Oracle NoSQL Database-Migrator verwenden
Erfahren Sie mehr über Oracle NoSQL Database Migrator und wie Sie ihn für die Datenmigration verwenden.
Oracle NoSQL Database Migrator ist ein Tool, mit dem Sie Oracle NoSQL-Tabellen von einer Datenquelle in eine andere migrieren können. Dieses Tool kann für Tabellen in Oracle NoSQL Database Cloud Service, Oracle NoSQL Database On-Premises und AWS S3 verwendet werden. Das Migrator-Tool unterstützt verschiedene Datenformate und physische Medientypen. Unterstützte Datenformate sind JSON-, Parquet-, MongoDB-formatierte JSON-, DynamoDB-formatierte JSON- und CSV-Dateien. Unterstützte physische Medientypen sind Dateien, OCI Object Storage, Oracle NoSQL Database On-Premises, Oracle NoSQL Database Cloud Service und AWS S3.
Dieser Artikel enthält die folgenden Themen:
Überblick
Mit Oracle NoSQL Database Migrator können Sie Oracle NoSQL-Tabellen von einer Datenquelle in eine andere verschieben, wie Oracle NoSQL Database On-Premise oder Cloud oder sogar eine einfache JSON-Datei.
Es kann viele Situationen geben, in denen Sie NoSQL-Tabellen von oder zu Oracle NoSQL Database migrieren müssen. Beispiel: Ein Entwicklerteam, das eine NoSQL Database-Anwendung verbessert, möchte möglicherweise den aktualisierten Code in der lokalen Oracle NoSQL Database Cloud Service-(NDCS-)Instanz mit cloudim testen. Um alle möglichen Testfälle zu überprüfen, müssen sie die Testdaten ähnlich den tatsächlichen Daten einrichten. Dazu müssen sie die NoSQL-Tabellen aus der Produktionsumgebung in ihre lokale NDCS-Instanz, die Cloud-Umgebung, kopieren. In einer anderen Situation müssen NoSQL-Entwickler ihre Anwendungsdaten möglicherweise von On Premise in die Cloud verschieben und umgekehrt, entweder zur Entwicklung oder zum Testen.
In all diesen und vielen weiteren Fällen können Sie mit Oracle NoSQL Database Migrator Ihre NoSQL-Tabellen von einer Datenquelle in eine andere verschieben, z. B. On-Premise oder Cloud von Oracle NoSQL Database oder sogar eine einfache JSON-Datei. Sie können NoSQL-Tabellen auch aus einer MongoDB-formatierten JSON-Eingabedatei, einer DynamoDB-formatierten JSON-Eingabedatei (entweder in AWS S3-Quelle oder aus Dateien gespeichert) oder einer CSV-Datei in Ihre NoSQL-Datenbank On-Premises oder in die Cloud kopieren.
Wie in der folgenden Abbildung dargestellt, fungiert das Utility NoSQL Database Migrator als Konnektor oder Pipe zwischen der Datenquelle und dem Ziel (als Sink bezeichnet). Im Wesentlichen exportiert dieses Dienstprogramm Daten aus der ausgewählten Quelle und importiert diese Daten in die Senke. Dieses Tool ist tabellenorientiert, d.h. Sie können die Daten nur auf Tabellenebene verschieben. Eine einzelne Migrationsaufgabe wird für eine einzelne Tabelle ausgeführt und unterstützt die Migration von Tabellendaten von Quelle zu Sink in verschiedenen Datenformaten.
Der Oracle NoSQL Database Migrator ist so konzipiert, dass er in Zukunft weitere Quellen und Senken unterstützen kann. Eine Liste der Quellen und Senken, die vom Oracle NoSQL Database-Migrator ab dem aktuellen Release unterstützt werden, finden Sie unter Unterstützte Quellen und Sinks. 
Beschreibung der Abbildung migrator_overview.png
Mit Oracle NoSQL Database Migrator verwendete Terminologie
Erfahren Sie mehr über die verschiedenen Begriffe, die im obigen Diagramm verwendet werden, im Detail.
-
Quelle: Eine Entity, aus der die NoSQL-Tabellen für die Migration exportiert werden. Einige Beispiele für Quellen sind On-Premise- oder Cloud-Oracle NoSQL Database, JSON-Datei, MongoDB-formatierte JSON-Datei, DynamoDB-formatierte JSON-Datei und CSV-Dateien.
-
Sink: Eine Entity, die NoSQL-Tabellen aus dem NoSQL-Datenbankmigrator importiert. Beispiele für Sinks sind Oracle NoSQL Database On-Premise oder Cloud- und JSON-Datei.
Das NoSQL Database Migrator-Tool unterstützt verschiedene Arten von Quellen und Senken (d.h. physische Medien oder Repositorys von Daten) und Datenformate (d.h. die Darstellung der Daten in der Quelle oder Sink). Unterstützte Datenformate sind JSON-, Parquet-, MongoDB-formatierte JSON-, DynamoDB-formatierte JSON- und CSV-Dateien. Unterstützte Quell- und Sink-Typen sind Dateien, OCI Object Storage, Oracle NoSQL Database On Premise und Oracle NoSQL Database Cloud Service.
-
Migrations-Pipe: Die Daten aus einer Quelle werden vom NoSQL-Datenbankmigrator an die Senke übertragen. Dies kann als Migrationsrohr visualisiert werden.
-
Transformationen: Sie können Regeln hinzufügen, um die NoSQL-Tabellendaten in der Migrations-Pipe zu ändern. Diese Regeln werden Transformationen genannt. Oracle NoSQL Database Migrator ermöglicht Datentransformationen nur in den Feldern oder Spalten der obersten Ebene. Sie können die Daten in den verschachtelten Feldern nicht transformieren. Beispiele für zulässige Transformationen:
-
Löschen oder ignorieren Sie eine oder mehrere Spalten.
-
eine oder mehrere Spalten umbenennen oder
-
Aggregieren Sie mehrere Spalten in einem einzelnen Feld, in der Regel ein JSON-Feld.
-
-
Konfigurationsdatei: In einer Konfigurationsdatei definieren Sie alle für die Migrationsaktivität erforderlichen Parameter im JSON-Format. Später übergeben Sie diese Konfigurationsdatei als einzelnen Parameter über die CLI an den Befehl
runMigrator. Ein typisches Konfigurationsdateiformat sieht wie unten dargestellt aus.{ "source": { "type" : <source type>, //source-configuration for type. }, "sink": { "type" : <sink type>, //sink-configuration for type. }, "transforms" : { //transforms configuration. }, "migratorVersion" : "<migrator version>", "abortOnError" : <true|false> }Gruppieren Parameter Erforderlich (J/N) Zweck Unterstützte Werte sourcetypeJ Stellt die Quelle dar, aus der die Daten migriert werden sollen. Die Quelle stellt Daten und Metadaten (sofern vorhanden) für die Migration bereit. Informationen zum Wert typefür jede Quelle finden Sie unter Unterstützte Quellen und Sinks.sourceQuellkonfiguration für Typ J Definiert die Konfiguration für die Quelle. Diese Konfigurationsparameter sind spezifisch für den oben ausgewählten Quelltyp. Eine vollständige Liste der Konfigurationsparameter für jeden Quelltyp finden Sie unter Quellkonfigurationsvorlagen . sinktypeJ Stellt die Senke dar, zu der die Daten migriert werden sollen. Die Sink ist das Ziel oder Ziel für die Migration. Informationen zum Wert typefür jede Quelle finden Sie unter Unterstützte Quellen und Sinks.sinksinken-Konfiguration für Typ J Definiert die Konfiguration für die Senke. Diese Konfigurationsparameter sind spezifisch für den oben ausgewählten Senktyp. Eine vollständige Liste der Konfigurationsparameter für jeden Senktyp finden Sie unter Sink-Konfigurationsvorlagen. transformstransformiert Konfiguration N Definiert die Transformationen, die auf die Daten in der Migrations-Pipe angewendet werden sollen. Eine vollständige Liste der vom NoSQL-Datenmigrator unterstützten Transformationen finden Sie unter Vorlagen für die Transformationskonfiguration. - migratorVersionN Version des NoSQL-Datenmigrators - - abortOnErrorN Gibt an, ob die Migrationsaktivität bei einem Fehler gestoppt werden soll.
Der Standardwert ist true, der angibt, dass die Migration gestoppt wird, wenn ein Migrationsfehler auftritt.
Wenn Sie diesen Wert auf false setzen, wird die Migration auch bei nicht erfolgreichen Datensätzen oder anderen Migrationsfehlern fortgesetzt. Die nicht erfolgreichen Datensätze und Migrationsfehler werden im CLI-Terminal als WARNUNGEN protokolliert.True, False
Hinweis: Wenn in der JSON-Datei die Groß-/Kleinschreibung beachtet wird, wird bei allen in der Konfigurationsdatei definierten Parametern die Groß-/Kleinschreibung beachtet, sofern nichts anderes angegeben ist.
Unterstützte Quellen und Sinks
Dieses Thema enthält die Liste der Quellen und Senken, die vom Oracle NoSQL Database-Migrator unterstützt werden.
Sie können eine beliebige Kombination aus einer gültigen Quelle und Sink aus dieser Tabelle für die Migrationsaktivität verwenden. Sie müssen jedoch sicherstellen, dass mindestens eines der Enden, d.h. Quelle oder Sink, ein Oracle NoSQL-Produkt sein muss. Mit dem NoSQL Database Migrator können Sie die NoSQL-Tabellendaten nicht von einer Datei in eine andere verschieben.
| Typ (Wert) | Format (Wert) | Gültige Quelle | Gültiger Sink |
|---|---|---|---|
Oracle NoSQL Database (nosqldb) |
- | J | J |
Oracle NoSQL Database Cloud Service (nosqldb_cloud) |
- | J | J |
Dateisystem (file) |
JSON (json) |
J | J |
Dateisystem (file) |
MongoDB-JSON (mongodb_json) |
J | N |
Dateisystem (file) |
DynamoDB-JSON (dynamodb_json) |
J | N |
Dateisystem (file) |
Parkett (parquet) |
N | J |
Dateisystem (file) |
CSV (csv) |
J | N |
OCI-Objektspeicher (object_storage_oci) |
JSON (json) |
J | J |
OCI-Objektspeicher (object_storage_oci) |
MongoDB-JSON (mongodb_json) |
J | N |
OCI-Objektspeicher (object_storage_oci) |
Parkett (parquet) |
N | J |
OCI-Objektspeicher (object_storage_oci) |
CSV (csv) |
J | N |
| AWS-S3 | DynamoDB-JSON (dynamodb_json) |
J | N |
Hinweis: Viele Konfigurationsparameter werden in der Quell- und Sink-Konfiguration verwendet. Zur Vereinfachung wird die Beschreibung für diese Parameter für jede Quelle und Sink in den Dokumentationsabschnitten wiederholt, die Konfigurationsdateiformate für verschiedene Arten von Quellen und Sinks erläutern. In allen Fällen sind Syntax und Semantik der Parameter mit demselben Namen identisch.
Sicherheit für Quelle und Ziel ("Sink")
Einige Quell- und Senktypen verfügen zu Authentifizierungszwecken über optionale oder obligatorische Sicherheitsinformationen.
Alle Quellen und Senken, die Services in Oracle Cloud Infrastructure (OCI) verwenden, können bestimmte Parameter verwenden, um optionale Sicherheitsinformationen bereitzustellen. Diese Informationen können mit einer OCI-Konfigurationsdatei oder einem Instanz-Principal bereitgestellt werden.
Oracle NoSQL Database-Quellen und -Senken erfordern obligatorische Sicherheitsinformationen, wenn die Installation sicher ist und eine Oracle Wallet-basierte Authentifizierung verwendet. Diese Informationen können durch Hinzufügen einer JAR-Datei zum Verzeichnis <MIGRATOR_HOME>/lib bereitgestellt werden.
Authentifizieren mit Instanz-Principals
Instanz-Principals ist ein IAM-Servicefeature, mit dem Instanzen für Serviceressourcen als autorisierte Akteure (oder Principals) ausführen können. Jede Compute-Instanz hat eine eigene Identität und authentifiziert sie mit den Zertifikaten, die ihr hinzugefügt werden.
Oracle NoSQL Database Migrator bietet eine Option zum Herstellen einer Verbindung zu einer NoSQL-Cloud und OCI Object Storage-Quellen und -Senken mit Instanz-Principal-Authentifizierung. Sie wird nur unterstützt, wenn das NoSQL Database Migrator-Tool innerhalb einer OCI-Compute-Instanz verwendet wird, z.B. das NoSQL Database Migrator-Tool, das in einer auf OCI gehosteten VM ausgeführt wird. Um dieses Feature zu aktivieren, verwenden Sie das useInstancePrincipal-Attribut der NoSQL-Cloud-Quell- und -Sink-Konfigurationsdatei. Weitere Informationen zu Konfigurationsparametern für verschiedene Typen von Quellen und Senken finden Sie unter Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen.
Weitere Informationen zu Instanz-Principals finden Sie unter Services von einer Instanz aufrufen.
Autorisierung in Oracle NoSQL Database Cloud Service-Quellen und -Senken
Der Zugriff auf Ressourcen in Oracle NoSQL Database Cloud Service, wie Tabellen, Tablespaces und APIs, wird über Identity and Access Management-(IAM-)Policys verwaltet. Dadurch wird sichergestellt, dass nur Benutzer oder Anwendungen mit den entsprechenden Berechtigungen zum Prüfen, Lesen, Verwenden oder Verwalten von Tabellen in einem bestimmten Compartment mit diesen Ressourcen interagieren können. Weitere Informationen finden Sie unter Zugriff auf NDCS-Tabellen verwalten.
Wenn Sie mit dem Utility Migrator Daten aus Oracle NoSQL Database Cloud Service-Tabellen importieren oder exportieren, bestimmen Ihre effektiven IAM-Berechtigungen die Ressourcen, aus denen Sie lesen oder in die Sie schreiben können. Wenn ein Benutzer aus einer definierten Gruppe eine Aktion über seine autorisierten Berechtigungen hinaus versucht, gibt das Migrator-Utility den entsprechenden Autorisierungsfehler zurück, der von OCI IAM bereitgestellt wird.
