Importando Dados Complementares
Importante: este tópico é para usuários da versão mais recente do Connect. Se a sua conta ainda usar o Connect Clássico, faça download do Guia do Usuário do Connect Clássico.
Você pode usar o Connect para importar registros para uma tabela de Dados Complementares no Oracle Responsys.
Após a execução de um job de importação, o arquivo de carregamento é arquivado no servidor. Se o job for bem-sucedido, o arquivo de carregamento será excluído. Se o job falhar, o arquivo de carregamento será excluído somente nas seguintes circunstâncias:
- Se o arquivo estiver vazio
- Se houver problemas nos dados do arquivo, como formato de dados inválido
- Se o arquivo de carregamento e o de contagem tiverem um número diferente de registros.
Para criar um job para Importar Dados Complementares:
- Clique em
 Dados na barra de navegação lateral e selecione Connect.
Dados na barra de navegação lateral e selecione Connect. - Clique em Criar Job na página Gerenciar Connect.
- Selecione Importar Dados Complementares na lista suspensa e informe um nome e uma descrição para o job de importação.
Os nomes de job não podem ter mais de 100 caracteres e só podem incluir os seguintes caracteres: A-Z a-z 0-9 espaço ! - = @ _ [ ] { }
- Clique em Concluído.
O assistente do Connect é aberto. Você pode concluir essas etapas em qualquer ordem, salvar as alterações e continuar depois.
- Conclua as etapas:
- Depois de configurar todas as etapas, clique em Salvar. Para salvar e ativar o job, clique em Ativar.
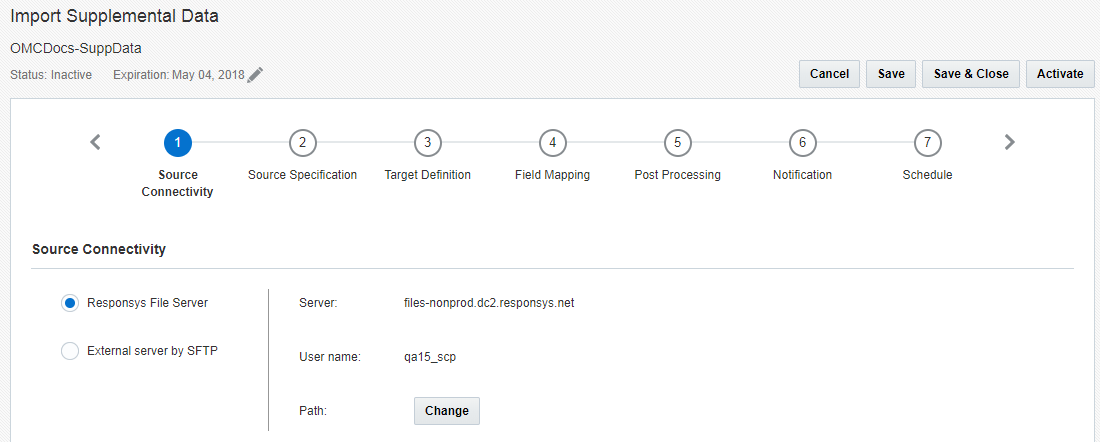
Importante: antes de poder salvar ou ativar o job, você precisa definir uma data de expiração ou definir que ele nunca expire. Para definir uma data de expiração, clique em Editar ao lado de Expiração. Quando o job expira, ele é excluído e não pode ser recuperado. Saiba mais sobre gerenciamento da data de expiração.
ao lado de Expiração. Quando o job expira, ele é excluído e não pode ser recuperado. Saiba mais sobre gerenciamento da data de expiração.
Depois de concluir:
- Depois de salvar seu job, você pode usar a página Gerenciar Connect para gerenciar o job. Saiba mais sobre o gerenciamento de jobs.
- Quando você salva seu job, o Connect pode retornar erros. Clique em Mostrar Erros para analisar os erros e ir rapidamente para a página que precisa de correção. Você deve resolver todos os erros antes de ativar o job.
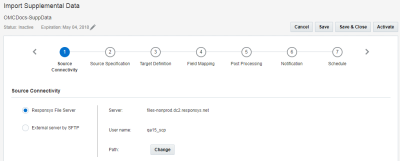
Etapa 1: Conectividade de Origem
Nesta etapa, você deve informar especificações do servidor de arquivos para recuperar seu arquivo de origem.
