| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
次の例では、事前定義されたNCS照合順番SPANISHを指定したドメインが作成されます。最初にCREATE COLLATING SEQUENCE文を実行する必要があることに注意してください。
SQL> -- SQL> CREATE COLLATING SEQUENCE SPANISH SPANISH; SQL> CREATE DOMAIN LAST_NAME_SPANISH CHAR(14) cont> COLLATING SEQUENCE IS SPANISH; SQL> -- SQL> SHOW DOMAIN LAST_NAME_SPANISH LAST_NAME_SPANISH CHAR(14) Collating sequence: SPANISH |
例6: データベースのデフォルト・キャラクタ・セットを使用したドメインの作成
次の各例では、データベースのデフォルト・キャラクタ・セットをDEC_KANJI、各国語キャラクタ・セットをKANJIと指定したデータベースが作成済であることを前提としています。
次の例では、データベースのデフォルト・キャラクタ・セットを使用してドメインDEC_KANJI_DOMが作成されます。
SQL> SHOW CHARACTER SET;
Default character set is DEC_KANJI
National character set is KANJI
Identifier character set is DEC_KANJI
Literal character set is DEC_KANJI
Alias RDB$DBHANDLE:
Identifier character set is DEC_KANJI
Default character set is DEC_KANJI
National character set is KANJI
SQL> CREATE DOMAIN DEC_KANJI_DOM CHAR(8);
SQL> SHOW DOMAIN
User domains in database with filename MIA_CHAR_SET
DEC_KANJI_DOM CHAR(8)
|
CREATE DOMAIN文でキャラクタ・セットが指定されていないため、Oracle Rdbでは、このドメインはデータベースのデフォルト・キャラクタ・セットを使用して定義されます。データベースのデフォルト・キャラクタ・セットはSHOW DOMAIN文では表示されません。
前述のCREATE DOMAIN文は、次の文と同義です。
SQL> CREATE DOMAIN DEC_KANJI_DOM CHAR(8) CHARACTER SET DEC_KANJI; |
例7: 各国語キャラクタ・セットを使用したドメインの作成
次の例では、NCHARデータ型を使用してドメインKANJI_DOMが作成され、各国語キャラクタ・セットを使用するように指定されます。
SQL> CREATE DOMAIN KANJI_DOM NCHAR(8);
SQL> SHOW DOMAIN
User domains in database with filename MIA_CHAR_SET
DEC_KANJI_DOM CHAR(8)
KANJI_DOM CHAR(8)
KANJI 8 Characters, 16 Octets
|
デフォルト以外のキャラクタ・セットを指定した場合、SHOW DOMAIN文でそのドメインに関連付けられたキャラクタ・セットが表示されます。
前述のCREATE DOMAIN文は、次の文と同義です。
SQL> CREATE DOMAIN KANJI_DOM NATIONAL CHAR(8); SQL> CREATE DOMAIN KANJI_DOM CHAR(8) CHARACTER SET KANJI; |
例8: ドメインの制約の作成
次の例では、ドメインの制約が作成されます。
