
|
|
この章では、BEA AquaLogic Data Services Platform を使用したクライアント プログラムに関するさまざまな機能について説明します。 トピックは以下のとおりです。
BEA AquaLogic Data Services Platform はシステム カタログ タイプ データ サービスである Catalog Services を通じて、データ サービス、アプリケーション、関数、スキーマに関するメタデータを保持します。 カタログ サービスは、任意の AquaLogic Data Services Platform アプリケーション、データ サービス、スキーマ、関数と関係に関する情報をプログラム的に取得するために、クライアント アプリケーション開発者に便利な方法を提供します。 カタログ サービスはデータ サービスでもあるので、AquaLogic データ サービス コンソール、AquaLogic Data Services Platform Palette およびデータ サービス コントロールを使用して表示することができます。
この節では、あらゆる AquaLogic Data Services Platform アプリケーションでメタデータにアクセスできるよう、カタログ サービスのインストールと使用の詳細を説明します。 この章の内容は以下のとおりです。
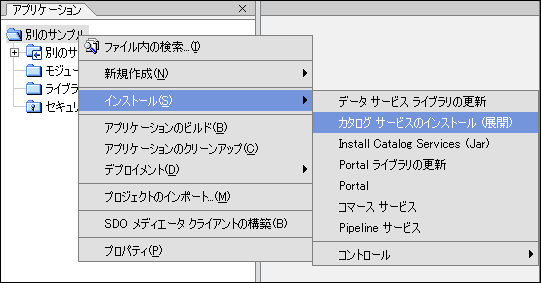
カタログ サービスは、AquaLogic Data Services Platform アプリケーションのプロジェクトとして、または WebLogic Workshop のライブラリ フォルダへ追加する JAR ファイルとしてインストールすることができます。 カタログ サービス プロジェクト (_catalogservices) には、アプリケーション、フォルダ、データ サービス、関数、スキーマおよびアプリケーションで使用可能な関係の情報を提供するデータサービスが含まれています。
DataServiceRef と SchemaRef は追加データサービスで、AquaLogic Data Services Platform アプリケーションで使用可能なデータ サービスとスキーマのパスを取得する関数から構成されます。 カタログ サービスで使用可能なデータサービスと関数の詳細については、カタログ サービスの使用を参照してください。
プロジェクトとしてカタログ サービスをインストールするには、以下の手順に従います。
カタログ サービスのインストール後、AquaLogic Data Services Platform アプリケーション用にカタログ サービスプロジェクトの _catalogservices が作成されます。 このプロジェクトでは、カタログ サービスに関連するすべてのデータサービスが使用可能です。 データサービス関数を呼び出して、メタデータにアクセスできます。 カタログ サービス メソッドを呼び出すには、クライアントの Mediator API を使用します。
_catalogservices にあるデータ サービスには以下のトピックが含まれています。
| 注意 : | カタログ サービスで使用可能なデータ サービス関数を使用するには、以下のサイトで利用できるコード サンプルを参照してください。 |
| 注意 : | http://dev2dev.bea.com/wiki/pub/CodeShare/Sample1/catalogsrv_output.zip |
以下の表には、Application.ds にある getApplication() 関数の宣言と説明が示されています。
表 11-3 は DataService.ds で使用可能な関数の宣言と説明を示します。
<urn:DataService kind="javaFunction" xmlns:acc="ld:RTLAppDataServices/CustomerDB/Customer" xmlns:urn="urn:metadata.ld.bea.com">
|
||
以下の表は DataServiceRef.ds で使用可能な関数の宣言と説明を示します。
以下の表は Folder.ds. で使用可能な関数の宣言と説明を示します。
以下の表に Function.ds の関数の宣言と説明を示す。
以下の表は Relationship.ds. で使用可能な関数の宣言と説明を示す。
| 注意 : | Relationship.ds の関数は、ナビゲーション関数のみに使われるメタデータへのアクセスに使用できる。 |
<urn:Relationship xmlns:acc="ld:RTLAppDataServices/CustomerDB/CUSTOMER" xmlns:urn="urn:metadata.ld.bea.com">
|
以下の表は Schema.ds. で使用可能な関数の宣言と説明を示す。
以下の表は SchemaRef.ds. で使用可能な関数の宣言と説明を示す。
フィルタ API により、クライアント アプリケーションはデータ サービス関数によって戻される情報にフィルタ条件を適用できます。 ある意味では、フィルタは、関数によりデータ オブジェクトをどのように実体化するか、また、関数をどのように戻すかをより詳細に指定することで、クライアント アプリケーションがデータ サービス インタフェースを拡張することを可能にします。
フィルタ API により、データ サービスの設計者は、クライアントが要求する可能性があるすべてのデータ ビューを予測しなくてもすむようになり、また、各ビューにデータ サービス関数を実装する必要がなくなります。 代わりに、設計者は、ビジネス エントリにアクセスするために、インタフェースをより幅のある一般的なものとして指定し、フィルタを通じてクライアント アプリケーションから思いとおりにビューをコントロールすることができます。
関数が返すオブジェクトのうち、条件と一致するオブジェクトだけが、クライアントに戻されます。 (サーバで評価されますので、フィルタされたオブジェクトはネットワークにより渡されることはありません。 フィルタにより除かれたオブジェクトは、基底のソースから取得さえできません。) フィルタは、XQuery や SQL 文の WHERE 句に似て、可能性のある結果セットに条件を適用します。 AND や OR 演算子を使って、複数のフィルタ条件を適用できます。 フィルタ条件に適用できる他の演算子は、表 11-10 のリストに表示されています。
