| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
デフォルトは100ページです。
エクステントの制御が単純な場合は、ページ数を指定します。複数データベースをより厳密に制御するには、かわりにMIN、MAXおよびPERCENT GROWTHのエクステント・オプションを使用します。
MIN、MAXおよびPERCENT GROWTHパラメータを使用する場合は、それらを丸カッコで囲む必要があります。
この引数を使用すると、CREATE STORAGE AREA句で作成したスナップショット・ファイルに別のファイル名、デバイスまたはディレクトリを指定できます。ファイル仕様には、.snp以外のファイル拡張子は指定しないでください。Oracle Rdbでは、別の拡張子を指定した場合でも、ファイル仕様に拡張子.snpが割り当てられます。
SNAPSHOT FILENAME引数を省略すると、スナップショット・ファイルのデバイス名、ディレクトリ名およびファイル名は記憶域ファイルと同じになります。
RDB$SYSTEM記憶域には、データベース・システムの表と索引があります。かわりにDEFAULT STORAGE AREAが割り当てられていない場合、この領域にはマップされていないユーザー表と索引が含まれている場合があります。
混在する領域のデフォルトのしきい値は、指定されていない場合は(70,85,95)であり、これは、公称レコード・サイズがSPAMしきい値計算に使用されることを示しています。Oracle Rdbでは、3つ目のしきい値までレコードがページに格納されません。最高しきい値に設定した値は、今後のレコード・サイズ増加に備えたページの予約領域として使用されます。
val1のみを指定した場合、これは(val1, 100, 100)に相当します。val1とval2を指定した場合、これは(val1, val2, 100)に相当します。最後の指定されていないしきい値は、デフォルトで100パーセントに設定されます。たとえば、THRESHOLDS ARE (40)は(40, 100, 100)となります。
PAGE FORMAT IS MIXEDを明示的に指定していない場合、THRESHOLDS記憶域パラメータは指定できません。
領域管理パラメータの設定の詳細は、『Oracle Rdb7 Guide to Database Maintenance』を参照してください。
- CREATE STORAGE AREA句は単一ファイルのデータベースには使用できません。CREATE DATABASE文にCREATE STORAGE AREA句を指定すると、データベースが単一ファイルか複数ファイルかを判断できます。複数ファイルのデータベースは、CREATE DATABASE文にCREATE STORAGE AREA句が含まれている場合のみ作成されます。
- CREATE STORAGE AREA句では、実際にどの表または索引が記憶域に関連付けられるかは制御されません。CREATE STORAGE MAP文およびCREATE INDEX文では、特定の記憶域ファイルに何を格納するかを制御します。リストの格納の詳細は、「CREATE STORAGE MAP文」を参照してください。
- LOCKING IS PAGE LEVEL句またはLOCKING IS ROW LEVEL句を(ALTER DATABASE文またはCREATE DATABASE文を使用して)データベース・レベルに指定した場合は、常に行レベル・ロックに設定されているRDB$SYSTEMを除き、すべての記憶域に反映されます。記憶域レベルで(CREATE STORAGE AREA句を使用して)指定した場合は、指定した記憶域属性のみに反映されます。
- 既存の最小ページ・サイズより小さいページ・サイズで新規領域を追加するには、データベースに排他アクセスする必要があります。
例1: 複数ファイルのデータベースの定義この例では、複数ファイルのデータベースのデータベースと記憶域の定義を示します。
SQL> -- Note that there is no semicolon before SQL> -- the first CREATE STORAGE AREA clause. SQL> CREATE DATABASE ALIAS MULTIFILE_EXAMPLE cont> FILENAME 'DB_DATA01:[DB.DATA]MULTIFILE_EXAMPLE' cont> CREATE STORAGE AREA EMPID_LOW cont> FILENAME 'DB_DATA02:[DB.DATA]EMPID_LOW' cont> ALLOCATION IS 10 PAGES cont> -- Notice that the snapshot file resides on a cont> -- different disk than the storage area file. This cont> -- strategy reduces disk input/output bottlenecks: cont> SNAPSHOT FILENAME 'DB_SNAP03:[DB.SNAP]EMPID_LOW' cont> SNAPSHOT ALLOCATION IS 10 PAGES cont> -- cont> CREATE