JupyterHub in Big Data Service 3.0.27 oder höher verwenden
Verwenden Sie JupyterHub, um Big Data Service 3.0.27- oder höher als ODH 2.x-Notizbücher für Benutzergruppen zu verwalten.
Voraussetzungen
Auf JupyterHub zugreifen
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste unter Services die Option JupyterHub aus.
JupyterHub verwalten
Ein JupyterHub-admin-Benutzer kann die folgenden Aufgaben ausführen, um Notizbücher in JupyterHub auf ODH 2.x-Knoten in Big Data Service 3.0.27 oder höher zu verwalten.
Informationen zum Verwalten von Oracle Linux 7-Services mit dem Befehl systemctl finden Sie unter Mit Systemservices arbeiten.
Informationen zur Anmeldung bei einer Oracle Cloud Infrastructure-Instanz finden Sie unter Verbindung mit der Instanz herstellen.
Als Administrator können Sie JupyterHub stoppen oder deaktivieren, sodass es keine Ressourcen wie Arbeitsspeicher belegt. Ein Neustart kann auch bei unerwarteten Problemen oder Verhaltensweisen helfen.
Stoppen oder starten Sie JupyterHub über Ambari für Big Data Service 3.0.27-Cluster oder höher.
Als Administrator können Sie einem Big Data Service-Knoten den Server JupyterHub hinzufügen.
Diese Option ist für Cluster von Big Data Service 3.0.27 oder höher verfügbar.
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste Hosts aus.
- Um den JupyterHub-Server hinzuzufügen, wählen Sie einen Host aus, auf dem JupyterHub nicht installiert ist.
- Wählen Sie Hinzufügen aus.
- Wählen Sie JupyterHub Server aus.
Als Administrator können Sie den JupyterHub-Server in einen anderen Big Data Service-Knoten verschieben.
Diese Option ist für Cluster von Big Data Service 3.0.27 oder höher verfügbar.
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste unter Services die Option JupyterHub aus.
- Wählen Sie Aktionen, JupyterHub-Server verschieben aus.
- Wählen Sie Weiter.
- Wählen Sie den Host aus, in den der JupyterHub-Server verschoben werden soll.
- Schließen Sie den Assistenten zum Verschieben ab.
Als Administrator können Sie JupyterHub-Service-/Health Checks über Ambari ausführen.
Diese Option ist für Cluster von Big Data Service 3.0.27 oder höher verfügbar.
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste unter Services die Option JupyterHub aus.
- Wählen Sie Aktionen, Serviceprüfung ausführen aus.
Benutzer und Berechtigungen verwalten
Verwenden Sie eine der beiden Authentifizierungsmethoden, um Benutzer bei JupyterHub zu authentifizieren, damit sie Notizbücher erstellen und optional JupyterHub in ODH 2.x-Clustern in Big Data Service 3.0.27 oder höher verwalten können.
JupyterHub-Benutzer müssen als BS-Benutzer auf allen Big Data Service-Clusterknoten für Nicht-Active Directory-(AD-)Big Data Service-Cluster hinzugefügt werden, wobei Benutzer nicht automatisch über alle Clusterknoten hinweg synchronisiert werden. Administratoren können das Benutzerverwaltungsskript JupyterHub verwenden, um Benutzer und Gruppen hinzuzufügen, bevor sie sich bei JupyterHub anmelden.
Erforderlich
Gehen Sie folgendermaßen vor, bevor Sie auf JupyterHub zugreifen:
- Melden Sie sich mit SSH bei dem Knoten an, auf dem JupyterHub installiert ist.
- Navigieren Sie zu
/usr/odh/current/jupyterhub/install. - Um die Details aller Benutzer und Gruppen in der Datei
sample_user_groups.jsonanzugeben, führen Sie Folgendes aus:sudo python3 UserGroupManager.py sample_user_groups.json Verify user creation by executing the following command: id <any-user-name>
Unterstützte Authentifizierungstypen
- NativeAuthenticator: Dieser Authentikator wird für kleine oder mittlere JupyterHub-Anwendungen verwendet. Registrierung und Authentifizierung werden als nativ in JupyterHub implementiert, ohne sich auf externe Services zu verlassen.