| 注意 : | フィルタ API Javadoc は他の AquaLogic Data Services Platform API とともに、「AquaLogic Data Services Platform Mediator API Javadoc」に記述されています。 |
フィルタ機能は、Mediator および Data Service コントロール クライアント アプリケーションが使用できます。 フィルタ条件を使用して、戻すデータを特定したり、データをソートしたり、戻されるレコードの数に制限をかけることができます。 Mediator クライアント アプリケーションでフィルタを使用するには、適切なパッケージをインポートし、与えられたインタフェースを使用してフィルタ条件を生成、適用します。 Data Service コントロール クライアントにより、自動的にインタフェースが取得されます。 関数がコントロールに追加されると、対応する「 WithFilter 」関数も同じように追加されます。
com.bea.ld.filter.FilterXQuery; FilterXQuerymyFilter = newFilterXQuery();
addFilter() メソッドには、以下のような異なるパラメータを持つ複数の署名があります。
public void addFilter(java.lang.String appliesTo,
java.lang.String field,
java.lang.String operator,
java.lang.String value,
java.lang.Boolean everyChild)
appliesTo はフィルタによる影響を受けるノードを示す。 つまり、フィールド引数によって指定されたノードが条件に一致しない場合、appliesTo ノードがフィルタにより除かれます。 field はフィルタ条件をテストするノードである。 operator と value はともに条件文を構成する。 operator パラメータは、特定の value に対して作成された比較の型を指定します。 利用可能な演算子に関する情報は、表 11-10 フィルタ演算子 を参照してください。everyChild は省略可能なパラメータである。 デフォルトでは false に設定されています。 このパラメータを ture に設定すると、フィルタ基準に一致する子要素のみが返されることになります。 たとえば、演算子 GREATER_THAN (または「>」) と値 1000 を設定することで、すべての注文が 1000 を超える顧客のレコードだけが戻されます。 1000 未満の量の注文がある顧客は、たとえ他の注文の量が 1000 を超えていても戻されません。
以下は 1000 以上の量の注文を含む注文を戻す add filter メソッドの例です (everyChild が指定されていないので、1000 以下の量の注文も戻ることに注意してください)。
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
">",
"1000");CUSTOMER custDS = CUSTOMER.getInstance(ctx, "RTLApp");
custDS.setFilterCondition(myFilter);
特定の要素値を false にしたフィルタ条件を適用した場合、要素は結果セットに含まれません。 フィルタによって除かれた要素は、addFilter() 関数の最初の引数として指定されます。
求める結果次第で、フィルタの効果は異なります。 たとえば、図 11-1 にある CUSTOMERS データ オブジェクトと想定します。 複数の複雑な要素 (CUSTOMER と ORDERS) や、ORDER_AMOUNT を含むいくつかの単純な要素が含まれています。 この階層の任意の要素にも、フィルタを適用できます。
一般的には、ネストされた XML データにおいて、「CUSTOMER/ORDER/ORDER_AMOUNT> 1000」のような条件は、どのようなオブジェクトが返されるかについて、複数の方法で影響を及ぼすことができます。 たとえば、1000 未満の ORDERS を取り除き、すべての CUSTOMER オブジェクトを戻すことが可能です。
また、最低、1つの大きな注文を持つ CUSTOMER オブジェクトのみを戻したり、すべての ORDER オブジェクトを各 CUSTOMER に戻すこともできます。 さらに、ORDER が 1000 を超える CUSTOMER オブジェクトのみを戻すこともできます。たとえば、
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter( "CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000",true);
省略可能な 4 番目のパラメータ everychild = true は、デフォルトで属性が false であることに注意してください。 このパラメータを true に設定することで、それぞれ ORDER が 1000 超える CUSTOMER オブジェクトのみ戻ります。
FilterXQuery myFilter = new FilterXQuery();
Filter f1 = myFilter.createFilter(
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER", f1);
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter("CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter("CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
最後の例は、複数の機能を持つフィルタです。つまり、2 つの条件を持つフィルタです。リスト 11-1 では、AND 演算子を使用してフィルタの組み合わせを、結果セットおよび与えられたデータ サービス インスタンス customerDS に適用します。
FilterXQuery myFilter = new FilterXQuery();
