| Oracle TimesTen In-Memory Databaseアーキテクチャ概要
リリース6.0 B25763-01 |
|


 前へ |
 次へ |
レプリケーションとは、データ・ストア間でデータをコピーするプロセスです。TimesTenレプリケーションの重要な目的は、パフォーマンスへの影響を最小限に抑えて、ミッション・クリティカルなアプリケーションのデータの可用性を高めることにあります。
障害リカバリにおける役割の他に、レプリケーションは、ユーザー負荷を複数のデータ・ストアに分散してパフォーマンスを最大化させたり、「TimesTenのアップグレード」で説明するように、オンライン・アップグレードとメンテナンスを容易にする場合に有効なプロセスです。
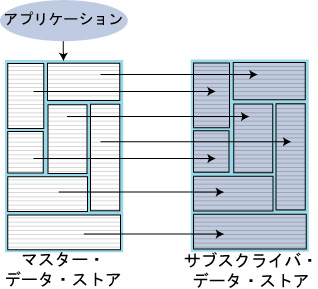
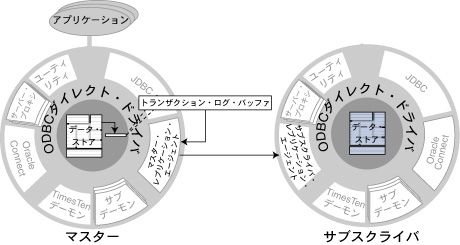
図7.4に示すように、TimesTenレプリケーションは、マスター・データ・ストアに対して実行された更新をサブスクライバ・データ・ストアにコピーします。
図7.4 マスターおよびサブスクライバ・データ・ストア
効率性の向上とオーバーヘッドの低減を実現するために、TimesTenはトランザクション・ログ・ベースのレプリケーション・スキームを使用します。
図7.5に示すように、マスターおよびサブスクライバの各データ・ストアのレプリケーションは、TCP/IPストリーム・ソケットを介して通信するレプリケーション・エージェントによって制御されます。マスター・データ・ストアのレプリケーション・エージェントは、トランザクション・ログからレコードを読み取り、レプリケートされた要素への変更を検出した場合はそれらをサブスクライバ・データ・ストアのレプリケーション・エージェントに転送します。その後、サブスクライバ・データ・ストアのレプリケーション・エージェントが、それらの更新をサブスクライバ・データ・ストアに適用します。マスター・エージェントは、更新転送時にサブスクライバ・エージェントが稼働していない場合、サブスクライバで適用可能になるまでそれらの更新をログに保持します。
図7.5 マスターおよびサブスクライバ・レプリケーション・エージェント
TimesTenのデータ・レプリケーションでは、可用性を高めることに焦点を合わせています。この目的を達成するため、パフォーマンスと可用性間のバランスが最適になるように、様々な方法でTimesTenレプリケーションを構成できます。
レプリケーションはSQL文を介して構成されます。通常、マスターから1つ以上のサブスクライバへの単方向(一方向)、またはマスターおよびサブスクライバの両方として機能する2つ以上のデータ・ストア間の双方向(2方向)になるよう、レプリケーションを構成できます。双方向レプリケーションとして構成される3つ以上のデータ・ストアは、N-wayまたはupdate-anywhereレプリケーションと呼ばれる場合があります。
図7.6 レプリケーション構成スキームの例
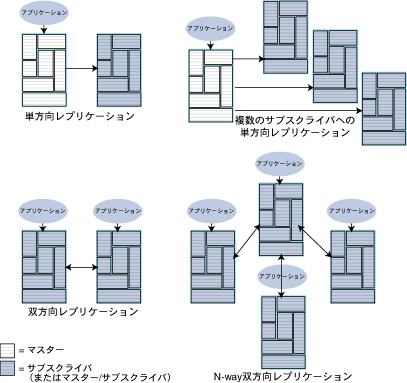
図7.7に、ホットスタンバイ・バックアップ・データ・ストアを実現するための、そしてユーザー負荷をより均等にするための、レプリケーションの構成方法を示します。
ホットスタンバイの構成では、アプリケーション自体に組み込まれた、適切なフェイルオーバー・メカニズムを持つサブスクライバ・データ・ストアに、単一のマスター・データ・ストアがレプリケートされます。ホットスタンバイ・データ・ストアを使用するアプリケーションの例については、「使用例1: 携帯利用者の利用状況計測アプリケーション」および「使用例3: オンライン旅行代理店のアプリケーション」を参照してください。
ロード・バランス化のペア構成では、2つの双方向レプリケーション・データ・ストア間でワークロードを分割できます。図7.7に示すように、ロード・バランス化の構成には、2つの基本タイプがあります。
図7.7 ホットスタンバイとロード・バランシングの構成
