Search interfaces allow your end-users to search on multiple properties and/or dimensions simultaneously.
A search interface is a named collection of properties and dimensions, each of which has its Enable Record Search option checked. A search interface may also contain a number of attributes such as name, cross-field matching configuration, and an ordered collection of one or more ranking strategies that determine the order of search results.
The search interface's name is used just like a normal property or dimension when performing record searches. A record search query on a search interface returns results that match any of the properties or dimensions in the interface.
For example, if a data set contains both an Actor property and Director dimension, it would be useful to provide the end-user with the ability to search for a person's name in both. In this case you might create a search interface called People that contained both the Actor property and the Director dimension.
All search interfaces are shown in the Search Interfaces view on the Project tab.
To view all of your search interfaces at once:
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
The Search Interfaces view displays all of the search interfaces established in your project, their member dimensions and properties, as well as any associated relevance ranking strategies.
The Search Interfaces view contains the following columns.
|
Field |
Description |
|---|---|
|
Name |
A unique name for this search interface. NoteA search interface cannot share a name with a dimension value or a property.
|
|
Members |
The dimensions and Endeca properties that make up this search interface. |
|
Ranking Strategy |
The ranking modules associated with this search interface. |
Create new search interfaces within the Search Interfaces editor of the Search Interfaces view.
To create a new search interface:
On the Project tab, double-click Search Interfaces to open the Search Interface view.
In the Search Interface view, click New.
The Search Interfaces editor appears.
From the Allow Cross-field Matches list, choose Always, Never, or On Failure. The Allow Cross-field Matches option specifies when the MDEX Engine should try to match search queries across dimension or property boundaries, but within the members of the search interface. There are three possible values:
In the All (Searchable) Members list, select a member and click Add to add it to the Selected Members list. Repeat as many times as necessary to add additional members to the search interface.
Only Endeca properties and dimensions that have their Enable record search option checked appear in this list.
( Optional) If you want to associate a relevance ranking strategy to the search interface, click Relevance Ranking Modules.
( Optional ) If you want to make more detailed adjustments to the search interface, click Options and configure the Customize partial match settings, which specify if partial matches for search terms should be supported for this search interface.
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
Select a search interface from the Search Interfaces view to change it in the editor.
To edit a search interface:
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
Remove search interfaces from the Search Interfaces view.
To delete a search interface:
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
You use the Search Interface editor to create a new search interface or modify the attributes of an existing one.
The Search Interface editor contains the following fields:
The Allow Cross-field Matches option, in the Search Interface editor, specifies when the MDEX Engine should try to match search queries across dimension or property boundaries, but within the members of the search interface.
There are three possible values:
The MDEX Engine always looks for matches across dimension or property boundaries, in addition to matches within a dimension or property. This is the default.
The MDEX Engine does not look across dimension or property boundaries for matches.
The MDEX Engine only tries to match queries across dimension or property boundaries if it fails to find any matches within a single dimension or property.
Note
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
This section describes customizations available in the Customize Partial Match Settings feature of Developer Studio.
The Customize Partial Match Settings feature specifies if partial matches for search terms should be supported for this search interface.
To customize partial matching in a search interface:
In the Search Interface Options editor, check Customize Partial Match Settings.
The Match at Least ... Words and Omit at Most ... Words text boxes are each populated with 2 (the suggested value).
In the Match at Least ... Words text box, modify the minimum number of words that must match in order to consider a match.
You cannot enter 0 for this value.
In the Omit at Most ... Words text box, modify the maximum number of words that can be omitted in order to consider a match.
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Advanced Development Guide for details.
A snippet contains the search terms that the user provides along with a portion of the term’s surrounding content to provide context.
The snippeting feature (also referred to as keyword in context) provides the ability to return an excerpt from a record—a snippet—to an application user who performs a record search query. A snippet contains the search terms that the user provides along with a portion of the term’s surrounding content to provide context. A Web application displays these snippets on the record list page of a query’s results. With the added context, a user can more quickly choose the individual records they are interested in.
You enable snippeting on individual members (fields) in a search interface that typically have many lines of content. For example, fields such as Description, Abstract, DocumentBody, and so on are good candidates to provide snippeting results.
