| Oracle® TimesTen In-Memory Database Scaleoutユーザーズ・ガイド リリース18.1 E98636-05 |
|


 前 |
 次 |
エラー条件や障害状況が発生した場合、可用性に影響することがあります。エラー条件から自動的にリカバリできる場合は、通常の操作が再開されます。ただし、障害からリカバリするためにユーザーによる介入が必要になる場合があります。
TimesTen Scaleoutには、TimesTen Scaleoutを使用するすべてのアプリケーションの継続的操作を維持するために、多数のエラーおよび障害状況に対する自動リカバリ付きのエラーおよび障害検出機能が備わっています。エラーおよび障害状況には、次のものがあります。
ソフトウェア・エラー。
ネットワークの停止またはその他の通信チャネルの障害。通信チャネルは、TCP接続です。
データ・インスタンスをホストしている1つ以上のマシンの、予期しない再起動またはクラッシュ。
インスタンスのTimesTenメイン・デーモンまたはそのいずれかのサブデーモンの障害。
ハング状態からまたは高負荷の結果として、要素の応答が遅くなったか、応答しなくなった場合。
データ・インスタンスをホストするマシンまたはマシンのラックが、不明な理由で予期せず停止した場合。
エラー条件および障害状況に対して必要な対応は、次のとおりです。
一時エラー: 一時エラーは、通常はTimesTen Scaleoutが迅速に解決できる一時的な状況が原因で発生します。失敗したトランザクションをすぐに再試行でき、再試行は通常成功します。
要素の障害: 要素に障害が発生した場合、TimesTen Scaleoutでは、ほとんどの場合、その要素を自動的にリカバリできます。ただし、要素の障害の状況によっては、ユーザーが問題を解決する必要がある場合があります。要素の障害に対するアプリケーションの対応は、グリッドおよびデータベースの構成によって異なる場合があります。問題の修正後、TimesTen Scaleoutによって要素がリカバリされ、操作が継続されるか、障害が発生した要素のかわりとなる新規要素をユーザーが提供します。
レプリカ・セットの障害: レプリカ・セット内のすべての要素に障害が発生した場合、(元となる障害の問題が解決された後で) TimesTen Scaleoutにより自動的に要素をリカバリする方法が用意されています。シード要素と呼ばれる、最新の変更を持つ要素が最初にリカバリされます。その後、後続のすべての要素がシード要素からリカバリされます。
データベースの障害: すべてのレプリカ・セットに障害が発生した場合、データベースに障害が発生したとみなされます。リカバリするには、データベースを再ロードする必要があります。再ロードされたときにデータベースがどのようにリカバリされるかは、Durability属性の値によって決まります。
データ分散の失敗: データ分散プロセスが中断されたか完了に失敗した場合は、データの再同期を試行できます。再同期には、ttGridAdmin dbDistribute -resync操作の実行が含まれます。
次の各項では、エラーまたは障害状況およびリカバリについて説明しています。
要素ステータスは、次のことを示します。
要素がロードされている(opened)。
要素が変更中である。たとえば、オープン中(opening)、ロード中(creating、loading)、アンロード中(unloading)、破棄中(destroying)またはクローズ中(closing)です。
要素またはそのデータ・インスタンスで障害が発生し、シード要素のリカバリを待機している。この場合、表示されるステータスはwaiting for seedです。障害が発生した要素の中で最新の変更を持つもの(シード要素と呼ばれます)が最初に、チェックポイントおよびトランザクション・ログ・ファイル内の最新のトランザクションにリカバリされます。レプリカ・セット内の他の要素は、レプリカ・セットのシード要素からコピーされます。
要素が稼働していない(evictedまたはdown)。
次の例では、データベース、データ領域グループ、レプリカ・セットおよび要素のステータスを表示する方法を示しています。各ステータスへの対応方法の詳細は、要素ステータスに基づくトラブルシューティングを参照してください。
例11-1 データベースおよびすべての要素のステータスの表示
ttGridAdmin dbStatus -allコマンドを使用して、データベース、データベース内のすべての要素、レプリカ・セットおよびデータ領域グループの現在のステータスをリストできます。
最初のセクションは、データベース全体のステータスを示しています。この例では、データベースは作成、ロードされて、オープンしています。また、このステータスは、作成済、ロード済およびオープンしている要素の合計数も示します。
データベースのステータスは、データベースが最初に作成され、次にロードされて、最後にオープンされる、一連の進行状況を示します。データベースを停止する場合は、逆の順序となり、データベースは最初にクローズされ、次にアンロードされて、最後に破棄されます。
% ttGridAdmin dbStatus database1 -all Database database1 summary status as of Thu Feb 22 07:37:28 PST 2018 created,loaded-complete,open Completely created elements: 6 (of 6) Completely loaded elements: 6 (of 6) Completely created replica sets: 3 (of 3) Completely loaded replica sets: 3 (of 3) Open elements: 6 (of 6)
ただし、データベースのステータスに、データベースが作成、ロードされ、クローズしていることが示されている場合、データベースはまだオープンされていません。次の例では、データベースはまだオープンしていませんが、分散マップが更新されて、作成済およびロード済のレプリカ・セットが示されています。データベースがオープンされるまでは、いずれの要素もオープンされないことに注意してください。
% ttGridAdmin dbStatus database1 -all Database database1 summary status as of Thu Feb 22 07:37:01 PST 2018 created,loaded-complete,closed Completely created elements: 6 (of 6) Completely loaded elements: 6 (of 6) Completely created replica sets: 3 (of 3) Completely loaded replica sets: 3 (of 3) Open elements: 0 (of 6)
2番目のセクションには、要素に関する情報が示されます。これは、各要素が存在するホストおよびインスタンス名、その要素に割り当てられた番号および要素のステータスです。
Database database1 element level status as of Thu Feb 22 07:37:28 PST 2018 Host Instance Elem Status Date/Time of Event Message ----- --------- ---- ------ ------------------- ------- host3 instance1 1 opened 2018-02-22 07:37:25 host4 instance1 2 opened 2018-02-22 07:37:25 host5 instance1 3 opened 2018-02-22 07:37:25 host6 instance1 4 opened 2018-02-22 07:37:25 host7 instance1 5 opened 2018-02-22 07:37:25 host8 instance1 6 opened 2018-02-22 07:37:25
3番目のセクションには、レプリカ・セットに関する情報が示されます。この例では、3つのレプリカ・セットがあります。要素に関する情報に加えて、各要素が存在するレプリカ・セットの番号もRS列に示されます。(ホスト内のデータ・インスタンス内で)各要素が存在するデータ領域グループは、DS列に示されます。各レプリカ・セットには、データ領域グループごとに1つの要素があることに注意してください。
Database database1 Replica Set status as of Thu Feb 22 07:37:28 PST 2018
RS DS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host3 instance1 opened 2018-02-22 07:37:25
2 2 host4 instance1 opened 2018-02-22 07:37:25
2 1 3 host5 instance1 opened 2018-02-22 07:37:25
2 4 host6 instance1 opened 2018-02-22 07:37:25
3 1 5 host7 instance1 opened 2018-02-22 07:37:25
2 6 host8 instance1 opened 2018-02-22 07:37:25
最後のセクションでは要素に関する情報が整理され、各データ領域グループにどの要素が存在するかが、DS列の下に表示されます。この例では、データ領域グループは2つあります。要素は、データ領域グループ1または2の下に配置されています。
Database database1 Data Space Group status as of Thu Feb 22 07:37:28 PST 2018
DS RS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host3 instance1 opened 2018-02-22 07:37:25
2 3 host5 instance1 opened 2018-02-22 07:37:25
3 5 host7 instance1 opened 2018-02-22 07:37:25
2 1 2 host4 instance1 opened 2018-02-22 07:37:25
2 4 host6 instance1 opened 2018-02-22 07:37:25
3 6 host8 instance1 opened 2018-02-22 07:37:25
いずれかのレプリカ・セットを置換せずに除去した場合のステータスを次に示します。データベースがロードされ、オープンされたときに、6個の要素が作成されたが、そのうちロードされているのは4つのみであることが示されています。表示されているすべてのセクションでレプリカ・セットが1つ少なく、除去された要素はステータスにevictedと示されています。
% ttGridAdmin dbStatus database1 -all
Database database1 summary status as of Thu Feb 22 07:52:08 PST 2018
created,loaded-complete,open
Completely created elements: 6 (of 6)
Completely loaded elements: 4 (of 6)
Completely created replica sets: 2 (of 2)
Completely loaded replica sets: 2 (of 2)
Open elements: 4 (of 6)
Database database1 element level status as of Thu Feb 22 07:52:08 PST 2018
Host Instance Elem Status Date/Time of Event Message
----- --------- ---- ------- ------------------- -------
host3 instance1 1 evicted 2018-02-22 07:52:06
host4 instance1 2 evicted 2018-02-22 07:52:06
host5 instance1 3 opened 2018-02-22 07:37:25
host6 instance1 4 opened 2018-02-22 07:37:25
host7 instance1 5 opened 2018-02-22 07:37:25
host8 instance1 6 opened 2018-02-22 07:37:25
Database database1 Replica Set status as of Thu Feb 22 07:52:08 PST 2018
RS DS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 3 host5 instance1 opened 2018-02-22 07:37:25
2 4 host6 instance1 opened 2018-02-22 07:37:25
2 1 5 host7 instance1 opened 2018-02-22 07:37:25
2 6 host8 instance1 opened 2018-02-22 07:37:25
Database database1 Data Space Group status as of Thu Feb 22 07:52:08 PST 2018
DS RS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 3 host5 instance1 opened 2018-02-22 07:37:25
2 5 host7 instance1 opened 2018-02-22 07:37:25
2 1 4 host6 instance1 opened 2018-02-22 07:37:25
2 6 host8 instance1 opened 2018-02-22 07:37:25
様々なステータス・オプションの詳細は、このガイドの要素ステータスに基づくトラブルシューティング、およびOracle TimesTen In-Memory Databaseリファレンスのデータベース管理操作およびデータベースのステータスのモニター(dbStatus)を参照してください。
グリッドは複数のホストにまたがるため、複数のタイプの障害が発生する可能性があり、その多くは一時エラーである可能性があります。ほとんどの場合、TimesTen Scaleoutによって一時エラーを検出し、迅速に対応できます。グリッドのエラーのほとんどは、エラー・コードにTransientと示される一時エラーで、これは特定のAPI、SQL文またはトランザクションの失敗の原因となる可能性があります。ほとんどの場合、アプリケーションはまったく同じ操作を正常に再試行できます。
特定の文の実行が失敗します。アプリケーションが文を再実行する必要があります。
特定のトランザクションの実行に失敗します。アプリケーションがトランザクションをロールバックし、トランザクションの操作を再度実行する必要があります。
データ・インスタンスへの接続に失敗します。クライアント/サーバー接続を使用している場合は、TimesTen Scaleoutによって、別のアクティブ・データ・インスタンスに接続が転送されます。詳細は、クライアント接続のフェイルオーバーを参照してください。
次の各項では、TimesTen Scaleoutによる、より一般的な一時エラーからの要素のリカバリ方法について説明しています。
TimesTen Scaleoutでは、ほとんどの一時エラーの原因に自動的に対処しますが、表11-1に示されているエラーを受け取ったときに、アプリケーションがトランザクション全体を再試行する場合があります。
表11-1 一時エラーの後に再試行するSQLSTATEおよびORAエラー
| SQLSTATE |
ORAエラー |
PL/SQLの例外 | エラー・メッセージ |
|---|---|---|---|
|
|
|
例外 |
Transient transaction failure due to unavailability of a grid resource.Roll back the transaction and then retry the transaction. |
アプリケーションでは、次のように一時エラーをチェックできます。
ODBCまたはJDBCアプリケーションでは、SQLSTATE TT005エラーがないかを確認して、アプリケーションがトランザクションを再試行する必要があるかどうかを決定します。詳細は、Oracle TimesTen In-Memory Database C開発者ガイドの一時エラー後の再試行(ODBC)およびOracle TimesTen In-Memory Database Java開発者ガイドの一時エラー後の再試行(JDBC)を参照してください。
OCIおよびPro*Cアプリケーションでは、ORA-57005エラーがないかを確認して、アプリケーションがSQL文またはトランザクションを再試行する必要があるかどうかを決定します。詳細は、Oracle TimesTen In-Memory Database C開発者ガイドの一時エラー(OCI)を参照してください。
PL/SQLアプリケーションでは、-57005 PL/SQL例外がないかを確認して、アプリケーションがトランザクションを再試行する必要があるかどうかを決定します。詳細は、Oracle TimesTen In-Memory Database PL/SQL開発者ガイドの一時エラー後の再試行(PL/SQL)を参照してください。
