| Oracle Rdb for OpenVMS Oracle RMUリファレンス・マニュアル リリース7.2 E06177-01 |
|


 戻る |
 次へ |
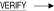
例1
RdbALTER> AREA 3 PAGE 100 RdbALTER> VERIFY
RMU Load、RMU UnloadおよびRMU Analyzeコマンドで使用されるレコード定義ファイル(.rrd)は、バイナリ・データ・ファイルやデリミタ付きテキスト・データ・ファイルのフィールドのデータ型やフィールドの順序を記述するために使用されます。.rrdファイルには、Oracle CDD RepositoryのCDOインタフェースで受け入れられる言語と似た単純な言語が含まれます。RMU Unloadコマンドは、データベースの表定義からレコード定義ファイルを自動的に生成します。
この付録では、RMU Loadコマンドによって使用される.rrd言語について説明します。RMUでサポートされる言語の便利なサブセットを示します。RMUによって受け入れられるが無視されるCDOの句については説明しません。
A.1 DEFINE FIELD文
各レコード定義ファイルには、アンロードされるレコードの1フィールドのデータ型を指定する少なくとも1つのDEFINE FIELD文が必要です。この文の形式は次の2つです。
define field name_string datatype is text size is 20 characters. |
define field first_name based on name_string. |
RMU Unloadでは、DATATYPE句のみを含むDEFINE FIELD文が生成されます。詳細な構文を「図A-1」に示します。
図A-1 DEFINE FIELD文

次に、さらに詳しいDEFINE FIELD文の例を示します。注釈(DESCRIPTION句)やbased-onフィールドも使用されています。
define field name_string
description is
/* This a generic string type to be used for based on */
datatype is text size is 20 characters.
define field first_name
based on name_string.
define field last_name
based on name_string.
define record PERSON
description is
/* Record which describes the PERSON.DAT RMS file */.
first_name.
last_name.
end.
|
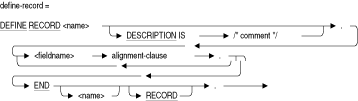
A.2 DEFINE RECORD文
DEFINE RECORD文では、ファイル内のフィールドの順序が定義されます。1つのフィールドは1回しか使用できません。Corresponding修飾子をRMU Loadコマンドで使用しないかぎり、フィールドの名前は列名の照合に使用されません。
図A-2 DEFINE RECORD文
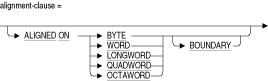
ALIGNED ON句を使用して、ホスト言語アプリケーションによって明示的または暗黙的に加えられた位置合せを調整します。たとえば、OpenVMS Alphaでは、データの位置が適切な場合に効率よく実行されるAlphaプロセッサ・ハードウェアを活用するために、多くの3GL言語コンパイラがフィールドの位置合せを自然に行います。デフォルトはBYTE位置合せです。
次の例では、フィールドCがquadword境界から開始すると想定されるため、Aに最初のlongwordが割り当てられ、次のlongwordが無視され、その後、Cに最後のlongword値が割り当てられます。
define field A datatype is signed longword. define field C datatype is signed longword. define record RMUTEST. A . C aligned on quadword boundary. end RMUTEST record. |
$ rmu/unload mf_personnel employees employees.unl $ rmu/dump/export/nodata employees.unl |
Oracle Rdbでサポートされるデータ型は『Oracle Rdb SQLリファレンス・マニュアル』に記載しています。
図A-3 データ型


