検索機能の管理
この章では、Oracle TextをOracle WebCenter Contentのプライマリ・フルテキスト検索エンジンとして使用するようにOracleTextSearch機能を構成する方法、Oracle Search Enterprise Search (SES)を使用するようにコンテンツ・サーバーを構成する方法、およびフルテキスト・データベース検索を構成する方法について説明します。
また、この章では、再構築時間が大幅に短縮されたElasticsearchの構成方法についても説明します
この章の構成は、次のとおりです。
OracleTextSearchの管理
Oracle Database 12cでOracleTextSearch機能を使用するライセンスがある場合、Oracle Text製品をWebCenter Contentのプライマリ・フルテキスト検索エンジンとして使用するようにOracleTextSearchを構成できます。Oracle Textは最新の索引付け機能を提供し、Oracle Secure Enterprise Search (Oracle SES)の基礎となる検索機能を提供します。ただし、Oracle Textには独自の問合せ構文があり、一般的なエンドユーザーではなくアプリケーションまたは情報の専門家による使用を対象としています。
OracleTextSearchにより、管理者は、特定のメタデータ・フィールドを検索索引用に最適化するように指定したり、追加のフィールドをカスタマイズできます。また、この機能を使用すると、索引再構築と索引の最適化を迅速に実行することもできます。
この項の内容は次のとおりです。
OracleTextSearchを使用する上での考慮事項
OracleTextSearch機能の使用を検討する上で重要な事項を、次に示します。
-
WebCenter Contentバージョン12cでは、Oracle Textがサポートするすべての言語がサポートされます。OracleTextSearchは、様々な言語の様々なドキュメント・フォーマットのコンテンツをフィルタリングおよび抽出できます。Microsoft Officeファイル形式、Adobe PDF、HTML、XMLなど、多数のドキュメント・フォーマットがサポートされています。zip、zipxおよびgzなどのアーカイブおよび圧縮ファイル形式もサポートします。検索結果は、未フォーマットのテキスト、検索語を強調表示するHTML、元のドキュメント・フォーマットなど、様々なフォーマットでレンダリングできます。
-
Oracle Textは、Oracle Database 12cで実行されます。コンテンツ・サーバーのデータベースは、Oracle Database 12c、Microsoft SQL Server、またはOracle WebCenter Content 12cの動作保証マトリックスに記載されている他のデータベースにすることができます。ただし、システム・データベースがOracle Database 12cでない場合は、OracleTextSearchのための外部プロバイダを構成する必要があります。外部プロバイダの詳細は、「コンテンツ・サーバー用のOracleTextSearchの構成」を参照してください。
-
OracleTextSearchを使用する場合は、Oracle Databaseバージョン11.1.0.7.0以上が必要です。
-
OracleTextSearchで最適化されたフィールドはSDATAフィールドとして作成され、最大249文字に制限されます。この制限はOracle Databaseによって適用され、OracleTextSearchコンポーネントによりコンテンツ・サーバーに反映されます。デフォルトのSDATAフィールドには、dDocName、dDocTitle、dDocTypeおよびdSecurityGroupがあります。SDATAフィールドの合計数は、32フィールドに制限されます。
-
WebCenter Contentには各種データベース(Oracle、Microsoft SQL Server、IBM DB2)を使用する多数の検索オプションが備わっていますが、デフォルトでは、検索索引として機能するデータベースはWebCenter Contentでメタデータやその他の構成情報(ユーザー、セキュリティ・グループなど)の管理に使用されるのと同じシステム・データベースです。OracleTextSearch機能は、Oracle TextをWebCenter ContentのOracle Database 12c上の別の検索コレクション・インスタンスとして有効にすることにより、検索コレクションが別のコンピュータ上に存在し、プロセッサやメモリーのためにWebCenter Contentと競合しないようにできます。その結果、索引付けおよび検索のレスポンス時間を短縮できます。
-
OracleTextSearchコレクション・インスタンスは、WebCenter Contentインストールとは異なるプラットフォームにインストールできます。
-
管理者またはコンポーネントによってOracleTextSearch機能が構成および実行され、メタデータ・フィールドがコンテンツ・サーバー・インスタンスにプッシュされる場合(コンテンツ・サーバー・インスタンスの再起動が必要です)、新規メタデータ・フィールドを使用してコンテンツをコンテンツ・サーバー・インスタンスにチェックインする前に、OracleTextSearch索引を再構築する必要があります。
Oracle Textの機能と利点
この項の内容は次のとおりです。
索引付けおよび問合せの速度と方法
Oracle Textの使用により、WebCenter Contentの索引付けの速度が大幅に向上します。Oracle Textの索引付けは、トランザクションです。コンテンツ・サーバーは、ドキュメントのバッチをOracle Textに送信し、バッチをコミットしてから、Oracle Textインデクサを起動します。コンテンツ・サーバーには、索引付けに失敗したドキュメントが通知され、それらのドキュメントのみが索引付けのために再送信されます。追加の機能には、コンテンツ・サーバー・インスタンスに5,000ドキュメントが追加されるたびに実行される自動の高速最適化と、50,000ドキュメントごとにまたはリポジトリが20%増加するたびに実行される完全最適化があります。コンテンツ・サーバーのメタデータのみの検索問合せにOracle Textを使用すると、パフォーマンスが下がる場合があります。
WebCenter Contentでは、いくつかの最新のOracle Text機能を使用しています。たとえば、コンテンツ・サーバーでは、検索速度を上げるために、テキスト情報フィールドごとに新しい検索索引ゾーンが自動的に作成されます。情報ゾーンを使用すると、コンテンツ・サーバーでデータがフルテキスト・データであるかのようにデータを問い合せることができます。テキストベースの情報フィールド(テキスト、ロング・テキストおよびメモ)すべてが、別々のゾーンとして自動的に追加されます。テキスト情報フィールド用に作成されるゾーンに加えて、コンテンツ・サーバーにはIdcContentという追加ゾーンも用意されており、これにより、カスタム・コンポーネント、Oracle WebCenter Content: Inbound Refineryのコンポーネント、アプリケーションまたはユーザーは、フルテキスト・メタデータ・フィールドとして索引付けされるタグ付きXMLコンテンツを作成できます。
WebCenter Contentでは、Oracle TextのSDATAセクション機能を使用して、重要なテキスト、日付および整数の各フィールドに索引を設定し、これらのフィールドを最適化フィールドとして定義します。SDATAセクションはOracle Textエンジンが管理する独立したXML構造で、この構造によって、エンジンはデータと整数の範囲が含まれているリクエストに対して迅速に応答できます。コンテンツ・サーバーでは最大で32の最適化フィールドを保持でき、これらの最適化フィールドには、データ、整数、Content Serverの標準フィールド(dInDate、dOutDate、最適化対象として選択したフィールドなど)が格納されます。最適化されたすべてのフィールドはSDATAフィールドで、デフォルトではdDocName、dDocTitle、dDocTypeおよびdSecurityGroupが含まれます。
ノート:
Oracle Textに定義された一連の最適化フィールドを変更する場合、定義できる最大最適化フィールド数は32です。
索引付けのエラーを防ぐために、存在しないメタデータ・フィールドを構成マネージャのDrillDownFieldsパラメータに追加しないでください。また、SDATAセクションまたはDrillDownFieldsパラメータにメモ・フィールドを追加しないでください。『Oracle WebCenter Contentのマネージメント』の管理ツールの理解に関する項を参照してください。
マルチスレッド索引付け
MultiThreadIndexerコンポーネントは、(シングルスレッド・プロセスであり、クラスタ内に構成されたサーバーの1つでのみ実行されるように特別に設計されている)既存のレガシー・インデクサにある程度の並列性を導入することで、索引付けのスループットを向上させるように設計されています。
MultiThreadIndexerコンポーネントの設計は、現在、ORACLETEXTSEARCH (OTS)検索エンジンでの使用のみに制限されており、テキスト抽出とOTS索引作成をパラレルに実行できます。この機能はエンド・ユーザーに対してシームレスで透過的であり、UIを含むすべての機能は同じままです。
新しいMultiThreadIndexer機能を使用するには:
- MultiThreadIndexerコンポーネントを有効にします。
-
config.cfgファイルで次の構成が設定されていることを確認します:
SearchIndexerEngineName=ORACLETEXTSEARCH EnableMultiThreadIndexer=true - WebCenter Content Serverを再起動します。
ノート:
- ForceMetadataOnlyIndexing構成変数をtrueに設定すると、構成されている検索エンジンに関係なく、メタデータのみの索引付けを実行するようにインデクサに強制できます。そのため、OracleTextSearchやOpenSearchなどの全文ベースの検索エンジンを使用するが、全文索引付け機能を必要としないシナリオにおいては、索引付けのパフォーマンスが向上します。
- ValidateMaxIndexableFileSizeEarly構成変数をtrueに設定すると、索引付け中に、アップロードされたドキュメントのファイル・サイズが構成されたMaxIndexableFileSize制限を上回っているかどうかを確認および検証できます。デフォルト値は10MBです。ファイル・サイズがMaxIndexableFileSizeの制限を上回っているドキュメントにはテキスト抽出プロセスが適用されず、ファイル・システムにダウンロードされないため、索引付けのパフォーマンスが向上します。
高速再構築
OracleTextSearchでは、リポジトリ・マネージャ・アプリケーションの「インデクサ」タブで「コレクション再構築サイクル」ウィンドウを使用する際、「インデクサの再構築」ウィンドウが用意されています。高速再構築機能により、検索エンジンは、コレクション全体を再構築することなく、検索コレクションに新しい情報を追加できます。高速再構築は次の場合に必要です。
-
情報フィールドの追加または削除
-
任意の最適化フィールドの変更
-
情報フィールドの最適化フィールドへの変更
高速再構築により、すべての情報(メタデータとフルテキスト)に索引が付け直されるわけではありません。コレクション全体に変更を追加し、更新します。高速再構築サイクル中にコンテンツ・サーバーの検索機能に対する影響はありません。
高速再構築の実行については、「高速再構築の実行」を参照してください。
問合せ構文
Universal Query Syntaxで定義されている問合せがサポートされており、通常変更は不要です。これには、ユーザーが保存した問合せ、カスタム・コンポーネントで定義された問合せ、Site Studioのページで定義された問合せが含まれます。
OracleTextSearchの演算子
Oracle Textでは、次のデフォルトがサポートされています。
-
CONTAINS
-
MATCHES
-
Has Word Prefix
-
日付および整数の範囲検索
検索シソーラス
stemやRelated Termなどの特定の問合せは、Oracle Textシソーラスを使用すると、効果が上がる場合があります。Oracle Textを使用すると、語や句のシノニムや階層上の関係を定義する、大/小文字の区別ありまたは大/小文字の区別なしのシソーラスを作成できます。その結果、問合せを拡張してシソーラスに定義されている類義語または関連語を含めることで、関連テキストを含むドキュメントを検索し、取得できます。たとえば、特定の製品名、関連モデル、関連機能などをシソーラスに入れることができます。
-
デフォルトのシソーラス: 問合せでシソーラスの名前を指定しないと、デフォルトでは、シソーラスの演算子はDEFAULTというシソーラスを使用します。ただし、Oracle TextにはDEFAULTシソーラスは用意されていません。
その結果、シソーラス演算子にデフォルトのシソーラスを使用する場合は、DEFAULTという名前のシソーラスを作成する必要があります。このシソーラスの作成には、Oracle Textがサポートしている次のシソーラス作成方法を使用できます。
-
CTX_THES.CREATE_THESAURUS(PL/SQL) -
ctxloadユーティリティ
-
-
提供されるシソーラス: Oracle Textではデフォルトのシソーラスはありませんが、
ctxloadによりロードするファイル形式のシソーラスが提供されており、汎用の英語シソーラスの作成に使用できます。シソーラス・ロード・ファイルは、Oracle Text用のデフォルト・シソーラスの作成に使用でき、また特定のサブジェクトや、サブジェクトの範囲にあわせたシソーラスの作成の基礎として使用することもできます。
ノート:
ctxloadおよびCTX_THESパッケージの使用方法についてさらに学習するには、『Oracle Textリファレンス』および『Oracle Textアプリケーション開発者ガイド』の「Oracle Textでのシソーラスの使用」を参照してください。
大/小文字の区別およびステミングのルール
コンテンツ・サーバーでは、問合せは自動的に大文字と小文字を区別しないものとして実行されます。デフォルトでは、フルテキストおよびテキスト・フィールド検索の問合せは、すべて大文字と小文字の区別はありません。コンテンツ・サーバーでは、最適化フィールドとして格納されている情報に対する大文字と小文字を区別しない検索問合せも処理します。
ステミングはOracle Textの機能で、stem ($)演算子を使用して、問合せ語句と同じ言語学上の語根を持つ語句を検索します(構文は$term)。たとえば、$singと入力すると、sang sung singを含むように検索が拡張されます。ステミング・ルールは、複数形、動詞などの検索アカウントを設定するときに使用できます。コンテンツ・サーバーは、デフォルトではOracle Textにステミング・ルールを適用しませんが、stem ($)演算子を使用することで、ステミング・ルールのセットを作成できます。ステミング・ルールを実装する方法には他に、searchindexerrules構成ファイル(カスタム・コンポーネントが必要)での標準問合せ定義の変更や、Oracle Textエンジン(Oracle Database)での構成の変更があります。
ノート:
詳細は、『Oracle Textリファレンス』の「Oracle Text CONTAINS問合せ演算子」を参照してください。
コンテンツ・サーバーでは、Oracle TextエンジンでWORLD_LEXER機能を使用することで、英語以外の言語のコンテンツを処理します。これにより、Oracle Textは自動的に言語を識別し、適切なトークン化ルールを適用できます。
検索結果データのクラスタリング
コンテンツ・サーバーでは、Oracle Text検索機能を使用して、検索結果リストについての追加情報を取得し、「検索結果」ページの新しいメニュー・バーに表示しますこの情報には、特定の情報フィールドの特定の値にどれだけのドキュメントが添付されているかが要約されています。コンテンツ・サーバーでは、最大4つの情報フィールドのクラスタリングがサポートされています(デフォルトのフィールドは、「セキュリティ・グループ」と「ドキュメント・タイプ」)。
これは、多くのアイテムを返す問合せの場合に役に立ちます。たとえば、結果セットに、「Public」セキュリティ・グループに属する100のドキュメント、「Sales」グループに属する75のドキュメント、および「Marketing」グループに属する25のドキュメントを含む、200のコンテンツ・アイテムが含まれているとします。「セキュリティ・グループ」のメニュー・オプションには、値リストと、各値に属するドキュメント数が表示されます。メニューから値(「Public」、「Sales」、「Marketing」)の1つを選択すると、その値に属するドキュメントのみが結果セットのリストに示されます。
スニペット