SQL> -- The SET DIALECT 'SQL99' statement sets the default date format SQL> -- to the ANSI/ISO SQL standard format. SQL> -- SQL> SET DIALECT 'SQL99'; SQL> -- SQL> -- The following domain ensures that any dates inserted into the database SQL> -- are later than January 1, 1900: SQL> -- SQL> CREATE DOMAIN TEST_DOM DATE cont> DEFAULT NULL cont> CHECK (VALUE > DATE'1900-01-01' OR cont> VALUE IS NULL) cont> NOT DEFERRABLE; SQL> SQL> -- The following example creates a table with one column based on the SQL> -- domain TEST_DOM: SQL> -- SQL> CREATE TABLE DOMAIN_TEST cont> (DATE_COL TEST_DOM); SQL> -- SQL> -- SQL returns an error if you attempt to insert data that does not SQL> -- conform to the domain constraint: SQL> -- SQL> INSERT INTO DOMAIN_TEST cont> VALUES (DATE'1899-01-01'); %RDB-E-NOT_VALID, validation on field DATE_COL caused operation to fail |
Oracle Rdbデータベースにスキーマ・オブジェクトとして外部ファンクションを作成します。CREATE FUNCTION文の詳細は、「CREATE ROUTINE文」を参照してください。外部ファンクション定義の作成の詳細は、「CREATE ROUTINE文」を参照してください。
表の索引を作成します。索引を使用すると表内の行に直接アクセスでき、順番に検索する必要がなくなります。索引は、構成する表の列をリストして定義します。1つの表に複数の索引を定義できます。索引は1列または複数の列で構成できます。2列以上で構成される索引は、複数セグメント索引と呼ばれます。
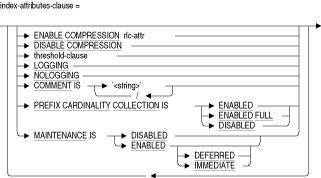
CREATE INDEX文には、オプションの引数で次の内容を指定できます。
- 索引構造の種類(ハッシュ、ランクなしソート、またはランク付きソート)
- 索引を含む記憶域の名前
- 索引ノードのサイズ、および各ノードの最初の占有率などの、ソート索引構造に関する物理特性
- テキスト索引の圧縮キーの接尾辞、およびSMALLINTまたはINTEGERの数値列の整数列圧縮などの、圧縮特性
- テキスト・データ型からの空白文字の圧縮、および非テキスト・データ型からのバイナリ・ゼロの圧縮
- 索引を含む論理記憶域に対するしきい値
- 索引定義のコメント
- 索引作成操作で、.rujファイルおよび.aijファイルへのロギングの有効化または無効化
CREATE INDEX文は次の環境で使用できます。
- 対話型SQL内
- プリコンパイル対象のホスト言語プログラムに埋め込まれる場合
- SQLモジュールのプロシージャの一部として
- 動的SQLで動的に実行される文として
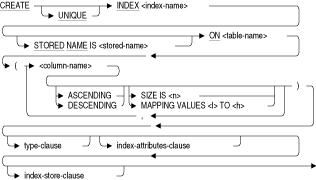






ASCENDING
SQLで昇順の索引セグメントを作成するためのオプションのキーワードです。ASCENDINGキーワードまたはDESCENDINGキーワードを省略した場合、デフォルトは昇順です。BUILD ALL PARTITIONS
この句を作成ペンディング状態にある索引(MAINTENANCE IS ENABLED DEFERREDを使用して作成)に対して指定すると、すべて不完全なパーティションが作成されます。索引が作成ペンディング状態にない場合、この文は正常に完了し、警告が出されます。同一ALTER INDEX文内には他の句を使用できません。
BUILD PARTITION partition-name
この句を作成ペンディング状態にある索引(MAINTENANCE IS ENABLED DEFERREDを使用して作成)に対して指定すると、指定されたパーティションが作成されます。索引が作成ペンディング状態にない場合、この文は正常に完了し、警告が出されます。同一ALTER INDEX文内には他の句を使用できません。
