JupyterHub in Big Data Service 3.0.26 oder früher verwenden
Verwenden Sie JupyterHub, um Big Data Service 3.0.26 oder frühere ODH 1.x-Notizbücher für Benutzergruppen zu verwalten.
Voraussetzungen
Bevor über einen Browser auf JupyterHub zugegriffen werden kann, muss ein Administrator folgende Schritte ausführen:
- Der Knoten muss für eingehende Verbindungen von Benutzern verfügbar gemacht werden. Die private IP-Adresse des Knotens muss einer öffentlichen IP-Adresse zugeordnet werden. Alternativ kann das Cluster so eingerichtet werden, dass es einen Bastionhost oder Oracle FastConnect verwendet. Siehe Verbindung zu Clusterknoten mit privaten IP-Adressen herstellen.
- Der Port
8000muss auf dem Knoten geöffnet werden, indem die Ingress-Regeln in der Netzwerksicherheitsliste konfiguriert werden. Siehe Sicherheitsregeln festlegen.
JupyterHub Standardzugangsdaten
Die Standardzugangsdaten für die Admin-Anmeldung für JupyterHub in Big Data Service 3.0.21 und früher sind:
- Benutzername:
jupyterhub - Kennwort: Apache Ambari-Admin-Kennwort. Hierbei handelt es sich um das Cluster-Admin-Kennwort, das bei der Erstellung des Clusters angegeben wurde.
- Principal-Name für HA-Cluster:
jupyterhub - Keytab für HA-Cluster:
/etc/security/keytabs/jupyterhub.keytab
Die Standardzugangsdaten für die Admin-Anmeldung für JupyterHub in Big Data Service 3.0.22 bis 3.0.26 sind:
- Benutzername:
jupyterhub - Kennwort: Apache Ambari-Admin-Kennwort. Hierbei handelt es sich um das Cluster-Admin-Kennwort, das bei der Erstellung des Clusters angegeben wurde.
- Principal-Name für HA-Cluster:
jupyterhub/<FQDN-OF-UN1-Hostname> - Keytab für HA-Cluster:
/etc/security/keytabs/jupyterhub.keytabBeispiel:Principal name for HA cluster: jupyterhub/pkbdsv2un1.rgroverprdpub1.rgroverprd.oraclevcn.com Keytab for HA cluster: /etc/security/keytabs/jupyterhub.keytab
Der Administrator erstellt zusätzliche Benutzer und ihre Anmeldedaten und stellt diesen Benutzern die Anmeldedaten zur Verfügung. Weitere Informationen finden Sie unter Benutzer und Berechtigungen verwalten.
Sofern nicht explizit auf einen anderen Administratortyp verwiesen wird, bezieht sich die Verwendung von administrator oder admin in diesem Abschnitt auf den JupyterHub-Administrator jupyterhub.
Auf JupyterHub zugreifen
Alternativ können Sie auf der Seite "Clusterdetails" unter Cluster-URLs auf den Link JupyterHub zugreifen.
Sie können auch einen Load Balancing erstellen, um ein sicheres Frontend für den Zugriff auf Services bereitzustellen, einschließlich JupyterHub. Siehe Mit Load Balancer Verbindungen zu Services auf einem Cluster herstellen.
Notizbücher starten
Die Voraussetzungen müssen erfüllt sein, damit der Benutzer Notizbücher starten kann.
- Rufen Sie JupyterHub auf.
- Melden Sie sich mit Administratorzugangsdaten an. Die Autorisierung funktioniert nur, wenn der Benutzer auf dem Linux-Host vorhanden ist. JupyterHub sucht den Benutzer auf dem Linux-Host, während versucht wird, den Notizbuchserver zu starten.