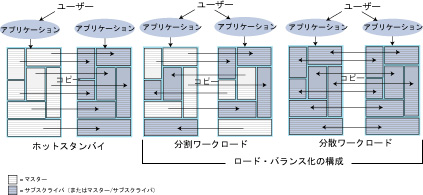
分散ワークロード構成では、アプリケーションで作業を2つのシステム間で分割して、レプリケーションの衝突が発生しないようにする必要があります。衝突が発生した場合、TimesTenにはタイムスタンプ・ベースの衝突検出と問題解消の機能があります。
また、レプリケーションを使用して、1つ以上のデータ・ストアから多数のデータ・ストアに更新を伝播できます。これは、より低い帯域幅の接続で複製データ・ストアを保持する場合や、マスター・データ・ストアを多数のサブスクライバにレプリケートする必要がある構成でレプリケーション・ロードを分散させる(または放射状に広げる)場合に有効です。
図7.8 伝播の構成
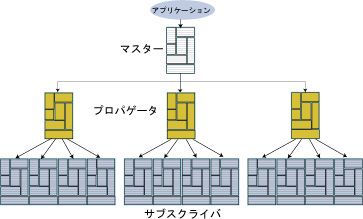
図7.9に、アクティブ・スタンバイ・ペアを示します。
図7.9 アクティブ・スタンバイ・ペア
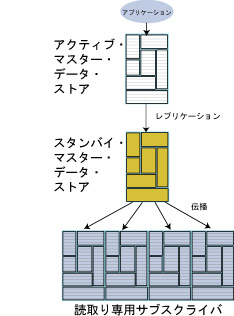
アクティブ・スタンバイ・ペアは、SQL文CREATE ACTIVE STANDBY PAIRによって作成します。CREATE ACTIVE STANDBY PAIR文では、アクティブ・マスター・データ・ストア、スタンバイ・マスター・データ・ストア、サブスクライバ・データ・ストア、およびデータ・ストアを構成する表とキャッシュ・グループを指定します。
アクティブ・スタンバイ・ペアでは、2つのデータ・ストアがマスターとして定義されます。1つは、アクティブ・マスター・データ・ストアで、もう1つはスタンバイ・マスター・データ・ストアです。アクティブ・マスター・データ・ストアは直接更新されます。スタンバイ・マスター・データ・ストアは、直接更新できません。スタンバイ・マスター・データ・ストアは、アクティブ・マスター・データ・ストアからの更新を受信し、それらの変更を最大62の読取り専用サブスクライバ・データ・ストアに伝播します。この構成では、スタンバイ・マスター・データ・ストアがサブスクライバ・データ・ストアより常に先行し、アクティブ・マスター・データ・ストアで障害が発生した場合は、スタンバイ・データ・ストアに即時にフェイルオーバーできます。
1つのマスター・データ・ストアのみが、特定の時間にアクティブ・マスター・データ・ストアとして機能できます。アクティブ・ロールは、ttRepStateSetプロシージャを使用して指定します。アクティブ・データ・ストアで障害が発生した場合、ユーザーは、ttRepStateSetプロシージャを使用して、障害が発生したデータ・ストアをスタンバイ・データ・ストアとしてリカバリする前に、スタンバイ・マスター・データ・ストアのロールをアクティブに変更できます。新しいスタンバイ・マスター・データ・ストアで、レプリケーション・エージェントを起動する必要があります。
スタンバイ・マスター・データ・ストアで障害が発生した場合は、アクティブ・マスター・データ・ストアでサブスクライバに変更を直接レプリケートできます。スタンバイ・マスター・データ・ストアは、リカバリ後、アクティブ・マスター・データ・ストアに接続し、スタンバイ・マスター・データ・ストアの停止またはリカバリ中にサブスクライバに送信された更新を受信します。アクティブ・マスター・データ・ストアとスタンバイ・マスター・データ・ストアで同期が取られている場合、スタンバイ・マスター・データ・ストアは、サブスクライバへの変更の伝播を再開します。
TimesTenレプリケーションは、デフォルトでは非同期メカニズムになります。非同期レプリケーションを使用する場合、アプリケーションは、マスター・データ・ストアを更新すると、サブスクライバがその更新を受信するまで待機せずに処理を続行します。マスターおよびサブスクライバのデータ・ストアには、サブスクライバが更新を正常に受信およびコミットしたことを確認するための内部メカニズムがあります。これらのメカニズムは、更新がサブスクライバで1回のみ適用されることを保証しますが、アプリケーションでは完全に透過的です。
