



|
|
キャパシティ プランニング プロセスはいくつかの手順で構成されます。以下の節では、これらの手順について説明します。
| 注意 : | このガイドで説明するテストは、適切に管理された環境で実行したものです。個別環境でテストを実行した場合に得られる数値は、ここに示されているテスト結果の数値と異なる場合があります。これらの数値は、キャパシティ プランニング プロセスを分かりやすく説明するためのものです。 |
ここでは、アーキテクトや開発者が WLI アプリケーションを設計する際に、パフォーマンスの面で留意すべき事項について説明します。
サブプロセスの呼び出しには、(サービス コントロールではなく) プロセス コントロールのみを使用するようにしてください。サービス コントロールは、別のサーバやクラスタにある Web サービスや JPD の呼び出しにのみ使用することをお勧めします。プロセス コントロールを使用しても Web サービスにオーバーヘッドがかかることはありません。この点は、CPU と入出力のコストが大きいサービス コントロールとは異なります。
プロセス コントロール コールバックは、JPD インスタンスに直接ルーティングされるため、メッセージ ブローカ サブスクリプションに比べ高速です。フィルタを使用するメッセージ ブローカ サブスクリプションでは、フィルタ値をプロセス インスタンスにマップするためにデータベース アクセスが必要になります。
| 注意 : | 動的サブスクリプションは疎結合に対応しています。したがって、疎結合が必要な場合は、プロセス コントロール コールバックの代わりに動的サブスクリプションを使用して設計することをお勧めします。 |
プロセスがステートフルになり、処理においてステートをデータベースに永続化する必要がない設計であれば、永続性フラグを [なし] または [オーバーフロー時] に変更することを検討してください。
| 注意 : | 永続性を [なし] または [ [オーバーフロー時] に設定しても、クラスタでは正常に機能しない場合があります。 |
ワークリスト API を使用すると、WLI JPD コントロールよりも高速にワークリストにアクセスできます。ただし、コントロールのほうが使用方法やプログラミングが容易です。API で直接ワークリストにアクセスすると、コントロールが内部的にワークリスト API を使用することになり、コントロール ランタイムのオーバーヘッドを軽減できます。
ステートレス JPD はメモリ内で実行され、ステートは永続化されません。したがって、ステートフル JPD を使用する場合に比べパフォーマンスが向上します。プロセスの以前のステートに関する情報が必要ない場合は、ステートレス JPD を使用してください。ステートレス JPD の場合、ステートが永続化されないため入出力コストはかかりません。ステートレス JPD は本質的にスケーラブルです。
非同期プロセスでは、コールバックの場所が WLS JMS キューで、それがプロセスのすべてのインスタンスで同じである場合、負荷が大きくなると WLI パフォーマンスが低下します。
通常、非同期処理は、時間のかかるプロセスで大きな効果を発揮します。一方、同期処理は、あまり時間のかからないタスクに向いています。ただし、同期プロセスがブロックされるアプリケーションではそれがボトルネックとなり、サーバで必要以上のスレッドが使用される結果になる場合があります。
| 注意 : | パフォーマンスに影響する可能性のある設計上の留意事項については、『WLI アプリケーション ライフ サイクルのベスト プラクティス』および「WLI のチューニング」で詳しく説明しています。 |
WLI アプリケーションのパフォーマンスは、アプリケーションの設計だけでなく、それを実行する環境にも大きく左右されます。
環境には、WLI サーバ、データベース、オペレーティング システムとネットワーク、および JVM が含まれます。良好なパフォーマンスを実現するには、すべての構成要素を適切にチューニングする必要があります。
JDBC データ ソース、weblogic.wli.DocumentMaxInlinSize、プロセス トラッキング レベル、B2B メッセージ トラッキング レベル、Log4j などの要素を適切に設定する必要があります。詳細については、「WLI のチューニング」を参照してください。
データベースのチューニング項目としては、初期化パラメータのデフォルト設定、統計情報の生成、ディスク I/O、インデックス化などがあります。詳細については、『Oracle9i データベース チューニング ガイド』を参照してください。
OS とネットワークを適切にチューニングすることで、エラーの発生を抑制し、システムのパフォーマンスを向上させることができます。詳細については、『WebLogic Server パフォーマンス チューニング ガイド』の「オペレーティング システムのチューニング」を参照してください。
