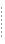| ドキュメントのダウンロード | サイトマップ | 用語集 | |
|
|||
| bea ホーム | 製品 | dev2dev | support | askBEA |
|
|
||||||||
| e-docs > Tuxedo > Tuxedo システム入門 > BEA Tuxedo ATMI のアーキテクチャ |
|
Tuxedo システム入門
|
BEA Tuxedo ATMI のアーキテクチャ
以下の節では、BEA Tuxedo ATMI 環境の基本的な構成要素について説明します。
BEA Tuxedo ATMI 環境の基本アーキテクチャ
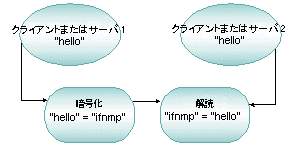
次の図は、BEA Tuxedo ATMI 環境を構成する基本的な要素を示しています。BEA Tuxedo は、システムへの外部インターフェイス、ATMI 層、MIB、BEA Tuxedo システムの各サービス、および標準に準拠したリソース・マネージャとのインターフェイスから構成されます。
図 2-1 BEA Tuxedo ATMI の基本アーキテクチャ
この図で示してあるように、BEA Tuxedo ATMI 環境は次の要素から構成されています。 
ATMI の使用
BEA Tuxedo API である ATMI は、通信、トランザクション、およびデータ・バッファ管理を行うためのインターフェイスで、BEA Tuxedo システムでサポートされているすべての環境で動作します。ATMI によって、アプリケーション・プログラムと BEA Tuxedo システムとが接続されます。ATMI は、広範囲にわたる各種機能に対する 1 つの単純なインターフェイスです。ATMI には、トランザクション処理の X/Open DTP モデルがインプリメントされています。
図 2-2 ATMI の使用
ATMI ライブラリには、BEA Tuxedo ATMI アプリケーションでグローバル・トランザクションを定義し、制御するための各種の関数 (ルーチンなど) が含まれています。グローバル・トランザクションを使用すると、分散アプリケーションにおいて、複数のプログラムとリソース・マネージャにかかわる排他的な操作単位を管理できます。1 つのトランザクションでのすべての操作は、1 つの論理単位として扱われます。そのため、タスクを正常に完了できないプログラムが 1 つでもあると、そのトランザクションではプログラムによってどの操作も実行されません。 ATMI 関数は、プログラム間でデータを送受信できるようにして、分散プログラムを互いに結び付けます。すべてのATMI 関数は、型付きバッファでデータを送受信します。 次の表は、C および COBOL のバインディング対応の ATMI 関数と、それらの関数によって行われる処理を示しています。関数は、タスクごとに分類されています。
注記 BEA Tuxedo ATMI トランザクション管理関数を使用することは必須ではありません。BEA Tuxedo は X/Open TX トランザクション管理関数もサポートしているので、トランザクション管理にそれらの関数を使用することもできます。 関連項目
BEA Tuxedo のメッセージング・パラダイム
アプリケーションのサーバ・プロセスの管理およびトランザクションの管理に加えて、BEA Tuxedo ATMI ではクライアント/サーバ通信も管理します。つまり、クライアント (およびサーバ) が次表で示されたメッセージング パラダイムのいずれかを使用してアプリケーション・サービスを呼び出せるようにします。
要求/応答型通信 ATMI クライアントとサーバの間で要求/応答型通信をインプリメントするために、BEA Tuxedo システムではプロセス間通信 (IPC) メッセージ キューを使用します。キューは、コネクションレス型通信の基本要素です。各サーバには、要求キューと呼ばれる IPC メッセージ・キューが割り当てられ、各クライアントには応答キューが割り当てられます。そのため、クライアント・アプリケーションでは、サーバとの継続的な接続を確立する代わりに、要求をサーバのキューに登録して、サーバにその要求を送信できます。また、アプリケーションの応答キューからメッセージを取り出して、サーバからのメッセージを確認して取得できます。 要求/応答型モデルは、同期と非同期の両方のサービス要求に使用できます。 同期メッセージング 同期呼び出しでは、クライアントがサーバに要求を送信し、クライアントが待機している間にサーバが要求された処理を行います。その後、サーバがクライアントに応答を送信し、クライアントが応答を受信します。 図 2-3 同期要求/応答型通信
