Service planen
Nehmen Sie sich etwas Zeit, um Ihren Oracle NoSQL Database Cloud Service-Service vor der Erstellung zu planen. Gehen Sie die hier aufgeführten Fragen durch, und entscheiden Sie vorab, was Sie erreichen möchten.
Dieser Artikel enthält die folgenden Themen:
Entwicklerüberblick
Verschaffen Sie sich einen allgemeinen Überblick über die Servicearchitektur und wählen Sie ein SDK/Treiber, das Ihren Anforderungen an die Anwendungsentwicklung entspricht.
NDCS-Entwickleraufgaben
Oracle NoSQL Database Cloud Service (NDCS) ist ein vollständig hochverfügbarer Service. Sie ist für anspruchsvolle Anwendungen konzipiert, die Reaktionszeiten mit geringer Latenz, ein flexibles Datenmodell und elastische Skalierung für dynamische Workloads erfordern. Als vollständig verwalteter Service übernimmt Oracle alle administrativen Aufgaben, wie Softwareupgrades, Sicherheitspatches, Hardwarefehler und Patching.
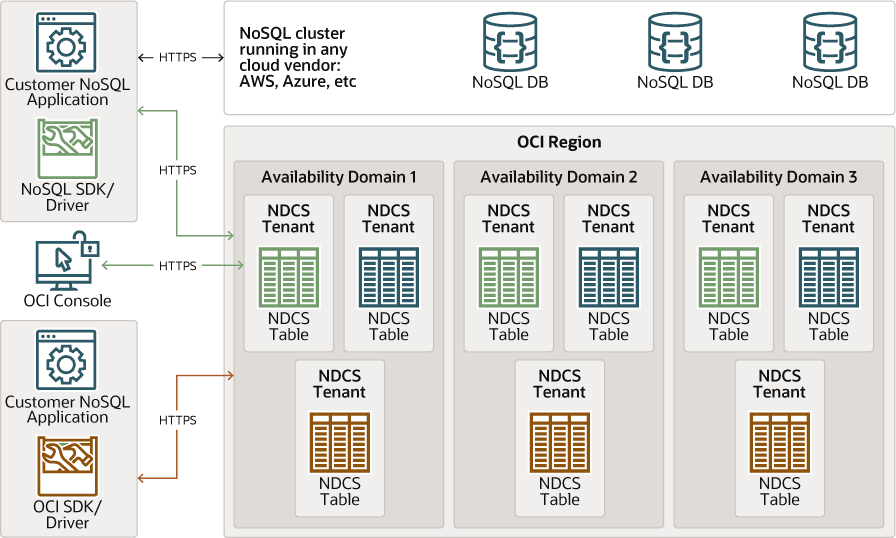
Beschreibung der Abbildung developer_overview.png
NoSQL Database-SDKs/Treiber - Diese SDKs sind unter der Universal Permissive License (UPL) lizenziert und können entweder in NoSQL Cloud Service oder in der On-Premise-Datenbank verwendet werden. Hierbei handelt es sich um SDKs mit vollem Funktionsumfang. Diese Treiber können auch in Anwendungen verwendet werden, die für Oracle NoSQL-Cluster ausgeführt werden, die in der Cloud anderer Anbieter ausgeführt werden.
Links zu den SDKs, API-Leitfäden und Beispielen finden Sie in der folgenden Tabelle:
-
SDK (GitHub) - Enthält Details zur Installation, Verbindung und den ersten Schritten mit dem SDK
-
API-Handbuch - Stellt die im SDK verfügbaren Packages, Klassen, Methoden und Schnittstellen bereit
-
Beispiele - Bietet Codebeispiele, die Sie ausprobieren können
OCI-Konsole - Bietet die Möglichkeit, Tabellen schnell zu erstellen, Tabellen zu ändern, Tabellen zu löschen, Daten zu laden, Indizes schnell zu erstellen, Indizes, grundlegende Abfragen zu löschen, Tabellenkapazitäten zu ändern und Metriken anzuzeigen.
