Importazione dei dati del profilo
Importante: questo argomento è valido per gli utenti della versione più recente di Connect. Se il proprio account ancora utilizza Connect versione classica, scaricare la Guida per l'utente di Connect versione classica.
Ulteriori informazioni sono disponibili in questo video
È possibile utilizzare Connect per importare i dati in un elenco di profili o in una tabella di estensioni del profilo (PET) in Oracle Responsys.
Dopo l'esecuzione di un job di importazione, il file di caricamento viene archiviato sul server. Se il job viene eseguito correttamente, il file di caricamento viene eliminato. Se il job non viene eseguito correttamente, il file di caricamento viene eliminato solo nelle seguenti circostanze:
- Il file è vuoto
- Il file contiene errori di dati, ad esempio un formato dati non valido
- Il file di caricamento e il file dei conteggi contengono una diversa quantità di record.
Nota: con Connect è possibile importare i dati sia in un elenco profili che nelle relative tabelle estensioni profilo. In Connect versione classica erano supportati solo i dati dell'elenco.
Per creare un job di importazione di dati profilo:
- Fare clic su
 Dati nella bara di navigazione laterale e selezionare Connetti.
Dati nella bara di navigazione laterale e selezionare Connetti. - Fare clic su Crea job nella pagina Gestisci Connect.
- Selezionare Importa i dati del profilo nell'elenco a discesa e fornire il nome e la descrizione del job di importazione.
I nomi job non possono superare i 100 caratteri e possono includere solo i caratteri seguenti: A-Z a-z 0-9 spazio ! - = @ _ [ ] { }
- Fare clic su Fine.
Viene visualizzata la procedura guidata Connect. È possibile completare i passi in qualsiasi ordine nonché salvare le modifiche e continuare in un secondo momento.
- Completare i passi riportati di seguito.
- Dopo aver configurato tutti i passi, fare clic su Salva. Per salvare e attivare il job, fare clic su Attiva.
Importante: prima di poter salvare o attivare il job, è necessario impostare una data di scadenza oppure impostare il job in modo che non scada mai. Per impostare una data di scadenza, fare clic su Modifica
 accanto a Scadenza. Quando il job scade, viene eliminato e non può essere recuperato. Ulteriori informazioni sulla gestione della data di scadenza.
accanto a Scadenza. Quando il job scade, viene eliminato e non può essere recuperato. Ulteriori informazioni sulla gestione della data di scadenza.
Al termine della procedura:
- Dopo aver salvato il job, è possibile utilizzare la pagina Gestisci Connect per gestirlo. Ulteriori informazioni sulla gestione dei job.
- È possibile che Connect restituisca errori quando si salva il job. Fare clic su Mostra errori per esaminare gli errori e passare rapidamente alla pagina da correggere. È necessario correggere tutti gli errori per poter attivare il job.
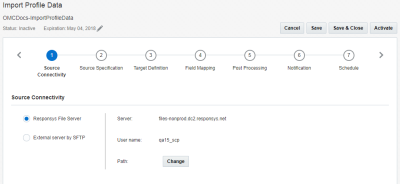
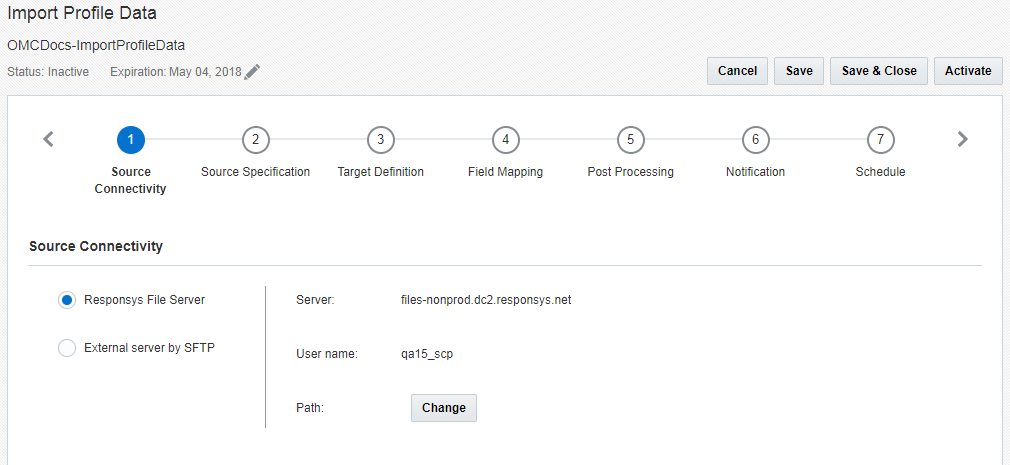
Passo 1: connettività di origine
In questo passo l'utente fornisce le specifiche del file server per il recupero del file di origine.