- Sie werden umgeleitet auf eine Seite mit Serveroptionen, auf der Sie ein Kerberos-Ticket anfordern müssen. Dieses Ticket kann entweder mit dem Kerberos-Principal und der Keytab-Datei oder mit dem Kerberos-Kennwort angefordert werden. Der Clusteradministrator kann den Kerberos- Principal und die Keytab-Datei oder das Kerberosos-Kennwort angeben.
Sie benötigen das Kerberos-Ticket, um Zugriff auf die HDFS-Verzeichnis und anderen Big-Data-Services zu erhalten, die Sie verwenden möchten.
Die Voraussetzungen müssen erfüllt sein, damit der Benutzer Notizbücher starten kann.
- Rufen Sie JupyterHub auf.
- Melden Sie sich mit Administratorzugangsdaten an. Die Autorisierung funktioniert nur, wenn der Benutzer auf dem Linux-Host vorhanden ist. JupyterHub sucht den Benutzer auf dem Linux-Host, während versucht wird, den Notizbuchserver zu starten.
JupyterHub verwalten
Ein JupyterHub-admin-Benutzer kann die folgenden Aufgaben ausführen, um Notizbücher in JupyterHub auf Big Data Service 3.0.26- oder früheren ODH 1.x-Knoten zu verwalten.
Als admin können Sie JupyterHub konfigurieren.
Konfigurieren Sie JupyterHub über den Browser für Big Data Service 3.0.26-Cluster oder frühere Cluster.
Stoppen oder starten Sie JupyterHub über den Browser für Big Data Service 3.0.26-Cluster oder frühere Cluster.
Als admin können Sie die Anwendung stoppen oder deaktivieren, sodass sie keine Ressourcen wie Arbeitsspeicher belegt. Ein Neustart kann auch bei unerwarteten Problemen oder Verhaltensweisen helfen.
Als Administrator können Sie die Anzahl der aktiven Notebook-Server im Big Data Service-Cluster begrenzen.
Notizbücher werden standardmäßig im HDFS-Verzeichnis eines Clusters gespeichert.
Sie benötigen Zugriff auf das HDFS-Verzeichnis hdfs:///user/<username>/. Die Notizbücher werden in hdfs:///user/<username>/notebooks/ gespeichert.
- Melden Sie sich als Benutzer
opcbei dem Utilityknoten an, auf dem JupyterHub installiert ist (der zweite Utilityknoten eines HA-(hochverfügbaren) Clusters oder der erste und einzige Utilityknoten eines Nicht-HA-Cluster). - Verwalten Sie mit
sudoJupyterHub-Konfigurationen, die unter/opt/jupyterhub/jupyterhub_config.pygespeichert sind.c.Spawner.args = ['--ServerApp.contents_manager_class="hdfscm.HDFSContentsManager"'] - Starten Sie mit
sudoJupyterHub neu.sudo systemctl restart jupyterhub.service
Als Admin-Benutzer können Sie die einzelnen Benutzernotizbücher in Object Storage statt in HDFS speichern. Wenn Sie den Content Manager von HDFS in Objektspeicher ändern, werden die vorhandenen Notizbücher nicht in Objektspeicher kopiert. Die neuen Notizbücher werden in Object Storage gespeichert.
- Melden Sie sich als Benutzer
opcbei dem Utilityknoten an, auf dem JupyterHub installiert ist (der zweite Utilityknoten eines HA-(hochverfügbaren) Clusters oder der erste und einzige Utilityknoten eines Nicht-HA-Cluster). - Verwalten Sie mit
sudoJupyterHub-Konfigurationen, die unter/opt/jupyterhub/jupyterhub_config.pygespeichert sind. Informationen zum Generieren der erforderlichen Schlüssel finden Sie unter Zugriff und Secret Key generieren.c.Spawner.args = ['--ServerApp.contents_manager_class="s3contents.S3ContentsManager"', '--S3ContentsManager.bucket="<bucket-name>"', '--S3ContentsManager.access_key_id="<accesskey>"', '--S3ContentsManager.secret_access_key="<secret-key>"', '--S3ContentsManager.endpoint_url="https://<object-storage-endpoint>"', '--S3ContentsManager.region_name="<region>"','--ServerApp.root_dir=""'] - Starten Sie mit
sudoJupyterHub neu.sudo systemctl restart jupyterhub.service
Mit Object Storage integrieren
Integrieren Sie Spark in Object Storage zur Verwendung mit Big Data Service-Clustern.