column-name
索引キーを構成する列の名前です。複数の列を指定すると、指定した列が結合されて複数セグメント索引キーを作成できます。列はすべて同じ表の一部である必要があります。複数の列名をカンマで区切ります。
注意
CHARデータ型、VARCHARデータ型またはLONG VARCHARデータ型として定義されている列をcolumn-nameが参照する場合、列のサイズを254文字以下とするか、SIZE IS句を使用する必要があります。
COMMENT IS 'string '
索引の記憶域マップ定義に関するコメントを追加します。SQLでは、SHOW INDEXES文の実行時にコメントのテキストが表示されます。コメントは一重引用符(')で囲み、コメント内の複数の行はスラッシュ(/)で区切ります。DESCENDING
SQLで降順の索引セグメントを作成するためのオプションのキーワードです。ASCENDINGキーワードまたはDESCENDINGキーワードを省略した場合、デフォルトは昇順です。DISABLE COMPRESSION
圧縮索引を無効にします。圧縮が無効になると、ハッシュ索引にはどのような形の圧縮も使用されなくなり、ソート索引には接頭辞圧縮またはプリフィックス圧縮が使用されます。プリフィックス圧縮とは、連続した索引キーに共通する先頭の数バイトを圧縮することです。プリフィックス圧縮により、これらの共通する情報のバイトが格納されなくなり、領域を節約できます。反対に、接尾辞圧縮では、隣接する索引キーの最後の数バイトが圧縮されます。これらのバイトについて一意性を保証する必要はありません。
CREATE INDEX文のDISABLE COMPRESSION句を指定した後では、ALTER INDEX文を使用して索引圧縮を有効にできません。
デフォルトでは、索引圧縮は無効です。
DUPLICATES ARE COMPRESSED
重複が圧縮されることを指定します。ランク付きソート索引で重複するエントリが許可されている場合、重複を圧縮すると小さい領域に多くのレコードを格納できるため、I/Oが最小化されてパフォーマンスが向上します。Oracle Rdbでは、重複エントリを非圧縮状態のdbkeyと関連付けるのではなく、バイト単位のビットマップ圧縮と呼ばれる特許技術を使用して重複するエントリのdbkeyを示します。DUPLICATES ARE COMPRESSED句を指定せずにRANKEDを指定すると、デフォルトで重複は圧縮されます。
DUPLICATES ARE COMPRESSED句は、ランクなし索引の作成時またはUNIQUEキーワードの指定時には使用できません。
ランク付きソートBツリー索引の詳細は、『Oracle Rdb7 Guide to Database Design and Definition』を参照してください。
ENABLE COMPRESSION
ソート索引およびハッシュ索引を圧縮形式で格納するように指定します。圧縮が有効になっている場合、Oracle Rdbではランレングス圧縮を使用して、テキスト・データ型からの連続する空白文字(オクテット)、および非テキスト・データ型からのバイナリ・ゼロを圧縮します。キャラクタ・セットが異なると、空白文字の表現も異なります。Oracle Rdbでは、索引値を構成する列のキャラクタ・セットにおける空白文字列表現を圧縮します。
CREATE INDEX文のENABLE COMPRESSION句を指定した後では、ALTER INDEX文を使用して索引圧縮を無効にできません。
圧縮型索引の詳細は、『Oracle Rdb7 Guide to Database Design and Definition』を参照してください。
IN area-name
索引を単一の記憶域と直接関連付けます。索引のすべてのエントリは指定した領域に格納されます。index-name
索引の名前です。この名前を使用して他の文にある索引を参照できます。スキーマがデフォルト以外の場合、この索引名を認可識別子で修飾する必要があります。名前の選択時に有効な名前を指定します。有効なユーザー指定の名前の詳細は、第2.2節を参照してください。index-store-clause
索引の記憶域マップ定義です。複数ファイルのデータベース内の索引にかぎり、STORE句を指定できます。CREATE INDEX文でSTORE句を指定すると、索引エントリの格納に使用する記憶域ファイルを指定できます。