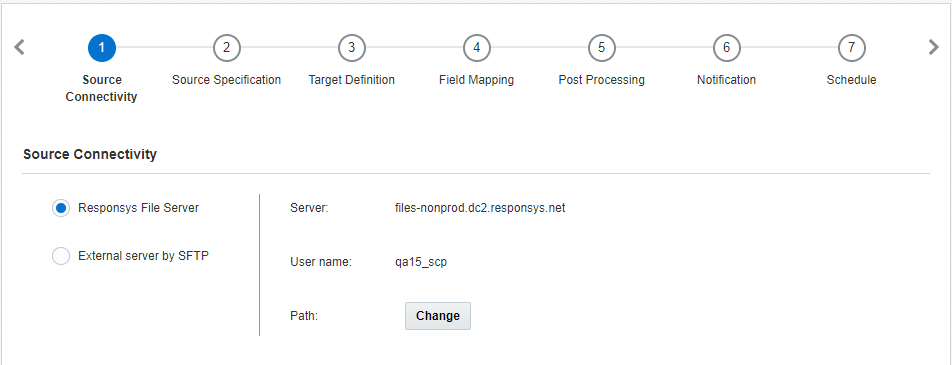
Selecione uma das seguintes opções:
- Servidor de Arquivos da Responsys: os jobs do Connect podem importar dados por meio do servidor de arquivos de conta Responsys SCP (Secure Copy Protocol). Essa conta inclui três diretórios: upload, download e arquivo-morto.
Importante: o Suporte do Oracle Responsys e sua própria equipe de TI precisarão trabalhar juntos para gerar um par de chaves pública/privada SSH-2, caso isso ainda não tenha sido estabelecido. Isso garante acesso seguro à sua conta SCP por meio de um cliente SSH/SCP. Você também pode criar seus próprios diretórios usando um cliente SSH (Secure Shell).
- Se você selecionar essa opção, clique em Alterar para especificar o diretório em que seus arquivos estão localizados.
- Servidor externo por SFTP: se você selecionar esta opção, detalhe as seguintes informações:
- Nome do Host: selecione o nome do host na lista suspensa.
- Caminho do Diretório: informe o nome do caminho do diretório associado.
- Nome do Usuário: informe o nome do usuário para acessar sua conexão SFTP.
- Autenticação: dependendo da maneira como seu servidor está configurado, selecione Senha ou Chave.
Se este for seu primeiro job usando autorização por chave, clique em Acessar ou Gerar Informações da Chave e informe o endereço de e-mail a receber a chave pública e as instruções para adicionar a chave à sua conta SFTP. Depois de instalar a chave pública, clique em Testar Conexão para verificar se a configuração da sua conexão SFTP é válida.
Dica: para obter informações sobre autenticação com chave, consulte Selecionando, Importando ou Gerando Chaves Públicas.
Etapa 2: Especificação da Origem
Nesta etapa, você deve inserir informações sobre o arquivo a ser importado.
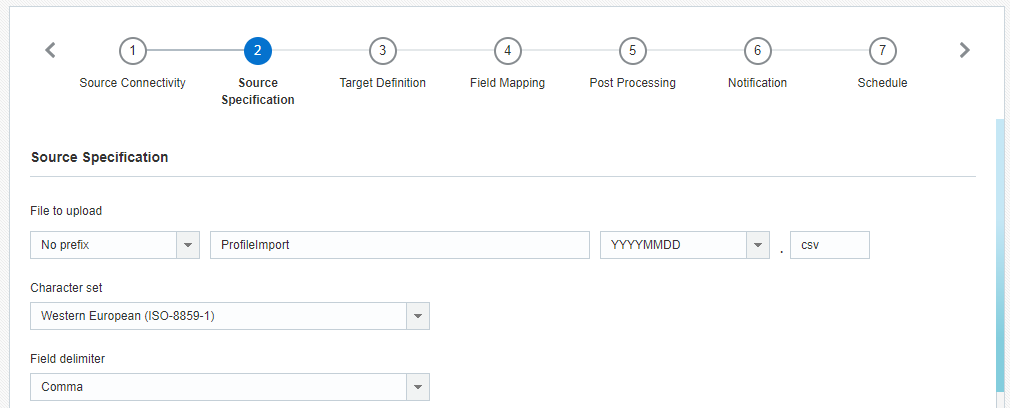
- Arquivo a ser carregado: o nome completo e a extensão do arquivo para importar. É possível adicionar a data de criação do arquivo como prefixo ou sufixo.
- Conjunto de caracteres: o conjunto de caracteres do arquivo. Se o seu arquivo contiver emojis, você precisará selecionar Unicode (UTF-8) como o seu conjunto de caracteres.
- Delimitador de campos: o delimitador que divide os campos (colunas) no arquivo.