Damit Spark mit Object Storage funktioniert, müssen Sie in JupyterHub einige Systemeigenschaften definieren und in den Eigenschaften spark.driver.extraJavaOption und spark.executor.extraJavaOptions in den Spark-Konfigurationen auffüllen.
Vor der erfolgreichen Integration von JupyterHub mit Object Storage müssen Sie folgende Schritte ausführen:
- Erstellen Sie einen Bucket im Objektspeicher, um Daten zu speichern.
- Erstellen Sie einen Object Storage-API-Schlüssel.
Folgende Eigenschaften müssen Sie in den Spark-Konfigurationen definieren:
-
TenantID -
Userid -
Fingerprint -
PemFilePath -
PassPhrase -
Region
Rufen Sie die Werte für diese Eigenschaften ab:
- Öffnen Sie das Navigationsmenü, und wählen Sie Analysen und KI aus. Wählen Sie unter Data Lake die Option Big Data Service aus.
- Wählen Sie auf der Listenseite Cluster das Cluster, mit dem Sie arbeiten möchten. Wenn Sie Hilfe beim Suchen der Listenseite oder des Clusters benötigen, finden Sie weitere Informationen unter Cluster in einem Compartment auflisten.
-
Um Cluster in einem anderen Compartment anzuzeigen, wechseln Sie zum Compartment.
Sie benötigen die Berechtigung, in einem Compartment zu arbeiten, um die darin enthaltenen Ressourcen anzuzeigen. Wenn Sie nicht sicher sind, welches Compartment zu verwenden ist, wenden Sie sich an einen Administrator. Weitere Informationen finden Sie unter Compartments.
- Wählen Sie auf der Seite "Clusterdetails" die Option Object Storage-API-Schlüssel aus.
- Wählen Sie im Menü des API-Schlüssels, den Sie anzeigen möchten, Konfigurationsdatei anzeigen aus.
Die Konfigurationsdatei enthält alle Details der Systemeigenschaften mit Ausnahme der Passphrase. Die Passphrase wird beim Erstellen des Object Storage-API-Schlüssels angegeben. Sie müssen dieselbe Passphrase erneut ermitteln und verwenden.
- Rufen Sie JupyterHub auf.
- Öffnen Sie ein neues Notizbuch.
- Kopieren Sie die folgenden Befehle, und fügen Sie sie ein, um eine Verbindung zu Spark herzustellen.
import findspark findspark.init() import pyspark - Kopieren Sie die folgenden Befehle, und fügen Sie sie ein, um eine Spark-Session mit den angegebenen Konfigurationen zu erstellen. Ersetzen Sie die Variablen durch die zuvor abgerufenen Systemeigenschaftswerte.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("spark.driver.extraJavaOptions", "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .config("spark.executor.extraJavaOptions" , "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .appName("<appname>") \ .getOrCreate() - Kopieren Sie die folgenden Befehle, und fügen Sie sie ein, um die Object Storage-Verzeichnisse und -Dateien zu erstellen und Daten im Parquet-Format zu speichern.
demoUri = "oci://<BucketName>@<Tenancy>/<DirectoriesAndSubDirectories>/" parquetTableUri = demoUri + "<fileName>" spark.range(10).repartition(1).write.mode("overwrite").format("parquet").save(parquetTableUri) - Kopieren Sie den folgenden Befehl, und fügen Sie ihn ein, um Daten aus Object Storage zu lesen.
spark.read.format("parquet").load(parquetTableUri).show() - Führen Sie das Notizbuch mit all diesen Befehlen aus.