Beispiel: OCI IAM verweigert jeden Versuch, Daten in eine Oracle NoSQL Database Cloud Service-Tabelle zu importieren, wenn Ihre Benutzergruppe nur über die Leseberechtigung für die Tabelle verfügt. Eine Fehlermeldung wie die Folgende wird in den Logs angezeigt:
[INSUFFICIENT_PERMISSION] Authorization failed or requested resource not foundWorkflow für Oracle NoSQL Database-Migrator
Erfahren Sie mehr über die verschiedenen Schritte bei der Verwendung des Oracle NoSQL Database Migrator-Utilitys für die Migration Ihrer NoSQL-Daten.
Der allgemeine Ablauf der Aufgaben, die mit der Verwendung von NoSQL Database Migrator verbunden sind, wird in der folgenden Abbildung dargestellt.
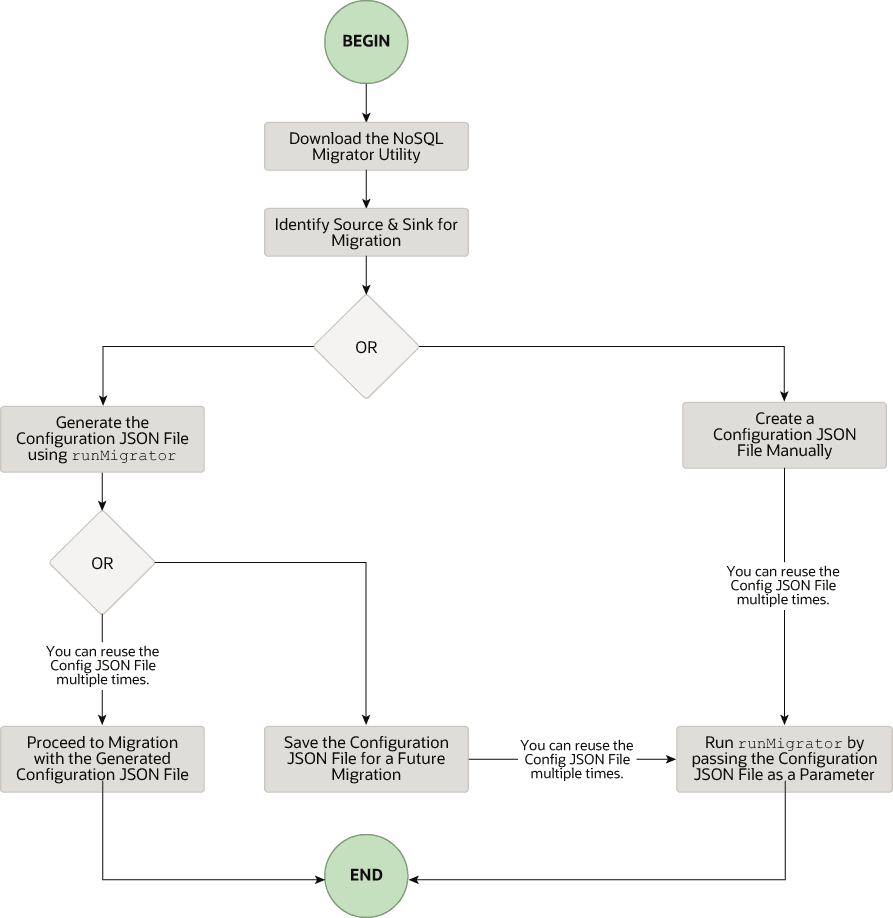
Beschreibung der Abbildung migrator_flow.png
Utility NoSQL Data Migrator herunterladen
Das Oracle NoSQL Database-Migratorutility kann auf der Seite Oracle NoSQL-Downloads heruntergeladen werden. Nachdem Sie den Befehl heruntergeladen und auf Ihrem Rechner dekomprimiert haben, können Sie über die Befehlszeilenschnittstelle auf den Befehl runMigrator zugreifen.
Hinweis: Für das Oracle NoSQL Database-Migratorutility ist die Ausführung von Java 11 oder höheren Versionen erforderlich.
Quelle und Sink angeben
Bevor Sie den Migrator verwenden, müssen Sie die Datenquelle und die Senke identifizieren. Beispiel: Wenn Sie eine NoSQL-Tabelle von Oracle NoSQL Database On Premise in eine JSON-formatierte Datei migrieren möchten, lautet die Quelle Oracle NoSQL Database, und die Sink-Datei ist eine JSON-Datei. Stellen Sie sicher, dass die identifizierte Quelle und Sink vom Oracle NoSQL Database-Migrator unterstützt werden, indem Sie auf unterstützte Quellen und Sinks verweisen. Dies ist auch eine geeignete Phase, um das Schema für die NoSQL-Tabelle im Ziel oder in der Sink zu bestimmen und zu erstellen.
-
Sink-Tabellenschema identifizieren: Wenn die Sink Oracle NoSQL Database On-Premise oder Cloud ist, müssen Sie das Schema für die Sink-Tabelle identifizieren und sicherstellen, dass die Quelldaten mit dem Zielschema übereinstimmen. Verwenden Sie bei Bedarf Transformationen, um die Quelldaten der Sink-Tabelle zuzuordnen.
-
Standardschema: NoSQL Database Migrator bietet eine Option zum Erstellen einer Sink-Tabelle mit dem Standardschema, ohne dass das Schema für die Tabelle vordefiniert werden muss.
MongoDB-formatierte JSON:
Wenn die Quelle eine MongoDB-formatierte JSON-Datei ist, lautet das Standardschema für die Tabelle wie folgt:
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id))Dabei gilt:
-
tablename = für das Tabellenattribut in der Konfiguration angegebener Wert.
-
id = _id Wert aus jedem Dokument der MongoDB exportierten JSON-Quelldatei.
-
document = Für jedes Dokument in der exportierten MongoDB-Datei werden die Inhalte ohne das Feld
_idin der Dokumentspalte zusammengefasst.
Hinweis:
- Wenn der _id-Wert nicht als Zeichenfolge in der mongoDB-formatierten JSON-Datei angegeben ist, konvertiert NoSQL Database Migrator ihn in eine Zeichenfolge, bevor er in das Standardschema eingefügt wird.
- Wenn die Tabelle
<tablename>bereits in Oracle NoSQL Database On-Premise oder in der Cloud vorhanden ist und Sie Daten mit der KonfigurationdefaultSchemain die Tabelle migrieren möchten, müssen Sie sicherstellen, dass die vorhandene Tabelle die ID-Spalte in Kleinbuchstaben (ID) und den Typ STRING aufweist.
DynamoDB-formatierte JSON:
Wenn die Quelle eine JSON-Datei im DynamoDB-Format ist, lautet das Standardschema für die Tabelle wie folgt:
CREATE TABLE IF NOT EXISTS <tablename>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type],DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))Dabei gilt:
-
tablename = Wert für die Sink-Tabelle in der Konfiguration
-
DDBPartitionKey_name = Wert für den Partitionsschlüssel in der Konfiguration angegeben
-
DDBPartitionKey_type = Wert für den Datentyp des Partitionsschlüssels in der Konfiguration
-
DDBSortKey_name = Wert, der für den Sortierschlüssel in der Konfiguration angegeben wird, sofern vorhanden
-
DDBSortKey_type = Wert für den Datentyp des Sortierschlüssels in der Konfiguration, sofern vorhanden
-
DOCUMENT = Alle Attribute mit Ausnahme des Partitions- und Sortierschlüssels eines DynamoDB-Tabellenelements, das in einer NoSQL-JSON-Spalte aggregiert wird
Wenn das Quellformat eine CSV-Datei ist, wird ein Standardschema für die Zieltabelle nicht unterstützt. Sie können eine Schemadatei mit einer Tabellendefinition erstellen, die dieselbe Anzahl von Spalten und Datentypen wie die CSV-Quelldatei enthält. Weitere Informationen zum Erstellen der Schemadatei finden Sie unter Tabellenschema bereitstellen.
Andere gültige Quellen:
Für alle anderen Quellen ist das Standardschema wie folgt:
CREATE TABLE IF NOT EXISTS <tablename> (id LONG GENERATED ALWAYS AS IDENTITY, document JSON, PRIMARY KEY(id))Dabei gilt:
-
tablename = für das Tabellenattribut in der Konfiguration angegebener Wert.
-
id = Ein automatisch generierter LONG-Wert.
-
document = Der von der Quelle bereitgestellte JSON-Datensatz wird in die Dokumentspalte aggregiert.
-
-
-
Tabellenschema angeben: Mit NoSQL Database Migrator kann die Quelle Schemadefinitionen für die Tabellendaten mit dem schemaInfo-Attribut bereitstellen. Das schemaInfo-Attribut ist in allen Datenquellen verfügbar, für die noch kein implizites Schema definiert ist. Sink-Datenspeicher können eine der folgenden Optionen auswählen.
-
Verwenden Sie das vom NoSQL Database Migrator definierte Standardschema.
-
Verwenden Sie das von der Quelle bereitgestellte Schema.
-
Überschreiben Sie das von der Quelle bereitgestellte Schema, indem Sie ein eigenes Schema definieren. Beispiel: Wenn Sie die Daten aus dem Quellschema in ein anderes Schema transformieren möchten, müssen Sie das von der Quelle bereitgestellte Schema außer Kraft setzen und die Transformationsfunktion des NoSQL Database Migrator-Tools verwenden.
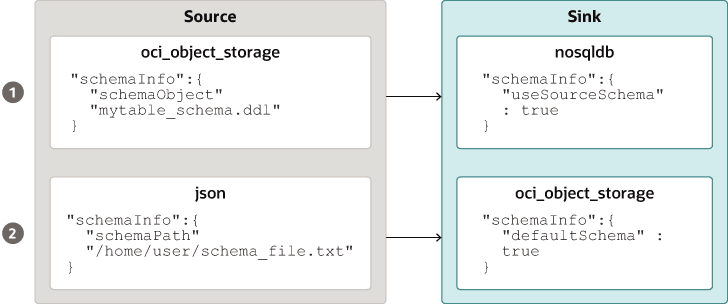
Beschreibung der Abbildung source_sink_schema_example.png
Die Tabellenschemadatei, z.B.
mytable_schema.ddl, kann Tabellen-DDL-Anweisungen enthalten. Das NoSQL Database Migrator-Tool führt diese Tabellenschemadatei aus, bevor die Migration gestartet wird. Das Migrationstool unterstützt nicht mehr als eine DDL-Anweisung pro Zeile in der Schemadatei. Beispiel:CREATE TABLE IF NOT EXISTS(id INTEGER, name STRING, age INTEGER, PRIMARY KEY(SHARD(ID))) -
Hinweis: Die Migration verläuft nicht erfolgreich, wenn die Tabelle in der Sink-Datei vorhanden ist und die DDL in schemaPath sich von der Tabelle unterscheidet.
- Sink-Tabelle erstellen: Nachdem Sie das Sink-Tabellenschema identifiziert haben, erstellen Sie die Sink-Tabelle entweder über die Admin-CLI oder mit dem Attribut
schemaInfoder Sink-Konfigurationsdatei. Siehe Sink-Konfigurationsvorlagen.
Hinweis: Wenn die Quelle eine CSV-Datei ist, erstellen Sie eine Datei mit den DDL-Befehlen für das Schema der Zieltabelle. Geben Sie den Dateipfad in dem Parameter schemaInfo.schemaPath der Sink-Konfigurationsdatei an.
Befehl runMigrator ausführen
Die ausführbare Datei runMigrator ist in den extrahierten NoSQL Database Migrator-Dateien verfügbar. Sie müssen Java 11 oder eine höhere Version und bash auf Ihrem System installieren, um den Befehl runMigrator erfolgreich auszuführen.
Sie können den Befehl runMigrator auf zwei Arten ausführen:
-
Indem Sie die Konfigurationsdatei mit den Laufzeitoptionen des Befehls
runMigratorerstellen, wie unten gezeigt.[~]$ ./runMigrator configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y ... ...-
Wenn Sie das Utility
runMigratoraufrufen, stellt es eine Reihe von Laufzeitoptionen bereit und erstellt die Konfigurationsdatei basierend auf Ihren Auswahlmöglichkeiten für jede Option. -
Nachdem das Utility die Konfigurationsdatei erstellt hat, können Sie entweder mit der Migrationsaktivität in derselben Ausführung fortfahren oder die Konfigurationsdatei für eine zukünftige Migration speichern.
-
Unabhängig von Ihrer Entscheidung, mit der generierten Konfigurationsdatei fortzufahren oder die Migrationsaktivität zu verzögern, steht die Datei für Änderungen oder Anpassungen zur Verfügung, um Ihre zukünftigen Anforderungen zu erfüllen. Sie können die benutzerdefinierte Konfigurationsdatei später für die Migration verwenden.
-
-
Durch Übergabe einer manuell erstellten Konfigurationsdatei (im JSON-Format) als Laufzeitparameter mit der Option
-coder--config. Sie müssen die Konfigurationsdatei manuell erstellen, bevor Sie den BefehlrunMigratormit der Option-coder--configausführen. Weitere Informationen zu den Quell- und Sinkkonfigurationsparametern finden Sie in der Oracle NoSQL Database-Migratorreferenz.[~]$ ./runMigrator -c </path/to/the/configuration/json/file>
Hinweis: NoSQL Database Migrator konsumiert Leseeinheiten beim Datenexport aus der Oracle NoSQL Cloud Service-Tabelle in eine beliebige gültige Sink.
Fortschritt des Logging-Migrators
Das NoSQL Database Migrator-Tool bietet Optionen, mit denen Trace-, Debugging- und Fortschrittsmeldungen in die Standardausgabe oder in eine Datei gedruckt werden können. Diese Option kann nützlich sein, um den Fortschritt des Migrationsvorgangs zu verfolgen, insbesondere bei sehr großen Tabellen oder Datasets.