STORAGE AREA EMPID_MID cont> FILENAME 'DB_DATA04:EMPID_MID' cont> ALLOCATION IS 10 PAGES cont> SNAPSHOT FILENAME 'DB_SNAP05:[DB.SNAP]EMPID_MID' cont> SNAPSHOT ALLOCATION IS 10 PAGES cont> -- cont> CREATE STORAGE AREA EMPID_OVER cont> FILENAME 'DB_DATA06:[DB.DATA]EMPID_OVER' cont> ALLOCATION IS 10 PAGES cont> SNAPSHOT FILENAME 'DB_SNAP07:[DB.SNAP]EMPID_OVER' cont> SNAPSHOT ALLOCATION IS 10 PAGES cont> -- cont> CREATE STORAGE AREA HISTORIES cont> FILENAME 'DB_DATA02:[DB.DATA]HISTORIES' cont> ALLOCATION IS 10 PAGES cont> SNAPSHOT FILENAME 'DB_SNAP03:[DB.SNAP]HISTORIES' cont> SNAPSHOT ALLOCATION IS 10 PAGES cont> -- cont> CREATE STORAGE AREA CODES cont> FILENAME 'DB_DATA04:[DB.DATA]CODES' cont> ALLOCATION IS 10 PAGES cont> SNAPSHOT FILENAME 'DB_SNAP05:[DB.SNAP]CODES' cont> SNAPSHOT ALLOCATION IS 10 PAGES cont> -- cont> CREATE STORAGE AREA EMP_INFO cont> FILENAME 'DB_DATA08:[DB.DATA]EMP_INFO' cont> ALLOCATION IS 10 PAGES cont> SNAPSHOT FILENAME 'DB_SNAP09:[DB.SNAP]EMP_INFO' cont> SNAPSHOT ALLOCATION IS 10 PAGES cont> -- cont> -- End the CREATE DATABASE statement: cont> ;
例2:
この例では、データベース・レベルと、記憶域レベルの両方で、記憶域にページレベル・ロックおよび行レベル・ロックを設定する方法を示します。
SQL> CREATE DATABASE FILENAME sample cont> LOCKING IS PAGE LEVEL cont> -- cont> -- All storage areas will default to page-level locking unless cont> -- explicitly set to row-level locking. cont> -- cont> CREATE STORAGE AREA RDB$SYSTEM cont> FILENAME sample_system cont> -- cont> -- You cannot specify page-level locking on RDB$SYSTEM. RDB$SYSTEM cont> -- always defaults to row-level locking. cont> -- cont> CREATE STORAGE AREA HASH_AREA cont> FILENAME sample_hash cont> PAGE FORMAT IS MIXED cont> -- cont> -- HASH_AREA defaultS to page-level locking. cont> -- cont> CREATE STORAGE AREA DATA_AREA cont> FILENAME sample_data cont> LOCKING IS ROW LEVEL cont> -- cont> -- DATA_AREA is explicitly set to row-level locking. cont> -- cont> ; SQL> SHOW STORAGE AREAS (ATTRIBUTES) * Storage Areas in database with filename sample RDB$SYSTEM List storage area. Access is: Read write Page Format: Uniform Page Size: 2 blocks . . . Extent : Enabled Locking is Row Level HASH_AREA Access is: Read write Page Format: Mixed Page Size: 2 blocks . . . Extent : Enabled Locking is Page Level DATA_AREA Access is: Read write Page Format: Uniform Page Size: 2 blocks . . . Extent : Enabled Locking is Row Level