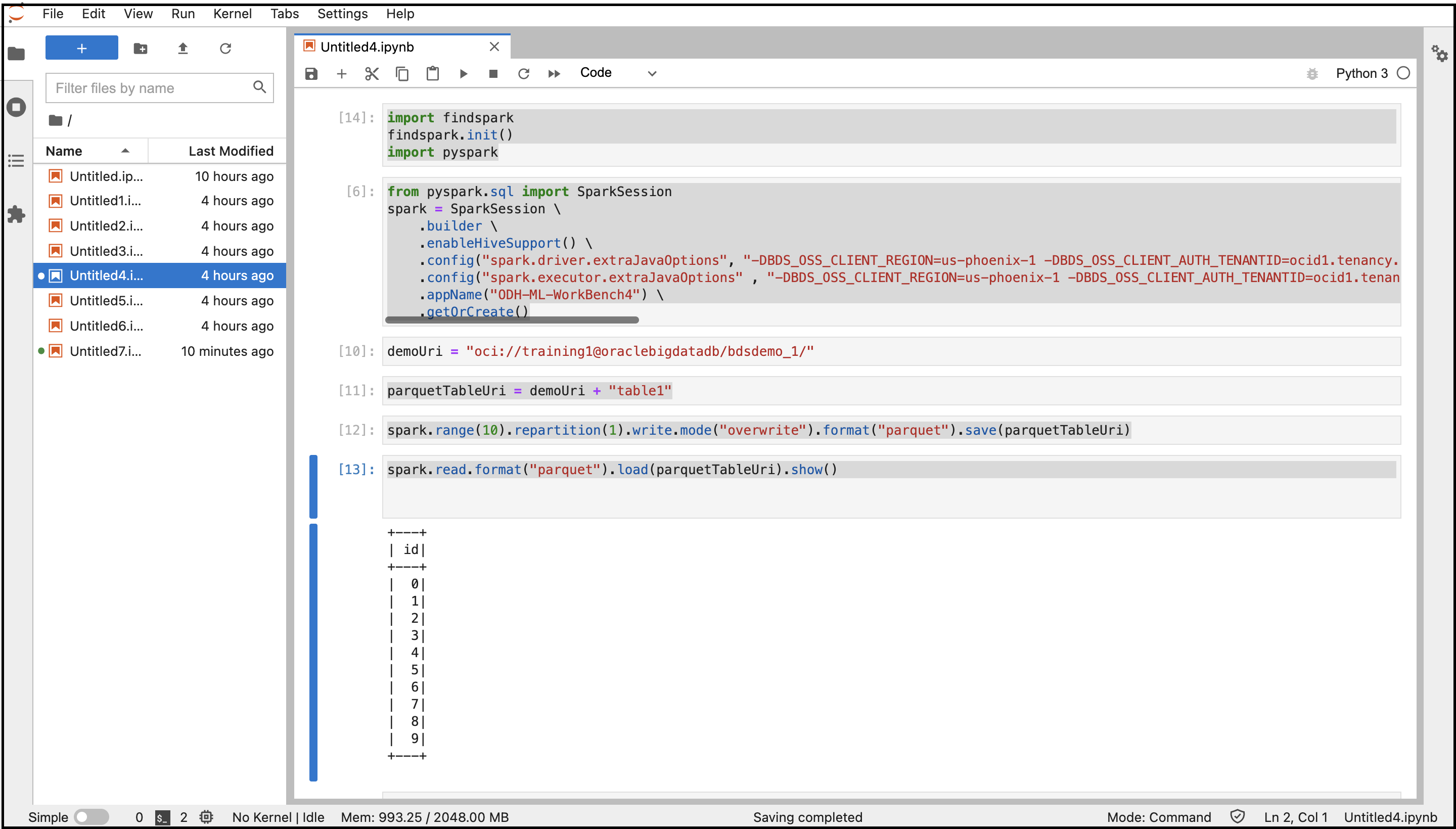
Die Ausgabe des Codes wird angezeigt. Sie können in der Konsole zum Objektspeicher-Bucket navigieren und die im Bucket erstellte Datei suchen.
