プロファイル・データのインポート
重要: このトピックは、Connectの最新バージョンのユーザーを対象としています。引き続きクラシックConnectを使用する場合は、Classic Connect User Guideをダウンロードしてください。
詳細は、ビデオを参照してください。
Connectを使用して、データをOracle Responsysのプロファイル・リストまたはプロファイル拡張表(PET)にインポートできます。
インポート・ジョブを実行した後、アップロード・ファイルはサーバーにアーカイブされます。ジョブが正常に終了すると、アップロード・ファイルは削除されます。ジョブが失敗すると、次の状況の場合のみアップロード・ファイルが削除されます。
- ファイルが空の場合
- 無効なデータ書式などのデータの問題がファイルにある場合
- アップロード・ファイルとカウント・ファイルのレコード数が異なる場合
注意: Connectでは、プロファイル・リストとそのプロファイル拡張表の両方にデータがインポートされます。クラシックConnectでは、リスト・データのみがサポートされます。
プロファイル・データのインポート・ジョブを作成するには:
- サイド・ナビゲーション・バーの
 「データ」をクリックし、「Connect」を選択します。
「データ」をクリックし、「Connect」を選択します。 - Connectの管理ページで、「ジョブの作成」をクリックします。
- ドロップダウン・リストからプロファイル・データのインポートを選択して、インポート・ジョブの名前と摘要を指定します。
ジョブ名は100文字以下で、使用できる文字は、A-Z、a-z、0-9、空白、! - = @ _ [ ] { }のみです。
- 「完了」をクリックします。
Connectウィザードが開きます。任意の順序でステップを完了でき、変更内容を保存して後から続行できます。
- 次のステップを完了します。
- すべてのステップを構成した後、「保存」をクリックします。ジョブを保存およびアクティブ化するには、「アクティブ化」をクリックします。
重要: ジョブを保存したりアクティブにする前に、失効日を設定するか、ジョブが失効しないように設定する必要があります。「失効」の横にある「編集」
 をクリックします。ジョブが失効すると、ジョブは削除されて復元できなくなります。失効日の管理の詳細を参照してください。
をクリックします。ジョブが失効すると、ジョブは削除されて復元できなくなります。失効日の管理の詳細を参照してください。
終了後は、次のようになります。
- ジョブを保存した後、Connectの管理ページを使用してジョブを管理できます。ジョブの管理の詳細を参照してください。
- ジョブを保存すると、Connectによりエラーが返される場合があります。「エラーの表示」をクリックしてエラーを確認し、修正が必要なページに素早くジャンプします。ジョブをアクティブ化する前に、すべてのエラーを解決する必要があります。