OCI-SDKs/Treiber – Oracle Cloud Infrastructure stellt eine Reihe von Software Development Kits (SDKs) bereit, um die Entwicklung benutzerdefinierter Lösungen zu vereinfachen. Diese sind typischerweise unter UPL lizenziert.
Unterschied zwischen NoSQL-Datenbank-SDKs/Treibern und OCI-SDKs/Treibern:
OCI-SDKs sind REST-basiert. Sie sind einfach zu bedienen, haben aber nur eine begrenzte Funktionalität. Die NoSQL-Datenbank-SDKs bieten dagegen eine umfangreiche Funktionalität. Es wird empfohlen, NoSQL Database-SDKs zu verwenden, da sie die folgenden Vorteile gegenüber OCI-SDKs bieten.
-
NoSQL Database-SDKs können in Anwendungen verwendet werden, die eine Verbindung zum Cloud-Service, zu On-Premise-Datenspeichern und zum NoSQL Cloud-Simulator herstellen.
-
NoSQL-Datenbank-SDKs bieten eine viel umfassendere Entwicklungserfahrung. Sie unterstützen weitere SQL-Features, die nicht über REST unterstützt werden.
-
Sie können Implementierungen von Drittanbietern wie Jakarta NoSQL oder Eclipse TopLink mit NoSQL Database-SDKs verwenden.
Referenzen:
Oracle NoSQL Database Cloud Service-Limits
Für Oracle NoSQL Database Cloud Service gelten verschiedene Standardlimits. Wenn Sie eine Oracle NoSQL Database Cloud Service-Tabelle erstellen, stellt das System sicher, dass Ihre Anforderungen innerhalb der Begrenzungen des angegebenen Limits liegen. Einige Limits werden auf Tabellenebene festgelegt, andere auf Regionsebene.
Weitere Informationen zu Servicelimits, deren Umfang und wie Sie Ihre Servicelimits durch eine Anfrage erhöhen, finden Sie unter Servicelimits. Im Folgenden werden die aktuellen Limits aufgeführt, die für Oracle NoSQL Database Cloud Service gelten.
| Grenzwert | Scope | Beschreibung | Wert in einer nicht gehosteten Umgebung | Wert in einer gehosteten Umgebung |
|---|---|---|---|---|
| Maximale Tabellenspeichergröße | Tabelle | Maximale Gesamtspeichergröße pro Mandant. Der gesamte Speicherplatz für eine oder mehrere Tabellen darf diesen Wert nicht überschreiten. | 5 TB | 17.5TB |
| Tabellennamen | Tabelle | Maximale Anzahl der Zeichen, zulässigen Zeichen und Anfangszeichen für Tabellennamen. | Tabellennamen dürfen maximal 256 Zeichen umfassen. Alle Namen müssen mit einem Buchstaben (a-z, A-Z.) beginnen. Nachfolgende Zeichen können Buchstaben (A-z, A-Z), Ziffern (0-9) oder Unterstriche sein. | Wie bei einer nicht gehosteten Umgebung |
| Bereitgestellte Kapazität - Maximaler Lese- und Schreibdurchsatz | Tabelle | Maximaler Lese- und Schreibdurchsatz beim Provisioning einer Tabelle. | 40.000 Leseeinheiten und 20.000 Schreibeinheiten pro Tabelle. | Bis zu 420.000 Leseeinheiten und insgesamt 280.000 Schreibeinheiten für alle Tabellen in der gehosteten Umgebung |
| On-Demand-Kapazität - Maximaler Lese- und Schreibdurchsatz | Tabelle | Maximaler Lese- und Schreibdurchsatz bei Verwendung von On Demand Capacity für das Provisioning von Tabellen. | 10.000 Leseeinheiten und 5.000 Schreibeinheiten pro Tabelle. | In einer gehosteten Umgebung nicht zulässig/benötigt |
| On-Demand Kapazität - Anzahl der Tabellen | Bereich | Anzahl der Tabellen mit On Demand-Kapazität. | 3 | In einer gehosteten Umgebung nicht zulässig/benötigt |
| Provisioning-Modus ändern | Tabelle | Ändern Sie den Provisioning-Modus für die Tabelle von "Bereitgestellt" in "On Demand" oder umgekehrt. | Kann nur einmal pro Tag geändert werden. | N/V |