-
SSOAuthenticator: Dieser Authentikator stellt eine Unterklasse von
jupyterhub.auth.Authenticatorbereit, die als SAML2-Serviceprovider fungiert. Leiten Sie sie an einen entsprechend konfigurierten SAML2-Identitätsprovider weiter, und aktivieren Sie Single Sign-On für JupyterHub.
Die native Authentifizierung ist von der JupyterHub-Benutzerdatenbank zur Authentifizierung von Benutzern abhängig.
Die native Authentifizierung gilt sowohl für HA- als auch für Nicht-HA-Cluster. Einzelheiten zum nativen Authentikator finden Sie unter Nativer Authentikator.
Diese Voraussetzungen müssen erfüllt sein, um einen Benutzer in einem Big Data Service-HA-Cluster mit nativer Authentifizierung zu autorisieren.
Diese Voraussetzungen müssen erfüllt sein, um einen Benutzer in einem Big Data Service-Nicht-HA-Cluster mit nativer Authentifizierung zu autorisieren.
Admin-Benutzer sind für die Konfiguration und Verwaltung von JupyterHub verantwortlich. Admin-Benutzer sind auch für die Autorisierung neu registrierter Benutzer in JupyterHub verantwortlich.
Bevor Sie einen Admin-Benutzer hinzufügen, müssen die Voraussetzungen für ein Nicht-HA-Cluster erfüllt sein.
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste unter Services die Option JupyterHub aus.
- Wählen Sie Konfigurationen, Erweiterte Konfigurationen aus.
- Wählen Sie Advanced jupyterhub-config aus.
-
Fügen Sie den Admin-Benutzer zu
c.Authenticator.admin_usershinzu. - Wählen Sie Speichern aus.
Bevor Sie andere Benutzer hinzufügen, müssen die Voraussetzungen für ein Big Data Service-Cluster erfüllt sein.
-
Der Admin-Benutzer muss sich bei JupyterHub anmelden und über die neue Menüoption zur Autorisierung angemeldeter Benutzer den neuen Benutzer autorisieren.
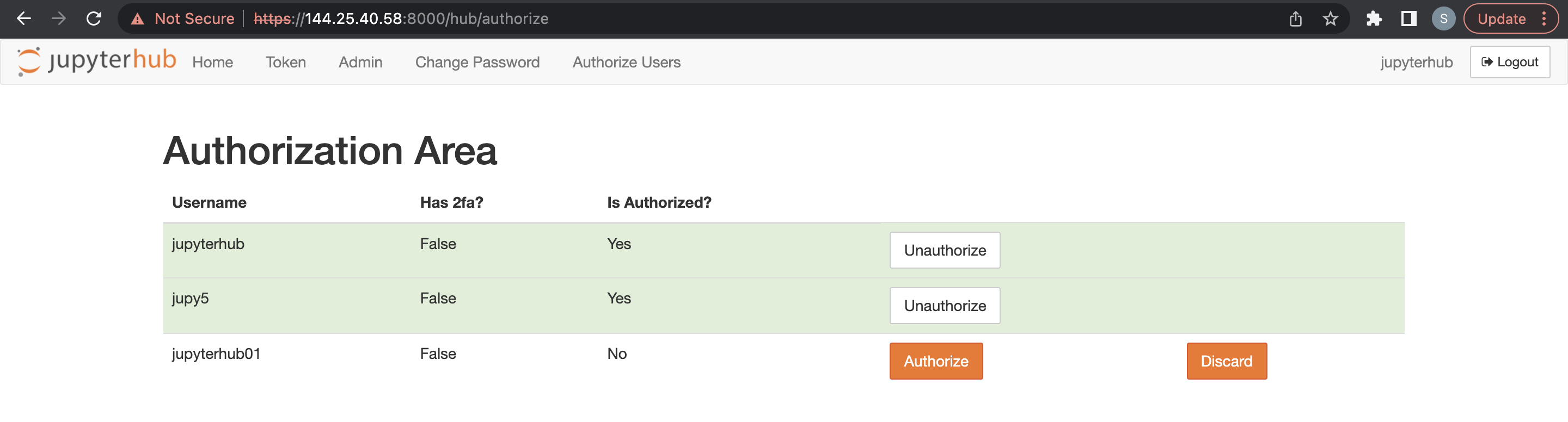
Ein Admin-Benutzer kann JupyterHub-Benutzer löschen.