コンテンツ・サーバーでは、使用される文脈での検索語の出現を示すために、検索結果の一部としてドキュメントのスニペットを取得できます。この機能はデフォルトで無効です。この機能を有効にするには、config.cfgファイルで次の構成エントリを設定します。ただし、検索問合せのパフォーマンスに影響することがあります。
OracleTextDisableSearchSnippet=falseその他の変更
Oracle Textの使用によって生じるその他の変更点は次のとおりです。
-
XMLコンテンツには、自動的に索引が付けられます。
-
「検索」ユーザー・インタフェースには、検索演算子オプションとして「Substring」が削除されている以外に目に見える変更はありません。デフォルトの検索演算子は、CONTAINS、MATCHESおよびHAS WORD PREFIXです。部分文字列ベースの問合せはそのまま機能します。
-
MATCHES演算子を非最適化フィールドで使用する問合せは、CONTAINS問合せと同じ動作をします。たとえば、
xDepartmentが最適化されていない場合、問合せxDepartment MATCHES 'Marketing'はxDepartment CONTAINS 'Marketing'と同じ動作をし、コンテンツ・アイテムで'Marketing Services'または'Product Marketing'のxDepartment値を持つヒットを返します。 -
関連性ランキングは、DEFINESCOREと呼ばれる演算子の使用を介してOracle Textで変更することができます。この演算子は、
SearchQueryDefinition表(Oracle Textのsearchindexerrules構成ファイル内)のOracleTextSearchのWhereClause値にコンポーネントを使用して追加できます。この演算子の詳細は、『Oracle Textリファレンス』を参照してください。 -
以前はフルテキスト検索ボックスに入力していたような複雑な問合せを、現在は「クエリー・ビルダー・フォーム」の詳細オプションに入力します。「クエリー・ビルダー・フォーム」の詳細は、『Oracle WebCenter Contentの使用』を参照してください。
-
エスケープ文字を指定する必要がある場合は、構成変数
AdditionalEscapeChars=を使用します。デフォルト設定は次のとおりです。AdditionalEscapeChars=_:#,-:#デフォルトでは、アンダースコア(_)とハイフン(-)がエスケープ文字として設定されます。
-
PDFの強調表示機能は無効になりました。
-
スペル・チェック機能は有効にできますが、Autonomy VDKの場合と同様に、カスタム・コンポーネントが必要です。
コンテンツ・サーバー用のOracleTextSearchの構成
コンテンツ・サーバーを最初にインストールするときにOracleTextSearchを指定しなかった場合、この機能を構成するには、次の手順を実行します。
-
コンテンツ・サーバー・インスタンスの
config.cfgファイルをテキスト・エディタで開きます。例:MW_HOME/user_projects/domain/servers/ucm/config/config.cfg -
次のプロパティ値を設定します。
SearchIndexerEngineName=OracleTextSearchノート:
ACLを使用しており、
UseEntitySecurity=trueがOracleTextSearchに検索エンジンとして設定されている場合、コンテンツ・サーバー・インスタンスのconfig.cfgファイルで次のコードも設定する必要があります。ZonedSecurityFields=xClbraUserList,xClbraAliasList -
システム・データベースではなく外部データ・ソースを使用する場合は、次のプロパティ設定の値
SystemDatabaseを外部データベース・プロバイダ名に変更します。IndexerDatabaseProviderName=SystemDatabaseノート:
IndexerDatabaseProviderNameの値として、SystemDatabaseではなく、別のOracle Databaseを指定できます。OracleTextSearchで使用するコンテンツ・サーバー・データベースがOracle Databaseでない場合は、OracleTextSearchのための外部プロバイダを構成する必要があります。ドライバおよび
fmwgenerictoken.jarをMW_HOME/oracle_common/modules/oracle.jdbc_11.1.1/ojdbc6dms.jarから取得します。 -
ファイルを保存します。
-
Content Serverインスタンスを再起動します。手順については、「Fusion Middleware Controlを使用したコンテンツ・サーバーまたはInbound Refineryの再起動」を参照してください。
-
検索索引を再構築します。
索引の再構築の詳細は、「検索索引の使用」を参照してください。インストール時のContent ServerおよびOracleTextSearchの構成の詳細は、『Oracle WebCenter Contentのインストールと構成』のWebCenter Content構成ページに関する項の全文検索オプションを参照してください。
最初にコンテンツ・サーバーでOracleTextSearchを使用した外部プロバイダを使用するよう構成したものの、SystemDatabaseの使用に切り替える必要がある場合は、システム・データベース・スキーマに対してcontentprocedures.sqlスクリプトを手動で実行する必要があります。このスクリプト・ファイルはWC_CONTENT_ORACLE_HOME/ucm/idc/database/oracle/admin/ディレクトリにあります。
OracleTextSearchの管理
この項の内容は次のとおりです。
最適化するフィールドの決定
最適化するフィールドを決定するときには、次のことを考慮します。
-
問合せで完全一致検索を行うか。
-
検索で照合を高速化するか。
-
検索結果をフィールド別にソートするか。
デフォルトでは、OracleTextSearch機能で、「コンテンツID」および「ドキュメント・タイトル」メタデータ・フィールドが最適化されます。
最大32フィールドを、Oracle Text Search機能で最適化フィールドとして定義できます。コンテンツ・サーバー・インスタンスでは最大で32の最適化フィールドを保持でき、これらの最適化フィールドには、データ、整数、コンテンツ・サーバーの標準フィールド(dInDate、dOutDate、最適化対象として選択したフィールドなど)が格納されます。最適化されたすべてのフィールドはSDATAフィールドで、デフォルトではdDocName、dDocTitle、dDocTypeおよびdSecurityGroupが含まれます。
整数フィールドの表示は動的で、コンテンツ・サーバー構成に依存します。
最適化フィールドの割当て/編集
メタデータの非最適化フィールドを選択し、検索のための最適化フィールドに割り当てたり、最適化フィールドを編集して非最適化にすることができます。
最適化フィールドの割当てまたは編集を行うには:
-
「管理」→「管理アプレット」を選択します。
-
「構成マネージャ」→「情報フィールド」タブ→「拡張検索のデザイン」を選択します。構成マネージャ・アプレットの詳細は、『Oracle WebCenter Contentのマネージメント』の補助メタデータ・セットのエクスポートに関する項を参照してください。
-
メタデータ・フィールドを最適化するには、「フィールドの編集」をクリックします。「metadata_fieldの詳細なオプション」ウィンドウで、「最適化されています」を選択します。
-
最適化フィールドを編集して非最適化にするには、「フィールドの編集」をクリックします。「metadata_fieldの詳細なオプション」ウィンドウで、「最適化されています」の選択を解除します。
-
フィールドの移動が完了したら、リポジトリ・マネージャで「索引の高速再構築」を使用し、検索コレクションを更新して新規および変更したフィールドを使用します。
ノート:
高速再構築は、検索コレクションの再構築が進行中の場合は機能しません。
高速再構築の実行
高速再構築機能により、検索エンジンは、コレクション全体を再構築することなく、検索コレクションに新しい情報を追加できます。高速再構築は次の場合に必要です。
-
情報フィールドの追加または削除
-
任意の最適化フィールドの変更
-
情報フィールドの最適化フィールドへの変更
高速再構築を行うには:
-
「管理」→「管理アプレット」を選択します。
-
「リポジトリ・マネージャ」→「インデクサ」タブを選択します。
-
リポジトリ・マネージャ・アプリケーションの「インデクサ」タブの「コレクション再構築サイクル」部分で、「起動」をクリックします。
「インデクサの再構築」ウィンドウが、検索索引の再構築には時間がかかることを示す警告とともに開きます。今すぐに再構築を開始しない場合は「取消」をクリックし、それ以外の場合はこの手順を続行します。
-
「インデクサの再構築」ウィンドウで、「OK」をクリックします。
検索コレクションの高速再構築が実行されます。
ノート:
検索コレクションの再構築が進行中の場合、高速再構築は実行されません。
ノート:
高速再構築プロセスでは、「全文」、「メタデータのみ」、「削除」のインデクサ・カウンタ値は作成されません。インデクサ・カウントの統計値を取得するには、コレクション全体の再構築を実行する必要があります。
検索結果で表示されるフィールドの変更
OracleTextSearch機能には、「検索結果」ページにデフォルトのメニュー・オプションが用意されています(Oracle Database構成スクリプトで設定)。
DrillDownFields=dDocType, dSecurityGroup管理者は、最適化フィールドのリストからもう1つオプションを追加し、検索結果をさらにカスタマイズできます。構成を編集して、DrillDownFieldsのリストにオプションを追加します。(この機能では、複数値オプションのリストはサポートされません。)
DrillDownfields設定に変更を加えた後には、高速再構築を実行する必要があります。
OracleTextSearchによる検索
OracleTextSearchによる検索の実行は、検索演算子オプションとして「Substring」が削除されている以外に「検索: 拡張フォーム」に目に見える変更がない点を除き、一般に同じです。デフォルトの検索演算子はCONTAINSです。部分文字列ベースの問合せはそのまま機能します。
『Oracle WebCenter Contentの使用』のOracle Text Searchによる検索に関する項を参照してください。
次の表で、デフォルトの検索演算子について説明します。
| 演算子 | 説明 | 例 |
|---|---|---|
| CONTAINS | メタデータ・フィールドで、指定した単語またはフレーズ全体を含むコンテンツ・アイテムを検索します。 これは、OracleTextSearch、またはオプションのDBSearchContainsOpSupportコンポーネントが有効化されているOracle DatabaseおよびMicrosoft SQL Serverデータベースでのみ使用可能です。 |
「タイトル」フィールドにformと入力した場合、タイトルにformという語を持つアイテムは返されますが、performanceまたはreformという語を持つアイテムは返されません。 |
| MATCHES | 指定した値と完全に一致する値がメタデータ・フィールドに含まれるアイテムを検索します。 | 「タイトル」フィールドにaddress change formと入力すると、タイトルがaddress change formと完全に一致するアイテムが返されます。最適化されていないフィールドでMATCHES演算子を使用する問合せの動作は、CONTAINS演算子を使用する問合せと同じです。 たとえば、 xDepartmentフィールドが最適化されていない場合、問合せxDepartment MATCHES 'Marketing'の動作はxDepartment CONTAINS 'Marketing'と同じで、xDepartmentの値が'Marketing Services'または'Product Marketing'であるドキュメントがあればヒットを返します。 |
| HAS WORD PREFIX | 指定した語がメタデータ・フィールドの先頭に含まれるコンテンツ・アイテムをすべて検索します。指定する値の前後にワイルドカード文字を配置しません。 | 「タイトル」フィールドにformと入力した場合、タイトルの頭の部分にformという語を持つすべてのアイテムは返されますが、タイトルがperformanceまたはreformという語で始まるアイテムは返されません。 |
ノート: CONTAINSおよびHAS WORD PREFIX演算子が使用されている場合、ワイルドカード(?および*)を使用して特殊文字をエスケープすることはできません。たとえば、Webcenter_ContentというdDocTitleがある場合、CONTAINSおよびHAS WORD PREFIX演算子を使用してWebcenter?ContentやWebcenter*Contentで検索することはできません。
メタデータ・ワイルドカードの使用
「クイック検索」フィールドを使用している場合であっても、次のワイルドカードをメタデータ検索フィールドで使用できます。
-
アスタリスク(*)は、ゼロまたは多数の文字を示します。たとえば:
-
form*は、formやformulaと一致します。 -
*ormは、formやreformと一致します。 -
*form*は、form、formula、reform、performanceと一致します。
-
-
疑問符(?)は、1つの文字を示します。たとえば:
-
form?は、formsやform1と一致しますが、formやformalとは一致しません。 -
??formは、reformと一致しますが、performとは一致しません。
-
ノート:
アスタリスク(*)または疑問符(?)をワイルドカードとして扱わずに検索する場合は、"here*"のように、検索語を引用符で囲む必要があります。OracleTextSearchの「セキュリティ・グループ」メタデータ・フィールドでは、ワイルドカード(?)は機能しません。また、アンダースコア(_)を含むメタデータ・フィールド値は、ワイルドカード(?)を含めると機能しません。
インターネット・スタイルの検索構文の使用
通常のインターネット検索エンジンで一般的な検索手法はコンテンツ・サーバーでもサポートされています。たとえば、「クイック検索」フィールドにnew productと入力すると、new <AND> productが検索され、new, productと入力すると、new <OR> productが検索されます。
この検索のスタイルを有効にするには、変数をDoMetaInternetSearch=Trueのように設定します。この検索のスタイルを無効にするには、変数をDoMetaInternetSearch=Falseのように設定します。これはデフォルトです。詳細は、『Oracle Fusion Middleware Oracle WebCenter Content構成リファレンス』のDoMetaInternetSearchに関する項を参照してください。
次の表に、一般的な文字がコンテンツ・サーバーでどのように解釈されるかを示します。
| 文字 | 解釈方法 |
|---|---|
| スペース( ) | AND |
| カンマ(,) | OR |
| マイナス(-) | NOT |
二重引用符で囲まれた句("任意の句") |
入力した句と正確に一致する句 |
次の表に、フルテキスト検索でインターネット・スタイルの構文がどのように解釈されるかの例を示します。
| 問合せ | 解釈方法 |
|---|---|
new product |
new <AND> product |
(new, product) images |
(new <OR> product) <AND> images |
new product -images |
(new <AND> product) <AND> <NOT> images |
"new product", "new images" |
"new product" <OR> "new images" |
次の表に、substring演算子を使用してタイトル・メタデータを検索する場合にインターネット・スタイルの構文がどのように解釈されるかの例を示します。
| 問合せ | 解釈方法 |
|---|---|
new product |
dDocTitle <substring> 'new' <AND> dDocTitle <substring> 'product' |
new, product |
dDocTitle <substring> 'new' <OR> dDocTitle <substring> 'product' |
new -product |
dDocTitle <substring> 'new' <AND> <NOT> 'product' |
"new product" |
dDocTitle <substring> 'new product' |
OracleTextSearch結果のスコアの調整