非同期メッセージング 非同期呼び出しでは、BEA Tuxedo クライアントは、送信したサービス要求の処理が完了するまで待機しません。要求を発行した後も、別のタスク (ほかの要求の発行など) を実行します。最初の要求への応答が返されると、クライアントはその応答を取得します。 図 2-4 非同期要求/応答型通信
会話型通信 会話型通信は BEA Tuxedo システムのメッセージ交換のパラダイムで、人の会話に似た通信がクライアントとサーバ間でインプリメントされています。この通信方法では、クライアントとサーバ間に仮想の接続が行われます。人が 2 人で会話するように、ある結論に達するまで、2 つのエンティティ間で数多くのメッセージがやり取りされます。通信が行われている間、両者によって会話のポイント (または状態) が「記憶」されます。そのため、一時的な照会、レポート、ファイル転送などの比較的時間のかかる操作をサポートできます。デフォルトで、会話型サーバを使用できます。必要に応じて、自動的にサーバを追加することもできます。 BEA Tuxedo システムでは、アプリケーション内で会話を作成するための API が提供されています。この API を使用して、クライアントをサーバに接続し、メッセージを送受信し、会話を終了します。 図 2-5 会話型通信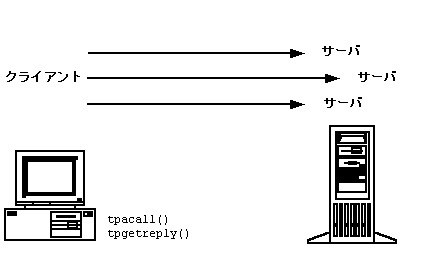
会話は入れ子にすることもできます。ただし、そのためにパフォーマンスが低下する場合があります。会話には、トランザクションまたはサービス要求のいずれかが含まれます。会話型サービスによってサービス呼び出しを行ったり、会話を確立できます。ただし、これらのサービス呼び出しと会話は転送できません。会話は、トランザクションのスコープ内に置いて、トランザクションによって制御されます。 メッセージ・キューイング通信 BEA Tuxedo システムでは、/Q と呼ばれるキュー・ベースのアーキテクチャが提供されています。これは、ATMI アプリケーションでデータを継続的に格納する必要がある場合に使用します。/Q コンポーネントでは、すべてのクライアントまたはサーバがメッセージまたはサービスの要求をキューに格納できます。格納された要求は、必ずトランザクション・プロトコルを使用して送信されるので、安全が保証されています。 BEA Tuxedo システムのキューは、後入れ先出し (LIFO) または先入れ先出し (FIFO)、または時刻や優先順位に基づいて順序付けすることができます。キューの集まりは、キュー・スペースと呼ばれる 1 つのエンティティとして管理され、参照されます。 図 2-6 キュー・ベースのメッセージング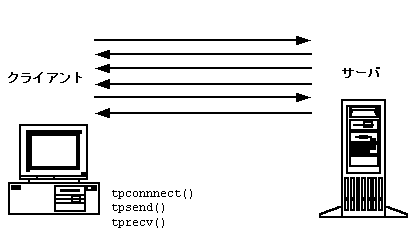
アプリケーション・キューは、時間に依存しない通信を行う場合に使用します。時間に依存しない通信とは、プログラムが互いに独立して動作し、互いの通信を同期する必要がない通信方法です。時間に依存しないプログラムでは、互いにアプリケーション・キューにメッセージを残すことによって同期が行われます。メッセージをキューから取り出す場合は、FIFO 順、優先順位、時刻順など、任意の順序付けスキーマを使用できます。BEA Tuxedo のクライアント・プログラムとサーバ・プログラムでは、メッセージをキューに登録したり、キューから取り出すことができます。同じキューに複数のクライアントやサーバがアクセスできます。 アプリケーション・キューを使用するには、アクセスするキューと、そのキューが置かれたキュー・スペースに名前を付ける必要があります。アプリケーションでは、複数のキュー・スペースを使用できます。また、各キュー・スペースには、複数のメッセージ・キューを格納できます。 アプリケーション・キューはディスク上に存在するため、格納したメッセージはマシンに障害が発生した場合でも利用できます。どのような場合にアプリケーション・キューを使用するかは、業務 (たとえば、注文書の入力) で時間に依存しない同期をいつ行うかによって決定されます。注文書は、ディスク上のキューに登録し、品目や出荷場所など特定の注文条件によって、異なるキュー・スペースに置くことができます。各キュー・スペースに、コストや状態などの条件を追加することもできます。 パブリッシュ・アンド・サブスクライブ通信 BEA Tuxedo のイベント・ブローカと呼ばれるパブリッシュ・アンド・サブスクライブ・コンポーネントは、任意の数の供給者が任意の数のサブスクライバにメッセージをポストできる通信パラダイムを提供します。イベント・ブローカを使用する ATMI クライアント・プロセスとサーバ・プロセスは、「サブスクリプション」に基づいて相互に通信します。イベント・ブローカでは、購読料を支払っている購読者だけに新聞を配達するように、処理が行われます。 図 2-7 イベントのポストとサブスクライブ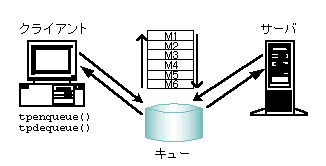