JVM のヒープ サイズをチューニングして、ガベージ コレクションにかかる時間を最短にすると同時に、特定の時点でサーバが処理できるクライアントの数を最大にする必要があります。詳細については、『WebLogic Server パフォーマンス チューニング ガイド』の「Java 仮想マシン (JVM) のチューニング」を参照してください。
アプリケーションのパフォーマンス テストを実行したり、負荷生成スクリプトでアプリケーションを呼び出したりするには、アプリケーションを少し変更しなければならない場合があります。
どの程度の変更が必要になるかは、アプリケーションの性質、ロード ジェネレータの性能、キャパシティ プランニング プロセスにどのような成果を期待するか、などによって異なります。
パフォーマンス テストの品質は、使用する作業負荷によって大きく左右されます。
作業負荷は、システムが完了できると想定される処理の量です。つまり、システムでどのくらいのアプリケーションを実行できるか、何人のユーザがシステムに接続して処理を実行できるかです。
作業負荷は、できるだけプロダクション環境に近い状態になるように設計する必要があります。
また、ユーザの思考時間も考慮する必要があります。ユーザがシステムに対して指示を出すまでには、どのような選択肢があるかを考えて意思決定するための時間が必要です。
WLI アプリケーションには、Web サービス、JMS、ファイルという 3 種類のクライアントがあります。ユーザの属性は、たとえば次の図のように表現できます。
作業負荷を設計する際は、以下の要素を考慮に入れる必要があります。
サービス レベル アグリーメント (SLA) とは、許容できる (許容できない) サービス レベルを定義したもので、サービスのプロバイダとコンシューマの間で契約として締結します。通常、SLA は応答時間やスループット (1 秒あたりのトランザクション数) を基準として定義されます。
同期型のシステムの場合、応答時間の要件 (現実的にはトランザクションの 95% 程度) を満たしたうえで、最大のスループットを達成できるようにシステムをチューニングすることが目標となります。したがって、応答時間が SLA になります。非同期型のシステムの場合は、スループットまたは 1 秒あたりのメッセージ数が SLA になります。
キャパシティ プランニングの目的に照らすと、キャパシティ プランニングに基づいて SLA を定義する前に、作業単位 (各トランザクションに含まれるアクティビティのセット) を定義することが重要になってきます。

各ノードは JPD です。すべての JPD は、注文処理に必要なプロセスです。このケースでは、作業単位 (トランザクション) の定義として以下が考えられます。
各 JPD ではなく、ビジネス処理のフロー全体を単一の作業単位とみなすことをお勧めします。
負荷生成スクリプトは、テストを実行する際に、設計した負荷をサーバにかけるために必要となります。
| 注意 : | テストの実行方法の詳細については、「ベンチマーク テストの実行」および「スケーラビリティ テストの実行」を参照してください。 |
負荷生成スクリプトの記述にあたっては、以下の点に留意する必要があります。
各仮想ユーザは処理中のリクエストを 1 つしか持たないと制限することで、負荷レベルの把握と管理が容易になります。リクエストの送信率を制御できないと、フロー バランスを超えるペースで送信され続け、キュー オーバーフローなどの問題につながる可能性があります。
次の図には、単一のユーザが、以前のリクエストがサーバによって処理された後にのみ、次のリクエスト送信する場合を示します。
この方法であれば、同時ユーザの数を増やすことで、システムでの受信率 (システムへの負荷) を増やすことができます。システムに悪影響を及ぼすことがないため、システムの性能を正確に計測できます。
次の図には、単一のユーザが、以前のリクエストの処理をサーバが完了するのを待つことなく、新しいリクエストを送信する場合を示します。

この方法では、キュー オーバーフローなどの問題が発生し、システムの性能を見誤るおそれがあります。
バランスのよい負荷生成スクリプトを設計することをお勧めします。
外部要因による影響を排除してテスト結果の信頼性の高めるため、以下の説明に従ってテスト環境をコンフィグレーションする必要があります。
ベンチマーク テストを実行すると、システムのボトルネックを特定し、システムを適切にチューニングできるようになります。
ベンチマーク テストでは、スループットがそれ以上増えなくなるまで、徐々にシステムへの負荷を増やしていきます。
| 注意 : | ベンチマーク テストの目的に照らし、テストする WLI アプリケーションがシステム リソースを必要とするあらゆる要因を想定した負荷にします (同時ユーザの数、ドキュメントのサイズなど)。 |