Selezionare una delle seguenti opzioni:
- File server Responsys: i job di Connect possono importare i dati tramite il file server dell'account Responsys SCP (Secure Copy Protocol). Questo account include tre directory, ovvero upload, download e archive.
Importante: se non è già stato stabilito in precedenza, il personale del Supporto Oracle Responsys deve collaborare con il team IT per generare una coppia di chiavi pubblica-privata SSH-2. In questo modo viene garantito l'accesso sicuro all'account SCP mediante un client SSH/SCP. È inoltre possibile creare directory personalizzate utilizzando un client SSH (Secure Shell).
- Se si seleziona questa opzione, fare clic su Modifica per specificare la directory in cui si trovano i file.
- Server esterno per SFTP: quando si seleziona questa opzione, è necessario fornire le informazioni riportate di seguito.
- Nome host: selezionare il nome host dall'elenco a discesa.
- Percorso directory: immettere il percorso della directory associata.
- Nome utente: immettere il nome utente per l'accesso alla connessione SFTP.
- Autenticazione: a seconda delle modalità di impostazione del server, selezionare Password o Chiave.
Se si tratta del primo job che utilizza l'autenticazione tramite chiave, fare clic su Accedi o genera informazioni chiave e immettere l'indirizzo e-mail per ricevere le chiave pubblica e le istruzioni per l'aggiunta della chiave all'account SFTP. Dopo aver installato la chiave pubblica, fare clic su Test connessione per confermare la validità della configurazione della connessione SFTP.
Suggerimento: per informazioni sull'autenticazione con chiave, vedere Selezione, importazione o generazione di chiavi pubbliche.
Passo 2: specifica dell'origine
In questo passo l'utente fornisce le informazioni sul file da importare.
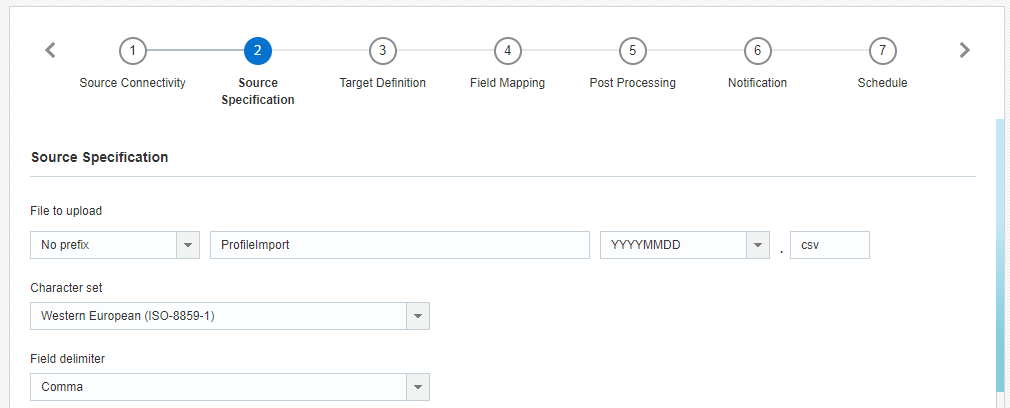
- File da caricare: il nome completo e l'estensione del file da importare. È possibile aggiungere la data di creazione del file come prefisso o suffisso.
- Set di caratteri: il set di caratteri del file. Se il file contiene emoji, sarà necessario selezionare Unicode (UTF-8) come set di caratteri.