Benutzer und Berechtigungen verwalten
Verwenden Sie eine der beiden Authentifizierungsmethoden, um Benutzer bei JupyterHub zu authentifizieren, damit sie Notizbücher erstellen und JupyterHub optional verwalten können.
Standardmäßig unterstützen ODH 1.x-Cluster die native Authentifizierung. Die Authentifizierung für JupyterHub und andere Big-Data-Services muss jedoch anders erfolgen. Um Notizbücher für einzelne Benutzer zu starten, muss der Benutzer, der sich bei JupyterHub anmeldet, auf dem Linux-Host vorhanden sein und über Schreibberechtigungen für das Root-Verzeichnis in HDFS verfügen. Andernfalls verläuft der Start nicht erfolgreich, weil der Notizbuchprozess als Linux-Benutzer ausgelöst wird.
Informationen zur nativen Authentifizierung finden Sie unter Native Authentifizierung.
Informationen zur LDAP-Authentifizierung für Big Data Service 3.0.26 oder früher finden Sie unter LDAP-Authentifizierung.
Die native Authentifizierung ist von der JupyterHub-Benutzerdatenbank zur Authentifizierung von Benutzern abhängig.
Die native Authentifizierung gilt sowohl für HA- als auch für Nicht-HA-Cluster. Einzelheiten zum nativen Authentikator finden Sie unter Nativer Authentikator.
Diese Voraussetzungen müssen erfüllt sein, um einen Benutzer in einem Big Data Service-HA-Cluster mit nativer Authentifizierung zu autorisieren.
Diese Voraussetzungen müssen erfüllt sein, um einen Benutzer in einem Big Data Service-Nicht-HA-Cluster mit nativer Authentifizierung zu autorisieren.
Admin-Benutzer sind für die Konfiguration und Verwaltung von JupyterHub verantwortlich. Admin-Benutzer sind auch für die Autorisierung neu registrierter Benutzer in JupyterHub verantwortlich.
Bevor Sie einen Admin-Benutzer hinzufügen, müssen die Voraussetzungen für ein Nicht-HA-Cluster erfüllt sein.
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste unter Services die Option JupyterHub aus.
- Wählen Sie Konfigurationen, Erweiterte Konfigurationen aus.
- Wählen Sie Advanced jupyterhub-config aus.
-
Fügen Sie den Admin-Benutzer zu
c.Authenticator.admin_usershinzu. - Wählen Sie Speichern aus.
Bevor Sie andere Benutzer hinzufügen, müssen die Voraussetzungen für ein Big Data Service-Cluster erfüllt sein.
-
Der Admin-Benutzer muss sich bei JupyterHub anmelden und über die neue Menüoption zur Autorisierung angemeldeter Benutzer den neuen Benutzer autorisieren.