Filter f1 = myFilter.createFilter("CUSTOMER_PROFILE/ADDRESS/ISDEFAULT",
FilterXQuery.NOT_EQUAL,"0");
Filter f2 = myFilter.createFilter("CUSTOMER/ADDRESS/STATUS",
FilterXQuery.EQUAL,
"\"ACTIVE\"");
Filter f3 = myFilter.createFilter(f1,f2, FilterXQuery.AND);
Customer customerDS = Customer.getInstance(ctx, "RTLApp");
CustomerDS.setFilterCondition(myFilter);
クライアント アプリケーション コードで使用できるフィルタの型に、順序付け条件もあります。データ サービスから戻される結果の順序 (昇順、降順) を指定します。 メソッド (FilterXQuery クラスの addOrderBy()) は、プロパティ名を昇順や降順の判断基準とします。リスト 11-2 では、顧客プロファイルを、その人が顧客となった日に基づいて昇順で戻すフィルタを生成する例を説明します。
FilterXQuery myFilter = new FilterXQuery();
myFilter.addOrderBy("CUSTOMER_PROFILE",
"CustomerSince" ,FilterXQuery.ASCENDING);
ds.setFilterCondition(myFilter);
DataObject objArrayOfCust = (DataObject) ds.invoke("getCustomer", null);
同様に、関数から戻される結果の最大数を設定できます。 setLimit() 関数は、配列要素の中の要素数を指定した数に制限します。 そして、繰り返しのノードで、戻される結果の制限をかける場合に、その意味があります。 (繰り返しのないノードで制限を設定しても、結果が短縮されるわけではありません。)
リスト 11-3 では、SetLimit() 関数の使用方法について説明します。 結果セット (アクティブ アドレスをフィルタ) 中のアクティブなアドレス数を、10 個のデータ サービス インスタンス ds に制限します。
FilterXQuery myFilter = new FilterXQuery();
Filter f2 = myFilter.createFilter("CUSTOMER_PROFILE/ADDRESS",
FilterXQuery.EQUAL,"\"INACTIVE\"");
myFilter.addFilter("CUSTOMER_PROFILE", f2);
myFilter.setLimit("CUSTOMER_PROFILE", "10");
ds.setFilterCondition(myFilter);
アドホック クエリは、データ サービスの一部として定義されていない XQuery 関数です。クライアント アプリケーションのコンテキストで定義されます。 アドホック クエリは、一般的には、クライアント アプリケーションの中で、データ サービス関数を呼び出し、何らかの方法で結果を最適化するために使用します。 アドホック クエリを使って、データ サービスに対して XQuery の正しい式を実行することができます。 式は、データ サービスの基礎にある、実際のデータ ソースをターゲットにすることができます。また、データ サービスによって提供される関数やプロシージャを使用することができます。
XQuery の式を実行するには、Mediator API で使用できる PreparedExpression インタフェースを使用します。 PreparedExpression インタフェースは、JDBC の PreparedStatement と同様に、JNDI サーバ コンテキストやアプリケーション名とともに、XQuery 式をコンストラクタの文字列とします。 用意された式オブジェクトをこの方法で作成した後、executeQuery( ) メソッドを呼び出すことができます。 アドホック クエリがデータ サービス関数やプロシージャを呼び出した場合、データ サービスのネームスペースは、アドホック クエリでメソッドを参照する前にクエリ 文字列にインポートする必要があります。
リスト 11-4 では、詳細な例について説明しています。ネームスペースにある getCustomers( ) という名前のデータ サービス関数の結果がコードにより戻されます。
ld:DataServices/RTLServices/Customer
import com.bea.ld.dsmediator.client.PreparedExpression;
String queryStr =
"declare namespace ns0=\"ld:DataServices/RTLServices/Customer\";" +
"<Results>" +
" { for $customer_profile in ns0:getCustomer()" +
" return $customer_profile }" +
"</Results>";
PreparedExpression adHocQuery =
DataServiceFactory.prepareExpression(context,"RTLApp",queryStr );
XmlObject objResult = (XmlObject) adHocQuery.executeQuery();
AquaLogic Data Services Platform は、XMLObject データ型として、アドホック クエリに情報を戻します。 XMLObject であれば、デプロイされた XML スキーマのデータ型にダウンキャストできます。 XMLObject は、ルート型を 1 つのみ保持しているため、データ サービス関数が配列を戻す場合、アドホック クエリに配列のコンテナとしてルート要素を含めなければなりません。
たとえば、リスト 11-4 のアドホック クエリは、<Results> コンテナ オブジェクトを特定し、その中には、getCustomer() データ サービス関数により戻される CUSTOMER_PROFILE 要素の配列があります。