For example, if a user searches for intense in a wine catalog, the record list for this query has many records that match intense. A snippet for each matching record displays on a record list page:
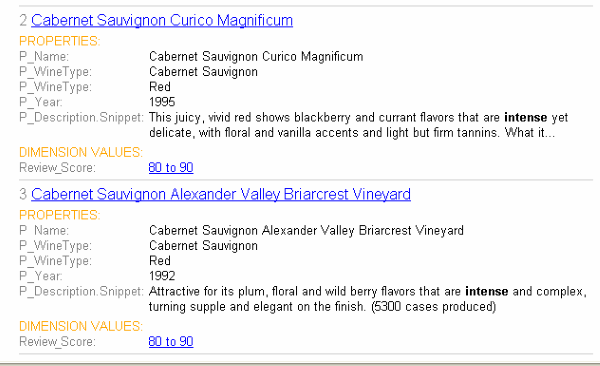
A snippet consists of search terms, surrounding context words, and ellipses.
A snippet can contain any
number of search terms bracketed by
<endeca_term></endeca_term> tags. The
tags call out search terms and allow you to more easily reformat the terms for
display in your Web application.
The snippet size is the total number of search terms and surrounding context words. You can configure the total number of words in a snippet as described in Enabling snippeting. In order to adhere to the size setting for a snippet, it is possible that the MDEX Engine may omit some search terms and context words from a snippet. This situation becomes more likely if an application user provides a large number of search terms and the maximum snippet size is comparatively small.
A snippet consists of one or more segments. The segments are delimited by ellipses in between them. Ellipses (...) indicate that there is text omitted from the snippet occurring before or after the ellipses.
For example, here is a snippet made up of two segments with a maximum
size set at 20 words. The snippet resulted from a search for the search terms
Scotland and British which are enclosed within
<endeca_term> tags.
...in Edinburgh
<endeca_term>Scotland</endeca_term>,
and has been employed by Ford for 25 years ... He first joined
Ford's
<endeca_term>British</endeca_term>
operation. Mazda motor ...
Note
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
The MDEX Engine dynamically creates new snippet properties by
appending .Snippet to the original name of the search interface members (fields) that
you enabled for snippeting.
For example, if you enable snippeting
for properties named
Description
and
Reviews, the MDEX Engine creates new properties named Description.Snippet and
Reviews.Snippet
and returns these properties with the result set for a user's
record search.
Note
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Advanced Development Guide for details.
The snippet property appears with a record only on a record list page.
It is important to emphasize that the MDEX Engine dynamically generates snippet properties. This means the snippet properties, unlike other Endeca properties, are not created, configured, or mapped using Developer Studio. A dynamically generated snippet property is not tagged to an Endeca record.
Note
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
You enable the snippeting feature in the Member Options dialog box, which is accessed from the Search Interface editor.
You enable the snippeting feature in the Member Options dialog box, which is accessed from the Search Interface editor. Each member of a search interface is enabled and configured separately. In other words, snippeting results are enabled and configured for each member of a search interface and not for all members of a single search interface.
A search interface member is a dimension or property that has been enabled for search and that has been added to the Selected members pane of the Search Interface editor. You can enable and configure any number of individual search interface members. Each member that you enable produces its own snippet.
Enabling a member in one search interface does not affect that member if it appears in other search interfaces. For example, enabling the Description property for Search Interface A does not affect the Description property in Search Interface B.
To configure a search interface member for snippeting results:
Open your project file in Developer Studio and double-click Search Interfaces.
Either create a new search interface or select an existing one from the Search Interfaces view and click Edit.
From the Selected Member area of the Search Interface editor, click a member that you want to configure for snippeting.
The Member Options dialog box displays.
From the Member Options dialog box, check Enable snippeting.
Specify the maximum snippet size (number of words) a snippet can contain.
Repeat steps 3-7 if you want to configure additional search interface members.
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
You can increase the maximum size of snippets to include more context words.
If you are not seeing enough context words in your snippet, open the Member Options editor and increase the value for Maximum Snippet Size. The default value is 25 words.
Note
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Basic Development Guide for details.
You use relevance ranking to control the order in which record search results are displayed to the end-user.
You use relevance ranking to control the order in which record search results are displayed to the end-user. Typically, relevance ranking is used to ensure that the most important search results are displayed earliest to the user, since users are generally unlikely to page or scan through large result sets.