| Maximale Anzahl von Tabellen | Bereich | Die maximale Anzahl von Tabellen. | 30 | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale Spaltenanzahl. | Tabelle | Die maximale Anzahl von Spalten. | 50 | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale Anzahl von Tabellenschemaupdates | Tabelle | Die maximale Anzahl von Tabellenschemaupdates. | 100 | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale Anzahl von Indizes | Tabelle | Die maximale Anzahl der Indizes. | 5 | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale Anzahl der Änderungen von Durchsatz- und Speicherlimits | Tabelle | Die maximale Anzahl der Änderungen von Durchsatz- und Speicherlimits. | Oracle lässt Folgendes zu:
|
Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Indexnamen | Index | Die maximale Anzahl der Zeichen, zulässigen Zeichen und Anfangszeichen. | Indexnamen dürfen maximal 64 Zeichen umfassen. Alle Namen müssen mit einem Buchstaben (a-z, A-Z.) beginnen. Nachfolgende Zeichen können Buchstaben (A-z, A-Z), Ziffern (0-9) oder Unterstriche sein. | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
Maximale Anzahl der einzelnen Vorgänge pro WriteMultiple-Anforderung |
Anforderungs- | Die maximale Anzahl der einzelnen Vorgänge pro WriteMultiple-Anforderung. |
50 | Wie bei einer nicht gehosteten Umgebung. Dies kann auch mit dem Update "Servicelimits beantragen" erhöht werden |
Maximale Datengröße pro WriteMultiple-Anforderung. |
Anforderungs- | Die maximale Datengröße für WriteMultiple-Anforderung. |
25 MB | Wie bei einer nicht gehosteten Umgebung. Dies kann auch mit dem Update "Servicelimits beantragen" erhöht werden |
| Spaltennamen | Spalte | Die maximale Anzahl der Zeichen, zulässigen Zeichen und Anfangszeichen. | Feldnamen dürfen maximal 64 Zeichen umfassen. Alle Namen müssen mit einem Buchstaben (a-z, A-Z.) beginnen. Nachfolgende Zeichen können Buchstaben (A-z, A-Z), Ziffern (0-9) oder Unterstriche sein. | Wie bei einer nicht gehosteten Umgebung. |
| Maximale Sekundärindexschlüsselgröße | Index | Maximale Größe des Indexschlüssels. | 64 Byte | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale Größe für Primärindexschlüssel | Index | Maximale Größe des Primärschlüssels. | 64 Byte | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale Zeilengröße | Zeile | Maximale Zeilengröße. | 512 KB | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale Länge von Abfragezeichenfolgen. | Abfrage | Maximale Länge von Abfragezeichenfolgen. | 10 KB | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Maximale unterstützte Rate von DDL-Vorgängen. | Bereich | Maximale unterstützte Rate von DDL-Vorgängen. | 4 pro Minute | Dies kann mit der Aktualisierung der Servicelimits für Serviceanfragen angepasst werden |
| Höchstwerte für Durchsatz und Datenspeicherressourcen. | Bereich | Höchstwerte für Durchsatz und Datenspeicherressourcen. | Pro Region ermöglicht Oracle:
Oracle lässt eine maximale Speichergröße von 5 TB pro Mandant zu. Der Bereich kann über eine einzelne Tabelle mit 5 TB Speichergröße verfügen. In diesem Fall kann die Region keine weitere Tabelle erstellen. Sie können auch über mehrere Tabellen verfügen und sicherstellen, dass die Daten in allen Tabellen die maximale Speichergröße von 5 TB überschreiten. |
420.000 Schreibeinheiten, 280.000 Leseeinheiten, 17,5 TB Speicher |
Kapazität schätzen
Erfahren Sie, wie Sie Durchsatz- und Speicherkapazität für Oracle NoSQL Database Cloud Service schätzen.
Grundlagen für die Berechnung
Bevor Sie erfahren, wie Sie Durchsatz und Speicher für den Service schätzen, lassen Sie sich mit den Definitionen von Durchsatz und Speichereinheit vertraut machen.