データ サービスで定義されているセキュリティ ポリシーは、アドホック クエリの中のデータ サービスの呼び出しにも同様に適用されます。 アドホック クエリが保護されたリソースを使用している場合は、JNDI 初期コンテキストの作成時に適切な資格を送る必要があります (詳細については、「AquaLogic Data Services Platform 用のWebLogic JNDI コンテキストの取得」を参照してください)。
JDBC の PreparedStatement インタフェースのように、PreparedExpression インタフェースは、アドホック クエリの式における動的なバインディング変数をサポートします。 さまざまなデータ型の値をバインディングするため、PreparedExpression は複数のメソッド (bindType( ) メソッドは表 11-12 を参照) を提供します。
bindType メソッドを使用するには、たとえば、以下のように、この値に対応する XML 修飾名 (QName) を変数名として送ります。
adHocQuery.bindInt(new QName("i"),94133);
リスト 11-5 では、bindInt() メソッドをアドホック クエリのコンテキスト内で使用する例について説明しています。
PreparedExpression adHocQuery = DataServiceFactory.preparedExpression(
context, "RTLApp",
"declare variable $i as xs:int external;
<result><zip>{fn:data($i)}</zip></result>");
adHocQuery.bindInt(new QName("i"),94133);
XmlObject adHocResult = adHocQuery.executeQuery();
| 注意 : | QName に関する詳細については、以下を参照してください。 |
リスト 11-6 では、アドホック クエリの詳細な例について説明しています。PreparedExpression インタフェースと QName を使用し、バインド メソッドの中で値を送っています。
import com.bea.ld.dsmediator.client.DataServiceFactory;
import com.bea.ld.dsmediator.client.PreparedExpression;
import com.bea.xml.XmlObject;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.xml.namespace.QName;
import weblogic.jndi.Environment;
public class AdHocQuery
{
public static InitialContext getInitialContext() throws NamingException {
Environment env = new Environment();
env.setProviderUrl("t3://localhost:7001");
env.setInitialContextFactory("weblogic.jndi.WLInitialContextFactory");
env.setSecurityPrincipal("weblogic");
env.setSecurityCredentials("weblogic");
return new InitialContext(env.getInitialContext().getEnvironment());
}
public static void main (String args[]) {
System.out.println("========== Ad Hoc Client ==========");
try {
StringBuffer xquery = new StringBuffer();
xquery.append("declare variable $p_firstname as xs:string external; \n");
xquery.append("declare variable $p_lastname as xs:string external; \n");
xquery.append(
"declare namespace ns1=\"ld:DataServices/MyQueries/XQueries\"; \n");
xquery.append(
"declare namespace ns0=\"ld:DataServices/CustomerDB/CUSTOMER\"; \n\n");
xquery.append("<ns1:RESULTS> \n");
xquery.append("{ \n");
xquery.append(" for $customer in ns0:CUSTOMER() \n");
xquery.append(" where ($customer/FIRST_NAME eq $p_firstname \n");
xquery.append(" and $customer/LAST_NAME eq $p_lastname) \n");
xquery.append(" return \n");
xquery.append(" $customer \n");
xquery.append(" } \n");
xquery.append("</ns1:RESULTS> \n");
PreparedExpression pe = DataServiceFactory.prepareExpression(
getInitialContext(), "RTLApp", xquery.toString());
pe.bindString(new QName("p_firstname"), "Jack");
pe.bindString(new QName("p_lastname"), "Black");
XmlObject results = pe.executeQuery();
System.out.println(results);
} catch (Exception e) {
e.printStackTrace();
}
}