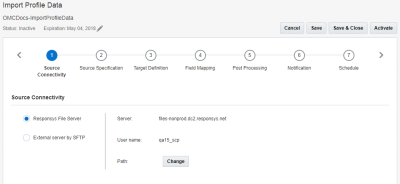
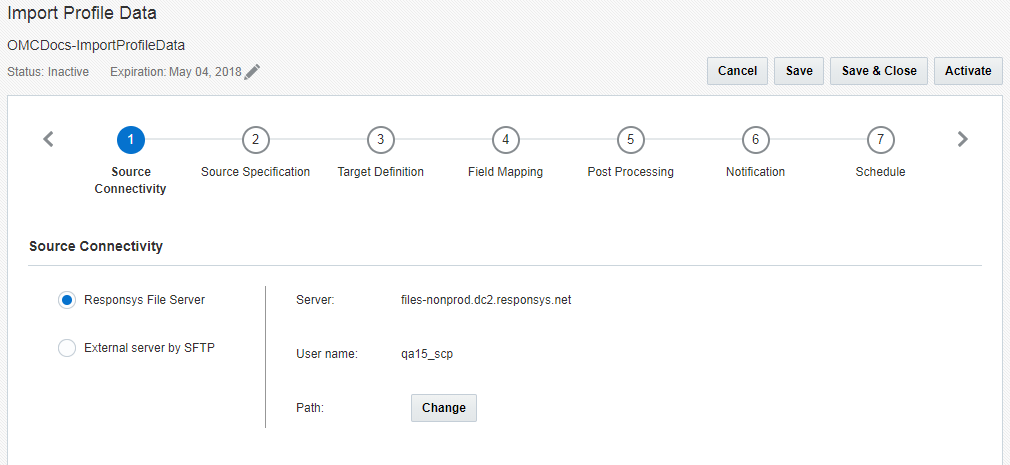
ステップ1: ソース接続
このステップでは、ソース・ファイルを取得するためのファイル・サーバーの仕様を指定します。
次のオプションから1つ選択してください。
- Responsysファイル・サーバー: コネクト・ジョブにより、Responsys SCP (Secure Copy Protocol)アカウント・ファイル・サーバーを介してデータをインポートできます。このアカウントには、アップロード、ダウンロード、アーカイブの3つのディレクトリが含まれています。
重要: まだ確立されていない場合は、Oracle Responsysサポートとお客様のITチームが共同でSSH-2公開キー/秘密キーのペアを生成する必要があります。そうすればSSH/SCPクライアントを経由したSCPアカウントへのアクセスの安全を確保できます。SSH (Secure Shell)クライアントを使用した独自のディレクトリを作成することもできます。
- このオプションを選択する場合は、「変更」をクリックして、ファイルを配置するディレクトリを指定します。
- SFTPによる外部サーバー: このオプションを選択する場合は、次の情報を指定します。
- ホスト名: ドロップダウン・リストからホスト名を選択します。
- ディレクトリ・パス: 関連するディレクトリのパス名を入力します。
- ユーザー名: SFTP接続にアクセスするためのユーザー名を入力します。
- 認証: サーバーの設定方法に応じて、「パスワード」または「キー」のいずれかを選択します。
これがキー承認を使用する最初のジョブである場合は、「キー情報へアクセスまたはキー情報の生成」をクリックして、公開キーと公開キーをSFTPアカウントに追加するための指示を受信するEメール・アドレスを入力します。公開キーをインストールした後、「接続のテスト」をクリックして、SFTP接続構成が有効であることを確認します。
ヒント: キー認証の詳細は、公開キーの選択、インポートまたは生成を参照してください。
ステップ2: ソース仕様
このステップでは、インポートするファイルに関する情報を指定します。
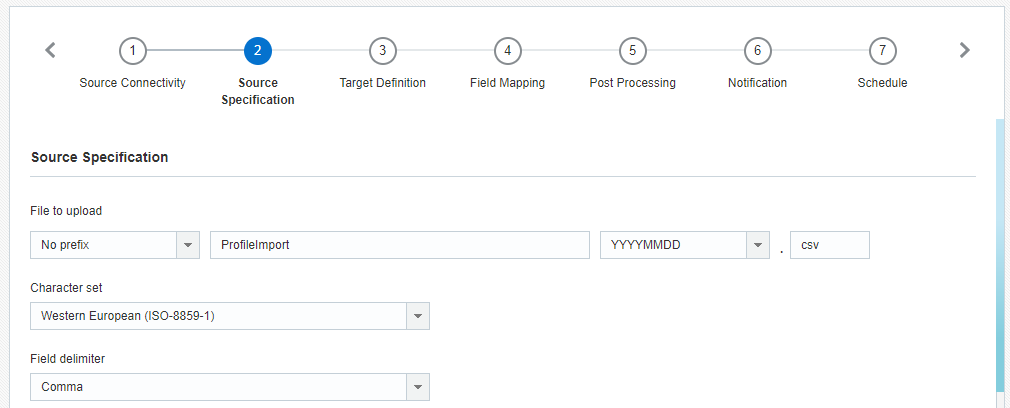
- アップロードするファイル: インポートするファイルのフル・ネームとファイル拡張子。プリフィクスまたはサフィクスとして、ファイルの作成日を追加できます。
- キャラクタ・セット: ファイルのキャラクタ・セット。ファイルに絵文字が含まれている場合は、「Unicode (UTF-8)」のキャラクタ・セットを選択する必要があります。
- フィールド区切り文字: ファイル内のフィールド(列)を区切る区切り記号。