- Delimitatore campo: il delimitatore che divide i campi (le colonne) del file.
- Delimitatore di inclusione campo: specificare se le colonne di testo e i valori sono racchiusi tra apici o virgolette.
- Formato data: selezionare il formato della data del file di importazione. Per informazioni sui formati data supportati, vedere Formati data supportati in Connect.
- La prima riga contiene nomi di colonna: selezionare questa casella di controllo se la prima riga del file contiene nomi di campo.
- Il file è cifrato con la chiave PGP/GPG: selezionare questa casella di controllo se il file è stato cifrato con una chiave e deve essere decifrato prima del caricamento.
- Il file è firmato con la chiave PGP/GPG: selezionare questa casella di controllo se il file è stato firmato con una chiave.
- File per confermare conteggio record previsto: selezionare facoltativamente questa casella di controllo e specificare il file da utilizzare per confrontare il conteggio dei record con il numero dei record importati. Ad esempio, se il conteggio record previsto nel file è 300, ma il file importato contiene solo 100 record, viene trascritto un errore di trasferimento e il processo di caricamento viene interrotto.
Passo 3: definizione della destinazione
In questo passo l'utente seleziona l'elenco profili e la tabella PET in cui importare i dati.
Nota: sarà inoltre necessario selezionare le tabelle di destinazione durante la mappatura dei campi nel Passaggio 4.
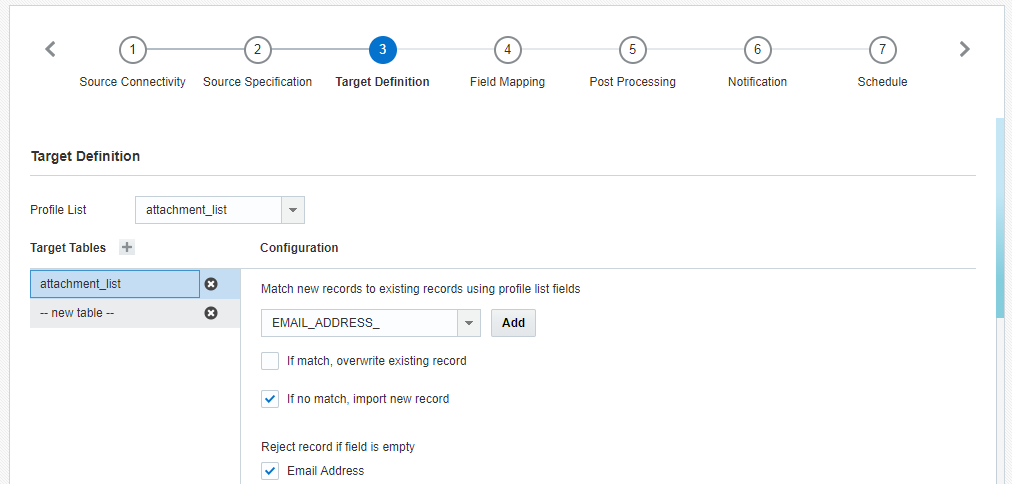
Per aggiungere una definizione destinazione:
- In Definizione target selezionare l'elenco profili o la tabella PET da Elenco profili, se richiesto o se si desidera utilizzare un elenco diverso da quello visualizzato. Questo è l'elenco in cui si esegue l'importazione.
- Se all'elenco di destinazione è associato un elenco di canali applicazioni con una tabella PET, è possibile importare i dati nella tabella PET dell'elenco di canali applicazioni. A tale scopo selezionare la casella di controllo Usa elenco canali applicazioni.
- Specificare la tabella di destinazione per i dati di importazione.
- Fare clic sul segno + e selezionare la tabella in cui importare i dati. Se l'importazione viene eseguita in una tabella PET, è possibile selezionare una sola tabella. Se l'importazione viene eseguita in un elenco, è possibile selezionare un elenco e una tabella PET.
Se si usa l'elenco di canali applicazioni, l'elenco Tabelle di destinazione mostra solo le tabelle PET di tale elenco. Negli altri casi l'elenco Tabelle di destinazione include l'elenco profili e tutte le tabelle PET associate.