この節では、Data Service Mediator API を使用したクライアント プログラムに関するプログラムのさまざまなトピックについて説明します。 内容は以下のとおりです。
標準データ サービス インタフェースにて関数が呼び出されると、要求されたデータは、まずサーバ マシンのシステム メモリ内で実体化されます。 関数が大量のデータを戻すことを目的とする場合、メモリ内のデータの実体化は実用的でない場合があります。 たとえば、管理を行う関数が、AquaLogic Data Services Platform で公開されるデータの「inventory reports」を生成する場合が考えられます。 このような場合、AquaLogic Data Services Platform では、情報を出力ストリームとして提供します。
AquaLogic Data Services Platform では、WebLogic XML Streaming API をストリーミング インタフェースとして呼び出します。 WebLogic XML Streaming API は標準 SAX (XML の Streaming API) インタフェースと似ています。 しかし、SAX で使われるイベント ハンドラが複雑であるのに対し、WebLogic Streaming API によって、データ オブジェクト要素を段階的に進む中で、XML ドキュメントのストリームベース (またはプルベースの) のハンドリングを使用することができます。 WebLogic Streaming API は SAX インタフェースよりも多くのコントロールを利用可能であり、そのなかで、利用するアプリケーションがイベントを初期化します。たとえば、応答する代わりに、属性を反復したり、次の要素まで移動します。
| 注意 : | Streaming API は大量の結果セットが必要で、メモリに簡単に実体化できない場合に使用することを目的としています。 リアルタイム クエリや大きなバッチ指向クエリの両方を同時にサポートするため、異なるサーバのデータ サービス クエリを起動することが望ましい場合があります。 ただし、2 台のサーバが利用できない場合、オフピーク時には、Streaming API を起動することを検討してください。 |
AquaLogic Data Services Platform では、サーバ側のストリーミングのみをサポートしています。 したがって、JSP はサーバでホストされるため、Streaming API を呼び出すことができます。 ただし、外部の Java アプリケーションではこれを実行できません。
アドホックや型なしのデータ サービス インタフェースを使用して、AquaLogic Data Services Platform をストリームとして取得することができます。
| 注意 : | ストリーミングは、静的なインタフェースではサポートされていません。 WebLogic Streaming API の詳細については、 http://edocs.beasys.co.jp/e-docs/wls/docs81/xml/xml_stream.html の「WebLogic XML Streaming API の使い方」を参照してください。 |
このストリーミング インタフェースは、com.bea.ld.dsmediator.client パッケージ内の以下のクラスにあります。
これらのインタフェースを使用するのは、SDO Mediator クライアント API 等価式を使用するのに似ています。 しかし、戻されるデータは、ドキュメント オブジェクトではなく、XMInputStream です。 複雑な要素 (大量のデータである可能性がある) を入力パラメータとする関数では、XMLInputStream が入力引数としてサポートされています。 以下はその例です:
StreamingDataService ds = DataServiceFactory.newStreamingDataService(
context,
"ld:DataServices/RTLServices/Customer");
XMLInputStream stream = ds.invoke("getCustomerByCustID", "CUSTOMER0");
前述の例では、動的ストリーミング インタフェースについて説明しています。 以下の例では、アドホック クエリを使用しています。
String adhocQuery =
"declare namespace ns0=\"ld:DataServices/RTLServices/Customer\";\n" +
"declare variable $cust_id as xs:string external;\n" +
"for $customer in ns0:getCustomerByCustID($cust_id)\n" +
"return\n" +
" $customer\n";
StreamingPreparedExression expr =
DataServiceFactory.prepareExpression(context, adhocQuery);
クエリの string (上記の例のアドホック クエリ) に外部変数がある場合、以下のことを行う必要があります。
expr.bindString("$cust_id","CUSOMER0");
XMLInputStream xml = expr.executeQuery();| 注意 : | 動的インタフェースとアドホック インタフェースの使用に関する詳細については、「Java クライアントからの Data Services へのアクセス」の「動的 Mediator API の使用」を参照してください。 |
| 注意 : | StreamingDataService インタフェース用の Javadoc と、他の AquaLogic Data Services Platform API は、「AquaLogic Data Services Platform Mediator API Javadoc」に記述されています。 |
リスト 11-7 では、XML 入力ストリームを読み取るメソッドの例について説明しています。 このメソッドは、属性反復子を使用して XML イベントの属性とネームスペースを表示し、エラーが発生すると SMLStream 例外を送出します。