記憶域マップ定義を省略すると、デフォルトでは、索引のすべてのエントリがデフォルトの主記憶域に格納されます。
関連付けられている表の記憶域マップに一致する索引について、記憶域を定義する必要があります。
特に次の条件の場合、索引エントリはデータベース・システムによって実際の行を含むデータ・ページと同じデータ・ページの行またはその付近に格納されます。
- 表の記憶域で混合ページ形式の場合。
- 索引に対して、表の記憶域マップに存在するものと同一のSTORE句を指定する場合。
- 表の記憶域マップでPLACEMENT VIA INDEX句の索引も指定されている場合。
このようにして索引と行を同時にクラスタ化すると、I/O操作を削減できます。ハッシュ索引および同時クラスタ化を使用すると、データベース・システムで完全一致の問合せに関する行を1回のI/O操作で取得できます。
ソート索引の場合、同一の記憶域マップを指定すると索引ノードでのI/O競合が削減されます。
LOGGING
NOLOGGING
LOGGING句は、パーティションがリカバリ・ユニット・ジャーナル・ファイル(.ruj)とアフター・イメージ・ジャーナル・ファイル(.aij)に記録されることを指定します。NOLOGGING句は、パーティションがリカバリ・ユニット・ジャーナル・ファイル(.ruj)とアフター・イメージ・ジャーナル・ファイル(.aij)に記録されないことを指定します。STORE句を使用しない場合、これらの属性がCREATE INDEX文の設定を指定します。LOGGING句およびNOLOGGING句は相互に排他的です。1つのみ指定してください。デフォルトはLOGGING句です。MAINTENANCE IS DISABLED
この句を使用して作成した索引は保持されません。索引定義はテンプレートとしてのみ機能します。MAINTENANCE IS ENABLED DEFERRED
この句を使用して作成した索引には、表の現在行の索引キーが含まれません。(ALTER INDEX ... BUILDを使用して)索引が作成されるまで、索引は作成ペンディング状態に置かれます。作成ペンディング状態の索引がある表は、INSERT文、DELETE文、またはUPDATE文では更新できません。MAINTENANCE IS ENABLED IMMEDIATE
CREATE INDEXのデフォルトの動作です。MAPPING VALUES l to h
すべての数値列に対するCOMPRESSION句で、列値をコンパクトなエンコード形式に変換します。マップされた列とマップされていない列は混在できますが、ほとんどの記憶域はSMALLINTデータ型またはINTEGERデータ型の複数列から索引を作成すると取得されます。Oracle Rdbでは、このような列をすべてできるかぎり最小の領域に圧縮しようとします。l(低)〜h(高)で、索引キーの値として整数の範囲を指定します。
圧縮キーの有効範囲(l〜h)は次のとおりです。
- ゼロは不可
- 231〜4 x 10scaleまで
キーの値がゼロ未満、または231〜4 x 10scaleを超えている場合、Oracle Rdbから例外のシグナルが発行されます。
MINIMUM RUN LENGTH
Oracle Rdbで圧縮する最短のシーケンス長を指定します。この値は設定した後には変更できません。MINIMUM RUN LENGTH 2を指定すると、Oracle Rdbでは、複数の空白または複数のバイナリ・ゼロのシーケンスを単一のオクテットのキャラクタ・セットに圧縮し、1つの空白または1つのバイナリ・ゼロを複数のオクテットのキャラクタ・セットに圧縮します。シーケンスの圧縮時には、そのシーケンスが最短のランレングスに1バイトを加えた値で置き換えられます。多数の索引値で、後続の空白に加えて文字間に1つの空白が含まれる場合、最短のランレングス2を使用すると、意図せずに255バイトの制限を超えて索引を拡張することを防止できます。索引の作成時に、意図せずに255バイトを超えて索引が拡張されると、Oracle Rdbから警告メッセージが返されます。
デフォルトの最短ランレングスの値は2です。最短ランレングスの有効な値の範囲は1〜127です。圧縮する文字はOracle Rdbで決定されます。
NODE SIZE number-bytes
バイト単位での各索引ノードのサイズ。結果として生成される索引ノードの数およびレベルは、次の条件に依存します。
- このnumber-bytesの値
- 索引キーの数およびサイズ