次に、障害が発生する可能性のある通信のタイプについて説明します。
要素間の通信: 必要に応じて、要素間のトランザクションおよびストリーム・データ内でSQL文を実行するために使用されます。アプリケーションがトランザクションを実行中に通信エラーが発生した場合は、トランザクションをロールバックする必要があります。トランザクションを再試行すると、通信が再作成され、作業が続行されます。
データ・インスタンスの間の通信: 通信の作成およびリカバリ・メッセージの送受信のために、データ・インスタンスは相互に通信します。データ・インスタンス間の通信が遮断された場合、操作を再試行すると、通信が自動的にリカバリされます。
データ・インスタンスおよびZooKeeperメンバーシップ・サーバー間の通信: 各データ・インスタンスが、定義されたZooKeeperサーバーのいずれかを使用して、ZooKeeperメンバーシップ・サービスと通信します。データ・インスタンスと通信相手のZooKeeperサーバーとの間の通信に障害が発生した場合、データ・インスタンスは別のZooKeeperサーバーとの接続を試みます。データ・インスタンスがどのZooKeeperサーバーにも接続できない場合、データ・インスタンスはそれ自体を停止しているとみなします。
データ・インスタンスが停止している場合の対処方法の詳細は、データ・インスタンスが停止している場合のリカバリを参照してください。
ソフトウェア・エラーが原因で要素がアンロードされた場合、アクティブなアプリケーションに対してエラーが返されます。トランザクションのロールバック後、各レプリカ・セットで要素が1つオープンしているかぎり、アプリケーションはトランザクションの実行を継続できます。
TimesTen Scaleoutは、要素の再ロードを試行します。オープンした要素は、再度トランザクションを受け入れられるようになります。
|
ノート: ttGridAdmin dbloadコマンドを使用してデータベースを再ロードすることで、要素の再ロードを手動で開始できます。要素ステータスがload failedの場合は、要素のロードが失敗した原因を修正してから、ttGridAdmin dbloadコマンドを使用して要素を再ロードしてください。詳細は、Oracle TimesTen In-Memory Databaseリファレンスのメモリーへのデータベースのロード(dbLoad)を参照してください。 |
データ・インスタンスを含むホストがクラッシュした場合またはデータ・インスタンスがクラッシュした場合は、アクティブなアプリケーションに対してエラーが返されます。データ・インスタンスが停止しているため、要素ステータスにはdownと表示されます。データ・インスタンスが再起動すると(自動リカバリまたは手動操作のいずれの場合も)、データ・インスタンス内の要素はほとんどの場合、リカバリされます。ttGridAdmin dbStatusコマンドを使用して要素のステータスをモニターし、要素がリカバリされたかどうかを確認します。
|
ノート: 要素ステータスへの対応方法の詳細は、要素ステータスに基づくトラブルシューティングを参照してください。データ・インスタンスを手動でリカバリする方法は、データ・インスタンスが停止している場合のリカバリを参照してください。 |
ttGridAdmin dbDistribute -applyコマンドを使用して分散マップに変更を適用すると、既存のデータが再分散されます。(詳細は、データベース内のデータの再分散を参照)。データ分散の進行中にデータ分散またはリセットをリクエストすると、エラーが発生します。
TimesTenでは、データ分散を実行するために複数のプロセスが生成されます。また、アクティブ管理インスタンスは、データ分散を促進するためにデータ・インスタンスと通信します。アクティブ管理インスタンスは、各データ分散の進行状況を追跡するためにメタデータを格納します。そのため、クリティカル・プロセスが失敗した場合や、インスタンスが失敗した場合や、アクティブ管理インスタンスとデータ・インスタンスとの通信が失敗した場合は、データ分散が失敗する可能性があります。
データ分散中にdbDistribute -applyコマンドが失敗した場合は、次のエラー・メッセージが表示されます。
% ttGridAdmin dbDistribute database1 -apply Error : Distribution failed, error message lost due to process failure
アクティブ管理インスタンスでデータ分散操作の成功や失敗を認識できない場合や、メタデータが中間状態のままになっている場合は、いくつかの障害が発生する可能性があります。これは、dbDistribute -applyが実行されたプロセスが異常終了したか強制終了された場合に発生します。
データ分散が失敗したか完了しない場合は、別のdbDistribute -applyコマンドを再度開始しないでください。かわりに、dbDistribute -resyncコマンドを実行します。dbDistribute -resyncコマンドは、アクティブ管理インスタンス内のメタデータを調べて、dbDistribute -apply操作が進行中であったが完了しなかった(変更のコミットもロールバックも行われていない)かどうかを判断します。そのような場合、dbDistribute -resyncコマンドは、データベース内のメタデータをアクティブ管理インスタンス内のメタデータと再同期します(一致する状態がない場合)。
dbDistribute -resyncコマンドが成功した場合は、再同期により、前のdbDistribute -apply操作のメタデータ変更がコミットまたはロールバックされる可能性があります。
dbDistribute -resyncコマンドが失敗した場合は、次のいずれかを実行できます。
dbDistribute -applyコマンドを実行して同じ分散を試行します。
dbDistribute -resetコマンドを実行して、まだ適用されていないすべての分散設定を破棄し、dbDistribute -applyコマンドを使用して新しいデータ分散を試行します。
次の例は、dbDistribute -resyncコマンドでデータ分散操作が正常に完了した場合の出力を示しています。
% ttGridAdmin dbDistribute -resync Distribution map updated
次の例は、dbDistribute -resyncコマンドでデータ分散操作をロールバックした場合の出力を示しています。
% ttGridAdmin dbDistribute database1 -resync Distribution map Rolled Back
次の例は、dbDistribute -resyncコマンドで進行中のデータ分散がないことが検出された場合の出力を示しています。
% ttGridAdmin dbDistribute database1 -resync No DbDistribute is currently in progress
次の例は、dbDistribute -resyncコマンドでデータ分散がまだ進行中であることが検出された場合の出力を示しています。
% ttGridAdmin dbDistribute database1 -resync Distribute is still in progress. Wait for dbDistribute to complete, then call resync
再同期に失敗した場合は、エラーが表示されます。たとえば、アクティブなデータ・インスタンスがないときにデータ分散を再同期しようとしたとします。このような場合は、次のエラーが表示されます。
% ttGridAdmin dbDistribute database1 -resync Error : Could not connect to data instance to retrieve partition table version
詳細は、Oracle TimesTen In-Memory Databaseリファレンスのデータベースの分散スキームの設定または変更(dbDistribute)を参照してください。
要素がアンロードされ、データベースがロードされている必要がある場合、TimesTen Scaleoutは要素の再ロードを試みます。このとき、要素はTimesTen Scaleoutによって自動的にリカバリされるため、要素ステータスがloadingに変更されます。
ttGridAdmin dbStatus -elementコマンドを使用して、要素ステータスをモニターできます。この例では、host3.instance1データ・インスタンスの要素のステータスがloadingであるため、この要素がリカバリ処理中であることがわかります。
% ttGridAdmin dbStatus database1 -element Database database1 element level status as of Wed Jan 10 14:34:08 PST 2018 Host Instance Elem Status Date/Time of Event Message ----- --------- ---- ------ ------------------- ------- host3 instance1 1 loading 2018-01-10 14:33:23 host4 instance1 2 opened 2018-01-10 14:33:21 host5 instance1 3 opened 2018-01-10 14:33:23 host6 instance1 4 opened 2018-01-10 14:33:23 host7 instance1 5 opened 2018-01-10 14:33:23 host8 instance1 6 opened 2018-01-10 14:33:23
要素またはレプリカ・セット全体が停止した場合に何が行われるかの詳細は、レプリカ・セット内の1つの要素で障害が発生しても可用性を保持およびレプリカ・セット全体が停止するか障害が発生した場合のデータの使用不可を参照してください。
TimesTen Scaleoutの主な目的は、障害が発生した場合でもデータへのアクセスを提供することです。k = 2の場合、レプリカ・セット内に含まれるデータは、レプリカ・セット内の少なくとも1つの要素が稼働しているかぎり使用できます。レプリカ・セット内の要素が停止し、その後リカバリされた場合、その要素はレプリカ・セット内の他の要素と自動的に再同期されます。
|
ノート: k =1の場合、レプリカ・セットに含まれている要素は1つのみであるため、要素に障害が発生するとレプリカ・セットが停止します。k = 1の場合に、要素に永続的な障害が発生した場合のリカバリの詳細は、レプリカ・セット全体が停止するか障害が発生した場合のデータの使用不可を参照してください。 |
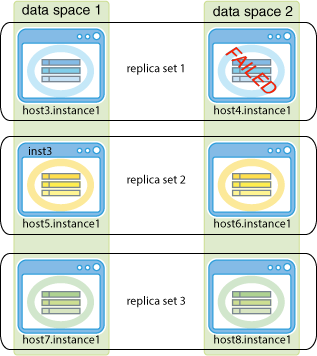
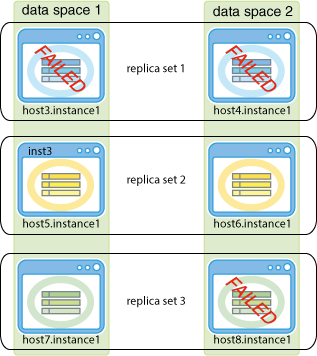
次の例は、k = 2の場合のグリッドを示しています。3つのレプリカ・セットが作成され、各レプリカ・セットに2つの要素があります。host4.instance1データ・インスタンスの要素に障害が発生します。TimesTen Scaleoutはhost3.instance1データ・インスタンス内の要素に自動的に再接続して、トランザクションの実行を継続します。host4.instance1データ・インスタンスの要素が使用不可の間またはリカバリ中は、host3.instance1データ・インスタンスの要素がレプリカ・セットのすべてのトランザクションを処理します。host4.instance1データ・インスタンスの要素がリカバリされると、レプリカ・セット内の両方の要素がトランザクションを処理できるようになります。
各レプリカ・セットで1つの要素が稼働しているかぎり、異なるレプリカ・セットで複数の障害が発生しても、機能が失われることはありません。レプリカ・セット全体に障害が発生した場合は、データが失われることがあります。
次の例は、3つのレプリカ・セットがある、k = 2の場合のグリッドを示しています。この例では、host4.instance1、host5.instance1およびhost8.instance1データ・インスタンスの要素に障害が発生しています。ただし、各レプリカ・セットで1つ以上の要素が使用可能であるため、トランザクションの実行は継続されます。
k=2の場合に、レプリカ・セット内の単一の要素に障害が発生したときの対応方法は、次の各項を参照してください。
要素ステータスの中には、ユーザーによる介入が必要なものがあります。要素ステータスを表示したときに、これらの各要素ステータスに対応できます。表11-2に、各要素ステータスの詳細と要素ステータスの変更への推奨される対応方法を示します。
表11-2 要素ステータス
| ステータス | 意味 | ノートおよび推奨事項 |
|---|---|---|
|
|
要素をクローズしようとして失敗しました。 |
障害の詳細は、
|
|
|
要素をクローズ中です。 |
しばらく待ってから、 |
|
|
要素を作成しようとして失敗しました。 |
障害の詳細は、
|
|
|
要素を作成中です。 |
しばらく待ってから、 |
|
|
要素を破棄しようとして失敗しました。 |
障害の詳細は、 要素ステータスが |
|
|
要素が破棄されました。 |
要素は存在しません。 ノート: データベースの最後の要素が破棄されると、要素ステータスを含め、データベースのレコードは何も存在しなくなります。 |
|
|
要素を破棄中です。 |
しばらく待ってから、 |
|
|
この要素が配置されているデータ・インスタンスが実行されていません。 |
データ・インスタンスが停止している場合、要素のステータスはdownです。
手動でデータ・インスタンスを再起動する方法の詳細は、例11-3「停止しているデータ・インスタンスの再起動」およびデータ・インスタンスが停止している場合のリカバリを参照してください。 |
|
|
要素は |
要素ステータスが |
|
|
要素は |
しばらく待ってから、 要素ステータスが |
|
|
要素は |
しばらく待ってから、 要素ステータスが |
|
|
要素をロードしようとして失敗しました。 |
障害の詳細は、
|
|
|
要素がロードされました。 |
要素はロードされ、オープンできるようになりました。 |
|
|
要素をロード中です。 |
しばらく待ってから、 |
|
|
要素はオープンしています。 |
機能している要素の標準ステータスです。要素を介してデータベース接続が可能です。 |
|
|
要素をオープンしようとして失敗しました。 |
障害の詳細は、
|
|
|
要素をオープン中です。 |
しばらく待ってから、 |
|
|
要素を作成する必要がありますが、作成はまだ開始されていません。 |
しばらく待ってから、 |
|
|
要素はアンロードされました。 |
データベースを再度ロード(
|
|
|
要素をアンロード中です。 |
しばらく待ってから、 |
|
|
要素はロードされますが、レプリカ・セット内の他の要素がロードされた後でロードされます。 |
レプリカ・セット内の他の要素のステータスに注意してください。
|
|
ノート: ノートおよび推奨事項の列では、頻繁にttGridAdminコマンドが示されています。これらのコマンドの詳細は、Oracle TimesTen In-Memory Databaseリファレンス内で、ttGridAdmin dbStatusについてはデータベースのステータスのモニター(dbStatus)、ttGridAdmin dbCreateについてはデータベースの作成(dbCreate)、ttGridAdmin dbOpenについてはデータベースのオープン(dbOpen)、ttGridAdmin dbLoadについてはメモリーへのデータベースのロード(dbLoad)、ttGridAdmin dbUnloadについてはデータベースのアンロード(dbUnload)、ttGridAdmin dbCloseについてはデータベースのクローズ(dbClose)、ttGridAdmin dbDestroyについてはデータベースの破棄(dbDestroy)、ttGridAdmin instanceExecについてはグリッド・インスタンスでのコマンドまたはスクリプトの実行(instanceExec)を参照してください。 |
次の各項では、レプリカ・セット内の単一の要素に障害が発生した場合の様々なシナリオへの対応方法を示します。
例11-2 要素の作成の再試行
要素の作成が失敗した場合は、その要素が存在する必要がある同じデータ・インスタンスで、ttGridAdmin dbCreate -instanceコマンドを使用して要素の作成を再試行してください。
% ttGridAdmin dbCreate database1 -instance host3 Database database1 creation started
データ・インスタンスが停止している場合、データ・インスタンス内の要素は停止しています。ttGridAdmin instanceExec -onlyコマンドを使用してttDaemonAdmin -startコマンドを実行することで、データ・インスタンスのデーモンを再起動します。詳細は、データ・インスタンスが停止している場合のリカバリを参照してください。
% ttGridAdmin instanceExec -only host4.instance1 ttDaemonAdmin -start Overall return code: 0 Commands executed on: host4.instance1 rc 0 Return code from host4.instance1: 0 Output from host4.instance1: TimesTen Daemon (PID: 15491, port: 14000) startup OK.