Oracle TextをWebCenter Contentでの検索エンジンとしてOracleTextSearchを使用する場合、スコアによる検索結果は、ドキュメントの関連性に基づきソートされます。理論上は、検索語のドキュメントに対する関連性が高ければ高いほど、受け取るスコアは高くなるはずです。実際には、検索語に基づき、あるドキュメントの重要性の、それ以外に対する関連性スコアのランク付け方法は、完全に明らかではありません。ある語がドキュメント内に特定の回数出現すると、スコアは最大値の100に到達し、上位の結果を相互に区別することは難しい場合があります。
たとえば、「vacation」という語をドキュメントのセットで検索し、7つの結果のうち6つのスコアが100であると、これらは基本的に同じランクです。多数のドキュメントのランクが同じだと、スコアによるソートはまったく意味がなくなります。
関連性によるソートに加えて、発生回数によるソートをOracle Textに伝えることもできます。発生回数によるソートは、ドキュメントのランク付けでより予測可能な結果をもたらし、多くの場合、関連性よりも意味のあるソート結果を得ることができます。
Oracle Textに発生回数によるソートを伝えるには、SearchOperatorMapリソースに対しコンポーネントを多少変更する必要があります。デフォルトでは、フルテキスト検索に使用される問合せは次のようなコードになります。
<td>(ORACLETEXTSEARCH)fullText</td>
<td>DEFINESCORE((%V), <strong>RELEVANCE * .1</strong>)</td>
<td>text</td>このリソースを上書きして、RELEVANCEのかわりにOCCURRENCEを使用するように変更します。この変更により、リソースは強制的に発生回数を使用するようになります(.1から.01へのスケールの変更にも注意してください)。
<td>(ORACLETEXTSEARCH)fullText</td>
<td>DEFINESCORE((%V),<strong> OCCURRENCE * .01</strong>)</td>
<td>text</td>前述の例と同じ検索とソート・オプションを実行すると、結果は違うものとなり、7つのドキュメントそれぞれが一意のスコアを持ちます。これにより、アイテムのランクをより明確に理解できるようになります。一般的に、あるドキュメントで検索語が他のドキュメントよりも3回多く出現すると、ユーザーが調査しようと思うドキュメントとなる可能性が高まります。
ノート:
発生回数のランクでも最大回数は100なので、ドキュメントでの検索語の発生がこの回数を超えても、スコア結果は100のままです。
サイトによっては、関連性ランクの使用が発生回数ランクよりも有用な場合もありますが、このオプションは結果に対してより適切に動作する可能性のある代替方法を提供します。
OracleTextSearchの検索結果のカスタマイズ
「検索: 拡張フォーム」を使用して検索を実行すると、「検索結果」ページには、検索結果を選択的に表示できるオプションを含む追加のメニュー・バーが表示されますこれらのオプションは、検索結果をフィルタ処理するために使用されるカテゴリを表しています。オプションは状況に応じて変化し、オプションとして返されるコンテンツ・アイテムが1つのみの場合は、図1に示すように、メニュー自体に1つの結果のみが表示されます。オプションのデフォルト・セットには、Content Type、Security GroupおよびAccountが含まれます。
ノート:
「検索結果」のOracleTextSearchメニューの2つのデフォルト・メニュー・オプションを、カスタマイズ・メニュー・オプションSecurity GroupおよびDocument Typeに置き換えることができます。

1つのオプションに対して複数のコンテンツ・アイテムが検索された場合、オプション名の横に矢印が表示されます。オプション名の上にカーソルを移動すると、そのオプションの検索結果に含まれるカテゴリのリストと各カテゴリのコンテンツ・アイテム数を示すメニューが表示されます。メニューで任意のカテゴリ名をクリックして、「検索結果」ページにそのカテゴリに一致するアイテムのみを表示するように変更できます。
図2は、Security Groupのカテゴリのリストと各カテゴリで検索されたアイテム数を示しています。

| 要素 | 説明 |
|---|---|
| カテゴリによるフィルタ | 検索結果のフィルタ処理に使用されるカテゴリ(「Content Type」、「Security Group」、「Account」など)を表示します。 |
| コンテンツ・タイプ | (デフォルト)検索結果には、コンテンツ・アイテムのタイプと、各タイプのコンテンツ・アイテムの数がリストされます。 コンテンツ・タイプ名の1つをクリックすると、そのコンテンツ・タイプに一致するアイテムのみを表示するように検索結果が変更されます。 |
| セキュリティ・グループ | (デフォルト)セキュリティ・グループのリスト、および検索結果におけるグループ別のコンテンツ・アイテム数が表示されます。セキュリティ・グループには、Administration、PublicおよびSecureがあります。 セキュリティ・グループ名の1つをクリックすると、そのセキュリティ・グループに一致するアイテムのみを表示するように検索結果が変更されます。 |
| アカウント | (デフォルト)検索結果には、アカウント・タイプと、各アカウントに割り当てられたアイテムの数がリストされます。 アカウント・タイプの1つをクリックすると、そのアカウントに一致するコンテンツ・アイテムのみを表示するように検索結果が変更されます。 |
バッチ・ロード・ファイルのレコードについて
バッチ・ロード・ファイルは、実行するアクションまたは個々のコンテンツ・アイテムに対するメタデータ(あるいはその両方)を指定する名前と値のペアのセットである、ファイル・レコードで構成されています。
ノート:
フィールド名およびパラメータは、大文字と小文字が区別されます。これらは、次の項で表示されているとおりに、バッチ・ロード・ファイルに表示される必要があります。たとえば、dDocNameは、ddocname、dDocnameまたはDDOCNAMEと同じになりません。
-
各ファイル・レコードは、
<<EOD>>(データの終了)マーカーで終了します。 -
行頭にあるポンド記号(#)に続く空白は、コメントを示します。コメント記号の後には、空白を続ける必要があります。たとえば、
# primaryFile=test.txtは正常に機能しますが、#primaryFile=test.txtはエラーが発生します。 -
次に、ファイル・レコードの例を示します。
# This is a comment Action=insert dDocName=Sample1 dDocType=Document dDocTitle=Batch Load record insert example dDocAuthor=sysadmin dSecurityGroup=Public primaryFile=links.doc dInDate=8/15/2001 <<EOD>>
Oracle Secure Enterprise Searchの管理
Oracle Secure Enterprise Search (Oracle SES) 12cにより、企業のすべての情報資産に対する安全、高品質かつ容易な検索が可能になります。Oracle SES 12cを使用するライセンスを持っている場合、Oracle SESを次のように使用するようにWebCenter Contentを構成できます。
-
OracleTextSearch機能により、Oracle SESをWebCenter Contentの外部フルテキスト検索エンジンとして使用できるようにする。Oracle SESの設定の詳細は、「Oracle SESを外部フルテキスト検索エンジンとして使用」を参照してください。
-
SESCrawlerExportコンポーネントにより、プライマリ検索エンジンとしてでなくとも、Oracle SESがコンテンツ・サーバー・インスタンスのコンテンツを検索できるようにする。SESCrawlerExportの設定の詳細は、「Oracle SESでSESCrawlerExportを使用してコンテンツ・サーバーのコンテンツを検索」を参照してください。
詳細は、クックブック: SESとUCMの設定ブログを参照してください。Oracle SESの詳細は、『Oracle Secure Enterprise Search管理者ガイド』を参照してください。
Oracle SESを外部フルテキスト検索エンジンとして使用
Oracle Secure Enterprise Search (Oracle SES) 12cをバックエンド検索エンジンとして使用するように、OracleTextSearch機能を含むWebCenter Contentを構成できます。この構成により、ユーザーは1つのファイルに対して複数のコンテンツ・サーバー・インスタンスを検索できます。
Oracle SESでは、デフォルトで10MBまでのファイルにフルテキスト索引付けが行われますが、この設定を最大ファイル・サイズ(1GB)に構成できます。
OracleTextSearchとともに使用するようにOracle SESを構成
OracleTextSearchオプションとともに使用するようにOracle SESを構成するには:
ノート:
WebCenter ContentでOracle SES以外の検索エンジンをすでに使用していて(コンテンツ・サーバーの「構成後処理」ページで設定されたエンジンなど)、その検索エンジンをOracle SESに変更する場合、新規データベース・プロバイダを作成し、そのプロバイダを使用するようOracle SESを構成する必要があります。詳細は、「Oracle SESをOracleTextSearchとともに使用するように検索エンジンを再構成」を参照してください。
-
Oracle SESのインストール後、ファイル
ORACLE_HOME/network/admin/sqlnet.oraを編集して、次の2行をコメント・アウトします:tcp.invited_nodes tcp.validate_checking -
Oracle SESが実行中の場合、シャットダウンします(中間層およびデータベース)。
*`ORACLE_HOME`*/bin/searchctl stopall -
データベースを起動します:
*`ORACLE_HOME`*/bin/searchctl start_backend -
後で使用するために、次のファイルでデータベース接続情報を見つけます。
*`ORACLE_HOME`*/search/webapp/config/search.properties -
Oracle SESに対してリポジトリ作成ユーティリティ(RCU)を実行して、OCSEARCHスキーマを作成します。OCSEARCHでは、Oracle SESでRCUによってすでに設定されているデータベースの検索部分のみが設定されます。
このスキーマを作成するには、RCUの「コンポーネントの選択」ウィンドウで「Content Server 12c - 検索のみ」を選択します。『Oracle WebCenter Contentのインストールと構成』のRCU画面への移動によるスキーマの作成に関する項を参照してください。
-
WebCenter Contentの標準インストールおよびコンテンツ・サーバーのインストールを実行します。手順については、『Oracle WebCenter Contentのインストールと構成』を参照してください。
ノート:
コンテンツ・サーバーの「構成後処理」ページでは、通常のデータベース構成が設定されるため、このステップは行わないでください。
-
Oracle WebLogic ServerインスタンスでOracle SESに接続する新規データ・ソース(WLS DataSource)を作成します。
-
Oracle WebLogic Server管理コンソールで、「サービス」メニューを使用して「JDBC」、「データ・ソース」の順に選択します。
JDBCデータ・ソースのサマリーを示すウィンドウが開きます。
-
「新規」をクリックして、「新しいデータ・ソースの作成」ウィンドウで次のアイテムの値を入力します:
名前: 新しいデータ・ソース名を入力します。
JNDI名: 新しい名前を再入力します。
データベース・タイプ: Oracleと入力します。
データベース・ドライバ: *「Oracleのインスタンス接続用ドライバ(Thin XA)」をクリックします。
-
「次」をクリックして、「トランザクション・オプション」を表示します。
-
「次」をクリックして、データベース・パラメータを入力します。ステップ4で説明したように、
search.propertiesファイルでデータベース接続情報を見つけることができます。データベース名:
sesなど、接続するデータベースの名前を入力します。ホスト名: データベース・サーバーのIPアドレスを入力します。
ポート: データベース接続用のデータベース・サーバーのポート番号を入力します。
データベース・ユーザー名: データベース・アカウントのユーザー名を入力します。これは、RCU作成プロセスで指定したSchemaOwner名です。
パスワード: データベース接続の作成に使用するデータベース・アカウントのパスワードを入力します。これは、RCU作成プロセスで指定したパスワードです。
パスワードの確認: データベース・アカウントのパスワードを再入力します。
-
「次」をクリックします。
-
「構成のテスト」をクリックします。ページ上部に
「接続テストが成功しました。」というメッセージが表示されたことを確認して、「次」をクリックします。 -
使用可能なターゲット・サーバーのリストから、新しいJDBCデータ・ソースをデプロイするターゲットContent Serverのチェック・ボックスを選択します。たとえば、ターゲットContent Serverには
UCM_server1という名前が付けられています。 -
「終了」をクリックします。
-
-
コンテンツ・サーバーの構成後処理ページで、「外部フルテキスト検索オプションの選択」」をクリックして、データ・ソース名を入力します。
-
Content Serverインスタンスを再起動します。手順については、「Fusion Middleware Controlを使用したコンテンツ・サーバーまたはInbound Refineryの再起動」を参照してください。
Oracle SESをOracleTextSearchとともに使用するように検索エンジンを再構成
WebCenter ContentでOracle SES以外の検索エンジンをすでに使用していて(コンテンツ・サーバーの「構成後処理」ページで設定されたエンジンなど)、その検索エンジンをOracle SESに変更する場合、新規データベース・プロバイダを作成し、そのプロバイダを使用するようにコンテンツ・サーバーのOracle SESを構成する必要があります。
-
Oracle SESのインストール後、ファイル
ORACLE_HOME/network/admin/sqlnet.oraを編集して、次の2行をコメント・アウトします:tcp.invited_nodes tcp.validate_checking -
Oracle SESが実行中の場合、シャットダウンします(中間層およびデータベース)。
*`ORACLE_HOME`*/bin/searchctl stopall -
データベースを起動します:
*`ORACLE_HOME`*/bin/searchctl start_backend -
後で使用するために、次のファイルでデータベース接続情報を見つけます。
*`ORACLE_HOME`*/search/webapp/config/search.properties -
Oracle SESに対してOracleリポジトリ作成ユーティリティ(RCU)を実行して、OCSEARCHスキーマを作成します。OCSEARCHでは、Oracle SESでRCUによってすでに設定されているデータベースの検索部分のみが設定されます。
このスキーマを作成するには、RCUの「コンポーネントの選択」ウィンドウで「Content Server 12c - 検索のみ」を選択します。
RCU実行の詳細は、『Oracle WebCenter Contentのインストールと構成』を参照してください。
-
コンテンツ・サーバー・インスタンスでOracle SESに接続する新規データ・ソース(WLS DataSource)を作成します。
-
Oracle WebLogic Server管理コンソールで、「サービス」メニューを使用して「JDBC」、「データ・ソース」の順に選択します。
JDBCデータ・ソースのサマリーを示すウィンドウが開きます。
-
「新規」をクリックして、「新しいデータ・ソースの作成」ウィンドウで次のアイテムの値を入力します:
名前: 新しいデータ・ソース名ExternalSearchProviderを入力します
JNDI名: 新しい名前を再入力します。
データベース・タイプ: Oracleと入力します。
データベース・ドライバ: *「Oracleのインスタンス接続用ドライバ(Thin XA)」をクリックします。
-
「次」をクリックして、「トランザクション・オプション」を表示します。
-
「次」をクリックして、データベース・パラメータを入力します。ステップ4で説明したように、
search.propertiesファイルでデータベース接続情報を見つけることができます。データベース名:
SESなど、接続するデータベースの名前を入力します。ホスト名: データベース・サーバーのIPアドレスを入力します。
ポート: データベース接続用のデータベース・サーバーのポート番号を入力します。