- フィールド囲み文字: テキスト列や値を一重引用符または二重引用符で囲むかを指定します。
- 日付書式: インポート・ファイルの日付形式を選択します。サポートされている日付形式の詳細は、Connectでサポートされる日付形式を参照してください。
- 最初の行は列名を含む: ファイル内の1行目にフィールド名を含める場合は、このチェック・ボックスを選択します。
- ファイルはPGP/GPGキーで暗号化されています: ファイルがキーを使用して暗号化され、アップロードの前に復号化する必要がある場合は、このチェック・ボックスを選択します。
- ファイルはPGP/GPGキーで署名されています: ファイルがキーで署名されている場合は、このチェック・ボックスを選択します。
- 概算レコード数確認用ファイル: オプションで、このチェック・ボックスを選択し、レコード数をインポートされたレコード数と比較するために使用するファイルを指定します。たとえば、このファイル内の概算レコード数が300であり、インポートされたファイルに100個のレコードのみが含まれる場合、転送エラーが示されて、アップロード処理は中止されます
ステップ3: ターゲット定義
このステップでは、データをインポートするプロファイル・リストおよびPETを選択します。
注意: また、ステップ4でフィールドをマップする際にターゲット表を選択する必要もあります。
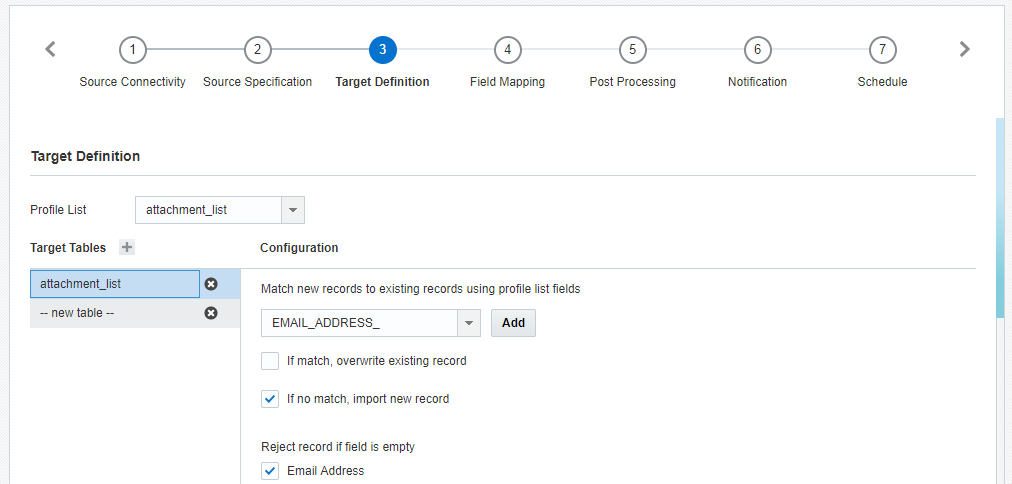
ターゲット定義を追加するには:
- 「ターゲット定義」ステップで、プロンプトされた場合や選択されているものとは別のリストを使用する場合は、「プロファイル」リストからプロファイル・リストまたはPETを選択します。これは、インポート先となるリストです。
- ターゲット・リストにPETと関連アプリ・チャネル・リストがある場合は、アプリ・チャネル・リストPETにデータをインポートできます。これを行うには、「アプリ・チャネル・リストの使用」チェック・ボックスを選択します。
- インポート・データのターゲット表を指定します。
- +をクリックして、データをインポートする表を選択します。PETにインポートする場合、選択できるPETは1つのみです。リストにインポートする場合、1つのリストと1つのPETにインポートできます。
アプリ・チャネル・リストを使用した場合、ターゲット表リストにはそのリストからのPETのみが表示されます。それ以外の場合、ターゲット表リストには、プロファイル・リストとそのリストに関連付けられるすべてのPETが含まれます。
ターゲット表のオプションを指定します。
 リストの場合
リストの場合プロファイル・リスト・フィールドを使用して新規レコードと既存レコードを照合: 新規レコードを既存レコードと照合するためのリスト・フィールド(例: RIID_)を選択します。