例11-4 除去された要素または破棄が失敗した要素の破棄
要素を除去した場合でも、その要素が使用しているファイル・システム領域を解放するために、要素を破棄する必要があります。その後で、新しい要素を作成できます。除去の詳細は、レプリカ・セット全体が停止するか障害が発生した場合のデータの使用不可を参照してください。
要素ステータスがdestroy failedまたはevictedの場合は、ttGridAdmin dbDestroy -instanceコマンドを使用して、データ・インスタンスの要素を破棄します。
% ttGridAdmin dbDestroy database1 -instance host3 Database database1 destroy started
k = 2の場合、同じレプリカ・セット内のすべてのアクティブな要素は、トランザクション上同期化されます。レプリカ・セット内の1つの要素に適用されるDML文またはDDL文はすべて、レプリカ・セット内の他のすべての要素にも適用されます。レプリカ・セット内の1つの要素が稼働していない場合、他の要素はDML文またはDDL文を引き続き実行できます。
障害が発生した要素がリカバリされた場合、その要素はしばらくの間使用不可能になり、トランザクション上の遅れが生じます。この要素がグリッド内のレプリカ・セットにおける役割を再開するためには、レプリカ・セットのアクティブな要素とデータを同期する必要があります。
要素にファイル・システム障害などの永続的な障害が発生した場合は、ttGridAdmin dbDistribute -remove -replaceWithコマンドを使用して、レプリカ・セットからその要素を削除し、別の要素に置き換える必要があります。詳細は、別の要素での要素の置換を参照してください。
TimesTen Scaleoutは、次の方法を使用して、レプリカ・セット内のリストアされた要素または新しい要素のデータを自動的に再同期およびリストアします。
ログベースのキャッチ・アップ: このプロセスでは、レプリカ・セット内のアクティブな要素からトランザクション・ログを転送し、リカバリされる要素に欠落しているトランザクション・レコードを適用します。この操作によって、要素がレプリカ・セットに参加していなかったときに実行されたDML文またはDDL文が適用されます。
レプリカ・セットのいずれかの要素が停止していたときに開始されたトランザクションは、停止していた要素のリカバリ時に再実行する必要があります。ログベースのキャッチアップ・プロセスでは、すべてのオープン・トランザクションがコミットまたはロールバックするまで待機してから、それらのトランザクションをトランザクション・ログから再実行します。停止している要素が長時間にわたってリカバリ処理中の場合は、リカバリされる要素に対するログベースのキャッチアップ・プロセスの完了を妨げるオープン・トランザクションが(アクティブな要素に)存在してる可能性があります。ttXactAdminユーティリティを使用して、オープン・トランザクションがないか確認します。すべてのオープン・トランザクションを、コミットするかロールバックして解決します。
複製: TimesTen Scaleoutは、リカバリされる要素または障害が発生した要素を置換する新しい要素のいずれかに、アクティブな要素を複製します。複製操作では、アクティブな要素のすべてのチェックポイントおよびログ・ファイルがリカバリされる要素にコピーされます。
ただし、アクティブな要素は複製操作中も引き続きトランザクションを受け入れるため、コピーされたトランザクション・ログ・ファイルに含まれない追加のトランザクション・ログ・レコードが存在する可能性があります。複製操作が完了すると、TimesTen Scaleoutはアクティブな要素に接続してログベースのキャッチアップ操作を実行し、新しい要素を完全に最新の状態に更新します。
k = 2の場合に、要素を自動的にリカバリできないときは、障害の原因を調査する必要があります。ドライブを再マウントする必要があるなど、修正できる問題が見つかる場合もあります。ただし、ドライブが完全に破壊されているなど、修正できない問題が見つかることもあります。永続的で、リカバリ不可能な障害のほとんどは、通常、ハードウェアの障害に関連しています。
修正可能な場合は、ホストまたはデータ・インスタンスの問題を修正してから、次のいずれかを実行します。
データ・インスタンスを再起動します。データ・インスタンスを再起動する方法の詳細は、データ・インスタンスが停止している場合のリカバリを参照してください。
ttGridAdmin dbloadコマンドを使用して、TimesTenデータベースを再ロードします。これにより、要素の再ロードが試行されます。
ホストまたはデータ・インスタンスに関する問題を修正できない場合は、要素のデータが取得できない状態になっている可能性があります。この場合は、要素を削除して、別の要素に置換する必要があります。置換されると、アクティブな要素によって、このレプリカ・セットのデータで新しい要素が更新されます。
いずれかのホストで複数のエラーが発生している場合(自動的にリカバリ可能であった場合でも)、より信頼性が高い別のホストに置き換えることをお薦めします。
データを失うことなく要素を置換するには、ttGridAdmin dbDistribute -remove -replaceWithコマンドを実行します。これは、置換する要素に存在するデータを取得して、新しい要素に再分散します。詳細は、別の要素での要素の置換を参照してください。
単一のレプリカ・セット内のすべての要素が停止しているか、障害が発生している場合、停止しているレプリカ・セットに格納されているデータは使用できなくなります。レプリカ・セット全体に障害が発生しないようにするには、レプリカ・セット全体の障害が発生する可能性を軽減するような方法で要素を分散させます。物理的に分離している複数のホストにデータ・インスタンスをインストールする方法の詳細は、データ領域グループへのホストの割当てを参照してください。
次の各項では、レプリカ・セットが停止しているときのトランザクションの動作、TimesTen Scaleoutによるレプリカ・セットのリカバリ方法、およびレプリカ・セットを完全にリカバリするためにユーザーによる介入が必要な場合のユーザーの操作について説明します。
表11-3で説明しているように、停止しているか、障害が発生しているレプリカ・セットがある場合、データを正常に保持できるかどうかは、Durability接続属性の設定によって決まります。Durability接続属性の設定の詳細は、永続性の設定を参照してください。
表11-3 Durabilityの値に基づくトランザクションのリカバリの可能性
| Durabilityの値 | レプリカ・セットに障害が発生した場合のトランザクションへの影響 |
|---|---|
|
1 |
参加者は、分散トランザクションのトランザクション・ログに、コミットの準備ログ・レコードまたはコミット・ログ・レコードを同期的に書き込みます。こうすることで、コミットされたトランザクションが保持される可能性を最大限に高めることができます。レプリカ・セットが停止した場合、すべてのトランザクション・ログ・レコードが永続的にファイル・システムにコミットされているため、TimesTen Scaleoutによってリカバリできます。 |
|
0 |
参加者は、分散トランザクションのコミットの準備ログ・レコードおよびコミット・ログ・レコードを非同期的に書き込みます。レプリカ・セット全体が停止した場合、トランザクション・ログ・レコードが永続的にファイル・システムにコミットされる保証はありません。レプリカ・セット内の要素に障害が発生したまたは停止した状況によっては、データ損失の可能性があります。 |
次の各項では、レプリカ・セットが停止した後に新しいトランザクションで何が行われるか、また、Durability接続属性の値に基づいたレプリカ・セットのリカバリ方法について説明します。
次のリストでは、停止しているレプリカ・セットがある場合のトランザクションの動作を説明しています。
アクティブなレプリカ・セット内の行のみにアクセスする(停止しているレプリカ・セット内の行にはアクセスしない)問合せのトランザクションは成功します。停止しているレプリカ・セット内のデータにアクセスしようとする問合せは失敗します。アプリケーションは、レプリカ・セットがリカバリされたときにトランザクションを再試行する必要があります。
停止しているレプリカ・セットからのデータを必要としない、部分的な結果のヒントを持つグローバル読取りは成功します。
たとえば、レプリカ・セット1の両方の要素で障害が発生しており、トランザクション内の問合せにレプリカ・セット1からのデータが必要な場合、そのトランザクションは失敗します。アプリケーションがトランザクションを再度実行する必要があります。
DDL文ではすべてのレプリカ・セットが使用可能である必要があるため、停止しているレプリカ・セットがある場合、DDL文を含むトランザクションは失敗します。アプリケーションがトランザクションをロールバックする必要があります。
DML文を含むトランザクションは、停止しているレプリカ・セット内の要素で1つ以上の行を更新しようとすると、失敗します。アプリケーションがトランザクションをロールバックする必要があります。Durability=0の場合、このシナリオでは、データ損失が発生する可能性があります。詳細は、Durability=0の場合の障害が発生したレプリカ・セットのリカバリを参照してください。
Durability=1の場合、停止しているレプリカ・セットからのデータを必要としない、DMLを含むトランザクションは成功します。たとえば、レプリカ・セット1の両方の要素に障害が発生した場合、SELECT、INSERT、INSERT...SELECT、UPDATEまたはDELETEのいずれの文もレプリカ・セット1に格納されたデータに依存していない場合にのみ、トランザクションは成功します。
次の各項では、Durability=1の場合の、障害が発生したレプリカ・セットのリカバリ・プロセスについて説明します。
レプリカ・セット内のすべての要素が一時的にでも停止した場合、TimesTen Scaleoutでは、次のようにして完全なレプリカ・セットを自動的にリカバリできることがあります(最初の問題が解決されている場合)。
シード要素を判別してリカバリします。シード要素と呼ばれる、障害が発生した要素の中で最新の変更を持つ要素が最初にリカバリされます。シード要素は、チェックポイントおよびトランザクション・ログ・ファイルの最新のトランザクションにリカバリされます。
要素のリカバリが完了すると、TimesTen Scaleoutはインダウト・トランザクションがないか確認します。
一時障害または予期しない終了の後で、要素がファイル・システム(チェックポイントおよびトランザクションログ・ファイル)からロードされた場合、準備されていたが、コミットされていない2フェーズ・コミット・トランザクションはすべて保留のままになります。これは、インダウト・トランザクションと呼ばれます。トランザクションが中断された場合、2フェーズ・コミットのプロトコルによってトランザクション全体がコミットされたかどうかが疑わしいことがあります。
インダウト・トランザクションがない場合は、処理を通常どおり実行します。
インダウト・トランザクションがある場合、すべてのインダウト・トランザクションが解決されるまで、このレプリカ・セットを含む通常処理は続行されません。インダウト・トランザクションがある場合、TimesTen Scaleoutはトランザクション・ログを確認して、いずれかの参加者でトランザクションがコミットされたか、コミットする準備ができているかを判別します。トランザクション・ログ・レコードには、トランザクション内の他の参加者に関する情報が含まれています。TimesTen Scaleoutによるインダウト・トランザクションの解決方法は、表11-4を参照してください。
このプロセス中に要素に障害が発生し、トランザクションがコミットまたはロールバックされた後に再度起動した場合、要素は参加している他の要素の結果をリクエストすることでそれ自体をリカバリします。
シード要素がリカバリされると、レプリカ・セット内の他の要素は、複製およびログベースのキャッチアップ方法を使用して、シード要素からリカバリされます。複製およびログベースのキャッチアップ方法の詳細は、要素が停止した後のレプリカ・セットのリカバリを参照してください。
表11-4 TimesTen Scaleoutによるインダウト・トランザクションの解決方法
| 障害 | アクション |
|---|---|
|
少なくとも1人の参加者がコミット・ログ・レコードを受信しました。他のすべての参加者は、少なくともコミットの準備ログ・レコードを受信します。 |
トランザクションは、すべての参加者でコミットされます |
|
トランザクションのすべての参加者が、コミットの準備ログ・レコードを受信しました。 |
トランザクションは、すべての参加者でコミットされます。 |
|
少なくとも1人の参加者が、コミットの準備ログ・レコードを受信していません。 |
トランザクション・マネージャからすべての参加者に、トランザクションのロールバックの導入である、コミットの準備を元に戻すように通知されます。
|
ただし、停止しているレプリカ・セット内の要素をリカバリできない場合は、いずれかの要素を削除して置換するか、レプリカ・セット全体を除去する必要がある場合があります。詳細は、レプリカ・セットに永続的な障害が発生した要素がある場合のリカバリを参照してください。
次に、Durability=0の場合の、障害が発生したレプリカ・セットのリカバリ・プロセスについて説明します。
Durability=0と設定した場合は、レプリカ・セットに障害が発生した場合にデータ損失の可能性があることを認めることになります。ただし、TimesTen Scaleoutでは、複数の異なる時点で要素に障害が発生した場合、データ損失を回避しようとします。
レプリカ・セット内の単一の要素のみに障害が発生した場合、TimesTen Scaleoutでは、レプリカ・セット内の残りの要素を永続モードに切り替えようとします(k = 2の場合)。つまり、(Durability=0の場合に残りの要素で障害が発生すると生じる)データ損失を制限するために、TimesTen Scaleoutでは、Durability=1と構成されているかのように、要素の永続性の動作を変更します。
TimesTen Scaleoutがレプリカ・セット内の残りの要素を永続モードに切り替えることができる場合、参加している要素は、分散トランザクションのファイル・システムにコミットの準備ログ・レコードを同期的に書き込みます。その後、この要素にも障害が発生してレプリカ・セット全体が停止した場合、TimesTen Scaleoutによってトランザクション・ログ・レコードからレプリカ・セットがリカバリされます。したがって、このシナリオではトランザクションは失われず、TimesTen Scaleoutは、Durability=1と設定された場合と同様にレプリカ・セットを自動的にリカバリします。単一の要素がリカバリされた後のリカバリの詳細は、Durability=1の場合の障害が発生したレプリカ・セットの永続的なリカバリを参照してください。
TimesTen Scaleoutで、最後に残っている要素に障害が発生するまでレプリカ・セットを永続モードに切り替えられない場合、レプリカ・セットに一時的または永続的な障害が発生しているかどうかに応じて、データ損失が発生することがあります。
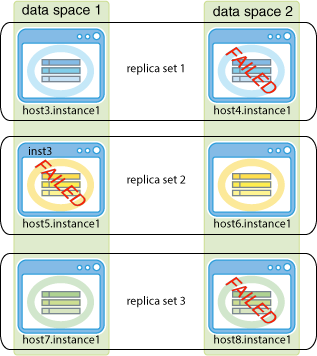
要素が非永続的である場合の一時的なレプリカ・セットの障害: レプリカ・セット内のいずれの要素も、レプリカ・セットが停止する前に関与していた分散トランザクションのコミットの準備ログ・レコードを同期的に書き込んでいないため、最後に成功したエポック・トランザクションの後にコミットされたトランザクションはすべて失われます。
両方の要素のステータスがwaiting for seedである場合、レプリカ・セットが停止する前に永続モードへの切替えは行われていません。この場合は、エポック・リカバリが必要で、最後に成功したエポック・トランザクションの後にコミットされたトランザクションはすべて失われます。このレプリカ・セット内の要素は、いずれもトランザクション・ログを使用してリカバリできないため、リカバリされたときにwaiting for seedステータスのままになることがあります。かわりに、レプリカ・セットをリカバリまたは削除してからデータベースをアンロードして再ロードすることで、エポック・リカバリを実行する必要があります。詳細は、非永続状態のレプリカ・セットに障害が発生した場合のプロセスを参照してください。
永続的なレプリカ・セットの障害: レプリカ・セット内のいずれの要素もリカバリできない場合、これらの要素の除去が必要な場合があります。これにより、そのレプリカ・セットのデータが失われます。詳細は、レプリカ・セットに永続的な障害が発生した要素がある場合のリカバリを参照してください。
非永続状態のレプリカ・セットに障害が発生した場合のプロセス
レプリカ・セットが停止し、その状態が非永続的である場合、TimesTen Scaleoutによってレプリカ・セットの停止が認識されるまで、トランザクションがデータベースに対してコミットを続けることがあります。(エポック・トランザクションの実行が失敗した後で) TimesTen Scaleoutがレプリカ・セットの停止を認識すると、失われるトランザクションの数を最小限に抑えるために、データベースが読取り専用に切り替えられます。エポック・リカバリ時には、データベースが最後に成功したエポック・トランザクションまで再ロードされ、実質上、最後に成功したエポック・トランザクションの後にコミットされたすべてのトランザクションが失われます。このシナリオでは、EpochInterval接続属性の値によって、エポック・トランザクション間の時間のみでなく、コミットされたトランザクションが失われる可能性のあるおおよその時間の長さも決定されます。
|
ノート: 停止しているレプリカ・セットが原因でエポック・トランザクションが失敗した場合、データベースは読取り専用に設定されます。その他の理由でエポック・トランザクションが失敗した場合、TimesTen Scaleoutではデータベースを読取り専用に設定しません。 |
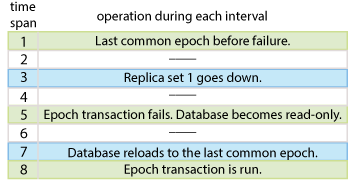