データベース・ユーザー名: データベース・アカウントのユーザー名を入力します。これは、RCU作成プロセスで指定したSchemaOwner名です。
パスワード: データベース接続の作成に使用するデータベース・アカウントのパスワードを入力します。これは、RCU作成プロセスで指定したパスワードです。
パスワードの確認: データベース・アカウントのパスワードを再入力します。
-
「次」をクリックします。
-
「構成のテスト」をクリックします。ページ上部に
「接続テストが成功しました。」というメッセージが表示されたことを確認して、「次」をクリックします。 -
使用可能なターゲット・サーバーのリストから、新しいJDBCデータ・ソースをデプロイするターゲットContent Serverのチェック・ボックスを選択します。たとえば、ターゲットのコンテンツ・サーバー・インスタンスを
UCM_server1などの名前にします。 -
「終了」をクリックします。
ノート:
Oracle WebLogic Serverインスタンスを再起動する必要はありません。
-
-
コンテンツ・サーバーで、次の手順に従って検索(データベース)プロバイダを変更します。
-
「管理」→「プロバイダ」を選択します。
-
新規データベース・プロバイダを作成する行で、「追加」をクリックします。
-
新しいデータベース・プロバイダの設定を入力または確認します。
プロバイダ名:
ExternalSearchProvider。プロバイダの説明:
External Database Provider。プロバイダ・クラス:
intradoc.jdbc.JdbcWorkspace接続クラス:
intradoc.jdbc.JdbcConnectionデータベース・タイプ:
ORACLEを選択します。データ・ソースの使用: このボックスを選択します。
データ・ソース:
SESなど、データ・ソースの名前を入力します。問合せのテスト:
select * from SES.IDCTEXTなど、問合せのテストを入力します接続の数: デフォルトでは、
5に設定されています。追加のストレージ・キー: デフォルトでは、
systemに設定されています。 -
「追加」をクリックします。
-
Content Serverインスタンスを再起動します。手順については、「Fusion Middleware Controlを使用したコンテンツ・サーバーまたはInbound Refineryの再起動」を参照してください。
新規データベース・プロバイダ名が、「プロバイダ」ページのリストに表示されているはずです。
-
-
「管理」、「管理サーバー」、「一般構成」の順に選択します。
-
「一般構成」の「追加の構成変数」セクションで、次の設定を入力または確認します:
SearchIndexerEngineName=OracleTextSearchIndexerDatabaseProviderName=ExternalSearchProvider -
Content Serverインスタンスを再起動します。手順については、「Fusion Middleware Controlを使用したコンテンツ・サーバーまたはInbound Refineryの再起動」を参照してください。
-
リポジトリ・マネージャ・アプレットを使用して、検索索引を再構築します。
『Oracle WebCenter Contentのマネージメント』のリポジトリ・マネージャの起動に関する項を参照してください。
Oracle SESでSESCrawlerExportを使用してコンテンツ・サーバーのコンテンツを検索
SESCrawlerExportコンポーネントにより、RSSフィード・ジェネレータとしての機能がコンテンツ・サーバー・インスタンスに追加され、Oracle Secure Enterprise Search (Oracle SES)による検索が可能になりました。このコンポーネントは、コンテンツ・サーバー・インスタンスの現在のコンテンツのスナップショットを生成して、Oracle SES Crawlerに提供します。
SESCrawlerExportコンポーネントは、インデクサ・アクティビティに基づいて、内部インデクサからRSSフィードをXMLファイルとして生成します。このコンポーネントは、元のWebCenter Contentコンテンツ(Microsoft Wordドキュメントなど)、Web表示可能レンディション、および各ドキュメントの関連付けられているすべてのメタデータにアクセスできます。このコンポーネントには、インデクサからメタデータ値を適用してXMLドキュメントを生成するIdocスクリプトを含むテンプレートもあります。
SESCrawlerExportは、すべてのドキュメントの初期クロール用のRSSフィードを生成するほかに、更新および削除されたドキュメントの増分クロール用のフィードを生成します。各ドキュメントは、フィード内のアイテム、そのアイテムの操作(挿入、削除、更新など)、そのメタデータ(作成者、サマリーなど)、URLリンクなどになることができます。インデクサは定期的(約30秒)にウェイクアップし、変更されたドキュメントのデータ・フィードを作成します。
Oracle SES用コンテンツ・サーバー・コネクタは、クローリング・スケジュールに従って、SESCrawlerExportにより提供されるフィードを読み取ります。Oracle SESは汎用RSSクローラ・フレームワークを使用して、メタデータ情報を解析および抽出し、ドキュメントのコンテンツを取得します。
SESCrawlerExportコンポーネントは、コンテンツ・サーバー・インスタンスで使用される検索エンジンの影響を受けません。SESCrawlerExportは、Oracle SESによる検索の実行方法に影響を与えません。
ノート:
コンテンツ・サーバー・インスタンスで、YahooUserInterfaceLibraryコンポーネントが有効になっている必要があります。このコンポーネントには、SESCrawlerExportが初期クロール時にフィード生成ステータスをレポートするために使用するJavaScriptライブラリがあります。
ノート:
デフォルトで、SESCrawlerExportはDigitalMediaドキュメント・タイプのスナップショットをサポートしていないため、このタイプのドキュメントはSES検索で検出されません。SESExportCrawler管理ページにあるsceCoreFilter構成パラメータは、ソース格納場所スクリプトの事前フィルタとして機能し、DigitalMediaコンテンツがsceSourceLocationスクリプトに送られる前にフィルタ処理で除外します。sceCoreFilterのデフォルトのパラメータ設定は次のとおりです。
<$if dDocType and dDocType like 'DigitalMedia'$>#none<$else$>#customScript#<$endif$>コア・フィルタリングをsceSourceLocationScriptに従うようにすることによりDigitalMediaドキュメント・タイプを許可するには、デフォルトのsceCoreFilter構成パラメータを#customScript#に変更します。
この項の内容は次のとおりです。
SESCrawlerExportコンポーネントへのアクセス
SESCrawlerExportコンポーネントにアクセスするには:
-
「管理」、「管理サーバー」、「コンポーネント・マネージャ」の順に選択します。
-
「コンポーネント・マネージャ」ページで、統合コンポーネントのリストから、「SESCrawlerExport」を選択します。
-
「更新」をクリックします。
SESCrawlerExportコンポーネントが有効化されます。
-
「管理」→「SESCrawlerExport」を選択して、「SESCrawlerExport管理」ページを開きます。このページを使用して、コンテンツのスナップショットを取得してRSSフィードを生成し、「SESCrawlerExportの構成」ページにアクセスします。
コンテンツのスナップショットの取得
コンテンツ・サーバー・インスタンスのコンテンツのスナップショットを取得すると、Oracle SES Crawlerに提供するフィードが生成されます。スナップショットにより、SESCrawlerExportコンポーネントのFeedLocパラメータで指定された場所で、configFile.xmlが生成されます。XMLフィードは、wikisなどのソース名でサブディレクトリに作成されます。コンテンツ・サーバー・インスタンスに格納されているアイテム数および生成しているソース数によっては、スナップショットの実行に多少時間がかかることがあります。
スナップショットを取得するには:
-
「管理」→「SESCrawlerExport」を選択します。
-
「SESCrawlerExport管理」ページで、使用可能なメニュー・オプションから、スナップショットを取得するソースを選択します。
コンテンツ・ソースのリストから「すべてのソース」を選択すると、SESCrawlerExportで、定義されているすべてのソースに対してRSSフィードが生成されます。個別のソースを選択したり、ソースのサブセットを選択して、それらのソースのスナップショットのみを取得することもできます。
configFile.xmlドキュメントの更新により再索引付けが行われる場合、同じ場所にフィードも生成されます。 -
「スナップショットの取得」をクリックします。
ノート:
configFile.xmlファイルは、初期スナップショットまたは任意のドキュメントの最初の更新のどちらか最初に行われた方の、同じ構成に対して1度生成されます。
SESCrawlerExportパラメータの構成
SESCrawlerExportコンポーネントには、データ・フィードのソース、コンテンツ、メタデータ、データ・フィードごとのアイテム数などを指定するために構成できる、複数のパラメータがあります。パラメータに対する変更はただちに有効になりますが、変更内容を伝播するには、スナップショットを新たに再取得する必要があります。
これらのパラメータを構成するには:
-
「管理」→「SESCrawlerExport」を選択します。
-
「SESCrawlerExport管理」ページで、「SESCrawlerExportの構成」をクリックします。
-
次のSESCrawlerExportパラメータ・フィールドに値を入力するか、値を確認します。
| 要素 | 説明 |
|---|---|
| ホスト名 (sceHostname) |
エクスポートされるコンテンツをホスティングする、コンテンツ・サーバー・インスタンスのホスト名の文字列。値が空白の場合、ホスト名はOracle SESエクスポートを実行するホストに設定されます。このフィールドはIdoc対応です。 |
| フィード・ロケーション (sceFeedLoc) |
構成ファイルとデータ・フィードが書き込まれるディレクトリ。configFile.xmlファイルはこの場所で生成されます。データ・フィードおよびコンテンツは、このロケーションからのソース名を使用してサブディレクトリ内に生成されます。 クラスタのSESフィード・ロケーションが共有ファイル・ロケーションに配置されていることを確認します。共有のファイルの場所にない場合、SESインデクサによってファイルは無視されます。 |
| メタデータ・リスト (sceMetadataList) |
Oracle SESにエクスポートされるメタデータ値のカンマで区切られたリスト。値が空白の場合、メタデータ値のリストは次のフィールドで構成されます: - dID - dDocName - dRevLabel - dDocType - dDocAccount - dSecurityGroup - dOriginalName - dReleaseDate - dOutDate - dDocCreator - dDocLastModifier - dDocCreatedDate - dDocFunction - fParentGUID - fApplicationGUID - すべてのカスタム・メタデータ・フィールド(文字「x」で始まるもの) このリストにメタデータ・フィールドのセットが入力されている場合、それらのフィールドのみがOracle SESにエクスポートされます。これらのフィールドには、標準またはカスタム・メタデータ・フィールドを指定できます。 |
| 管理者の電子メール (sceAdminEmail) |
クローリング・エラーの発生時に電子メールで通知される、電子メール・アドレス、ユーザー名、ユーザー・エイリアスのカンマで区切られたリスト。 |
| カスタム・メタデータ・ブラックリスト (sceCustomMetadataBlacklist) |
Oracle SESにエクスポートされない、メタデータ値のカンマで区切られたリスト。これらのフィールドには、標準またはカスタム・メタデータ・フィールドを指定できます。 |
| SESによるソースごとの保留消費量の最大フィード(sceMaxFeedsPerSource) | SESによる保留中の消費量であるソースごとのデータフィードが指定された値を超えた場合に、新規データフィードの作成を制限する数。 フィードを制限するには、この数値を0または正の値に設定する必要があります。この数が負の値に設定されている場合、生成されるフィードは制限されません。 |
| データフィード当たりの最大アイテム数 (sceMaxItemsPerFeed) |
各データ・フィードのコンテンツ・アイテムの最大数。(フィード内のコンテンツ・アイテムは操作です。たとえば: ドキュメントの挿入、更新または削除。) |
| コア・フィルタ (sceCoreFilter) |
コンテンツに対して事前フィルタ処理を実行して、Oracle SESへのエクスポート対象から削除します。この値はデフォルト設定のままにすることをお薦めします。 |
| クローラ・ロール (sceCrawlerRole) |
Oracle SESがコンテンツ・サーバー・インスタンスのクロールに使用するアカウントで必要なコンテンツ・サーバーのロール。デフォルトでは、コンテンツ・サーバーのadminロールが必要です。ノート: Oracle SESからのクロールに、デフォルトのOracle WebLogic Server管理者アカウントは使用しないでください。かわりに、外部ソース(LDAPプロバイダなど)の管理者アカウントまたはローカルのコンテンツ・サーバー・アカウントを使用します。必要に応じて、このSESCrawlerExportフィールドを使用して、必須ロール adminを他のロールに変更できます。例:1。コンテンツ・サーバー・インスタンスで、 scecrawlerroleという新規ロールを作成します。2。新規ローカル・ユーザー・アカウント sescrawlerを作成して、ロールscecrawlerroleをこのユーザー・アカウントに割り当てます。3。Oracle SESで、 sescrawlerアカウントを使用してコンテンツ・サーバー・インスタンスをクロールするように、ソース定義を変更します。4。コンテンツ・サーバー・インスタンスで、 config.cfgファイルにsceCrawlerRole=sescrawlerroleを追加します。 |
| ソース名 (sceSourceName) |
WebCenter Content Serveインスタンスで作成されたすべてのコンテンツ・ソースの、カンマで区切られたリスト。リストされた各ソースは、まったく同じです(ミラー化)。複数のソースを持つことで、複数のOracle SESサーバーがこのインスタンスのコンテンツを個別に消費できます。 これらのソース名が、データ・フィードおよびコンテンツを保持するフィード・ロケーション・ディレクトリ用のサブディレクトリ名として使用されます。 ノート: 「ssSource」という名前は予約済ソース名なので、このフィールドでは使用しないでください。 |
| Secure APIの無効化 (sceDisableSecureAPIs) |
SESCrawlerExportコンポーネントで提供されるサービスのセキュリティが内部的に実行されるか(false)、またはコンテンツ・サーバーによってネイティブに実行されるか(true)を判断する、ブール・フラグ。シングル・サインオンの詳細は、「コンテンツ・サーバー・ソースをOracle Single Sign-Onで構成」を参照してください。 |
Oracle SESでのコンテンツ・サーバー・ソースの構成
コンテンツ・サーバー・コネクタにより、Oracle SESはWebCenter Contentでコンテンツ・サーバー・インスタンスを検索できるようになります。コネクタは、クローリング・スケジュールに従って、コンテンツ・サーバー・インスタンスにより提供されるフィードを読み取ります。Oracle SESからデータをクロールするには、タイプContent Serverのソースを作成する必要があります。コネクタ・パッチをインストールしてコンテンツ・サーバー・ソースを作成する方法は、『Oracle Secure Enterprise Search管理者ガイド』を参照してください。
コンテンツ・サーバー・ソースの設定には、次のパラメータを使用します。
-
構成URL:
http://*host\_name*/*instance\_name*/idcplg?IdcService=SES_CRAWLER_DOWNLOAD_CONFIG&source=*source\_name*source_nameで表されるパラメータは、SESCrawlerExportコンポーネントのソース名(sceSourceName)パラメータで使用される文字列の1つと同じである必要があります。このパラメータは、コンテンツ・サーバー・インスタンスのコンテンツ・ソースの1つを指しています。たとえば:http://stahz16/ucm/idcplg?IdcService=SES_CRAWLER_DOWNLOAD_CONFIG&source=cs -