SHOW STORAGE AREAS文の詳細は、「SHOW文」を参照してください。
例3: 記憶域への行キャッシュの作成および割当て
SQL> create database cont> filename SAMPLE_DB cont> reserve 2 cache slots cont> row cache is enabled cont> default storage area is AREA1 cont> create cache CACHE1 cont> cache size is 1000 rows cont> row length is 1000 bytes cont> create storage area AREA1 cont> cache using CACHE1 cont> ; SQL> show cache CACHE1 CACHE1 Cache Size: 1000 rows Row Length: 1000 bytes Row Replacement: Enabled Shared Memory: Process Large Memory: Disabled Window Count: 100 Working Set Count: 10 Reserved Rows: 20 Allocation: 100 blocks Extent: 100 blocks SQL> show storage area AREA1 AREA1 Access is: Read write Page Format: Uniform Page Size: 2 blocks Area File: USER_DISK:[DOC.DATABASES]AREA1.RDA;1 Area Allocation: 702 pages Extent: Enabled Area Extent Minimum: 99 pages Area Extent Maximum: 9999 pages Area Extent Percent: 20 percent Snapshot File: USER_DISK:[DOC.DATABASES]AREA1.SNP;1 Snapshot Allocation: 100 pages Snapshot Extent Minimum: 99 pages Snapshot Extent Maximum: 9999 pages Snapshot Extent Percent: 20 percent Locking is Row Level Using Cache CACHE1 Database objects using Storage Area AREA1: Usage Object Name Map / Partition ---------------- ------------------------------- ------------------------------- Default Area
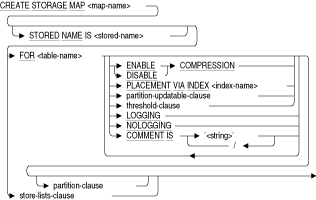
複数ファイルのデータベースの1つ以上の記憶域と表を関連付けます。CREATE STORAGE MAP文では、どの記憶域に表のどのリストまたは行が格納されるかを制御するstorage mapを指定します。CREATE STORAGE MAP文は記憶域マップを作成する他に、次を制御するオプションがあります。
- 表に行を挿入する場合に、データベース・システムでどの索引が使用されるか。
- 表の行が圧縮形式で格納されるかどうか。
- パーティション化キーが変更可能かどうか。
- 表を垂直にパーティション化するか、水平にパーティション化するか、またはその両方か。
- この操作中、ロギングを有効にするか無効にするか。
CREATE STORAGE MAP文は次の環境で使用できます。
- 対話型SQL内
- プリコンパイル対象のホスト言語プログラムに埋め込まれる場合
- SQLモジュールのプロシージャの一部として
- 動的SQLで動的に実行される文として
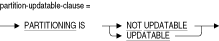







across-clause
表を複数の記憶域と関連付けます。COMMENT IS 'string'
記憶域マップに関するコメントを追加します。SQLでは、SHOW STORAGE MAPS文の実行時にコメントのテキストが表示されます。コメントは一重引用符(')で囲み、コメント内の複数の行はスラッシュ(/)で区切ります。ENABLE COMPRESSION
DISABLE COMPRESSION
パーティション行を格納する際、圧縮するかどうかを指定します。それぞれの垂直パーティションで、圧縮を有効または無効に設定できます。ディスク領域を節約するために圧縮を有効化しても、圧縮行の挿入と検索にはわずかにCPUオーバーヘッドが発生します。この句を省略すると、デフォルトの圧縮は、最初のSTORE COLUMNS句の前に記憶域マップに指定されたものになります。デフォルトはENABLE COMPRESSIONです。
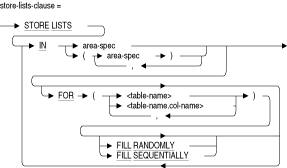
FILL RANDOMLY
FILL SEQUENTIALLY