-
Logebenen
Um das Loggingverhalten über das NoSQL Database Migrator-Tool zu steuern, übergeben Sie den Laufzeitparameter –log-level oder -l an den Befehl
runMigrator. Sie können die Menge der zu schreibenden Loginformationen angeben, indem Sie den entsprechenden Wert auf Logebene übergeben.$./runMigrator --log-level <loglevel>Beispiel:
$./runMigrator --log-level debugTabelle - Unterstützte Logebenen für NoSQL Database Migrator
Logebene Beschreibung Warnung Druckt Fehler und Warnungen. Info (Standard) Druckt den Fortschrittsstatus der Datenmigration, wie das Validieren der Quelle, das Validieren der Senke, das Erstellen von Tabellen und die Anzahl der migrierten Datensätze. debug Gibt zusätzliche Debug-Informationen aus. all Druckt alles. Diese Stufe aktiviert alle Logging-Ebenen. -
Logdatei:
Sie können den Namen der Logdatei mit dem Parameter –log-file oder -f angeben. Wenn –log-file als Laufzeitparameter an den Befehl
runMigratorübergeben wird, schreibt der NoSQL Database Migrator alle Logmeldungen in die Datei, ansonsten in die Standardausgabe.$./runMigrator --log-file <log file name>Beispiel:
$./runMigrator --log-file nosql_migrator.log
Beschränkung
Oracle NoSQL Database Migrator sperrt die Datenbank während des Backups nicht und blockiert andere Benutzer. Daher wird dringend empfohlen, die folgenden Aktivitäten nicht auszuführen, wenn eine Migrationsaufgabe ausgeführt wird:
-
Alle DML-/DDL-Vorgänge in der Quelltabelle.
-
Jede topologiebezogene Änderung im Datenspeicher.
TTL-Metadaten für Tabellenzeilen migrieren
Erfahren Sie, wie Sie TTL-Daten von der Quelle in die Sink migrieren.
Die Gültigkeitsdauer (Time to Live, TTL) ist ein Verfahren, mit dessen Hilfe Sie Tabellenzeilen automatisch ablaufen lassen. Die Gültigkeitsdauer gibt an, wie lange Daten im Speicher gültig sind Daten, die den Ablauf-Timeout-Wert erreicht haben, können nicht mehr abgerufen werden und werden in keinen Speicherstatistiken angezeigt.
Sie können die TTL-Metadaten für Tabellenzeilen zusammen mit den tatsächlichen Daten bei der Migration von Oracle NoSQL Database-Tabellen einschließen. Der NoSQL Database Migrator stellt Konfigurationsparameter bereit, die den Export und Import von TTL-Metadaten für Tabellenzeilen für die folgenden Quelltypen unterstützen:
Tabelle - TTL-Metadaten werden migriert
| Quelltypen | Quellkonfigurationsparameter | Sink-Konfigurationsparameter |
|---|---|---|
| Oracle NoSQL Database | includeTTL |
includeTTL |
| Oracle NoSQL Database Cloud Service | includeTTL |
includeTTL |
| DynamoDB-formatierte JSON-Datei | ttlAttributeName |
includeTTL |
| DynamoDB-formatierte JSON-Datei in AWS S3 gespeichert | ttlAttributeName |
includeTTL |
TTL-Metadaten in Oracle NoSQL Database und Oracle NoSQL Database Cloud Service exportieren
NoSQL Database Migrator stellt den includeTTL-Konfigurationsparameter bereit, um den Export der TTL-Metadaten der Tabellenzeile zu unterstützen.
Beim Export einer Tabelle werden die TTL-Daten für die Tabellenzeilen exportiert, die eine gültige Ablaufzeit aufweisen. Wenn eine Zeile nicht abläuft, wird das JSON-Objekt _metadata nicht explizit in den exportierten Daten enthalten, da der Ablaufwert immer
- Der NoSQL Database Migrator exportiert die Ablaufzeit für jede Zeile als die Anzahl der Millisekunden seit der UNIX-Epoche (1. Januar 1970). Beispiel:
//Row 1
{
"id" : 1,
"name" : "xyz",
"age" : 45,
"_metadata" : {
"expiration" : 1629709200000 //Row Expiration time in milliseconds
}
}
//Row 2
{
"id" : 2,
"name" : "abc",
"age" : 52,
"_metadata" : {
"expiration" : 1629709400000 //Row Expiration time in milliseconds
}
}
//Row 3 No Metadata for below row as it will not expire
{
"id" : 3,
"name" : "def",
"age" : 15
}TTL-Metadaten importieren
Sie können optional TTL-Metadaten mit dem includeTTL-Konfigurationsparameter in der Sink-Konfigurationsvorlage importieren.
Die Standardreferenzzeit des Importvorgangs ist die aktuelle Zeit in Millisekunden, die von System.currentTimeMillis() auf dem Rechner abgerufen wird, auf dem das NoSQL Database Migrator-Tool ausgeführt wird. Sie können jedoch auch eine benutzerdefinierte Referenzzeit mit dem ttlRelativeDate-Konfigurationsparameter festlegen, wenn Sie die Ablaufzeit verlängern und Zeilen importieren möchten, die andernfalls sofort ablaufen würden. Die Verlängerung wird wie folgt berechnet und der Ablaufzeit hinzugefügt.
Extended time = expiration time - reference timeDer Importvorgang behandelt die folgenden Anwendungsfälle bei der Migration von Tabellenzeilen, die TTL-Metadaten enthalten. Diese Anwendungsfälle sind nur anwendbar, wenn der includeTTL-Konfigurationsparameter auf "true" gesetzt ist.
-
Anwendungsfall 1: In der importierenden Tabellenzeile sind keine TTL-Metadateninformationen vorhanden.
Wenn die Zeile, die Sie importieren möchten, keine TTL-Informationen enthält, legt der NoSQL Database Migrator die TTL=0 für die Zeile fest.
-
Anwendungsfall 2: Der TTL-Wert der Quelltabellenzeile ist relativ zur Referenzzeit abgelaufen, zu der die Tabellenzeile importiert wird.
Die abgelaufene Tabellenzeile wird ignoriert und nicht in den Speicher geschrieben.
-
Anwendungsfall 3: Der TTL-Wert der Quelltabellenzeile ist relativ zur Referenzzeit, zu der die Tabellenzeile importiert wird, nicht abgelaufen.
Die Tabellenzeile wird mit einem TTL-Wert importiert. Der importierte TTL-Wert stimmt jedoch möglicherweise nicht mit dem ursprünglich exportierten TTL-Wert überein, da die Constraints für das ganzzahlige Stunden- und Tagesfenster in der Klasse TimeToLive gelten. Beispiel:
Betrachten Sie eine exportierte Tabellenzeile:
{ "id" : 8, "name" : "xyz", "_metadata" : { "expiration" : 1734566400000 //Thursday, December 19, 2024 12:00:00 AM in UTC } }Die Referenzzeit beim Import ist 1734480000000, also Mittwoch, 18. Dezember 2024, 12:00:00 Uhr.
Importierte Tabellenzeile
{ "id" : 8, "name" : "xyz", "_metadata" : { "ttl" : 1734739200000 //Saturday, December 21, 2024 12:00:00 AM } }
TTL-Metadaten in DynamoDB-formatierte JSON-Datei und DynamoDB-formatierte JSON-Datei importieren, die in AWS S3 gespeichert sind
NoSQL Database Migrator bietet einen zusätzlichen Konfigurationsparameter, ttlAttributeName, der den Import von TTL-Metadaten aus den DynamoDB-formatierten JSON-Dateielementen unterstützt.
DynamoDB exportierte JSON-Dateien enthalten in jedem Element ein bestimmtes Attribut, um den TTL-Ablaufzeitstempel zu speichern. Um optional die TTL-Werte aus exportierten JSON-Dateien von DynamoDB zu importieren, müssen Sie den Namen des spezifischen Attributs als Wert für den ttlAttributeName-Konfigurationsparameter in der DynamoDB-formatierten JSON-Datei oder der DynamoDB-formatierten JSON-Datei angeben, die in AWS S3-Quellkonfigurationsdateien gespeichert ist. Außerdem müssen Sie den includeTTL-Konfigurationsparameter in der Sink-Konfigurationsvorlage festlegen. Die gültigen Senken sind Oracle NoSQL Database und Oracle NoSQL Database Cloud Service. NoSQL Database Migrator speichert TTL-Informationen im JSON-Objekt _metadata für das importierte Element.
Der Importvorgang verwaltet die folgenden Anwendungsfälle bei der Migration von Tabellenelementen der exportierten JSON-Dateien von DynamoDB:
-
Anwendungsfall 1: Der ttlAttributeName-Konfigurationsparameterwert wird auf den TTL-Attributnamen gesetzt, der in der exportierten JSON-Datei von DynamoDB angegeben ist.
NoSQL Database Migrator importiert die Ablaufzeit für dieses Element als die Anzahl der Millisekunden seit der UNIX-Epoche (1. Januar 1970).
Beispiel: Ein Element in der exportierten JSON-Datei von DynamoDB:
{ "Item": { "DeptId": { "N": "1" }, "DeptName": { "S": "Engineering" }, "ttl": { "N": "1734616800" } } }Hier gibt das Attribut
ttlden Wert für die Gültigkeitsdauer für das Element an. Wenn Sie den ttlAttributeName-Konfigurationsparameter in der JSON-Datei im DynamoDB-Format oder in der JSON-Datei im DynamoDB-Format, die in der AWS S3-Quellkonfigurationsdatei gespeichert ist, alsttlfestlegen, importiert NoSQL Database Migrator die Ablaufzeit für das Element wie folgt:{ "DeptId": 1, "document": { "DeptName": "Engineering" } "_metadata": { "expiration": 1734616800000 } }
Hinweis: Sie können den Konfigurationsparameter "tttlRelativeDate" in der Sink-Konfigurationsvorlage als Referenzzeit für die Berechnung der Ablaufzeit angeben.
-
Anwendungsfall 2: Der ttlAttributeName-Konfigurationsparameterwert ist festgelegt. Der Wert ist jedoch nicht als Attribut im Element der exportierten JSON-Datei von DynamoDB vorhanden.
NoSQL Database Migrator importiert die TTL-Metadateninformationen für das angegebene Element nicht.
-
Anwendungsfall 3: Der ttlAttributeName-Konfigurationsparameterwert stimmt nicht mit dem Attributnamen im Element der exportierten JSON-Datei von DynamoDB überein. NoSQL Database Migrator verarbeitet den Import auf eine der folgenden Arten basierend auf der Sink-Konfiguration:
-
Kopiert das Attribut als normales Feld, wenn es für den Import mit dem Standardschema konfiguriert ist.
-
Überspringt das Attribut, wenn es für den Import mit einem benutzerdefinierten Schema konfiguriert ist.
-
Daten mit einer IDENTITY-Spalte in eine Spüle importieren
Erfahren Sie, wie Sie Daten in eine Spüle importieren, die eine IDENTITY-Spalte enthält.
Sie können die Daten aus einer gültigen Quelle in eine Sink-Tabelle (On-Premise/Cloud Services) mit einer IDENTITY-Spalte importieren. Sie erstellen die IDENTITY-Spalte entweder als "Immer als IDENTITY generiert" oder als "Von Standard als IDENTITY generiert". Weitere Informationen zur Tabellenerstellung mit einer IDENTITY-Spalte finden Sie unter Tabellen mit einer IDENTITY-Spalte erstellen in der SQL-Referenzdokumentation.
Stellen Sie vor dem Import der Daten sicher, dass die Oracle NoSQL Database-Tabelle in der Sink leer ist, falls sie vorhanden ist. Wenn bereits vorhandene Daten in der Sink-Tabelle vorhanden sind, kann die Migration zu Problemen führen, z.B. zum Überschreiben vorhandener Daten in der Sink-Tabelle oder zum Überspringen von Quelldaten während des Imports.
Tabelle mit IDENTITY-Spalte als IMMER GENERIERT WIE IDENTITY
Betrachten Sie eine Sink-Tabelle mit der IDENTITY-Spalte, die als GENERATED ALWAYS AS IDENTITY erstellt wurde. Der Datenimport hängt davon ab, ob die Quelle die Werte für die IDENTITY-Spalte und den Transformationsparameter ignoreFields in der Konfigurationsdatei bereitstellt.
Beispiel: Sie möchten Daten aus einer JSON-Dateiquelle als Sink in die Oracle NoSQL Database-Tabelle importieren. Das Schema der Sink-Tabelle lautet:
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED ALWAYS AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))Das Migrator-Utility verarbeitet die Datenmigration wie in den folgenden Fällen beschrieben:
| Quellbedingung | Benutzeraktion | Migrationsergebnis |
|---|---|---|
|
CASE 1: Quelldaten liefern keinen Wert für das IDENTITY-Feld der Sink-Tabelle. Beispiel: JSON-Quelldatei |
Erstellen/generieren Sie die Konfigurationsdatei. |
Datenmigration war erfolgreich. IDENTITY-Spaltenwerte werden automatisch generiert. Migrierte Daten in Oracle NoSQL Database-Sink-Tabelle |
|
FALL 2: Quelldaten liefern Werte für das IDENTITY-Feld der Sink-Tabelle. Beispiel: JSON-Quelldatei |
Erstellen/generieren Sie die Konfigurationsdatei. Sie geben eine ignoreFields-Transformation für die ID-Spalte in der Sink-Konfigurationsvorlage an.
|
Datenmigration war erfolgreich. Die angegebenen ID-Werte werden übersprungen, und die IDENTITY-Spaltenwerte werden automatisch generiert. Migrierte Daten in Oracle NoSQL Database-Sink-Tabelle |
|
Sie erstellen/generieren die Konfigurationsdatei ohne die ignoreFields-Transformation für die IDENTITY-Spalte. |
Datenmigration ist mit der folgenden Fehlermeldung nicht erfolgreich:
|
Weitere Informationen zu den Transformationskonfigurationsparametern finden Sie im Thema Vorlagen für die Transformationskonfiguration.
Sink-Tabelle mit IDENTITY-Spalte als GENERIERT VON DEFAULT ALS IDENTITY
Betrachten Sie eine Sink-Tabelle mit der IDENTITY-Spalte, die als GENERATED BY DEFAULT AS IDENTITY erstellt wurde. Der Datenimport hängt davon ab, ob die Quelle die Werte für die IDENTITY-Spalte und den Transformationsparameter ignoreFields bereitstellt.