Suggerimento: è possibile creare una nuova tabella PET utilizzando una tabella esistente come modello. Vedere .
Specificare le opzioni per la tabella di destinazione.
 Per gli elenchi
Per gli elenchiAbbina i nuovi record ai record esistenti mediante campi elenco profili: selezionare il campo elenco per l'abbinamento dei nuovi record ai record esistenti, ad esempio RIID_.
In caso di corrispondenza, sovrascrivi record esistente: selezionare questa casella di controllo per sostituire i record esistenti con i nuovi dati quando un record corrisponde. Se non si seleziona la casella di controllo, il record in entrata verrà ignorato.
In mancanza di corrispondenza, importa il nuovo record: selezionare questa casella di controllo per importare i record se non esistono corrispondenze. Se non si seleziona la casella di controllo, il record in entrata verrà ignorato.
Rifiuta record se il campo è vuoto: specificare se si desidera rifiutare i record con indirizzi e-mail o valori numerici mobile vuoti.
Stato autorizzazione predefinito per il nuovo canale aggiunto: selezionare lo stato di autorizzazione predefinito per il nuovo canale aggiunto per l'inclusione o l'esclusione.
Valori stato inclusione/esclusione nel file di origine: specificare il valore utilizzato nel file di origine per lo stato di inclusione e di esclusione.
Valori formato e-mail nel file in entrata: selezionare i valori di formato e-mail nel file di origine, ovvero H per HTML e T per Testo. Formato di caricamento numero cellulare: selezionare il formato del numero mobile nel file di origine. Connect convalida il formato dei numeri mobile in entrata in base al formato selezionato per l'account. Il formato selezionato qui va a sostituire l'impostazione dell'account per questo job.
Abilita applicazione filtro su ultimo caricamento di questo nome: selezionare questa casella di controllo per abilitare l'applicazione del filtro sull'ultimo caricamento con lo stesso nome. NOTA: se l'opzione è selezionata, è possibile specificare i criteri (mediante la finestra Progettazione filtro) per la selezione dei clienti all'interno del caricamento corrente per la ricezione di una campagna o l'esportazione in un file .CSV.
Per le tabelle PETRimuovi tutti i record prima di inserirne di nuovi: selezionare questa casella di controllo per sostituire i record esistenti della tabella con i nuovi record caricati.
Abbina i nuovi record ai record esistenti mediante campi elenco profili: selezionare il campo elenco per l'abbinamento dei nuovi record ai record esistenti, ad esempio RIID_.
In caso di corrispondenza, sovrascrivi record esistente: selezionare questa casella di controllo per sostituire i record esistenti con i nuovi dati quando un record corrisponde. Se non si seleziona la casella di controllo, il record in entrata verrà ignorato.
In mancanza di corrispondenza, importa il nuovo record: selezionare questa casella di controllo per importare i record se non esistono corrispondenze. Se non si seleziona la casella di controllo, il record in entrata verrà ignorato.
Il file di origine include dati finali di definizione target e personalizzazione: selezionare questa casella di controllo per utilizzare i dati delle campagne esterne senza eseguire il join con i record esistenti.
Includi record con esclusione: per le campagne esterne, selezionare questa casella di controllo per inviare la comunicazione agli utenti con esclusione solo per i messaggi transazionali.
- Fare clic sul segno + e selezionare la tabella in cui importare i dati. Se l'importazione viene eseguita in una tabella PET, è possibile selezionare una sola tabella. Se l'importazione viene eseguita in un elenco, è possibile selezionare un elenco e una tabella PET.
Creazione di una tabella PET
Creare una nuova tabella PET in cui importare i dati. La nuova tabella creata avrà lo stesso layout a colonne della tabella utilizzata come modello. Sarà tuttavia possibile specificare altre opzioni per il nuovo file.
Per creare la nuova tabella PET in cui importare i dati:
- In Definizione target selezionare l'elenco profili o la tabella PET da Elenco profili, se richiesto o se si desidera utilizzare un elenco diverso da quello visualizzato. Questo è l'elenco in cui si esegue l'importazione.