一致する場合は既存レコードを書き換える: レコードが一致する場合に既存レコードを新しいデータで置き換えるには、このチェック・ボックスを選択します。このチェック・ボックスを選択しない場合、受信レコードは無視されます。
一致しない場合は新しいレコードをインポート: 一致しない場合にレコードをインポートするには、このチェック・ボックスを選択します。このチェック・ボックスを選択しない場合、受信レコードは無視されます。
フィールドが空の場合はレコードを処理しない: Eメール・アドレスまたはモバイル番号の値が空のレコードを却下するかを確認します。
新しく追加されたチャネルのデフォルト権限ステータス: オプトインまたはオプトアウトに新しく追加したチャネルのデフォルトの権限ステータスを選択します。
ソース・ファイル内のオプトイン/オプトアウト・ステータス値: オプトインおよびオプトアウトのステータスにソース・ファイルで使用する値を指定します。
入力ファイルのEメール形式値: HTMLの場合にはH、テキストの場合にはTというように、ソース・ファイルでのEメール形式値を選択します。モバイル番号アップロード形式の場合には、ソース・ファイルでのモバイル番号形式を選択します。Connectにより、アカウントに対して選択した書式に従ってインバウンド・モバイル番号の書式が検証されます。ここで選択する書式によって、このジョブのアカウント設定が上書きされます。
この名前の最新ロードに対してフィルタリングを使用可能にする: 同じ名前の最新のロードに対してフィルタを使用可能にする場合は、このチェック・ボックスを選択します。注意: 選択すると、このロードからキャンペーンを受信する顧客と.CSVファイルにエクスポートする顧客を選択する基準を(フィルタ・デザイナを通じて)指定できます。
PETの場合新規の挿入前にすべてのレコードを削除: 既存の表レコードを新しくアップロードしたレコードで置き換えるには、このチェック・ボックスを選択します。
プロファイル・リスト・フィールドを使用して新規レコードと既存レコードを照合: 新規レコードを既存レコードと照合するためのリスト・フィールド(例: RIID_)を選択します。
一致する場合は既存レコードを書き換える: レコードが一致する場合に既存レコードを新しいデータで置き換えるには、このチェック・ボックスを選択します。このチェック・ボックスを選択しない場合、受信レコードは無視されます。
一致しない場合は新しいレコードをインポート: 一致しない場合にレコードをインポートするには、このチェック・ボックスを選択します。このチェック・ボックスを選択しない場合、受信レコードは無視されます。
ソース・ファイルには最終的なターゲティング・データとパーソナライズ・データがあります: 既存レコードと結合されていない外部キャンペーンからのデータを使用するには、このチェック・ボックスを選択します。
オプトアウトされたレコードを含める: 外部キャンペーンの場合、オプトアウトされたユーザーにトランザクショナル・メッセージについてのみ通信を送信するには、このチェック・ボックスを選択します。