- PERCENT FILL句またはUSAGE句で指定されている値
NODE SIZE句を省略すると、デフォルト値は次のようになります。
- 索引キーの合計サイズが120バイト以下の場合、430バイト
- 索引キーの合計サイズが120バイトより大きい場合、860バイト
索引キーのサイズは、ソート索引の列値を表現するために使用されるバイト数です。
ユーザー指定の索引ノード・サイズ(バイト)の有効範囲は、次の式で推定できます。
3(キー長 + オーバーヘッド)+32)<= ノード・サイズ <= 32767
OTHERWISE IN area-name
パーティション記憶域マップに対してのみ、オーバーフロー・パーティションとして使用される記憶域を指定します。オーバーフロー・パーティションとは、最後のWITH LIMIT TO句で指定された値より大きい値を保持する記憶域です。オーバーフロー・パーティションでは、指定された制限のパーティションからオーバーフローした値を保持します。PARTITION name
パーティションに名前を付けます。名前にはデリミタ付き識別子を使用できます。パーティション名は索引内で一意である必要があります。この句を指定しない場合は、Oracle Rdbでパーティションのデフォルト名が生成されます。PERCENT FILL percentage
変更中の索引構造にある各ノードの最初の占有率を指定します。有効範囲は1〜100パーセントです。デフォルトは70パーセントです。PERCENT FILL句およびUSAGE句は両方とも、索引ノードを最初にどの程度占有するかを指定します。PERCENT FILLまたはUSAGEのいずれかを指定し、両方は指定しないでください。
PREFIX CARDINALITY COLLECTION IS DISABLED
これを設定すると、カーディナリティ収集が無効になり、かわりに、適切に調整された索引ツリーを想定した固定スケール・アルゴリズムが使用されます。PREFIX CARDINALITY COLLECTION IS ENABLED
CREATE INDEXのデフォルトの動作です。Oracle Rdbのオプティマイザでは、索引列のカーディナリティの概算値を収集して、将来の問合せの最適化に役立てます。これらの値を収集するための特別なI/Oは発生せず、したがって、他の索引ノードの隣接したキー値はチェックできません。そのため、これらの索引は不正確になる可能性があります。ただし、通常の問合せの最適化には十分です。PREFIX CARDINALITY COLLECTION IS ENABLED FULL
これを設定すると、必要に応じて特別なI/Oの実行がリクエストされ、隣接した索引ノードのキー値の変更がカーディナリティ値に反映されるようになります。REBUILD ALL PARTITIONS
この句を使用すると、TRUNCATE処理およびBUILD処理を単一のファンクションに組み合せることができます。同一ALTER INDEX文内には他の句を使用できません。REBUILD PARTITION partition-name
この句を使用すると、指定したパーティションに対し、TRUNCATE処理およびBUILD処理を単一のファンクションに組み合せることができます。同一ALTER INDEX文内には他の句を使用できません。SIZE IS n
テキストまたは可変テキストの索引キーのCOMPRESSION句で、データ取得に使用する文字数を制限します。nに、索引で使用するキーの文字数を指定します。
注意
SIZE IS索引を作成してUNIQUE句を指定することは可能ですが、索引のキー値を切り捨てるとキー値が一意でなくなる場合があります。この場合、索引定義、INSERT文、またはUPDATE文は失敗します。
STORE IN area-name
索引を単一の記憶域と直接関連付けます。索引のすべてのエントリは指定した領域に格納されます。STORE USING (column-name-list)
複数の記憶域で索引をパーティション化するための制限として値を使用する列を指定します。索引キー・セグメントとして指定されていない列は指定できません。索引キーが複数セグメントである場合、結合されて索引キーを形成する列の一部または全部を含めることができます。列は、索引キーの定義時に指定した順序で指定する必要があります。列のサブセットのみを含める場合、複数セグメント索引の先頭のセグメントを必ず含めてください。