The importance of a particular record search result is generally an application-specific concept. Thus, the relevance ranking feature provides a flexible, configurable set of ranking modules. These modules are then grouped into strategies that can be used in combination to produce a wide range of relevance ranking effects. Each search interface has its own ranking strategy.
Relevance ranking contains a rich set of features that should be used advisedly. Misuse of relevance ranking strategies can cause unexpected results and degraded performance.
Ranking modules are selected from a stock list of modules. The Static and Phrase modules both take parameters.
You may have multiple instances of the Static module, however, you should only have one instance of the Phrase module for each search interface.
To assign one or more ranking modules to a search interface:
In the Search Interface editor, click Relevance Ranking Modules.
The Relevance Ranking Modules editor appears.
In the All Modules list, select a relevance ranking module and click Add.
The module is moved to the Selected Modules list.
Note
Selecting a module causes a brief description to appear in the frame in the lower left corner of the editor.
If you selected the Static module, edit the Static module parameters.
If you selected the Phrase module, edit the Phrase module parameters.
(Optional) Repeat step 2 to add additional modules to the search interface.
(Optional) Use the up and down arrows to adjust the relative rank of the modules in your ranking strategy.
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Advanced Development Guide for details.
Edit ranking modules from the Relevance Ranking Modules editor, in the Search Interface editor.
To edit a ranking module in a search interface:
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Advanced Development Guide for details.
Delete ranking modules from the Relevance Ranking Modules editor.
To remove a ranking module from a search interface:
In the Search Interfaces view, select the search interface you want to modify and click Edit to open it in the Search Interface editor.
In the Search Interface editor, click Relevance Ranking Modules.
The Relevance Ranking Modules editor appears.
In the Selected Modules list, select the module you want to delete and click Remove.
Implementing search features requires additional work outside of Developer Studio. Please refer to the Endeca Advanced Development Guide for details.
Select and move modules as needed from the Relevance Ranking Modules editor.
By default, ranking modules are evaluated in the order in which you created them.
To change the order of ranking modules:
In the Search Interfaces view, select the search interface you want to modify and click Edit to open it in the Search Interface editor.
In the Search Interface editor, click Relevance Ranking Modules.
The Relevance Ranking Modules editor appears.
In the Selected Modules list, select a module that you want to move and click either the up arrow or the down arrow until the module is in the correct order.
Edit static module parameters from the Relevance Ranking Modules editor.
The Static relevance ranking module, which indicates that a constant score be applied to a given result, is one of two modules that take parameters. You can apply it to a specific searchable dimension or property, and specify whether the records will be sorted in ascending or descending order. You can have multiple Static modules, as long as they have different configurations.
To rank the members of a dimension or property statically:
In the All Modules list, select Static and click Add. The Edit Static Relevance Rank Module editor appears.
In the New Property or Dimension list, select the property or searchable dimension to which you want to apply the static ranking module.
Check Sort Records in Descending Order if you want the resulting records sorted in that order. If you want the records sorted in ascending order (the default), make sure the checkbox is cleared.
Edit phrase modules parameters from the Relevance Ranking Modules editor.
You can use only one Phrase module in any given search interface, but you can set all of your options in it.
The Phrase relevance ranking module states that results containing the user's query as an exact phrase, or a subset of the exact phrase, should be considered more relevant than matches simply containing the user's search terms scattered throughout the text. Phrase is one of two modules that take parameters.
To edit Phrase module parameters:
In the All Modules list, select Phrase and click Add. The Edit Phrase Relevance Rank Module editor appears.
Set the following options. See "Phrase" for detailed descriptions, interaction information, and examples of how to use these options.
Rank based on length of subphrases: Ranks results based on the length of their subphrase matches. In other words, results that match three terms are considered more relevant than results that match two terms, and so on.
Use approximate subphrase/phrase matching: When enabled, the Phrase module looks at a limited number of positions in each result that a phrase match could possibly exist, rather than all the positions.
Apply spell correction, thesaurus, and stemming: When enabled, the Phrase module ranks results that match a phrase's expanded forms in the same stratum as results that match the original phrase.
Relevance ranking contains a rich set of features that should be used advisedly.
Misuse of relevance ranking strategies can cause unexpected results and degraded performance. See the Endeca Advanced Development Guide for detailed information on relevance ranking and recommended strategies.