- Inclusão de campo: especifique se as colunas de texto e os valores devem ser delimitados por aspas simples ou duplas.
- Formato de dados: selecione o formato de dados do arquivo de importação. Para obter informações sobre todos os formatos de datas compatíveis, consulte Formatos de Dados Compatíveis no Connect.
- Primeira linha contém nomes de coluna: marque esta caixa de seleção se a primeira linha do arquivo contiver nomes.
- O arquivo está criptografado com Chave PGP/GPG: marque esta caixa de seleção se o arquivo tiver sido criptografado usando uma chave e precisar ser descriptografado antes de ser carregado.
- O arquivo está assinado com Chave PGP/GPG: marque esta caixa de seleção se o arquivo estiver assinado com uma chave.
- Arquivo para confirmação de número esperado de registros: como opção, marque essa caixa de seleção e especifique um arquivo para comparar o número do registro com o número de registros importados. Por exemplo, se o número esperado de registros no arquivo for de 300, mas o arquivo importado contiver apenas 100 registros, um erro de transferência será visto, e o processo de carregamento será abortado
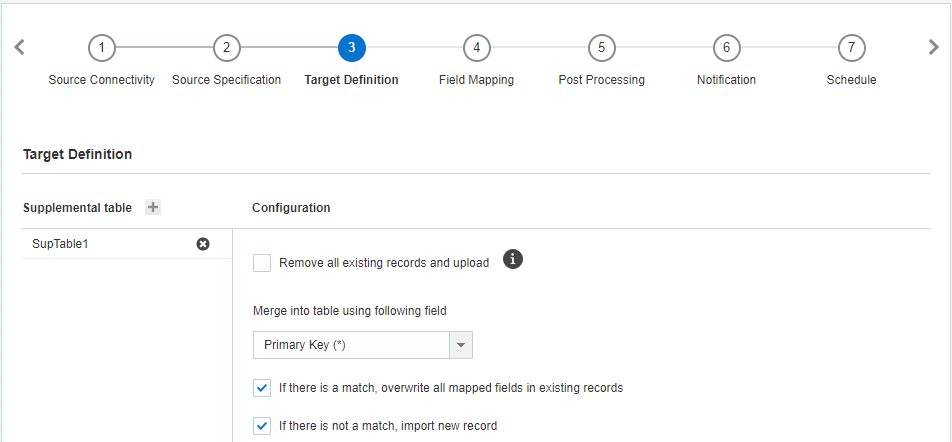
Etapa 3: Definição de Destino
Nesta etapa, selecione a tabela de Dados Complementares para a qual deseja importar dados.
Observação: você também precisará selecionar tabelas de destino ao mapear campos na Etapa 4.
Para adicionar uma definição de destino:
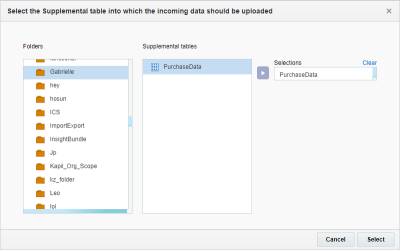
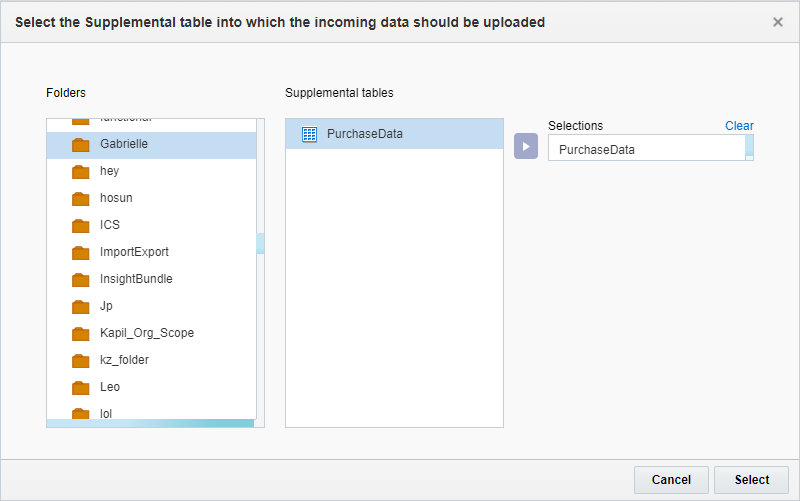
- Na etapa Definição de Destino, clique em Adicionar + e selecione a tabela de Dados Complementares para a qual deseja importar dados.
