


|
|
キャパシティ プランニングのプロセスには、複数のアクティビティが含まれます。以下の節で、これらのアクティビティについて説明します。
| 注意 : | このガイドで説明されているテストは、制御された環境で実施されたものです。ここで示されている数値は、ユーザがそれぞれの環境でテストを実行して得られる結果と一致しない場合があります。これらの数値は、キャパシティ プランニングのプロセスについて説明するためのものです。 |
以下に、設計者および開発者が、WLI アプリケーションを設計する際に留意する必要がある、パフォーマンスに関連する設計上の問題をいくつか示します。
(サービス コントロールではなく) プロセス コントロールのみを使用して、サブプロセスを呼び出す必要があります。サービス コントロールは、別のサーバまたはクラスタの Web サービスおよび JPD を呼び出すときにのみ使用することをお勧めします。
プロセス コントロール コールバックは、JPD インスタンスに直接ルーティングされるため、メッセージ ブローカ サブスクリプションよりも高速です。フィルタが指定されたメッセージ ブローカ サブスクリプションでは、データベース アクセスにより、フィルタ値がプロセス インスタンスにマップされます。
| 注意 : | 動的なサブスクリプションは、疎結合を提供します。そのため、疎結合が必要な設計シナリオでは、プロセス コントロール コールバックの代わりに、動的なサブスクリプションを使用できます。 |
プロセスがステートフルになり、操作で、データベースに状態を永続させる必要がない場合は、意図的に、永続性フラグを Never または Overflow に変更することを検討してください。
| 注意 : | Never または Overflow に設定された永続性フラグは、クラスタで適切に動作しない可能性があります。 |
ワークリスト API を使用したワークリストへのアクセスは、WLI JPD コントロールを使用した場合よりも高速です。ただし、コントロールの方が、使いやすく、プログラミングが容易です。
ステートレス JPD は、メモリで実行され、状態が永続化されないため、パフォーマンスでは、ステートフル JPD よりも優れています。プロセスの以前の状態に関する情報が必要ないシナリオでは、ステートレス JPD を使用してください。
非同期プロセスでは、コールバックの場所が WLS JMS キューであり、プロセスのすべてのインスタンスで同一である場合、高負荷条件で WLI のパフォーマンスが影響を受けます。
| 注意 : | パフォーマンスに影響する可能性がある、設計上の考慮事項の詳細については、WebLogic Integration のベスト プラクティスおよび「WLI のチューニング」を参照してください。 |
WLI アプリケーションのパフォーマンスは、アプリケーションの設計だけでなく、アプリケーションが動作する環境によっても異なります。
環境には、WLI サーバ、データベース、オペレーティング システムとネットワーク、および JVM があります。システムから十分なパフォーマンスを引き出すには、これらすべてのコンポーネントが適切にチューニングされている必要があります。
JDBC データ ソース、weblogic.wli.DocumentMaxInlinSize、プロセス トラッキング レベル、B2B メッセージ トラッキング レベル、および Log4j などのパラメータを適切に設定する必要があります。詳細については、「WLI のチューニング」を参照してください。
これには、初期化パラメータ、統計の生成、ディスク I/O、インデックス作成などの設定の定義が含まれます。データベースのチューニングの詳細については、データベース チューニング ガイドを参照してください。
OS とネットワークを適切にチューニングすると、エラー状態の発生が回避され、システム パフォーマンスが向上します。詳細については、『WebLogic Server パフォーマンス チューニング ガイド』の「オペレーティング システムのチューニング」を参照してください。
JVM ヒープ サイズをチューニングして、JVM によるガベージ コレクションの実行時間を最小限に抑え、サーバで所定の時間に処理できるクライアントの数を最大限に増やす必要があります。詳細については、『WebLogic Server パフォーマンス チューニング ガイド』の「Java 仮想マシン (JVM) のチューニング」を参照してください。
| 注意 : | スケーラビリティ テストおよびベンチマーク テストを実行する際に、ヒープ サイズに大きな値を設定して、ガベージ コレクションの頻繁な発生を回避することができます。ただし、これによりパフォーマンスが影響を受ける場合があります。 |
ロード ジェネレータ スクリプトを使用して、パフォーマンス テストの実行、およびアプリケーションの起動を行うためには、アプリケーションにいくつかの細かい変更を加える必要がある場合があります。
変更の程度は、アプリケーションの特性、ロード ジェネレータの能力、およびキャパシティ プランニング プロセスから予期される結果によって異なります。
パフォーマンス テストの結果の質は、使用される作業負荷に依存します。
作業負荷は、システムが実行すると考えられる処理の量です。これは、システムに接続している、およびシステムと対話している一定数のユーザを持つシステムで実行されている特定のアプリケーションで構成されます。
作業負荷は、可能な限りプロダクション環境に近くなるように設計する必要があります。
さらに、ユーザが、思考時間を必要とする場合があります。思考時間は、ユーザが、システムでアクションをトリガする前に、可能性のある代替案について考え、決定するために必要な時間です。
たとえば、Web サービス、JMS、およびファイルの 3 種類のクライアントを持つ WLI アプリケーションには、次の図に示すようなユーザ プロファイルがある可能性があります。
作業負荷を設計する際は、以下のパラメータを考慮する必要があります。
サービス レベル アグリーメント (SLA) は、サービスの提供者とサービスの消費者との間の契約であり、サービスの許容 (および非許容) レベルを定義します。一般的に、SLA は、応答時間またはスループット (1 秒あたりのトランザクション数) で定義されます。
キャパシティ プランニングを行うためには、作業の単位 (つまり、各トランザクションに含まれる一連のアクティビティ) を定義してから、それを使用して SLA を定義することが重要です。
次の図に示されている、注文アプリケーションについて検討します。