-
Schreibeinheit (WU): Eine Schreibeinheit wird als Durchsatz von bis zu 1 Kilobyte (KB) pro Sekunde definiert. Ein Schreibvorgang ist jeder Oracle NoSQL Database Cloud Service-API-Aufruf, der zu einem Einfügen, Aktualisieren oder Löschen eines Datensatzes führt. Für eine NoSQL-Tabelle gilt ein Schreibgrenzwert, der die Anzahl der Schreibeinheiten angibt, die pro Sekunde verwendet werden können. Indexaktualisierungen konsumieren auch Schreibeinheiten.
Beispiel: Für eine Datensatzgröße von weniger als 1 KB ist eine Schreibeinheit für einen Schreibvorgang erforderlich. Für eine Datensatzgröße von 1,5 KB werden zwei Schreibeinheiten für den Schreibvorgang benötigt.
-
Leseeinheit (RU): Eine Leseeinheit wird als Durchsatz von bis zu 1 KB pro Sekunde für einen Lesevorgang mit Eventual Consistence definiert. Ihre NoSQL-Tabelle enthält einen Lesegrenzwert, der die Anzahl der Leseeinheiten angibt, die pro Sekunde verwendet werden können.
Beispiel: Eine Datensatzgröße von weniger als 1 KB erfordert eine Leseeinheit für einen Lesevorgang mit Eventual Consistency. Eine Datensatzgröße von 1,5 KB erfordert zwei Leseeinheiten für einen Lesevorgang mit Eventual Consistency und vier Leseeinheiten für einen Lesevorgang mit Absolute Consistency.
-
Speicherkapazität: Eine Speichereinheit ist ein einzelnes Gigabyte (GB) des Datenspeichers.
-
Absolute Consistency: Es wird erwartet, dass es sich bei den zurückgegebenen Daten um die zuletzt in die Datenbank geschriebenen Daten handelt.
-
Eventual Consistency: Die zurückgegebenen Daten sind möglicherweise nicht die zuletzt in die Datenbank geschriebenen Daten. Wenn keine neuen Aktualisierungen an den Daten vorgenommen werden, geben alle Zugriffe auf die betreffenden Daten den zuletzt aktualisierten Wert zurück.
Hinweis: Oracle NoSQL Database Cloud Service verwaltet die Lese- und Schreibkapazitäten automatisch, um die Anforderungen dynamischer Workloads bei Verwendung von On-Demand-Kapazität zu erfüllen. Es wird empfohlen, zu überprüfen, ob der Kapazitätsbedarf die On Demand-Kapazitätslimits nicht überschreitet. Weitere Informationen finden Sie unter Oracle NoSQL Database Cloud Service-Limits.
Faktoren mit Auswirkung auf die Kapazitätseinheit
Vor dem Bereitstellen der Kapazitätseinheiten sind die folgenden Faktoren zu berücksichtigen, die sich auf Lese-, Schreib- und Speicherkapazitäten auswirken.
-
Datensatzgröße: Mit zunehmende Datensatzgröße erhöht sich auch die Anzahl der Kapazitätseinheiten, die beim Schreiben oder Lesen der Daten konsumiert werden.
-
Datenkonsistenz: Absolute Consistenz-Lesezugriffe sind doppelt so teuer wie die von Lesezugriften mit Eventual Consistency.
-
Sekundäre Indizes: Wenn ein vorhandener Datensatz in einer Tabelle geändert (hinzugefügt, aktualisiert oder gelöscht) wird, konsumiert die Aktualisierung sekundärer Indizes Schreibeinheiten. Die Gesamtkosten des bereitgestellten Durchsatzes für einen Schreibvorgang entsprechen der Summe der Schreibeinheiten, die durch Schreibvorgänge in die Tabelle und Aktualisierungen der lokalen sekundären Indizes belegt werden.
-
Auswahl von Datenmodellierung: Bei schemalosem "JSON" enthält jedes Dokument einen Eigenbeschreibung, wodurch Metadaten-Overhead auf die Gesamtgröße des Datensatzes aufgesetzt wird. Bei festen Schematabellen beträgt der Overhead für jeden Datensatz genau 1 Byte.