イベントの発信元 (クライアントまたはサーバのいずれか) は、変更や問題が起こると、イベント・ブローカに通知します。このプロセスはイベントのポストと呼ばれます。通知を受けたイベント・ブローカは、そのイベントの名前をサブスクライバのリストに定義されたイベント名と照合し、合致した場合はそのサブスクライバにイベントを通知します。 通知されるイベントのタイプ BEA Tuxedo システムでは、次のイベントが通知されます。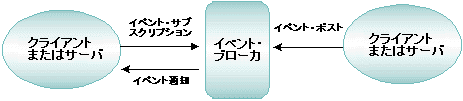
イベントの通知
プロセスは、イベント・ブローカにサブスクリプションを登録し、特定のイベントに関心があることを示します。以降、指定されたイベントが発生したことが別のプロセスから通知されると、イベント・ブローカはそのイベントをサブスクライブしているすべてのプロセスに通知します。
図 2-8 イベント・ベースのメッセージング
イベント・ブローカでは、次のメカニズムを使用して、イベントのパブリッシュ (通知の発行) が行われます。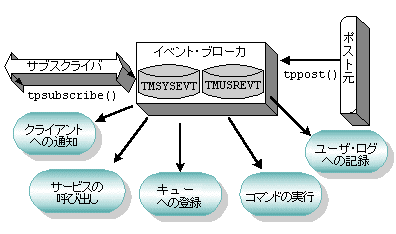
任意通知型通信
BEA Tuxedo システムでは、任意通知型通知と呼ばれる通信パラダイムが提供されています。任意通知型通知が発生すると、ATMI クライアントは要求していないメッセージを受け取ります。イベント・ブローカによって管理されるこの機能によって、アプリケーション・クライアントは、アプリケーション固有のイベントが発生したときに、リアルタイムで明示的に通知を要求しなくても、そのイベントの通知を受け取ることができます。
任意通知型メッセージは、名前 (tpbroadcast) または以前に処理されたメッセージと共に受け取った識別子 (tpnotify) としてクライアント・プロセスに送信されます。tpbroadcast 関数を使用すると、サービスまたは別のクライアントにメッセージを送信できます。メッセージは、狭い範囲または広い範囲のターゲットに対して送信できます。配達保証付きまたは配達保証なしのメッセージをポイント・ツー・ポイントの通知によって個々のクライアントに送信したり (tpnotify)、クライアントのグループに対して情報を送信する (tpbroadcast) ことができます。たとえば、クライアントから照会された口座が解約されていることをサーバからそのクライアントだけに通知できます。または、あるマシンがメンテナンスのために特定の時刻にシャットダウンされることをそのマシン上のすべてのクライアントに通知することもできます。
図 2-9 任意通知型通知のメッセージング
プロセスが特定のイベント (メンテナンスのためにシャットダウンされるマシンなど) について通知が必要な場合は、自動的に通知されるように要求をシステムに登録できます。登録されたイベントは、発生するたびにクライアントまたはサーバに通知されます。イベントのこのような自動通信は、任意通知型通知と呼ばれます。 イベントを生成したり、イベントについて任意通知型通知を受信するクライアントおよびサーバの数に制限はありません。そのため、このカテゴリの通信は、管理業務が複雑になる場合があります。 関連項目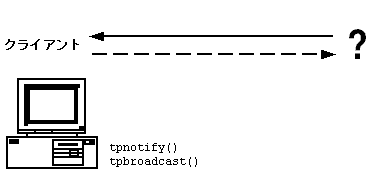
要求の入れ子と転送
サービス要求の入れ子および転送を利用すると、BEA Tuxedo サービスは ATMI クライアントとして機能して他のサービスを呼び出すことができます。
入れ子になった要求
入れ子のレベルは、2 レベルに制限されています。これは、3 層クライアント/サーバ・アーキテクチャ、つまりプレゼンテーション・ロジック層、ビジネス・ロジック層、およびデータベース層から構成されるシステムで特に有用です。このようなシステムでは、プレゼンテーション層で特定のビジネス関数が要求され、データベースに 1 つ以上の照会が行われます。入れ子は 2 レベルに制限されているため、パフォーマンスが低下することはありません。
図 2-10 入れ子になったサービス要求
入れ子になった要求の利点 入れ子になった要求を使用すると、各コード部分が限定された処理だけを行うので、コードが少なくて済み、再利用も可能になります。ただし、システムのサービスが複数のサーバに分散している場合は、要求を入れ子にするとパフォーマンスが低下する場合があります。入れ子になった要求が処理されている間、元のサービス (入れ子になった要求を発行したサービス) は、応答を待機する必要があります。つまり、応答を受信するまで、別の要求を処理することはできません。そのため、このサービスを持つサーバの要求キューに、メッセージがバックアップされます。 入れ子になったサービス要求の例 ある顧客が現金自動支払機を使って、普通口座から当座預金に預金を移すとします。振替に必要な操作は、BEA Tuxedo アプリケーションによって行われます。まず、顧客に代わって、クライアントが TRANSFER サービスへの要求を発行します。