- Na seção Configuração, especifique as seguintes opções:
- Remover todos os registros existentes e carregar: marque esta caixa de seleção para substituir os registros existentes por registros carregados recentemente.
- Mesclar na tabela usando o campo a seguir: se não for remover todos os registros existentes, selecione o campo para mesclar novos registros a registros existentes.
- Se houver uma correspondência, substituir todos os campos mapeados em registros existentes: marque esta caixa de seleção para substituir arquivos existentes por novos dados quando um registro corresponder. Se você não marcar essa caixa de seleção, o registro de entrada será ignorado.
- Se não houver uma correspondência, importar novo registro: marque esta caixa de seleção para importar registros se não houver correspondência. Se você não marcar essa caixa de seleção, o registro de entrada será ignorado.
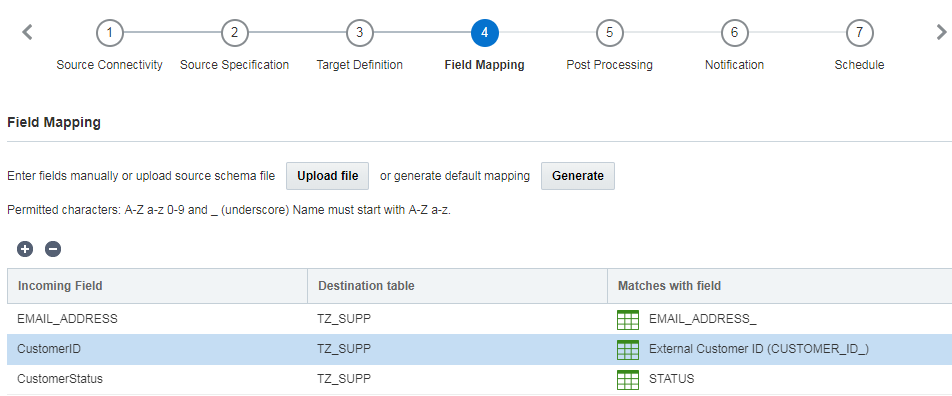
Etapa 4: Mapeamento de Campos
Nesta etapa, mapeie as colunas do arquivo de origem para os campos na tabela de destino. O mapeamento de campos especifica quais campos de origem correspondem a quais campos de destino.
Você pode mapear manualmente os campos, usar um arquivo carregado ou gerar automaticamente o mapeamento do campo.
Observe o seguinte:
- Nomes de campo longos são truncados com 30 caracteres.
- Os nomes dos campos devem começar com uma letra ou um número e conter apenas letras, dígitos e _ (sublinhados).
- Quando criados, os nomes de arquivo não diferenciam maiúsculas e minúsculas, mas são posteriormente traduzidos com todas as letras maiúsculas.
- Se alguma alteração resultar em nomes de arquivo duplicados, você vai precisar renomeá-los manualmente.
- Todos os nomes de campos do sistema (definidos e reservados pelo Oracle Responsys) terminam com um caractere sublinhado. Por exemplo, EMAIL_ADDRESS_. Como prática recomendada, os nomes de campos carregados não devem terminar com caracteres sublinhados, pois eles são reservados para os campos do sistema.
- Sempre que possível, corresponda os campos de entrada de nome semelhante a campos existentes. Por exemplo, corresponda CUST_ID a CUSTOMER_ID_.
Para obter mais detalhes sobre as exigências de tipo de dados e nome de campo, consulte Tipos e Nomes de Campo.
Para carregar um arquivo de mapeamento:
- Na etapa Mapeamento de Campo, clique em Carregar Arquivo.
- Selecione o arquivo de mapeamento e preencha os detalhes.
- Campos são delimitados por: selecione o delimitador (normalmente tabulação ou vírgula) que divide as colunas do arquivo.
- Os campos estão entre: especifique se as colunas de texto e os valores devem ficar entre aspas simples ou duplas.
- Primeira linha contém nomes de coluna: marque esta caixa de seleção se a primeira linha contiver nomes de campo.
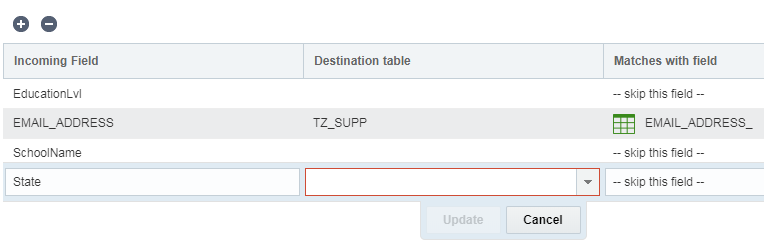
Para mapear campos:
- Na etapa Mapeamento de Campo, clique em Adicionar +.