- Fare clic sul segno +. Nella finestra di dialogo Seleziona tabelle di destinazione fare clic su Crea nuova tabella.
La nuova tabella viene aggiunta all'elenco Tabelle target.
- Fare clic sulla nuova tabella nell'elenco Tabelle di destinazione.
- Nella sezione Configurazione fare clic su Seleziona e selezionare la tabella da utilizzare come modello.
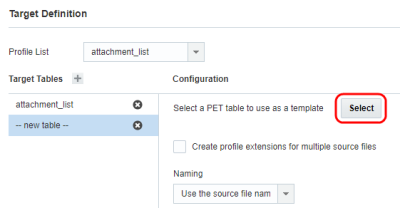
-
Specificare le opzioni indicate di seguito nella sezione Configurazione.
- Creare le estensioni profilo per più file di origine: selezionare questa casella di controllo per creare una tabella PET per ogni file di origine.
- Denominazione: specificare se utilizzare il nome della tabella di origine oppure specificare un nome diverso per la nuova tabella.
- Cartella: selezionare la cartella per la nuova tabella, se richiesto o se si desidera utilizzare una cartella diversa da quella visualizzata.
- Imposta scadenza: specificare il numero di giorni trascorsi i quali la tabella scadrà. Connect eliminerà automaticamente la tabella scaduta.
- Abbina i nuovi record ai record esistenti mediante campi elenco profili: selezionare i campi da utilizzare per l'abbinamento dei nuovi record ai record esistenti. Per definire l'abbinamento di due campi, fare clic su Aggiungi per aggiungere un secondo campo.
- In caso di corrispondenza, sovrascrivi record esistente: selezionare questa casella di controllo per sostituire i record esistenti con i nuovi dati quando un record corrisponde. Se non si seleziona la casella di controllo, il record in entrata verrà ignorato.
- In mancanza di corrispondenza, importa il nuovo record: selezionare questa casella di controllo per importare i record se non esistono corrispondenze. Se non si seleziona la casella di controllo, il record in entrata verrà ignorato.
- Il file di origine include dati finali di definizione target e personalizzazione: selezionare questa casella di controllo per utilizzare i dati delle campagne esterne senza eseguire il join con i record esistenti.
- Includi record con esclusione: per le campagne esterne, selezionare questa casella di controllo per inviare la comunicazione agli utenti con esclusione solo per i messaggi transazionali.
Passo 4: mapping dei campi
In questo passo l'utente esegue il mapping delle colonne dal file di origine ai campi dell'elenco profili o della tabella PET target. Il mapping specifica la colonna che corrisponde al campo.
È possibile eseguire il mapping dei campi manualmente oppure utilizzando un file di caricamento.
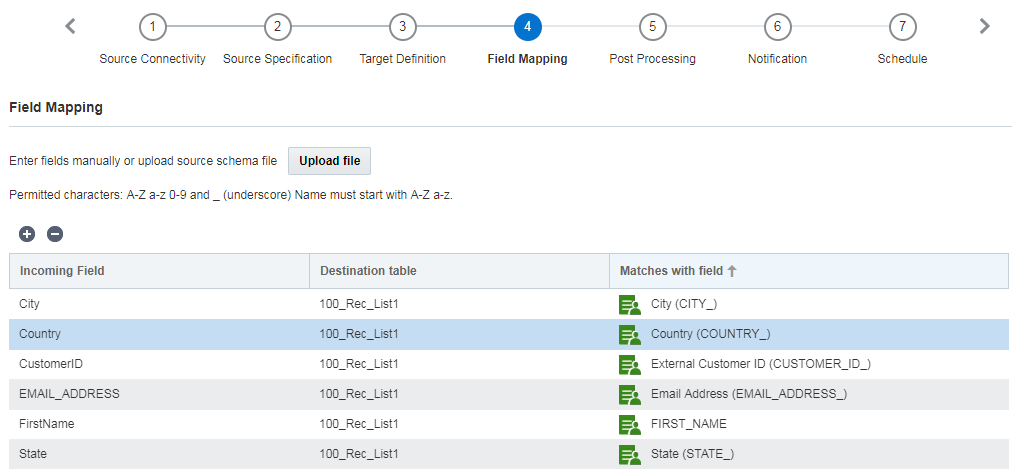
Tenere presente quanto riportato di seguito.