この要求は、そのサービスを提供するサーバのキューに置かれます。次に、TRANSFER サービスが WITHDRAW および DEPOSIT という 2 つのサービスを要求します。この 2 つのサービスは、別のサーバによって行われます。WITHDRAW および DEPOSIT の各サービスが TRANSFER サービスに応答を返します。最後に、TRANSFER サービスがクライアントの応答キューに対して応答を送ります。クライアントがキューから応答を取得すると、現金自動支払機の画面に振替が完了したことを通知するメッセージが表示されます。 要求の転送 入れ子になったサービス要求に代わる方法として、要求の転送があります。クライアントの要求を処理する代わりに、サービスはその要求を別のサービスに渡します。要求を受け取ったサービスは、要求を処理するか、または別のサービスに渡します。 図 2-11 サービス要求の転送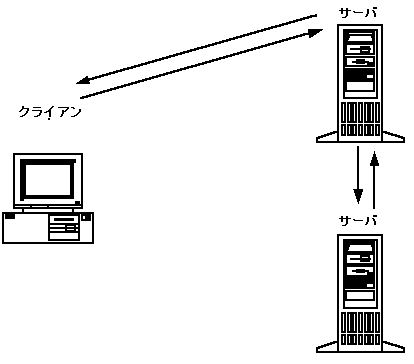
要求を転送できる回数に制限はありません。要求を転送したサービスは、その要求を受け取った別のサービスからの応答を待つ必要がありません。そのため、入れ子になった要求とは異なり、転送ではサーバがブロックされることはありません。ただし、転送は X/Open のプロトコル X/ATMI でサポートされていないため、アプリケーションによっては支障が出る場合があります。 関連項目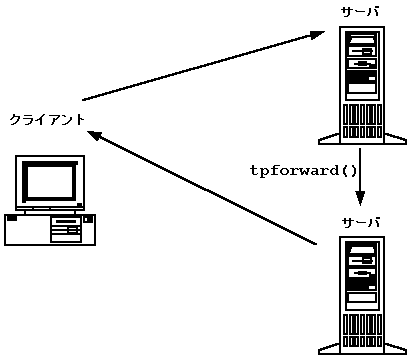
BEA Tuxedo によるメッセージの処理
BEA Tuxedo ATMI 環境内のすべての通信は、メッセージを転送することによって行われます。BEA Tuxedo システムでは、オペレーティング・システム (OS) のプロセス間通信 (IPC) メッセージ・キューを使用して、ATMI クライアントとサーバ間でサービス要求のメッセージをやり取りします。システムのメッセージとデータは、バッファに格納され、クライアントとサーバのキュー間でやり取りされます。これは、OS でサポートされたメモリ・ベースのキューです。BEA Tuxedo ATMI 環境では、メッセージは型付きバッファにパッケージ化されます。このバッファには、メッセージ・データと、送信されたメッセージ・データのタイプを識別するデータが格納されます。
図 2-12 要求の処理
クライアントは、ATMI 関数を使ってサービスを名前で要求します。ネーミング機能を使って MIB が照会され、指定されたサービスが現在利用可能かどうかが確認されます。 BEA Tuxedo システムでは、データ依存型ルーティングが使用されます。データ依存型ルーティングは、特定の条件 (メッセージの値) を満たすメッセージを特定のサーバにマップする自動ルーティング・オプションです。メッセージにデータ依存型ルーティングが使用される場合、ルーティング・アルゴリズムではバッファに格納されたデータが使用されます。このアルゴリズムによって、サービス要求を処理できるサーバのグループが選択されます。 一部のサーバに要求が集中し、同じサービスを宣言するほかのサーバがアイドル状態になることを避けるために、BEA Tuxedo システムではサービス要求をすべてのサーバ間で均等に分散するために MIB を使用しています。これはロード・バランシングと呼ばれます。 選択されたサーバに対してローカルのサービス要求が用意され、そのサーバのキューに定義済みの優先順位で登録されます。これはサービスの優先順位付けと呼ばれます。サービス要求がサーバ上に置かれると、ランタイム・システムによってメッセージが優先順位に従って取得されます。メッセージは、適切なサービスにディスパッチされて、処理されます。その後、クライアントのキューに結果が返されます。 BEA Tuxedo システムで提供されるソフトウェアには、メッセージ処理の際にアプリケーションが自動的に、そして定期的に使用できる機能があります。たとえば、データの符号化と復号化、データの圧縮と圧縮解除、トランザクション・コンテキストの設定、セキュリティに関する処理などがあります。また、BEA Tuxedo システムのソフトウェアは、サービス関数をディスパッチし、それを適切に前処理されたバッファに渡すことによって、アプリケーションのビジネス・ロジックを呼び出します。 サービス・ルーチンが実行されると、応答 (型付きバッファ) が返されます。ランタイム・システムは、メッセージを自動的に符号化することによって、クライアントへの応答を用意します。つまり、バイトの並び順が異なるマシン間で転送できるようにデータをパッケージ化し、データがネットワークやプラットフォームの境界を越えて転送できるようにします。その後、メッセージをクライアントに送信します。このプロセスはデータの符号化と呼ばれます。