- Certifique-se também de selecionar a tabela de destino desse campo.
- Especifique o campo de entrada e o campo que corresponde a ele. Se você não quiser corresponder um campo, selecione ignorar este campo.
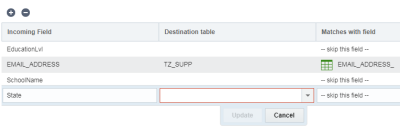
- Clique em Atualizar.
Etapa 5: Pós-processamento
Nesta etapa, você pode enviar campanhas depois de uma execução de job bem-sucedida. Você pode selecionar até 40 campanhas.
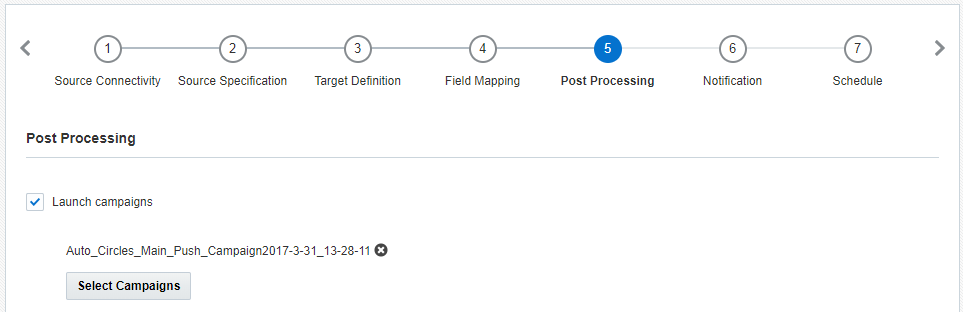
Para receber notificações de andamento sobre envios de campanha, certifique-se de que as configurações de cada campanha especifiquem um ou mais endereços de e-mail para receber essas notificações.
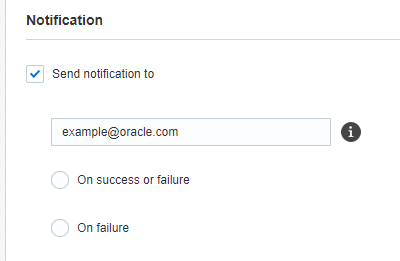
Etapa 6: Notificação
Nesta etapa, configure notificações de e-mail para o job. Você pode optar por enviar notificações depois do êxito ou da falha de um job.
Etapa 7: Agendamento
Nesta etapa, agende o envio do job. O job pode ser executado uma vez em uma data e hora especificadas ou em um agendamento recorrente. Para executar o job por demanda, use a opção Não programar.
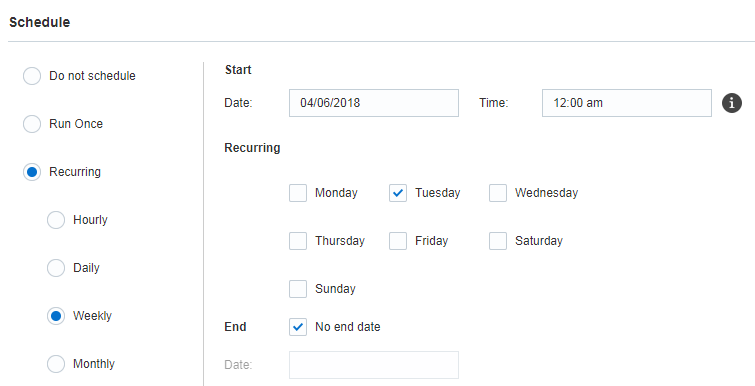
Importante: para garantir que anos bissextos e meses com 31 dias não causem problemas, você não pode agendar uma recorrência mensal nos dias 29, 30 nem 31 do mês. Você pode agendar o job para ser executado em um dia da semana que seja o último dia do mês. Por exemplo, na última sexta-feira do mês.
Ao definir a hora inicial de um job, selecione um dos quatro períodos dentro da hora: 0 a 14, 15 a 29, 30 a 44 e 45 a 59. Para cada tarefa agendada, o sistema escolhe um minuto aleatório (por exemplo, 12 dentro do segmento de 0-14). Isso distribui as horas iniciais das tarefas mais uniformemente.
O job começará em horários aleatórios dentro do período escolhido. Se você tentar configurar um novo job em um intervalo que coincida com a hora atual, uma mensagem de erro poderá ser emitida informando que a hora selecionada ocorre no passado. Por isso, como prática recomendada, escolha o período seguinte ao período atual.