Beispiel: Sie möchten Daten aus einer JSON-Dateiquelle als Sink in die Oracle NoSQL Database-Tabelle importieren. Das Schema der Sink-Tabelle lautet:
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED BY DEFAULT AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))Das Migrator-Utility verarbeitet die Datenmigration wie in den folgenden Fällen beschrieben:
| Quellbedingung | Benutzeraktion | Migrationsergebnis |
|---|---|---|
|
CASE 1: Quelldaten liefern keinen Wert für das IDENTITY-Feld der Sink-Tabelle. Beispiel: JSON-Quelldatei |
Erstellen/generieren Sie die Konfigurationsdatei. |
Datenmigration war erfolgreich. IDENTITY-Spaltenwerte werden automatisch generiert. Migrierte Daten in Oracle NoSQL Database-Sink-Tabelle |
|
FALL 2: Quelldaten stellen Werte für das IDENTITY-Feld der Sink-Tabelle bereit, und es handelt sich um ein Primärschlüsselfeld. Beispiel: JSON-Quelldatei |
Erstellen/generieren Sie die Konfigurationsdatei. Sie geben eine ignoreFields-Transformation für die ID-Spalte in der Sink-Konfigurationsvorlage an (empfohlen).
|
Datenmigration war erfolgreich. Die angegebenen ID-Werte werden übersprungen, und die IDENTITY-Spaltenwerte werden automatisch generiert. Migrierte Daten in Oracle NoSQL Database-Sink-Tabelle |
|
Sie erstellen/generieren die Konfigurationsdatei ohne die ignoreFields-Transformation für die IDENTITY-Spalte. |
Datenmigration war erfolgreich. Die angegebenen Wenn Sie versuchen, eine zusätzliche Zeile in die Tabelle einzufügen, ohne einen ID-Wert anzugeben, versucht der Sequence-Generator, den ID-Wert automatisch zu generieren. Der Startwert des Sequenzgenerators ist 1. Dadurch kann der generierte ID-Wert möglicherweise einen der vorhandenen ID-Werte in der Sink-Tabelle duplizieren. Da dies eine Verletzung des Primärschlüssel-Constraints ist, wird ein Fehler zurückgegeben, und die Zeile wird nicht eingefügt. Weitere Informationen finden Sie unter Sequence Generator. Um die Verletzung des Primärschlüssel-Constraints zu vermeiden, muss der Sequence-Generator die Sequence mit einem Wert beginnen, der nicht mit vorhandenen ID-Werten in der Sink-Tabelle in Konflikt steht. Informationen zum Verwenden des Attributs START WITH für diese Änderung finden Sie im folgenden Beispiel: Beispiel: Migrierte Daten in Oracle NoSQL Database-Sink-Tabelle Um den entsprechenden Wert für den Sequence-Generator zu finden, der in die ID-Spalte eingefügt werden soll, rufen Sie den Höchstwert des Feldes Ausgabe: Der Höchstwert der Spalte Dadurch wird die Sequenz bei 4 gestartet. Wenn Sie nun Zeilen in die Sink-Tabelle einfügen, ohne die ID-Werte anzugeben, generiert der Sequence-Generator die ID-Werte ab 4 automatisch, wodurch die Duplizierung der IDs abgewendet wird. |
Weitere Informationen zu den Transformationskonfigurationsparametern finden Sie im Thema Vorlagen für die Transformationskonfiguration.
Daten mit Abfrageprädikaten filtern
Erfahren Sie, wie Sie Abfrageprädikate angeben, um nur die Tabellenzeilen zu exportieren, die den Filterkriterien entsprechen.
Abfrageprädikat
NoSQL Database Migrator bietet eine Option zum Filtern von Daten während des Exports, indem ein Abfrageprädikat angegeben wird. Das Abfrageprädikat gibt Bedingungen an, die erfüllt sein müssen, damit eine Zeile exportiert werden kann. Das Migrator-Utility übersetzt das Abfrageprädikat in eine SQL WHERE-Klausel und wendet es auf die angegebene Tabelle an, um eine Filterbedingung bereitzustellen, mit der nur die Zeilen exportiert werden, die mit der angegebenen Bedingung übereinstimmen. Sie können integrierte Funktionen (modification_time(), expiration_time(), creation_time()) im Abfrageprädikat verwenden, um erweiterte Filteroptionen zu erstellen.
Sie können Abfrageprädikate nur in Oracle NoSQL Database- und Oracle NoSQL Database Cloud Service-Quellen für alle unterstützten Sinks verwenden. Weitere Informationen finden Sie unter Oracle NoSQL Database und Oracle NoSQL Database Cloud Service.
Eine Anwendungsfalldemonstration finden Sie unter Von Oracle NoSQL Database Cloud Service in eine JSON-Datei migrieren.
Filter ausgeben
Das Utility Migrator bietet eine Option, um die SQL-Abfrage zu wiederholen, die auf dem Backend ausgeführt wird. Mit diesem Feature können Sie die generierte Abfrage prüfen und bei Bedarf den Filter verfeinern, bevor Sie die Migrationsaufgabe ausführen.
Sie können das Utility Migrator mit der Dumpfilteroption wie folgt ausführen:
[~/nosqlMigrator]$./runMigrator --dump-filter|df [optional-config-file]-
Mit der Konfigurationsdatei: Das Migrator-Utility zeigt die bereitgestellte Konfigurationsdatei und die generierte Abfrage an, wie im folgenden Beispiel dargestellt:
[~/nosqlMigrator]./runMigrator --dump-filter migrator-config.json[INFO] Configuration for migration: { "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "users", "queryFilter" : "$row.address.city='Houston'", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : false, "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "pretty" : true, "dataPath" : "<complete/path/to/directory>" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] Query for the migration: 'select $row, expiration_time($row) from users $row where $row.address.city='Houston'' -
Ohne Konfigurationsdatei: Das Migrator-Utility erfasst interaktiv alle Eingaben, die zum Generieren der Konfigurationsdatei erforderlich sind, einschließlich des Abfrageprädikats. Anschließend werden die generierte Konfigurationsdatei und Abfrage angezeigt.
Hinweis:
Mit der Dumpfilteroption werden nur die Konfigurationsdatei und die Abfrage angezeigt. Die Datenmigration wird nicht initiiert. Um die Migration auszuführen, führen Sie nach der Prüfung das Utility Migrator mit der Konfigurationsdatei mit der Option
--coder--configwie folgt aus:$./runMigrator --config <complete/path/to/the/JSON/config/file>
Anwendungsfalldemonstrationen für Oracle NoSQL Database-Migrator
Erfahren Sie, wie Sie die Datenmigration mit dem Oracle NoSQL Database-Migrator für bestimmte Anwendungsfälle durchführen. Detaillierte systematische Anweisungen mit Codebeispielen für die Migration in jedem Anwendungsfall.
Dieser Artikel enthält die folgenden Themen:
Von Oracle NoSQL Database Cloud Service in eine JSON-Datei migrieren
Dieses Beispiel zeigt, wie Sie mit dem Oracle NoSQL Database-Migrator Daten und die Schemadefinition einer NoSQL-Tabelle aus Oracle NoSQL Database Cloud Service (NDCS) in eine JSON-Datei kopieren.
Anwendungsfall
Eine Organisation beschließt, ein Modell mit den Oracle NoSQL Database Cloud Service-(NDCS-)Daten zu trainieren, um zukünftiges Verhalten vorherzusagen und personalisierte Empfehlungen bereitzustellen. Sie können eine periodische Kopie der Daten der NDCS-Tabellen in eine JSON-Datei übernehmen und sie auf die Analyse-Engine anwenden, um das Modell zu analysieren und zu trainieren. Dies hilft ihnen, die analytischen Abfragen von den kritischen Pfaden mit geringer Latenz zu trennen.
Beispiel
Sehen wir uns an, wie Sie die Daten- und Schemadefinition einer NoSQL-Tabelle mit dem Namen myTable von NDCS in eine JSON-Datei migrieren.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: Oracle NoSQL Database Cloud Service
-
Sink: JSON-Datei
-
-
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten, und erfassen Sie sie in der OCI-Konfigurationsdatei. Speichern Sie die Konfigurationsdatei in
/home/.oci/config. Siehe Zugangsdaten anfordern.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Geben Sie den Regionsendpunkt und den Compartment-Namen für Oracle NoSQL Database Cloud Service an.
-
Endpunkt:
us-ashburn-1 -
Compartment:
ocid1.compartment.oc1..aa..rhsmq
-
Vorgehensweise
Um die Daten- und Schemadefinition Ihrer Tabelle von Oracle NoSQL Database Cloud Service in eine JSON-Datei zu migrieren, können Sie eine der folgenden Optionen verwenden:
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Um die Konfigurationsdatei mit dem NoSQL Database Migrator zu generieren, führen Sie den Befehl
runMigratorohne Laufzeitparameter aus.[~/nosqlMigrator]$./runMigrator -
Da Sie die Konfigurationsdatei nicht als Laufzeitparameter angegeben haben, fordert das Utility Sie auf, die Konfiguration jetzt zu generieren. Geben Sie
**y**ein.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. -
Wählen Sie basierend auf den Eingabeaufforderungen des Utilitys Ihre Optionen für die Quellkonfiguration aus.
Enter a location for your config [./migrator-config.json]: /home/<user>/nosqlMigrator/NDCS2JSON Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 2 Configuration for source type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-phoenix-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: developers Enter table name: myTable Include TTL data? If you select 'yes' TTL of rows will also be included in the exported data.(y/n) [n]: Enter percentage of table read units to be used for migration operation. (1-100) [90]: Enter store operation timeout in milliseconds. (1-30000) [5000]: -
Wählen Sie basierend auf den Eingabeaufforderungen des Utilitys Ihre Optionen für die Sink-Konfiguration aus.
Select the sink: 1) nosqldb 2) nosqldb_cloud 3) file #? 3 Configuration for sink type=file Enter path to a directory to store JSON data: /home/<user>/nosqlMigrator would you like to export data to multiple files for each source?(y/n) [y]: n Would you like to store JSON in pretty format? (y/n) [n]: y Would you like to migrate the table schema also? (y/n) [y]: y Enter path to a file to store table schema: /home/<user>/nosqlMigrator/myTableSchema -
Wählen Sie basierend auf den Prompts aus dem Utility Ihre Optionen für die Quelldatentransformationen aus. Der Standardwert ist
n.Would you like to add transformations to source data? (y/n) [n]: -
Geben Sie an, ob Sie mit der Migration fortfahren möchten, falls ein Datensatz nicht migriert werden kann.
Would you like to continue migration in case of any record/row is failed to migrate?: (y/n) [n]: -
Das Utility zeigt die generierte Konfiguration auf dem Bildschirm an.
generated configuration is: { "source": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "myTable", "compartment": "ocid1.compartment.oc1..aa..rhsmq", "credentials": "/home/<user>/.oci/config", "credentialsProfile": "DEFAULT", "readUnitsPercent": 90, "requestTimeoutMs": 5000 }, "sink": { "type": "file", "format": "json", "useMultiFiles" : false, "schemaPath": "/home/<user>/nosqlMigrator/myTableSchema", "pretty": true, "dataPath": "/home/<user>/nosqlMigrator" }, "abortOnError": true, "migratorVersion": "1.8.0" } -
Das Utility fordert Sie auf, zu entscheiden, ob Sie mit der Migration mit der generierten Konfigurationsdatei fortfahren möchten oder nicht. Die Standardoption ist
y.Hinweis: Wenn Sie
nauswählen, können Sie die Migration mit der generierten Konfigurationsdatei mit der Option./runMigrator -coder./runMigrator --configausführen.Would you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config /home/<user>/nosqlMigrator/NDCS2JSON (y/n) [y]: -
Der NoSQL Database Migrator migriert Ihre Daten und Ihr Schema von NDCS in die JSON-Datei.
Records provided by source=10,Records written to sink=10,Records failed=0,Records skipped=0. Elapsed time: 0min 1sec 277ms Migration completed.Validierung
Um die Migration zu validieren, können Sie zum angegebenen Sink-Verzeichnis navigieren und das Schema und die Daten anzeigen.
-- Exported myTable Data. JSON files are created in the supplied data path
[~/nosqlMigrator]$cat myTable_1_5.json
{
"id" : 10,
"document" : {
"course" : "Computer Science",
"name" : "Neena",
"studentid" : 105
}
}
{
"id" : 3,
"document" : {
"course" : "Computer Science",
"name" : "John",
"studentid" : 107
}
}
{
"id" : 4,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 6,
"document" : {
"course" : "Bio-Technology",
"name" : "Rekha",
"studentid" : 104
}
}
{
"id" : 7,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 5,
"document" : {
"course" : "Journalism",
"name" : "Rani",
"studentid" : 106
}
}
{
"id" : 8,
"document" : {
"course" : "Computer Science",
"name" : "Tom",
"studentid" : 103
}
}
{
"id" : 9,
"document" : {
"course" : "Computer Science",
"name" : "Peter",
"studentid" : 109
}
}
{
"id" : 1,
"document" : {
"course" : "Journalism",
"name" : "Tracy",
"studentid" : 110
}
}
{
"id" : 2,
"document" : {
"course" : "Bio-Technology",
"name" : "Raja",
"studentid" : 108
}
}-- Exported myTable Schema
[~/nosqlMigrator]$cat myTableSchema
CREATE TABLE IF NOT EXISTS myTable (id INTEGER, document JSON, PRIMARY KEY(SHARD(id)))-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den Quell- und JSON-Sink-Details von Oracle NoSQL Database Cloud Service (NDCS) vor. Siehe Quellkonfigurationsvorlagen und Verknüpfungskonfigurationsvorlagen.
In diesem Beispiel wird eine Tabelle
usersmit den folgenden Daten verwendet:{"id":10,"firstName":"John","lastName":"Smith","age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008}} {"id":20,"firstName":"Jane","lastName":"Smith","age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005}} {"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}} {"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}Stellen Sie sicher, dass Sie den Parameter
queryFiltermit dem entsprechenden Abfrageprädikat in die Quellkonfigurationsvorlage aufnehmen, um nur die erforderlichen Zeilen aus der Tabelle zu exportieren. Einzelheiten zum Erstellen von Abfrageprädikaten finden Sie in der Tabelle Beispielprädikate für Abfragen im Thema NoSQL Database Cloud-Servicequelle.In diesem Beispiel exportiert das Abfrageprädikat Zeilen mit dem Feld
cityin der JSON-Spalteaddress= 'Houston' aus der Tabelleusers.{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "queryFilter" : "$row.address.city='Houston'", "compartment" : "ocid1.compartment.oc1..aa..rhsmq", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : true, "chunkSize" : 32, "schemaPath" : "/scratch/<user>/nosqlMigrator/tableschema.ddl", "pretty" : false, "dataPath" : "/scratch/<user>/nosqlMigrator" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei übergeben. Verwenden Sie die Option--configoder-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file>Hinweis:
Sie können den Befehl auch mit dem
Option zum Anzeigen und Prüfen der generierten Abfrage, bevor die Migrationsaufgabe wie folgt ausgeführt wird. Weitere Einzelheiten finden Sie unter
.
