカスタム化可能な拡張領域を提供します。DFFはコンテキスト依存で、情報が格納されるアプリケーション内の場所は、ユーザー入力の他の値により異なります。キー・フレックスフィールドとは異なり、付加フレックスフィールドには複数のコンテキスト依存セグメントがあります。
使用方法: 字句の定義の際、字句の使用方法に一致する名前を付けます。これにより、エディタ・ダイアログがポップアップし、SQL問合せのデフォルト値の入力が容易になります。たとえば、字句をSELECT句で使用する場合、"_select"を接尾辞に使用します。デフォルト値は、メタデータの取得に有効な値です。
次の例では、字句の使用方法を示します。
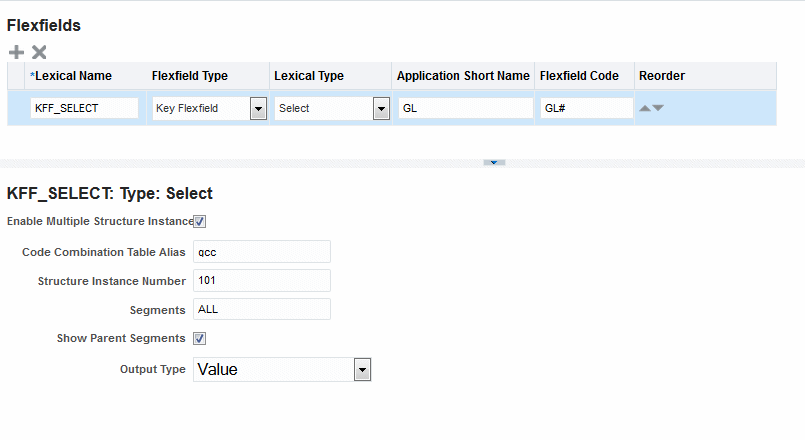
データ・セット問合せを選択された列に対して作成する場合、次のようにして、列の別名を指定します。
SELECT gcc.CODE_COMBINATION_ID, GCC.ATTRIBUTE_CATEGORY, gcc.segment1 seg1, gcc.segment2 seg2, gcc.segment3 seg3, gcc.segment4 seg4, gcc.segment5 seg5, &KFF_SELECT account FROM GL_CODE_COMBINATIONS GCC WHERE gcc.CHART_OF_ACCOUNTS_ID = 101 AND &KFF_WHERE
問合せを保存すると、ポップアップ・ダイアログでデフォルト値の入力を求められます。設計時にSQLメタデータを取得するには、有効なSQL問合せを形成するデフォルト値を指定してください。次に例を示します。
字句の使用方法が、SELECT句の場合、nullを入力できます
字句の使用方法が、WHERE句の場合、1 = 1または1 = 2を入力できます
字句の使用方法が、ORDER BY句の場合、1を入力できます

Oracle BI Publisherは、常に、日付列または日付パラメータをタイムスタンプ・パラメータとしてバインドします。タイムスタンプに変換されないようにするには、パラメータを文字列として定義して、DD-MON-YYYYの書式設定で値を渡し、RDBMS日付書式設定に合せます。
インタラクティブ/オンライン・モードでのレポートの実行は、インメモリー処理を使用します。次のガイドラインを使用して、レポートをオンラインで実行する適切な時期を判断してください。
次の場合、オンライン/インタラクティブ・モードを使用します。
レポート出力サイズが、50MBより小さい場合
ブラウザは、大量のデータのロードを想定していません。ブラウザで50MBを超えてロードすると、速度が低下するか、セッションがクラッシュする可能性があります。