各ノードは JPD です。注文を処理するには、これらすべての JPD が必要です。このシナリオでは、作業の単位 (トランザクション) を、次のいずれかとして定義できます。
各 JPD ではなく、ビジネス オペレーションのフロー全体を作業の単位と見なすことをお勧めします。
負荷生成スクリプトは、テストの実行時に、サーバで意図した作業負荷を発生させるために必要です。
| 注意 : | テストの実行の詳細については、「ベンチマーク テストの実行」および「スケーラビリティ テストの実行」を参照してください。 |
負荷生成スクリプトを作成する際は、以下の点に留意する必要があります。
要求を送信する速度が制御されていない場合、フローの均衡が維持される比率を超えてもなおシステムに要求が到着し続け、キューのオーバーフローなどの問題が発生する可能性があります。
以下の図は、前の要求がサーバによって処理された場合にのみ、単一のユーザが次の要求を送信する様子を表しています。

この手法により、同時ユーザの数を増やすことで、システムに悪影響を与えずに、システムの到着率 (負荷) を上げることができるため、システムのキャパシティを正確に測定することができます。
以下の図は、単一のユーザが、サーバによる前の要求の処理が完了するのを待たずに新しい要求を送信する様子を表しています。

このやり方は、キューのオーバーフローなどの問題の原因となり、キャパシティの誤認を招く可能性があります。
この節の説明に従ってテスト環境をコンフィグレーションし、テストの結果を、信頼性の高い、外的要因に影響されないものにする必要があります。
ベンチマーク テストは、システムのボトルネックの特定およびシステムの適切なチューニングに役立ちます。
テストでは、スループットがそれ以上増加しなくなるまで、システムへの負荷を徐々に増加させます。
| 注意 : | ベンチマーク テストの目的上、テストにおける負荷は、システム リソースを要求する、WLI アプリケーションの任意の側面 (同時ユーザの数、ドキュメント サイズなど) となります。 |
| 注意 : | システムが適切なウォームアップ時間を取れるように、負荷は徐々に増加させていく必要があります。 |
| 注意 : | ベンチマーク テストは、単一の WLI マシンを使用して、思考時間なしで実行します。 |
スループットの増加が停止した場合、以下のいずれかが発生した可能性があります。
以下の図は、Mercury LoadRunner の負荷の増加スケジュールを表しています。最初の 10 分間は、10 の同時ユーザによるウォームアップ テストのための時間です。その後、15 分ごとに 10 のユーザを追加する割合で、負荷を増加させます。