図11-3に、8つの期間にわたって行われるアクションを示します。
エポック・トランザクションは正常にコミットされます。
エポック・トランザクションが正常に実行された後、トランザクションを続行できます。停止しているレプリカ・セット内の要素はいずれもトランザクション・ログを永続的にフラッシュできなかったため、最後に成功したエポック・トランザクションの後にコミットされたトランザクションはすべて、エポック・リカバリ後に失われます。
レプリカ・セット1は、いずれの要素も永続モードに切り替えずに停止します。
|
ノート: レプリカ・セットが停止している間に、順序が増分することがあります。 |
データベースがまだ読取り専用に設定されていない場合、トランザクションはレプリカ・セットの停止後も続行できます。停止しているレプリカ・セット内の要素はいずれもトランザクション・ログを永続的にフラッシュできなかったため、最後に成功したエポック・トランザクションの後にコミットされたトランザクションはすべて、エポック・リカバリ後に失われます。
|
ノート: 停止しているレプリカ・セットがある場合のトランザクションの動作で説明されているように、レプリカ・セットが停止した後のトランザクションの動作は、トランザクション内の文のタイプによって異なります。 |
稼働していないレプリカ・セットがあるため、次のエポック・トランザクションは失敗します。TimesTen Scaleoutからすべてのデータ・インスタンスに、データベースが読取り専用になったことが通知されます。すべてのアプリケーションは、オープン・トランザクション内でDML文、DDL文またはコミット文を実行すると失敗します。ユーザーが各トランザクションをロールバックする必要があります。
|
ノート: ttGridAdmin dbStatusコマンドには、読取り専用モードまたは読取り/書込みモードであるかどうかなど、データベースの状態が示されます。 |
レプリカ・セットをリカバリまたは除去する必要があります。
停止しているレプリカ・セットをリカバリします。複数のレプリカ・セットが停止している場合、すべてのレプリカ・セットがリカバリされるか置換されるまで、データベースは読取り/書込みモードを開始できません。
レプリカ・セット内のいずれの要素もリカバリできない場合、レプリカ・セットを除去する必要がある場合があります。除去すると、そのレプリカ・セットのデータが失われます。詳細は、レプリカ・セットに永続的な障害が発生した要素がある場合のリカバリを参照してください。
一貫した方法でデータベースをリカバリしてデータ損失を一部に制限するために、データベースをアンロードしてから、最後に成功したエポック・トランザクションまで再ロードすることで、エポック・リカバリを実行します。データベースをアンロードしてから、最後に成功したエポック・トランザクションまで再ロードすると、最後に成功したエポックの後にコミットされたトランザクションがすべて失われます。ttGridAdmin dbLoadコマンドの詳細は、メモリーへのデータベースのロード(dbLoad)を参照してください。また、ttGridAdmin dbUnloadコマンドの詳細は、データベースのアンロード(dbUnload)を参照してください。
新しいエポック・トランザクションが成功します。データベースが読取り/書込みに設定されます。通常のトランザクション動作が再開されます。
永続的な障害が発生したために、レプリカ・セット内の要素またはレプリカ・セット全体がリカバリ不可能な場合は、障害が発生した要素を削除するか、障害が発生したレプリカ・セットを除去する必要があります。ホストに永続的な障害が発生した場合またはレプリカ・セット内のすべての要素に障害が発生した場合に、永続的な障害が発生することがあります。
レプリカ・セット内のすべての要素に永続的な障害が発生した場合は、レプリカ・セット全体を除去する必要があります。これにより、そのレプリカ・セット内の要素のデータは完全に失われます。
k = 1の場合、1つの要素の永続的な障害はレプリカ・セットの障害です。k = 2の場合は、レプリカ・セット内の両方の要素に障害が発生した場合にのみ、レプリカ・セットに障害が発生したとみなされます。k = 2で、レプリカ・セットに永続的な障害が発生した場合は、レプリカ・セットの両方の要素を同時に除去する必要があります。
レプリカ・セットを除去すると、グリッドの分散からそのレプリカ・セットが削除されます。ただし、障害が発生したレプリカ・セットがデータベース内の唯一のレプリカ・セットである場合は、レプリカ・セットを除去できません。この場合、チェックポイント・ファイル、トランザクション・ログ・ファイルまたはデーモン・ログ・ファイル(可能な場合)をすべて保存してから、データベースを破棄して再作成します。
レプリカ・セットが停止した場合:
Durabilityが0である場合、データベースは読取り専用モードになります。
Durabilityが1である場合、障害が発生したレプリカ・セットを含むすべてのトランザクションは、障害が発生したレプリカ・セットが除去されるまでブロックされます。ただし、障害が発生したレプリカ・セットを含まないすべてのトランザクションは、何も問題がないかのように動作を継続します。
k = 2で、レプリカ・セットの1つの要素のみに障害が発生した場合、障害が発生した要素を新しい要素で置換できるまで、アクティブな要素がデータに対するすべてのリクエストを引き継ぎます。このため、障害が発生してもデータは失われません。レプリカ・セット内のアクティブな要素が、受信トランザクションを処理します。単純に、障害が発生した要素を削除し、レプリカ・セット内のアクティブな要素から複製された新しい要素で置換できます。アクティブな要素は、新しい要素の複製の基礎を提供します。障害が発生した要素を削除および置換する方法の詳細は、別の要素での要素の置換を参照してください。
|
ノート: TimesTen Scaleoutが認識していない問題があり、レプリカ・セットを除去する必要があるとわかっている場合は、必要に応じてレプリカ・セットを除去および置換できます。 |
ttGridAdmin dbDistribute -evictコマンドを使用して、グリッドの分散マップからレプリカ・セットを除去できます。レプリカ・セットの除去をリクエストする前に、要素を追加または削除するために保留中のリクエストがすべて適用されていることを確認してください。
レプリカ・セットを除去する場合は、次のオプションがあります。
レプリカ・セットを置換せずに即時除去します。
このレプリカ・セットのデータ・インスタンスおよびホストに障害が発生していない場合は、同じデータ・インスタンスを使用してレプリカ・セットを再作成できます。グリッド上に他のデータベースがあり、ホストに問題がない場合は、これが推奨されるオプションです。
この場合、次の手順を実行する必要があります。
データ・インスタンスおよびホストが稼働した状態で、障害が発生したレプリカ・セットの要素を除去します。
レプリカ・セットを除去すると、このレプリカ・セット内のデータは失われますが、データベース内の他のレプリカ・セットは引き続き機能します。これで、グリッド内のレプリカ・セットが1つ減りました。
除去された要素を保持していたのと同じデータ・インスタンス上の分散マップに新しい要素を追加する場合は、除去されたレプリカ・セット内の要素のすべてのチェックポイントおよびトランザクション・ログを消去します。
データ・インスタンスおよびホストが稼働した状態で、除去されたレプリカ・セットの要素を破棄します。
必要に応じて、除去されたレプリカ・セットを、同じデータ・インスタンスおよびホスト(まだ有効な場合)または新しいデータ・インスタンスおよびホストのいずれかにある新しいレプリカ・セットで置換できます。新しい要素を分散マップに追加します。これにより、グリッドが必要な構成にリストアされます。
レプリカ・セットを除去し、ただちに新しいレプリカ・セットに置き換えて、グリッドを予期されている構成に戻します。
障害が発生したレプリカ・セットのデータ・インスタンスおよびホストと置換するための新しいデータ・インスタンスおよびホストを作成します。
障害が発生したレプリカ・セットの要素を除去し、新規レプリカ・セットに置き換えます。レプリカ・セットを除去すると、このレプリカ・セット内のデータは失われますが、データベース内の他のレプリカ・セットは引き続き機能します。
ttGridAdmin dbDistribute -evict -replaceWithコマンドを使用して、レプリカ・セットを除去して新しいレプリカ・セットで置き換えます。これにより、新しいデータ・インスタンスおよびホストで各要素が新規作成されます。新しいレプリカ・セットの要素が分散マップに追加されます。ただし、他のレプリカ・セットの残りのデータが、新しいレプリカを含めて再分散されることはありません。そのため、データを挿入するまで新しいレプリカ・セットは空のままです。
除去されたレプリカ・セットの要素を破棄します。
次の各項では、レプリカ・セットに1個または2個の要素がある場合に、障害が発生したレプリカ・セットを除去する方法を示しています。
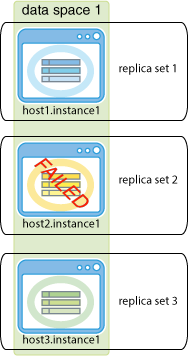
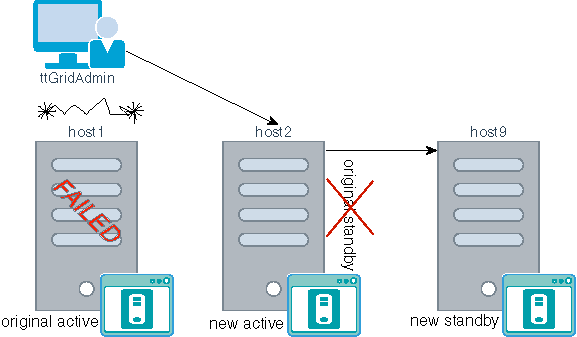
図11-4の例は、kが1に設定され、host1.instance1、host2.instance1およびhost3.instance1の3つのデータ・インスタンスを持つように構成されている、TimesTenデータベースを示しています。host2.instance1データ・インスタンス上の要素には、永続的なハードウェア障害による障害が発生しています。
次の例では、除去オプションを示しています。
例11-5 別のときに置換できるようにするための要素の除去
障害が発生した要素をリカバリできない場合は、レプリカ・セットを除去できます。
次に例を示します。
ttGridAdmin dbDistribute -evictコマンドを使用して、host2.instance1データ・インスタンス上の要素のレプリカ・セットを除去します。
ttGridAdmin dbDestroy -instanceコマンドを使用して、除去されたレプリカ・セット内のこの要素のみのチェックポイントおよびトランザクション・ログを破棄します。
% ttGridAdmin dbDistribute database1 -evict host2.instance1 -apply
Element host2.instance1 evicted
Distribution map updated
% ttGridAdmin dbDestroy database1 -instance host2.instance1
Database database1 instance host2 destroy started
% ttGridAdmin dbStatus database1 -all
Database database1 summary status as of Thu Feb 22 16:44:15 PST 2018
created,loaded-complete,open
Completely created elements: 2 (of 3)
Completely loaded elements: 2 (of 3)
Open elements: 2 (of 3)
Database database1 element level status as of Thu Feb 22 16:44:15 PST 2018
Host Instance Elem Status Date/Time of Event Message
----- --------- ---- --------- ------------------- -------
host1 instance1 1 opened 2018-02-22 16:42:14
host2 instance1 2 destroyed 2018-02-22 16:44:01
host3 instance1 3 opened 2018-02-22 16:42:14
Database database1 Replica Set status as of Thu Feb 22 16:44:15 PST 2018
RS DS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host1 instance1 opened 2018-02-22 16:42:14
2 1 3 host3 instance1 opened 2018-02-22 16:42:14
Database database1 Data Space Group status as of Thu Feb 22 16:44:15 PST 2018
DS RS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host1 instance1 opened 2018-02-22 16:42:14
2 3 host3 instance1 opened 2018-02-22 16:42:14
この例では、データ・インスタンスおよびホストがまだ有効であるため、レプリカ・セットの新しい要素を作成します。その後、新しい要素を分散マップに追加します。
レプリカ・セットが除去される前に、以前の要素が存在していた同じデータ・インスタンスで、ttGridAdmin dbCreate -instanceコマンドを使用して新しい要素を作成します。
ttGridAdmin dbDistribute -addコマンドを使用して、分散マップに新しい要素を追加します。
% ttGridAdmin dbCreate database1 -instance host2
Database database1 creation started
% ttGridAdmin dbDistribute database1 -add host2 -apply
Element host2 is added
Distribution map updated
% ttGridAdmin dbStatus database1 -all
Database database1 summary status as of Thu Feb 22 16:53:17 PST 2018
created,loaded-complete,open
Completely created elements: 3 (of 3)
Completely loaded elements: 3 (of 3)
Open elements: 3 (of 3)
Database database1 element level status as of Thu Feb 22 16:53:17 PST 2018
Host Instance Elem Status Date/Time of Event Message
----- --------- ---- ------ ------------------- -------
host1 instance1 1 opened 2018-02-22 16:42:14
host3 instance1 3 opened 2018-02-22 16:42:14
host2 instance1 4 opened 2018-02-22 16:53:14
Database database1 Replica Set status as of Thu Feb 22 16:53:17 PST 2018
RS DS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host1 instance1 opened 2018-02-22 16:42:14
2 1 3 host3 instance1 opened 2018-02-22 16:42:14
3 1 4 host2 instance1 opened 2018-02-22 16:53:14
Database database1 Data Space Group status as of Thu Feb 22 16:53:17 PST 2018
DS RS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host1 instance1 opened 2018-02-22 16:42:14
2 3 host3 instance1 opened 2018-02-22 16:42:14
3 4 host2 instance1 opened 2018-02-22 16:53:14
例11-6 再分散なしのデータ・インスタンスの除去および置換
開始時と同じ数のレプリカ・セットがある、データベースの初期容量をリカバリするには、ttGridAdmin dbDistribute -evict -replaceWithコマンドを使用して、要素を除去し、置換します。
次に例を示します。
新しいホスト(host4として識別)、インストール、データ・インスタンスおよび要素を作成します。
ttGridAdmin dbDistribute -evict -replaceWithコマンドを使用して、host2.instance1データ・インスタンス上の障害が発生した要素を含むレプリカ・セットを除去し、除去した要素をhost4.instance1データ・インスタンス上の要素で置換します。
host1.instance1およびhost3.instance1データ・インスタンス上の要素に存在するデータは、host4.instance1データ・インスタンス上の新しい要素に再分散されません。host4.instance1データ・インスタンス上の要素は空です。
ttGridAdmin dbDestroy -instanceコマンドを使用して、host2.instance1データ・インスタンス上の要素を破棄します。
% ttGridAdmin hostCreate host4 -address myhost.example.com -dataspacegroup 1
Host host4 created in Model
% ttGridAdmin installationCreate -host host4 -location /timesten/host4/installation1
Installation installation1 on Host host4 created in Model
% ttGridAdmin instanceCreate -host host4 -location /timesten/host4