- +をクリックして、データをインポートする表を選択します。PETにインポートする場合、選択できるPETは1つのみです。リストにインポートする場合、1つのリストと1つのPETにインポートできます。
PETの作成
データをインポートする新しいPETを作成します。新しい表を作成する場合、その列レイアウトは、テンプレートとして使用している表と同じになります。新しいファイルに他のオプションを指定できます。
データをインポートする新しいPETを作成するには:
- 「ターゲット定義」ステップで、プロンプトされた場合や選択されているものとは別のリストを使用する場合は、「プロファイル」リストからプロファイル・リストまたはPETを選択します。これは、インポート先となるリストです。
- +をクリックします。「ターゲット表の選択」ダイアログで、「新しい表の作成」をクリックします。
「ターゲット表」リストに新しい表が追加されます。
- 「ターゲット表」リストで新しい表をクリックします。
- 「構成」セクションで「選択」をクリックし、テンプレートとして使用する表を選択します。
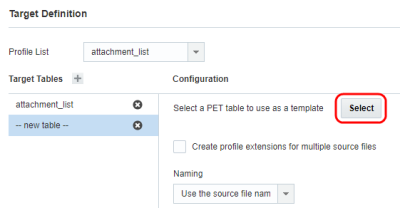
- 「構成」セクションで、次のオプションを指定します。
- 複数のソース・ファイルにプロファイル拡張を作成する: 各ソース・ファイルに1つのPETを作成するには、このチェック・ボックスを選択します。
- 命名: 新しい表にソース表名を使用するか、別の名前を指定するかを指定します。
- フォルダ: 新しい表用のフォルダを選択するように求められた場合や別のフォルダを使用する場合は、そのフォルダを選択します。
- 失効を設定: 経過後に表が失効する日数を指定します。失効後、Connectにより表は自動的に削除されます。
- プロファイル・リスト・フィールドを使用して新規レコードと既存レコードを照合: 新規レコードを既存レコードと照合するために使用するフィールドを選択します。2つのフィールドについて照合するには、「追加」をクリックして2番目のフィールドを追加します。
- 一致する場合は既存レコードを書き換える: レコードが一致する場合に既存レコードを新しいデータで置き換えるには、このチェック・ボックスを選択します。このチェック・ボックスを選択しない場合、受信レコードは無視されます。
- 一致しない場合は新しいレコードをインポート: 一致しない場合にレコードをインポートするには、このチェック・ボックスを選択します。このチェック・ボックスを選択しない場合、受信レコードは無視されます。
- ソース・ファイルには最終的なターゲティング・データとパーソナライズ・データがあります: 既存レコードと結合されていない外部キャンペーンからのデータを使用するには、このチェック・ボックスを選択します。