[~/nosqlMigrator]$./runMigrator --dump-filter <complete/path/to/the/JSON/config/file>Das Utility führt die Datenmigration wie folgt durch:
[INFO] creating source from given configuration: [INFO] [cloud source] : query = 'SELECT $row,expiration_time_millis($row) AS expiration FROM users $row where $row.address.city='Houston'' [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [json file sink] : writing table schema to /scratch/raumesh/nosqlMigrator/tableschema.ddl [INFO] migration started [INFO] Migration success for source users. read=2,written=2,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 182ms Migration completed.
Verifizierung
Um die Migration zu prüfen, können Sie zum angegebenen Sink-Verzeichnis navigieren und das Schema und die Daten anzeigen. Nur die Zeilen in der JSON-Spalte address mit dem Feldwert city "Houston" werden exportiert.
-- Exported users data. Schema and JSON files are created in the supplied data paths.
[~/nosqlMigrator]: cat tableschema.ddl
CREATE TABLE IF NOT EXISTS users (id INTEGER, firstName STRING, lastName STRING, age INTEGER, income INTEGER, address JSON, PRIMARY KEY(SHARD(id)))[~/nosqlMigrator]: cat users_6_10.json
{"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}}
{"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}
bash-4.4$Von Oracle NoSQL Database On-Premise zu Oracle NoSQL Database Cloud Service migrieren
Dieses Beispiel zeigt, wie Sie mit dem Oracle NoSQL Database-Migrator Daten und die Schemadefinition einer NoSQL-Tabelle aus Oracle NoSQL Database in Oracle NoSQL Database Cloud Service (NDCS) kopieren.
Anwendungsfall
Als Entwickler untersuchen Sie Optionen, um den Overhead bei der Verwaltung der Ressourcen, Cluster und Garbage Collection für Ihre vorhandenen NoSQL Database KVStore-Workloads zu vermeiden. Als Lösung entscheiden Sie sich, Ihre vorhandenen On-Premise-KVStore-Workloads in Oracle NoSQL Database Cloud Service zu migrieren, da NDCS sie automatisch verwaltet.
Beispiel
Sehen wir uns an, wie Sie die Daten- und Schemadefinition einer NoSQL-Tabelle mit dem Namen myTable aus dem NoSQL Database KVStore in NDCS migrieren. In diesem Anwendungsfall wird auch gezeigt, wie Sie das Utility runMigrator ausführen, indem Sie eine vorab erstellte Konfigurationsdatei übergeben.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: Oracle NoSQL Database
-
Sink: Oracle NoSQL Database Cloud Service
-
-
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten, und erfassen Sie sie in der OCI-Konfigurationsdatei. Speichern Sie die Konfigurationsdatei in
/home/.oci/config. Siehe Zugangsdaten anfordern in Oracle NoSQL Database Cloud Service verwenden.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Geben Sie den Regionsendpunkt und den Compartment-Namen für Oracle NoSQL Database Cloud Service an.
-
Endpunkt:
us-phoenix-1 -
Compartment:
developers
-
-
Geben Sie die folgenden Details für den On-Premise-KVStore an:
-
storeName:
kvstore -
helperHosts:
<hostname>:5000 -
Tabelle:
myTable
-
Vorgehensweise
So migrieren Sie die Daten- und Schemadefinition von myTable von NoSQL Database KVStore zu NDCS:
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den angegebenen Quell- und Sinkdetails vor. Siehe Quellkonfigurationsvorlagen und Verknüpfungskonfigurationsvorlagen.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "myTable", "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "myTable", "compartment" : "developers", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "readUnits" : 100, "writeUnits" : 100, "storageSize" : 1 }, "credentials" : "<complete/path/to/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei mit der Option--configoder-cübergeben.[~/nosqlMigrator/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie unten gezeigt.
Records provided by source=10, Records written to sink=10, Records failed=0. Elapsed time: 0min 10sec 426ms Migration completed.
Validierung
Um die Migration zu validieren, können Sie sich bei der NDCS-Konsole anmelden und prüfen, ob myTable mit den Quelldaten erstellt wird.
Von JSON-Dateiquelle zu Oracle NoSQL Database Cloud Service migrieren
Dieses Beispiel zeigt die Verwendung des Oracle NoSQL Database-Migrators zum Kopieren von Daten aus einer JSON-Dateiquelle in Oracle NoSQL Database Cloud Service.
Nach der Auswertung mehrerer Optionen schließt eine Organisation Oracle NoSQL Database Cloud Service als NoSQL Database-Plattform ab. Da die Quellinhalte im JSON-Dateiformat vorliegen, suchen sie nach einer Möglichkeit, sie in Oracle NoSQL Database Cloud Service zu migrieren.
In diesem Beispiel lernen Sie, wie Sie die Daten aus einer JSON-Datei mit dem Namen SampleData.json migrieren. Sie führen das Utility runMigrator aus, indem Sie eine vorab erstellte Konfigurationsdatei übergeben. Wenn die Konfigurationsdatei nicht als Laufzeitparameter angegeben wird, werden Sie vom Utility runMigrator aufgefordert, die Konfiguration über eine interaktive Prozedur zu generieren.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: JSON-Quelldatei.
SampleData.jsonist die Quelldatei. Es enthält mehrere JSON-Dokumente mit einem Dokument pro Zeile, begrenzt durch ein neues Zeilenzeichen.{"id":6,"val_json":{"array":["q","r","s"],"date":"2023-02-04T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-03-04T02:38:57.520Z","numfield":30,"strfield":"foo54"},{"datefield":"2023-02-04T02:38:57.520Z","numfield":56,"strfield":"bar23"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":3,"val_json":{"array":["g","h","i"],"date":"2023-02-02T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-02T02:38:57.520Z","numfield":28,"strfield":"foo3"},{"datefield":"2023-02-02T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":7,"val_json":{"array":["a","b","c"],"date":"2023-02-20T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-01-20T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-01-22T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":4,"val_json":{"array":["j","k","l"],"date":"2023-02-03T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-03T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-02-03T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} -
Sink: Oracle NoSQL Database Cloud Service.
-
-
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten, und erfassen Sie sie in der OCI-Konfigurationsdatei. Speichern Sie die Konfigurationsdatei im Verzeichnis
/home/<user>/.oci/config. Weitere Informationen finden Sie unter Zugangsdaten anfordern in Oracle NoSQL Database Cloud Service verwenden.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Geben Sie den Regionsendpunkt und den Compartment-Namen für Oracle NoSQL Database Cloud Service an.
-
Endpunkt:
us-ashburn-1 -
Compartment:
Training-NoSQL
-
-
Geben Sie die folgenden Details für die JSON-Quelldatei an:
-
schemaPath:
<absolute path to the schema definition file containing DDL statements for the NoSQL table at the sink>.In diesem Beispiel lautet die DDL-Datei
schema_json.ddl.create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id));Der Oracle NoSQL Database-Migrator bietet eine Option zum Erstellen einer Tabelle mit dem Standardschema, wenn
schemaPathnicht angegeben ist. Weitere Informationen finden Sie im Thema Quelle und Sink identifizieren im Workflow für Oracle NoSQL Database-Migrator. -
Datenpfad:
<absolute path to a file or directory containing the JSON data for migration>.
-
Vorgehensweise
Um die JSON-Quelldatei von SampleData.json zu Oracle NoSQL Database Cloud Service zu migrieren, führen Sie folgende Schritte aus:
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den identifizierten Quell- und Sink-Details vor. Siehe Quellkonfigurationsvorlagen und Verknüpfungskonfigurationsvorlagen.
{ "source" : { "type" : "file", "format" : "json", "schemaInfo" : { "schemaPath" : "[~/nosql-migrator-1.8.0]/schema_json.ddl" }, "dataPath" : "[~/nosql-migrator-1.8.0]/SampleData.json" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "Migrate_JSON", "compartment" : "Training-NoSQL", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility Oracle NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei mit der Option--configoder-cübergeben.[~/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/config/file> -
Das Utility fährt mit der Datenmigration fort, wie unten gezeigt. Die Tabelle
Migrate_JSONwird in der Sink mit dem Schema erstellt, das inschemaPathangegeben ist.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records [json file source] : start parsing JSON records from file: SampleData.json [INFO] migration completed. Records provided by source=4, Records written to sink=4, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 778ms Migration completed.
Validierung
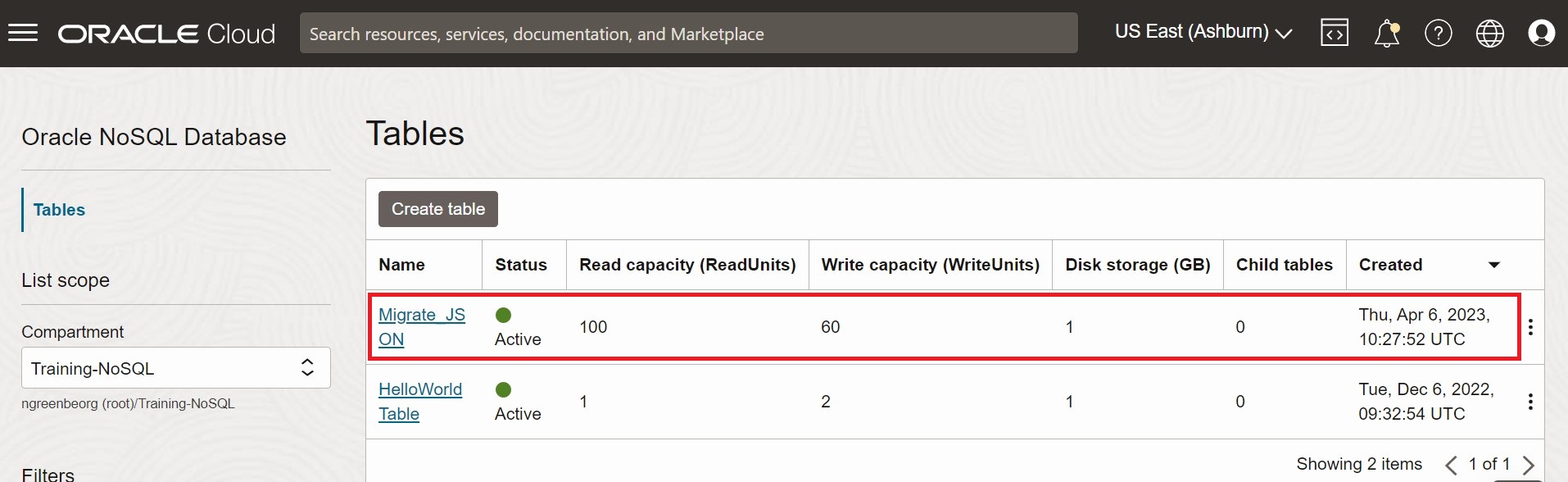
Um die Migration zu validieren, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die Tabelle Migrate_JSON mit den Quelldaten erstellt wird. Die Vorgehensweise für den Zugriff auf die Konsole finden Sie im Artikel Über die Infrastructure-Konsole auf den Service zugreifen im Oracle NoSQL Database Cloud Service-Dokument.
Abbildung - Konsolentabellen für Oracle NoSQL Database Cloud Service
Beschreibung der Abbildung "migration_json1.png"
Abbildung - Tabellendaten der Oracle NoSQL Database Cloud Service-Konsole
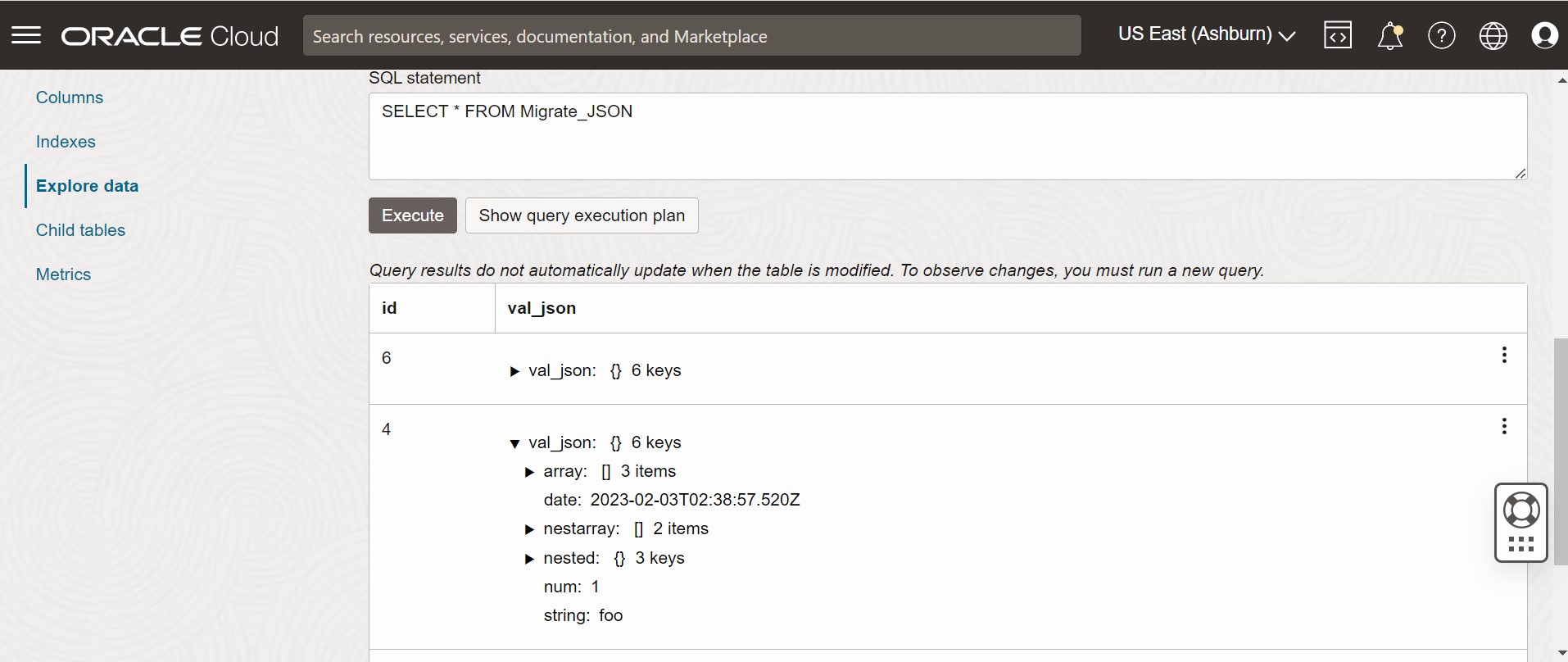
Beschreibung der Abbildung "migration_json2.png"
Von einer MongoDB-JSON-Datei zu Oracle NoSQL Database Cloud Service migrieren
Dieses Beispiel zeigt, wie Sie mit dem Oracle NoSQL Database-Migrator MongoDB-formatierte Daten in Oracle NoSQL Database Cloud Service (NDCS) kopieren.