領域セットをランダムに使用するか、または順に使用するかを指定します。FILL RANDOMLYまたはFILL SEQUENTIALLYを指定する場合はFOR句が必要です。記憶域を使用すると、その記憶域は空き領域のリストから削除されます。Oracle Rdbでは、現在のデータベースのアタッチ中は、この領域にリストは格納されません。かわりに、次に指定した領域が使用されます。領域セットが順に使用される場合は、最初に指定した領域が使用されるまで、その領域にリストが格納されます。
領域セットがランダムに使用される場合は、リストは複数の領域に格納されます。これはデフォルトです。ランダム使用は、記憶域全体へのI/O分散による利点を活用できるため、読取り/書込みメディアに向いています。
キーワードFILL RANDOMLYおよびFILL SEQUENTIALLYは、領域リスト内に含まれる領域にのみ適用されます。
FOR (table-name)
このリストの記憶域マップが適用される1つ以上の表を指定します。指定した表は定義されている必要があります。複数の表のリストを記憶域に格納する場合は、表名をカンマで区切ります。それぞれの領域には、1つのFOR句と表名のリストを指定できます。FOR (table-name.col-name)
この記憶域マップが適用されるリストを含む表と列の名前を指定します。表名と列名はピリオド(.)で区切ります。指定した表と列は定義されている必要があります。複数のリストを記憶域に格納する場合は、表名と列名の組合せをカンマで区切ります。それぞれの領域には、1つのFOR句と列名のリストを指定できます。LOGGING
NOLOGGING
LOGGING句は、CREATE STORAGE MAP文がリカバリ・ユニット・ジャーナル・ファイル(.ruj)とアフター・イメージ・ジャーナル・ファイル(.aij)に記録されることを指定します。NOLOGGING句は、CREATE STORAGE MAP文がリカバリ・ユニット・ジャーナル・ファイル(.ruj)とアフター・イメージ・ジャーナル・ファイル(.aij)に記録されないことを指定します。
デフォルトはLOGGING句です。
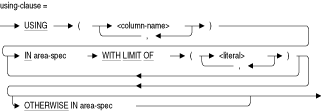
OTHERWISE IN area-name
パーティション記憶域マップに対してのみ、オーバーフロー・パーティションとして使用される記憶域を指定します。オーバーフロー・パーティションとは、WITH LIMIT OF句で指定された値より大きい値を保持する記憶域です。オーバーフロー・パーティションでは、指定された上限の値を超える値を保持します。partition-clause
垂直パーティション化、水平パーティション化、またはその両方を指定の表に定義します。水平パーティション化とは、1つ以上の列のデータ値に応じて、表の行を複数の記憶域に分割することを意味します。垂直パーティション化とは、表の列を複数の記憶域に分割することを意味します。このため、指定の記憶域にはその表の一部の列のみが含まれます。1つのマップで、水平パーティションと垂直パーティションを組み合せることができます。
垂直パーティション化では、使用頻度の高いデータを1領域に置くことでディスクI/O操作を削減し、単一のディスクI/O操作で表のその部分を読み取り、更新できます。
パーティション化の詳細は、『Oracle Rdb7 Guide to Database Design and Definition』を参照してください。
PARTITION name
パーティションに名前を付けます。言語または引用ルールがSQL92またはSQL99に設定されている場合、この名前にデリミタ付き識別子を指定できます。パーティション名は記憶域マップで一意である必要があります。この句を指定しない場合は、Oracle Rdbでパーティションのデフォルト名が生成されます。PARTITIONING IS NOT UPDATABLE
パーティション化キーの値が変更できず、行が常にSTORE USING句のパーティション化基準に基づいて記憶域に格納されることを指定します。パーティション化キーはSTORE USING句で指定した列または列のリストです。PARTITIONING IS NOT UPDATABLE句を指定すると、問合せを最適化する際にパーティション化基準を使用できるため、Oracle Rdbではより迅速にデータを取得できます。
NOT UPDATABLE記憶域マップでパーティション化キーである列を更新するには、行を削除してから再挿入し、行が正しい場所に配置されていることを確認します。
PARTITIONING句を指定する場合は、記憶域マップの定義でSTORE USING句も指定する必要があります。
PARTITIONING句が指定されていない場合は、UPDATABLEがデフォルトになります。
パーティション化の詳細は、『Oracle Rdb7 Guide to Database Design and Definition』を参照してください。
PARTITIONING IS UPDATABLE
パーティション化キーが変更可能であることを指定します。パーティション化キーはSTORE USING句で指定した列または列のリストです。UPDATABLE記憶域マップで行を変更する場合は、パーティション化キーの新規の値が元の記憶域の範囲内にない場合でも、その行は別の記憶域に移動されません。結果として、Oracle Rdbでは、行を取得する際にSTORE USING句で指定したすべての記憶域が考慮されます。