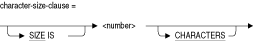
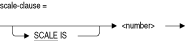
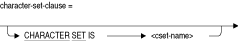
cset-nameは、Oracle Rdbによってサポートされる任意のキャラクタ・セットです。これらのキャラクタ・セットはリリースごとに拡張されています。新しいキャラクタ・セットや次に示すキャラクタ・セットの詳細は、『Oracle Rdb SQLリファレンス・マニュアル』を参照してください。
同一の言語で複数のキャラクタ・セットを利用できますが(KanjiとHanyuなど)、それぞれは形式や構造が異なるローカル標準または国際標準に基づきます。たとえば、日本ではSHIFT_JISがMicrosoft Windowsシステムでよく使用されていますが、Hewlett Packard CompanyのDECWindows製品でサポートされるDEC_KANJIキャラクタ・セットとは形式が異なります。
| キャラクタ・セット | 説明 |
|---|---|
| ARABIC | ASMO 449およびISO9036標準で定義されたアラビア語文字 |
| BIG5 | 台湾情報産業で使用されているキャラクタ・セット |
| DEC_HANYU | 標準CNS11643:1986で定義され台湾で使用されている繁体字中国語文字(Hanyu)、DTSCCで定義されている補足文字、ASCII |
| DEC_HANZI | 標準GB2312:1980で定義された中国語(Bopomofo)文字およびASCII文字 |
| DEC_KANJI | JIS X0208:1990標準で定義された日本語文字、JIS X0201:1976で定義された半角カタカナ文字(接頭辞SS2(8E hex)付き)、ユーザー定義文字、ASCII文字 |
| DEC_KOREAN | 標準KS C5601:1987で定義された韓国語文字およびASCII文字 |
| DEC_MCS | 発音区別符号付きの文字を含むアルファベットと数字の国際キャラクタ・セット |
| DEC_SICGCC | 標準CNS11643:1986で定義され台湾で使用されている繁体字中国語文字(Hanyu)およびASCII |
| DEVANAGARI | ISCII:1988標準で定義されたDevanagari文字 |
| DOS_LATIN1 | DOS Latin 1コード |
| DOS_LATINUS | DOS Latin USコード |
| HANYU | 標準CNS11643:1986で定義され台湾で使用されている繁体字中国語文字(Hanyu) |
| HANZI | 標準GB2312:1980で定義された中国語(Bopomofo)文字 |
| HEX | テキスト・データと16進データ間での変換 |
| ISOLATINARABIC | ISO/IEC 8859-6:1987標準で定義されたアラビア語文字 |
| ISOLATINCYRILLIC | ISO/IEC 8859-5:1987標準で定義されたキリル語文字 |
| ISOLATINGREEK | ISO/IEC 8859-7:1987標準で定義されたギリシャ語文字 |
| ISOLATINHEBREW | ISO/IEC 8859-8:1987標準で定義されたヘブライ語文字 |
| KANJI | JIS X0208:1990標準で定義された日本語文字およびユーザー定義文字 |
| KATAKANA | 標準JIS X0201:1976で定義された日本語音標文字(半角カタカナ) |
| KOREAN | 標準KS C5601:1987で定義された韓国語文字 |
| SHIFT_JIS | Shift_JIS固有のコード体系を使用するJIS X0208:1990標準で定義された日本語文字、JIS X0201:1976で定義された半角カタカナ文字、ASCII文字 |
| TACTIS | ISO 646-1983およびTIS 620-2533標準の組合せであるTACTIS(Thai API Consortium/Thai Industrial Standard)に基づくタイ語文字 |
| UNICODE | Unicode標準およびISO/IEC 10646変換形式UTF-16によって記述されるUnicode文字 |
| UTF8 | Unicode標準およびISO/IEC 10646 UTFエンコード形式によって記述されるUnicode文字 |
| WIN_ARABIC | MS Windowsコード・ページ1256 8-Bit Latin/Arabic |
| WIN_CYRILLIC | MS Windowsコード・ページ1251 8-Bit Latin/Cyrillic |
| WIN_GREEK | MS Windowsコード・ページ1253 8-Bit Latin/Greek |
| WIN_HEBREW | MS Windowsコード・ページ1255 8-Bit Latin/Hebrew |
| WIN_LATIN1 | MS Windowsコード・ページ1252 8-Bit West European |