クライアント上のランタイム・システムは、応答メッセージを取得し、必要に応じて復号化した後、フィールド操作言語 (FML) バッファ (またはほかのメッセージ・バッファ・タイプのバッファ) を送信してアプリケーション・データをパッケージ化します。必要に応じて、タイプの検証、符号化、ルーティング、およびロード・バランシングが行われます。サービス要求は、同期でも非同期でも実行されます。 リモート要求は、ローカル・ブリッジを通ってリモート・マシンに到達します。リモート・マシンでは、リモート・ブリッジがクライアントとして動作し、クライアントとサーバが同じマシン上にあるかのように要求が処理されます。ブリッジは、標準のデータ符号化/復号化を行い、標準のネットワーク転送を使用して通信します。クライアントとサーバからは、ブリッジは通常のローカル・サーバのように見えます。 サービス要求処理の利点 サービス要求処理の利点は次のとおりです。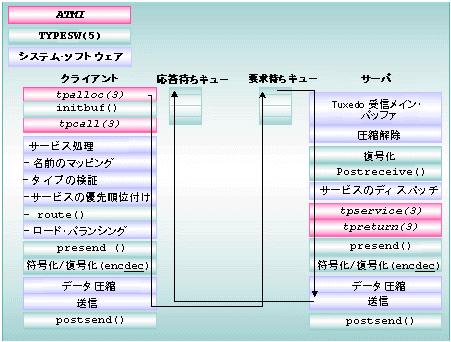
関連項目
型付きバッファ
すべての ATMI 関数は、型付きバッファを使ってデータを送受信します。BEA Tuxedo システムでは、異種のマシン間での翻訳とデータ変換が可能です。BEA Tuxedo プログラムではバッファが使用されているので、異なるデータ表現の異種プラットフォーム間でやり取りされるデータを変換する必要はありません。
バッファとは、データの論理的な入れ物として機能するメモリ領域です。バッファにメタデータ (バッファ自体に関する情報) が含まれていない場合、そのバッファは型なしのバッファと呼ばれます。バッファ内に格納できる情報として、タイプとサブタイプ、またはバッファを特徴付ける文字列名などのメタデータが含まれている場合、そのバッファは型付きバッファと呼ばれます。
型付きバッファは、BEA Tuxedo システムでサポートされる任意のプロトコルを使用して、どの種類のネットワークからもどの種類のオペレーティング・システムにも送ることができできます。異なるデータ表現のプラットフォーム上で使用することもできます。そのため、型付きバッファを使用すると、異種マシン間での翻訳とデータ変換のためのタスクが簡略化されます。
BEA Tuxedo システムでは、次の 5 種類の型付きバッファがサポートされています。
バッファ・タイプは、Tuxedo (UBBCONFIG) コンフィギュレーション・ファイルの MACHINES セクションに定義されている ENVFILE パラメータで指定します。Tuxedo コンフィギュレーション・ファイルの SERVERS セクションの ENVFILE パラメータでバッファ・タイプを指定したり上書きすると、バッファ・タイプが必要なプロセスでそれらのバッファ・タイプを使用できなくなる場合があります。
メッセージ・バッファの各種のタイプの定義については、『BEA Tuxedo のファイル形式とデータ記述方法』の tuxtypes(5) の tm_typesw の説明を参照してください。
バッファ・タイプの特徴
ATMI 通信関数を使用する場合、まずアプリケーションで tpalloc を使用して、バッファのサイズ、タイプ、およびサブタイプ (省略可能) を指定し、システムからバッファを取得する必要があります。BEA Tuxedo システムによってバッファ・タイプが認識されて処理されるため、データは BEA Tuxedo システムによってサポートされているどの種類のネットワーク、プロトコル、およびオペレーティング・システム上でも転送できます。さまざまなタイプの BEA Tuxedo バッファの説明については、『C 言語を使用した BEA Tuxedo アプリケーションのプログラミング』の「型付バッファの管理」を参照してください。
関連項目
データ圧縮
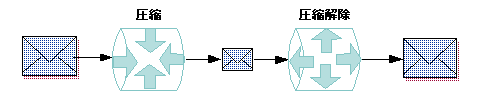
データ圧縮とは、ネットワーク上またはリモート・ドメインへの転送を高速化するために、アプリケーション・バッファを縮小するプロセスです。アプリケーション・バッファの最大サイズを指定し、そのサイズ以上のアプリケーション・バッファが自動的に圧縮されるように設定できます。バッファが送信先に到着すると、データは圧縮解除されて元のサイズに戻ります。
マシン間でファイルを送付する前にデータ圧縮を行うと、ネットワークのパフォーマンスが向上します。圧縮の過程ではデータのスクランブリングも行われるので、セキュリティも若干強化されます。
注記 データ圧縮は、暗号化でも頻繁に行われます。
図 2-13 データ圧縮
データ依存型ルーティング
BEA Tuxedo システムでは、データ依存型ルーティングと呼ばれる操作を使用して、クライアントが同じサービスへの要求をそのサービスの複数のコピーに対して送信できるようにします。サービスのどのコピーが最終的に要求を受け入れて処理するのかは、要求メッセージのデータによって決まります。管理者がアプリケーションにデータ依存型ルーティングを設定すると、クライアントの要求は要求内のデータに基づいて自動的にサーバにルーティングされます。