PARTITIONING句を指定する場合は、記憶域マップの定義でSTORE USING句も指定する必要があります。
PARTITIONING句が指定されていない場合は、UPDATABLEがデフォルトになります。
パーティション化の詳細は、『Oracle Rdb7 Guide to Database Design and Definition』を参照してください。
PLACEMENT VIA INDEX index-name
示したパスによる列へのアクセスを最適化する方法で、列を格納するようデータベース・システムに指示します。指定した索引タイプ(ソートまたはハッシュ)、関連する記憶域タイプ(均一または混在)、および索引と表の記憶域への割当て方法を考慮したルールによって、列を格納するターゲット・ページが選択されます。ハッシュ索引については、列を指し示すハッシュ索引ノードを含むページが計算されます。ページが列を格納する記憶域と同一記憶域内にある場合は、列を格納するターゲット・ページとして使用されます。そのページが列の格納先と同一の記憶域にない場合、(混在記憶域の場合は)該当する記憶域内の相対的な位置にあるターゲット・ページ、または(均一記憶域の場合は)その表用に予約されているクランプのページが選択されます。
ソート索引については、格納されている下から2番目の行のデータベース・キーが検出され、そのデータベース・キーのページ番号がターゲット・ページとして使用されます。
STORAGE MAP map-name
作成する記憶域マップの名前を指定します。この名前はデータベースの他の定義と同じものにはできません。store-clause
記憶域マップ定義です。CREATE STORAGE MAP文のstore-clauseにより、表の行の格納に使用される記憶域ファイルを指定できます。
- 1つの表のすべての行は単一の記憶域に関連付けられます。
- 1つの表の行は複数の記憶域にランダムに分散できます。
- 1つの表の行は、特定の記憶域の列の値に上限を設定することによって、複数の記憶域に体系的に分散またはパーティション化できます。これは水平パーティション化と呼ばれます。
- 1つの表の列は複数の記憶域にパーティション化できます。これは垂直パーティション化と呼ばれます。
記憶域マップ定義を省略すると、デフォルトでは、1つの表のすべての行がデフォルト記憶域に格納されます。デフォルト記憶域の詳細は、「CREATE文」および「IMPORT DATABASE文」を参照してください。
STORE COLUMNS (column-name)
後続のマップに格納される列をリストします。複数のSTORE COLUMNS句がマップに表示され、複数の記憶域に分散される場合があります。列名は1つのSTORE COLUMNS句にのみ表示されます。最後のSTORE句は、指定されていない列すべての場所を指定します。
STORE IN area-name
表を単一の記憶域と直接関連付けます。表のすべての行は指定した領域に格納されます。STORE LISTS IN area-name
指定した記憶域または領域セットの表から、リストを格納するようデータベース・システムに指示します。各データベースに作成できるリストの記憶域マップは1つのみです。STORE LISTS句で、リストのデフォルト記憶域を指定する必要があります。デフォルト・リスト記憶域には、システム表のリスト、および他の場所ではSTORE LISTS句で指示されないリストが含まれます。また、リストのデフォルト記憶域は、CREATE DATABASE文のLIST STORAGE AREA句を使用して指定できます。STORE LISTS句を使用せず、CREATE DATABASE文でリスト記憶域を指定しない場合は、デフォルトの記憶域がデフォルト・リスト記憶域として使用されます。次の例では、記憶域マップで指定されていないかぎり、LISTS記憶域にリストをすべて配置するよう指示します。
SQL> CREATE DATABASE FILENAME mf_personnel SQL> LIST STORAGE AREA IS LISTS SQL> CREATE STORAGE AREA LISTS;
関連する記憶域マップ文では、LISTS記憶域をデフォルト記憶域としても指定する必要があります。
SQL> CREATE STORAGE MAP LISTS_MAP cont> STORE LISTS IN LISTS1 FOR (EMPLOYEES.RESUME) cont> IN LISTS;
領域セットを使用すると、複数の領域に分散するデータを指定できます。次の例では、3つの記憶域(LISTS1、LISTS2およびLISTS3)のデータを、TABLE1の2つの列に格納する方法を示します。デフォルト・リスト記憶域はLISTS1です。
CREATE STORAGE MAP LISTS_MAP STORE LISTS IN (LISTS1,LISTS2,LISTS3) FOR (TABLE1.COL1,TABLE1.COL2) IN LISTS1;
同一領域に複数の表のリストを格納できます。次の例では、TABLE1、TABLE2およびTABLE3のデータをLISTS記憶域に格納する方法を示します。デフォルト・リスト記憶域はRDB$SYSTEMです。