非同期レプリケーションは最高のパフォーマンスを実現しますが、アプリケーションは、サブスクライバ上のレプリケートされた要素の受信プロセスと完全に切り離されます。また、TimesTenでは、レプリケートされたデータがマスター・データ・ストアとサブスクライバ・データ・ストア間で一貫していることをより高いレベルで保証する必要がある即時アプリケーションに、2つのRETURN RECEIPTサービス・オプションを提供します。
RETURNサービスを使用するアプリケーションでは、パフォーマンスは低下しますが、マスター・データ・ストアとサブスクライバ・データ・ストア間でのより高いレベルのデータの整合性および一貫性が保証されます。このアプリケーションでは、マスターで障害が発生した場合でも、マスターでコミットされたトランザクションがサブスクライバ・データ・ストアに保持されることが高度なレベルで保証されます。RETURN RECEIPTのレプリケーションでは、同期性を低くすることによって、RETURN TWOSAFEのレプリケーションよりパフォーマンスへの影響が小さくなっています。
図7.10 非同期およびRETURNサービス・レプリケーション

パフォーマンスに及ぼす影響を最小限に抑え、ミッション・クリティカルなアプリケーションのデータの可用性を高めるには、できるかぎりシームレスな方法で、障害のあったデータ・ストアから、保持されているそのバックアップにユーザーを移動することが必要になります。
フェイルオーバーとリカバリ処理の管理は、TimesTenでは行えません。かわりに、TimesTenレプリケーションは、カスタムとサード・パーティ両方のクラスタ・マネージャと連携して動作するように設計およびテストされています。クラスタ・マネージャは、障害を検出し、ユーザーやアプリケーションを障害が発生したデータ・ストアからそのサブスクライバの1つにリダイレクトし、障害のあったデータ・ストアのリカバリを管理します。クラスタ・マネージャまたは管理者は、TimesTenのttRepAdmin -duplicateユーティリティまたはttRepDuplicateEx() C関数を使用して、障害の発生していないデータ・ストアを複製し、障害の発生したデータ・ストアをリカバリできます。
通常、サブスクライバの障害は、マスター・データ・ストアに接続したアプリケーションに影響を及ぼすことはなく、ユーザー・サービスを中断させることなくリカバリできます。一方、マスター・データ・ストアで障害が発生した場合、サービスを中断させずに、または最小限の中断でサービスを継続するために、クラスタ・マネージャはアプリケーション負荷をサブスクライバにリダイレクトする必要があります。
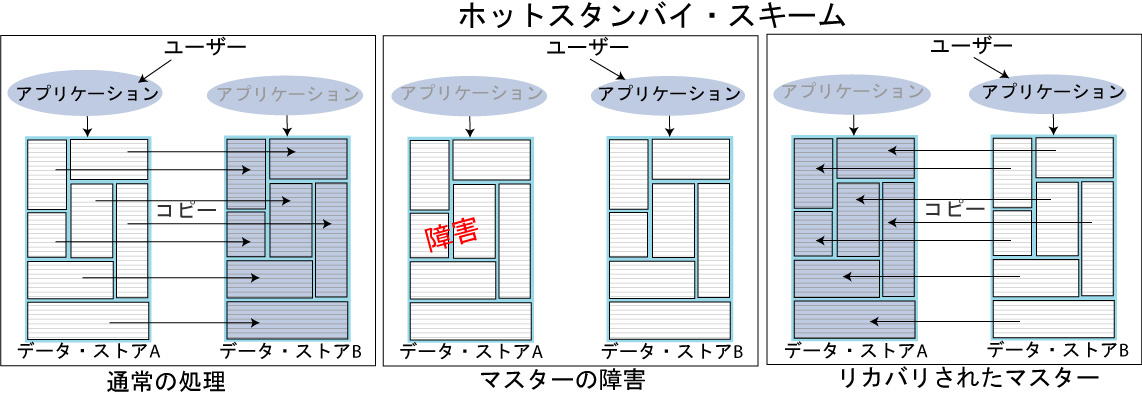
図7.11のホットスタンバイ・スキームや図7.12の分散ワークロード・スキームのように、データ・ストアが双方向の一般ワークロード・スキームで構成される場合、フェイルオーバーとリカバリはより効率的です。
ホットスタンバイ・スキームでは、マスター・データ・ストアで障害が発生した場合にクラスタ・マネージャで必要となるのは、サブスクライバ・データ・ストア上のホットスタンバイ・アプリケーションに、ユーザー負荷をシフトすることのみです。障害のあったデータ・ストアのリカバリでは、マスター・データ・ストアとサブスクライバ・データ・ストアの役割を交替させることで、サービスの中断を最小限に抑えてレプリケーションを再開できます。
図7.11 ホットスタンバイ・スキームのフェイルオーバーの使用例
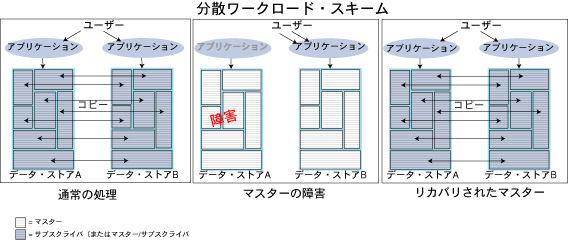
分散ワークロード・スキームを使用して構成したデータ・ストアのフェイルオーバーの手順は、障害のあったデータ・ストアの影響を受けたユーザーを移動して、障害が発生していないデータ・ストア上の他のアプリケーションのユーザーに加えることを除けば、ホットスタンバイで使用する手順と類似しています。リカバリが完了すると、リカバリしたデータ・ストア上のアプリケーションにワークロードを再分散できます。
図7.12 分散ワークロード・スキームのフェイルオーバーの使用例