Erste Schritte mit Oracle Cloud Infrastructure Data Flow
Dieses Tutorial bietet Ihnen eine Einführung in Oracle Cloud Infrastructure Data Flow. Dabei handelt es sich um einen Service, mit dem Sie jede Apache Spark-Anwendung in beliebigem Umfang ohne bereitzustellende oder zu verwaltende Infrastruktur ausführen können.
Wenn Sie Spark bereits verwendet haben, werden Sie mehr aus diesem Tutorial herausholen. Allerdings sind keine Vorkenntnisse zu Spark erforderlich. Alle Spark-Anwendungen und -Daten wurden für Sie bereitgestellt. In diesem Tutorial wird gezeigt, wie Spark-Anwendungen mit Data Flow ganz einfach, wiederholt und sicher ausgeführt und problemlos im gesamten Unternehmen gemeinsam genutzt werden können.
- Wie Sie Java für die Ausführung von ETL in einer Data Flow Anwendung verwenden.
- Wie Sie SparkSQL in einer SQL-Anwendung verwenden.
- Wie Sie eine Python-Anwendung erstellen und ausführen, um eine einfache Aufgabe für maschinelles Lernen auszuführen.
Sie können dieses Tutorial auch mit spark-submit über CLI oder mit spark-submit und Java-SDK ausführen.
- Der Service ist serverlos, d.h. Sie benötigen für das Provisioning, Patching, Upgrade oder die Wartung von Spark-Cluster keine Experten. Sie können sich also ausschließlich auf Ihren Spark-Code konzentrieren.
- Die Vorgänge und Optimierungen sind unkompliziert. Der Zugriff auf die Spark-UI ist ein Select-away und unterliegt den IAM-Autorisierungs-Policys. Wenn ein Benutzer meldet, dass ein Job zu viel Zeit in Anspruch nimmt, kann jede Person mit Zugriffsberechtigung für die Ausführung die Spark-UI öffnen und der Ursache auf den Grund gehen. Der Zugriff auf den Spark-Historienserver ist ebenso einfach für bereits ausgeführte Jobs.
- Data Flow eignet sich hervorragend für die Batchverarbeitung. Die Anwendungsausgabe wird automatisch erfasst und über REST-APIs zur Verfügung gestellt. Müssen Sie einen vierstündigen Spark-SQL-Job ausführen und die Ergebnisse in das Pipeline-Managementsystem laden? In Data Flow ist dies mit nur zwei REST-APIs möglich.
- Data Flow bietet konsolidierte Steuerung. Mit Data Flow erhalten Sie eine konsolidierte Ansicht aller Spark-Anwendungen mit Informationen darüber, wer sie ausführt und wie viel Speicherplatz sie in Anspruch nehmen. Möchten Sie wissen, welche Anwendungen die meisten Daten schreiben und von wem sie ausgeführt werden? Sortieren Sie einfach nach der Spalte "Geschriebene Daten". Nimmt die Ausführung eines Jobs zu viel Zeit in Anspruch? Jeder Benutzer mit den entsprechenden IAM-Berechtigungen kann den Job anzeigen und stoppen.