ユーザのエミュレートおよびメトリクスの記録には、Mercury LoadRunner および Grinder などのツールを使用します。
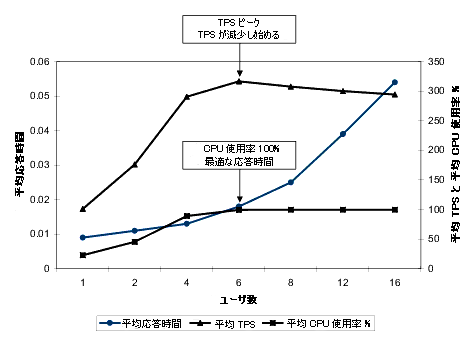
ユーザの追加に従い、平均 TPS が増加しています。ハードウェア リソースのいずれか (この場合は CPU) の使用率が 100% に達した時点で、平均 TPS がピークに達しています。この時点での応答時間が、最適な結果です。システムにユーザをさらに追加すると、TPS が減少し始めます。
この結果のパターンは、システムでリソースが最大限に使用されていることを示しています。
キャパシティ プランニング プロセスの次のアクティビティは、ベンチマーク テストの結果の検証です。
テスト結果を分析する前に、リトルの法則を使用してそれらを検証し、テストのセットアップでのボトルネックを特定する必要があります。テスト結果は、リトルの法則を適用した場合に得られる結果から大きく外れるものであってはなりません。
マルチユーザ システムの応答時間の式は、リトルの法則を使用して証明することができます。応答時間が r の任意のシステムに接続している、平均思考時間が z である n 人のユーザについて検討します。各ユーザは、思考と応答の待機を繰り返すため、メタシステム (ユーザとコンピュータ システムで構成される) でのジョブの合計数は n に固定されます。
n は平均負荷、z + r は平均応答時間、および x はスループットです。
結果を解釈する際は、システムの定常値のみを考慮するように注意してください。負荷を増加および減少させるための時間をパフォーマンス メトリクスに含めないでください。
スループットが飽和状態に達したときに、リソース (CPU、メモリ、ハード ディスク、またはネットワーク) の使用率がピークに達していなければなりません。リソースのいずれも使用率がピークに達していない場合は、システムにボトルネックがないかどうか分析し、適切にチューニングします。
スループットが飽和状態に達した時点で、リソースのボトルネックが存在していない場合は、ボトルネックがアプリケーションおよびシステム パラメータに存在している可能性があります。これらのボトルネックは、以下のいずれかが原因となっている可能性があります。
オペレーティング システムおよびネットワークのパラメータが適切にチューニングされていることを確認します。詳細については、『WebLogic Server パフォーマンス チューニング ガイド』を参照してください。
増加した負荷を、パフォーマンスを低下させることなく処理できる場合、そのアプリケーションはスケーラブルであると見なすことができます。増加した負荷を処理するために、ハードウェア リソースを追加する必要がある場合があります。
アプリケーションは、マシンを追加することで水平に拡張できます。また、同じマシンにリソース (CPU など) を追加することで垂直に拡張することもできます。
以下の表では、水平拡張と垂直拡張の相対的な利点を比較しています。
アプリケーションを拡張する必要がある場合、要件に応じて、水平拡張、垂直拡張、またはこれらの組み合わせを選択できます。
以下の図は、単一のクラスタ化されていない 4 CPU マシン (垂直拡張) と、2 台のクラスタ化された 2 CPU マシン (水平拡張) で実行されている WLI の比較を示しています。

