8 Built-In Single-Row Functions
This chapter provides a reference to single-row functions in Oracle Continuous Query Language (Oracle CQL). Single-row functions return a single result row for every row of a queried stream or view.
This chapter includes the following section:
8.1 Introduction to Oracle CQL Built-In Single-Row Functions
Table 8-1 lists the built-in single-row functions that Oracle CQL provides.
|
Table 8-1 Oracle CQL Built-in Single-Row Functions
|
Note:
Built-in function names are case sensitive and you must use them in the case shown (in lower case).
Note:
In stream input examples, lines beginning with h (such as h 3800) are heartbeat input tuples. These inform Oracle Stream Explorer that no further input will have a timestamp lesser than the heartbeat value.
8.2 concat
Syntax
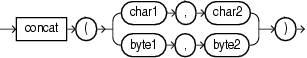
Purpose
concat returns char1 concatenated with char2 as a char[] or byte1 concatenated with byte2 as a byte[]. The char returned is in the same character set as char1. Its data type depends on the data types of the arguments.
Using concat, you can concatenate any combination of character, byte, and numeric data types. The concat performs automatic numeric to string conversion.
This function is equivalent to the concatenation operator (||).
To concatenate xmltype arguments, use xmlconcat. For more information, see xmlconcat.
Examples
concat Function
Consider the query chr_concat in concat and data stream S4 in concat. Stream S4 has schema (c1 char(10)). The query returns the relation in concat.
Example 8-1 concat Function Query
<query id="chr_concat"><![CDATA[
select
concat(c1,c1),
concat("abc",c1),
concat(c1,"abc")
from
S4[range 5]
]]></query>
Example 8-2 concat Function Stream Input
Timestamp Tuple 1000 2000 hi 8000 hi1 9000 15000 xyz h 200000000
Example 8-3 concat Function Relation Output
Timestamp Tuple Kind Tuple 1000: + ,abc,abc 2000: + hihi,abchi,hiabc 6000: - ,abc,abc 7000: - hihi,abchi,hiabc 8000: + hi1hi1,abchi1,hi1abc 9000: + ,abc,abc 13000: - hi1hi1,abchi1,hi1abc 14000: - ,abc,abc 15000: + xyzxyz,abcxyz,xyzabc 20000: - xyzxyz,abcxyz,xyzabc
Concatenation Operator (||)
Consider the query q264 in Example 8–4 and the data stream S10 in Example 8–5. Stream S10 has schema (c1 integer, c2 char(10)). The query returns the relation in Example 8–6.
Example 8-4 Concatenation Operator (||) Query
<query id="q264"> select c2 || "xyz" from S10 ]]></query>
Example 8-5 Concatenation Operator (||) Stream Input
Timestamp Tuple 1 1,abc 2 2,ab 3 3,abc 4 4,a h 200000000
Example 8-6 Concatenation Operator (||) Relation Output
Timestamp Tuple Kind Tuple 1: + abcxyz 2: + abxyz 3: + abcxyz 4: + axyz
8.3 hextoraw
Syntax
Purpose
hextoraw converts char containing hexadecimal digits in the char character set to a raw value.
See Also:
Examples
Consider the query q6 and the data stream SByt. Stream SByt has schema (c1 integer, c2 char(10)). The query returns the relation.
<query id="q6"><![CDATA[
select * from SByt[range 2]
where
hextoraw(c2) between and hextoraw("5600")
]]></query>
Timestamp Tuple 1000 1,"51c1" 2000 2,"52" 3000 3,"53aa" 4000 4,"5" 5000 ,"55ef" 6000 6, h 8000 h 200000000
Timestamp Tuple Kind Tuple 3000 + 3,"53aa" 5000 - 3,"53aa" 5000 + ,"55ef" 7000 - ,"55ef"
8.4 length
Syntax
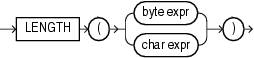
Purpose
The length function returns the length of its char or byte expression as an int. length calculates length using characters as defined by the input character set.
For a char expression, the length includes all trailing blanks. If the expression is null, this function returns null.
Examples
Consider the query chr_len and the data stream S2. Stream S2 has schema (c1 char(10), c2 integer). The query returns the relation.
