Tuning Cluster Parameters
To tune cluster parameters, use the Cluster Tuning (MCF_SYSTEM_NV_CMP) component.
This section discusses how to tune cluster parameters.
Access the Cluster Tuning page using the following navigation path:
Image: Cluster Tuning page
This example illustrates the tuning parameters on the Cluster Tuning page.
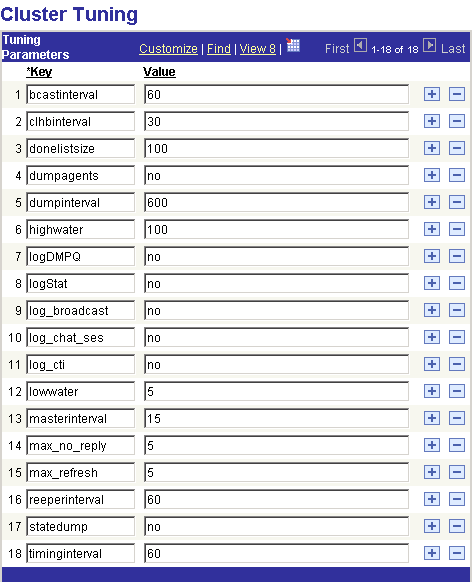
Use the Cluster Tuning page to set MCF cluster parameters to optimize performance or enable logging.
If you make changes to a cluster parameter, you must use the Notify Cluster page to propagate the changes.
See Notifying Clusters of Changed Parameters.
The following table lists the cluster tuning parameters you can modify and describes the default values and usage of each.
|
Key |
Default value |
Usage |
|---|---|---|
|
bcastinterval |
60 |
The interval, in seconds, after which the number of unassigned tasks per physical queue and the number of agents that are logged into each physical queue are broadcast to the MultiChannel Consoles for display next to the queue names. A smaller value provides more accurate queue statistics, but increases the load on the queue server and REN server. A larger value decreases queue server and REN server load, but also decreases statistical accuracy. The bcastinterval value also determines how frequently onStat2 event statistics are calculated. A smaller value provides updated statistics more frequently. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Using the Monitor Queues Page and Sample Monitor - Queue Statistics Page, Using the Monitor Agents Page and Sample Monitor - Agent States Page. |
|
clhbinterval |
30 |
The interval, in seconds, in which the queue server expects to receive a heartbeat from a connected JSMCAPI client. If the queue server receives no heartbeat during this interval, the queue server stops the client session. For a queue server, to avoid a session time-out for the client when CPU usage of the machine on which the client is running is high, increase the heartbeat interval of the client. Note: For third-party server, increase the heartbeat interval on the third-party server side to avoid a session time-out. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Using and Demonstrating JSMCAPI. |
|
donelistsize |
100 |
The number of completed tasks that are stored in the list that is used to calculate average task duration. Configure the donelistsize value depending on the task volume that is encountered and the interval over which you want to monitor tasks. This is a timing parameter. If you change the value of this parameter you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Using and Demonstrating JSMCAPI. |
|
dumpagents |
No |
Enter Yes if the status of agent activity should be written to the database during the periodic state dumps. Logging agent status increases queue server load, but provides information about agent performance. This is a task parameter. If you change the value of this parameter, you must use the Refresh Task Properties button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Viewing the Agent State Summary. |
|
dumpinterval |
600 |
The interval, in seconds, after which the queue state is written to the database. A smaller value increases load on the queue server, but provides more frequent statistics. A larger value decreases load on the queue server, but provides less frequent statistics. A value of less than one minute will significantly reduce queue server performance. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Viewing the Queue Server State, Viewing the Queue State Summary. |
|
highwater |
100 |
The maximum number of persistent tasks that are retrieved from the database and cached in memory in the queue server. The highwater and lowwater mark values determine how often, and how many, persistent tasks should be read into memory. A higher value causes the queue server to retrieve more persistent tasks at one time, which results in less frequent access to the database, but also more tasks for the queue server to manage, slowing performance. A lower value speeds performance, but requires more frequent access to the database. If a large number of enqueued tasks cannot be routed by the queue server (for example, a call center handling a specific physical queue is offline), increase the highwater mark so that tasks that can be routed can fit into memory cache. This is a threshold parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. |
|
logDMPQ |
No |