-
Abfragemuster: Die Kosten eines Abfragevorgangs hängen von der Anzahl der abgerufenen Zeilen, der Anzahl der Prädikate, der Größe der Quelldaten, den Projektionen und dem Vorhandensein von Indizes. Die Abfragen, die mit geringstem Aufwand arbeiten, geben einen Shard-Schlüssel oder Indexschlüssel (mit einem zugehörigen Index) an, um dem System die Nutzung von primären und sekundären Indizes zu ermöglichen. Eine Anwendung kann anhand verschiedener Abfragen den konsumierten Durchsatz untersuchen, um die Vorgänge zu optimieren.
Beispiel aus der Praxis: So schätzen Sie Ihre Anwendungs-Workload
Im praktischen Beispiel einer E-Commerce-Anwendung erfahren Sie, wie Lese- und Schreibvorgänge pro Sekunde geschätzt werden. In diesem Beispiel werden die Produktkataloginformationen der Anwendung mit Oracle NoSQL Database Cloud Service gespeichert.
-
Identifizieren Sie das Datenmodell (JSON oder feste Tabelle), die Datensatzgröße und die Schlüsselgröße für die Anwendung.
Angenommen, die E-Commerce-Anwendung folgt dem JSON-Datenmodell, und der Entwickler hat eine einfache Tabelle mit zwei Spalten erstellt. Eine Datensatz-ID (Primärschlüssel) und ein JSON-Dokument für die Produktfeatures und -attribute. Das JSON-Dokument mit einer Größe unter 1 KB (0,8 KB) ist wie folgt:
{ "additionalFeatures": "Front Facing 1.3MP Camera", "os": "Macintosh OS X 10.7", "battery": { "type": "Lithium Ion (Li-Ion) (7000 mAH)", "standbytime" : "24 hours" }, "camera": { "features": ["Flash","Video"], "primary": "5.0 megapixels" }, "connectivity": { "bluetooth": "Bluetooth 2.1", "cell": "T-mobile HSPA+ @ 2100/1900/AWS/850 MHz", "gps": true, "infrared": false, "wifi": "802.11 b/g" }, "description": "Apple iBook is the best in class computer for your professional and personal work.", "display": { "screenResolution": "WVGA (1280 x 968)", "screenSize": "13.0 inches" }, "hardware": { "accelerometer": true, "audioJack": "3.5mm", "cpu": "Intel i7 2.5 GHz", "fmRadio": false, "physicalKeyboard": false, "usb": "USB 3.0" }, "id": "appleproduct_1", "images": ["img/apple-laptop.jpg"], "name": "Myshop.com : Apple iBook", "sizeAndWeight": { "dimensions": [ "300 mm (w)", "300 mm (h)", "12.4 mm (d)" ], "weight": "1250.0 grams" }, "storage": { "hdd": "750GB", "ram": "8GB" } }Angenommen, die Anwendung verfügt über 100.000 derartiger Datensätze, und der Primärschlüssel hat eine Größe von etwa 20 Byte. Nehmen wir außerdem an, dass Abfragen vorhanden sind, mit denen Datensätze mit dem sekundären Index gelesen werden. Beispiel: Sie können alle Datensätze mit einer Bildschirmgröße von 13 Zoll suchen. Daher wird ein Index im Feld
screenSizeerstellt.Die Informationen werden wie folgt zusammengefasst:
Tabellen Zeilen pro Tabelle Spalten pro Tabelle Schlüsselgröße (in Byte) Wertgröße in Byte (Summe aller Spalten) Indizes Indexschlüsselgröße in Byte 1 100000 2 20 1 KB 1 20 -
Identifizieren Sie die Liste der Vorgänge (im Allgemeinen CRUD-Vorgänge und Indexlesevorgänge) in der Tabelle sowie deren zu erwartende Rate (pro Sekunde).