<query id="chr_len"><![CDATA[ select length(c1) from S2[range 5] ]]></query>
Timestamp Tuple 1000 2000 hi 8000 hi1 9000 15000 xyz h 200000000
Timestamp Tuple Kind Tuple 1000: + 0 2000: + 2 6000: - 0 7000: - 2 8000: + 3 9000: + 0 13000: - 3 14000: - 0 15000: + 3 20000: - 3
8.5 lk
Syntax
Purpose
lk boolean true if char1 matches the regular expression char2, otherwise it returns false.
This function is equivalent to the LIKE condition. For more information, see .
Examples
Consider the query q291 and the data stream SLk1. Stream SLk1 has schema (first1 char(20), last1 char(20)). The query returns the relation.
<query id="q291"><![CDATA[ select * from SLk1 where lk(first1,"^Ste(v|ph)en$") = true ]]></query>
Timestamp Tuple 1 Steven,King 2 Sten,Harley 3 Stephen,Stiles 4 Steven,Markles h 200000000
Timestamp Tuple Kind Tuple 1: + Steven,King 3: + Stephen,Stiles 4: + Steven,Markles
8.6 nvl
Syntax
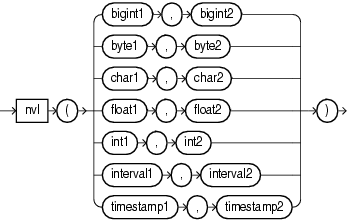
Purpose
nvl lets you replace null (returned as a blank) with a string in the results of a query. If expr1 is null, then NVL returns expr2. If expr1 is not null, then NVL returns expr1.
The arguments expr1 and expr2 can have any data type. If their data types are different, then Oracle Stream Explorer implicitly converts one to the other. If they cannot be converted implicitly, Oracle Stream Explorer returns an error. The implicit conversion is implemented as follows:
If
expr1is character data, then Oracle Stream Explorer convertsexpr2to character data before comparing them and returnsVARCHAR2in the character set ofexpr1.If
expr1is numeric, then Oracle Stream Explorer determines which argument has the highest numeric precedence, implicitly converts the other argument to that data type, and returns that data type.
Examples
Consider the query q281 and the data stream SNVL. Stream SNVL has schema (c1 char(20), c2 integer). The query returns the relation.
<query id="q281"><![CDATA[ select nvl(c1,"abcd") from SNVL ]]></query>
Timestamp Tuple 1 ,1 2 ab,2 3 abc,3 4 ,4 h 200000000
Timestamp Tuple Kind Tuple 1: + abcd 2: + ab 3: + abc 4: + abcd
8.7 prev
Syntax

Purpose
prev returns the value of the stream attribute (function argument identifier2) of the event that occurred previous to the current event and which belongs to the partition to which the current event belongs. It evaluates to NULL if there is no such previous event.
The type of the specified stream element may be any of:
integerbigintfloatdoublebytecharintervaltimestamp.
The return type of this function depends on the type of the specified stream attribute (function argument identifier2).
Where:
identifier1.identifier2:identifier1is the name of a correlation variable used in thePATTERNclause and defined in theDEFINEclause andidentifier2is the name of a stream attribute whose value in the previous event should be returned byprev.const_int: if this argument has a value n, then it specifies the nth previous event in the partition to which the current event belongs. The value of the attribute (specified in argumentidentifier2) in the nth previous event will be returned if such an event exists,NULLotherwise.const_bigint: specifies a time range duration in nanoseconds and should be used if you are interested in previous events that occurred only within a certain range of time before the current event.
If the query uses PARTITION BY with the prev function and input data will include many different partition key values (meaning many partitions), then total memory consumed for storing the previous event(s) per partition could be large. In such cases, consider using the time range duration (the third argument, possibly with a large range value) so that this memory can be reclaimed wherever possible.
Examples
prev(identifier1.identifier2)
Consider query q2 and the data stream S1. Stream S1 has schema (c1 integer). This example defines pattern A as A.c1 = prev(A.c1). In other words, pattern A matches when the value of c1 in the current stream element matches the value of c1 in the stream element immediately before the current stream element. The query returns the stream.