Anwendungsfall
Nach der Auswertung mehrerer Optionen schließt eine Organisation Oracle NoSQL Database Cloud Service als NoSQL Database-Plattform ab. Die Tabellen und Daten befinden sich in MongoDB, und das Unternehmen möchte beide zu Oracle NDCS migrieren.
Sie können eine Datei oder ein Verzeichnis mit den exportierten JSON-Daten der MongoDB für die Migration kopieren, indem Sie die Datei oder das Verzeichnis in der Quellkonfigurationsvorlage angeben.
Betrachten wir die folgenden zwei JSON-Beispieldateien, die aus MongoDB exportiert wurden, um unseren Anwendungsfall zu demonstrieren.
Eine JSON-Beispieldatei im MongoDB-Format lautet wie folgt:
{"_id":0,"name":"Aimee Zank","scores":[{"score":1.463179736705023,"type":"exam"},{"score":11.78273309957772,"type":"quiz"},{"score":35.8740349954354,"type":"homework"}]}
{"_id":1,"name":"Aurelia Menendez","scores":[{"score":60.06045071030959,"type":"exam"},{"score":52.79790691903873,"type":"quiz"},{"score":71.76133439165544,"type":"homework"}]}
{"_id":2,"name":"Corliss Zuk","scores":[{"score":67.03077096065002,"type":"exam"},{"score":6.301851677835235,"type":"quiz"},{"score":66.28344683278382,"type":"homework"}]}
{"_id":3,"name":"Bao Ziglar","scores":[{"score":71.64343899778332,"type":"exam"},{"score":24.80221293650313,"type":"quiz"},{"score":42.26147058804812,"type":"homework"}]}
{"_id":4,"name":"Zachary Langlais","scores":[{"score":78.68385091304332,"type":"exam"},{"score":90.2963101368042,"type":"quiz"},{"score":34.41620148042529,"type":"homework"}]}Eine JSON-Beispieldatei im MongoDB-Format, die aus einer Spring-Anwendung exportiert wird, lautet wie folgt:
{"_id":{"$oid":"63d3a87cf564fc21dac3838d"},"firstName":"John","lastName":"Smith","address":{"Country":"France"},"_class":"com.example.demo.Customer"}
{"_id":{"$oid":"63d3a87cf564fc21dac3838e"},"firstName":"Sam","lastName":"David","address":{"Country":"USA"},"_class":"com.example.demo.Customer"}
{"_id":"3","firstName":"Dona","lastName":"William","address":{"Country":"England"},"_class":"com.example.demo.Customer"}MongoDB unterstützt zwei Typen von Erweiterungen für die formatierten JSON-Dateien, Canonical-Modus und Relaxed-Modus. Sie können die MongoDB-formatierte JSON-Datei angeben, die mit dem Tool mongoexport im Canonical- oder Relaxed-Modus generiert wird. NoSQL Database Migrator unterstützt beide Modi.
Weitere Informationen zur MongoDB Extended JSON-(v2-)Datei finden Sie unter mongoexport_formats.
Weitere Informationen zur Generierung einer MongoDB-formatierten JSON-Datei finden Sie unter mongoexport.
Beispiel
Sehen wir uns an, wie Sie eine MongoDB-formatierte JSON-Datei zu NDCS migrieren. Für dieses Beispiel wird eine manuell erstellte Konfigurationsdatei verwendet.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: MongoDB-formatierte JSON-Datei
-
Sink: Oracle NoSQL Database Cloud Service
-
- Extrahieren Sie die Daten aus MongoDB mit dem Utility mongoexport. Siehe mongoexport.
-
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten, und erfassen Sie sie in der OCI-Konfigurationsdatei. Speichern Sie die Konfigurationsdatei im Verzeichnis
/home/<user>/.oci/config. Weitere Informationen finden Sie unter Zugangsdaten anfordern.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Geben Sie den Regionsendpunkt und den Compartment-Namen für Oracle NoSQL Database Cloud Service an.
-
Endpunkt:
us-ashburn-1 -
Compartment:
ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza
-
Vorgehensweise
Um die MongoDB-formatierten JSON-Daten in Oracle NoSQL Database Cloud Service zu migrieren, können Sie eine der folgenden Optionen auswählen:
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den angegebenen Quell- und Sinkdetails vor. Siehe Quellkonfigurationsvorlagen und Verknüpfungskonfigurationsvorlagen.
Hier setzen Sie den Konfigurationsparameter
defaultSchemaauf "true". Daher erstellt NoSQL Database Migrator eine Tabelle mit dem Standardschema in der Sink.{ "source" : { "type" : "file", "format" : "mongodb_json", "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "mongoImport", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "defaultSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Das Standardschema für die MongoDB-formatierte JSON-Dateiquelle lautet wie folgt:
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id));Dabei gilt:
-
tablename= Wert für das Attributtablein der Konfiguration angegeben. -
id= Der Wert_idaus jedem Dokument der exportierten JSON-Quelldatei für MongoDB. -
document= Für jedes Dokument in der exportierten MongoDB-Datei werden die Inhalte außer dem Feld_idin der Spaltedocumentaggregiert.
Hinweis: Wenn die Tabelle
<tablename>bereits in Oracle NoSQL Database Cloud Service vorhanden ist und Sie Daten mit der KonfigurationdefaultSchemain die Tabelle migrieren möchten, müssen Sie sicherstellen, dass die vorhandene Tabelle die ID-Spalte in Kleinbuchstaben (id) und den Typ STRING aufweist. -
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei übergeben. Verwenden Sie die Option--configoder-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie unten gezeigt.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS mongoImport (id STRING, document JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 448ms Migration completed.
Verifizierung
Um die Migration zu prüfen, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die Tabelle mongoImport mit den Quelldaten erstellt wird. Informationen zum Zugriff auf die Konsole finden Sie im Artikel Über die Infrastructure-Konsole auf den Service zugreifen.
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den angegebenen Quell- und Sinkdetails vor. Siehe Quellkonfigurationsvorlagen und Verknüpfungskonfigurationsvorlagen.
Hier geben Sie die Datei mit der DDL-Anweisung der Sink-Tabelle im Parameter
schemaPathder Quellkonfigurationsvorlage an. Setzen Sie den KonfigurationsparameteruseSourceSchemain der Sink-Konfigurationsvorlage entsprechend auf "true".Sie können ein benutzerdefiniertes Schema wie folgt generieren:
-
Notieren Sie sich die Namen und Datentypen für jede Spalte aus den MongoDB-formatierten JSON-Daten. Verwenden Sie diese Informationen, um eine SchemadDL-Datei für die Oracle NoSQL Database Cloud Service-Tabelle zu erstellen.
-
Benennen Sie in der Schemadatei die erste Spalte (Primärschlüssel) als
iddes Typs STRING. Fügen Sie denselben Namen und denselben Typ für die verbleibenden Spalten ein, wie in der MongoDB-formatierten JSON-Datei aufgezeichnet. -
Speichern Sie die Schemadatei, und notieren Sie sich den vollständigen Pfad.
In diesem Beispiel wird das folgende benutzerdefinierte Schema verwendet:
CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id STRING, name STRING, scores JSON, PRIMARY KEY(SHARD(id)));Sie müssen eine
renameFields-Transformation einfügen, die NoSQL Database Migrator anweist, die Spalte_idbeim Erstellen der Tabelle inidzu konvertieren. Parameterdetails finden Sie unter Vorlagen für die Transformationskonfiguration. NoSQL Database Migrator erstellt eine Tabelle mit dem benutzerdefinierten Schema in der Sink.{ "source" : { "type" : "file", "format" : "mongodb_json", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/schema/file>" }, "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "sampleMongoDBImp", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : false, "requestTimeoutMs" : 5000 }, "transforms": { "renameFields" : { "_id":"id" } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei übergeben. Verwenden Sie die Option--configoder-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie unten gezeigt.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id INTEGER, name STRING, scores JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 438ms Migration completed.
Verifizierung
Um die Migration zu prüfen, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die Tabelle sampleMongoDBImp mit den Quelldaten erstellt wird. Informationen zum Zugriff auf die Konsole finden Sie im Artikel Über die Infrastructure-Konsole auf den Service zugreifen.
-
Für diesen Anwendungsfall verwenden wir die JSON-Beispieldatei im MongoDB-Format, die aus einer Spring-Anwendung exportiert wurde. Weitere Informationen zu diesem Format finden Sie unter Frühlingsdaten.
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den angegebenen Quell- und Sinkdetails vor. Siehe Quellkonfigurationsvorlagen und Verknüpfungskonfigurationsvorlagen.
Hier geben Sie die Datei mit der DDL-Anweisung der Sink-Tabelle im Parameter
schemaPathder Quellkonfigurationsvorlage an. Setzen Sie den KonfigurationsparameteruseSourceSchemain der Sink-Konfigurationsvorlage entsprechend auf "true".Sie können ein benutzerdefiniertes Schema wie folgt generieren:
-
Notieren Sie sich die Namen und Datentypen für jede Spalte aus den MongoDB-formatierten JSON-Daten.
-
Benennen Sie in der Schemadatei die erste Spalte (Primärschlüssel) als
iddes Typs STRING. Aggregieren Sie die restlichen Felder in einem Feld mit dem Namenkv_json_vom Typ JSON, das dem Spring-Datenformat entspricht. Weitere Informationen finden Sie unter Persistenzmodell des Spring Data Frameworks. -
Speichern Sie die Schemadatei, und notieren Sie sich den vollständigen Pfad.
In diesem Beispiel wird das folgende benutzerdefinierte Schema verwendet:
CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp(id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id)))Für das oben angegebene Spring-Datenbeispiel müssen Sie die folgenden Transformationen einschließen:
-
Transformation
renameFields, um die Spalte_idinidzu konvertieren -
ignoreFields-Transformation, um die Spalte_classzu ignorieren und nicht in die Sink-Tabelle aufzunehmen -
aggregateFields-Transformation zum Aggregieren der verbleibenden Felder (außerid) in ein Feld vom Typ JSON
Parameterdetails finden Sie unter Vorlagen für die Transformationskonfiguration. NoSQL Database Migrator erstellt eine Tabelle mit dem benutzerdefinierten Schema in der Sink.
{ "source": { "type": "file", "format": "mongodb_json", "schemaInfo": { "schemaPath": "<complete/path/to/the/schema/file>" }, "dataPath": "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "sampleMongoDBSpringImp", "compartment": "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL": true, "schemaInfo": { "readUnits": 100, "writeUnits": 60, "storageSize": 1, "useSourceSchema": true }, "credentials": "<complete/path/to/the/oci/config/file>", "credentialsProfile": "DEFAULT", "writeUnitsPercent": 90, "overwrite": false, "requestTimeoutMs": 5000 }, "transforms": { "renameFields": { "_id": "id" }, "ignoreFields": ["_class"], "aggregateFields": { "fieldName": "kv_json_", "skipFields": ["id"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei übergeben. Verwenden Sie die Option--configoder-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie unten gezeigt.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp (id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [mongo file source] : start parsing MongoDB JSON records from file: mongodbspring.json Migration success for source mongodbspring. read=3,written=3,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=3, Records written to sink=3, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 393ms Migration completed.
Verifizierung
Um die Migration zu prüfen, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die Tabelle sampleMongoDBImp mit den Quelldaten erstellt wird. Informationen zum Zugriff auf die Konsole finden Sie im Artikel Über die Infrastructure-Konsole auf den Service zugreifen.
Von einer DynamoDB-JSON-Datei zu Oracle NoSQL Database Cloud Service migrieren
In diesem Beispiel wird gezeigt, wie Sie mit dem Oracle NoSQL Database-Migrator die DynamoDB-JSON-Datei in NoSQL Database Cloud Service kopieren.
Anwendungsfall
Nach der Auswertung mehrerer Optionen schließt eine Organisation Oracle NoSQL Database Cloud Service über die DynamoDB-Datenbank ab. Die Organisation möchte ihre Tabellen und Daten von DynamoDB zu Oracle NoSQL Database Cloud Service migrieren.
Weitere Informationen finden Sie unter DynamoDB-Tabelle zu Oracle NoSQL-Tabelle zuordnen.
Sie können eine Datei oder ein Verzeichnis mit den exportierten JSON-Daten von DynamoDB aus einem Dateisystem migrieren, indem Sie den Pfad in der Quellkonfigurationsvorlage angeben.
Eine JSON-Beispieldatei im DynamoDB-Format lautet wie folgt:
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"},"ttl": {"N": "1734616800"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"},"ttl": {"N": "1734616800"}}}Sie exportieren die DynamoDB-Tabelle in den AWS S3-Speicher, wie unter DynamoDB-Tabellendaten in Amazon S3 exportieren angegeben.