百科事典の第 1 巻に「A」で始まる項目が複数含まれているように、アプリケーションに同じサービスのコピーが複数含まれている場合、各コピーに対して一意な目的が割り当てられます。そのサービスのすべてのコピーのリストと、各コピーの目的に関する情報の識別文字列は、BEA Tuxedo の掲示板 (MIB の動的部分) のルーティング・テーブルに保持されています。システムがクライアントの要求を受信すると、要求メッセージ内の識別文字列を読み取り、その文字列を掲示板のルーティング・テーブルで検索します。文字列が合致すると、クライアントの要求を転送する適切なサーバが識別されます。
注記 掲示板のルーティング・テーブルは、必要に応じて変更できます。
データ依存型ルーティング
データ依存型ルーティングは、クライアントが次のものにサービスを要求した場合に有用です。
水平分離型データベースとは、セグメントに分割された情報リポジトリです。各セグメントには、異なるカテゴリの情報が格納されます。これは、各本棚に異なるカテゴリ (伝記、フィクションなど) の本が収納されている図書館に似ています。
ルール・ベース・サーバとは、サービス要求をサービス・ルーチンに転送する前に、サービス要求が特定のアプリケーション固有の条件を満たしているかどうかを判定するサーバです。ルール・ベース・サーバは、ほとんど同じ複数の要求に対して、ビジネス上の理由で多少異なる処理を行う場合に使用すると有用です。
分散アプリケーションとは、1 つ以上のローカルまたはリモートのクライアントが、ネットワーク接続された複数のマシン上の 1 つ以上のサーバと通信するアプリケーションです。クライアント (またはクライアントとして動作するサーバ) は、特定のサービスに対する要求を発行します。要求のアドレスは、その要求を実行できるサーバを識別するデータ (要求と同じバッファで転送されるデータ) によって決定されます。要求を実行できるサーバが複数存在する場合もあります。BEA Tuxedo システムでは、掲示板のルーティング条件とデータが照合されて、要求を受け取るサーバが決定されます。
水平分離型データベースでのデータ依存型ルーティングの例
銀行取引アプリケーションで 2 つのクライアントが口座 3 と口座 17 という 2 つの口座の現在の残高を照会する要求を発行したとします。アプリケーションでデータ依存型ルーティングが使用されている場合、BEA Tuxedo システムでは次の処理が行われます。
次の図は、このプロセスを示しています。
図 2-14 水平分離型データベースでのデータ依存型ルーティング
ルール・ベース・サーバでのデータ依存型ルーティングの例 次の規則を持つ銀行取引アプリケーションがあるとします。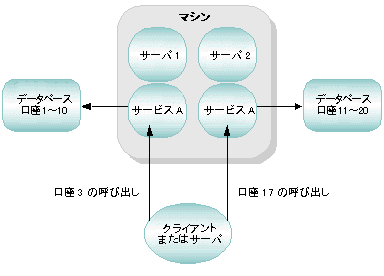
2 つのクライアントが1 万円と 8 万円の引き出しを要求したとします。引き出しの規則でデータ依存型ルーティングが有効になっている場合、BEA Tuxedo では次のような処理が行われます。
次の図は、このプロセスを示しています。
図 2-15 ルール・ベース・サーバでのデータ依存型ルーティング
分散アプリケーションでのデータ依存型ルーティングの例 次の図は、分散アプリケーションでクライアントの要求がサーバにルーティングされる方法を示しています。この例では、bankapp という銀行取引アプリケーションでデータ依存型ルーティングが使用されています。bankapp には、3 つのサーバ・グループ (BANK1、BANK2、BANK3) と 2 つのルーティング条件 (Account ID と Branch ID) があります。WITHDRAW、DEPOSIT、および INQUIRY の 3 つのサービスは、Account_ID フィールドを使用してルーティングされます。サービス OPEN および CLOSE は、Branch_ID フィールドを使用してルーティングされます。 図 2-16 ルーティング条件を使用した銀行取引のサンプル・アプリケーション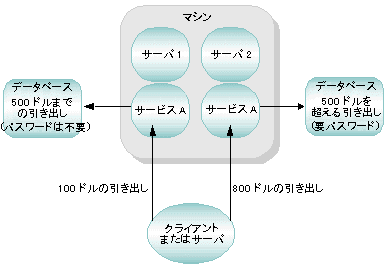
データの符号化と復号化
符号化と復号化を行うと、データ表現 (バイトの順序や文字セットなど) が異なるメッセージをマシン間で転送できるようになります。BEA Tuxedo システムでは、BEA Tuxedo アプリケーションに関与する他のマシンに転送できるように、マシンに依存しない表現にデータを符号化および復号化します。