<query id="q2"><![CDATA[ select T.Ac1, T.Cc1 from S1 MATCH_RECOGNIZE ( MEASURES A.c1 as Ac1, C.c1 as Cc1 PATTERN(A B+ C) DEFINE A as A.c1 = prev(A.c1), B as B.c1 = 10, C as C.c1 = 7 ) as T ]]></query>
Timestamp Tuple 1000 35 3000 35 4000 10 5000 7
Timestamp Tuple Kind Tuple 5000: + 35,7
prev(identifier1.identifier2, const_int)
Consider query q35 and the data stream S15. Stream S15 has schema (c1 integer, c2 integer). This example defines pattern A as A.c1 = prev(A.c1,3). In other words, pattern A matches when the value of c1 in the current stream element matches the value of c1 in the third stream element before the current stream element. The query returns the stream.
<query id="q35"><![CDATA[ select T.Ac1 from S15 MATCH_RECOGNIZE ( MEASURES A.c1 as Ac1 PATTERN(A) DEFINE A as (A.c1 = prev(A.c1,3) ) ) as T ]]></query>
Timestamp Tuple 1000 45,20 2000 45,30 3000 45,30 4000 45,30 5000 45,30 6000 45,20 7000 45,20 8000 45,20 9000 43,40 10000 52,10 11000 52,30 12000 43,40 13000 52,50 14000 43,40 15000 43,40
Timestamp Tuple Kind Tuple 4000: + 45 5000: + 45 6000: + 45 7000: + 45 8000: + 45 12000: + 43 13000: + 52 15000: + 43
prev(identifier1.identifier2, const_int, const_bigint)
Consider query q36 and the data stream S15. Stream S15 has schema (c1 integer, c2 integer). This example defines pattern A as A.c1 = prev(A.c1,3,5000000000L). In other words, pattern A matches when:
the value of
c1in the current event equals the value ofc1in the third previous event of the partition to which the current event belongs, andthe difference between the timestamp of the current event and that third previous event is less than or equal to
5000000000Lnanoseconds.
The query returns the output stream. Notice that in the output stream, there is no output at 8000. The following example shows the contents of the partition (partitioned by the value of the c2 attribute) to which the event at 8000 belongs.
Timestamp Tuple 1000 45,20 6000 45,20 7000 45,20 8000 45,20
As the following example shows, even though the value of c1 in the third previous event (the event at 1000) is the same as the value c1 in the current event (the event at 8000), the range condition is not satisfied. This is because the difference in the timestamps of these two events is more than 5000000000 nanoseconds. So it is treated as if there is no previous tuple and prev returns NULL so the condition fails to match.
<query id="q36"><![CDATA[ select T.Ac1 from S15 MATCH_RECOGNIZE ( PARTITION BY c2 MEASURES A.c1 as Ac1 PATTERN(A) DEFINE A as (A.c1 = prev(A.c1,3,5000000000L) ) ) as T ]]></query>
Timestamp Tuple 1000 45,20 2000 45,30 3000 45,30 4000 45,30 5000 45,30 6000 45,20 7000 45,20 8000 45,20 9000 43,40 10000 52,10 11000 52,30 12000 43,40 13000 52,50 14000 43,40 15000 43,40
Timestamp Tuple Kind Tuple 5000: + 45
8.8 rawtohex
Syntax
Purpose
rawtohex converts byte containing a raw value to hexadecimal digits in the CHAR character set.
See Also:
Examples
Consider the query byte_to_hex and the data stream S5. Stream S5 has schema (c1 integer, c2 byte(10)). This query uses the rawtohex function to convert a ten byte raw value to the equivalent ten hexadecimal digits in the character set of your current locale. The query returns the relation.
<query id="byte_to_hex"><![CDATA[ select rawtohex(c2) from S5[range 4] ]]></query>
Timestamp Tuple 1000 1,"51c1" 2000 2,"52" 2500 7,"axc" 3000 3,"53aa" 4000 4,"5" 5000 ,"55ef" 6000 6, h 8000 h 200000000
Timestamp Tuple Kind Tuple 1000: + 51c1 2000: + 52 3000: + 53aa 4000: + 05 5000: - 51c1 5000: + 55ef 6000: - 52 6000: + 7000: - 53aa 8000: - 05 9000: - 55ef 10000: -
8.9 systimestamp
Syntax
Purpose
systimestamp returns the system date, including fractional seconds and time zone, of the system on which the Oracle Stream Explorer server resides. The return type is TIMESTAMP WITH TIME ZONE.