Bevor Sie beginnen
Für eine gelungene Ausführung dieses Tutorials müssen Sie Ihren Mandanten einrichten haben und können auf Data Flow zugreifen.
Vor der Ausführung von Data Flow müssen Sie Berechtigungen erteilen, die ein effektives Logerfassungs- und Ausführungsmanagement ermöglichen. Weitere Informationen finden Sie im Abschnitt Administration einrichten der Dokumentation zum Data Flow-Service, und befolgen Sie die dort angegebenen Anweisungen.
- Wählen Sie in der Konsole das Navigationsmenü aus, um die Liste der verfügbaren Services anzuzeigen.
- Wählen Sie Analysen und KI aus.
- Wählen Sie unter "Big Data" die Option Data Flow aus.
- Wählen Sie Anwendungen aus.
1. ETL mit Java
Eine Übung zum Erstellen einer Java-Anwendung in Data Flow
Die hier beschriebenen Schritte beziehen sich für die Verwendung der Konsolenkonsole-UI. Sie können diese Übung mit spark-submit über CLI oder spark-submit mit Java-SDK abschließen.
Der häufigste erste Schritt in Datenverarbeitungsanwendungen besteht darin, Daten aus einer Quelle in ein Format umzuwandeln, das für das Reporting und andere Arten der Analyse geeignet ist. In einer Datenbank werden eine Flat File in die Datenbank geladen und Indizes erstellt. In Spark besteht der erste Schritt darin, Daten zu reinigen und aus einem Textformat in das Parquet-Format zu konvertieren. Parquet ist ein optimiertes Binärformat, das effiziente Lesezugriffe unterstützt und sich somit ideal für Reporting und Analysen eignet. In dieser Übung konvertieren Sie die Quelldaten in das Parquet-Format und führen dann einige interessante Vorgänge damit durch. Das Dataset ist das Dataset Berlin Airbnb Data, das von der Kaggle-Website heruntergeladen wurde, gemäß den Bedingungen der Lizenz Creative Commons CC0 1.0 Universal (CC0 1.0) "Public Domain Dedication".

Die Daten werden im CSV-Format bereitgestellt, und der erste Schritt besteht darin, diese Daten in das Parquet-Format zu konvertieren und zur weiteren Verarbeitung im Objektspeicher zu speichern. Eine Spark-Anwendung mit dem Namen oow-lab-2019-java-etl-1.0-SNAPSHOT.jar wird zur Konvertierung bereitgestellt. Das Ziel ist es, eine Datenflussanwendung zu erstellen, die diese Spark-Anwendung ausgeführt wird, und sie mit den richtigen Parametern auszuführen. Da Sie sich zum ersten Mal mit der Arbeit vertraut machen, werden Sie in dieser Übung Schritt für Schritt geführt, und es werden die erforderlichen Parameter bereitgestellt. Später müssen Sie die Parameter selbst angeben. Daher müssen Sie wissen, was Sie eingeben und warum.
Erstellen Sie eine Data Flow-Java-Anwendung über die Konsole oder mit Spark-Submit über die Befehlszeile oder mit SDK.
Erstellen Sie eine Java-Anwendung in Data Flow in der Konsole.
Datenflussanwendung erstellen.
- Navigieren Sie in der Konsole zum Data Flow-Service, indem Sie das Hamburger-Menü oben links einblenden und zum Ende scrollen.
- Markieren Sie Datenfluss, und wählen Sie "Anwendungen" aus. Wählen Sie ein Compartment aus, in dem die Data Flow-Anwendungen erstellt werden sollen. Wählen Sie schließlich Anwendung erstellen aus.