- Öffnen Sie JupyterHub.
- Öffnen Sie File > HubControlPanel.
- Navigieren Sie zur Seite Authorize Users.
- Löschen Sie die Benutzer, die Sie entfernen möchten.
Sie können die LDAP-Authentifizierung über Ambari für ODH 2.x-Cluster von Big Data Service 3.0.27 oder höher verwenden.
LDAP-Authentifizierung mit Ambari verwenden
Um den LDAP-Authentikator zu verwenden, müssen Sie die JupyterHub-Konfigurationsdatei um die LDAP-Verbindungsdetails aktualisieren.
Verwenden Sie Ambari für die LDAP-Authentifizierung in Clustern von Big Data Service 3.0.27 oder höher.
Einzelheiten zum LDAP-Authentikator finden Sie unter LDAP-Authentikator.
pConfigure SSO-Authentifizierung in Big Data Service 3.0.27 oder höher ODH 2.x JupyterHub-Service.
Mit der Oracle-Identitätsdomain können Sie SSO-Authentifizierung in ODH 2.x JupyterHub-Clustern in Big Data Service 3.0.27 oder höher einrichten.
Mit OKTA können Sie SSO-Authentifizierung in Big Data Service 3.0.27- oder höherem ODH 2.x JupyterHub-Cluster einrichten.
Als Administrator können Sie JupyterHub-Konfigurationen über Ambari für ODH 2.x-Cluster in Big Data Service 3.0.27 oder höher verwalten.
Notizbücher starten
Die folgenden Spawner-Konfigurationen werden in Big Data Service 3.0.27- und späteren ODH 2.x-Clustern unterstützt.
Geben Sie folgende Werte an:
- Native Authentifizierung:
- Melden Sie sich mit den Zugangsdaten des angemeldeten Benutzers an.
- Benutzername eingeben.
- Kennwort eingeben.
- Verwenden Sie SamlSSOAuthenticator:
- Melden Sie sich mit SSO an.
- Schließen Sie die Anmeldung mit der konfigurierten SSO-Anwendung ab.
Notebooks in einem HA-Cluster starten
Für AD-integriertes Cluster:
- Melden Sie sich mit einer der oben genannten Methoden an. Die Autorisierung funktioniert nur, wenn der Benutzer auf dem Linux-Host vorhanden ist. JupyterHub sucht den Benutzer auf dem Linux-Host, während versucht wird, den Notizbuchserver zu starten.
- Sie werden umgeleitet auf eine Seite mit Serveroptionen, auf der Sie ein Kerberos-Ticket anfordern müssen. Dieses Ticket kann entweder mit dem Kerberos-Principal und der Keytab-Datei oder mit dem Kerberos-Kennwort angefordert werden. Der Clusteradministrator kann den Kerberos- Principal und die Keytab-Datei oder das Kerberosos-Kennwort angeben. Sie benötigen das Kerberos-Ticket, um Zugriff auf die HDFS-Verzeichnis und anderen Big-Data-Services zu erhalten, die Sie verwenden möchten.