import weblogic.xml.stream.Attribute;
import weblogic.xml.stream.AttributeIterator;
import weblogic.xml.stream.ChangePrefixMapping;
import weblogic.xml.stream.CharacterData;
import weblogic.xml.stream.XMLEvent;
import weblogic.xml.stream.EndDocument;
import weblogic.xml.stream.EndElement;
import weblogic.xml.stream.EntityReference;
import weblogic.xml.stream.Space;
import weblogic.xml.stream.StartDocument;
import weblogic.xml.stream.XMLInputStream;
import weblogic.xml.stream.XMLInputStreamFactory;
import weblogic.xml.stream.XMLName;
import weblogic.xml.stream.XMLStreamException;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class ComplexParse {
public void parse(XMLEvent event)throws XMLStreamException
{
switch(event.getType()) {
case XMLEvent.START_ELEMENT:
StartElement startElement = (StartElement) event;
System.out.print("<" + startElement.getName().getQualifiedName() );
AttributeIterator attributes = startElement.getAttributesAndNamespaces();
while(attributes.hasNext()){
Attribute attribute = attributes.next();
System.out.print(" " + attribute.getName().getQualifiedName() +
"='" + attribute.getValue() + "'");
}
System.out.print(">");
break;
case XMLEvent.END_ELEMENT:
System.out.print("</" + event.getName().getQualifiedName() +">");
break;
case XMLEvent.SPACE:
case XMLEvent.CHARACTER_DATA:
CharacterData characterData = (CharacterData) event;
System.out.print(characterData.getContent());
break;
case XMLEvent.COMMENT:
// Print comment
break;
case XMLEvent.PROCESSING_INSTRUCTION:
// Print ProcessingInstruction
break;
case XMLEvent.START_DOCUMENT:
// Print StartDocument
break;
case XMLEvent.END_DOCUMENT:
// Print EndDocument
break;
case XMLEvent.START_PREFIX_MAPPING:
// Print StartPrefixMapping
break;
case XMLEvent.END_PREFIX_MAPPING:
// Print EndPrefixMapping
break;
case XMLEvent.CHANGE_PREFIX_MAPPING:
// Print ChangePrefixMapping
break;
case XMLEvent.ENTITY_REFERENCE:
// Print EntityReference
break;
case XMLEvent.NULL_ELEMENT:
throw new XMLStreamException("Attempt to write a null event.");
default:
throw new XMLStreamException("Attempt to write unknown event["
+event.getType()+"]");
}
}
WriteOutputToFile メソッドを使用して、データ サービス関数の一連の結果をファイルに書き出すことができます。 この関数は、データ サービスの中で定義される各関数用に、自動的に生成されます。 セキュリティの理由で、サーバのファイル システムにのみファイルを書き出します。
この関数が提供するサービスは、Streaming API に似ています。 データ サービス情報のレポートや在庫の作成を目的としています。 ただし、writeOutputToFile メソッドは、リモート Mediator API から呼び出すことができます。(「ストリーミング インタフェースの使用」で記述されている、Streaming API と比較してください。)
以下の例では、型なしインタフェースからファイルに書き込む方法を説明しています。
StreamingDataService sds =
DataServiceFactory.newStreamingDataService(
context,"RTLApp","ld:DataServices/RTLServices/Customer"");
sds.writeOutputToFile("getCustomer", null, "streamContent.txt");
sds.closeStream();
| 注意 : | フォルダを作成するわけではありません。 上記では、myData という名のフォルダの中にデータを書き込む場合、そのフォルダは、書き込む操作より前に、サーバ ドメイン ルートに存在する必要があります。 |
 
|