たとえば、CREATE INDEX文でLAST_NAME、FIRST_NAMEおよびMIDDLE_INITIALの列に基づく複数セグメント索引を指定した場合、USING句には先頭のセグメントLAST_NAMEを含めるか、最初の2つのセグメントLAST_NAMEおよびFIRST_NAMEを含めるか、または索引のすべてのセグメントを含める必要があります。これはソート索引のみに適用されます。
データベース・システムでは、新しい表の行に関連付けられた索引エントリが属する記憶域を判定するためのキーとして、STORE USING句に指定された列の値が使用されます。
分散ハッシュ索引に制限はありません。順序付きハッシュ索引には、最後のセグメントを除き、リストされているすべてのセグメントを含めることができます。また、HASHED ORDERED索引には、最後の列のデータ型を数値にする必要があるという制限もあります。
STORED NAME IS stored-name
Oracle Rdbで、マルチスキーマ・データベースに作成した索引へのアクセスに使用する名前を指定します。ストアド名を使用すると、Oracle Rdb管理ユーティリティであるOracle RMUなどのインタフェースを使用して、マルチスキーマ定義にアクセスできます。このユーティリティでは、1つのデータベース内で複数のスキーマを認識しません。複数のスキーマに対応しないデータベース内では、索引のストアド名は指定できません。ストアド名の詳細は、第2.2.18項を参照してください。table-name
索引が含まれる表の名前。表は索引と同じスキーマにある必要があります。threshold-clause
統一ページ形式に、記憶域の索引が含まれる論理領域のデフォルトしきい値を1つ、2つまたは3つ指定します。しきい値を設定すると、圧縮データの格納に十分な領域を持つページがOracle Rdbで見落とされないよう確認できます。しきい値(val1、val2およびval3)はデータ・ページの占有率を示し、データ・ページ上で保証されている空き領域について、考えられる3つの範囲を設定します。論理領域のしきい値の詳細は、「CREATE STORAGE MAP文」を参照してください。データ圧縮を使用する場合、記憶域の最適なパフォーマンスを実現するには論理領域のしきい値を使用する必要があります。
混合ページ形式の領域の記憶域マップ属性には、しきい値は指定できません。混合ページ形式の場合は、ALTER DATABASE文、CREATE DATABASE文、またはIMPORT文のADD STORAGE AREA句またはCREATE STORAGE AREA句を使用して、記憶域のしきい値を設定します。
SPAMページの詳細は、『Oracle Rdb7 Guide to Database Design and Definition』を参照してください。
TRUNCATE ALL PARTITIONS
この句はTRUNCATE TABLEと同様に機能しますが、1つの索引のみを対象とします。索引は、現在ENABLED IMMEDIATEが指定されている場合、自動的にMAINTENANCE IS ENABLED DEFERRED(作成ペンディング状態)に設定されます。それ以外の場合は、無効な状態のままとなります。同一ALTER INDEX文内には他の句を使用できません。
TRUNCATE PARTITION partition-name
この句は、指定した索引パーティションにのみ機能します。索引は、現在ENABLED IMMEDIATEが指定されている場合、自動的にMAINTENANCE IS ENABLED DEFERRED(作成ペンディング状態)に設定されます。それ以外の場合は、無効な状態のままとなります。同一ALTER INDEX文内には他の句を使用できません。
TYPE IS HASHED ORDERED
TYPE IS HASHED SCATTERED
索引がハッシュ索引であることを指定します。HASHEDを指定した場合、NODE SIZE句、PERCENT FILL句またはUSAGE句は使用できません。ただし、データがORDEREDであるかSCATTEREDであるかは指定できます。デフォルトはSCATTEREDです。TYPE IS HASHED SCATTERED句は、データが複数の記憶域にわたって均等に分散されていない場合に適しています。このオプションにより、索引キーにハッシュ・アルゴリズムが適用されて選択されたページにレコードが配置されます。その結果、レコードの分散パターンは均等になるとは限らず、一部のページが他のページより頻繁に選択される可能性があります。TYPE IS HASHED SCATTERED句はデフォルトであり、TYPE IS HASHED ORDERED句についてデータが次の条件を満たしていないかぎり推奨されます。1