Examples
Consider the query q106 and the data stream S0. Stream S0 has schema (c1 float, c2 integer). The query returns the relation.
<query id="q106"><![CDATA[ select * from S0 where case c2 when 10 then null when 20 then null else systimestamp() end > "07/06/2007 14:13:33" ]]></query>
Timestamp Tuple 1000 0.1 ,10 1002 0.14,15 200000 0.2 ,20 400000 0.3 ,30 500000 0.3 ,35 600000 ,35 h 800000 100000000 4.04,40 h 200000000
Timestamp Tuple Kind Tuple 1002: + 0.14,15 400000: + 0.3 ,30 500000: + 0.3 ,35 600000: + ,35 100000000: + 4.04,40
8.10 to_bigint
Syntax
Purpose
Input/Output Types
The input/output types for this function are as follows:
| Input Type | Output Type |
|---|---|
INTEGER |
BIGINT |
TIMESTAMP |
BIGINT |
CHAR |
BIGINT |
Examples
Consider the query q282 and the data stream S11. Stream S11 has schema (c1 integer, name char(10)). The query returns the relation.
<query id="q282"><![CDATA[ select nvl(to_bigint(c1), 5.2) from S11 ]]></query>
Timestamp Tuple 10 1,abc 2000 ,ab 3400 3,abc 4700 ,a h 8000 h 200000000
Timestamp Tuple Kind Tuple 10: + 1 2000: + 5.2 3400: + 3 4700: + 5.2
8.11 to_boolean
Syntax
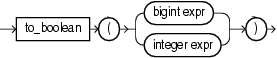
Purpose
to_boolean returns a value of true or false for its bigint or integer expression argument.
Examples
Consider the query q282 and the data stream S11. Stream S11 has schema (c1 integer, name char(10)). The query returns the relation.
<view id="v2" schema="c1 c2" ><![CDATA[ select to_boolean(c1), c1 from tkboolean_S3 [now] where c2 = 0.1 ]]></view><query id="q1"><![CDATA[ select * from v2 ]]></query>
Timestamp Tuple 1000 -2147483648, 0.1 2000 2147483647, 0.2 3000 12345678901, 0.3 4000 -12345678901, 0.1 5000 9223372036854775799, 0.2 6000 -9223372036854775799, 0.3 7000 , 0.1 8000 10000000000, 0.2 9000 60000000000, 0.3 h 200000000
Timestamp Tuple Kind Tuple 1000 + true,-2147483648 1000 - true,-2147483648 4000 + true,-12345678901 4000 - true,-12345678901 7000 + , 7000 - ,
8.12 to_char
Syntax
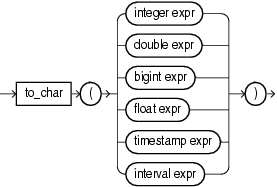
Purpose
to_char returns a char value for its integer, double, bigint, float, timestamp, or interval expression argument. If the bigint argument exceeds the char precision, Oracle Stream Explorer returns an error.
Examples
Consider the query q282 and the data stream S11. Stream S11 has schema (c1 integer, name char(10)). The query returns the relation.
<query id="q1"><![CDATA[ select to_char(c1), to_char(c2), to_char(c3), to_char(c4), to_char(c5), to_char(c6) from S1 ]]></query>
Timestamp Tuple 1000 99,99999, 99.9, 99.9999, "4 1:13:48.10", "08/07/2004 11:13:48", cep
Timestamp Tuple Kind Tuple 1000: + 99,99999,99.9,99.9999,4 1:13:48.10,08/07/2004 11:13:48
8.13 to_double
Syntax
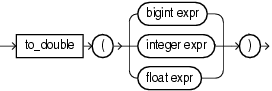
Purpose
to_double returns a double value for its bigint, integer, or float expression argument. If the bigint argument exceeds the double precision, Oracle Stream Explorer returns an error.
Examples
Consider the query q282 and the data stream S11. Stream S11 has schema (c1 integer, name char(10)). The query returns the relation.
<query id="q282"><![CDATA[ select nvl(to_double(c1), 5.2) from S11 ]]></query>
Timestamp Tuple 10 1,abc 2000 ,ab 3400 3,abc 4700 ,a h 8000 h 200000000
Timestamp Tuple Kind Tuple 10: + 1 2000: + 5.2 3400: + 3 4700: + 5.2
8.14 to_float
Syntax
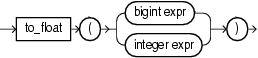
Purpose
to_float returns a float number equivalent of its bigint or integer argument. If the bigint argument exceeds the float precision, Oracle Stream Explorer returns an error.