| 注意 : | 負荷を徐々に大きくすることで、システムに急激に大きな負荷をかけないようにする必要があります。 |
| 注意 : | ベンチマーク テストは、単一の WLI マシンで思考時間なしで実行します。 |
スループットがこれ以上大きくならなくなると、以下のいずれかの現象が発生します。
次の図に、Mercury LoadRunner による始動スケジュールを示します。最初の 10 分間は、同時ユーザ 10 人でのウォーミングアップ テストです。その後、15 分ごとに 10 人ずつ同時ユーザを追加して負荷を徐々に増やしていきます。

Mercury LoadRunner、Grinder などのツールを使用すると、ユーザを操作したりメトリックを捕捉したりできます。

ユーザを追加するにつれ、平均 TPS (トランザクション/秒) が増大しています。いずれかのハードウェア リソース (ここでは CPU) の使用率が 100% に達すると、平均 TPS もピークに達します。その時点の応答時間が最適解です。さらにユーザを追加すると TPS は減少し始めます。TPS は、負荷が大きくなるにつれほぼ線形に増大しますが、CPU や入出力の制限によってシステムが飽和状態になるとピークに達し、それ以降は減少傾向になることが分かりました。応答時間は、システムが飽和状態になるまでほぼ線形に増大し、その後は非線形に増大します。
このようなテストを実行することで、リソースの使用率が最大値に達したとき、システムがどのように動作するかが分かります。
テスト結果を分析する前に、リトルの法則に基づいて検証し、そのテスト設定におけるボトルネックを特定する必要があります。テスト結果は、リトルの法則を適用した場合の結果と大きく食い違うべきではありません。
複数ユーザ システムの応答時間の算出式は、リトルの法則を用いて導出できます。平均思考時間 z のユーザ n 人が、応答時間 r の任意のシステムに接続しているとします。各ユーザは、思考と応答待ちを繰り返します。したがって、ユーザとコンピュータ システムから構成されるこのメタシステム内のジョブの総数は定数 n となります。
n はユーザ数として表される負荷、z + r は平均応答時間、x はスループットです。
| 注意 : | 単位の整合性を維持するようにしてください。たとえば、スループットを TPS で表すのであれば、応答時間は秒で表す必要があります。 |
結果の解釈にあたっては、安定状態のシステムの値のみを考慮します。始動段階や終了段階をパフォーマンス メトリクスに含めないようにしてください。
CPU、メモリ、ハード ディスク、ネットワークなどのリソースの使用率は、スループットが飽和するときにピークになるようにする必要があります。いずれかのリソースがピークに達しない場合は、システムのボトルネックを分析してチューニングしなおします。
スレッド プールが飽和した時点でリソースにボトルネックが存在しない場合は、アプリケーションやシステムのパラメータがボトルネックになっている可能性があります。こうしたボトルネックの原因としては以下が考えられます。
オペレーティング システムとネットワークのパラメータが適切にチューニングされていることを確認します。詳細については、『WebLogic Server パフォーマンス チューニング ガイド』を参照してください。
新たなハードウェア リソースを追加したときに、それに見合った分確実にパフォーマンスが向上するようであれば、そのシステムはスケーラブルであると考えられます。このようなシステムであれば、ある程度負荷が増大してもパフォーマンスが低下することはありません。負荷の増大に対応するには、ハードウェア リソースを追加する必要があるかもしれません。
アプリケーションについては、マシンを追加することで水平スケーラビリティを強化でき、同じマシンにリソース (たとえば CPU) を追加することで垂直スケーラビリティを強化できます。
次の表に、水平スケーラビリティと垂直スケーラビリティそれぞれの利点を示します。
アプリケーションのスケーラビリティを強化する必要がある場合は、そのときの要件に応じて水平スケーラビリティ、垂直スケーラビリティ、またはこれらの組み合わせを選択できます。
次の図に、WLI をクラスタ化されていない 4 CPU のマシン 1 台で稼働させた場合 (垂直スケーラビリティ) と、クラスタ化された 2 CPU のマシン 2 台で稼働させた場合 (水平スケーラビリティ) の比較結果を示します。
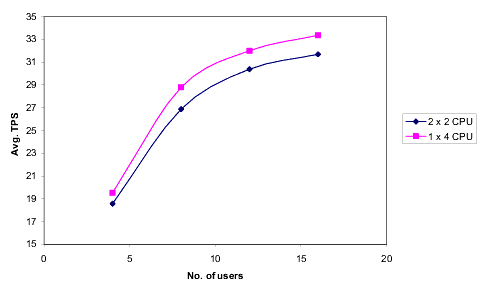
水平スケーラビリティ (2 CPU のマシン 2 台) の場合のパフォーマンスは、垂直スケーラビリティ (4 CPU のマシン 1 台) の場合に比べ少し劣っています。これは、水平スケーラビリティの場合、ロード バランシングとクラスタリングによるオーバーヘッドが余分にかかるためです。しかし、水平スケーラビリティ システムなら、マシンを追加することでキャパシティを広げることができます。これは垂直スケーラビリティ システムでは不可能です。