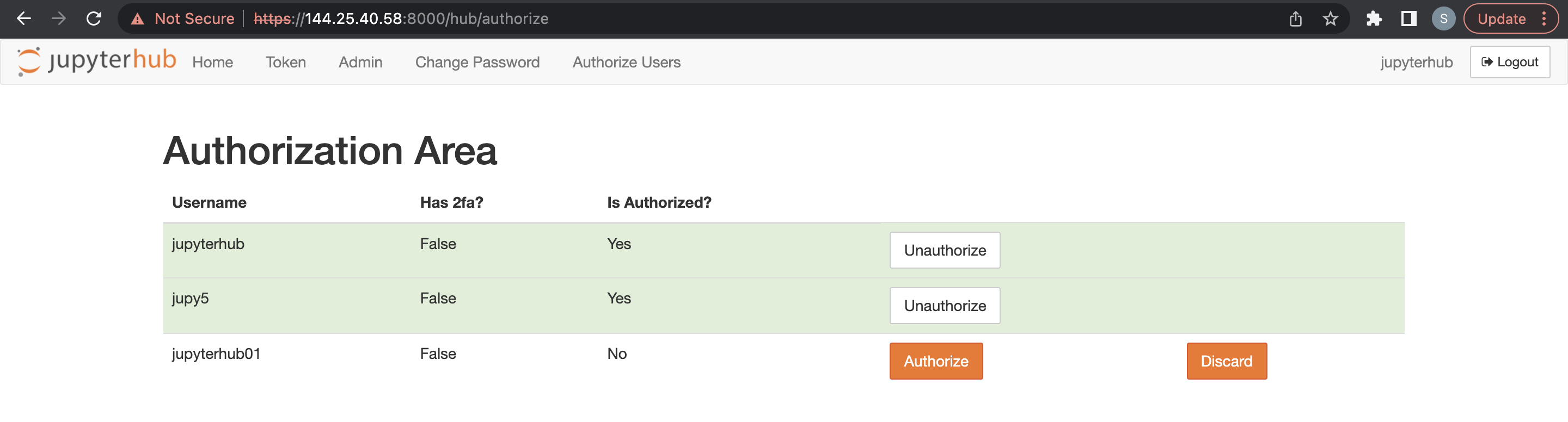
Ein Admin-Benutzer kann JupyterHub-Benutzer löschen.
- Rufen Sie JupyterHub auf.
- Öffnen Sie File > HubControlPanel.
- Navigieren Sie zur Seite Authorize Users.
- Löschen Sie die Benutzer, die Sie entfernen möchten.
Sie können die LDAP-Authentifizierung über einen Browser für Big Data Service 3.0.26- oder frühere ODH 1.x-Cluster verwenden.
Integration mit Trino
- Trino muss im Big Data Service-Cluster installiert und konfiguriert werden.
- Installieren Sie das folgende Python-Modul im Knoten JupyterHub (un1 für HA/un0 für Nicht-HA-Cluster) Hinweis
Ignorieren Sie diesen Schritt, wenn das Trino-Python-Modul bereits im Knoten vorhanden ist.python3.6 -m pip install trino[sqlalchemy] Offline Installation: Download the required python module in any machine where we have internet access Example: python3 -m pip download trino[sqlalchemy] -d /tmp/package Copy the above folder content to the offline node & install the package python3 -m pip install ./package/* Note : trino.sqlalchemy is compatible with the latest 1.3.x and 1.4.x SQLAlchemy versions. BDS cluster node comes with python3.6 and SQLAlchemy-1.4.46 by default.
Wenn das Trino-Ranger-Plugin aktiviert ist, müssen Sie den bereitgestellten Keytab-Benutzer in den entsprechenden Trino Ranger-Richtlinien hinzufügen. Siehe Trino in Ranger integrieren.
Standardmäßig verwendet Trino den vollständigen Kerberos-Principal-Namen als Benutzer. Wenn Sie Trino-ranger-Policys hinzufügen/aktualisieren, müssen Sie daher den vollständigen Kerberos-Principal-Namen als Benutzernamen verwenden.
Verwenden Sie für das folgende Codebeispiel jupyterhub@BDSCLOUDSERVICE.ORACLE.COM als Benutzer in den trino-ranger-Policys.
Wenn das Trino-Ranger-Plugin aktiviert ist, müssen Sie den angegebenen Keytab-Benutzer in den entsprechenden Trino Ranger-Policys hinzufügen. Weitere Informationen finden Sie unter Ranger für Trino aktivieren.
Geben Sie Ranger-Berechtigungen für JupyterHub für die folgenden Policys an:
-
all - catalog, schema, table, column -
all - function