水平拡張シナリオ (2 台の 2 CPU マシン) のパフォーマンスは、垂直拡張シナリオ (単一の 4 CPU マシン) のパフォーマンスよりもわずかに低くなっています。これは、水平拡張シナリオでは、追加の負荷分散およびクラスタリングのオーバーヘッドが発生するためです。
スケーラビリティ テストにより、システムに (水平または垂直に) リソースを追加した場合に、アプリケーションがどのように拡張されるかが分かります。この情報は、任意のシナリオに必要な追加のハードウェア リソースを見積る場合に役立ちます。
スケーラビリティ テストでは、SLA が達成されるか、またはターゲット リソースの使用率が上限に達するかの、いずれか早い方が発生するまで、負荷を徐々に増加させます。
| 注意 : | 対照的に、ベンチマーク テストでは、スループットの増加が停止するまで、負荷を増加させます。 |
スケーラビリティ テストを実行するためには、可能な限り厳密にプロダクション シナリオをエミュレートするように、作業負荷を設計する必要があります。ユーザによる対話が不要な場合、およびプロセスの呼び出しをプログラムによって行う場合は、ベンチマーク テストの手法と同様に、思考時間をゼロとする手法を使用することをお勧めします。
SLA が達成される前に、ターゲット リソースの使用率レベルが上限に達した場合は、システムにリソースを追加する必要があります。追加されるリソース (垂直拡張) またはマシン (水平拡張) の数は、1、2、4、8... といった順序である必要があります。
| 注意 : | キャパシティを見積るための方程式を導き出すには、少なくとも 3 つのデータ点を使用する必要があります。 |
ベンチマーク テストの実行時に記録したすべてのデータを、スケーラビリティ テストの実行時に捕捉する必要があります。詳細については、「ベンチマーク テストの実行」を参照してください。
| 注意 : | リソースの使用率が目標レベルに最も近付いた時点で記録されたデータのみを使用して、追加のリソース要件を見積る必要があります。 |
テストの実行後に、ベンチマーク テストで説明した手順に沿って結果を検証および分析し、必要に応じて、次の節の説明に従って、追加のリソース要件を見積ります。
要求される SLA が達成されない場合は、テスト結果をつなぐ曲線を描きます。曲線の方程式を導き出し、それを使用して、必要な追加のハードウェア リソースを見積ります。線形回帰および曲線の当てはめどの手法を使用して、必要なリソースを予測できます。これらの手法は、Microsoft Excel などのスプレッドシート アプリケーションを使用して実施できます。
以下の図は、水平スケーラビリティ テストの結果を示しています。

グラフは、ノード数がさまざまなクラスタにおける、70% の CPU 使用率での 1 秒あたりの平均トランザクション数 (TPS) を示しています。
このスケーラビリティ テストの結果の場合、線型方程式が最も当てはまります。最良適合曲線では、R2 は、値 1 に近付きます。
方程式は、y = 12.636x + 4.065 です。y は平均 TPS であり、x はノード数です。
| 注意 : | 水平または垂直にリソースを追加することで TPS を高めることができますが、目的が特定の応答時間を達成することである場合、この方法は役に立たない場合があります。このような場合は、より高速な CPU の使用を検討します。 |
スケーラビリティ テストの結果、および要求される結果を達成するために必要なチューニングを踏まえて、アプリケーションをコンフィグレーションし、プロダクション環境にデプロイする必要があります。
| 注意 : | プロダクション環境用に購入を決定したリソースが、スケーラビリティ テストで使用したものと同じ種類またはモデルでない場合は、以下の式を使用して、リソース要件を見積ることができます。 |
| 注意 : | E x T1 / T2 |
| 注意 : | E = スケーラビリティ テストによって得た見積り |
| 注意 : | T1 = テストが実行されたマシンの SPECint レート |
| 注意 : | T2 = 購入するマシンの SPECint レート |
| 注意 : | この式は、拡張が CPU の数に基づいている場合にのみ適用できます。 |
| 注意 : | SPECint レートの詳細については、http://www.spec.org を参照してください。 |


|