データ・モデルSQL問合せタイムアウトが、600秒より短い場合
600秒を超えるSQL問合せを実行すると、WebLogic Serverスタック・スレッドが発生します。このような状況を回避するために、ログ実行問合せをスケジュールします。スケジューラ・プロセスは、Weblogicサーバーのスレッドではなく、独自のJVMスレッドを使用します。これは、オンラインでレポートを実行するよりも、レポートのスケジュールが効率的です。
データ構造内の要素の合計数が、500より少ない場合
データ・モデルのデータ構造内に多数のデータ要素が含まれる場合、データ・プロセッサがメモリー内に要素の値を保持する必要があるため、OutOfMemory例外が発生します。このような状況を回避するために、これらのレポートをスケジュールします。スケジュールされたレポートでは、データ・プロセッサは一時ファイル・システムを使用してデータを保存および処理を実行します。
CLOB列またはBLOB列がない場合
オンライン処理では、CLOBまたはBLOB列全体を、メモリー内に保持します。CLOBまたはBLOB列を含むレポートをスケジュールする必要があります。
次のプロパティを使用して、システムでメモリー・エラーが発生するのを防ぎます。
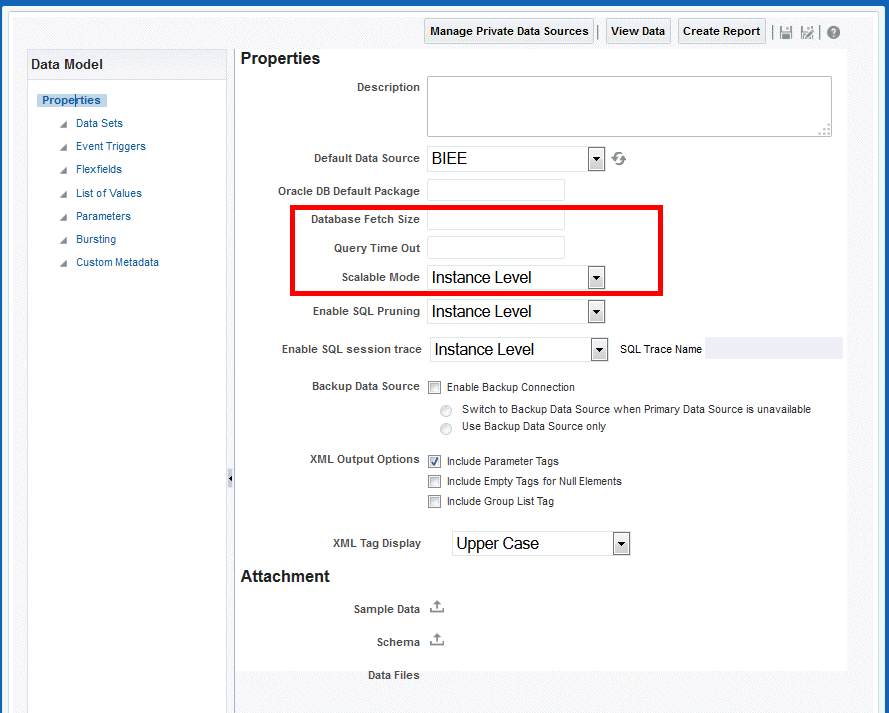
「問合せタイムアウト」プロパティでは、その時間内にデータベースがSQL文を実行する必要がある時間の制限を秒単位で指定します。BI Publisherでは、ユーザー優先の問合せタイムアウトを、データ・モデル・レベルで設定するメカニズムが提供されます。デフォルト値は600秒です。
600秒未満で実行できない問合せは、十分に最適化されません。DBAまたはパフォーマンスを熟知した人物が、問合せを分析してチューニングする必要があります。
タイムアウト値を大きくすると、WebLogic Serverスタック・スレッドが発生する可能性があります。他のすべての最適化および代替が使用可能でないかぎり、この値を大きくしないでください。
このプロパティは、データベースから一度にフェッチする行数を指定します。この設定は、データ・モデルの一般プロパティ内で「データベース・フェッチ・サイズ」を設定することにより、データ・モデル・レベルでオーバーライドされます。
高い値を設定すると、データベースとの間のやりとりの回数を削減できますが、メモリー消費が増加します。このプロパティを変更する前に、データ・モデル内の要素数を考慮してください。
BI Publisherでは、プロパティ「自動DBフェッチ・サイズ・モードの有効化」をtrueに設定することをお薦めします。これにより、システムでフェッチ・サイズが実行時に計算されます。