- I nomi di campi lunghi vengono troncati a 30 caratteri.
- I nomi dei campi devono iniziare con una lettera o un numero e possono contenere solo lettere, cifre e _ (carattere di sottolineatura).
- Una volta creati, i nomi di campo non fanno distinzione tra maiuscole e minuscole, ma in seguito vengono convertiti in formato tutto maiuscolo.
- Se le modifiche apportate generano nomi di campo duplicati, sarà necessario rinominare i nomi duplicati manualmente.
- Tutti i nomi di campo di sistema (definiti e riservati da Oracle Responsys) terminano con un carattere di sottolineatura, ad esempio EMAIL_ADDRESS_. Come procedura consigliata, i nomi di campo caricati non devono terminare con un carattere di sottolineatura. Questo carattere è riservato ai campi di sistema.
- Quando possibile, abbinare campi in entrata con nome simile a campi elenco esistenti, ad esempio abbinare CUST_ID a CUSTOMER_ID_.
Per ulteriori informazioni sui requisiti relativi ai tipi di dati e ai nomi di campo, vedere Tipi di dati e nomi di campo.
Per caricare un file di mapping
- In Mapping campi fare clic su Carica file.
- Selezionare il file di mapping e completare i dettagli.
- I campi sono delimitati da: selezionare il delimitatore, in genere una tabulazione o una virgola, utilizzato per suddividere le colonne nel file.
- I campi sono racchiusi tra: specificare se le colonne di testo e i valori sono racchiusi tra apici o virgolette.
- La prima riga contiene nomi di colonna: selezionare la casella di controllo se la prima riga contiene nomi di colonna.
Per eseguire il mapping dei campi:
- In Mapping campi fare clic su Aggiungi (+).
- Accertarsi di selezionare anche la tabella di destinazione del campo.
- Specificare il campo in entrata e il campo a cui corrisponde. Se non si desidera definire la corrispondenza per un campo, selezionare ignora questo campo.
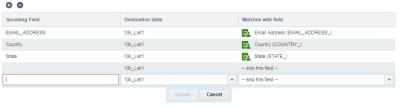
- Fare clic su Aggiorna.
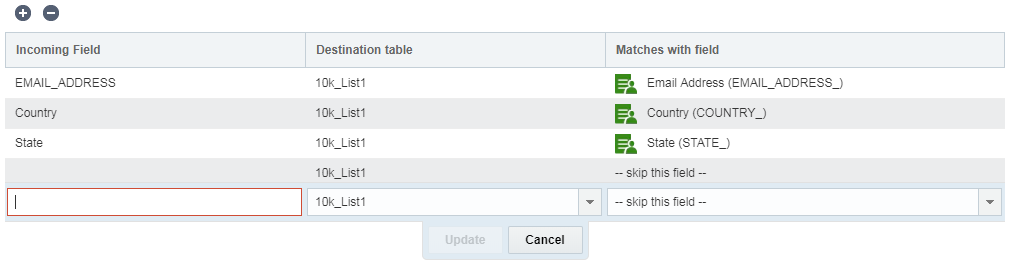
Nota: per aggiornare l'elenco profili, selezionare il campo corrispondente nella sezione Elenco profili. Per aggiornare la tabella PET, selezionare il campo corrispondenza nella sezione Estensione profilo. Ad esempio, per definire la corrispondenza su CUSTOMER_ID_ sia nell'elenco profili che nella tabella PET, selezionare 1, quindi 2.
Passo 5: post-elaborazione
In questo passo l'utente seleziona le azioni da eseguire dopo l'esecuzione riuscita del job.