Vorgang Anzahl von Vorgängen (pro Sekunde) Beispiel Datensätze erstellen. 3 Erstellen eines Produkts Datensätze anhand des Primärschlüssels lesen 200 Lesen von Produktdetails anhand der Produkt-ID Datensätze anhand des sekundären Index lesen 1 Abrufen aller Produkte mit einer Bildschirmgröße von 13 Zoll Datensatz aktualisieren oder einem Datensatz ein Attribut hinzufügen 5 Aktualisierung der Produktbeschreibung einer Kamera
Oder
Hinzufügen von Informationen zum Gewicht einer Kamera
Datensatz löschen. 5 Löschen eines vorhandenen Produkts -
Identifizieren Sie den Verbrauch von Lese- und Schreibvorgängen in KB.
Vorgang Annahmen (falls vorhanden) Formel Leseverbrauch (KB) Schreibverbrauch (KB) Notizen/Erläuterung Datensätze erstellen. Angenommen, die Datensätze werden ohne Ausführung von Bedingungsprüfungen (sofern vorhanden) erstellt. Record size (rounded to next KB) + 1 KB(index) * (number of indexes)0 1 KB + 1 KB (1 ) = 2 KB Die Datensatzgröße beträgt 1 KB (0,8 KB für die JSON-Spalte und 20 Byte für die Schlüsselspalte) und es gibt einen Index der Größe 1 KB.
Bei einem Erstellungsvorgang werden die Kosten für Leseeinheiten berechnet, wenn Sie die put-Befehle mit einigen Optionen ausführen. Da Sie sicherstellen müssen, dass Sie die aktuellste Version der Zeile lesen, werden absolute konsistente Lesevorgänge verwendet. In solchen Fällen verwenden Sie den Multiplikator 2 in der Formel der Leseeinheit. Hier sind die verschiedenen Optionen zur Bestimmung der Leseeinheitskosten:
- Wenn Option.IfAbsent oder Option.IfPresent verwendet wird, dann Leseverbrauch = 2
- Wenn setReturnRow verwendet wird, ist Leseverbrauch = 2 * Datensatzgröße
- Wenn Option.IfAbsent und setReturnRow verwendet werden, dann Leseverbrauch = 2 * Datensatzgröße
Datensätze anhand des Primärschlüssels lesen Record size round up to KBDatensatzgröße = 1 KB 0 Datensatzgröße ist 1 KB Datensätze anhand des sekundären Index lesen Angenommen, 100 Datensätze werden zurückgegeben. record_size * number_of_records_matched11 KB *100 = 100 KB
100 KB + 10 KB = 110 KB
0 Für den sekundären Index fallen keine Gebühren an. Die Datensatzgröße beträgt 1 KB. Für 100 Datensätze beträgt sie 100 KB.
Zusätzliche 10 KB für variablen Overhead, der je nach Anzahl der zurückgegebenen Batches und dem für die Abfrage festgelegten Größengrenzwert anfällt.
Gemeinkosten sind die Kosten für das Lesen des letzten Schlüssels in einem Batch. Dies ist eine Variable, die von der maxReadKB- und Datensatzgröße abhängt. Der Overhead beträgt bis zu (numBatches - 1) * Key-Lesekosten (1 KB).
Vorhandene Datensätze aktualisieren Angenommen, die Größe des aktualisierten Datensatzes ist identisch mit der alten Datensatzgröße (1 KB). Read consumption = record_size * 2Write consumption = original_record_size + new_record_size + 1 KB (index) * (number of writes)1 KB * 2 1 KB + 1 KB + 1 KB(1) *(2) = 4 KB Wenn Zeilen mit einer query(SQL-Anweisung) aktualisiert werden, werden sowohl Lese- als auch Schreibeinheiten verbraucht. Je nach Update muss der Primärschlüssel, der Sekundärschlüssel oder sogar der Datensatz selbst gelesen werden. Absolute konsistente Lesevorgänge sind erforderlich, um sicherzustellen, dass wir den neuesten Datensatz lesen. Die Lesezugriffe mit absoluter Konsistenz sind doppelt so teuer wie die Lesezugriffe mit Eventual Consistency. Dies ist der Grund für die Multiplikation mit 2 in der Formel.
Leseverbrauch: Keine Gebühr für Index und Datensatzgröße beträgt 1 KB. Bei Ausführung mit der Option setReturnRow, dann Leseverbrauch = 2 * Datensatzgröße
Schreibverbrauch: Die ursprüngliche und die neue Datensatzgröße betragen 1 KB und 1 KB für einen Index.
