|
|
通常、管理者は、設定済みの MASTER マシンで日常的な管理タスクを行います。MASTER マシン上の DBBL は、コンフィグレーション内のほかのマシンをモニタし、コンフィグレーションを更新し、TMIB への動的な変更をブロードキャストします。マシンのクラッシュ、データベースの破壊、Oracle Tuxedo システムの問題、ネットワークの分断、アプリケーションの障害などが原因で MASTER マシンに障害が発生しても、アプリケーションは停止しません。クライアントのアプリケーションへの参加、サーバからのサービス要求の発行、およびローカル マシンでの名前指定は引き続き可能です。ただし、MASTER マシンが復元されない限り、サーバをアクティブまたは非アクティブにしたり、管理者側でシステムを動的に再コンフィグレーションすることはできません。
同様のことがアプリケーション サーバにも当てはまります。アプリケーション サーバは、特定のマシン上でクライアントのリクエストを処理するようにコンフィグレーションされていますが、マシンに障害が発生したり、停止する必要が生じると、そのマシン上のサーバは使用できなくなります。このような場合は、設定済みの BACKUP マシンまたは代替マシンにサーバを移行することができます。
停止の準備 (サービスまたはアップグレードのため) として移行を行う場合、マシン障害に固有の問題は管理者に通知されません。したがって、この場合の管理者は、高レベルの権限で移行作業を管理できます。
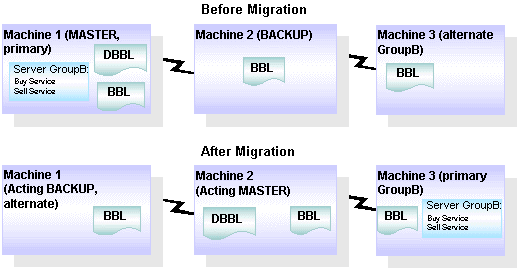
Master マシンの移行とは、設定済みの MASTER マシンから設定済みの BACKUP マシンに DBBL を移動するプロセスのことです。このプロセスにより、設定済みの MASTER マシンがダウンしていても、サーバは引き続きサービスを提供することができます。移行を行うには、まず、設定済みの BACKUP マシンを代理の MASTER マシンとし、設定済みの MASTER マシンを代理の BACKUP マシンとするよう、管理者側から要求します。これで、すべての管理機能は、代理の MASTER マシンで行われます。つまり、コンフィグレーション内のほかのマシンをモニタし、コンフィグレーションの動的な変更を受け付けます。
次の図では、マシン 2 (設定済みの BACKUP マシン) が代理の MASTER マシンになり、マシン 1 (設定済みの MASTER マシン) が代理の BACKUP マシンになっています。設定済みの MASTER マシンが利用できるようになると、代理の MASTER マシン (設定済みの BACKUP マシン) から再びアクティブにされます。設定済みの MASTER マシンには、代理の MASTER マシンを制御する権限が再び与えられます。
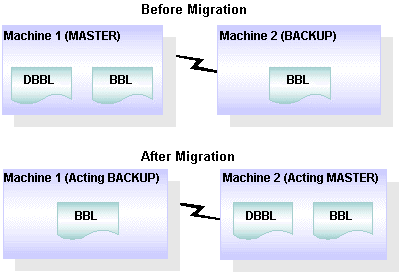
管理者は、各サーバ グループに対してプライマリ マシンと代替マシンを指定します。サーバ グループの移行プロセスでは、代替マシン上のサーバ グループをアクティブにします。
次の図では、グループ A がマシン 1 (プライマリ マシン) に割り当てられ、マシン 2 がグループ A の代替マシンとして割り当てられています。移行後、グループ A はマシン 2 でアクティブ化されます。つまり、このグループ内のすべてのサーバおよび関連するサービスは、マシン 2 (代理のプライマリ マシン) で提供されます。
単に 1 つのサーバ グループを移行することも便利ですが、実際には、マシン全体の移行の方が必要です。たとえば、コンピュータに障害が発生した場合にこのタイプの移行が必要になります。マシンの移行には、そのマシン上で稼動する各サーバ グループを移行することも含まれます。各サーバ グループには、代替マシンを設定する必要があります。
制御された状況 (コンピュータをオフラインにしたり、アップグレードする必要がある場合など) では、管理者は、サーバやサービスの現在のコンフィグレーション情報を保存し、これらの情報を、代替マシンでサーバをアクティブにするときに使用できます。コンフィグレーション情報をこのように使用できるのは、サーバが非アクティブになり、移行の要求に応答できなくなっても、サーバ エントリがプライマリ マシンに保持されるためです。
移行処理では、サーバ グループ全体を移行することも、マシン全体を移行することもできます。マシン全体の移行は、プライマリ マシン上のすべてのサーバ グループに対して同じマシンが代替マシンとして設定されている場合に可能です。これ以外の場合 (プライマリ マシン上の異なるサーバ グループに対して別々の代替マシンが設定されている)、サーバはマシン単位ではなく、グループ単位で移行しなければなりません。
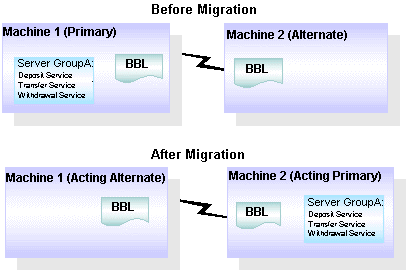
次の図では、マシン 1 が設定済みの MASTER マシンおよびグループ B のプライマリ マシンであり、マシン 2 が設定済みの BACKUP です。サーバ グループ B には、プライマリ マシンとしてマシン 1 が設定されており、代替マシンとしてマシン 3 が設定されています。マシン 1 がダウンすると、マシン 2 が代理の MASTER マシンとなります。サーバ グループ B は非アクティブになり、代替マシンであるマシン 3 に移行され、再びアクティブになります。