The Exact module provides a finer grained (but more computationally expensive) alternative to the Phrase module.
The Exact module groups results into three strata based on how well they match the query string:
The Exact module is computationally expensive, especially on large text fields. It is intended for use only on small text fields (such as dimension values or small property values like part IDs). This module should not be used with large or offline documents (such as FILE or ENCODED_FILE properties). Use of this module in these cases will result in very poor performance and/or application failures due to request timeouts. The Phrase module does similar but less sophisticated ranking and can be used as a higher performance substitute.
The Field module ranks documents based on the search interface field with the highest priority in which it matched.
Only the best field in which a match occurs is considered. The Field module is often used in relevance ranking strategies for catalog applications, because the category or product name is typically a good match. Field assigns a score to each result based on the static rank of the dimension or property member or members of the search interface that caused the document to match the query .
In Developer Studio, static field ranks are assigned based on the order in which members of a search interface are listed in the Search Interfaces view. The first (left-most) member has the highest rank.
By default, matches caused by cross-field matching are assigned a score of zero. The score for cross-field matches can be set explicitly in Developer Studio by moving the <<CROSS_FIELD>> indicator up or down in the Selected Members list of the Search Interface editor. The <<CROSS_FIELD>> indicator is available only for search interfaces that have the Field module and are configured to support cross-field matches.
All non-zero ranks must be non-equal and only their order matters. For example, a search interface might contain both Title and DocumentContent properties, where hits on Title are considered more important than hits on DocumentContent (which in turn are considered more important than <<CROSS_FIELD>> matches). Such a ranking is implemented by assigning the highest rank Title, the next highest rank to DocumentContent, and setting the <<CROSS_FIELD>> indicator at the bottom of the Selected Members list in the Search Interface editor.
If a document matches on multiple fields, it is ranked based on the best field that it matches.
Note
The Field module is only valid for record search operations. This module assigns a score of zero to all results for other types of search requests.
Designed primarily for use with unstructured data, the First module ranks documents by how close the query terms are to the beginning of the document.
First groups its results into variably-sized strata. The strata are not the same size, because while the first word is probably more relevant than the tenth word, the 301st is probably not so much more relevant than the 310th word. This module takes advantage of the fact that the closer something is to the beginning of a document, the more likely it is to be relevant.
The First module works as follows:
When the query has a single term, First's behavior is straight-forward: it retrieves the first absolute position of the word in the document, then calculates which stratum contains that position. The score for this document is based upon that stratum; earlier strata are better than later strata .
When the query has multiple terms, First behaves as follows:
With query expansion (using stemming, spelling correction, or the thesaurus), the First module treats expanded terms as if they occurred in the source query. For example, the phrase glucose intolerence would be corrected to glucose intolerance (with intolerence spell-corrected to intolerance). First then continues as it does in the non-expansion case. The first position of each term is computed and the median of these is taken.
In a partially matched query, where only some of the query terms cause a document to match, First behaves as if the intersection of terms that occur in the document and terms that occur in the original query were the entire query. For example, if the query cat bird dog is partially matched to a document on the terms cat and bird, then the document is scored as if the query were cat bird.
First works for partial match modes, such as MatchPartial, as well as for MatchAll. For partial matches, First ranks documents based on the median position of the matching terms.
First does not work with Boolean searches, cross-field matching, or wildcard search. It assigns all such matches a score of zero.
The Frequency (freq) module provides result scoring based on the frequency (number of occurrences) of the user's query terms in the result text.
Results with more occurrences of the user search terms are considered more relevant.
Frequency values are capped at 1024.
The Glom module ranks single-field matches ahead of cross-field matches.
This module serves as a useful tie-breaker function in combination with the Maximum Field module. It is only useful in conjunction with record search operations.
The Interpreted (interp) ranking module is a general-purpose module that assigns a score to each result based on the query processing techniques used to obtain the match.
Matching techniques considered include partial matching, cross-field matching, spelling correction, thesaurus, and stemming matching (discussed in detail in the Endeca Advanced Development Guide).
Specifically, the interpreted ranking module ranks results as follows:
All non-partial matches are ranked ahead of all partial matches.
Within the above layer, all single-field matches are ranked ahead of all cross-field matches.