認証および認可用HTTPエンドポイント: Oracle WebCenter Contentアイデンティティ・プラグインのアクティブ化および認可マネージャの構成時に、HTTPエンドポイントの値を求められます。一般に、2つの値は、同一のコンテンツ・サーバー・インスタンスでは同じで、形式は
http://host_name/instance_name/idcplgです。たとえば、http://host.example.com/ucm/idcplgとなります。この値は、コンテンツ・サーバー・インスタンスに対するすべてのサービス・コールのエンドポイントとして使用されます。この値は、「管理」、「管理サーバー」、「インターネットの構成」の順に選択して検索することもできます。現在のURL (URLパラメータなし)をHTTPエンドポイントとして使用します。
コンテンツ・サーバー・ソースをOracle Single Sign-Onで構成
コンテンツ・サーバー・インスタンスがOracle Single Sign-On (OSSO)で保護されている場合、Oracle SESがSESCrawlerExportによって提供されるサービスにアクセスできるように、SESCrawlerExportコンポーネントの構成を変更する必要があります。「SESCrawlerExportの構成」ページに移動し、「Secure APIの無効化」パラメータをtrueに設定して、内部セキュリティ・メカニズムを無効にします。
Oracle Access Managerでのコンテンツ・サーバー・ソースの構成
コンテンツ・サーバー・インスタンスがOracle Access Manager (OAM)で保護されている場合、Oracle SESがSESCrawlerExportコンポーネントによって提供されるサービスにアクセスできるように、なんらかの変更を加える必要があります。
-
コンテンツ・サーバー・インスタンスの
config.cfgファイルをテキスト・エディタで開きます。たとえば:DomainHomeName/ucm/cs/config/config.cfg。 -
次のプロパティ値を設定します。
HttpServerAddress=<OHSHost>:7778ここで、OHSHostはOracle HTTP Server (OHS)ホスト名で、7778はOHSポートです。
-
Content Serverインスタンスを再起動します。手順については、「Fusion Middleware Controlを使用したコンテンツ・サーバーまたはInbound Refineryの再起動」を参照してください。
-
「管理」→「SESCrawlerExport」を選択します。
-
「SESCrawlerExport管理」ページで、「SESCrawlerExportの構成」をクリックします。
-
「SESCrawlerExportの構成」ページで、「ホスト名」をクリックしてホスト名を<OHSHost>に設定します。
-
OAMで保護されたContent ServerインスタンスにアクセスするようにOracle SESを構成します。『Oracle Secure Enterprise Search管理者ガイド』を参照してください。
コンテンツ・サーバー・ソースを他のシングル・サインオンで構成
コンテンツ・サーバー・インスタンスがOracle Single Sign-On (OSSO)以外のシングル・サインオン・ソリューションで保護されている場合、Oracle SESがSESCrawlerExportコンポーネントによって提供されるサービスにアクセスできるように、なんらかの変更を加える必要があります。
-
構成: Oracle Single Sign-On以外のシングル・サインオン・ソリューションを使用している場合、SESCrawlerExportコンポーネントによって提供されるサービスのセキュリティは、コンポーネント自体によって提供されます。「SESCrawlerExportの構成」ページに移動し、「Secure APIの無効化」パラメータを
falseに設定して、内部SESCrawlerExportセキュリティ・メカニズムを有効にします。 -
Webサーバー: Oracle SESはシングル・サインオン・ソリューションと互換性がないため、SESCrawlerExportコンポーネントによって提供されるサービスへのアクセスは、シングル・サインオンをバイパスする必要があります。選択したシングル・サインオン・ソリューションによっては、バイパスを作成することが、サービスのサブセットへのアクセスを許可するようにWebサーバーを構成することと同じくらい簡単な場合もあります。
コンテンツ・サーバー・インスタンスで追加のWebサーバーを設定する場合、そのWebサーバーは標準のコンテンツ・サーバー・ポートとは別のポート(ポート80以外のポート)で実行される必要があります。シングル・サインオン保護をまったく設定せずに、この追加のWebサーバーを構成します。また、このWebサーバーへのOracle SESのアクセスのみを許可するように、アクセス制御リストを設定します。Oracle SESの構成では、コンテンツ・サーバー・ソースの構成URLで、この追加のWebサーバー・ポートを使用します。
コンテンツ・サーバー・ソース格納場所スクリプトの構成
コンテンツ・サーバー・ソース格納場所スクリプトは完全にカスタマイズ可能なIdocスクリプトで、コンテンツ・アイテムのメタデータを評価して、このコンテンツ・アイテムを設定するソースを返します。
ソース格納場所スクリプトを作成または更新するページにアクセスするには:
-
「管理」→「SESCrawlerExport」を選択します。
-
「SESCrawlerExport管理」ページで、「SESCrawlerExportの構成」をクリックします。
-
「SESCrawlerExportの構成」ページで、「ソース格納場所の構成スクリプト」をクリックします。
-
表示された領域にIdocスクリプトを入力します。
デフォルトでは、ソース格納場所スクリプトは
#allに設定され、Latest Releasedとフラグが付けられたすべてのコンテンツ・アイテムをコンテンツ・サーバー・インスタンスで構成されたすべてのソース(「ソース名」パラメータを参照)に送信します。#allソース名は、すべてのソースがコンテンツ・アイテムを受信することを示す予約キーワードです。同様に、
#noneソース名も予約キーワードですが、これはコンテンツ・アイテムをソースに送信しないことを示します(基本的に、コンテンツ・アイテムはOracle SESにエクスポートされない)。ノート:
コンテンツ・メタデータに基づいてコンテンツをフィルタするためにIdocScriptを使用する場合は、次のフィールドを使用しないでください: dCreateDate、dReleaseDate、dDocLastModifiedDate、dOutDate、dInDate。これらのフィールドは、スクリプトによって処理されるときにフォーマットされないため、エラーになるからです。かわりに、次のフィールドを使用してください: dCreateDateStdFmt、dReleaseDateStdFmt、dDocLastModifiedDateStdFmt、dOutDateStdFmt、dInDateStdFmt。
-
「更新」をクリックします。
ソース格納場所スクリプトを削除するには、「リセット」をクリックします。
-
ソース格納場所スクリプトをテストするには、コンテンツ・アイテムのドキュメント名(dDocName)を表示されたフィールドに入力して、「テスト」をクリックします。
スクリプトに構文エラーがある場合、構文エラーのタイプに応じて、エラーはページまたはサーバー出力に表示されます。論理エラーは、「SESCrawlerExportソース格納場所スクリプト」ページで修正して、ただちにテストを再実行できます。
スクリプトが存在しないソース名を返した場合、サーバー出力でエラーが生成されます。無効なソース名が削除され、アイテムの処理は続行されますが、ログに記録されます。この問題は、ソース名をスクリプトから削除するか、コンテンツ・サーバー・インスタンスに新しい「ソース名」パラメータ値を追加することで訂正できます。
スクリプトでは、複数のソース名をカンマで区切って返すことができます。
例
次の例では、ソース格納場所スクリプトを設定して、ドキュメント・タイプ(dDocType)がADACCTのすべてのコンテンツ・アイテムがaccountingという名前のソースに送信され、その他はすべてdefaultという名前のソースに含まれています。accountingおよびdefaultソースは、「SESCrawlerExportの構成」ページでそれぞれの名前を「ソース名」パラメータに追加することで、別個に設定する必要があります。
<$if dDocType like "ADACCT" $>
accounting
<$else$>
default
<$endif$>フルテキスト・データベース検索索引の構成
フルテキスト・データベース検索およびSQL Serverやその他のデータベースの索引付けを設定して使用するには:
-
WebCenter Contentをコンテンツ・サーバー・インスタンスとともにインストールし、データベースを使用できるように構成します。
-
次のエントリを
DomainHomeName\ucm\cs\config\config.cfgファイルに追加し、ファイルを保存します:SearchIndexerEngineName=DATABASE.FULLTEXT -
Content Serverインスタンスを再起動します。手順については、「Fusion Middleware Controlを使用したコンテンツ・サーバーまたはInbound Refineryの再起動」を参照してください。
-
リポジトリ・マネージャを使用して、検索索引を再構築します。
『Oracle WebCenter Contentのマネージメント』のリポジトリ・マネージャの起動に関する項を参照してください。
ノート:
OCSスキーマのインポート後、フルテキスト・データベース検索索引の再構築に問題があると、「Oracleテキスト・コレクション'IdcText1'を作成できません。」というメッセージが表示されることがあります。この場合の解決策は、(コンテンツ・サーバーの)データベース管理者としてログインして、表IdcText1と表IdcText2を削除することです。
『Oracle Fusion Middlewareの管理』のOracle WebCenter Contentのリカバリに関する項を参照してください。
Elasticsearchの管理
WebCenter Contentを使用したElasticsearchの管理について学習します。WebCenter Contentは、REST APIを介してElasticsearchと通信します。
WebCenter Contentでは、DATABASE.METADATA、DATABASE.FULLTEXT、ORACLETEXTSEARCHを含む様々な検索インデクサ・エンジンがサポートされています。このうち、ORACLETEXTSEARCHには、関連性ランキングを使用したフルテキスト検索、複雑な問合せ構造、DATABASE.FULLTEXTと比較したパフォーマンスの向上など、豊富な検索機能が備わっています。ただし、コンテンツ・アイテムが数百万に達し、取込みが大量になるような大規模なエンタープライズ設定では、ORACLETEXTSEARCH索引の再構築に時間がかかります。
WebCenter Contentは、Elasticsearchにより提供されるREST APIを介してElasticsearchと通信します。ユーザーに公開されるWebCenter Content API/サービスは変わりません。Elasticsearchでは、APIとユーザー・インタフェースはほとんど変わっていませんが、再構築時間が大幅に短縮されています。また、ユーザーの操作性も向上し、リアルタイムに近い検索レスポンスを実現しています。
この項の内容は次のとおりです。
Elasticsearchの機能と利点
Elasticsearchには、高速再構築、完全再構築、再索引付け、ソート、ファセット、検索演算子、検索などの機能があります。
この項の内容は次のとおりです。
Elasticsearchの再構築機能の仕組み
Elasticsearchには、新しくElasticsearch Reindexという再構築オプションが導入されました。
WebCenter ContentでOracleTextSearchを使用すると、高速再構築または完全再構築(抽出あり)を実行できます。したがって、ユーザーは、高速再構築、完全再構築(抽出を行う)、Elasticsearch Reindex (Elasticsearchから完全再構築)のいずれかを選択できるようになりました。
Elasticsearchを使用する場合、「インデクサの再構築」ダイアログには、「高速再構築の使用」と「コンテンツ抽出による完全再構築。」の2つのチェック・ボックスがあります。このダイアログ・ボックスにアクセスするには、「リポジトリ・マネージャ」で「インデクサ」→「コレクション再構築サイクル」→「開始」を選択します。
高速再構築
高速再構築機能により、検索エンジンは、コレクション全体を再構築することなく、検索コレクションに新しい情報を追加できます。
検索可能フィールドを追加または削除する際には、高速再構築を実行する必要があります。「コレクション再構築サイクル」ウィンドウを開き、「高速再構築の使用」チェック・ボックスを選択して「OK」をクリックすると、高速再構築を実行できます。
完全再構築
「完全再構築」オプションは、検索索引を再構築します。
コンテンツが抽出され、メタデータを使用してOpenSearchサーバーの新しい索引にプッシュされます。このタスクは時間がかかるため、細心の注意を払って使用してください。
「コレクション再構築サイクル」ウィンドウを開いて、「コンテンツ抽出による完全再構築。」チェック・ボックスを選択し、「OK」をクリックして完全再構築を実行します。
Elasticserver ReIndex
Elasticserver ReIndexオプションでは、Elasticsearch APIを使用して、既存のコレクションを新しいコレクションに再索引付けします。
再索引付けでは、アクティブなコレクションで使用可能な抽出済のコンテンツおよびメタデータが再利用されます。このオプションは、コンテンツを抽出する必要がないため、完全再構築よりも短時間で完了します。
「コレクション再構築サイクル」ウィンドウを開いて、いずれのオプションも選択しないこともできます。「OK」をクリックして、Elasticsearch ReIndexを実行します。
他にも索引付けのオプションがあります。このオプションでは、完全再構築(抽出を行う)のかわりにElasticsearch ReIndexを実行できます。Elasticsearch ReIndexを起動するには、「管理」→「管理アクション」→「コレクション再構築サイクル」(セクション)→「開始」を選択します。現在のバージョンでは、Elasticsearch ReIndexに対してインデクサ・カウンタは実装されていません。また、「取消」ボタンと「一時停止」ボタンが機能しない場合もあります。
ソート
Elasticsearchは既存の検索可能フィールドをSortFieldとして受け入れることができるため、検索結果の検索可能フィールドはソートできます。
フィールドをソート可または不可にするために再構築する必要はありません。フィールドのソート可/不可の切替えは、ユーザー・インタフェースで結果をソートする場合にのみ必要です。構成マネージャからフィールドをソート可能にしていない場合でも、フィールドがSortFieldとして渡されると、Elasticsearchによってそのフィールドを基準に検索結果がソートされます。
ファセット
WebCenter Content Elasticsearchでは、ドリルダウン値のデフォルト数は50です。
これは、構成内でMaxElasticSearchDrillDownValuesを使用することで構成可能であり、またバインダに渡すこともできます。MaxElasticSearchDrillDownValuesは任意の正の整数にできます。
検索演算子と検索
検索ユーザー・インタフェースに、より多くの検索演算子が組み込まれました。デフォルトの検索演算子は、Contains、Matches、Has Word Prefix、Starts、Ends、SubstringおよびNot Matchesです。
検索
- OracleTextSearchでサポートされるすべての検索機能は、Elasticsearchでもサポートされています。
- Elasticsearchには「最適化」フィールドと「ゾーン」フィールドがありません。
- Elasticsearchでは、検索中にメタデータ・フィールド名の大/小文字は区別されますが、
QueryTextでは大/小文字は区別されません。 MATCHES演算子を使用する問合せでは、すべての検索可能フィールドで、問合せテキストの大/小文字が区別されない完全一致が検索されます。- 存在しないフィールドまたはメタデータを検索した場合、Elasticsearchではエラーはスローされません。かわりに、ゼロの結果が表示されます。
- Elasticsearchを使用する場合、WebCenter Contentは特殊文字を無視せずに有効な結果を返します。