Instance instance1 on Host host4 created in Model
% ttGridAdmin modelApply
Copying Model.........................................................OK
Exporting Model Version 2.............................................OK
Marking objects 'Pending Deletion'....................................OK
Deleting any Hosts that are no longer in use..........................OK
Verifying Installations...............................................OK
Creating any missing Installations....................................OK
Creating any missing Instances........................................OK
Adding new Objects to Grid State......................................OK
Configuring grid authentication.......................................OK
Pushing new configuration files to each Instance......................OK
Making Model Version 2 current........................................OK
Making Model Version 3 writable.......................................OK
Checking ssh connectivity of new Instances............................OK
Starting new data instances...........................................OK
ttGridAdmin modelApply complete
% ttGridAdmin dbDistribute database1 -evict host2.instance1
-replaceWith host4.instance1 -apply
Element host2.instance1 evicted
Distribution map updated
% ttGridAdmin dbDestroy database1 -instance host2
Database database1 instance host2 destroy started
% ttGridAdmin dbStatus database1 -all
Database database1 summary status as of Thu Feb 22 17:04:21 PST 2018
created,loaded-complete,open
Completely created elements: 3 (of 4)
Completely loaded elements: 3 (of 4)
Open elements: 3 (of 4)
Database database1 element level status as of Thu Feb 22 17:04:21 PST 2018
Host Instance Elem Status Date/Time of Event Message
----- --------- ---- --------- ------------------- -------
host1 instance1 1 opened 2018-02-22 16:42:14
host3 instance1 3 opened 2018-02-22 16:42:14
host2 instance1 4 destroyed 2018-02-22 17:04:11
host4 instance1 5 opened 2018-02-22 17:03:18
Database database1 Replica Set status as of Thu Feb 22 17:04:21 PST 2018
RS DS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host1 instance1 opened 2018-02-22 16:42:14
2 1 3 host3 instance1 opened 2018-02-22 16:42:14
3 1 5 host4 instance1 opened 2018-02-22 17:03:18
Database database1 Data Space Group status as of Thu Feb 22 17:04:21 PST 2018
DS RS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ----- --------- ------ ------------------- -------
1 1 1 host1 instance1 opened 2018-02-22 16:42:14
2 3 host3 instance1 opened 2018-02-22 16:42:14
3 5 host4 instance1 opened 2018-02-22 17:03:18
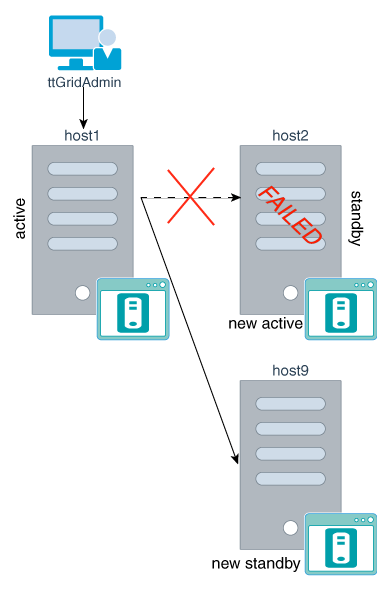
k = 2で、レプリカ・セットに永続的な障害が発生した場合は、レプリカ・セットの両方の要素を同時に除去する必要があります。
図11-5に、レプリカ・セット1のどこで障害が発生しているかを示します。
図11-5に示されている例では、レプリカ・セット1に、host3.instance1およびhost4.instance1データ・インスタンスの両方に存在する要素が含まれています。このレプリカ・セットに、修復不可能な障害が発生します。ttGridAdmin dbDistributeコマンドを実行してレプリカ・セットを除去するときに、除去されるレプリカ・セット内の両方の要素のデータ・インスタンスを指定します。
% ttGridAdmin dbDistribute database1 -evict host3.instance1 -evict host4.instance1 -apply Element host3.instance1 evicted Element host4.instance1 evicted Distribution map updated
レプリカ・セット内のいずれの要素もリカバリできない場合は、レプリカ・セット内の両方の要素を同時に除去します。開始時と同じ数のレプリカ・セットがある、データベースの初期容量をリカバリするには、ttGridAdmin dbDistribute -evict -replaceWithコマンドを使用して、障害が発生したレプリカ・セット内の要素を除去し、除去した要素を置換します。
次に例を示します。
host9.instance1およびhost10.instance1データ・インスタンスに新しい要素を作成します。
host3.instance1およびhost4.instance1データ・インスタンス上の障害が発生した要素があるレプリカ・セットを除去して、host9.instance1およびhost10.instance1データ・インスタンスの新しい要素で置換します。
アクティブなレプリカ・セット内の要素に存在するデータが、host9.instance1およびhost10.instance1データ・インスタンス上の新しい要素を含めて再分散されることはありません。host9.instance1およびhost10.instance1データ・インスタンス上の要素は空です。
ttGridAdmin dbDestroy -instanceコマンドを使用して、host3.instance1およびhost4.instance1データ・インスタンス上の要素を破棄します。
新しいレプリカ・セットは、host9.instance1およびhost10.instance1データ・インスタンスにある置換された要素からの要素を含むレプリカ・セット1として表示されるようになります。
% ttGridAdmin hostCreate host9 -internalAddress int-host9 -externalAddress
ext-host9.example.com -like host3 -cascade
Host host9 created in Model
Installation installation1 created in Model
Instance instance1 created in Model
% ttGridAdmin hostCreate host10 -internalAddress int-host10 -externalAddress
ext-host10.example.com -like host4 -cascade
Host host10 created in Model
Installation installation1 created in Model
Instance instance1 created in Model
% ttGridAdmin dbDistribute database1 -evict host3.instance1
-replaceWith host9.instance1 -evict host4.instance1
-replaceWith host10.instance1 -apply
Element host3.instance1 evicted
Element host4.instance1 evicted
Distribution map updated
% ttGridAdmin dbStatus database1 -all
Database database1 summary status as of Fri Feb 23 10:22:57 PST 2018
created,loaded-complete,open
Completely created elements: 8 (of 8)
Completely loaded elements: 6 (of 8)
Completely created replica sets: 3 (of 3)
Completely loaded replica sets: 3 (of 3)
Open elements: 6 (of 8)
Database database1 element level status as of Fri Feb 23 10:22:57 PST 2018
Host Instance Elem Status Date/Time of Event Message
------ --------- ---- ------- ------------------- -------
host3 instance1 1 evicted 2018-02-23 10:22:28
host4 instance1 2 evicted 2018-02-23 10:22:28
host5 instance1 3 opened 2018-02-23 07:28:23
host6 instance1 4 opened 2018-02-23 07:28:23
host7 instance1 5 opened 2018-02-23 07:28:23
host8 instance1 6 opened 2018-02-23 07:28:23
host10 instance1 7 opened 2018-02-23 10:22:27
host9 instance1 8 opened 2018-02-23 10:22:27
Database database1 Replica Set status as of Fri Feb 23 10:22:57 PST 2018
RS DS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ------ --------- ------ ------------------- -------
1 1 8 host9 instance1 opened 2018-02-23 10:22:27
2 7 host10 instance1 opened 2018-02-23 10:22:27
2 1 3 host5 instance1 opened 2018-02-23 07:28:23
2 4 host6 instance1 opened 2018-02-23 07:28:23
3 1 5 host7 instance1 opened 2018-02-23 07:28:23
2 6 host8 instance1 opened 2018-02-23 07:28:23
Database database1 Data Space Group status as of Fri Feb 23 10:22:57 PST 2018
DS RS Elem Host Instance Status Date/Time of Event Message
-- -- ---- ------ --------- ------ ------------------- -------
1 1 8 host9 instance1 opened 2018-02-23 10:22:27
2 3 host5 instance1 opened 2018-02-23 07:28:23
3 5 host7 instance1 opened 2018-02-23 07:28:23
2 1 7 host10 instance1 opened 2018-02-23 10:22:27
2 4 host6 instance1 opened 2018-02-23 07:28:23
3 6 host8 instance1 opened 2018-02-23 07:28:23
% ttGridAdmin dbDestroy database1 -instance host3
Database database1 instance host3 destroy started
% ttGridAdmin dbDestroy database1 -instance host4
Database database1 instance host4 destroy started
エラーがホストが関係するハードウェア・エラーである場合は、ホストの問題を修正し、ttGridAdmin dbLoadコマンドを使用してデータ・インスタンスを再ロードします。再ロード中、TimesTen Scaleoutは、データ・インスタンス内の要素をリカバリしようとします。
データ・インスタンスが停止している場合は、再起動する必要があります。データ・インスタンスが実行されていない場合は、そのデータ・インスタンスが管理するすべての要素が停止しています。
ttGridAdmin dbStatus -elementコマンドは、データ・インスタンス(およびその要素)が停止しているとみなされるかどうかを示します。
% ttGridAdmin dbStatus database1 -element Database database1 element level status as of Wed Mar 8 14:07:11 PST 2017 Host Instance Elem Status Date/Time of Event Message ----- --------- ---- ------ ------------------- ------- host3 instance1 1 opened 2017-03-08 13:58:06 host4 instance1 2 down host5 instance1 3 opened 2017-03-08 13:58:06 host6 instance1 4 opened 2017-03-08 13:58:09 host7 instance1 5 opened 2017-03-08 13:58:09 host8 instance1 6 opened 2017-03-08 13:58:09
(ハードウェアまたはソフトウェアの障害が原因で)データ・インスタンスが停止している場合、その管理対象の要素に対するすべての通信チャネルが停止され、すべてのデータ・インスタンスがリストアされ、管理対象の要素がリカバリされるまで、これらの要素にアクセスするための新規接続は許可されません。
データ・インスタンスが停止している場合は、TimesTenデーモンを再起動することで再起動します。再起動されると、データ・インスタンスがZooKeeperサーバーに接続します。すぐに接続されない場合、ZooKeeperサーバーへの接続を試行し続けます。接続後、データ・インスタンスはその要素をロードします。
|
ノート: データ・インスタンスがいずれのZooKeeperサーバーにも接続できない場合、データ・インスタンスは接続を試行し続けるため、永久ループとなることがあります。 |
instanceExecコマンドを使用して、TimesTen ttDaemonAdmin -startコマンドを実行することで、そのデータ・インスタンスのデーモンを手動で再起動できます。このとき、instanceExecコマンドの-only hostname[.instancename]オプションを使用します。
% ttGridAdmin instanceExec -only host4.instance1 ttDaemonAdmin -start Overall return code: 0 Commands executed on: host4.instance1 rc 0 Return code from host4.instance1: 0 Output from host4.instance1: TimesTen Daemon (PID: 15491, port: 14000) startup OK.