Within the above layer, all non-spelling-corrected matches are ranked above all spelling-corrected matches.
Within the above layer, all non-thesaurus matches are ranked above all thesaurus matches.
Within the above layer, all non-stemming matches are ranked above all stemming (word form) matches.
Unlike Field, which assigns a static score to cross-field matches, Maximum Field selects the score of the highest-ranked field that contributed to the match.
The Maximum Field (maxfield) module behaves identically to the Field module, except in how it scores cross-field matches.
Because Maximum Field defines the score for cross-field matches dynamically, it does not make use of the <<CROSS_FIELD>> indicator set in the Search Interface editor.
The Nterms module ranks matches according to how many query terms they match.
For example, in a three-word query, results that match all three words will be ranked above results that match only two, which will be ranked above results that match only one.
The Nterms module is only applicable to search modes where results can vary in how many query terms they match. These include MatchAny, MatchPartial, MatchAllAny, and MatchAllPartial. For details on specifying a search mode for a query, see the Endeca Advanced Development Guide.
The Number of Fields (numfields) module ranks results based on the number of fields in the associated search interface in which a match occurs.
Note that we are counting whole-field rather than cross-field matches, for example, a result that matches two fields matches each field completely, while a cross-field match typically does not match any field completely.
The Phrase module states that results containing the user's query as an exact phrase, or a subset of the exact phrase, should be considered more relevant than matches simply containing the user's search terms scattered throughout the text.
Note the following points about the Phrase module:
If a query contains only one word, then that word constitutes the entire phrase and all of the matching results will be put into one stratum (score = 1).
Because of the way hyphenated words are positionally indexed, Oracle recommends that you enable subphrase if your results contain hyphenated words.
When you add the Phrase module in the Relevance Ranking Modules editor, you are presented with an editor that allows you to set these options.
The Phrase module has a variety of options that you use to customize its behavior:
Subphrasing ranks results based on the length of their subphrase matches. In other words, results that match three terms are considered more relevant than results that match two terms, and so on.
When you configure the Phrase module, you have the option of enabling subphrasing.
A subphrase is defined as a contiguous subset of the query terms the user entered, in the order that he or she entered them. For example, the query "fax cover sheets" contains the subphrases "fax," "cover," "sheets," "fax cover," "cover sheets," and "fax cover sheets," but not "fax sheets."
Content contained inside nested quotation marks in a phrase is treated as one term. For example, consider the following phrase: "the question is 'to be or not to be.' " The quoted text, "to be or not to be," is treated as one query term, so this example consists of four query terms even though it has a total of nine words.
When subphrasing is not enabled, results are ranked into two strata: those that matched the entire phrase and those that didn't.
The approximate setting is appropriate in cases where the runtime performance of the standard Phrase module is inadequate because of large result contents and/or high site load.
Approximate matching provides higher-performance matching, as compared to the standard Phrase module, with somewhat less exact results. With approximate matching enabled, the Phrase module looks at a limited number of positions in each result that a phrase match could possibly exist, rather than all the positions. Only this limited number of possible occurrences is considered, regardless of whether there are later occurrences that are better, more relevant matches.
Enabling positional indexing increases the number of occurrences that the Phrase module looks at, thereby increasing the accuracy of the approximate phrase matching results. See Using positional indexing with the Phrase module for more information.
Describes available functions with query expansion enabled.
Applying spelling correction, thesaurus, and stemming adjustments to the original phrase is generically known as query expansion. With query expansion enabled, the Phrase module ranks results that match a phrase's expanded forms in the same stratum as results that match the original phrase. Consider the following example:
The query, "US government," is expanded to "United States government" for matching purposes, but the Phrase module gives a score of two to any results matching "United States government" because the original, unexpanded version of the query, "US government," only had two terms.
Edit phrase modules parameters from the Relevance Ranking Modules editor.
You can use only one Phrase module in any given search interface, but you can set all of your options in it.
The Phrase relevance ranking module states that results containing the user's query as an exact phrase, or a subset of the exact phrase, should be considered more relevant than matches simply containing the user's search terms scattered throughout the text. Phrase is one of two modules that take parameters.
To edit Phrase module parameters:
In the All Modules list, select Phrase and click Add. The Edit Phrase Relevance Rank Module editor appears.