Examples
Consider the query q1 and the data stream S11. Stream S1 has schema (c1 integer, name char(10)). The query returns the relation.
<query id="q1"><![CDATA[ select nvl(to_float(c1), 5.2) from S11 ]]></query>
Timestamp Tuple 10 1, abc 2000 , ab 3400 3, abc 4700 , a h 8000 h 200000000
Timestamp Tuple Kind Tuple 10:+ 1.02000:+ 5.23400:+ 3.04700:+ 5.2
8.15 to_timestamp
Syntax
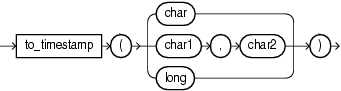
Purpose
to_timestamp converts char literals that conform to java.text.SimpleDateFormat format models to timestamp data types. There are two forms of the to_timestamp function distinguished by the number of arguments:
char: this form of theto_timestampfunction converts a singlecharargument that contains acharliteral that conforms to the defaultjava.text.SimpleDateFormatformat model (MM/dd/yyyy HH:mm:ss) into the correspondingtimestampdata type.char1, char2: this form of theto_timestampfunction converts thechar1argument that contains acharliteral that conforms to thejava.text.SimpleDateFormatformat model specified in the secondchar2argument into the correspondingtimestampdata type.long: this form of theto_timestampfunction converts a singlelongargument that represents the number of nanoseconds since the standard base time known as "the epoch", namely January 1, 1970, 00:00:00 GMT, into the correspondingtimestampdata type represented as a number in milliseconds since "the epoch" with a date format that conforms to the defaultjava.text.SimpleDateFormatformat model (MM/dd/yyyy HH:mm:ss).
Examples
Consider the query q277 and the data stream STs2. Stream STs2 has schema (c1 integer, c2 char(20)). The query returns the relation.
<query id="q277"><![CDATA[
select * from STs2
where
to_timestamp(c2,"yyMMddHHmmss") = to_timestamp("09/07/2005 10:13:48")
]]></query>
Timestamp Tuple 1 1,"040807111348" 2 2,"050907101348" 3 3,"041007111348" 4 4,"060806111248" h 200000000
Timestamp Tuple Kind Tuple 2: + 2,050907101348
8.16 xmlcomment
Syntax
Purpose
xmlcomment returns its double-quote delimited constant String argument as an xmltype.
Using xmlcomment, you can add a well-formed XML comment to your query results.
This function takes the following arguments:
quoted_string_double_quotes: a double-quote delimitedStringconstant.
The return type of this function is xmltype. The exact schema depends on that of the input stream of XML data.
Examples
Consider the query tkdata64_q1 and data stream tkdata64_S. Stream tkdata64_S has schema (c1 char(30)). The query returns the relation.
<query id="tkdata64_q1"><![CDATA[
select xmlconcat(xmlelement("parent", c1), xmlcomment("this is a comment"))
from tkdata64_S
]]></query>
Timestamp Tuple c 30 1000 "san jose" 1000 "mountain view" 1000 1000 "sunnyvale" 1003 1004 "belmont"
Timestamp Tuple Kind Tuple 1000: + <parent>san jose</parent> <!--this is a comment--> 1000: + <parent>mountain view</parent> <!--this is a comment--> 1000: + <parent/> <!--this is a comment--> 1000: + <parent>sunnyvale</parent> <!--this is a comment--> 1003: + <parent/> <!--this is a comment--> 1004: + <parent>belmont</parent> <!--this is a comment-->
8.17 xmlconcat
Syntax
Purpose
xmlconcat returns the concatenation of its comma-delimited xmltype arguments as an xmltype.
Using xmlconcat, you can concatenate any combination of xmltype arguments.
This function takes the following arguments:
non_mt_arg_list: a comma-delimited list ofxmltypearguments. For more information, see .
The return type of this function is xmltype. The exact schema depends on that of the input stream of XML data.
This function is especially useful when processing SQLX streams. For more information, see .
To concatenate data types other than xmltype, use CONCAT. For more information, see concat.