- Wählen Sie Java-Anwendung aus, und Geben Sie einen Namen für den Anwendungsbereich ein, beispielsweise
Tutorial Example 1.
- Scrollen Sie nach unten zu Ressourcenkonfiguration. Behalten Sie für alle diese Werte die jeweiligen Standardwerte bei.
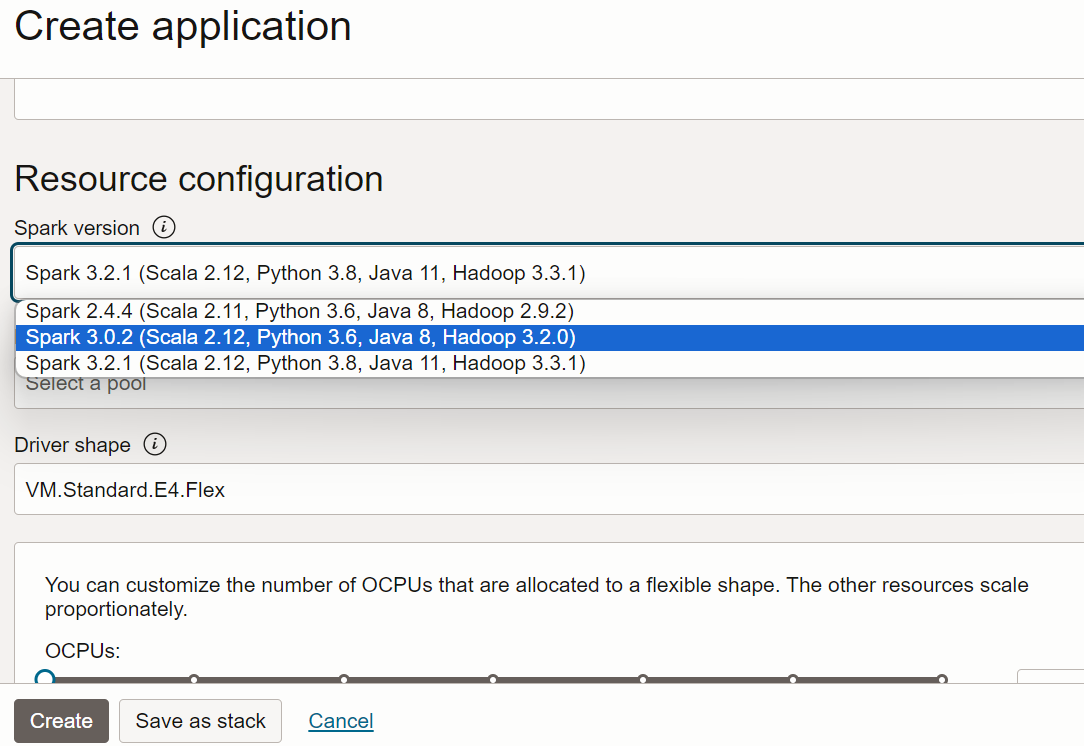
- Scrollen Sie nach unten zur Anwendungskonfiguration. Konfigurieren Sie die Anwendung wie folgt:
-
URL der Datei: Dies ist der Speicherort der JAR-Datei in Object Storage. Der Speicherort für diese Anwendung lautet:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar -
Name der Hauptklasse: Java-Anwendungen benötigen einen Namen der Hauptklasse, der von der Anwendung abhängig ist. Geben Sie für diese Übung Folgendes ein:
convert.Convert -
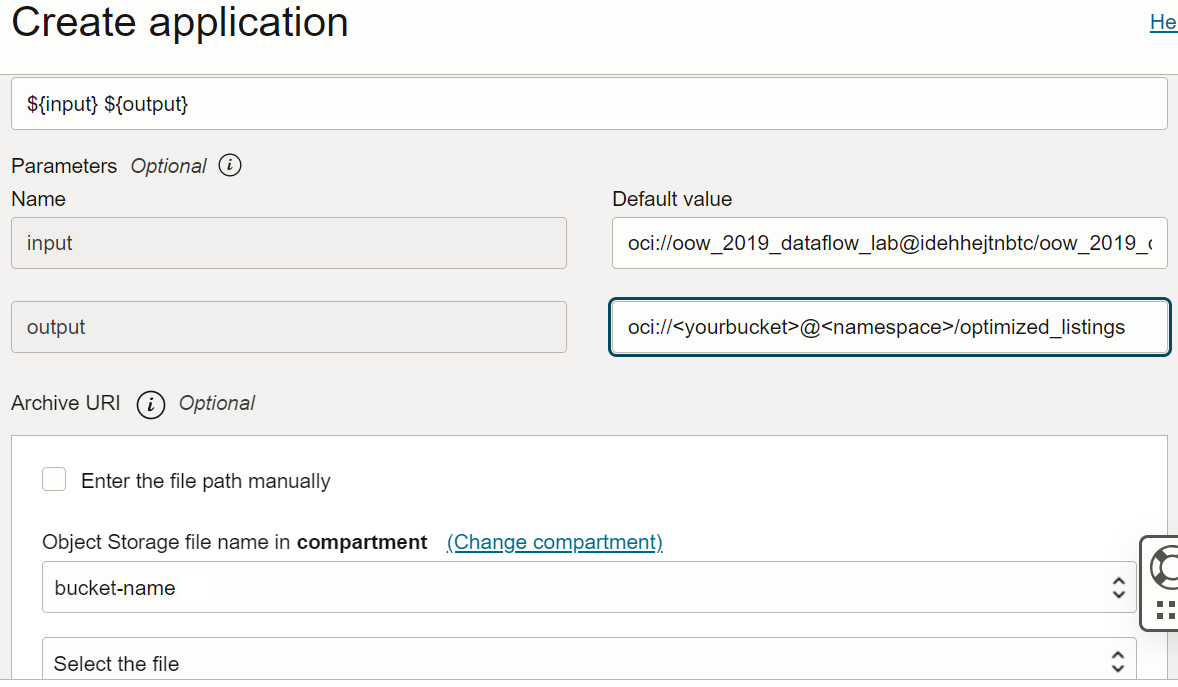
Argumente: Die Spark-Anwendung erwartet zwei Befehlszeilenparameter, einen für die Eingabe und einen für die Ausgabe. Geben Sie im Feld Argumente Folgendes ein: Sie werden zur Eingabe von Standardwerten aufgefordert, und Sie sollten diese jetzt eingeben.
${input} ${output}