- オプトアウトされたレコードを含める: 外部キャンペーンの場合、オプトアウトされたユーザーにトランザクショナル・メッセージについてのみ通信を送信するには、このチェック・ボックスを選択します。
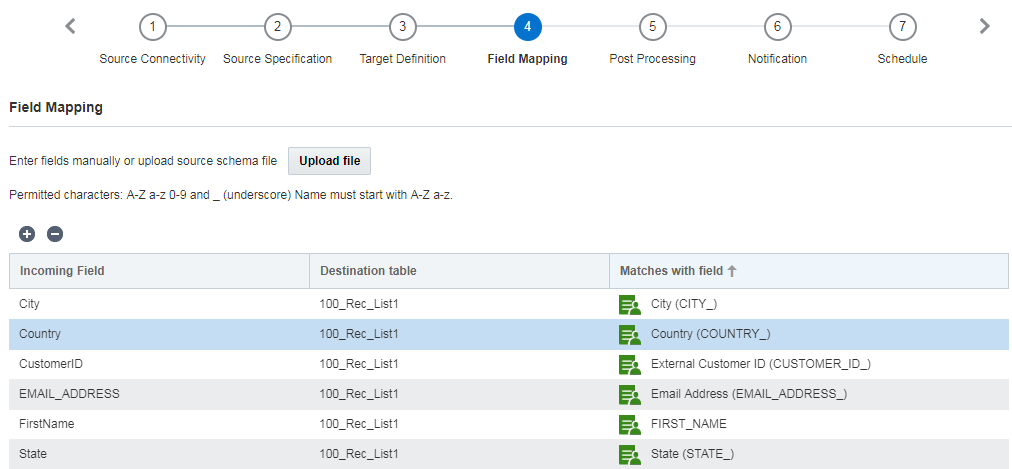
ステップ4: フィールドのマッピング
このステップでは、ソース・ファイルの列をターゲット・プロファイル・リストまたはPET内のフィールドにマッピングします。マッピング・フィールドを使用して、どの列がどのフィールドに対応するかを指定します。
フィールドを手動でマッピングすることも、マッピング用のアップロード・ファイルを使用することもできます。
次のことに注意してください。
- 長いフィールド名は30文字で切り捨てられます。
- フィールド名は、文字または数字で始める必要があり、文字、数字およびアンダースコア(_)のみを使用できます。
- 作成されたフィールド名に大文字と小文字の区別はありませんが、後にすべて大文字に変換されます。
- 変更によってフィールド名が重複した場合は、手作業で名前を変更する必要があります。
- (Oracle Responsysにより定義および予約されている)すべてのシステム・フィールド名は、EMAIL_ADDRESS_のように、末尾にアンダースコア文字が付いています。ベスト・プラクティスとして、アップロード・フィールド名の末尾をアンダースコア文字にすることは避けてください。システム・フィールド用に予約されているためです。
- 可能な場合、入力フィールド名は既存のリスト・フィールドに似た名前と一致させます。たとえば、CUST_IDをCUSTOMER_ID_に一致させます。
データ・タイプとフィールド名要件の詳細は「データ・タイプとフィールド名」をご覧ください。
マッピング・ファイルをアップロードするには:
- 「フィールドのマッピング」ステップで、「ファイルのアップロード」をクリックします。
- マッピング・ファイルを選択して、詳細を完了します。
- フィールドの区切り文字: ファイル内の列を区切る区切り記号(一般にタブやカンマ)を選択します。
- フィールドの囲み文字: テキスト列や値を一重引用符または二重引用符で囲むかを指定します。
- 最初の行は列名を含む: 1行目にフィールド名を含める場合は、このチェック・ボックスを選択します。
フィールドをマッピングするには:
- 「フィールドのマッピング」ステップで、「追加」+をクリックします。
- そのフィールドのターゲット表も必ず選択してください。
- 入力フィールドおよびそのフィールドと一致させるフィールドを指定します。フィールドを一致させない場合は、「このフィールドは取り込まない」を選択します。
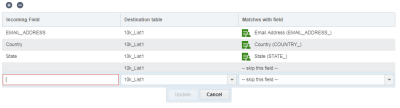
- 「更新」をクリックします。
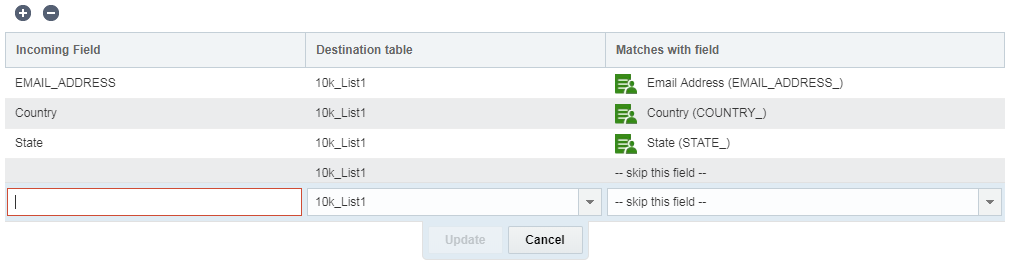