Set the following options. See "Phrase" for detailed descriptions, interaction information, and examples of how to use these options.
Rank based on length of subphrases: Ranks results based on the length of their subphrase matches. In other words, results that match three terms are considered more relevant than results that match two terms, and so on.
Use approximate subphrase/phrase matching: When enabled, the Phrase module looks at a limited number of positions in each result that a phrase match could possibly exist, rather than all the positions.
Apply spell correction, thesaurus, and stemming: When enabled, the Phrase module ranks results that match a phrase's expanded forms in the same stratum as results that match the original phrase.
You should only use one Phrase module in any given search interface and set all of your options in it.
The three configuration settings for the Phrase module can be used in a variety of combinations for different effects. The following matrix describes the behavior of each combination. You should only use one Phrase module in any given search interface and set all of your options in it.
|
Subphrase |
Approximate |
Expansion |
Behavior |
|---|---|---|---|
|
Off |
Off |
Off |
Default. Ranks results into two strata: those that match the user's query as a whole phrase, and those that do not. |
|
Off |
Off |
On |
Ranks results into two strata: those that match the original, or an extended version, of the query as a whole phrase, and those that do not. |
|
Off |
On |
Off |
Ranks results into two strata: those that match the original query as a whole phrase, and those that do not. Look only at the first possible phrase match within each record. |
|
Off |
On |
On |
Ranks results into two strata: those that match the original, or an extended version, of the query as a whole phrase, and those that do not. Look only at the first possible phrase match within each record. |
|
On |
Off |
Off |
Ranks results into N strata where N equals the length of the query and each result's score equals the length of its matched subphrase. |
|
On |
Off |
On |
Ranks results into N strata where N equals the length of the query and each result's score equals the length of its matched subphrase. Extend subphrases to facilitate matching but rank based on the length of the original subphrase (before extension). |
|
On |
On |
Off |
Ranks results into N strata where N equals the length of the query and each result's score equals the length of its matched subphrase. Look only at the first possible phrase match within each record. |
|
On |
On |
On |
Ranks results into N strata where N equals the length of the query and each result's score equals the length of its matched subphrase. Expand the query to facilitate matching but rank based on the length of the original subphrase (before extension). Look only at the first possible phrase match within each record. |
Phrase, like the other relevance ranking modules, is never applied to the results of MatchBoolean queries.
Endeca provides a variety of match modes to facilitate matching during search (MatchAny, MatchAll, MatchPartial and so on). These modes only determine which results match a user's query; they have no effect on how the results are ranked after the matches have been found. Therefore, the Phrase module works as described in this section, regardless of match mode. The one exception to this rule is MatchBoolean.
When using the Phrase module, stop words are always treated like non-stop word terms and stratified accordingly.
For example, the query 'raining cats and dogs' will result in a rank of two for a result containing 'fat cats and hungry dogs' and a rank of three for a result containing 'fat cats and dogs' (this example assumes subphrase is enabled).
If a single result has multiple subphrase matches, either within the same field or in several different fields, the result is slotted into a stratum based on the length of the longest subphrase match.
An entire phrase, or subphrase, must appear in a single field in order for it to be considered a match. (In other words, matches created by glomming fields together are not considered by the Phrase module.)
The Phrase module translates each wildcard in a query into a generic placeholder for a single term.
For example, the query "sparkling w* wine" becomes "sparkling * wine" during phrase relevance ranking, where "*" indicates a single term. This generic wildcard replacement causes slightly different behavior when subphrasing is and isn't enabled.
When subphrasing is not enabled, all results that match the generic version of the wildcard phrase exactly are still placed into the first stratum. It is important, however, to understand what constitutes a matching result from the Phrase module's point of view.
Consider the search query "sparkling w* wine" with the MatchAny mode enabled. In MatchAny mode, search results only need to contain one of the requested terms to be valid, so a list of search results for this query could contain phrases that look like this:
When phrase relevance ranking is applied to these search results, the Phrase module looks for matches to "sparkling * wine" not "sparkling w* wine." Therefore, there are three results-"sparkling white wine," "sparkling refreshing wine," and "sparkling wet wine"-that are considered phrase matches for the purposes of ranking. These results are placed in the first stratum. The other two results are placed in the second stratum.