SQL> CREATE STORAGE MAP LISTS_MAP -- to direct the list data to area LISTS cont> STORE LISTS IN LISTS FOR (TABLE1, TABLE2, TABLE3) cont> IN RDB$SYSTEM;
また、特定の領域に各表からのリストを格納できます。次の例では、TABLE1のリスト・データをLISTS1記憶域に格納し、TABLE2のリスト・データをLISTS2記憶域に格納する方法を示します。デフォルト・リスト記憶域はRDB$SYSTEMです。
CREATE STORAGE MAP LISTS_MAP STORE LISTS IN LIST1 FOR (TABLE1) IN LIST2 FOR (TABLE2) IN RDB$SYSTEM;
また、同一表の異なる列が別の領域に格納されるよう指定できます。次の例では、TABLE1の複数の列のデータをLISTS1またはLISTS2のいずれかに格納する方法を示します。デフォルト・リスト記憶域はRDB$SYSTEMです。
CREATE STORAGE MAP LISTS_MAP STORE LISTS IN LISTS1 FOR (TABLE1.COL1) IN LISTS2 FOR (TABLE1.COL2) IN RDB$SYSTEM;
STORE RANDOMLY ACROSS (area-name)
行が表に挿入されると、これらの行がリスト内で指定された複数の記憶域にランダムに分散されます。この句には複数の記憶域を指定する必要があります。STORE USING (column-name) IN area-name
表に挿入された行の代入を判定するため、データベース・システムでは、列の値とWITH LIMIT OF句の値が比較されます。たとえば、STORE USING (X,Y,Z) IN AREA1 WITH LIMIT OF (1,2,3)句のある記憶域マップは、行をAREA1に格納するには、行が次の基準を満たしている必要があることを示します。
( X < 1 ) OR ( ( X = 1 ) AND ( ( Y < 2 ) OR ( ( Y = 2 ) AND ( Z <=3 ) ) ) )
RMU EXTRACTを使用して、式を使用するストアを展開します。例9を参照してください。
STORED NAME IS stored-name
マルチスキーマ・データベースに作成した記憶域へのアクセスに使用される名前を指定します。ストアド名を使用すると、1つのデータベース内では複数のスキーマを認識しないインタフェースを使用して、マルチスキーマ定義にアクセスできます。複数のスキーマに対応しないデータベース内では、記憶域マップのストアド名は指定できません。ストアド名の詳細は、第2.2.18項を参照してください。threshold-clause
形式が均一のページに、記憶域の論理領域のデフォルトしきい値を1つ、2つまたは3つ指定します。しきい値(val1、val2およびval3)はデータ・ページの占有率を示し、データ・ページ上で保証されている空き領域について、考えられる3つの範囲を設定します。データ・ページがあるしきい値で定義されている割合に達した場合は、新しい占有率と残りの空き領域を反映するよう、データ・ページの領域管理(SPAM)エントリが更新されます。Oracle Rdbでは、3つ目のしきい値までレコードが格納されません。最高しきい値に設定した値は、今後のレコード・サイズ増加に備えたページの予約領域として使用されます。
val1のみを指定した場合、これは(val1, 100, 100)に相当します。val1とval2を指定した場合、これは(val1, val2, 100)に相当します。最後の指定されていないしきい値は、デフォルトで100パーセントに設定されます。たとえば、THRESHOLDS ARE (40)は(40, 100, 100)となります。
領域のしきい値が指定されていない場合は、デフォルトは(0,0,0)です。このため、SPAMアルゴリズムにより、索引のノード・サイズや、表の圧縮されていない行の長さなど、論理領域の公称レコード長に基づくしきい値が設定されます。
混合ページ形式の領域の記憶域マップ属性には、しきい値は指定できません。混合ページ形式の場合は、ALTER DATABASE文、CREATE DATABASE文、またはIMPORT文のADD STORAGE AREA句またはCREATE STORAGE AREA句を使用して、記憶域のしきい値を設定します。
VERTICAL PARTITION name
垂直パーティションに名前を付けます。言語または引用ルールがSQL92またはSQL99に設定されている場合、この名前にデリミタ付き識別子を指定できます。パーティション名は記憶域マップで一意である必要があります。この句を指定しない場合は、Oracle Rdbでパーティションのデフォルト名が生成されます。using-clause
複数の記憶域への表の水平パーティション化のための制限として値を使用する列を指定します。WITH LIMIT OF (literal)
指定した記憶域で最初に行を格納する際に、USING句で指定した列に設定できる値の上限を指定します。この句を繰り返して、複数の記憶域に表の行をパーティション化します。