BEA Tuxedo システムではデフォルトで、外部データ表現 (XDR) アルゴリズムが採用されています。BEA Tuxedo システムの関数をユーザ定義の関数で置き換えると、このアルゴリズムをカスタマイズできます。符号化および復号化は、マシン間でのみ使用されます。また、リモート・マシンのデータ表現がローカル・マシンのものと異なる場合にのみ使用されます。符号化と復号化によって、異なるデータ構造を持つマシンが異機種の BEA Tuxedo システムで動作できるようになります。プログラマは、それぞれの環境に適した表現でデータを管理できます。
BEA Tuxedo システムでは、バッファ・タイプを使用して、メッセージに含まれるフィールドのタイプが判別されたり、コードディングに必要なマッピングが行われます。このマッピングは、X_OCTET や CARRAY などの構造化されていないバッファ・タイプによって行われるものではありません。そのため、異機種が混在している環境でも、開発者は X_OCTET および CARRAY 型バッファを自由に運用できます。
データの暗号化
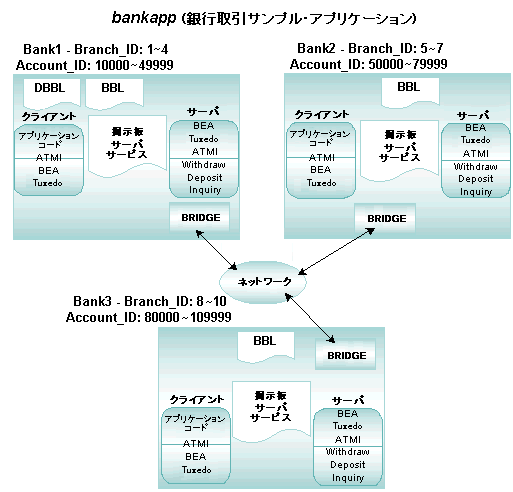
暗号化とは、メッセージをコード化された形式に変換して、メッセージの受け取りユーザ以外のすべてのユーザが解読できないようにすることです。暗号化されたメッセージは、送信先に到着すると解読されます。つまり、元の形式に変換されます。
図 2-17 データの暗号化
データの暗号化
データ・マーシャリングとは、BEA Tuxedo システムによって提供される言語ベースの TxRPC (X/Open-TxRPC) を使用して情報を扱う方法です。TxRPC はリモート・プロシージャ・コール (RPC) 用のプロトコルで、グローバル・トランザクションがサポートされます。TxRPC 呼び出しは、ローカル・プロシージャ・コールのように見えます。しかし、C 言語の関数が呼び出されると、関数に渡される引数がパッケージ化されてサーバに送られ、そこで呼び出された関数の処理が行われます。このような引数のパッケージ化をマーシャリングと呼びます。関数の引数は、ネットワークやプラットフォームの境界を越えることができるようにマーシャリング、つまりパッケージ化されます。そして、呼び出されたリモート・プロシージャに渡される前に、送信先でマーシャリングが解除されて、プロシージャで使用できる状態になります。
このプロセスは、クライアント (呼び出し元のプログラム) およびサーバ (リモート・プロシージャ) に透過的です。マーシャリングとマーシャリング解除のルーチンは、BEA Tuxedo のインターフェイス定義言語 (IDL) コンパイラによって自動的に生成されます。IDL コンパイラは RPC の記述を受け取り、クライアント・プログラムとサーバ・プログラムに対してスタブと呼ばれるルーチンを生成します。これらのスタブには、クライアントとサーバがマーシャリングされたデータを交換するための通信ロジック、およびマーシャリングとマーシャリング解除のロジックが含まれています。
図 2-18 データ・マーシャリング
ロード・バランシング
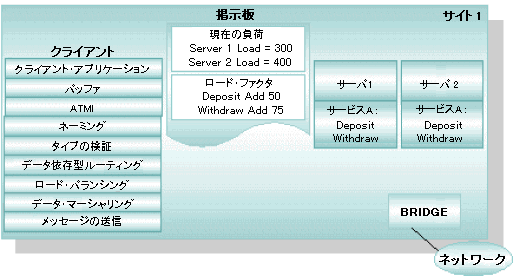
ロード・バランシングとは、同じサービスを提供するサーバ間でサービス要求を均等に分散する BEA Tuxedo システムの機能です。ロード・バランシングを使用すると、負荷の重いサーバがある一方で、アイドル状態または使用頻度の低いサーバが生じる状態を防ぐことができます。要求をサービス・ルーチンに送信する前に、その要求を処理できるすべてのサーバが BEA Tuxedo システムで識別され、コンフィギュレーション内のすべてのサーバで負荷を均衡化するために最も適したサーバが選択されます。
ロードとは、サービスの実行に必要な時間に基づいて、サービス要求に割り当てられた数値のことです。ロードはサービスに割り当てられるので、BEA Tuxedo システムで要求間の関係を識別できるようになります。コンフィギュレーション内の各サーバによって実行されている処理量、つまり負荷の合計をトラッキングするために、管理者はすべてのサービスとサービス要求にロード・ファクタを割り当てます。ロード・ファクタとは、あるサービスまたは要求を実行するために必要な時間を示す数値です。これらの数値に基づいて、各サーバに対して統計が生成され、各マシンの掲示板で維持されます。各掲示板では、各サーバの負荷が累積されます。そのため、すべてのサーバがビジー状態になった場合に、BEA Tuxedo システムでは最も負荷の低いサーバを選択できます。
システム全体に対して、ロード・バランシング・アルゴリズムを使用するかどうかを制御できます。たとえば、必要な場合のみ、つまり複数のキューを使用する複数のサーバによってサービスが提供される場合のみ、このアルゴリズムを使用するように設定できます。1 つのサーバだけで提供されるサービス、または複数サーバ、単一キュー (MSSQ) にある複数のサーバによって提供されるサービスは、ロード・バランシングを必要としません。これらのサービスの LDBAL パラメータは N に設定します。それ以外の場合は LDBAL に Y を設定します。