注意: プロファイル・リストを更新するには、「プロファイル・リスト」セクションから一致フィールドを選択します。PETを更新するには、「プロファイル拡張」セクションから一致フィールドを選択します。たとえば、プロファイル・リストとPETの両方のCUSTOMER_ID_について照合するには、1、2の順に選択します。
ステップ5: 後処理
このステップでは、ジョブ実行が成功した後に実行するアクションを選択します。
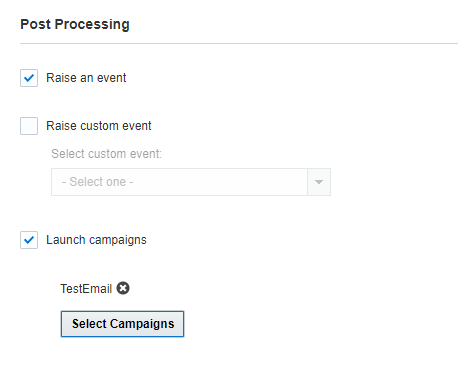
- イベントの実施: 完了したジョブをProgramで使用できるようにするには、このチェック・ボックスを選択します。選択されている場合、ジョブはProgramでConnectイベントとして使用できます。
- カスタム・イベントの実施: ジョブが正常に完了した後に指定したカスタム・イベントを実施するには、このチェック・ボックスを選択します。「カスタム・イベントの選択」ドロップダウン・リストから、実施するイベントを選択します。
- キャンペーンの開始: ジョブが正常に完了した後に選択したキャンペーンを開始するには、このチェック・ボックスを選択します。最大40つのキャンペーンを選択できます。キャンペーン開始に関する進捗通知を受信するには、各キャンペーンの設定で、進捗通知を受信する1つ以上のEメール・アドレスを指定していることを確認してください。
ステップ6: 通知
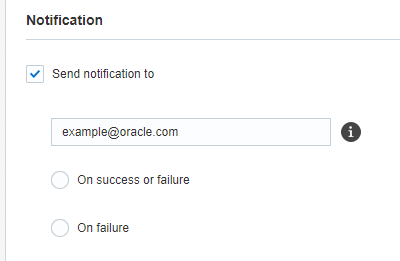
このステップでは、ジョブに関するEメール通知を設定します。ジョブが成功または失敗した後に通知を送信することを選択できます。
ステップ7: スケジュール
このステップでは、ジョブをスケジュールします。指定された日時に1回、または定期的にジョブを実行できます。オンデマンドでジョブを実行するには、「スケジュールしない」オプションを使用します。
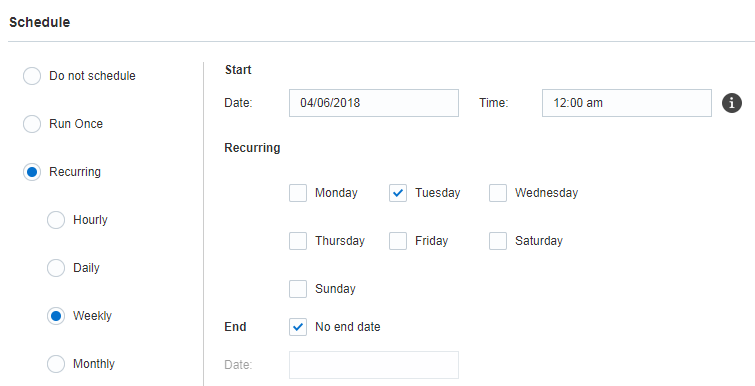
重要: うるう年および31日ある月に問題が発生しないようにするため、毎月繰返しの実行は月の29日、30日または31日にスケジュールできません。月の最後の金曜日など、月の最後の曜日にジョブを実行するようにスケジュールできます。
ジョブの開始時間を設定する場合は、1時間内の0-14、15-29、30-44、45-59の4つの時間スロットのいずれかを選択します。スケジュールされた各ジョブについて、システムが無作為な分(0-14セグメントで12分以内など)を選びます。これにより、ジョブの開始時間がより均等に配分されます。
ジョブは選択された時間スロット内で無作為に開始されます。新しいジョブを現在時刻と重なるスロットに設定しようとすると、選択した時間は過去に起こったという旨のエラー・メッセージが発行される場合があります。したがって、現在の時間スロットよりも後の時間スロットを選択することがベスト・プラクティスとなります。