- WebCenter Contentユーザー・インタフェースから実行する検索では、WebCenter Contentにより末尾のスペースが切り捨てられ、切捨て後の値が問合せテキストとして使用されます。問合せテキストの末尾または先頭(あるいはその両方)にスペースがある場合、WebCenter Contentユーザー・インタフェースとOracleTextSearchとでは返される結果が異なります。RIDCの場合、Elasticsearchは末尾のスペースも考慮して検索結果を返します。
- HTMLタグに囲まれたテキスト(
<script>..</script>、<style>..</style>、<! -- -->など)はトークン化されないため、検索不可能です。 - WebCenter Contentでは、存在しないフィールドや検索不能フィールドは検索できません。「<fieldname>は検索可能なフィールドではありません。」というエラー・メッセージがスローされます。
ストップワードの検索
ストップワードは、Webページの索引付けと解析を高速化するために検索から除外される一般的に使用されるワードです。ストップワードの場合、Elasticsearchは索引エントリを作成しません。
-
このリストはOTSストップワードから導出されます。
"Mr"、"Mrs"、"Ms"、"a"、"all"、"almost"、"also"、"although"、"an"、"and"、"any"、"are"、"as"、"at"、"be"、"because"、"been"、"both"、"but"、"by"、"can"、"could"、"d"、"did"、"do"、"does"、"either"、"for"、"from"、"had"、"has"、"have"、"having"、"he"、"her"、"here"、"hers"、"him"、"his"、"how"、"however"、"i"、"if"、"in"、"into"、"is"、"it"、"its"、"just"、"ll"、"me"、"might"、"my"、"no"、"non"、"nor"、"not"、"of"、"on"、"one"、"only"、"onto"、"or"、"our"、"ours"、"s"、"shall"、"she"、"should"、"since"、"so"、"some"、"still"、"such"、"t"、"than"、"that"、"the"、"their"、"them"、"then"、"there"、"therefore"、"these"、"they"、"this"、"those"、"though"、"through"、"thus"、"to"、"too"、"until"、"ve"、"very"、"was"、"we"、"were"、"what"、"when"、"where"、"whether"、"which"、"while"、"who"、"whose"、"why"、"will"、"with"、"would"、"yet"、"you"、"your"、"yours"。
- ストップワードで検索する場合、Elasticsearchでは、そのワードではなく空の文字列で検索する場合と同様に処理されます。
- ストップワードは、
Full-Text Search、Quick Search、Contains、Has Word Prefixの検索問合せにのみ適用できます。 - 1つのストップワードまたはストップワードのみで構成される句で構成される問合せ(
Full-Text Search、Quick SearchおよびContains)は、空の検索であるかのようにすべての結果を返します。たとえば、thisがストップワードとして定義されているため、ワードthisの問合せにはすべてのヒットが返されます。 - 1つのストップワードまたはストップワードのみで構成される句で構成される問合せ(
Has Word Prefix)は、結果を返しません。たとえば、thisがストップワードとして定義されているため、ワードthisの問合せにはすべてのヒットが返されます。 - ストップワードおよび非ストップワードを含む句を問い合せることができます。そのような場合、句にストップ・ワードが存在しないかのように句が検索されます。たとえば、句this titleの問合せでは、thisがストップワードであるため、ワードtitleのみを検索する場合と同様にヒットが返されます。
ステミング
ステミングは、テキスト問合せ(Contains、Has Word Prefix、Full Text SearchおよびQuickSearch)にのみ適用できます。
OracleTextSearchとElasticsearchでは、検索エンジンの内部で使用されるディクショナリが異なるため、ワードのステミングが異なります。たとえば、OracleTextSearchでは、「find」という語の検索問合せに対してfound、finds、findingが返され、「make」という語の問合せに対してはmake、made、makes、makingが返されます。Elasticsearchでは、「find」の検索結果にはfind、finds、findingが表示され、「make」の検索結果にはmake、makes、makingが表示されます。「found」と「made」は、Elasticsearchの結果には表示されませんが、OracleTextSearchでは表示されます。
スニペット
config.cfgファイルで次の構成エントリを設定することにより、Elasticsearchでスニペット機能を有効にすることができます: ElasticSearchDisableSearchSnippet=false。
この機能は、検索問合せのパフォーマンスに影響する可能性があります。Elasticsearchで表示されるスニペットは、OracleTextSearchで表示されるものとは異なります。Elasticsearchのスニペットのルック・アンド・フィールは、OracleTextSearchスニペットのルック・アンド・フィールとは異なります。Elasticsearchでは、1つの完全な文は1つのスニペットと同じです。
Elasticsearchの結果で、ドキュメントの抽出済コンテンツでなくメタデータの一致のみであったためにドキュメントが検索で返された場合、そのメタデータ値がスニペットとして表示されます。
強調表示
Elasticsearchでは検索キーワードは強調表示されますが、前および次の一致のポインタは表示されません。
OracleTextSearchでは検索キーワードが強調表示され、次および前の一致のポインタも示されます。
Elasticsearch強調表示では、抽出済コンテンツに一致がある場合のみ、ドキュメントの抽出済コンテンツが返されます。強調表示では、その特定のメタデータ値との一致があった場合にのみ、ドキュメントのメタデータが表示されます。
一致がドキュメントのメタデータのみであった場合は、一致したメタデータ・フィールドのみがリストされ、抽出済コンテンツはリストされません。
Elasticsearchの構成
この項では、WebCenter Content用にElasticsearchを構成する方法について学習します。WebCenter Content用にElasticsearchを構成する前に、クラスタのノードを保護し、Elasticsearchを保護して、ベース・ノードをまず起動してから他のノードを起動する必要があります。
WebCenter Content用にElasticsearchを構成するには、次のステップを実行します:
ノート: Elasticsearchの索引はディスク上にファイルとして格納されます。Elasticsearchが機能するためには、大きな空きディスク領域が必要です。詳細は、Oracleサポートにお問い合せください
- https://www.elastic.co/downloads/past-releases#elasticsearchから、8.xバージョンのElasticsearchをダウンロードして解凍します。
-
<IdcHomeDir>/components/ElasticSearch/scriptsに移動します。ノート: WebCenter Contentには、ElasticsearchクラスタのElasticsearchノード(1つ以上)を保護するステップを自動化するスクリプト
SecureES8.shまたはSecureES8.cmd(Elasticsearch 7.xの場合はSecureES.shまたはSecureES.cmd)が用意されています。クラスタのすべてのノードにElasticsearchクラスタがインストールされていることが前提となります。単一ノードのクラスタにすることもできます。マルチノード・クラスタの場合は、少なくとも3つのマスター候補ノードが必要です。 - クラスタのすべてのノードでスクリプトを実行します。ノードを実行する前に、まず保護しておく必要があります。最初にベース・ノードを起動してから、他のノードを起動する必要があります。
この項の内容は次のとおりです。
- ES8node.propertiesの更新
- UNIXでのSecureES8.shの使用
- WindowsでのSecureES8.cmdの使用
- Elasticsearchの保護
- クラスタの他のノードの保護
- Elasticsearchクラスタの起動
- WebCenter Content用のElasticsearchの構成
- Elasticsearchクラスタ・ヘルスの監視
- 索引設定の構成
ES8node.propertiesの更新
ES8node.propertiesファイルは、初期クラスタ設定の一部として保護されるすべてのElasticsearchノードを設定する前に更新する必要があります。
設定に含めるすべてのノードを保護する前に、それらの構成を更新します。ES8node.propertiesファイルは、スクリプト・ファイルが存在するのと同じフォルダに存在する必要があります。次のステップに従います:
-
個別ノードの構成: 初期クラスタ設定に計画されているすべてのノードを構成します。エントリ(node1、node2、node3、……、node{n})を、設定の一部として作成されるノードの数として指定します。
node{n}_ES_HOME node{n}_node_name node{n}_http_portここで、{n}は設定のn番目のノードです。たとえば:
##Node1 (BASE NODE) node1_ES_HOME=/ESuser/elasticsearch-8.19.3_1 node1_node_name=nodeA node1_http_port=9201##Node2 node2_ES_HOME=/ESuser/elasticsearch-8.19.3_2 node2_node_name=nodeB node2_http_port=9202 -
すべてのノードに共通の構成:
BASE_ES_HOME: これは、node1_ES_HOMEと同じであるか、すべてのノードからconfig/{certificate_name}およびconfig/elasticsearch.keystoreにアクセスできる必要があります。たとえば、BASE_ES_HOME=/ESuser/elasticsearch-8.19.3_1です。cluster_name: クラスタの名前。たとえば、cluster_name=wcc-elasticsearchです。certificate_name: クラスタを保護する証明書名(拡張子はe.p12である必要があります)。たとえば、certificate_name=elastic-certificates.p12です。wcc_es_admin_user: WebCenter ContentがElasticsearchと通信するユーザー。たとえば、wcc_es_admin_user=wccesadminです。cluster_initial_master_nodes: 初期クラスタ設定の一部であるすべてのノード名。たとえば、cluster_initial_master_nodes=["nodeA","nodeB","nodeC",…,”node{N}”]です。discovery_seed_hosts: これらのノードが構成されるすべてのホスト名。Elasticsearchクラスタが水平の場合にのみ必須です。たとえば、discovery_seed_hosts=["host1.example.com","host2.example.com","host3.example.com",…,” host{n}.example.com”]です
ノート: Elasticsearchバージョン7.xの場合は、引き続き
ESnode.propertiesを使用します。この場合、次の構成も使用する必要があります -WINDOWS_CURL_HOME: Windowsと、ベース・ノード(node1)にのみ必要です。たとえば、C:\curl-7.72.0_5-win64-mingw\bin\curl.exeの場合、WINDOWS_CURL_HOME = C:\curl-7.72.0_5-win64-mingwとなります。
UNIXでのSecureES8.shの使用
このスクリプトは、UNIXでElasticsearchクラスタ・ノードを保護するステップを自動化します。
使用方法:
ヘルプを表示する場合:
./SecureES8.sh -h or --helpスクリプトを実行するには:
./SecureES8.sh -n <nodenumber>たとえば、保護するノードが3つある場合、最初のノードでスクリプトを実行してから、他のノードでスクリプトを実行する必要があります。
./SecureES8.sh -n 1./SecureES8.sh -n 2./SecureES8.sh -n 3ノート: Elasticsearchバージョン7.xの場合、Unixでは引き続きSecureES.shを使用します。
WindowsでのSecureES8.cmdの使用
このスクリプトは、WindowsでElasticsearchクラスタ・ノードを保護するステップを自動化します。
使用方法:
このスクリプトを実行するには:
SecureES8.cmd -n <nodenumber>たとえば、保護するノードが3つある場合、最初のノードでスクリプトを実行してから、他のノードでスクリプトを実行する必要があります。
SecureES8.cmd -n 1SecureES8.cmd -n 2SecureES8.cmd -n 3ノート: Elasticsearchバージョン7.xの場合、Windowsでは引き続きSecureES.cmdを使用します。
Elasticsearchの保護
最初(ベース)のノードを保護するには、これらのステップに従います:
<ELASTIC_COMPONENT_DIR>/scriptsに移動します。- スクリプトを実行します。Windowsの場合は、
SecureES8.cmd -n <nodenumber>を実行し、Unixの場合は./SecureES8.sh -n <nodenumber>を実行します。</br> ノート: Elasticsearchバージョン7.xの場合は、引き続きSecureES.sh(Unixの場合)またはSecureES.cmd(Windowsの場合)を使用します。 -
証明書の名前を入力するように求められます。入力しない場合は、デフォルト名
elastic-certificates.p12が使用されます。証明書の拡張子はp12である必要があります。
証明書のパスワードを入力します。

-
証明書パスワードをキーストアに追加します。Elasticsearchキーストアが存在しない場合は、作成するように求められます。
「y」を押してキーワードを作成し、続行します。ここで「N」を選択すると、ノードは保護されません。
パスワードを4回入力するように求められます。前に使用した証明書パスワードを入力します。

-
予約済ユーザー
elasticのパスワードを設定します。ユーザーelasticのパスワードを入力します。これは、後のステップでWebCenter Contentと通信するユーザーを作成するために使用します。
-
WebCenter Contentと通信するユーザーを作成します。ユーザー名とパスワードの入力を求められます。名前を入力するか、[ENTER]を押してデフォルト名
wccesadminを使用します。
ユーザー
elasticに設定するパスワードを入力します。
- 設定が完了すると、設定完了のメッセージが表示されます。
- ここではノードを起動しないでください。
クラスタの他のノードの保護
スクリプトを実行してクラスタのノードを保護する必要があります。
クラスタの他のノードを保護するには、次のステップに従います:
<ELASTIC_COMPONENT_DIR>/scriptsに移動します。-
スクリプトを実行します。クラスタ名はすべてのノードで同じである必要があります。ノード名は一意である必要があります。
UNIXの場合:
./SecureES8.sh -n 2Windowsの場合:
SecureES8.cmd -n 2ノート: Elasticsearchバージョン7.xの場合、
SecureES.sh(Unixの場合)またはSecureES.cmd(Windowsの場合)を引き続き使用します。</br></br> - 設定が完了すると、設定完了のメッセージが表示されます。</br>
- ここではノードを起動しないでください。
Elasticsearchクラスタの起動
クラスタのすべてのノードを保護または構成した後、すべてのノードを起動できます。
すべてのノードを保護した後、各ノードの<ES_HOME>/binに移動して実行します