Beispiel
In dieser Demonstration erfahren Sie, wie Sie eine DynamoDB-JSON-Datei in Oracle NoSQL Database Cloud Service migrieren. In diesem Beispiel verwenden Sie eine manuell erstellte Konfigurationsdatei.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: DynamoDB-JSON-Datei
-
Sink: Oracle NoSQL Database Cloud Service
-
-
Um DynamoDB-Tabellendaten in Oracle NoSQL Database zu importieren, müssen Sie zuerst die DynamoDB-Tabelle in S3 exportieren. Weitere Informationen zum Exportieren der Tabelle finden Sie unter DynamoDB-Tabellendaten in Amazon S3 exportieren. Beim Export wählen Sie das Format als DynamoDB-JSON aus. Die exportierten Daten enthalten DynamoDB-Tabellendaten in mehreren
gzip-Dateien, wie unten gezeigt./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Sie müssen die Dateien von AWS S3 herunterladen. Die Struktur der Dateien nach dem Download wird wie unten gezeigt sein.
download-dir/01639372501551-bb4dd8c3 |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten, und erfassen Sie sie in der OCI-Konfigurationsdatei. Speichern Sie die Konfigurationsdatei im Verzeichnis
/home/<user>/.oci/config. Weitere Informationen finden Sie unter Zugangsdaten anfordern in Oracle NoSQL Database Cloud Service verwenden.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Geben Sie den Regionsendpunkt und den Compartment-Namen für Oracle NoSQL Database Cloud Service an.
-
Endpunkt:
us-ashburn-1 -
Compartment:
Training-NoSQL
-
Vorgehensweise
So migrieren Sie die DynamoDB-JSON-Daten in Oracle NoSQL Database:
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den identifizierten Quell- und Sink-Details vor. Weitere Informationen finden Sie unter Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen.
Hinweis: Wenn die exportierten JSON-Tabellenelemente von DynamoDB ein TTL-Attribut enthalten und optional die TTL-Werte importiert werden sollen, geben Sie das Attribut im Konfigurationsparameter
ttlAttributeNameder Quellkonfigurationsvorlage an, und setzen Sie den KonfigurationsparameterincludeTTLin der Sink-Konfigurationsvorlage auf "true". Weitere Informationen finden Sie unter TTL-Metadaten für Tabellenzeilen migrieren.Hier setzen Sie den Konfigurationsparameter
defaultSchemaauf "true". Daher erstellt der NoSQL-Datenbankmigrator das Standardschema in der Sink. Sie müssenDDBPartitionKeyund den entsprechenden NoSQL-Spaltentyp angeben. Andernfalls wird ein Fehler angezeigt.Details zum Standardschema für eine exportierte JSON-Quelle von DynamoDB finden Sie im Thema "Quelle und Sink identifizieren" unter Workflow für Oracle NoSQL Data Migrator.
{ "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }In diesem Beispiel wird das folgende Standardschema verwendet:
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) -
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie separate Konfigurationsdateien übergeben. Verwenden Sie die Option--configoder-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie im folgenden Beispiel dargestellt:
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Verifizierung
Um die Migration zu validieren, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die Tabelle sampledynDBImp mit den Quelldaten erstellt wird.
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den identifizierten Quell- und Sink-Details vor. Weitere Informationen finden Sie unter Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen.
Hinweis: Wenn die exportierten JSON-Tabellenelemente von DynamoDB ein TTL-Attribut enthalten und optional die TTL-Werte importiert werden sollen, geben Sie das Attribut im Konfigurationsparameter
ttlAttributeNameder Quellkonfigurationsvorlage an, und setzen Sie den KonfigurationsparameterincludeTTLin der Sink-Konfigurationsvorlage auf "true".Hier setzen Sie den Konfigurationsparameter
defaultSchemaauf "false". Daher geben Sie die Datei mit der DDL-Anweisung der Sink-Tabelle im ParameterschemaPathan. Weitere Informationen finden Sie unter DynamoDB-Typen zu Oracle NoSQL-Typen zuordnen.In diesem Beispiel wird das folgende benutzerdefinierte Schema verwendet:
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id)))NoSQL Database Migrator verwendet die Schemadatei, um die Tabelle in der Sink im Rahmen der Migration zu erstellen. Solange die Primärschlüsseldaten bereitgestellt werden, wird der JSON-Eingabedatensatz eingefügt. Andernfalls wird ein Fehler angezeigt.
Hinweis:
-
Wenn die Dynamo-DB-Tabelle einen Datentyp aufweist, der in NoSQL Database nicht unterstützt wird, verläuft die Migration nicht erfolgreich.
-
Wenn die Eingabedaten keinen Wert für eine bestimmte Spalte (außer dem Primärschlüssel) enthalten, wird der Spaltenstandardwert verwendet. Der Standardwert muss beim Erstellen der Tabelle Teil der Spaltendefinition sein. Beispiel:
id INTEGER not null default 0. Wenn die Spalte keine Standarddefinition aufweist, wird SQL NULL eingefügt, wenn keine Werte für die Spalte angegeben werden. -
Wenn Sie die DynamoDB-Tabelle als JSON-Dokument modellieren, stellen Sie sicher, dass Sie die
AggregateFields-Transformation verwenden, um nicht primäre Schlüsseldaten in eine JSON-Spalte zu aggregieren. Weitere Informationen finden Sie unter aggregateFields
Generated configuration is { "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie separate Konfigurationsdateien übergeben. Verwenden Sie die Option--configoder-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie im folgenden Beispiel dargestellt:
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Verifizierung
Um die Migration zu validieren, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die Tabelle sampledynDBImp mit den Quelldaten erstellt wird.
Migration von DynamoDB-JSON-Datei in AWS S3 zu Oracle NoSQL Database Cloud Service
In diesem Beispiel wird gezeigt, wie Sie mit Oracle NoSQL Database Migrator die in einem AWS S3-Speicher gespeicherte JSON-Datei von DynamoDB in Oracle NoSQL Database Cloud Service (NDCS) kopieren.
Anwendungsfall:
Nach der Auswertung mehrerer Optionen schließt eine Organisation Oracle NoSQL Database Cloud Service über die DynamoDB-Datenbank ab. Die Organisation möchte ihre Tabellen und Daten von DynamoDB zu Oracle NoSQL Database Cloud Service migrieren.
Weitere Informationen finden Sie unter DynamoDB-Tabelle der Oracle NoSQL-Tabelle zuordnen.
Sie können eine Datei mit den exportierten JSON-Daten von DynamoDB aus dem AWS S3-Speicher migrieren, indem Sie den Pfad in der Quellkonfigurationsvorlage angeben.
Eine JSON-Beispieldatei im DynamoDB-Format lautet wie folgt:
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"}}}Sie exportieren die DynamoDB-Tabelle in den AWS S3-Speicher, wie unter DynamoDB-Tabellendaten in Amazon S3 exportieren angegeben.
Beispiel:
In dieser Demonstration lernen Sie, wie Sie eine DynamoDB-JSON-Datei in einer AWS-S3-Quelle zu NDCS migrieren. In diesem Beispiel verwenden Sie eine manuell erstellte Konfigurationsdatei.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle:DynamoDB-JSON-Datei in AWS S3
-
Sink: Oracle NoSQL Database Cloud Service
-
-
Identifizieren Sie die Tabelle in AWS DynamoDB, die zu NDCS migriert werden muss. Melden Sie sich mit Ihren Zugangsdaten bei Ihrer AWS-Konsole an. Gehen Sie zu DynamoDB. Wählen Sie unter Tabellen die zu migrierende Tabelle.
-
Erstellen Sie einen Objekt-Bucket, und exportieren Sie die Tabelle in S3. Gehen Sie von Ihrer AWS-Konsole zu S3. Erstellen Sie unter "Buckets" einen neuen Objekt-Bucket. Gehen Sie zurück zu DynamoDB, und klicken Sie auf In S3 exportieren. Geben Sie die Quelltabelle und den S3-Ziel-Bucket an, und klicken Sie auf Exportieren.
Anweisungen zum Exportieren der Tabelle finden Sie unter DynamoDB-Tabellendaten in Amazon S3 exportieren. Beim Export wählen Sie das Format DynamoDB-JSON aus. Die exportierten Daten enthalten DynamoDB-Tabellendaten in mehreren
gzip-Dateien, wie unten gezeigt./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Sie benötigen AWS-Zugangsdaten (einschließlich Zugriffsschlüssel-ID und Secret Access Key) und Konfigurationsdateien (Zugangsdaten und optional Konfiguration), um über den NoSQL Database Migrator auf AWS S3 zuzugreifen. Weitere Informationen zu den Konfigurationsdateien finden Sie unter Konfigurationseinstellungen festlegen und anzeigen. Weitere Informationen zum Erstellen von Zugriffsschlüsseln finden Sie unter Schlüsselpaare erstellen.
-
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten, und erfassen Sie sie in der OCI-Konfigurationsdatei. Speichern Sie die Konfigurationsdatei in einem Verzeichnis
.ociunter Ihrem Home-Verzeichnis (~/.oci/config). Weitere Informationen finden Sie unter Zugangsdaten anfordern.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Geben Sie den Regionsendpunkt und den Compartment-Namen für Oracle NoSQL Database Cloud Service an. Beispiel:
-
Endpunkt:us-phoenix-1
-
Compartment: Entwickler
-
Vorgehensweise
Um die DynamoDB-JSON-Daten in Oracle NoSQL Database Cloud Service zu migrieren, verwenden Sie eine der folgenden Optionen:
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den identifizierten Quell- und Sink-Details vor. Weitere Informationen finden Sie unter Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen.
Hinweis: Wenn die Elemente in der DynamoDB-JSON-Datei in AWS S3 das TTL-Attribut enthalten und optional die TTL-Werte importieren, geben Sie das Attribut im Konfigurationsparameter
ttlAttributeNameder Quellkonfigurationsvorlage an, und setzen Sie den KonfigurationsparameterincludeTTLin der Sink-Konfigurationsvorlage auf True. Weitere Informationen finden Sie unter TTL-Metadaten für Tabellenzeilen migrieren.Setzen Sie
defaultSchemaaufTRUE, sodass das Migrator-Utility das Standardschema in der Sink erstellt. Sie müssenDDBPartitionKeyund den entsprechenden NoSQL-Spaltentyp angeben. Andernfalls wird ein Fehler ausgelöst.{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : true, "readUnits" : 100, "writeUnits" : 60, "DDBPartitionKey" : "<PrimaryKey:Datatype>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Für eine DynamoDB-JSON-Quelle wird das Standardschema für die Tabelle wie folgt angezeigt:
CREATE TABLE IF NOT EXISTS <TABLE_NAME>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type], DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))Dabei gilt:
TABLE_NAME = für die Senke 'table' in der Konfiguration angegebener Wert
DDBPartitionKey_name = Wert für den Partitionsschlüssel in der Konfiguration angegeben
DDBPartitionKey_type = Wert für den Datentyp des Partitionsschlüssels in der Konfiguration
DDBSortKey_name = Wert, der für den Sortierschlüssel in der Konfiguration angegeben wird, sofern vorhanden
DDBSortKey_type = Wert für den Datentyp des Sortierschlüssels in der Konfiguration, sofern vorhanden
DOCUMENT = Alle Attribute mit Ausnahme des Partitions- und Sortierschlüssels eines Dynamo DB-Tabellenelements, das in einer NoSQL-JSON-Spalte aggregiert wird
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei übergeben. Verwenden Sie die Option--configoder-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie unten gezeigt.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Verifizierung
Sie können sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die neue Tabelle mit den Quelldaten erstellt wurde.
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den identifizierten Quell- und Sink-Details vor. Weitere Informationen finden Sie unter Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen.
Hinweis: Wenn die Elemente in der DynamoDB-JSON-Datei in AWS S3 das TTL-Attribut enthalten und optional die TTL-Werte importieren, geben Sie das Attribut im ttlAttributeName-Konfigurationsparameter der Quellkonfigurationsvorlage an, und setzen Sie den includeTTL-Konfigurationsparameter in der Sink-Konfigurationsvorlage auf "true". Weitere Informationen finden Sie unter TTL-Metadaten für Tabellenzeilen migrieren.
Um eine benutzerdefinierte Schemadatei in der Sink-Konfigurationsvorlage anzugeben, setzen Sie defaultSchema auf
FALSE, und geben Sie schemaPath als Datei an, die Ihre DDL-Anweisung enthält. Weitere Informationen finden Sie unter DynamoDB-Typen Oracle NoSQL-Typen zuordnen.Hinweis: Wenn die Dynamo-DB-Tabelle einen Datentyp aufweist, der in NoSQL nicht unterstützt wird, verläuft die Migration nicht erfolgreich.
Eine Beispielschemadatei wird unten angezeigt.
CREATE TABLE IF NOT EXISTS sampledynDBImp (AccountId INTEGER,document JSON, PRIMARY KEY(SHARD(AccountId)));Die Schemadatei wird verwendet, um die Tabelle in der Sink im Rahmen der Migration zu erstellen. Solange die Primärschlüsseldaten bereitgestellt werden, wird der JSON-Eingabedatensatz eingefügt. Andernfalls wird ein Fehler ausgegeben.
Hinweis:
- Wenn die Eingabedaten keinen Wert für eine bestimmte Spalte (außer dem Primärschlüssel) enthalten, wird der Spaltenstandardwert verwendet. Der Standardwert muss bei der Erstellung der Tabelle Teil der Spaltendefinition sein. Beispiel:
id INTEGER not null default 0. Wenn die Spalte keine Standarddefinition enthält, wird SQL NULL eingefügt, wenn keine Werte für die Spalte angegeben sind. - Wenn Sie die DynamoDB-Tabelle als JSON-Dokument modellieren, stellen Sie sicher, dass Sie die
AggregateFields-Transformation verwenden, um nicht primäre Schlüsseldaten in eine JSON-Spalte zu aggregieren. Weitere Einzelheiten finden Sie unter aggregateFields.
{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : false, "readUnits" : 100, "writeUnits" : 60, "schemaPath" : "<full path of the schema file with the DDL statement>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "transforms": { "aggregateFields" : { "fieldName" : "document", "skipFields" : ["AccountId"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } - Wenn die Eingabedaten keinen Wert für eine bestimmte Spalte (außer dem Primärschlüssel) enthalten, wird der Spaltenstandardwert verwendet. Der Standardwert muss bei der Erstellung der Tabelle Teil der Spaltendefinition sein. Beispiel:
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei übergeben. Verwenden Sie die Option--configoder-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
Das Utility fährt mit der Datenmigration fort, wie unten gezeigt.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Verifizierung
Sie können sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und prüfen, ob die neue Tabelle mit den Quelldaten erstellt wurde.