「スケーラブル・モード」プロパティが使用可能な場合、BI Publisherは一時ファイルを使用してデータを生成します。データ・プロセッサは最低量のメモリーを使用します。「スケーラブル・モード」プロパティは、データ・モデル・レベルおよびインスタンス・レベルで設定できます。データ・モデル設定は、インスタンス値をオーバーライドします。
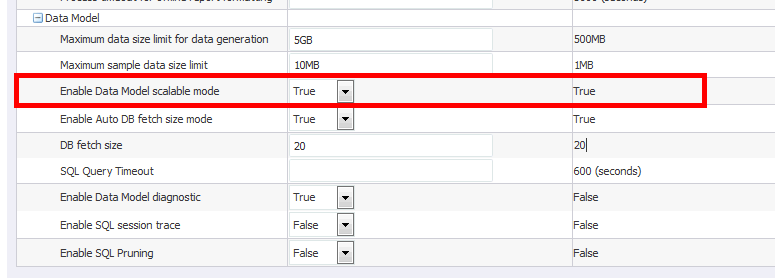
インスタンス値を、次のように「管理者」→「ランタイム・プロパティ」→「データ・モデル」から設定します。
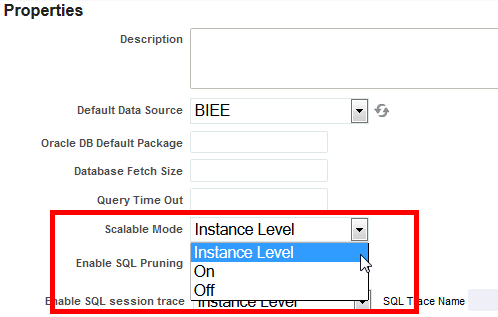
インスタンス値は、次のように、「データ・モデル」設定でオーバーライドされます。
次の表に、各レベルで設定可能な値に対して予測される結果の詳細を示します。
| 「スケーラブル・モード」のインスタンス値 | 「スケーラブル・モード」の「データ・モデル」値 | 予想される結果 |
|---|---|---|
| オン | インスタンス | オン |
| オフ | インスタンス | オフ |
| オン | オン | オン |
| オン | オフ | オフ |
| オフ | オン | オン |
| オフ | オフ | オフ |
問合せのチューニングは、レポートのパフォーマンスの向上のために非常に重要な手順です。実行計画、SQL監視、TKPROFのSQLトレース機能は、Oracleデータベースで実行されるアプリケーションのSQL問合せのチューニングに役立つ基本的なパフォーマンス診断ツールです。
Oracle BI Publisherでは、実行計画およびSQL監視レポートを生成し、SQLセッション・トレースを有効化するメカニズムが提供されます。この機能は、Oracle Databaseに対して実行されるSQL文にのみ適用されます。BI Serverまたはその他のいずれかのタイプのデータベースに対する論理問合せはサポートされていません。
単一問合せに対するデータ・レベル、またはレポート内のすべての問合せに対するレポート・レベルで、実行計画を生成できます。実行計画の解釈に関する詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。
実際に問合せを実行する前に、「SQLデータ・セット」の「編集」ダイアログから、実行計画を生成できます。これにより、計画を正確に予測することが可能です。問合せは、null値でバインドして実行されます。
「SQL問合せの編集」ダイアログの「実行計画の生成」をクリックします。生成されたドキュメントを、NotepadまたはWordPadなどのテキスト・エディタで開きます。