-
URL der Datei: Dies ist der Speicherort der JAR-Datei in Object Storage. Der Speicherort für diese Anwendung lautet:
- Die Eingabe- und Ausgabeargumente lauten:
-
Eingabe:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv -
Ausgabe:
oci://<yourbucket>@<namespace>/optimized_listings
Prüfen Sie die Anwendungskonfiguration, um zu bestätigen, dass sie etwa wie folgt aussieht:
 Hinweis
Hinweis
Sie müssen den Ausgabepfad anpassen, damit er auf einen Bucket im Mandanten verweist. -
Eingabe:
- Wählen Sie anschließend Erstellen aus. Nachdem die Anwendung erstellt wurde, wird sie in der Anwendungsliste angezeigt.

Herzlichen Glückwunsch. Sie haben Ihre erste Data Flow-Anwendung erstellt. Jetzt können Sie sie ausführen.
Erstellen Sie eine Java-Anwendung mit spark-submit und CLI.
Schließen Sie die Übung ab, um eine Java-Anwendung in Data Flow mit Funkenübermittlung und Java-SDK zu erstellen.
Mit diesen Dateien können Sie diese Übung ausführen. Sie sind in den folgenden öffentlichen Object Storage-URIs verfügbar:
- Eingabedateien im CSV-Format:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - JAR-Datei:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Nachdem die Java-Anwendung erstellt wurde, kann sie nun ausgeführt werden.
- Wenn Sie die Schritte genau ausgeführt haben, müssen Sie nur die Anwendung in der Liste markieren, das Menü "Aktionen" auswählen und Ausführen auswählen.
- Sie haben die Möglichkeit, Parameter vor dem Ausführen der Anwendung anzupassen. Im vorliegenden Fall haben Sie die genauen Werte bereits eingegeben. Sie können die Ausführung dann starten, indem Sie auf Ausführen klicken.

-
Während die Anwendung ausgeführt wird, können Sie optional die Spark-UI laden, um den Fortschritt zu überwachen. Wählen Sie im Menü "Aktionen" für die betreffende Ausführung Spark-UI aus.

- Sie werden automatisch zur Apache Spark-UI umgeleitet. Dies ist nützlich für das Debugging und die Performanceoptimierung.

-
Nach etwa einer Minute wird bei der Ausführung der erfolgreiche Abschluss mit dem Status
Succeededangezeigt:
-
Führen Sie einen Drilldown in die Ausführung durch, um weitere Details anzuzeigen, und scrollen Sie nach unten, um eine Liste der Logs anzuzeigen.

-
Wenn Sie die Datei spark_application_stdout.log.gz auswählen, wird die Logausgabe
Conversion was successfulangezeigt:
- Sie können auch zum Object Storage-Ausgabe-Bucket navigieren, um zu bestätigen, dass neue Dateien erstellt wurden.