詳細は、Oracle TimesTen In-Memory Databaseリファレンスのグリッド・インスタンスでのコマンドまたはスクリプトの実行(instanceExec)またはOracle TimesTen In-Memory DatabaseリファレンスのttDaemonAdminを参照してください。
データ・インスタンスの障害の原因となったエラーの原因がわかっている場合は、問題を修正した後で、ttGridAdmin dbLoadコマンドを使用してデータベースを再ロードします。
% ttGridAdmin dbLoad database1
ttGridAdmin dbStatusコマンドを使用して、結果を確認できます。
すべてのデータ・インスタンスが停止している場合、またはレプリカ・セット内の両方の要素がwaiting for seedステータスを示している場合は、データベースを再ロードしてデータベースのリカバリを開始します。
データベースを再ロードするには、次の手順を実行します。
ttGridAdmin dbStatusコマンドを実行して、該当するレプリカ・セット内のすべての要素のステータスを確認します。
表11-2「要素ステータス」の各要素ステータスの説明に従って、データベースの要素に関する問題をすべて解決します。
メモリーへのデータベースの再ロードの説明に従って、ttGridAdmin dbloadコマンドを実行し、データベースを再ロードします。
|
ノート: レプリカ・セットの要素はwaiting for seedステータスを示しているが、シード要素がリカバリされない場合は、その要素のホストおよびデータ・インスタンスを評価して、ハードウェア・エラーまたはソフトウェア・エラーのいずれかに対処する必要があるかどうかを確認します。
データベースを再ロードしてもシード要素がまだリカバリされない場合は、停止したレプリカ・セットを削除します。詳細は、レプリカ・セットに永続的な障害が発生した要素がある場合のリカバリを参照してください。 |
高可用性システムを構築する場合、次のことを確認する必要があります。
クライアント・アプリケーションの接続が、そのデータベースのアクティブなデータ・インスタンスに自動的にルーティングされること。
データ・インスタンスへの既存のクライアント接続が失敗した場合、クライアントはデータベース内の別のアクティブなデータ・インスタンスに自動的に再接続されること。
クライアントが接続されているデータ・インスタンスに障害が発生した場合、そのクライアントはデータベース内の別のアクティブなデータ・インスタンスに自動的に再接続されること。
デフォルトでは、接続に失敗した場合、クライアントは自動的に別のデータ・インスタンスに再接続しようとします(可能な場合)。接続の失敗に対する準備および対応に関する、次の詳細を確認してください。
TTC_REDIRECTクライアント接続属性を使用して、クライアントのリダイレクト方法を定義します。デフォルトでは、自動リダイレクトのためにTTC_REDIRECTは1に設定されます。0に設定し、目的のデータ・インスタンスへの初期接続試行が失敗した場合は、エラーが返され、それ以上の接続試行が実行されません。詳細は、Oracle TimesTen In-Memory DatabaseリファレンスのTTC_REDIRECTを参照してください。
TTC_NoReconnectOnFailoverクライアント接続属性を使用して、フェイルオーバー後にTimesTenが再接続するかどうかを定義します。デフォルトは0で、TimesTenが再接続を試行する必要があることを示します。これを1に設定すると、TimesTenは通常のクライアント・フェイルオーバーを実行しますが、再接続しません。このことは、アプリケーションが独自の接続プーリングを実行したり、フェイルオーバー後に自動的にデータベースへの再接続を試行する場合に役立ちます。詳細は、Oracle TimesTen In-Memory DatabaseリファレンスのTTC_NoReconnectOnFailoverを参照してください。
一般的に、ほとんどの接続の失敗はソフトウェア障害です。別のデータ・インスタンスへの再接続には時間がかかり、この間、クライアント・フェイルオーバー・プロセスが完了するまで接続は使用できません。クライアント・フェイルオーバーの処理中に接続を使用しようとすると、システム固有のエラーが生成されます。発生する可能性があるシステム固有のエラーについては、Oracle TimesTen In-Memory Database Java開発者ガイドの自動クライアント・フェイルオーバーのJDBCサポート、またはOracle TimesTen In-Memory Database C開発者ガイドのアプリケーションでの自動クライアント・フェイルオーバーの使用を参照してください。
アプリケーション内の操作に対してシステム固有のエラーを受け取った場合、アプリケーションではすべてのリカバリ操作を、後続の各試行が短い間隔で行われるループ内に配置する必要があります。このとき、試行の合計回数が制限されます。試行回数を制限しないと、クライアント・フェイルオーバー処理が正常に完了しなかった場合に、アプリケーションがハングしたように見えることがあります。自動クライアント・フェイルオーバーのためにアプリケーション内に再試行ブロックを作成する方法の例は、Oracle TimesTen In-Memory Database Java開発者ガイドのフェイルオーバー発生時のアプリケーションのアクション、またはOracle TimesTen In-Memory Database C開発者ガイドのフェイルオーバー発生時のアプリケーションのアクションを参照してください。
クライアント接続が失敗する可能性がある原因の1つは、ケーブルの切断やホストのハングまたはクラッシュなどのネットワーク障害です。クライアント接続が失われると、クライアント接続フェイルオーバーが開始されます。ただし、TCP接続が開始されている場合は、接続に対してTCPキープ・アライブ・パラメータを構成し、接続障害を確実かつ迅速に検出できるようにすることができます。
|
ノート: TimesTen ClientおよびTimesTen Serverを使用して完了されるネットワーク操作の時間の上限を設定する、TTC_Timeout属性を設定して、接続に問題があることを検出することもできます。また、TTC_Timeout属性では、その秒数をすぎるとタイムアウトする、TimesTen Clientアプリケーションが対応するTimesTen Serverプロセスからの結果を待機する最大秒数も指定します。
データベース操作によっては、予期せず この属性の詳細は、Oracle TimesTen In-Memory DatabaseリファレンスのTTC_Timeoutを参照してください。 |
次のパラメータを使用して、接続ごとにキープ・アライブ設定を制御できます。
TTC_TCP_KEEPALIVE_TIME_MS: 最後のデータ・パケット送信から最初のプローブまでの時間(ミリ秒単位)。デフォルトは10000ミリ秒です。
|
ノート: Linuxクライアント・プラットフォームでは、TTC_TCP_KEEPALIVE_TIME_MSの値の最後の3桁を切り捨てて、この値を秒単位に変換します。そのため、2500ミリ秒に設定した場合は、2.5秒ではなく2秒になります。 |
TTC_TCP_KEEPALIVE_INTVL_MS: 連続するプローブ間の時間間隔(ミリ秒単位)。デフォルトは10000ミリ秒です。
TTC_TCP_KEEPALIVE_PROBES: 接続が失敗とみなされ、クライアントに通知するまでに送信される確認応答のないプローブの数。デフォルトは、2つの確認応答のないプローブに設定されます。
デフォルト設定のままにした場合、TimesTen Scaleoutでは、10秒後に最初のプローブを送信します(TTC_TCP_KEEPALIVE_TIME_MS設定)。
応答があった場合は、接続は有効であり、TTC_TCP_KEEPALIVE_TIME_MSタイマーがリセットされます。
応答がない場合、TimesTen Scaleoutでは、この最初のプローブの後に10秒間隔で別のプローブを送信します(TTC_TCP_KEEPALIVE_INTVL_MS設定)。プローブに対して2回連続で応答がない場合、この接続は中止され、TimesTen Scaleoutによって別のデータ・インスタンスに接続がリダイレクトされます。
たとえば、クライアント/サーバー接続可能オブジェクトのTCPキープ・アライブ設定を次のように変更して、最初のプローブの待機時間を50000ミリ秒に短縮し、接続を20000ミリ秒ごとに、最大3回まで確認できるようにすることができます。
TTC_TCP_KEEPALIVE_TIME_MS=50000 TTC_TCP_KEEPALIVE_INTVL_MS=20000 TTC_TCP_KEEPALIVE_PROBES=3
これらの接続属性の詳細は、Oracle TimesTen In-Memory DatabaseリファレンスのTTC_TCP_KEEPALIVE_TIME_MS、TTC_TCP_KEEPALIVE_INTVL_MSおよびTTC_TCP_KEEPALIVE_PROBESを参照してください。
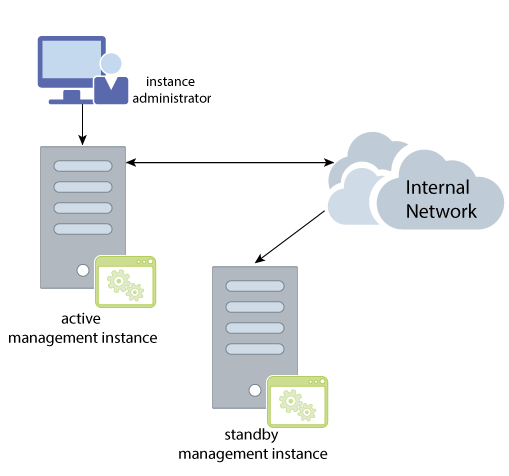
すべての管理アクティビティは、アクティブ管理インスタンスと呼ばれる単一の管理インスタンスから実行します。ただし、2つの管理インスタンスを構成し、アクティブ管理インスタンスの停止や障害が発生した場合に、スタンバイ管理インスタンスを使用できるようにすることをお薦めします。
管理インスタンスが1つのみで、それが停止した場合でも、データベースは引き続き動作します。ただし、管理インスタンスがリストアされるまでは、ほとんどの管理操作を使用できません。
グリッド内にアクティブ管理インスタンスおよびスタンバイ管理インスタンスの両方を構成し、アクティブ管理インスタンスのみが有効な場合は、この1つの管理インスタンスからグリッド全体を構成および管理できます。
両方の管理インスタンスが停止している場合は、次のようになります。
グリッド内のすべてのデータベースに引き続きアクセスできます。ただし、すべての管理操作はアクティブ管理インスタンスを介してリクエストされるため、アクティブ管理インスタンスがリストアされるまで、グリッドを管理できません。
グリッド内のデータ・インスタンスまたはその要素が停止するか、それらに障害が発生した場合、アクティブ管理インスタンスがリストアされるまで、それらはグリッドのリカバリ、再起動および再結合を実行できません。
|
ノート: 3つ目の管理インスタンスは追加できません。 |
図11-6に示すように、アクティブ管理インスタンスで使用されるすべての管理情報は、スタンバイ管理インスタンスに自動的にレプリケートされます。したがって、アクティブ管理インスタンスが停止するか、障害が発生した場合、スタンバイ管理インスタンスを新しいアクティブ管理インスタンスに昇格させ、これを使用してグリッドの管理を続行できます。
次の各項では、管理インスタンスの管理方法について説明します。
ttGridAdmin mgmtExamineコマンドを使用して両方の管理インスタンスのステータスを調べ、解決する必要がある問題があるかどうかを確認します。このコマンドは、必要に応じて、未解決の問題を修正するために実行できる修正処理を提案します。
次の例は、両方の管理インスタンスが稼働していることを示しています。
% ttGridAdmin mgmtExamine Both active and standby management instances are up. No action required. Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive ------------------------------------------------------------------------ host1 instance1 Yes Active Active 598 Up Yes host2 instance1 Yes Standby Standby 598 Up No
いずれかの管理インスタンスが停止するか、障害が発生した場合、出力には管理インスタンス・ロールがUnknownであることが示され、レプリケーション・エージェントが停止していることを示すメッセージが表示されます。出力には、管理インスタンスを再起動するために推奨されるコマンドが示されます。
% ttGridAdmin mgmtExamine Active management instance is up, but standby is down Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive Message ----- --------- --------- ------------- ---------- --- -------- --------- -------- host1 instance1 Yes Active Active 600 Up No host2 instance1 No Unknown Unknown Down No Management database is not available Recommended commands: ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttGridAdmin mgmtStandbyStart
管理インスタンスごとに、次の項目が表示されます。
HostおよびInstanceには、管理インスタンスの名前およびインスタンスが配置されているホストの名前が示されます。
Reachableには、管理インスタンスの状態を判別するために、コマンドが管理インスタンスに到達できたかどうかが示されます。
RepRole(Self)には、レプリケーション・エージェントが管理インスタンス間でデータをレプリケートするために認識している、記録されたロールが示されます(ある場合)。一方、Role(Self)には、管理インスタンスのデータベース内で認識されている、記録されたロールが示されます。この両方に同じロールが表示される必要があります。ロールが異なる場合、ttGridAdmin mgmtExamineコマンドはエラーを修正するコマンドを特定しようとします。
Seqは、管理インスタンスに対する最新の変更の順序番号です。Seq値が同じ場合、2つの管理インスタンスは同期されています。そうでない場合は、Seq値が大きいほうの管理インスタンスに最新のデータが含まれています。
RepAgentには、各管理インスタンスでレプリケーション・エージェントが実行されているかどうかが示されます。
RepActiveには、ttGridAdmin mgmtExamineコマンドによって内部的に起動されるttGridAdmin mgmtStatusコマンドによって、管理インスタンス上の管理データに対する変更が正常に行われたかどうかが示されます。
Messageには、管理インスタンスに関する詳細情報が示されます。
詳細は、Oracle TimesTen In-Memory Databaseリファレンスの管理インスタンスの確認(mgmtExamine)を参照してください。
ほとんどのttGridAdminコマンドは、アクティブ管理インスタンスを介して実行されます。ただし、アクティブ管理インスタンスのリカバリを管理するときには、スタンバイ管理インスタンスでttGridAdminコマンドを実行する必要がある場合があります。
スタンバイ管理インスタンスを起動、停止または昇格する場合は、次のようになります。
いずれの管理インスタンスでも、ttGridAdmin mgmtStandbyStopコマンドを実行できます。グリッドはスタンバイ管理インスタンスの場所を把握しており、それを停止します。
スタンバイ管理インスタンスにする管理インスタンスでttGridAdmin mgmtStandbyStartコマンドを実行する必要があります。ttGridAdmin mgmtStandbyStartコマンドでは、現行インスタンスをスタンバイ管理インスタンスにすると想定しています。
アクティブ管理インスタンスが停止している場合は、スタンバイ管理インスタンスでttGridAdmin mgmtActiveSwitchコマンドを実行して、スタンバイ管理インスタンスをアクティブ管理インスタンスに昇格させる必要があります。
スタンバイ管理インスタンスで実行する必要があるコマンドでは、ホストにログオンした後、ttGridAdminユーティリティを実行する前に、必ずttenvスクリプトを使用して環境を設定してください(初期管理インスタンスの作成を参照)。
障害の発生後、できるだけ早くアクティブ管理インスタンスを再アクティブ化して、すべてが引き続き、期待どおりに実行されることを確認する必要があります。
これはお薦めできませんが、スタンバイ管理インスタンスを用意せず、単一のアクティブ管理インスタンスでグリッドを管理できます。単一のアクティブ管理インスタンスに障害が発生してリカバリした場合、次のようにアクティブ管理インスタンスを再アクティブ化します。
ttGridAdmin mgmtExamineコマンドを使用して、アクティブ管理インスタンスとして動作している管理インスタンスが1つのみであること、およびその管理インスタンスに障害が発生したことを確認します。
% ttGridAdmin mgmtExamine The only defined management instance is down. Start it. Recommendation: define a second management instance Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive ------------------------------------------------------------------------- host1 instance1 No Unknown Unknown Down No Recommended commands: ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttDaemonAdmin -start