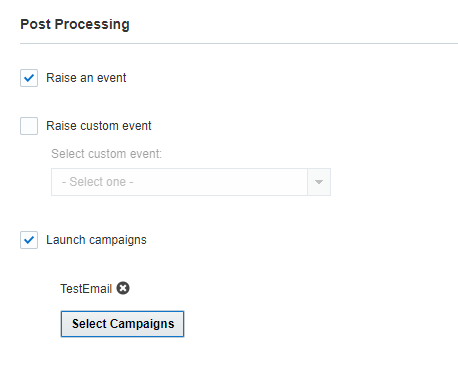
- Genera evento: selezionare questa casella di controllo per rendere disponibile il job completato per Program. Se questa opzione è selezionata, il job diventerà disponibile come evento Connect in Program.
- Genera evento personalizzato: selezionare questa casella di controllo per generare l'evento personalizzato specificato quando l'esecuzione del job riesce. Selezionare l'evento da generare nell'elenco a discesa Seleziona evento personalizzato.
- Lancia campagne: selezionare questa casella di controllo per lanciare le campagne selezionate quando l'esecuzione del job riesce. È possibile selezionare fino a 40 campagne. Per ricevere le notifiche relative all'avanzamento dei lanci delle campagne, assicurarsi che le impostazioni di ogni campagna specifichino uno o più indirizzi e-mail per la ricezione di tali notifiche.
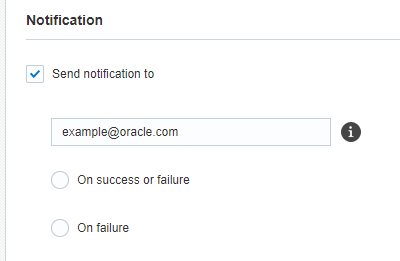
Passo 6: notifica
In questo passo l'utente imposta le notifiche e-mail per il job. È possibile scegliere di inviare le notifiche dopo un'esecuzione con esito positivo o negativo di un job.
Passo 7: schedulazione
In questo passo l'utente schedula il job. Il job può essere eseguito in una data e ora specifiche oppure in base a una schedulazione ricorrente. Per eseguire il job su richiesta, utilizzare l'opzione Non schedulare.
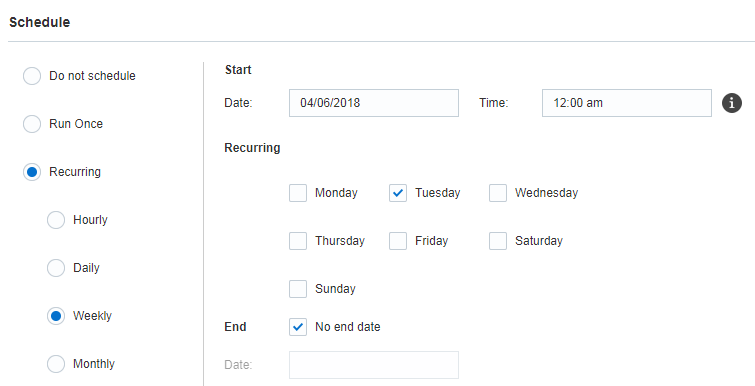
Importante: per evitare che gli anni bisestili e i mesi con 31 giorni generino problemi, non è possibile schedulare un'esecuzione mensile periodica nei giorni 29, 30 o 31 di un mese. È possibile schedulare il job in modo che venga eseguito in un giorno della settimana corrispondente all'ultimo del mese, ad esempio nell'ultimo venerdì del mese.
Durante l'impostazione dell'ora di inizio di un job, selezionare uno dei quattro intervalli di tempo disponibili all'interno dell'ora, ovvero 0-14, 15-29, 30-44, 45-59. Per ogni job schedulato, il sistema seleziona casualmente un minuto, ad esempio il minuto 12 all'interno del segmento 0-14. In questo modo le ore di inizio dei job vengono distribuite in modo uniforme.
Il job verrà avviato in orari casuali entro l'intervallo di tempo selezionato. Se si tenta di impostare un nuovo job in un intervallo che si sovrappone all'ora corrente, è possibile che venga visualizzato un messaggio di errore indicante che l'ora selezionata è passata. È pertanto consigliabile di scegliere un intervallo di tempo successivo all'intervallo corrente.