Enter Yes if you want PSMCFLOG to log REN server event notifications resulting from bcastinterval broadcasts. Only the event is logged, not its contents. This is a logging parameter. If you change the value of this parameter, you must use the Refresh Logging Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Viewing Event Logs. |
|
logStat |
No |
Enter Yes to log the statistics that are returned by the queue server for the onStat1 user and group events to the database. This is a logging parameter. If you change the value of this parameter, you must use the Refresh Logging Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Using and Demonstrating JSMCAPI. |
|
log_broadcast |
No |
Enter Yes to activate logging of the broadcast messages that are sent. This is a logging parameter. If you change the value of this parameter, you must use the Refresh Logging Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Viewing Broadcast Logs. |
|
log_chat_ses |
No |
Enter Yes to activate logging of the contents of chat sessions. This is a logging parameter. If you change the value of this parameter, you must use the Refresh Logging Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Viewing Chat Logs. |
|
log_cti |
No |
Select Yes to activate logging of CTI events. This is a logging parameter. If you change the value of this parameter, you must use the Refresh Logging Parameters button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Logging CTI Events. |
|
lowwater |
5 |
The minimum number of persistent tasks that are cached in memory in the queue server. When the lowwater value is reached, the queue server retrieves another batch of persistent tasks, up to the highwater value. The highwater and lowwater mark values determine when, and how many, persistent tasks should be read into memory. A higher value requires the queue server to access the database more frequently. A lower value can cause the queue server to run out of persistent tasks before refreshing its queue. The lowwater value should be greater than or equal to the maximum number of agents that are logged onto any physical queue at one time. This is a threshold parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. |
|
masterinterval |
15 |
The interval, in seconds, after which a cluster master updates its timestamp in its cluster tables. Slave clusters check the timestamp to determine whether the master cluster is still running. A lower value enables rapid discovery of a failed master server, but increases queue server overhead. A higher value reduces queue server overhead, but delays discovery of a failed master server. If only one queue server is configured for an MCF cluster, this value can be large. The masterinterval value also acts as a heartbeat interval for the master queue server connection to user consoles. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. |
|
max_no_reply |
5 |
Sets the maximum number of consecutive agent timeouts before the queue server automatically signs out the agent and sets the agent’s console status as Assumed Unavailable. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. |
|
max_refresh |
5 |
Sets the maximum number of consecutive times that results are discarded when task queue is refreshed from the database if an intervening notification of new persistent tasks exists. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. |
|
reeperinterval |
60 |
The interval, in seconds, after which deleted tasks are cleared from memory in the queue server. A lower value increases queue server load but clears memory more frequently. A higher value decreases queue server load but clears memory less frequently. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. |
|
statdump |
No |
Specify Yes to write queue server state to the database during the periodic state dumps. The state dump interval is set by the dumpinterval parameter. This is a task parameter. If you change the value of this parameter, you must use the Refresh Task Properties button on the Cluster Notify page to notify clusters of the changed parameter. See Notifying Clusters of Changed Parameters, Using and Demonstrating JSMCAPI. |
|
timinginterval |
60 |
The interval, in seconds, after which the database is checked for expired or overflowed persistent tasks. This parameter does not affect real-time tasks. A lower value increases queue server load but detects timed-out tasks more quickly. A higher value decreases queue server load but detects timed-out tasks less frequently. This is a timing parameter. If you change the value of this parameter, you must use the Refresh Threshold/Timing Parameters button on the Cluster Notify page to notify clusters of the changed parameter. |