Diese neuen Dateien werden von späteren Anwendungen verwendet. Stellen Sie sicher, dass sie in Ihrem Bucket angezeigt werden, bevor Sie mit den nächsten Übungen fortfahren.
2. SparkSQL leicht gemacht
In dieser Übung führen Sie ein SQL-Skript aus, um ein einfaches Profiling eines Datasets durchzuführen.
In dieser Übung wird die in 1. ETL mit Java generierte Ausgabe verwendet. Sie müssen den Vorgang erfolgreich abgeschlossen haben, bevor Sie ihn versuchen können.
Die hier beschriebenen Schritte beziehen sich für die Verwendung der Konsolenkonsole-UI. Sie können diese Übung mit spark-submit über CLI oder spark-submit mit Java-SDK abschließen.
Wie auch bei anderen Datenflussanwendungen werden SQL-Dateien in Object Storage gespeichert und können von vielen SQL-Benutzern gemeinsam verwendet werden. Um dies zu erleichtern, können Sie mit Data Flow SQL-Skripte parametrisieren und zur Laufzeit anpassen. Wie auch bei anderen Anwendungen können Sie Standardwerte für Parameter angeben, die häufig als wertvoller Hinweis für Personen dienen, die diese Skripte ausführen.
Das SQL-Skript kann direkt in der Datenflussanwendung verwendet werden. Sie müssen keine Kopie des Skripts erstellen. Das Skript wird hier reproduziert, um einige Punkte zu veranschaulichen.
Referenztext des SparkSQL-Skripts: 
- Das Skript beginnt, indem die erforderlichen SQL-Tabellen erstellt werden. Aktuell verfügt Data Flow über keinen persistenten SQL-Katalog, sodass alle Skripte mit der Definition der erforderlichen Tabellen beginnen müssen.
- Der Speicherort der Tabelle wird als
${location}festgelegt. Diesen Parameter muss der Benutzer zur Laufzeit angeben. Dies gibt Data Flow die Flexibilität, mit nur einem Skript viele verschiedene Speicherorte zu verwenden und Code für verschiedene Benutzer zu verwenden. Für diese Übung müssen wir${location}anpassen, damit auf den in Übung 1 verwendeten Ausgabespeicherort verwiesen wird. - Dadurch wird die Ausgabe des SQL-Skriptes erfasst und uns unter der Ausführung verfügbar gemacht.
- Erstellen Sie in Data Flow eine SQL-Anwendung, wählen Sie den Typ "SQL" aus, und übernehmen Sie die Standardressourcen.
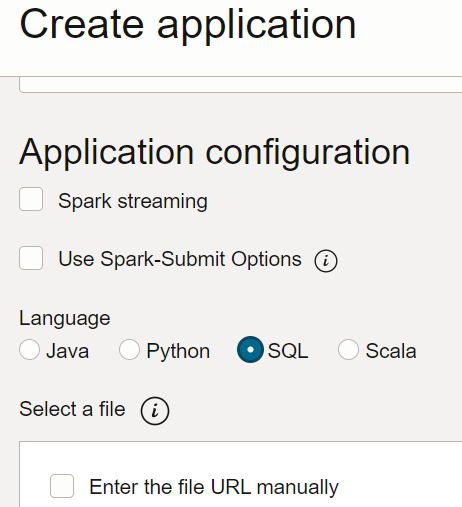
- Konfigurieren Sie die SQL-Anwendung unter "Anwendungskonfiguration" wie folgt:
-
URL der Datei: Dies ist der Speicherort der SQL-Datei in Object Storage. Der Speicherort für diese Anwendung lautet:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql -
Argumente: Das SQL-Skript erwartet einen Parameter, den Speicherort der Ausgabe aus dem vorherigen Schritt. Wählen Sie Parameter hinzufügen aus, und geben Sie einen Parameter namens
locationmit dem Wert ein, den Sie als Ausgabepfad in Schritt a basierend auf der Vorlage verwendet haben.oci://[bucket]@[namespace]/optimized_listings
Wenn Sie fertig sind, stellen Sie sicher, dass die Anwendungskonfiguration etwa wie folgt aussieht:

-
URL der Datei: Dies ist der Speicherort der SQL-Datei in Object Storage. Der Speicherort für diese Anwendung lautet:
- Ändern Sie den Speicherortwert in einen gültigen Pfad in Ihrem Mandanten.
- Speichern Sie die Anwendung, und führen Sie sie über die Anwendungsliste aus.
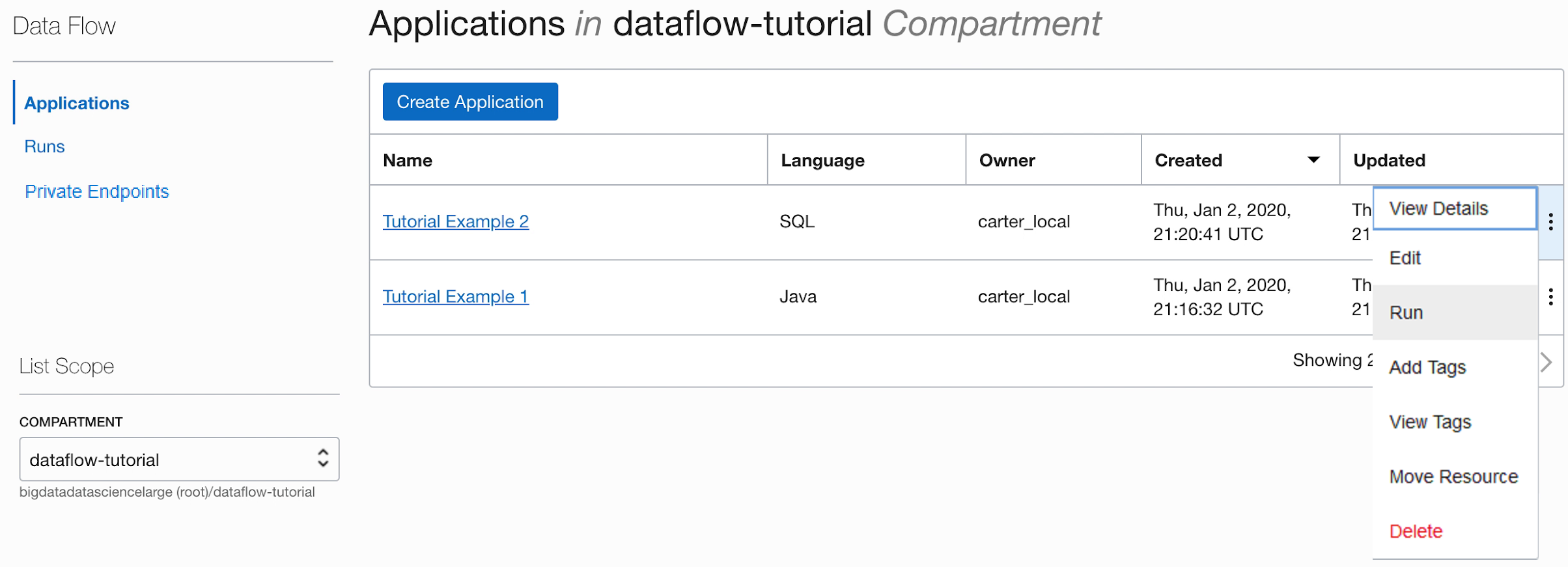
- Wenn die Ausführung abgeschlossen ist, öffnen Sie sie:

- Navigieren Sie zu den Ausführungslogs:

- Öffnen Sie spark_application_stdout.log.gz, und bestätigen Sie, dass die Ausgabe der folgenden Ausgabe entspricht. Hinweis
Die Reihenfolge Ihrer Zeilen kann sich von der im Bild unterscheiden, aber die Werte sollten übereinstimmen.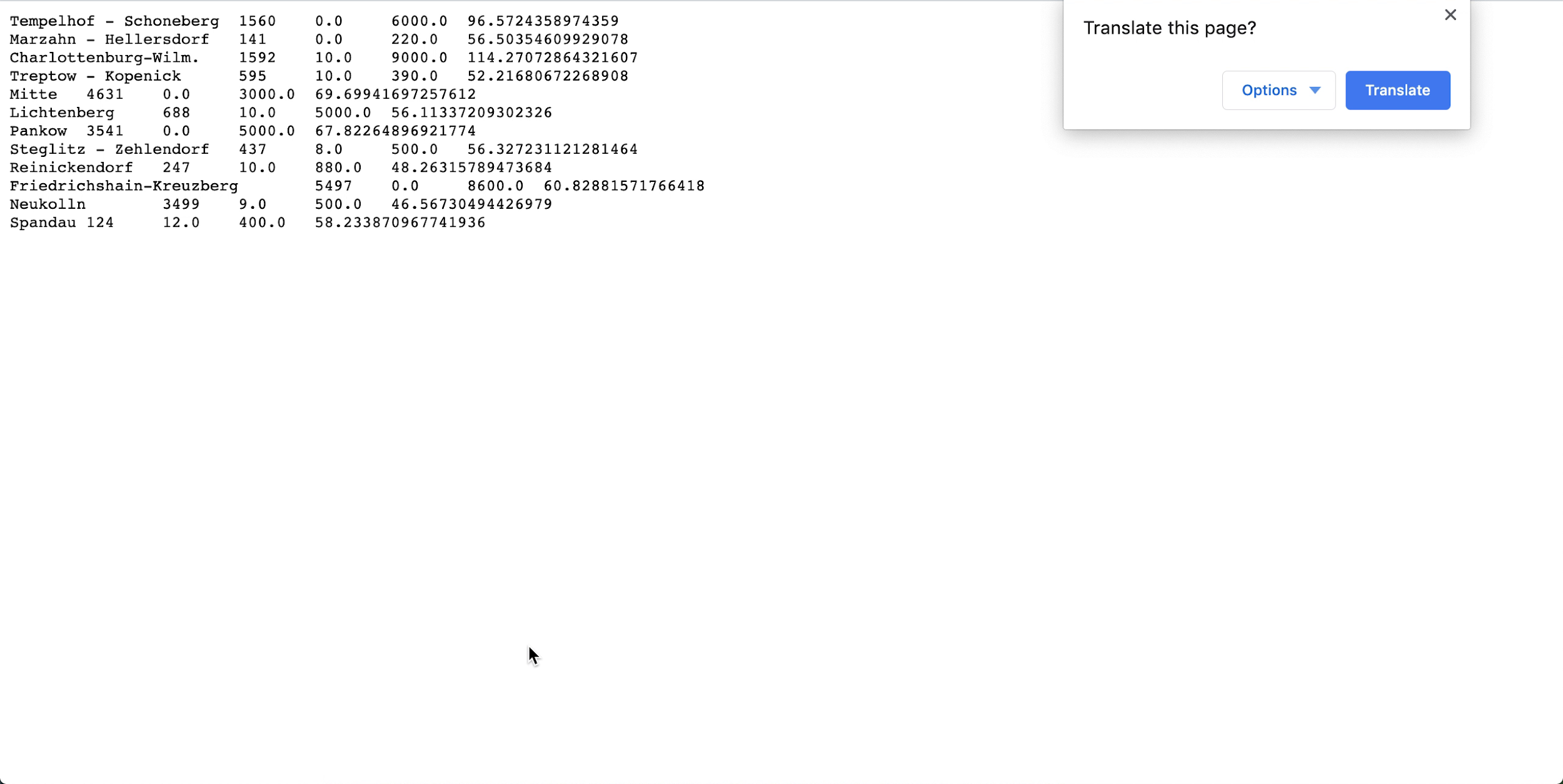
- Anhand Ihres SQL-Profilings können Sie schlussfolgern, dass in diesem Dataset Neukolln mit $ 46,57 den niedrigsten durchschnittlichen Listenpreis hat, während Charlottenburg-Wilmersdorf den höchsten Durchschnittswert mit $ 114,27 aufweist. (Hinweis: Das Quell-Dataset enthält Preise in USD und nicht in EUR.)
In dieser Übung wurden einige wichtige Aspekte von Data Flow gezeigt. Wenn eine SQL-Anwendung eingerichtet ist, kann sie problemlos von beliebigen Benutzern ausgeführt werden, ohne dass Clusterkapazität, Datenzugriff und -aufbewahrung, Zugangsdatenverwaltung oder andere Sicherheitsaspekte berücksichtigt werden müssen. Beispiel: Ein Business Analyst kann mit Data Flow ganz einfach Spark-basierte Berichte nutzen.
3. Maschinelles Lernen mit PySpark
Führen Sie mit PySpark eine einfache Aufgabe für maschinelles Lernen mit den Eingabedaten aus.
In dieser Übung wird die Ausgabe von 1. ETL mit Java für die Eingabedaten verwendet. Sie müssen die erste Übung erfolgreich abgeschlossen haben, bevor Sie mit dieser beginnen können. Diesmal ist es Ihr Ziel, die besten Tarife unter den verschiedenen Airbnb-Angeboten mit Spark-Algorithmen für maschinelles Lernen zu identifizieren.
Die hier beschriebenen Schritte beziehen sich für die Verwendung der Konsolenkonsole-UI. Sie können diese Übung mit spark-submit über CLI oder spark-submit mit Java-SDK abschließen.
Eine PySpark-Anwendung kann direkt in Ihren Datenflussanwendungen verwendet werden. Sie müssen keine Kopie erstellen.
Hier finden Sie einen Referenztext des PySpark-Skripts, um einige Punkte zu veranschaulichen: 
- Das Python-Skript erwartet ein Befehlszeilenargument (rot hervorgehoben). Wenn Sie die Datenflussanwendung erstellen, müssen Sie einen Parameter erstellen, den der Benutzer auf den Eingabepfad setzt.
- Das Skript verwendet die lineare Regression zur Vorhersage eines Preises pro Angebot und sucht die besten Angebote durch Subtrahieren des Listenpreises von der Vorhersage. Der negativste Wert gibt gemäß dem Modell den besten Wert an.
- Das Modell in diesem Skript ist vereinfacht und berücksichtigt nur die Größe in Quadratfuß. In einer echten Einstellung würden Sie mehr Variablen verwenden, wie die nähere Umgebung und andere wichtige Vorhersagevariablen.
Erstellen Sie eine PySpark-Anwendung in der Konsole oder mit spark-submit über die Befehlszeile oder mit SDK.
Erstellen Sie mit der Konsole eine PySpark-Anwendung in Data Flow.
-
Erstellen Sie eine Anwendung, und wählen Sie den Typ "Python" aus.
-
Überprüfen Sie die Anwendungskonfiguration, und bestätigen Sie, dass sie der folgenden ähnelt:

Erstellen Sie eine PySpark-Anwendung in Data Flow mit Spark-Submit und CLI.
Erstellen Sie eine PySpark-Anwendung in Data Flow mit Spark-Submit und SDK.
- Führen Sie die Anwendung von der Anwendungsliste aus.

-
Wenn die Ausführung abgeschlossen ist, öffnen Sie sie, und navigieren Sie zu den Logs.

- Öffnen Sie die Datei spark_application_stdout.log.gz. Die Ausgabe muss mit dem Folgenden identisch sein:

-
Aus dieser Ausgabe wird ersichtlich, dass das Angebot mit der ID 690578 den besten Tarif mit einem vorhergesagten Preis von $ 313,70 gegenüber dem Listenpreis von $ 35,00 mit der angegebenen Fläche von 4639 Quadratfuß aufweist. Wenn dieser Preis zu schön ist, um wahr zu sein, können Sie mithilfe der eindeutigen ID einen Drilldown in die Daten ausführen, um zu überprüfen, ob dies wirklich das Angebot des Jahrhunderts ist. Auch hier könnte ein professioneller Analyst die Ausgabe dieses Algorithmus für maschinelles Lernen ganz einfach dazu nutzen, seine Analyse weiter zu vertiefen.
Wie geht es weiter?
Jetzt können Sie Java-, Python- oder SQL-Anwendungen mit Data Flow erstellen und ausführen und die Ergebnisse explorieren.
Data Flow verarbeitet alle Details zu Deployment, Ausfall, Logmanagement, Sicherheit und UI-Zugriff. Mit Data Flow können Sie sich auf die Entwicklung von Spark-Anwendungen konzentrieren, ohne sich mit der Infrastruktur befassen zu müssen.