レポートの実行計画を生成するには、スケジューラを使用してレポートを実行します。
「新規」メニューで、「レポート・ジョブ」を選択します。
スケジュールするレポートを選択し、「診断」タブをクリックします。
注意: 「診断」タブにアクセスするには、BI管理者またはBIデータ・モデル開発者権限が必要です。
「SQL実行計画の有効化」および「データ・エンジン診断の有効化」を選択します。 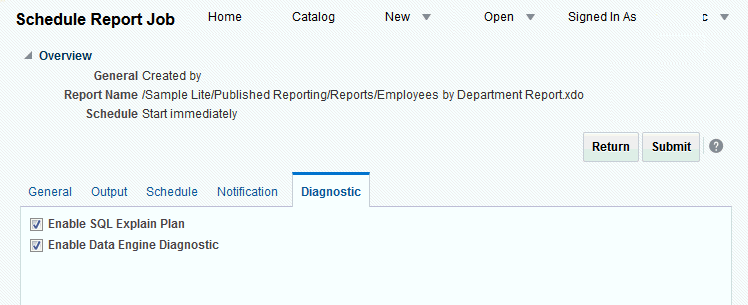
レポートを実行します。
レポートが終了したら、「レポート履歴」ページに移動します。
(「ホーム」ページから、「参照/管理」で「レポート・ジョブ履歴」を選択します。)
詳細を表示するレポートを選択します。「出力および配信」から、「診断ログ」をクリックして実行計画の出力をダウンロードします。 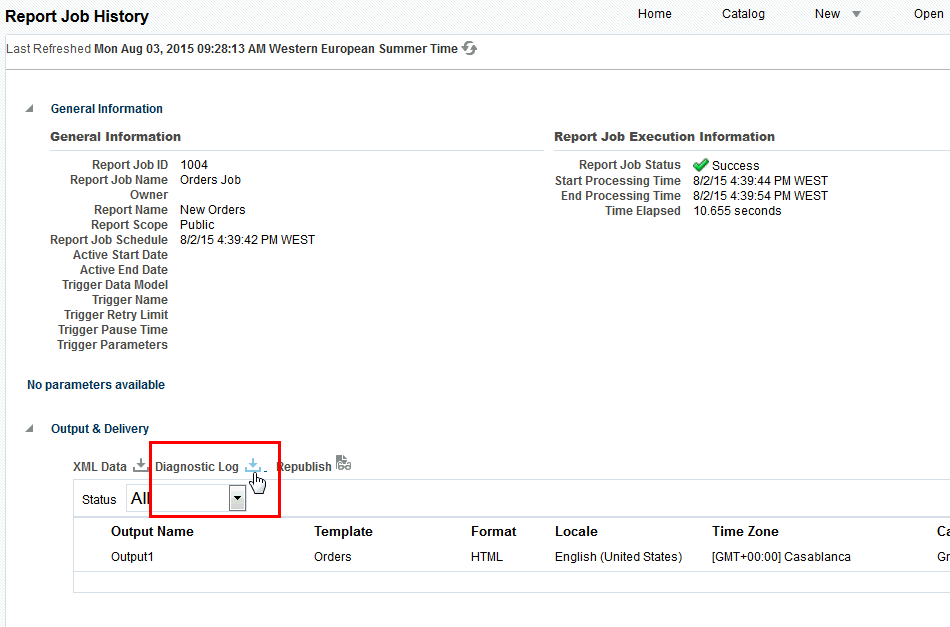
実行計画の例を次に示します。
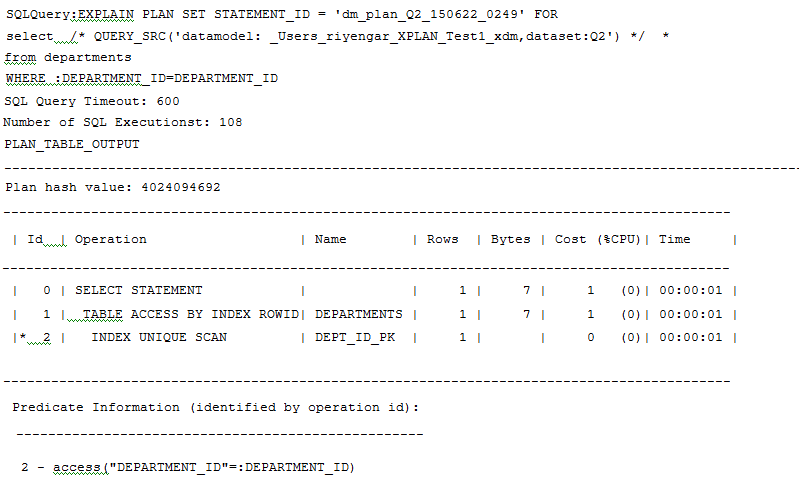
実行計画を分析し、影響が大きいSQL文を特定します。
必要なフィルタ条件を追加し、不要な結合を削除します。
大きな表に対するFTS (全表スキャン)を回避および削除します。小さな表に対する全表スキャンの実行は、迅速で問合せのフェッチを改善する場合もあります。小さな表では、キャッシュを使用してください。
SQLヒントを使用して、適切な索引を強制的に使用します。
複雑なサブ問合せの使用を避け、必要に応じグローバル一時表を使用します。
複数の集計でOracle SQL分析機能を使用します。
できるかぎり、WHERE句内で大量のサブ問合せの使用を避けます。かわりに、外部結合で問合せをリライトしてください。
HAVINGおよびIN / NOT INなどのWHERE句条件でグループ関数の使用を避けます。
複雑な集計関数では、CASE文およびDECODE関数を使用します。
データベース管理者と協力して、表の統計を収集します。
サーバーの速度が非常に遅い場合、ネットワーク/IO/ディスクの問題を分析し、サーバー・パラメータを最適化します。
いくつかのシナリオで、大量のデータのフェッチを回避できない場合、データベースでPGAヒープ・サイズ・エラーが発生する場合があります。これらの問題を解決するために、最終手段としてPGAヒープ・サイズを大きくします。次の文を使用して、ヒープ・サイズを大きくします。
alter session set events '10261 trace name context forever, level 2097152'