Datensatz löschen Read consumption = 1 KB (index) * 2Write consumption = record_size + 1KB (index) * (number_of_indexes)1 KB (1) *2 = 2 KB 1 KB + 1 KB(1) * (1) = 2 KB Beim Löschen fallen sowohl Lese- als auch Schreibkosten pro Einheit an. Da Sie sicherstellen müssen, dass Sie die aktuellste Version der Zeile anzeigen, werden absolute konsistente Lesevorgänge verwendet. Dies ist der Grund für die Verwendung des 2-Multiplikators in der Leseeinheitenformel.
Bei Ausführung mit der Option setReturnRow, Leseverbrauch = 2 * Datensatzgröße. Anderenfalls Leseverbrauch = 1 KB für einen Index
Schreibverbrauch: Die Datensatzgröße für den Index beträgt 1 KB und 1 KB. Die Anzahl der Indizes ist 1.
Bestimmen Sie mit den Schritten 2 und 3 die Lese- und Schreibeinheiten für die Anwendungs-Workload.
Betriebsabläufe Rate der Vorgänge Lesezugriffe pro Sekunde Schreibzugriffe pro Sekunde Datensätze erstellen 3 0 6 Datensätze anhand des Primärschlüssels lesen 300 300 0 Datensätze anhand des sekundären Index lesen 10 1.100 0 Vorhandenen Datensatz aktualisieren 5 10 20 Datensatz löschen 1 2 2 Leseeinheiten gesamt: 1412
Schreibeinheiten insgesamt:28
Daher wird geschätzt, dass die E-Commerce-Anwendung eine Workload von 1412 Lesevorgängen pro Sekunde und 28 Schreibvorgängen pro Sekunde aufweist. Laden Sie den Kapazitätsrechner herunter
Hinweis: Bei den obigen Berechnungen werden Anforderungen von Lesevorgängen mit Eventual Consistence angenommen. Bei der Anforderung eines Lesevorgangs mit Absolute Consistency konsumiert der Vorgang das Doppelte an Kapazitätseinheiten. Daher wären die Lesekapazitätseinheiten 4844 Leseeinheiten.
Monatliche Kosten schätzen
Erfahren Sie, wie Sie die monatlichen Kosten Ihres Oracle Cloud-Abonnements schätzen.
Zur Bestellung auf Ihre Oracle Cloud-Servicebestellung bietet Ihnen Oracle einen Kostenrechner, mit dem Ihnen Ihre monatliche Nutzung und die dazugehörigen Kosten ermittelt werden können, bevor Sie ein Abonnementmodell oder einen Betrag festlegen.
Der Kostenrechner berechnet automatisch Ihre monatlichen Kosten basierend auf den von Ihnen eingegebenen Werten für Leseeinheiten, Schreibeinheiten und Speicher. Führen Sie die folgenden Schritte aus, um ein Bild für die Berechnung der Lese- und Schreibeinheiten für Ihre Anwendung erhalten:
-
Schritt 1: Navigieren Sie zum Thema Kapazitätschätzen. Schätzen Sie Ihre Anwendungs-Workload anhand des Beispiels und der unter diesem Thema erläuterten Formeln.
Laden Sie den Kapazitätsrechner von Oracle Technology Network herunter, und verwenden Sie dieses Tool zur Schätzung von Schreibeinheiten, Leseeinheiten und die Speicherkapazität für Ihre Anwendung entsprechend den Kriterien der Anwendungs-Workload und des Datenbankvorgangs zu schätzen.
-
Schritt 2: Rufen Sie den Kostenrechner auf der Oracle Cloud-Webseite auf. Aktivieren Sie das Kontrollkästchen Datenmanagement. Scrollen Sie zu Oracle NoSQL Database Cloud, und wählen Sie Hinzufügen aus, um einen Eintrag für Oracle NoSQL Database Cloud in den Konfigurationsoptionen hinzuzufügen. Blenden Sie NoSQL-Datenbank ein, um die verschiedenen Nutzungs- und Konfigurationsoptionen zu suchen. Eingabewerte für die Nutzungs- und Konfigurationsparameter zur Schätzung der Kosten für die Oracle NoSQL Database Cloud Service-Nutzung aus Ihren Oracle Cloud-Abonnements Pay-As-You-Go und Monthly Flex.