When subphrasing is enabled, the behavior becomes a bit more complex. Again, we have to remember that wildcards become generic placeholders and match any single term in a result. This means that any subphrase that is adjacent to a wildcard will, by definition, match at least one additional term (the wildcard). Because of this behavior, subphrases break down differently. The subphrases for "cold sparkling w* wine" break down into the following (note that w* changes to *):
Notice that the subphrases "sparkling," "wine," and "cold sparkling" are not included in this list. Because these subphrases are adjacent to the wildcard, we know that the subphrases will match at least one additional term. Therefore, these subphrases are subsumed by the "sparkling *", "* wine", and "cold sparkling *" subphrases.
Like regular subphrase, stratification is based on the number of terms in the subphrase, and the wildcard placeholders are counted toward the length of the subphrase. To continue the example above, results that contain "cold" get a score of one, results that contain "sparkling *" get a score of two, and so on. Again, this is the case even if the matching result phrases are different, for example, "sparkling white" and "sparkling soda."
Finally, it is important to note that, while the wildcard can be replaced by any term, a term must still exist. In other words, search results that contain the phrase "sparkling wine" are not acceptable matches for the phrase "sparkling * wine" because there is no term to substitute for the wildcard. Conversely, the phrase "sparkling cold white wine" is also not a match because each wildcard can be replaced by one, and only one, term. Even when wildcards are present, results must contain the correct number of terms, in the correct order, for them to be considered phrase matches by the Phrase module.
Designed primarily for use with unstructured data, the Proximity module ranks how close the query terms are to each other in a document by counting the number of intervening words.
Like First, this module groups its results into variable sized strata, because the difference in significance of an interval of one word and one of two words is usually greater than the difference in significance of an interval of 21 words and 22.
Single words and phrases get assigned to the best stratum because there are no intervening words. When the query has multiple terms, Proximity behaves as follows:
All of the absolute positions for each of the query terms are computed.
The smallest range that includes at least one instance of each of the query terms is calculated. This range's length is given in number of words. The score for each document is the strata that contains the difference of the range's length and the number of terms in the query; smaller differences are better than larger differences.
Under query expansion (that is, stemming, spelling correction, and the thesaurus), the expanded terms are treated as if they were in the query, so the proximity metric is computed using the locations of the expanded terms in the matching document.
For example, if a user searches for big cats and a document contains the sentence, "Big Bird likes his cat" (stemming takes cats to cat), then the proximity metric is computed just as if the sentence were, "Big Bird likes his cats."
Proximity scores partially matched queries as if the query only contained the matching terms. For example, if a user searches for cat dog fish and a document is partially matched that contains only cat and fish, then the document is scored as if the query cat fish had been entered.
Proximity interacts with other features as follows:
Proximity works for partial match modes, such as Match Partial, as well as for MatchAll. For partial matches, Proximity ranks documents based on the median position of the matching terms.
Proximity does not work with Boolean searches, cross-field matching, or wildcard search. It assigns all such matches a score of zero.
The Static module assigns a static or constant data-specific value to each search result, depending on the type of search operation performed and depending on optional parameters that can be passed to the module.
For record search operations, the first parameter to the module specifies a property, which will define the sort order assigned by the module. The second parameter can be specified as ascending or descending to indicate the sort order to use for the specified property.
For example, using the module Static(Availability,descending) would sort result records in descending order with respect to their assignments from the Availability property. Using the module Static(Title,ascending) would sort result records in ascending order by their Title property assignments. In a catalog application, setting the static module by Price, descending leads to more expensive products being displayed first.
For dimension search, the first parameter can be specified as nbins, depth, or rank:
Specifying nbins causes the static module to sort result dimension values by the number of associated records in the full data set.
Depth causes the static module to sort result dimension values by their depth in the dimension hierarchy.
Rank causes dimension values to be sorted by the ranks assigned to them for the application.
The Weighted Frequency module scores results based on frequency of user terms, and weights those frequencies for each result by the content of each term.
Like the Frequency module, the Weighted Frequency (wfreq) module scores results based on the frequency of user query terms in the result. Additionally, the Weighted Frequency module weights the individual query term frequencies for each result by the information content (overall frequency in the complete data set) of each query term. Less frequent query terms (that is, terms that would result in fewer search results) are weighted more heavily than more frequently occurring terms.
Weighted Frequency values are capped at 1024.