Notizbücher in einem Nicht-HA-Cluster starten
Für AD-integriertes Cluster:
Melden Sie sich mit einer der oben genannten Methoden an. Die Autorisierung funktioniert nur, wenn der Benutzer auf dem Linux-Host vorhanden ist. JupyterHub sucht den Benutzer auf dem Linux-Host, während versucht wird, den Notizbuchserver zu starten.
- Konfigurieren Sie SSH-Schlüssel/Zugriffstoken für den Big Data Service-Clusterknoten.
- Wählen Sie den Notizbuchpersistenzmodus als Git aus.
Gehen Sie folgendermaßen vor, um die Git-Verbindung für JupyterHub einzurichten:
- Zugriffstoken für den Big Data Service-Clusterknoten.
- Notizbuchpersistenzmodus als Git auswählen
SSH-Schlüsselpaar generieren
Zugriffstoken verwenden
Sie können Zugriffstoken wie folgt verwenden:
- GitHub:
- Melden Sie sich bei Ihrem GitHub-Account an.
- Navigieren Sie zu Einstellungen > Entwicklereinstellungen > Persönliche Zugriffstoken.
- Generieren Sie ein neues Zugriffstoken mit den entsprechenden Berechtigungen.
- Verwenden Sie das Zugriffstoken als Kennwort, wenn Sie zur Authentifizierung aufgefordert werden.
- GitLab:
- Melden Sie sich bei Ihrem GitHub-Account an.
- Navigieren Sie zu Einstellungen > Zugriffstoken.
- Generieren Sie ein neues Zugriffstoken mit den entsprechenden Berechtigungen.
- Verwenden Sie das Zugriffstoken als Kennwort, wenn Sie zur Authentifizierung aufgefordert werden.
- BitBucket:
- Melden Sie sich bei Ihrem BitBucket-Account an.
- Navigieren Sie zu Einstellungen > App-Kennwörter.
- Generieren Sie ein neues App-Kennworttoken mit den entsprechenden Berechtigungen.
- Verwenden Sie das neue App-Passwort als Passwort, wenn Sie zur Authentifizierung aufgefordert werden.
Persistenzmodus als Git auswählen
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste unter Services die Option JupyterHub aus.
- Wählen Sie Konfigurationen, Einstellungen aus.
- Suchen Sie nach dem Notizbuchpersistenzmodus, und wählen Sie in der Dropdown-Liste die Option Git aus.
- Wählen Sie Aktionen, Alle neu starten aus.
- Öffnen Sie Apache Ambari.
- Wählen Sie in der seitlichen Symbolleiste unter Services die Option JupyterHub aus.
- Wählen Sie Konfigurationen, Einstellungen aus.
- Suchen Sie nach dem Notizbuchpersistenzmodus, und wählen Sie in der Dropdown-Liste die Option HDFS aus.
- Wählen Sie Aktionen, Alle neu starten aus.
Als Admin-Benutzer können Sie die einzelnen Benutzernotizbücher in Object Storage statt in HDFS speichern. Wenn Sie den Content Manager von HDFS in Objektspeicher ändern, werden die vorhandenen Notizbücher nicht in Objektspeicher kopiert. Die neuen Notizbücher werden in Object Storage gespeichert.
Oracle Object Storage-Bucket mit rclone und Benutzer-Principal-Authentifizierung mounten
Sie können Oracle Object Storage mit rclone mit der Benutzer-Principal-Authentifizierung (API-Schlüssel) auf einem Big Data-Serviceclusterknoten mit rclone und fuse3 mounten, die auf JupyterHub-Benutzer zugeschnitten sind.
Conda-Umgebungen in JupyterHub verwalten
Sie können Conda-Umgebungen in ODH 2.x-Clustern von Big Data Service 3.0.28 oder höher verwalten.
- Erstellen Sie eine Conda-Umgebung mit bestimmten Abhängigkeiten, und erstellen Sie vier Kernel (Python/PySpark/Spark/SparkR), die auf die erstellte Conda-Umgebung verweisen.