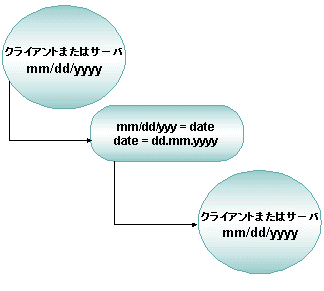
ロード・ファクタの割り当て (UBBCONFIG の SERVICES セクション) を決定する場合は、アプリケーションを長時間実行し、各サービスの実行に要する平均時間を記録します。平均値に近い時間を要するサービスには、LOAD 値に 50 (LOAD=50) を指定します。平均値より長い時間がかかるサービスには LOAD>50、短い時間のサービスには LOAD<50 を指定します。
図 2-19 ロード・バランシング
メッセージの優先順位付け
優先順位によって、サーバがキューからサービス要求を取り出す順序が決定されます。優先順位は、クライアントによって個々のサービスに割り当てられます。1 〜 100 までの値が使用され、100 が最も高い優先順位です。
すべてのサービスには、優先順位の初期値として 50 が割り当てられます。サーバの優先順位の初期値は、アプリケーションのコンフィギュレーション時に変更できます。サービスを定義した後、これらのサービスに適切な優先順位を割り当てることができます。たとえば、ビジネス上の優先順位が比較的高いサービスに優先順位 70 を設定すると、このサービスはこれよりも低い優先順位 50 のサービスよりも先にキューから取り出されます。次の例では、サーバが A (優先順位 50)、B (優先順位 50)、および C (優先順位 70) というサービスを提供しています。
図 2-20 メッセージの優先順位付け
C の優先順位が高いため、サービス C に対する要求は、常に A または B に対する要求よりも先にキューから取り出されます。A および B に対する要求は、同じ優先順位になります。この機能は、アプリケーションで要求の緊急度や重要度が異なる場合に使用すると有用です。 「枯渇防止策」は、優先順位の低いメッセージがキューでいつまでも待ち続けるのを防ぐためのメカニズムです。この方法では、優先順位に関係なく、10 個単位のメッセージの 10 番目にあるものが先入れ先出し (FIFO) の順序でキューから取り出されます。先頭から 9 番目までのメッセージは、優先順位に従って取り出されます。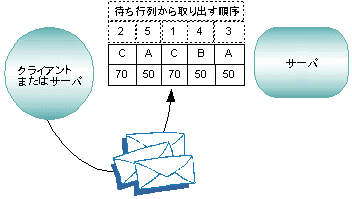
ネーミング
BEA Tuxedoシステムでは、サービス名、メッセージ・キュー名、イベント名の 3 つのネーミング・デバイスが使用されています。名前には、任意の単語または英数字の文字列を使用できます。ただし、ピリオド「.」で始まる文字列は使用できません。管理サーバでも BEA Tuxedo システムの同じインフラストラクチャが使用されるため、システム・リソースとアプリケーション・リソースは明確に区別する必要があります。
ネーミング・サービス
サービスに名前を付けると、あるアプリケーション・コンポーネントが別のコンポーネントをその名前から見つけられるようになります。名前には、単純な単語 (「deposit」など) や英数字の文字列 (「deposit2」など」) を使用できます。名前は、アプリケーションの規模、およびアプリケーション・コンポーネント間の全体的な関係のマッピイングに基づいて選択します。これらのマッピングまたはサービスは、アプリケーション・コンポーネントを記載した電話帳のページに似ています。
BEA Tuxedo システムのサーバをアクティブにすると、掲示板によってそのサービスの名前が宣言されます。サービス名はサーバの物理アドレスと対応付けられているので、要求をサーバにルーティングできます。プログラマがアプリケーションで使用する名前は、完全に位置透過的です。クライアント・プログラムがサービスを名前で要求すると、BEA Tuxedo システムは掲示板でその名前のレジストリを調べます。名前のレジストリには、文字列の名前 (TICKET など) をマシン名に変換するために必要な情報と、そのサービスを宣言しているサーバの物理アドレスが定義されています。BEA Tuxedo システムでは、これらを使用して要求を該当するサーバに送信します。
図 2-21 名前によるサービスの検索
イベントのネーミング BEA Tuxedo システムでは、パブリッシュ・アンド・サブスクライブのメカニズムが提供されています。クライアントおよびサーバは、特定のイベントが発生したときに警告 (またはメッセージ) を受信するための要求を動的に登録したり削除できます。ほかのクライアントおよびサーバは、アプリケーションで発生したユーザ定義のイベントまたはシステム・イベントをポストします。クライアントまたはサーバが特定のイベントに関する通知が必要なくなった場合、該当するサブスクリプションを取り消すことができます。 関連項目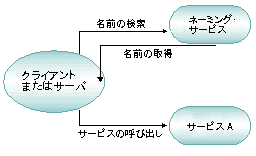
|

|

|