スケーラビリティ テストを実行すると、システムの水平スケーラビリティや垂直スケーラビリティを強化したときに、アプリケーションのスケーラビリティがどうなるかが分かります。この情報に基づいて、特定の状況に対応するためには、どのくらいのハードウェア リソースを追加する必要があるかを推定できます。
スケーラビリティ テストでは、SLA が満たされるか、目標とするリソース使用率に達するまで、徐々に負荷を増やします。
| 注意 : | 一方、ベンチマーク テストでは、スループットがそれ以上増えなくなるまで負荷を増やします。 |
スケーラビリティ テストを実行する場合は、できるだけプロダクション環境に近い負荷を再現する必要があります。ユーザの介在が必要なく、プロセスの呼び出しをプログラム的に発生させる場合は、ベンチマーク テストの場合のように思考時間をゼロとみなす手法をお勧めします。
SLA を満たす前に目標とするリソース使用率に達した場合は、システムに新たなリソースを追加する必要があります。追加のリソース (垂直スケーラビリティ) またはマシン (水平スケーラビリティ) は、1、2、4、8 のような順序で追加する必要があります。
| 注意 : | キャパシティの推定式の導出には、少なくとも 3 つのデータ ポイントを使用する必要があります。 |
ベンチマーク テストの実行中に記録されたすべてのデータは、スケーラビリティ テストの実行中にも捕捉する必要があります。詳細については、「ベンチマーク テストの実行」を参照してください。
| 注意 : | 追加のリソース要件を推定する場合は、リソース使用率が目標レベルに最も近づいたときに記録されたデータを使用する必要があります。 |
テストを実行したら、ベンチマーク テストと同じように検証と分析を行います。追加のリソース要件を推定する必要がある場合は、次の節の説明に従ってください。
キャパシティ プランニングを実施すると、現時点での SLA と将来の負荷に基づいて、現在および将来のリソース要件を推定できます。キャパシティ プランを作成するためには、システムの負荷モデルを作成する必要があります。
テスト結果は、この負荷モデルを作成するためのデータ ポイントを提供します。テスト結果から得られる曲線の式を導出し、これを使って必要となる追加ハードウェア リソースを推定します。線形回帰や曲線適合などの手法に基づいて、必要となるリソースを予測します。Microsoft Excel のようなスプレッドシート アプリケーションを使用すると、これらの手法の精度を上げることができます。
| 注意 : | 予測の精度は、負荷モデルの正確さに左右されます。負荷モデルは、アプリケーションの各リソース (CPU など) に基づいて正確に作成する必要があります。 |
| 注意 : | 過去のパフォーマンス データを使ってモデルを検証することも可能です。 |
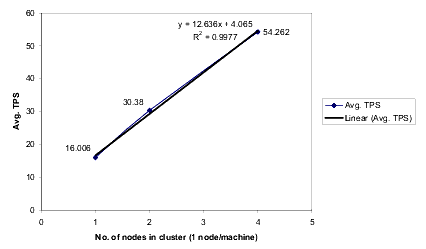
このグラフには、クラスタのノード数が異なると、CPU 使用率 70% の時点での平均 TPS がどう変化するかが示されています。
このスケーラビリティ テストの結果には、線形方程式が最も適合します。最も適合する曲線 R2 は、単位元 (値 1) に近似していなければなりません。
平均 TPS を y、ノード数を x とすると、式は y = 12.636x + 4.065 となります。
| 注意 : | 水平でも垂直でも、リソースを新たに追加することで TPS を上げることはできますが、特定の応答時間を実現したい場合は意味がないかもしれません。そのような場合は、より高速な CPU を検討してください。 |
スケーラビリティ テストの結果に基づいてチューニングを実施し、要求されるレベルを実現できたら、プロダクション環境にデプロイできるようにアプリケーションをコンフィグレーションします。
| 注意 : | プロダクション環境用に購入することになったリソースとスケーラビリティ テストに使用したリソースでタイプやモデルが異なる場合は、次の式を使ってリソース要件を推定できます。 |
| 注意 : | E x T1 / T2 |
| 注意 : | E = スケーラビリティ テストの推定値 |
| 注意 : | T1 = テストを実行したマシンの SPECint レート |
| 注意 : | T2 = 購入したいマシンの SPECint レート |
| 注意 : | この式は、CPU 数に基づくスケーラビリティにのみ適用できます。 |
| 注意 : | SPECint レートを使用した推定はあくまでも概算です。キャパシティ プランニングは、プロダクション環境と同じハードウェア、同じコンフィグレーションで実施することをお勧めします。SPECint レートの詳細については、http://www.spec.org を参照してください。 |


|