- Conda-Umgebungen und Kernel, die mit diesem Vorgang erstellt wurden, sind für alle Notizbuchserverbenutzer verfügbar.
- Beim separaten Vorgang "Conda-Umgebung erstellen" wird der Vorgang mit einem Neustart des Service entkoppelt.
- JupyterHub wird über die Ambari-UI installiert.
- Prüfen Sie den Internetzugriff auf das Cluster, um Abhängigkeiten während der Conda-Erstellung herunterzuladen.
- Conda-Umgebungen und Kernel, die mit diesem Vorgang erstellt wurden, sind für alle Benutzer des Notizbuchservers verfügbar."
- Angeben:
- Zusätzliche Conda-Konfigurationen zur Vermeidung von Conda-Erstellungsfehlern. Weitere Informationen finden Sie unter conda create.
- Abhängigkeiten im Standardanforderungsformat
.txt. - Ein Conda-Umgebungsname, der nicht vorhanden ist.
- Löschen Sie Conda-Umgebungen oder Kernel manuell.
Dieser Vorgang erstellt eine Conda-Umgebung mit angegebenen Abhängigkeiten und erstellt den angegebenen Kernel (Python/PySpark/Spark/SparkR), der auf die erstellte Conda-Umgebung verweist.
- Wenn die angegebene Conda-Umgebung bereits vorhanden ist, wird der Vorgang direkt mit dem Kernel-Erstellungsschritt fortgesetzt
- Conda-Umgebungen oder Kernel, die mit diesem Vorgang erstellt wurden, sind nur für einen bestimmten Benutzer verfügbar
- Führen Sie das python-Skript
kernel_install_script.pymanuell im sudo-Modus aus:'/var/lib/ambari-server/resources/mpacks/odh-ambari-mpack-2.0.8/stacks/ODH/1.1.12/services/JUPYTER/package/scripts/'Beispiel:
sudo python kernel_install_script.py --conda_env_name conda_jupy_env_1 --conda_additional_configs '--override-channels --no-default-packages --no-pin -c pytorch' --custom_requirements_txt_file_path ./req.txt --kernel_type spark --kernel_name spark_jupyterhub_1 --user jupyterhub
Voraussetzungen
- Prüfen Sie den Internetzugriff auf das Cluster, um Abhängigkeiten während der Conda-Erstellung herunterzuladen. Andernfalls verläuft die Erstellung nicht erfolgreich.
- Wenn ein Kernel mit dem Namen
--kernel_namevorhanden ist, wird eine Ausnahme ausgelöst. - Gehen Sie wie folgt vor:
- Conda-Konfigurationen zur Vermeidung von Erstellungsfehlern. Weitere Informationen finden Sie unter https://conda.io/projects/conda/en/latest/commands/create.html.
- Abhängigkeiten, die im Standardanforderungsformat
.txtangegeben werden.
- Löschen Sie Conda-Umgebungen oder Kernel manuell für jeden Benutzer.
Verfügbare Konfigurationen für Anpassung
-
--user(obligatorisch): BS- und JupyterHub-Benutzer, für den Kernel- und Conda-Umgebungen erstellt werden. -
--conda_env_name(obligatorisch): Geben Sie bei jeder Erstellung einer neuen En für--usereinen eindeutigen Namen für die Conda-Umgebung an. -
--kernel_name: (Pflichtfeld) Geben Sie einen eindeutigen Kernel-Namen an. -
--kernel_type: (obligatorisch) Muss einer der folgenden Werte sein (python / PysPark / Spark / SparkR) -
--custom_requirements_txt_file_path: (optional) Wenn Python/R/Ruby/Lua/Scala/Java/JavaScript/C/C++/FORTRAN usw. Abhängigkeiten über Conda-Kanäle installiert werden, müssen Sie diese Librarys in einer Anforderungsdatei.txtangeben und den vollständigen Pfad angeben.Weitere Informationen zu einem Standardformat zum Definieren der Anforderungsdatei
.txtfinden Sie unter https://pip.pypa.io/en/stable/reference/requirements-file-format/. -
--conda_additional_configs: (optional)- Dieses Feld enthält zusätzliche Parameter, die an den Standardbefehl zur Conda-Erstellung angehängt werden können.