- 索引キーの最後の列を次のデータ型のいずれかにする必要がある場合。
- TINYINT
- SMALLINT
- INTEGER
- BIGINT1
- DATE(ANSIおよびVMSの両方)1
- TIME1
- TIMESTAMP1
- INTERVAL1
- 索引が昇順であることが必要な場合。
- 索引が圧縮されていない、またはマッピング値を持っている必要がある場合。
TYPE IS HASHED ORDERED句は、索引キーの値が特定の範囲にわたって均等に分散されるアプリケーションに最適です。これにより、索引キーに順序付きハッシュ・アルゴリズムが適用されて導出されたページにレコードが配置されます。その結果、分散パターンが索引キーの分散に従うことが保証されます。また、値の範囲がわかっていれば、記憶域およびページのサイズをオーバーフローが最小になるよう指定できます。索引キーの値が均等に分散されていない場合は、TYPE IS HASHED SCATTERED句を使用してください。
ハッシュ索引は混合ページ形式の記憶域に格納する必要があり、複数ファイルのデータベースでのみ有効です。
ハッシュ索引を使用すると、特定の行に対して素早く直接アクセスでき、主に、同じくハッシュ索引のキーである列に対して完全一致での取得を指定する問合せに有効です。(たとえば、SELECT EMPLOYEE_ID FROM EMPLOYEES WHERE EMPLOYEE_ID = "00126"と指定すると、索引キーとしてEMPLOYEE_IDを持つハッシュ関数の使用が有効になります。)
ハッシュ索引体系では、索引キーの値が数学的に変換され、特定の表の記憶域の相対ページ番号になります。索引キーの情報と、索引キーの特定の値を含む行を指す(データベース・キーまたはdbkeyと呼ばれる)内部ポインタのリストの情報を保持する、ハッシュ・バケットというデータ構造体があります。ハッシュ索引を使用して行を検索する場合、データベース・システムではハッシュ・バケットを検索して適切なdbkeyを見つけた後で、その表の行をフェッチします。
ハッシュ索引は、そのハッシュ索引が定義されている索引キー全体が問合せに指定されている場合のランダムな直接アクセスに最も有効です。これらのタイプのアクセスでは、I/O操作を大幅に削減できます。多数の行および大規模な索引がある表には特に便利です。たとえば、深さ4レベルのソート索引を使用して行を取得するには、データベース・システムで5回のI/O操作の実行が必要な場合もあります。ハッシングを使用すると、I/O操作の数が最大で2回に削減されます。
ハッシュ索引とソート索引は同じ列に定義できます。その後、使用する問合せのタイプに応じて、Oracle Rdbのオプティマイザにより適切な取得方法が選択されます。たとえば、問合せに完全一致での取得が含まれる場合、オプティマイザではハッシュ索引アクセスが使用される場合があります。問合せに範囲取得が含まれる場合、オプティマイザによりソート索引が使用されます。この方法では2つの索引を保持するため追加のオーバーヘッドが発生します。そのため、迅速に取得できるというメリットと、データ変更のたびに索引を2つ更新するというデメリットを考慮する必要があります。
ハッシュ索引およびソート索引の相対的なメリットの詳細は、『Oracle Rdb7 Guide to Database Design and Definition』を参照してください。
TYPE IS SORTED
索引が、ランクなしソート(Bツリー)索引であることを指定します。TYPE IS句を省略すると、SORTEDがデフォルトで指定されます。ソート索引を使用すると、範囲演算子(BETWEENおよび大なり記号(>)など)を使用して値を比較する問合せのパフォーマンスが向上します。(たとえば、SELECT EMPLOYEE_ID FROM EMPLOYEES WHERE EMPLOYEE_ID > 200は範囲取得を指定する問合せであり、ソート索引の使用が有効になります。)
注意
1 これらのデータ型では下位32ビットのみが使用されます。