Examples
Consider the query tkdata64_q1 and the data stream tkdata64_S. Stream tkdata64_S has schema (c1 char(30)). The query returns the relation.
<query id="tkdata64_q1"><![CDATA[
select
xmlconcat(xmlelement("parent", c1), xmlcomment("this is a comment"))
from tkdata64_S
]]></query>
Timestamp Tuple c 30 1000 "san jose" 1000 "mountain view" 1000 1000 "sunnyvale" 1003 1004 "belmont"
Timestamp Tuple Kind Tuple 1000: + <parent>san jose</parent> <!--this is a comment--> 1000: + <parent>mountain view</parent> <!--this is a comment--> 1000: + <parent/> <!--this is a comment--> 1000: + <parent>sunnyvale</parent> <!--this is a comment--> 1003: + <parent/> <!--this is a comment--> 1004: + <parent>belmont</parent> <!--this is a comment-->
8.18 xmlexists
Syntax
Purpose
xmlexists creates a continuous query against a stream of XML data to return a boolean that indicates whether or not the XML data satisfies the XQuery you specify.
This function takes the following arguments:
const_string: An XQuery that Oracle Stream Explorer applies to the XML stream element data that you bind inxqryargs_list. For more information, see .xqryargs_list: A list of one or more bindings between stream elements and XQuery variables or XPath operators. For more information, see .
The return type of this function is boolean: true if the XQuery is satisfied; false otherwise.
This function is especially useful when processing SQLX streams. For more information, see .
See Also:
Examples
Consider the query q1 and the XML data stream S. Stream S has schema (c1 integer, c2 xmltype). In this example, the value of stream element c2 is bound to the current node (".") and the value of stream element c1 + 1 is bound to XQuery variable x. The query returns the relation.
<query id="q1"><![CDATA[ SELECT xmlexists( "for $i in /PDRecord where $i/PDId <= $x return $i/PDName" PASSING BY VALUE c2 as ".", (c1+1) AS "x" RETURNING CONTENT ) XMLData FROM S ]]></query>
Timestamp Tuple 3 1, "<PDRecord><PDName>hello</PDName></PDRecord>" 4 2, "<PDRecord><PDName>hello</PDName><PDName>hello1</PDName></PDRecord>" 5 3, "<PDRecord><PDId>4</PDId><PDName>hello1</PDName></PDRecord>" 6 4, "<PDRecord><PDId>46</PDId><PDName>hello2</PDName></PDRecord>"
Timestamp Tuple Kind Tuple 3: + false 4: + false 5: + true 6: + false
8.19 xmlquery
Syntax
Purpose
xmlquery creates a continuous query against a stream of XML data to return the XML data that satisfies the XQuery you specify.
This function takes the following arguments:
const_string: An XQuery that Oracle Stream Explorer applies to the XML stream element data that you bind inxqryargs_list. For more information, see .xqryargs_list: A list of one or more bindings between stream elements and XQuery variables or XPath operators. For more information, see .
The return type of this function is xmltype. The exact schema depends on that of the input stream of XML data.
This function is especially useful when processing SQLX streams. For more information, see .
See Also:
Examples
Consider the query and the XML data stream S. Stream S has schema (c1 integer, c2 xmltype). In this example, the value of stream element c2 is bound to the current node (".") and the value of stream element c1 + 1 is bound to XQuery variable x. The query returns the relation.
<query id="q1"><![CDATA[ SELECT xmlquery( "for $i in /PDRecord where $i/PDId <= $x return $i/PDName" PASSING BY VALUE c2 as ".", (c1+1) AS "x" RETURNING CONTENT ) XMLData FROM S ]]></query>
Timestamp Tuple 3 1, "<PDRecord><PDName>hello</PDName></PDRecord>" 4 2, "<PDRecord><PDName>hello</PDName><PDName>hello1</PDName></PDRecord>" 5 3, "<PDRecord><PDId>4</PDId><PDName>hello1</PDName></PDRecord>" 6 4, "<PDRecord><PDId>46</PDId><PDName>hello0</PDName></PDRecord>" 7 5, "<PDRecord><PDId>5</PDId><PDName>hello2</PDName></PDRecord>"
Timestamp Tuple Kind Tuple 3: + 4: + 5: + "<PDName>hello1</PDName>" 6: + 7: + "<PDName>hello2</PDName>"