グループ内のすべてのサーバを非アクティブにしたら、代理のプライマリ マシンから代理の代替マシンにグループを移行できます。実行中のサーバ、現在宣言されているサービス、および動的に変更されたコンフィグレーション内容を指定する必要はありません。設定済みの代替マシンは、設定済みのプライマリ マシン上で利用可能なサーバ (非アクティブの場合) のコンフィグレーション情報から、これらの情報を取得します。使用されているデータ依存型ルーティングが代替マシンでも適用される場合、サービスは、ルーティング先のグループ名 (マシン名ではない) に基づいてルーティングされます。
移行の対象がアプリケーションの一部であっても、全体であっても、サービスの中断を最小限に抑えるように変更処理を行ってください。アプリケーションのマシン、ネットワーク、データベース、およびその他のコンポーネントの整合性は、そのままにしておく必要があります。Oracle Tuxedo システムにはアプリケーションの移行時に、すべてのコンポーネントの整合性を保持するための方法が用意されています。
Oracle Tuxedo システムでの移行作業には、次の種類があります。
上記のアプリケーション コンポーネントの組み合わせに従って移行を行い、分断されたネットワークを回復するためのユーティリティを使用すると、マシン全体を移行できます。
MASTER マシンを保守のために停止する場合、または予想外の問題が原因でアクセスできなくなった場合 (ネットワークの分断など) は、MASTER マシンでの作業を設定済みの BACKUP マシンに移行する必要があります。
| 注意 : | MASTER マシンと BACKUP マシンで同じリリースの Oracle Tuxedo ソフトウェアを実行していることを確認してから MASTER マシンを移行してください。 |
この種の移行は、DBBL を MASTER マシンから BACKUP マシンへ移行することによって実現できます。DBBL を移行するには、次のコマンドを入力します。
ほとんどの場合、アプリケーション サーバを代替サイトに移行するか、または MASTER マシンを復元する必要があります。tmadmin コマンドの詳細については、『Tuxedo コマンド リファレンス』の「tmadmin(1)」リファレンス ページを参照してください。
次の 2 つの tmadmin セッションの例では、MASTER マシンと BACKUP マシンの切り替え方法を示しています。ここでは、BACKUP マシンから MASTER にアクセスできるかどうかは無関係です。最初の例では、BACKUP マシンから MASTER にアクセスできるため、DBBL プロセスは MASTER マシンから BACKUP マシンへ移行されます。
$ tmadmin
tmadmin - Copyright © 1987-1990 AT&T; 1991-1993 USL. All rights reserved.
> master
よろしいですか? [y,n] y
SITE1 から SITE2 にアクティブな DBBL を移行しています。お待ちください。
DBBL は SITE1 から SITE2 に移行しました。
> q
2 番目の例では、BACKUP マシンから MASTER マシンにアクセスできないため、DBBL プロセスは BACKUP マシン上に作成されます。
$ tmadmin
tmadmin - Copyright © 1987-1990 AT&T; 1991-1993 USL. All rights reserved.
TMADMIN_CATT:199: 管理者になることができません。一部のコマンドが利用できます。
> master
よろしいですか? [y,n] y
SITE2 上に新しい DBBL を作成しています。お待ちください。新しい DBBL を SITE2 に作成しました。
> q
UBBCONFIG ファイルの GROUPS セクションで、移行されるサーバ グループの LMID パラメータに代替ロケーションを指定します。そのグループ内のサーバには RESTART=Y を指定し、UBBCONFIG ファイルの RESOURCES セクションで MIGRATE オプションを指定する必要があります。tmshutdown -R -ggroupname
tmadmin セッションを開始します。tmadmintmadmin のプロンプトで、次のどちらかのコマンドを入力します。TLOG を BACKUP マシンに移動し、それをロードしてウォームスタートを行います。
プライマリ マシンから代替マシンにアクセスできる場合は、次の手順でサーバ グループを移行します。
プライマリ マシンから代替マシンにアクセスできない場合は、必要に応じて次の手順で MASTER マシンと BACKUP マシンを切り替えます。
次の 2 つのセッション例では、サーバ グループの移行方法を示しています。ここでは、プライマリ マシンから代替マシンにアクセスできるかどうかは無関係です。最初の例では、プライマリ マシンから代替マシンにアクセスできます。
$ tmshutdown -R -g GROUP1
アプリケーションのサーバ プロセスを停止します。
サーバ ID = 1 グループ ID = GROUP1 マシン = SITE1: 停止しました。
1 個のプロセスが終了しました。
$ tmadmin
tmadmin - Copyright © 1987-1990 AT&T; 1991-1993 USL.