障害の原因を特定し、その問題を解決したら、ttGridAdmin mgmtActiveStartコマンドを実行して、アクティブ管理インスタンスを再アクティブ化します。
% ttGridAdmin mgmtActiveStart This management instance is now the active
ttGridAdmin mgmtExamineコマンドを再実行して、アクティブ管理インスタンスが稼働していることを確認します。管理インスタンスが稼働していない場合は、表示されるコマンドに従います。
アクティブ管理インスタンスに障害が発生した場合、その管理インスタンスではttGridAdminコマンドを実行できなくなります。
次のいずれかの方法で、新しいスタンバイ管理インスタンスを作成します。
host1にある障害が発生した管理インスタンスをリカバリして、新しいスタンバイ管理インスタンスとして稼働させます。こうすると、新しいアクティブ管理インスタンスにより、すべての管理情報が新しいスタンバイ管理インスタンスにレプリケートされます。
アクティブ管理インスタンスに発生した障害が永続的である場合は、その管理インスタンスを削除して、新しいスタンバイ管理インスタンスを作成します。
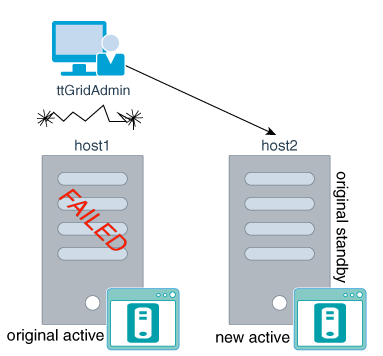
たとえば、ご使用の環境に2つの管理インスタンスがあり、アクティブ管理インスタンスはhost1に、スタンバイ管理インスタンスhost2にあるとします。ここで、host1のアクティブ管理インスタンスに障害が発生した場合、その管理インスタンスではttGridAdminコマンドを実行できなくなります。図11-7に示すように、host2のスタンバイ管理インスタンスを昇格させて、新しいアクティブ管理インスタンスにする必要があります。
スタンバイ管理インスタンスが存在するhost2ホストにログインし、そのホストでttenvスクリプトを使用して環境を設定します(初期管理インスタンスの作成を参照)。
スタンバイ管理インスタンスでttGridAdmin mgmtActiveSwitchコマンドを実行します。TimesTenによりスタンバイ管理インスタンスが昇格され、新しいアクティブ管理インスタンスになります。これで、新しいアクティブ管理インスタンスを使用して、グリッドの管理を続行できるようになりました。
% ttGridAdmin mgmtActiveSwitch This is now the active management instance
ttGridAdmin mgmtExamineコマンドを使用して、古いスタンバイ管理インスタンスが新しいアクティブ管理インスタンスになっていることを確認します。
% ttGridAdmin mgmtExamine Active management instance is up, but standby is down Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive ------------------------------------------------------------------------- host2 instance1 Yes Active Active 622 Up Yes host1 instance1 No Unknown Unknown Down No Management database is not available Recommended commands: ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttGridAdmin mgmtStandbyStart
新しいアクティブ管理インスタンスがリクエストを処理し始めたら、次のいずれかの方法により、新しいスタンバイ管理インスタンスが作成されていることを確認します。
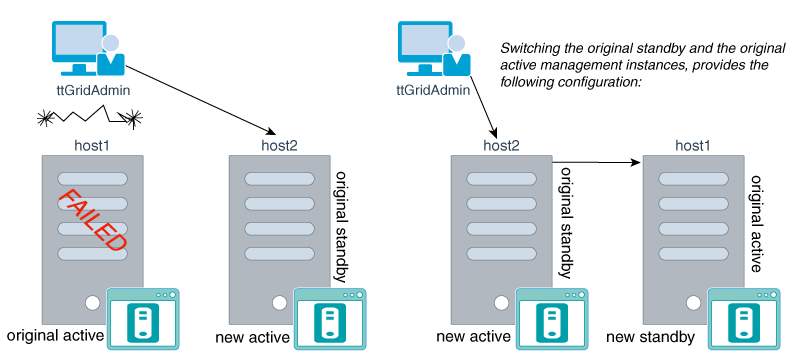
障害が発生したアクティブ管理インスタンスがリカバリ可能な場合は、次のタスクを実行する必要があります。
図11-8に示すように、障害が発生した管理インスタンスをリカバリできる場合は、古いアクティブ管理インスタンスが存在していた、障害が発生したホストを再度稼働させます。次に、このホストでttGridAdmin mgmtStandbyStartコマンドを実行すると、その管理インスタンスが新しいスタンバイ管理インスタンスとして再開されます。さらに、新しいアクティブ管理インスタンスとスタンバイ管理インスタンスの間のアクティブ・スタンバイ構成が再作成され、アクティブ管理インスタンス上のすべての管理情報がスタンバイ管理インスタンスにレプリケートされます。
% ttGridAdmin mgmtStandbyStart Standby management instance started
ttGridAdmin mgmtExamineコマンドを使用して、アクティブ管理インスタンスとスタンバイ管理インスタンスが、新しいロールで予期したとおりに動作していることを確認します。
% ttGridAdmin mgmtExamine Both active and standby management instances are up. No action required. Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive ------------------------------------------------------------------------- host2 instance1 Yes Active Active 603 Up Yes host1 instance1 Yes Standby Standby 603 Up No
障害が発生したアクティブ管理インスタンスに永続的な障害がある場合は、次のタスクを実行する必要があります。
ttGridAdmin instanceDeleteコマンドを使用して、永続的な障害が発生したアクティブ管理インスタンスをモデルから削除します。
% ttGridAdmin instanceDelete host1.instance1 Instance instance1 on Host host1 deleted from Model
|
ノート: 障害が発生したアクティブ管理インスタンスが存在していたホストに他のインスタンスがない場合は、ホストおよびインストールを削除することをお薦めします。 |
対応するホストおよびインストールとともに、新しいスタンバイ管理インスタンスをモデルに追加します。
% ttGridAdmin hostCreate host9 -address host9.example.com Host host9 created in Model % ttGridAdmin installationCreate -host host9 -location /timesten/host9/installation1 Installation installation1 on Host host9 created in Model % ttGridAdmin instanceCreate -host host9 -location /timesten/host9 -type management Instance instance1 on Host host9 created in Model
ttGridAdmin modelApplyコマンドを実行して、構成の変更を適用して障害が発生したアクティブ管理インスタンスを削除し、新しいスタンバイ管理インスタンスをグリッドに追加します。
% ttGridAdmin modelApply Copying Model.........................................................OK Exporting Model Version 2.............................................OK Unconfiguring standby management instance.............................OK Marking objects 'Pending Deletion'....................................OK Stop any Instances that are 'Pending Deletion'........................OK Deleting any Instances that are 'Pending Deletion'....................OK Deleting any Hosts that are no longer in use..........................OK Verifying Installations...............................................OK Creating any missing Installations....................................OK Creating any missing Instances........................................OK Adding new Objects to Grid State......................................OK Configuring grid authentication.......................................OK Pushing new configuration files to each Instance......................OK Making Model Version 2 current........................................OK Making Model Version 3 writable.......................................OK Checking ssh connectivity of new Instances............................OK Starting new management instance......................................OK Configuring standby management instance...............................OK Starting new data instances...........................................OK ttGridAdmin modelApply complete
ttGridAdmin modelApplyコマンドによって、アクティブ管理インスタンスとスタンバイ管理インスタンスの間のアクティブ・スタンバイ構成が開始され、アクティブ管理インスタンス上の管理情報がスタンバイ管理インスタンスにレプリケートされます。
ttGridAdmin mgmtExamineコマンドを使用して、アクティブ管理インスタンスとスタンバイ管理インスタンスが、新しいロールで予期したとおりに動作していることを確認します。
% ttGridAdmin mgmtExamine Both active and standby management instances are up. No action required. Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive ------------------------------------------------------------------------- host2 instance1 Yes Active Active 603 Up Yes host9 instance1 Yes Standby Standby 603 Up No
次の各項で説明しているように、スタンバイ管理インスタンスを再アクティブ化する方法は、障害のタイプによって異なります。
スタンバイ管理インスタンスがリカバリされる場合は、次のようにします。
ttGridAdmin mgmtExamineコマンドを使用して、ステータスを確認します。
% ttGridAdmin mgmtExamine Active management instance is up, but standby is down Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive Message ----------------------------------------------------------------------------- host1 instance1 Yes Active Active 605 Up No host2 instance1 No Unknown Unknown Down No Management database is not available Recommended commands: ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttGridAdmin mgmtStandbyStart
スタンバイ管理インスタンスのあるホストにログインします。まだ設定していない場合は、ttenvスクリプトを使用して環境を設定します(初期管理インスタンスの作成を参照)。
障害が発生した管理インスタンスを再度稼働させたら、スタンバイ管理インスタンスのあるホストでttGridAdmin mgmtStandbyStartコマンドを実行します。
% ttGridAdmin mgmtStandbyStart Standby management instance started
このコマンドにより、スタンバイ管理インスタンスがグリッドに再統合され、アクティブ管理インスタンスとスタンバイ管理インスタンスの間のアクティブ・スタンバイ構成が開始され、アクティブ管理インスタンス上のすべての管理情報がスタンバイ管理インスタンスにレプリケートされます。
スタンバイ管理インスタンスに永続的な障害が発生した場合は、次のコマンドを実行します。
host2ホスト上の障害が発生したスタンバイ管理インスタンスを削除します。
host9ホストで、障害が発生したスタンバイ管理インスタンスの役割を引き継ぐ新しいスタンバイ管理インスタンスを作成します。次に、アクティブ管理インスタンスによって管理情報が新しいスタンバイ管理インスタンスにレプリケートされます。
ttGridAdmin instanceDeleteコマンドを使用して、永続的な障害が発生したスタンバイ管理インスタンスをモデルから削除します。
% ttGridAdmin instanceDelete host2.instance1 Instance instance1 on Host host2 deleted from Model
|
ノート: 障害が発生した管理インスタンスが存在していたホストに他のインスタンスがない場合は、ホストおよびインストールを削除することをお薦めします。 |
対応するホストおよびインストールとともに、新しいスタンバイ管理インスタンスをモデルに追加します。
% ttGridAdmin hostCreate host9 -address host9.example.com Host host9 created in Model % ttGridAdmin installationCreate -host host9 -location /timesten/host9/installation1 Installation installation1 on Host host9 created in Model % ttGridAdmin instanceCreate -host host9 -location /timesten/host9 -type management Instance instance1 on Host host9 created in Model
モデルに加えた変更の適用に示すとおりに、ttGridAdmin modelApplyコマンドを実行して、構成の変更を適用して障害が発生したスタンバイ管理インスタンスを削除し、新しいスタンバイ管理インスタンスをグリッドに追加します。