./elasticsearch最初にベース・ノード(node1)を起動してから、他のノードを起動します。
最初にBASE NODE (node1)を起動してから、他のノードを起動する必要があります。
ノードの起動後は、wccesadminを使用して各ノードにアクセスできます。
https://<hostname>:<nodeport>WebCenter Content用のElasticsearchの構成
WebCenter Content用にElasticsearchを構成する前に、Elasticsearch検索インデクサを有効にして、必須の初期構成設定を行う必要があります。
WebCenter Content用にElasticsearchを構成するには、次のステップを実行します:
- WebCenter Content管理対象サーバーを起動します。
- 「管理」、「ElasticSearch」、「ElasticSearch構成」の順に選択します。
-
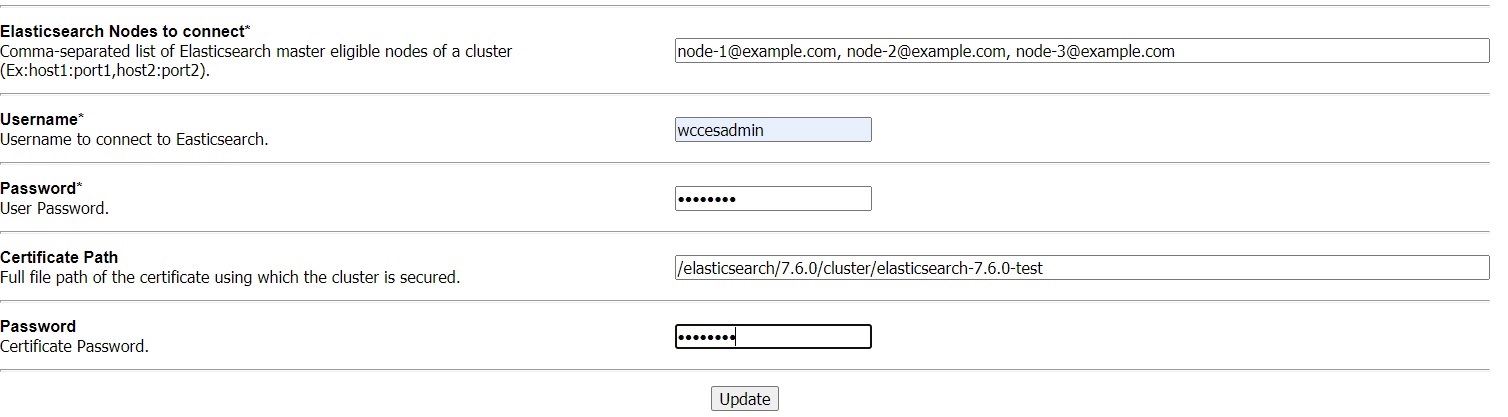
次の図に示すように、Elasticsearch構成ページで、次のフィールドに値を入力します:
- 接続するElasticsearchノード - クラスタのElasticsearchノードのカンマ区切りリスト
- ユーザー名 - Elasticsearchに接続するユーザー名
- パスワード - ユーザー・パスワード
- 証明書のパス - 保護されたクラスタを使用する証明書の絶対パス
- パスワード - 証明書パスワード
Elasticsearchクラスタ・ヘルスの監視
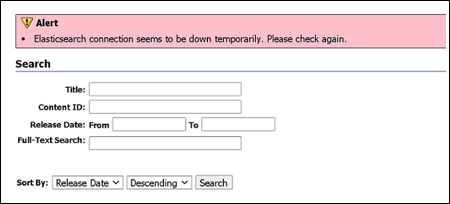
WebCenter Contentが正しく機能するには、Elasticsearchクラスタ・ヘルスが良好であることが重要です。
この機能は、Elasticsearchのヘルスを1時間間隔で監視するために導入されました。Elasticsearchのヘルス問題のステータスが赤または接続が停止している場合、Elasticsearchのヘルス・ステータスが緑または黄になるまで、アラートが1分ごとに追加および監視されます。Elasticsearchヘルスのステータスが緑または黄に変わると、ヘルス・アラートは自動的に削除され、その後は1時間ごとに監視が続行されます。
次の図は、Elasticsearch接続が一時的に停止していることを示しています。
索引設定の構成
必要なデータに従って、異なる索引のシャードおよびレプリカを構成できます。
この新機能により、Elasticsearch索引ごとにシャード数およびレプリカ数をカスタマイズできます。Elasticsearchの設計に従って、Elasticsearchの各索引はWebCenter Contentのセキュリティ・グループにマップされます。索引は、次の場合に作成されます:
- サーバーの起動
- 新規セキュリティ・グループがシステムに追加されました
- コレクションの再構築または再索引付け
- 他の検索エンジンからElasticsearchへの移行
シャードおよびレプリカは、ユーザー構成に基づいてシステムに作成されるときに索引に割り当てられます。これらの設定に対する更新は、次の完全再構築または再索引付けサイクルの後にのみ反映されます。シャード数およびレプリカ数に制限を設定できます。
シャード数: 5から300の範囲の整数値である必要があります。デフォルト値は5です。
レプリカ数: 1または2である必要があります。デフォルト値は1です。
Elasticsearchとの接続が確立されておらず、索引がまだ作成されていない場合は、既存のElasticsearchアラートとともに追加のオプション・アラートが表示されます。

このアラート・メッセージをクリックすると、「ElasticSearch索引設定」ページにリダイレクトされます。このページでは、システムに存在するセキュリティ・グループ(索引)ごとにシャードおよびレプリカをカスタマイズできます。
Elasticsearchとの接続の確立が成功すると、これらのカスタマイズされた設定を持つ索引が作成されます。他の検索エンジンからElasticsearchに移行する場合、これらの索引をカスタマイズされた設定で作成するには、移行が成功する必要があります。
すでに構成されているElasticsearchインスタンスの場合、索引はデフォルトの索引設定で作成されます。
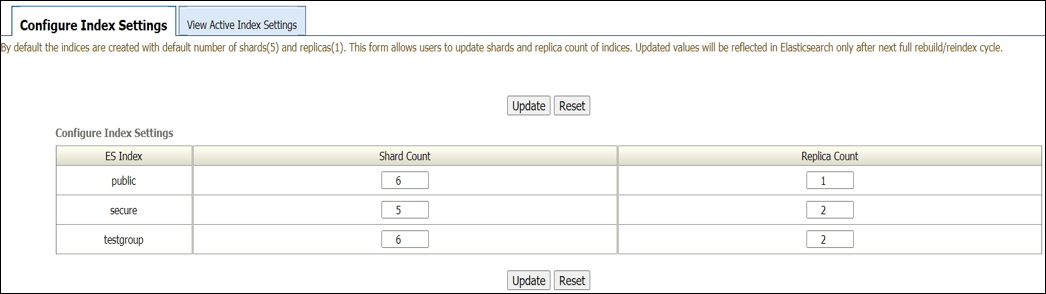
索引設定を構成するには:
- 「管理」、「ElasticSearch」、「ElasticSearch索引設定」の順に選択します。
-
「索引設定の構成」ページでは、目的のシャードおよびレプリカ数で索引を構成できます。更新されたシャードおよびレプリカ設定は、次の後に反映されます:
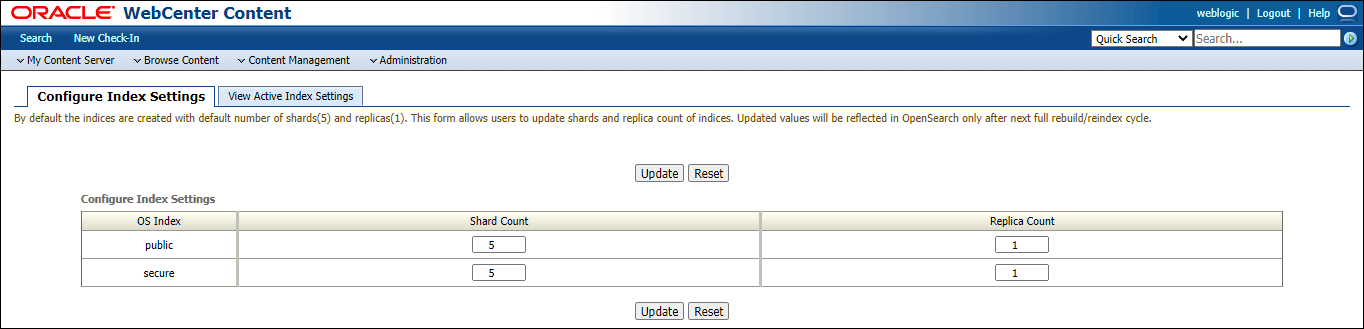
- 次の完全再構築または再索引付けサイクル
- 新規インスタンスでの正常な接続の確立
- 別の検索エンジンから切り替える場合の移行 特定の索引を更新することはできません。「更新」ボタンをクリックすると、すべてのレコードが更新されます。
-
Elasticsearchサーバーから取得されたすべてのアクティブな索引とそのシャードおよびレプリカ設定を表示するには、「アクティブな索引設定」タブを選択します。
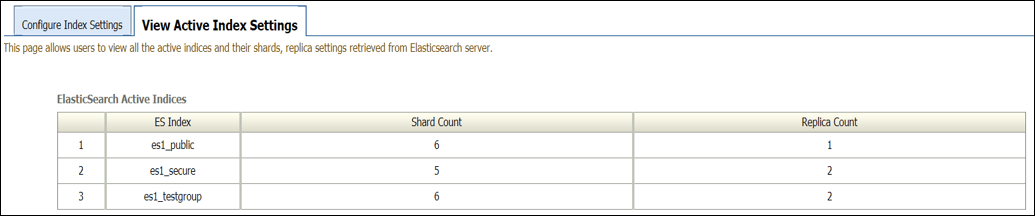
新規セキュリティ・グループの追加
WebCenter ContentからElasticsearchサーバーへの接続が成功した後に新しいセキュリティ・グループが追加されると、対応する索引がデフォルト・シャード数(5)およびレプリカ数(1)でElasticsearchに作成されます。
設定をカスタマイズする場合は、「ElasticSearch索引設定」ページから行うことができますが、これらは次の再構築または再索引付けサイクルの後にのみ反映されます。
既存の検索索引のElasticsearchサーバーへの移行
アクティブな検索索引からElasticサーバーに移行すると、アクティブな索引はes1に変更されます。
ノート: OTSからElasticsearchへの500万件のレコードの移行中、すべてのテキスト・フィールドについて、Elasticsearchの様々な検索操作に対して4種類のマッピングを作成する必要があります。Elasticsearchでは、これらのマッピングは異なるフィールドとみなされます。たとえば、テキスト・フィールドdDocTitleにはdDocTitle、dDocTitle.normalize、dDocTitle.keyword、dDocTitle.stemがあり、これらは1つのフィールドではなく4つのフィールドとみなされます。そのため、250のテキスト・フィールドがある場合、Elasticsearchではそれらを250*4 = 1000フィールドとみなします。テキスト・フィールド以外のメタデータの場合、マッピングは1つのみです。不要なメタデータ・フィールドを削除すると、移行アクティビティを実行できるようになります。
既存のWebCenter ContentインスタンスがORACLETEXTSEARCH (OTS)検索エンジンを使用するように構成されている場合は、すでに抽出されたコンテンツをフェッチするためにアクティブな索引ots1/ots2が使用されます。移行アクティビティが成功すると、アクティブな検索索引がElasticサーバー(es1)に変更されます。
「管理」を選択すると、「ページ<hostname with port>の構成」が表示されます。次に示すように、ots1/ots2がアクティブな索引として表示されます:

移行するには、「管理」→「ElasticSearch」を選択します。ElasticSearch移行ページが表示されます。次に示すように、「移行する検索エンジン」ドロップダウン・メニューから適切な検索エンジンを選択します:
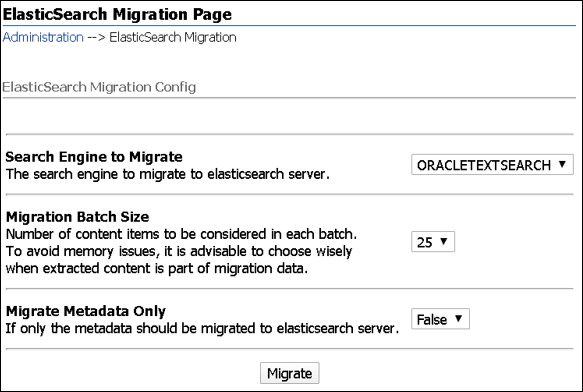
「移行バッチ・サイズ」は、Elasticsearchサーバーにプッシュするためにまとめてバッチ処理するドキュメント数を決定します。ORACLETEXTSEARCHのようなフルテキスト検索エンジンの場合、バッチにはドキュメントのテキスト抽出コンテンツとそのメタデータも含まれるため、バッチ・サイズは慎重に選択する必要があります。
「メタデータのみ移行」は、テキスト抽出コンテンツをElasticsearchサーバーにプッシュする必要があるかどうかを指定します。ORACLETEXTSEARCHのようなフルテキスト検索エンジンの場合、これは常にFalseに設定する必要があります。つまり、テキスト抽出コンテンツもElasticsearchサーバーにプッシュする必要があります。
移行アクティビティの開始時に、次に示すような、最近のすべての移行ジョブとそのステータス詳細の表がリストされます:

実行中の移行アクティビティは一時停止または再開でき、また失敗した最近の移行アクティビティがあれば再試行できます。完了した移行アクティビティの詳細を次に示します:

移行アクティビティが成功すると、次に示すようにアクティブな索引がes1に切り替わります:

ノート: 移行アクティビティが成功すると、移行アラート・バナーが削除されます。
OpenSearchの管理
WebCenter Contentを使用したOpenSearchの管理について学習します。
OpenSearchを使用したOracle Cloud Infrastructure (OCI) Search Serviceは、Oracle管理サービスとして提供されるインサイト・エンジンです。ダウンタイムなしで、サービスのパッチ適用、更新、アップグレード、バックアップおよびサイズ変更がOracleによって自動化されます。大量のデータをすばやく格納、検索および分析し、結果をほぼリアルタイムで確認できます。
WebCenter Contentは、REST APIを介してOpenSearchと通信します。ユーザーに公開されるWebCenter Content APIまたはサービスは変わりません。
この項の内容は次のとおりです。
OpenSearchの機能と利点
OpenSearchには、高速再構築、完全再構築、再索引付け、ソート、ファセット、検索演算子、検索などの機能があります。
この項の内容は次のとおりです。
OpenSearchの再構築機能の仕組み
OpenSearchには、新しくOpenSearch Reindexという再構築オプションが導入されました。
WebCenter ContentでOpenSearchを使用すると、高速再構築または完全再構築(抽出あり)を実行できます。したがって、ユーザーは、高速再構築、完全再構築(抽出を行う)、OpenSearch Reindex (Elasticsearchから完全再構築)のいずれかを選択できるようになりました。
OpenSearchを使用する場合、「インデクサの再構築」ダイアログには、「高速再構築の使用」と「コンテンツ抽出による完全再構築。」の2つのチェック・ボックスがあります。このダイアログ・ボックスにアクセスするには、「リポジトリ・マネージャ」で「インデクサ」→「コレクション再構築サイクル」→「開始」を選択します。
高速再構築
高速再構築機能により、検索エンジンは、コレクション全体を再構築することなく、検索コレクションに新しい情報を追加できます。
検索可能フィールドを追加または削除する際には、高速再構築を実行する必要があります。「コレクション再構築サイクル」ウィンドウを開き、「高速再構築の使用」チェック・ボックスを選択して「OK」をクリックすると、高速再構築を実行できます。
完全再構築
「完全再構築」オプションは、検索索引を再構築します。
コンテンツが抽出され、メタデータを使用してOpenSearchサーバーの新しい索引にプッシュされます。このタスクは時間がかかるため、細心の注意を払って使用してください。
「コレクション再構築サイクル」ウィンドウを開いて、「コンテンツ抽出による完全再構築。」チェック・ボックスを選択し、「OK」をクリックして完全再構築を実行します。
OpenSearch ReIndex
OpenSearch ReIndexオプションでは、OpenSearch APIを使用して、既存のコレクションを新しいコレクションに再索引付けします。
再索引付けでは、アクティブなコレクションで使用可能な抽出済のコンテンツおよびメタデータが再利用されます。このオプションは、コンテンツを抽出する必要がないため、完全再構築よりも短時間で完了します。
「コレクション再構築サイクル」ウィンドウを開いて、いずれのオプションも選択しないこともできます。「OK」をクリックして、OpenSearch ReIndexを実行します。
他にも索引付けのオプションがあります。このオプションでは、完全再構築(抽出を行う)のかわりにOpenSearch ReIndexを実行できます。OpenSearch ReIndexを起動するには、「管理」→「管理アクション」→「コレクション再構築サイクル」(セクション)→「開始」を選択します。現在のバージョンでは、OpenSearch ReIndexに対してインデクサ・カウンタは実装されていません。また、「取消」ボタンと「一時停止」ボタンが機能しない場合もあります。
ソート
OpenSearchは既存の検索可能フィールドをSortFieldとして受け入れることができるため、検索結果の検索可能フィールドはソートできます。
フィールドをソート可または不可にするために再構築する必要はありません。フィールドのソート可/不可の切替えは、ユーザー・インタフェースで結果をソートする場合にのみ必要です。構成マネージャからフィールドをソート可能にしていない場合でも、フィールドがSortFieldとして渡されると、OpenSearchによってそのフィールドを基準に検索結果がソートされます。
ファセット
WebCenter Content OpenSearchでは、ドリルダウン値のデフォルト数は50です。
これは、構成内でMaxOpenSearchDrillDownValuesを使用することで構成可能であり、またバインダに渡すこともできます。MaxOpenSearchDrillDownValuesは任意の正の整数にできます。
検索演算子と検索
検索ユーザー・インタフェースに、より多くの検索演算子が組み込まれました。デフォルトの検索演算子は、Contains、Matches、Has Word Prefix、Starts、Ends、SubstringおよびNot Matchesです。
検索
- OracleTextSearchでサポートされるすべての検索機能は、OpenSearchでもサポートされています。
- OpenSearchには「最適化」フィールドと「ゾーン」フィールドがありません。
- OpenSearchでは、検索中にメタデータ・フィールド名の大/小文字は区別されますが、
QueryTextでは大/小文字は区別されません。 MATCHES演算子を使用する問合せでは、すべての検索可能フィールドで、問合せテキストの大/小文字が区別されない完全一致が検索されます。- 存在しないフィールドまたはメタデータを検索した場合、OpenSearchではエラーはスローされません。かわりに、ゼロの結果が表示されます。
- OpenSearchを使用する場合、WebCenter Contentは特殊文字を無視せずに有効な結果を返します。
- WebCenter Contentユーザー・インタフェースから実行する検索では、WebCenter Contentにより末尾のスペースが切り捨てられ、切捨て後の値が問合せテキストとして使用されます。問合せテキストの末尾または先頭(あるいはその両方)にスペースがある場合、WebCenter Contentユーザー・インタフェースとOracleTextSearchとでは返される結果が異なります。RIDCの場合、OpenSearchは末尾のスペースも考慮して検索結果を返します。
- HTMLタグに囲まれたテキスト(
<script>..</script>、<style>..</style>、<! -- -->など)はトークン化されないため、検索不可能です。 - OpenSearchでは、存在しないまたは検索できないフィールドは検索できません。「<fieldname>は検索可能なフィールドではありません。」というエラー・メッセージがスローされます。
ストップワードの検索
ストップワードは、Webページの索引付けと解析を高速化するために検索から除外される一般的に使用されるワードです。ストップワードの場合、OpenSearchは索引エントリを作成しません。
-
このリストはOTSストップワードから導出されます。
"Mr"、"Mrs"、"Ms"、"a"、"all"、"almost"、"also"、"although"、"an"、"and"、"any"、"are"、"as"、"at"、"be"、"because"、"been"、"both"、"but"、"by"、"can"、"could"、"d"、"did"、"do"、"does"、"either"、"for"、"from"、"had"、"has"、"have"、"having"、"he"、"her"、"here"、"hers"、"him"、"his"、"how"、"however"、"i"、"if"、"in"、"into"、"is"、"it"、"its"、"just"、"ll"、"me"、"might"、"my"、"no"、"non"、"nor"、"not"、"of"、"on"、"one"、"only"、"onto"、"or"、"our"、"ours"、"s"、"shall"、"she"、"should"、"since"、"so"、"some"、"still"、"such"、"t"、"than"、"that"、"the"、"their"、"them"、"then"、"there"、"therefore"、"these"、"they"、"this"、"those"、"though"、"through"、"thus"、"to"、"too"、"until"、"ve"、"very"、"was"、"we"、"were"、"what"、"when"、"where"、"whether"、"which"、"while"、"who"、"whose"、"why"、"will"、"with"、"would"、"yet"、"you"、"your"、"yours"。