> migg GROUP1
移行が正常終了しました。
> q
2 番目の例では、プライマリ マシンから代替マシンにアクセスできません。
$ tmadmin
tmadmin - Copyright © 1987-1990 AT&T; 1991-1993 USL.
> pclean SITE1
DBBL のクリーニングをしています。
システムが安定するまで 10 秒間お待ちください。
掲示板から 3 個の SITE1 サーバを削除しました。
> migg GROUP1
移行が正常終了しました。
> boot -g GROUP2
アプリケーションのサーバ プロセスを起動します。
exec simpserv -A :
on SITE2 -> プロセス ID=22699 を起動しました。
1 個のプロセスを起動しました。
> q
LMID を使用して、サーバ グループが稼働するプロセッサを指定します。LMID のすべてのサーバ グループに対して同じ代替ロケーションを指定します。 UBBCONFIG ファイルの RESOURCES セクションで、次のようにパラメータを設定します。tmshutdown-R
migratemach (migm) コマンドを使用してすべてのサーバ グループを 1 つのマシンから別のマシンに移行します。このコマンドでは、引数として 1 つの論理マシン識別子を指定します。
プライマリ マシンから代替マシンにアクセスできる場合は、次の手順でマシンを移行します。
プライマリ マシンから代替マシンにアクセスできない場合は、必要に応じて次の手順で MASTER マシンと BACKUP マシンを切り替えます。
次のセッションの例は、マシンの移行方法を示しています。最初の例では、プライマリ マシンから代替マシンにアクセスできます。
$ tmshutdown -R -l SITE1
アプリケーションのサーバ プロセスを停止します。
サーバ ID = 1 グループ ID = GROUP1 マシン = SITE1: 停止しました。
1 個のプロセスが終了しました。
$ tmadmin
tmadmin - Copyright © 1987-1990 AT&T; 1991-1993 USL.
> migm SITE1
移行が正常終了しました。
> q
2 番目の例では、プライマリ マシンから代替マシンにアクセスできません。
$ tmadmin
tmadmin - Copyright © 1987-1990 AT&T; 1991-1993 USL.
>pclean SITE1
DBBL のクリーニングをしています。
システムが安定するまで 10 秒間お待ちください。
掲示板から 3 個の SITE1 サーバを削除しました。
> migm SITE1
移行が正常終了しました。
> boot -l SITE2
アプリケーションのサーバ プロセスを起動します。
exec simpserv -A :
on SITE2 -- プロセス ID=22782 を起動しました。
1 個のプロセスを起動しました。
>q
サーバ グループまたはマシンを非アクティブにした後で移行作業を中止したい場合は、再びサーバ グループまたはマシンをアクティブにする前に移行を取り消すことができます。ネーム サーバ内にある、非アクティブにされたサーバとサービスの情報はすべて削除されます。
停止を実行しても、migrate コマンドを実行する前であれば、次のコマンドを使用して移行を取り消すことができます。
次の tmadmin セッションの例は、サーバ グループとマシンが、対応するプライマリ マシンと代替マシン間で移行される手順を示しています。
$tmadmin
tmadmin - Copyright © 1987-1990 AT&T; 1991-1993 USL.
> psr -g GROUP1
a.out 名 キュー名 グループ名 ID 要求終了 ロード終了 現サービス
---------- ---------- -------- -- ------ ------- ---------------
simpserv 00001.00001 GROUP1 1 - - (DEAD MIGRATING)
> psr -g GROUP1
TMADMIN_CAT:121: そのようなサーバはありません。
migg -cancel GROUP1
>boot -g GROUP1
アプリケーションのサーバ プロセスを起動します。
exec simpserv -A:
on SITE1 ->プロセス ID_27636 を起動しました。1 個のプロセスを起動しました。
> psr -g GROUP1
a.out 名 キュー名 グループ名 ID 要求終了 ロード終了 現サービス
---------- ---------- -------- -- ------ ------- ---------------
simpserv 00001.00001 GROUP1 1 - - ( - )
> q
トランザクション ログを BACKUP マシンに移行するには、次の手順に従います。
tmadmin セッションを開始します。tmadminTLOG をダンプします。dumptlog [-zconfig] [-ooffset] [-nfilename] [-ggroupname]
| 注意 : | TLOG は、引数 config および offset を使用して指定します。offset はデフォルトで 0 に設定されます。name はデフォルトで TLOG に設定されます。-g オプションを選択すると、TMS によって調整された、groupname のレコードだけがダンプされます。 |
filename を BACKUP マシンにコピーします。TLOG にファイルを読み込みます。loadtlog -mmachine filename
TLOG を強制的にウォームスタートさせます。logstartmachine
TLOG の情報が読み込まれ、この情報を使用して共有メモリ内のトランザクション テーブルにエントリが作成されます。
BACKUP マシンに移行します。
 
|