% ttGridAdmin modelApply Copying Model.........................................................OK Exporting Model Version 9.............................................OK Unconfiguring standby management instance.............................OK Marking objects 'Pending Deletion'....................................OK Stop any Instances that are 'Pending Deletion'........................OK Deleting any Instances that are 'Pending Deletion'....................OK Deleting any Hosts that are no longer in use..........................OK Verifying Installations...............................................OK Creating any missing Instances........................................OK Adding new Objects to Grid State......................................OK Configuring grid authentication.......................................OK Pushing new configuration files to each Instance......................OK Making Model Version 9 current........................................OK Making Model Version 10 writable......................................OK Checking ssh connectivity of new Instances............................OK Starting new management instance......................................OK Configuring standby management instance...............................OK Starting new data instances...........................................OK ttGridAdmin modelApply complete
ttGridAdmin modelApplyコマンドによって、アクティブ管理インスタンスとスタンバイ管理インスタンスの間のアクティブ・スタンバイ構成が開始され、アクティブ管理インスタンス上の管理情報がスタンバイ管理インスタンスにレプリケートされます。
グリッドの全機能を取り戻し、アクティブ管理インスタンスからグリッドを管理できるようにするには、管理インスタンスを再起動する必要があります。
両方の管理インスタンスが停止している場合は、どちらの管理インスタンスを新しいアクティブ管理インスタンスにするかを決定するために、どちらの管理インスタンスに最新の変更があるかを確認する必要があります。
|
ノート: 両方の管理インスタンスで永続的な障害が発生した場合は、Oracleサポートに連絡してください。 |
次に、両方の管理インスタンスが停止している場合に実行する手順について説明します。
両方の管理インスタンスを再度稼働させることができる場合は、次の手順を実行します。
いずれかの管理インスタンスでttGridAdmin mgmtExamineコマンドを実行し、どちらをアクティブ管理インスタンスにするのが適切かを確認します。ttGridAdmin mgmtExamineコマンドでは、両方の管理インスタンスを評価し、より多くの管理データを持つ管理インスタンスに最大の順序番号を出力します。アクティブ管理インスタンスとして再アクティブ化する必要があるのは、この管理インスタンスです。
% ttGridAdmin mgmtExamine One or more management instance is down. Start them and run mgmtExamine again. Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive Message ------------------------------------------------------------------------------ host1 instance1 No Unknown Unknown Down No Management database is not available host2 instance1 No Unknown Unknown Down No Management database is not available Recommended commands: ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttDaemonAdmin -start -force ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttDaemonAdmin -start -force sleep 30 /timesten/host1/instance1/bin/ttenv ttGridAdmin mgmtExamine
ttGridAdmin mgmtExamineコマンドにより示される推奨コマンドを実行します。この例のコマンドを実行すると、各管理インスタンスのデーモンが再起動されます。
% ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttDaemonAdmin -start -force TimesTen Daemon (PID: 3858, port: 11000) startup OK. % ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttDaemonAdmin -start -force TimesTen Daemon (PID: 4052, port: 12000) startup OK.
ttGridAdmin mgmtExamineコマンドを再実行して、両方の管理インスタンスが稼働していることを確認します。いずれかの管理インスタンスが稼働していない場合は、ttGridAdmin mgmtExamineコマンドから、実行する別のコマンドが提示されることがあります。
この例では、ttGridAdmin mgmtExamineコマンドの2回目の実行で、管理インスタンスが稼働していないことが示されます。したがって、この例では、次の手順を実行するようにコマンドから要求されます。
両方の管理インスタンスのデータ・インスタンスのメイン・デーモンを停止します。
ttGridAdmin mgmtExamineコマンドによって示された順序番号が大きいほうの管理インスタンスで、ttGridAdmin mgmtActiveStartコマンドを実行します。これにより、アクティブ管理インスタンスが再アクティブ化されます。
スタンバイ管理インスタンスとして機能させる管理インスタンスで、ttGridAdmin mgmtStandbyStartコマンドを実行します。このコマンドにより、TimesTen Scaleoutで他の管理インスタンスがスタンバイ管理インスタンスとして割り当てられ、アクティブ管理インスタンスとスタンバイ管理インスタンスの間のアクティブ・スタンバイ構成が開始され、アクティブ管理インスタンス上の管理情報がスタンバイ管理インスタンスと同期されます。
% ttGridAdmin mgmtExamine Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive Message ------------------------------------------------------------------------ host1 instance1 Yes Active Active 581 Down No host2 instance1 Yes Standby Standby 567 Down No Recommended commands: ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttDaemonAdmin -stop ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttDaemonAdmin -stop sleep 30 ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttGridAdmin mgmtActiveStart sleep 30 ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttGridAdmin mgmtStandbyStart
次のコマンドを実行すると、アクティブ管理インスタンスおよびスタンバイ管理インスタンスの両方が再起動されます。
% ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttDaemonAdmin -stop TimesTen Daemon (PID: 3858, port: 11000) stopped. % ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttDaemonAdmin -stop TimesTen Daemon (PID: 3859, port: 12000) stopped. % ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host1.example.com /timesten/host1/instance1/bin/ttenv ttGridAdmin mgmtActiveStart This management instance is now the active % ssh -o StrictHostKeyChecking=yes -o PasswordAuthentication=no -x host2.example.com /timesten/host2/instance1/bin/ttenv ttGridAdmin mgmtStandbyStart Standby management instance started
両方の管理インスタンスが稼働していることを示すメッセージを受信するまで、ttGridAdmin mgmtExamineコマンドの再実行を続けます。
% ttGridAdmin mgmtExamine
Both active and standby management instances are up. No action required.
Host Instance Reachable RepRole(Self) Role(Self) Seq RepAgent RepActive Message
----------------------------------------------------------------------
host1 instance1 Yes Active Active 567 Up Yes
host2 instance1 Yes Standby Standby 567 Up No
スタンバイ管理インスタンスが停止していることに気付いたら、できるだけ早くスタンバイ管理インスタンスを再作成することが重要です。そうしない場合、さらにアクティブ管理インスタンスも停止した場合に、グリッド・トポロジが以前とは大幅に異なるものになる可能性があります。つまり、アクティブ管理インスタンスが停止したか、障害が発生し、最適なオプションはスタンバイ管理インスタンスを再度稼働させることであるが、スタンバイ管理インスタンスがある程度の期間停止している場合、次のような現象により間違ったグリッド・トポロジが生成される可能性があります。
最近グリッドにインスタンスを追加した場合、それらが失われる可能性があります。
最近グリッドからインスタンスを削除した場合、削除が取り消される可能性があります。
最近データベースを作成した場合、それらが削除される可能性があります。
最近データベースを破棄した場合、それらが再作成される可能性があります。
1つの管理インスタンスのみを再度稼働させることができる場合は、このインスタンスをアクティブ管理インスタンスとして再アクティブ化します。次の例では、host2ホスト上の管理インスタンスが停止しており、host1ホスト上の管理インスタンスを再度稼働させることができたと仮定しています。
host1上の管理インスタンスで、ttGridAdmin mgmtActiveStartコマンドを実行します。これにより、アクティブ管理インスタンスとして再アクティブ化されます。
% ttGridAdmin mgmtActiveStart This management instance is now the active
ttGridAdmin instanceDeleteコマンドを使用して、永続的な障害が発生したスタンバイ管理インスタンスをモデルから削除します。
% ttGridAdmin instanceDelete host2.instance1 Instance instance1 on Host host2 deleted from Model
|
ノート: 停止している管理インスタンスが存在していたホストに他のインスタンスがない場合は、ホストおよびインストールを削除することをお薦めします。 |
対応するホストおよびインストールとともに、新しいスタンバイ管理インスタンスをモデルに追加します。
% ttGridAdmin hostCreate host9 -address host9.example.com Host host9 created in Model % ttGridAdmin installationCreate -host host9 -location /timesten/host9/installation1 Installation installation1 on Host host9 created in Model % ttGridAdmin instanceCreate -host host9 -location /timesten/host9 -type management Instance instance1 on Host host9 created in Model
ttGridAdmin modelApplyコマンドを実行して、構成の変更を適用して障害が発生したスタンバイ管理インスタンスを削除し、新しいスタンバイ管理インスタンスをグリッドに追加します。
% ttGridAdmin modelApply Copying Model.........................................................OK Exporting Model Version 9.............................................OK Unconfiguring standby management instance.............................OK Marking objects 'Pending Deletion'....................................OK Stop any Instances that are 'Pending Deletion'........................OK Deleting any Instances that are 'Pending Deletion'....................OK Deleting any Hosts that are no longer in use..........................OK Verifying Installations...............................................OK Creating any missing Instances........................................OK Adding new Objects to Grid State......................................OK Configuring grid authentication.......................................OK Pushing new configuration files to each Instance......................OK Making Model Version 9 current........................................OK Making Model Version 10 writable......................................OK Checking ssh connectivity of new Instances............................OK Starting new management instance......................................OK Configuring standby management instance...............................OK Starting new data instances...........................................OK ttGridAdmin modelApply complete
ttGridAdmin modelApplyコマンドによって、アクティブ管理インスタンスとスタンバイ管理インスタンスの間のアクティブ・スタンバイ構成が開始され、アクティブ管理インスタンス上の管理情報がスタンバイ管理インスタンスにレプリケートされます。
チャネル作成のタイムアウトを設定して、パフォーマンスを向上させます。
各要素は、チャネル経由で他のすべての要素と通信します。ただし、ソフトウェアの問題やネットワーク障害が原因で、要素間のチャネルの作成リクエストがハングした場合は、すべてのチャネル作成リクエストがブロックされる可能性があります。要素の通信にはオープン・チャネルが必要なため、チャネル作成プロセス内でハングを検出する必要があります。
ChannelCreateTimeout一般接続属性を使用して、リモート要素に対するチャネル作成リクエストへのレスポンスを待機するタイムアウト(ミリ秒単位)を設定します。詳細は、Oracle TimesTen In-Memory Databaseリファレンスの「ChannelCreateTimeout」を参照してください。