- ストップワードで検索する場合、OpenSearchでは、そのワードではなく空の文字列で検索する場合と同様に処理されます。
- ストップワードは、
Full-Text Search、Quick Search、Contains、Has Word Prefixの検索問合せにのみ適用できます。 - 1つのストップワードまたはストップワードのみで構成される句で構成される問合せ(
Full-Text Search、Quick SearchおよびContains)は、空の検索であるかのようにすべての結果を返します。たとえば、thisがストップワードとして定義されているため、ワードthisの問合せにはすべてのヒットが返されます。 - 1つのストップワードまたはストップワードのみで構成される句で構成される問合せ(
Has Word Prefix)は、結果を返しません。たとえば、thisがストップワードとして定義されているため、ワードthisの問合せにはすべてのヒットが返されます。 - ストップワードおよび非ストップワードを含む句を問い合せることができます。そのような場合、句にストップ・ワードが存在しないかのように句が検索されます。たとえば、句this titleの問合せでは、thisがストップワードであるため、ワードtitleのみを検索する場合と同様にヒットが返されます。
ステミング
ステミングは、テキスト問合せ(Contains、Has Word Prefix、Full Text SearchおよびQuickSearch)にのみ適用できます。
OracleTextSearchとOpenSearchでは、検索エンジンの内部で使用されるディクショナリが異なるため、ワードのステミングが異なります。たとえば、OracleTextSearchでは、「find」という語の検索問合せに対してfound、finds、findingが返され、「make」という語の問合せに対してはmake、made、makes、makingが返されます。OpenSearchでは、「find」の検索結果にはfind、finds、findingが表示され、「make」の検索結果にはmake、makes、makingが表示されます。「found」と「made」は、OpenSearchの結果には表示されませんが、OracleTextSearchでは表示されます。
スニペット
OpenSearchでスニペット機能を有効にするには、config.cfgファイルで次の構成エントリを設定します: OpenSearchDisableSearchSnippet=false。
この機能は、検索問合せのパフォーマンスに影響する可能性があります。OpenSearchで表示されるスニペットは、OracleTextSearchで表示されるものとは異なります。OpenSearchのスニペットのルック・アンド・フィールは、OracleTextSearchスニペットのルック・アンド・フィールとは異なります。OpenSearchでは、1つの完全な文は1つのスニペットと同じです。
OpenSearchの結果で、ドキュメントの抽出済コンテンツでなくメタデータの一致のみであったためにドキュメントが検索で返された場合、そのメタデータ値がスニペットとして表示されます。
強調表示
OpenSearchでは検索キーワードは強調表示されますが、前および次の一致のポインタは表示されません。
OracleTextSearchでは検索キーワードが強調表示され、次および前の一致のポインタも示されます。
OpenSearch強調表示では、抽出済コンテンツに一致がある場合のみ、ドキュメントの抽出済コンテンツが返されます。強調表示では、その特定のメタデータ値との一致があった場合にのみ、ドキュメントのメタデータが表示されます。
一致がドキュメントのメタデータのみであった場合は、一致したメタデータ・フィールドのみがリストされ、抽出済コンテンツはリストされません。
OpenSearchの構成
この項では、WebCenter Content用のOpenSearchの構成、クラスタのヘルスのモニターおよび索引設定の構成を行う方法を学習します。
WebCenterコンテンツは、既存のOCI OpenSearchクラスタに接続します。
この項の内容は次のとおりです。
WebCenter Content用のOpenSearchの構成
WebCenter Content用にOpenSearchを構成する前に、OpenSearch検索インデクサを有効にして、必須の初期構成設定を行う必要があります。
初期構成設定を次の図に示します。
前述のステップを実行していない場合は、WebCenter Content管理対象サーバーを停止し、config.cfgファイルで次のパラメータを設定します:
SearchIndexerEngineName=OPENSEARCHここで、WebCenter Content管理対象サーバーを起動します。
WebCenter Content用のOpenSearchを構成するには、次のステップに従います:
- WebCenter Content管理対象サーバーを起動します。
- 「管理」、「OpenSearch」、「OpenSearch構成」の順に選択します。
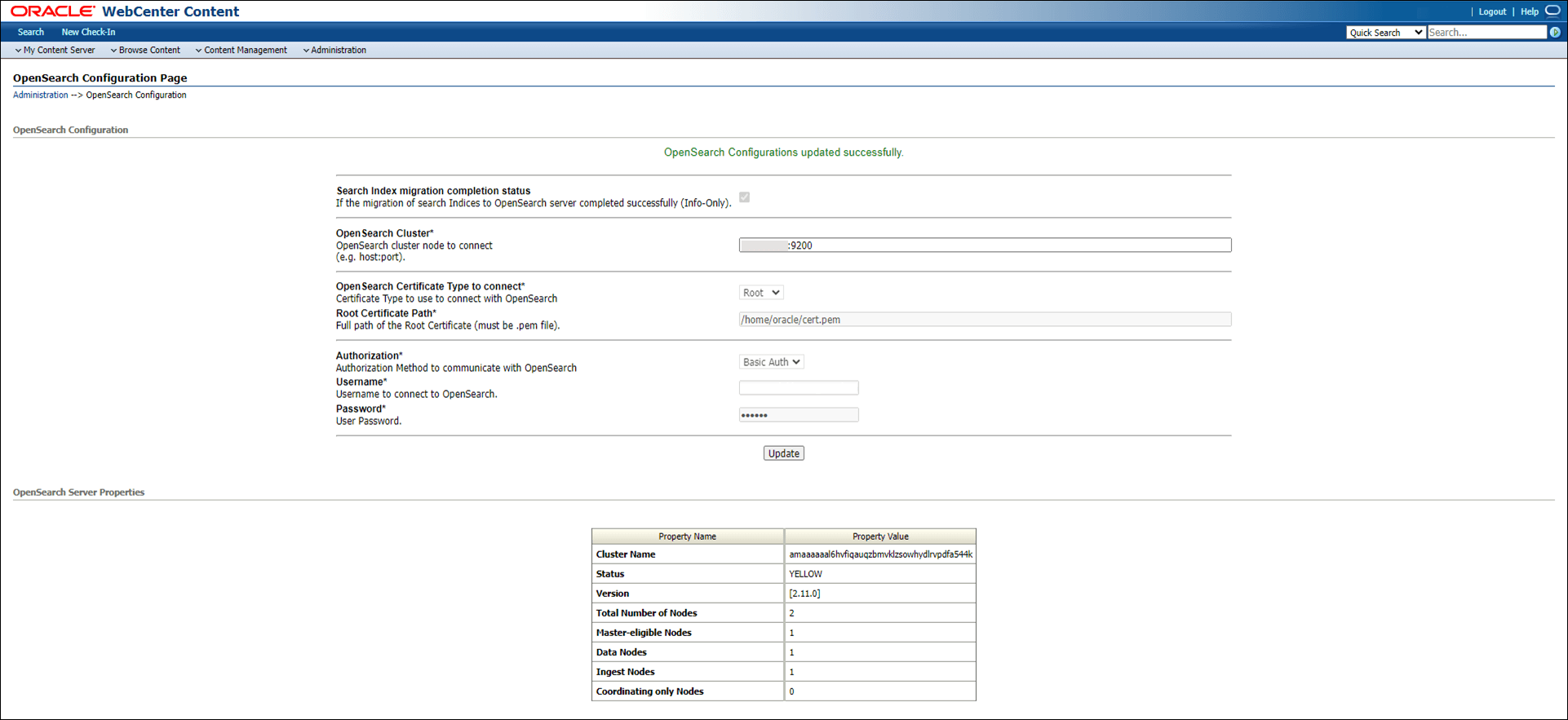
-
次の図に示すように、「OpenSearch構成」ページで、次のフィールドに値を入力します:
- OpenSearchクラスタ - クラスタのOpenSearchノードのカンマ区切りリスト
- 接続するOpenSearch証明書タイプ - OpenSearchに接続するための証明書タイプ
- ルート証明書のパス - ルート証明書の絶対パス
- 認可 - OpenSearchと通信する方法 ノート: OpenSearch 2.xを使用している場合は、認可方式として「Basic認証」を使用する必要があります。
OCIを使用したWebCenter Content用のOpenSearchの構成
OCIを使用してWebCenter Content用のOpenSearchを構成するには、次のステップに従います:
- WebCenter Contentインスタンスの場合、WebCenter Contentドメイン・ファイルおよびディレクトリを所有するユーザー(通常はユーザー
oracle)としてログインしたシェルを開きます。 - ディレクトリを
<WCC domain path>に変更します。 -
OpenSearch証明書を取得するには、WebCenter Contentインスタンスのシェルで次のコマンドを実行します:
openssl s_client -showcerts -connect <OpenSearch private IP>:9200 </dev/null | sed -n -e '/-.BEGIN/,/-.END/ p' > cert.pem -
WebCenter ContentインスタンスからOpenSearchクラスタへの接続をテストするには:
/usr/bin/curl -u <username>:<password> https:<OpenSearch private IP>:9200 –insecureこれは、WebCenter ContentインスタンスがOSクラスタにアクセスできるかどうかを確認するための単純なテストにすぎません。成功すると、次が返されます:
[oracle@wcctestinstance ~]$ /usr/bin/curl -u <username>:<password> https://<OpenSearch private IP>:9200 { "name" : "opensearch-master-0", "cluster_name" : "amaaaaaal6hvfiqauqzbmvklzsowhydlrvpdfa544kitmgdymnugepq5nkwq", "cluster_uuid" : "EtrnIgjXQmmuK4gBdf02xg", "version" : { "distribution" : "opensearch", "number" : "2.11.0", "build_type" : "tar", "build_hash" : "unknown", "build_date" : "2024-05-28T05:20:26.940869407Z", "build_snapshot" : false, "lucene_version" : "9.7.0", "minimum_wire_compatibility_version" : "7.10.0", "minimum_index_compatibility_version" : "7.0.0" }, "tagline" : "The OpenSearch Project: https://opensearch.org/" } - シェルで、ディレクトリを
<WCC domain path>/ucm/cs/configに変更します。クラスタ化されたWebCenter Contentの場合、config.cfgファイルは、WebCenter Contentで使用されるファイル共有の下に配置されます。 -
config.cfgファイルを編集します。次のエントリをSearchIndexerEngineName=OPENSEARCHSearchIndexerEngineNameがOracleTextSearchまたはDATABASE.METADATAに設定されている場合、それらの行を削除するかコメント・アウトします。 - ファイルを保存し、終了します。
- WebCenter Content管理対象サーバーを再起動します。
- WebCenter Contentページを開きます。
- 「管理」、「OpenSearch」、「OpenSearch構成」の順に選択します。
- 「OpenSearch構成」ページで、WebCenter Content用のOpenSearchの構成の説明に従って、フィールドの値を入力します。「更新」ボタンをクリックします。
WebCenter ContentがOpenSearchに接続すると、次のステータスが表示されます:
- 緑: OpenSearchは3つのマスター・ノードおよびデータ・ノード用に構成されました。
- 黄: OpenSearchは単一ノード・クラスタ用に構成されました。これは、単一ノードがレプリケート・シャードを分散できないためです。これは無視することができ、索引付けおよび検索には影響しません。
OpenSearchの初期構成では、初期コレクションの再構築は必要ありません。「OpenSearch構成」ページのパラメータが完了し、WebCenter ContentがOpenSearchに接続されると、コレクションの再構築は必要ありません。
構成の一部として、(WebCenter Contentセキュリティ・グループに基づく) OpenSearch索引が作成されます。アイテムはチェックインして検索できます。以前にチェックインされたアイテムも検索可能です。
ノート: 新しいメタデータ・フィールドを作成する場合、または別のWebCenter ContentインスタンスのフィールドをCMUを使用して移行する場合は、作成またはCMUインポート後、ただちに高速再構築を実行します。
高速再構築が実行されるまで:
- 新しいフィールド値が移入された新しいコンテンツをチェックインしないでください。
- フィールド値が移入されているインポート・コンテンツをアーカイブしないでください。
高速再構築では、索引にそのフィールドがまだ存在していないフィールドで、フィールド値に索引付けする必要がある場合、完了までに非常に時間がかかります。詳細は、ElasticSearch高速再構築の完了に長時間かかるを参照してください。
OpenSearchクラスタ・ヘルスの監視
WebCenter Contentが正しく機能するには、OpenSearchクラスタ・ヘルスが良好であることが重要です。
この機能は、OpenSearchのヘルスを1時間間隔で監視するために導入されました。OpenSearchのヘルス問題のステータスが赤または接続が停止している場合、OpenSearchのヘルス・ステータスが緑または黄になるまで、アラートが1分ごとに追加および監視されます。OpenSearchヘルスのステータスが緑または黄に変わると、ヘルス・アラートは自動的に削除され、その後は1時間ごとに監視が続行されます。
索引設定の構成
必要なデータに従って、異なる索引のシャードおよびレプリカを構成できます。
この新機能により、OpenSearch索引ごとにシャード数およびレプリカ数をカスタマイズできます。OpenSearchの設計に従って、OpenSearchの各索引はWebCenter Contentのセキュリティ・グループにマップされます。索引は、次の場合に作成されます:
- サーバーの起動
- 新規セキュリティ・グループがシステムに追加されました
- コレクションの再構築または再索引付け
- 他の検索エンジンからOpenSearchへの移行
シャードおよびレプリカは、ユーザー構成に基づいてシステムに作成されるときに索引に割り当てられます。これらの設定に対する更新は、次の完全再構築または再索引付けサイクルの後にのみ反映されます。シャード数およびレプリカ数に制限を設定できます。
シャード数: 5から300の範囲の整数値である必要があります。デフォルト値は5です。
レプリカ数: 1または2である必要があります。デフォルト値は1です。
OpenSearchとの接続が確立されておらず、索引がまだ作成されていない場合は、既存のOpenSearchアラートとともに追加のオプション・アラートが表示されます。
アラート・メッセージをクリックすると、OpenSearch索引設定ページにリダイレクトされます。このページでは、システムに存在するセキュリティ・グループ(索引)ごとにシャードおよびレプリカをカスタマイズできます。
OpenSearchとの接続の確立が成功すると、これらのカスタマイズされた設定を持つ索引が作成されます。他の検索エンジンからOpenSearchに移行する場合、これらの索引をカスタマイズされた設定で作成するには、移行が成功する必要があります。
すでに構成されているOpenSearchインスタンスの場合、索引はデフォルトの索引設定で作成されます。
索引設定を構成するには:
- 「管理」、「OpenSearch」、「OpenSearch索引設定」の順に選択します。
-
「索引設定の構成」ページでは、目的のシャードおよびレプリカ数で索引を構成できます。更新されたシャードおよびレプリカ設定は、次の後に反映されます:
- 次の完全再構築または再索引付けサイクル
- 新規インスタンスでの正常な接続の確立
- 別の検索エンジンから切り替える場合の移行 特定の索引を更新することはできません。「更新」ボタンをクリックすると、すべてのレコードが更新されます。
-
OpenSearchサーバーから取得されたすべてのアクティブな索引とそのシャードおよびレプリカ設定を表示するには、アクティブな索引設定タブを選択します。

新規セキュリティ・グループの追加
WebCenter ContentからOpenSearchサーバーへの接続が成功した後に新しいセキュリティ・グループが追加されると、対応する索引がデフォルト・シャード数(5)およびレプリカ数(1)でOpenSearchに作成されます。
設定をカスタマイズする場合は、OpenSearch索引設定ページから行うことができますが、これらは次の再構築または再索引付けサイクルの後にのみ反映されます。
既存の検索索引のOpenSearchへの移行
WebCenter Contentサーバーが以前に他の検索エンジン(OTS、FULLTEXT、Elasticsearchなど)で構成されていて、検索エンジンがOpenSearchに変更された場合は、コンテンツを移行する必要があります。
移行するには、「管理」、「OpenSearch」、「OpenSearch移行」の順に選択します。次の図は、ElastisearchからOpenSearchへの移行を示しています。ElastisearchからOpenSearchへの移行中、「移行する検索エンジン」ドロップダウン・メニューでは「メタデータ」オプションのみを使用できます。
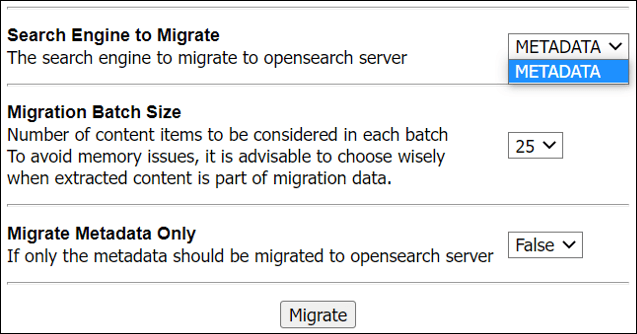
「移行バッチ・サイズ」は、OpenSearchサーバーにプッシュするためにまとめてバッチとして含めるドキュメント数を決定します。バッチ・サイズを慎重に選択する必要があります。バッチには、ドキュメントのテキスト抽出コンテンツとそのメタデータも含まれます。
「メタデータのみ移行」は、テキスト抽出コンテンツをOpenSearchサーバーにプッシュする必要があるかどうかを指定します。OpenSearchのようなフルテキスト検索エンジンの場合、これは常にFalseに設定する必要があります。つまり、テキスト抽出コンテンツもOpenSearchサーバーにプッシュする必要があります。
移行アクティビティの開始時に、最近のすべての移行ジョブとそのステータス詳細の表がリストされます。