-
Schritt 3: Rufen Sie den Kostenrechner auf der Oracle Cloud-Webseite auf. Wählen Sie im Dropdown-Menü die Option {\b Data Management}. Unter "Datenmanagement" werden verschiedene Optionen angezeigt. Scrollen Sie durch Oracle NoSQL Database Cloud. Klicken Sie auf Hinzufügen, um einen Eintrag für Oracle NoSQL Database Cloud in den Konfigurationsoptionen hinzuzufügen.
-
Schritt 4: Blenden Sie "Datenbank - NoSQL" ein, um die verschiedenen Auslastungs- und Konfigurationsoptionen zu finden. Unter "Konfiguration" können Sie zwei Optionen auswählen. Sie können mit der Option "Immer kostenlos" beginnen (nur in der Region Phoenix verfügbar), oder Sie können Ihrer Instanz die gewünschte Konfiguration bereitstellen.
- Schritt 4a: Wenn Sie eine Option vom Typ "Immer kostenlos" verwenden möchten, blenden Sie unter "Konfiguration" die Optionen "Oracle NoSQL Database Cloud - Lesen", "Oracle NoSQL Database Cloud Service - Speicher" und "Oracle NoSQL Database Cloud Service - Schreiben" ein, und ändern Sie die Lese-, Speicher- und Schreibkapazität als 0. Anschließend wird Ihre Gesamtkostenschätzung als 0 angezeigt, und Sie können mit der Option Immer kostenlos fortfahren.
-
Schritt 5: Wenn Sie alternativ eine höhere Lese-, Schreib- und Speicherkapazität als die in "Immer kostenlos" verfügbare Kapazität bereitstellen möchten, können Sie die Konfigurationswerte unter "Database-NoSQL" eingeben.
-
Schritt 5a: Ändern Sie unter "Auslastung" die Standardwerte nicht, da Oracle NoSQL Database Cloud Service keinen dieser Werte verwendet.
-
Schritt 5b: Fügen Sie unter "Konfiguration" die Anzahl der Leseeinheiten, Schreibeinheiten und Speicherkapazität hinzu, die Sie im vorherigen Schritt geschätzt haben. Die Kosten werden basierend auf Ihren Eingabewerten geschätzt und auf der Seite angezeigt.
-
Hinweis: Wenn Sie das Autoscaling-Feature verwenden, wird am Monatsende eine Rechnung für den tatsächlichen Verbrauch von Lese- und Schreibeinheiten in Echtzeit generiert. Sie können also Ihre eigenen Auditlogs in der Anwendung erfassen, um die Abrechnung am Monatsende zu verifizieren. Es wird empfohlen, die verbrauchten Lese- und Schreibeinheiten zu protokollieren, die vom NoSQL Database Cloud-Service bei jedem API-Aufruf zurückgegeben werden. Sie könnten diese Daten verwenden, um mit den Fakturierungsdaten zum Monatsende aus dem Oracle Cloud-Metering- und -Abrechnungssystem zu korrelieren.
Ausführliche Informationen zu den verschiedenen verfügbaren Preismodellen finden Sie unter NoSQL Database Cloud Service - Preise.
Kosten/Fakturierung für globale aktive Tabellen
Die Kosten/Fakturierung für eine globale aktive Tabelle enthält zwei Komponenten. Die erste Komponente ist das Preismodell, das für Singleton-Tabellen befolgt wird. Dabei werden die Leseeinheiten pro Monat, die Schreibeinheiten pro Monat und die Gigabyte-(GB-)Speicherkapazität pro Monat berücksichtigt. Die zweite Komponente bezieht sich auf die replizierten Schreibvorgänge für jedes regionale Tabellenreplikat für die Tabelle Global Active. Eingehende replizierte Schreibvorgänge werden basierend auf konsumierten Schreibvorgängen in Rechnung gestellt.