- Der Standardbefehl zum Erstellen von Conda-Umgebungen lautet:
'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8'. - Wenn
--conda_additional_configsals'--override-channels --no-default-packages --no-pin -c pytorch'angegeben wird, lautet der letzte Conda-Erstellungsbefehl'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8 --override-channels --no-default-packages --no-pin -c pytorch'.
Benutzerspezifische Conda-Umgebung einrichten
Load Balancer und Backend-Set erstellen
Weitere Informationen zum Erstellen von Backend-Sets finden Sie unter Backend-Set für Load Balancer erstellen.
Weitere Informationen zum Erstellen eines öffentlichen Load Balancers finden Sie unter Load Balancer erstellen. Geben Sie die folgenden Details ein.
Weitere Informationen zum Erstellen eines öffentlichen Load Balancers finden Sie unter Load Balancer erstellen. Geben Sie die folgenden Details ein.
- Öffnen Sie das Navigationsmenü, und wählen Sie Networking aus. Wählen Sie dann Load Balancer. Wählen Sie Load Balancer aus. Die Seite Load Balancer wird angezeigt.
- Wählen Sie das Compartment in der Liste aus. Alle Load Balancer in diesem Compartment werden tabellarisch aufgelistet.
- Wählen Sie den Load Balancer, dem Sie ein Backend hinzufügen möchten. Die Detailseite des Load Balancers wird angezeigt.
- Wählen Sie Backend-Sets aus, und wählen Sie dann das Backend-Set aus, das Sie unter Load Balancer erstellen erstellt haben.
- Wählen Sie IP-Adressen aus, und geben Sie die erforderliche private IP-Adresse des Clusters ein.
- Geben Sie 8000 für den Port ein.
- Wählen Sie Hinzufügen aus.
Weitere Informationen zum Erstellen eines öffentlichen Load Balancers finden Sie unter Load Balancer erstellen. Geben Sie die folgenden Details ein.
-
Öffnen Sie einen Browser, und geben Sie
https://<loadbalancer ip>:8000ein. - Wählen Sie das Compartment in der Liste aus. Alle Load Balancer in diesem Compartment werden tabellarisch aufgelistet.
- Stellen Sie sicher, dass er zu einem der JupyterHub-Server umgeleitet wird. Um zu prüfen, öffnen Sie eine Terminalsession in der JupyterHub, um zu ermitteln, welcher Knoten erreicht wurde.
- Nach dem Hinzufügen des Knotenvorgangs muss der Clusteradministrator den Load Balancer-Hosteintrag in den neu hinzugefügten Knoten manuell aktualisieren. Gilt für alle Knoten, die dem Cluster hinzugefügt werden. Beispiel: Worker-Knoten, nur Computing und Knoten.
- Im Falle eines Ablaufs muss das Zertifikat manuell auf Load Balancer aktualisiert werden. Dieser Schritt stellt sicher, dass der Load Balancer keine veralteten Zertifikate verwendet, und vermeidet Health Check-/Kommunikationsfehler bei Backend-Sets. Weitere Informationen finden Sie unter Ablaufendes Load-Balancer-Zertifikat aktualisieren, um abgelaufenes Zertifikat zu aktualisieren.
Trino-SQL-Kerne starten
Der JupyterHub PyTrino-Kernel bietet eine SQL-Schnittstelle, mit der Sie Trino-Abfragen mit JupyterHub SQL ausführen können. Diese Option ist für Big Data Service 3.0.28 oder höher ODH 2.x-Cluster verfügbar.
Weitere Informationen zu den SqlMagic-Parametern finden Sie unter https://jupysql.ploomber.io/en/latest/api/configuration.html#changing-configuration.