Zwischen Oracle NoSQL Database Cloud Service-Regionen migrieren
In diesem Beispiel wird die Verwendung von Oracle NoSQL Database Migrator zur regionsübergreifenden Migration gezeigt.
Anwendungsfall
Eine Organisation speichert und verwaltet ihre Daten mit Oracle NoSQL Database Cloud Service. Sie beschließt, Daten aus einer vorhandenen Region zu Testzwecken in eine neuere Region zu replizieren, bevor die neue Region für die Produktionsumgebung gestartet werden kann.
In diesem Anwendungsfall lernen Sie, wie Sie mit dem NoSQL Database Migrator Daten aus der Tabelle user_data in der Region Ashburn in die Region Phoenix kopieren.
Sie führen das Utility runMigrator aus, indem Sie eine vorab erstellte Konfigurationsdatei übergeben. Wenn Sie die Konfigurationsdatei nicht als Laufzeitparameter angeben, werden Sie vom Utility runMigrator aufgefordert, die Konfiguration über eine interaktive Prozedur zu generieren.
Voraussetzungen
-
Laden Sie den Oracle NoSQL Database-Migrator von der Seite Oracle NoSQL-Downloads herunter, und extrahieren Sie den Inhalt auf Ihrem Rechner. Weitere Informationen finden Sie unter Workflow für Oracle NoSQL Database-Migrator.
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: Die Tabelle
user_datain der Region Ashburn.Die Tabelle
user_dataenthält die folgenden Daten:{"id":40,"firstName":"Joanna","lastName":"Smith","otherNames":[{"first":"Joanna","last":"Smart"}],"age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085},"connections":[70,30,40],"email":"joanna.smith123@reachmail.com","communityService":"**"} {"id":10,"firstName":"John","lastName":"Smith","otherNames":[{"first":"Johny","last":"Good"},{"first":"Johny2","last":"Brave"},{"first":"Johny3","last":"Kind"},{"first":"Johny4","last":"Humble"}],"age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008},"connections":[30,55,43],"email":"john.smith@reachmail.com","communityService":"****"} {"id":20,"firstName":"Jane","lastName":"Smith","otherNames":[{"first":"Jane","last":"BeGood"}],"age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005},"connections":[40,75,63],"email":"jane.smith201@reachmail.com","communityService":"*****"} {"id":30,"firstName":"Adam","lastName":"Smith","otherNames":[{"first":"Adam","last":"BeGood"}],"age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075},"connections":[60,45,73],"email":"adam.smith201reachmail.com","communityService":"***"}Geben Sie entweder den Regionsendpunkt oder den Serviceendpunkt und den Compartment-Namen für die Quelle an.
-
Endpunkt:
us-ashburn-1 -
Compartment:
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Sink: Die Tabelle
user_datain der Region Phoenix.Geben Sie entweder den Regionsendpunkt oder den Serviceendpunkt und den Compartment-Namen für die Sink an.
-
Endpunkt:
us-phoenix-1 -
Compartment:
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Geben Sie das Schema der Sink-Tabelle an.
Sie können denselben Tabellennamen und dasselbe Schema wie die Quelltabelle verwenden. Weitere Informationen zu anderen Schemaoptionen finden Sie im Thema Quelle und Sink identifizieren in Workflow für Oracle NoSQL Database-Migrator.
-
-
-
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten für beide Regionen, und erfassen Sie sie in der Konfigurationsdatei. Speichern Sie die Konfigurationsdatei auf Ihrem Rechner im Verzeichnis
/home/<user>/.oci/config. Weitere Informationen finden Sie unter Zugangsdaten anfordern.Hinweis:
-
Wenn sich die Regionen unter verschiedenen Mandanten befinden, müssen Sie verschiedene Profile in der Datei
/home//.oci/configmit den entsprechenden OCI-Cloud-Zugangsdaten für jede dieser Regionen angeben. -
Wenn sich die Regionen unter demselben Mandanten befinden, kann ein einzelnes Profil in der Datei
/home//.oci/configvorhanden sein.
-
In diesem Beispiel befinden sich die Regionen unter verschiedenen Mandanten. Das DEFAULT-Profil enthält OCI-Zugangsdaten für die Region Ashburn, und DEFAULT2 enthält OCI-Zugangsdaten für die Region Phoenix.
Im Parameter endpoint der Migrationskonfigurationsdatei (sowohl Quell- als auch Sink-Konfigurationsvorlagen) können Sie die Serviceendpunkt-URL oder die Regions-ID der Regionen angeben. Eine Liste der für Oracle NoSQL Database Cloud Service unterstützten Datenregionen und der zugehörigen Serviceendpunkt-URLs finden Sie unter Datenregionen und zugehörige Service-URLs im Oracle NoSQL Database Cloud Service-Dokument.
[DEFAULT]
user=ocid1.user.oc1....
fingerprint=fd:96:....
tenancy=ocid1.tenancy.oc1....
region=us-ashburn-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=abcd
[DEFAULT2]
user=ocid1.user.oc1....
fingerprint=1b:68:....
tenancy=ocid1.tenancy.oc1....
region=us-phoenix-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=23456Vorgehensweise
Um die Tabelle user_data aus der Region Ashburn in die Region Phoenix zu migrieren, führen Sie die folgenden Schritte aus:
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit den identifizierten Quell- und Sink-Details vor. Siehe Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen.
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 100, "includeTTL" : false, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT2", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Navigieren Sie auf Ihrem Rechner zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben. Sie können über die Befehlszeilenschnittstelle auf den Befehl
runMigratorzugreifen. -
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei mit der Option –config oder -c übergeben.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
Das Utility fährt mit der Datenmigration wie unten gezeigt fort. Die Tabelle
user_datawird in der Sink mit demselben Schema wie die Quelltabelle erstellt, da Sie den Parameter useSourceSchema in der Sink-Konfigurationsvorlage als "true" konfiguriert haben.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS user_data (id INTEGER, firstName STRING, lastName STRING, otherNames ARRAY(RECORD(first STRING, last STRING)), age INTEGER, income INTEGER, address JSON, connections ARRAY(INTEGER), email STRING, communityService STRING, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 603ms Migration completed.Hinweis:
-
Wenn die Tabelle bereits in der Sink mit demselben Schema wie die Quelltabelle vorhanden ist, werden die Zeilen mit denselben Primärschlüsseln überschrieben, da Sie den Überschreibparameter in der Konfigurationsvorlage als "true" angegeben haben.
-
Wenn die Tabelle bereits in der Senke mit einem anderen Schema als der Quelltabelle vorhanden ist, verläuft die Migration nicht erfolgreich.
-
Validierung
Um die Migration zu validieren, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole in der Region Phoenix anmelden. Prüfen Sie, ob die Quelldaten aus der Tabelle user_data in der Region Ashburn in die Tabelle user_data in dieser Region kopiert werden. Informationen zum Zugriff auf die Konsole finden Sie im Artikel Über die Infrastructure-Konsole auf den Service zugreifen.
Von Oracle NoSQL Database Cloud Service zu OCI Object Storage migrieren
Dieses Beispiel zeigt die Verwendung des Oracle NoSQL Database-Migrators aus einer Cloud Shell.
Anwendungsfall
Ein Start-up-Unternehmen plant, Oracle NoSQL Database Cloud Service als Datenspeicherlösung zu verwenden. Das Unternehmen möchte mit Oracle NoSQL Database Migrator Daten aus einer Tabelle in Oracle NoSQL Database Cloud Service in OCI Object Storage kopieren, um ihre Daten regelmäßig zu sichern. Als kostengünstige Kennzahl möchten sie das NoSQL Database Migrator-Utility aus der Cloud Shell ausführen, auf das alle OCI-Benutzer zugreifen können.
In diesem Anwendungsfall lernen Sie, wie Sie das Utility NoSQL Database Migrator in eine Cloud Shell in der abonnierten Region kopieren und eine Datenmigration durchführen. Sie migrieren die Quelldaten aus der Oracle NoSQL Database Cloud Service-Tabelle in eine JSON-Datei im OCI Object Storage.
Sie führen das Utility runMigrator aus, indem Sie eine vorab erstellte Konfigurationsdatei übergeben. Wenn Sie die Konfigurationsdatei nicht als Laufzeitparameter angeben, werden Sie vom Utility runMigrator aufgefordert, die Konfiguration über eine interaktive Prozedur zu generieren.
Voraussetzungen
-
Laden Sie den Oracle NoSQL Database-Migrator von der Seite Oracle NoSQL-Downloads auf Ihren lokalen Rechner herunter.
-
Starten Sie Cloud Shell über das Menü Entwicklungstools in der Cloud-Konsole. Der Webbrowser öffnet Ihr Home-Verzeichnis. Klicken Sie oben rechts im Cloud Shell-Fenster auf das Cloud Shell-Menü, und wählen Sie in der Dropdown-Liste die Option Upload aus. Verschieben Sie im Popup-Fenster das Oracle NoSQL Database Migrator-Package per Drag-and-Drop von Ihrem lokalen Rechner, oder klicken Sie auf die Option Von Ihrem Rechner auswählen, wählen Sie das Package auf Ihrem lokalen Rechner aus, und klicken Sie auf die Schaltfläche Hochladen. Sie können das Oracle NoSQL Database-Migrator-Package auch per Drag-and-Drop direkt von Ihrem lokalen Rechner in das Home-Verzeichnis in der Cloud Shell verschieben. Extrahieren Sie den Inhalt des Packages.
-
Identifizieren Sie die Quelle und Sink für das Backup.
-
Quelle: Tabelle
NDCSuploadin der Region Ashburn von Oracle NoSQL Database Cloud Service.Bei der Demonstration sollten Sie die folgenden Daten in der Tabelle
NDCSuploadberücksichtigen:{"id":1,"name":"Jane Smith","email":"iamjane@somemail.co.us","age":30,"income":30000.0} {"id":2,"name":"Adam Smith","email":"adam.smith@mymail.com","age":25,"income":25000.0} {"id":3,"name":"Jennifer Smith","email":"jenny1_smith@mymail.com","age":35,"income":35000.0} {"id":4,"name":"Noelle Smith","email":"noel21@somemail.co.us","age":40,"income":40000.0}Identifizieren Sie den Endpunkt und die Compartment-ID für die Quelle. Für den Endpunkt können Sie entweder die Regions-ID oder den Serviceendpunkt angeben. Eine Liste der in Oracle NoSQL Database Cloud Service unterstützten Datenregionen finden Sie unter Datenregionen und zugehörige Service-URLs.
-
Endpunkt:
us-ashburn-1 -
Compartment-ID:
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Sink: JSON-Datei im OCI Object Storage-Bucket.
Identifizieren Sie den Regionsendpunkt, den Namespace, den Bucket und das Präfix für OCI Object Storage. Weitere Informationen finden Sie unter Auf Oracle Cloud Object Storage zugreifen. Die Liste der OCI Object Storage-Serviceendpunkte finden Sie unter Object Storage-Endpunkte.
-
Endpunkt:
us-ashburn-1 -
Bucket:
Migrate_oci -
Präfix:
Delegation -
Namespace: <> Wenn Sie keinen Namespace angeben, verwendet das Utility den Standard-Namespace des Mandanten.
Hinweis: Wenn sich der Objektspeicher-Bucket in einem anderen Compartment befindet, stellen Sie sicher, dass Sie über die Berechtigungen zum Schreiben von Objekten im Bucket verfügen. Weitere Informationen zum Festlegen der Policys finden Sie unter Objekte in Object Storage schreiben.
-
-
Vorgehensweise
Um von Oracle NoSQL Database Cloud Service zu OCI Object Storage zu migrieren, führen Sie im Cloud Shell-Fenster Folgendes aus:
-
Bereiten Sie eine Migrator-Konfigurationsdatei
migrator-config.jsonmit der Oracle NoSQL Database Cloud Service-Quelle und der OCI Object Storage-Senke vor. Informationen zu Vorlagen finden Sie unter Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen. Stellen Sie sicher, dass Sie den ParameteruseDelegationTokenin Quell- und Sink-Konfigurationsvorlagen auftruesetzen.In diesem Anwendungsfall wird die folgende Konfigurationsvorlage verwendet:
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "NDCSupload", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "useDelegationToken" : true, "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "Delegation", "chunkSize" : 32, "compression" : "", "useDelegationToken" : true }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Navigieren Sie in der Cloud Shell zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl
runMigratoraus, indem Sie die Konfigurationsdatei mit der Option--configoder-cübergeben.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
Das Utility NoSQL Database Migrator fährt mit der Datenmigration fort. Wenn Sie den Parameter "useDelegationToken" auf true gesetzt haben, authentifiziert sich die Cloud Shell automatisch mit dem Delegationstoken, während das Utility "NoSQL Database Migrator" ausgeführt wird. Der NoSQL-Datenbankmigrator kopiert Ihre Daten aus der Tabelle
NDCSuploadin eine JSON-Datei im Objektspeicher-BucketMigrate_oci. Prüfen Sie die Logs auf ein erfolgreiches Datenbackup.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [OCI OS sink] : writing table schema to Delegation/Schema/schema.ddl [INFO] [OCI OS sink] : start writing records with prefix Delegation [INFO] migration completed. Records provided by source=4,Records written to sink=4,Records failed=0. Elapsed time: 0min 0sec 486ms Migration completed.Hinweis:
Die Daten werden in die Datei
Migrate_oci/NDCSupload/Delegation/Data/000000.jsonkopiert.Je nach Parameter chunkSize in der Sink-Konfigurationsvorlage können die Quelldaten in mehrere JSON-Dateien im selben Verzeichnis aufgeteilt werden.
Das Schema wird in die folgende Datei kopiert:
Migrate_oci/NDCStable1/Delegation/Schema/schema.ddl
Validierung
Um das Datenbackup zu validieren, melden Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole an. Navigieren Sie durch die Menüs Storage > Object Storage & Archive Storage > Buckets. Greifen Sie über das Verzeichnis NDCSupload/Delegation im Bucket Migrate_oci auf die Dateien zu. Informationen zum Zugriff auf die Konsole finden Sie im Artikel Über die Infrastructure-Konsole auf den Service zugreifen.
Mit OKE-Authentifizierung von OCI Object Storage zu Oracle NoSQL Database Cloud Service migrieren
In diesem Beispiel wird gezeigt, wie Sie mit dem Oracle NoSQL Database-Migrator mit OKE-Workload-Identitätsauthentifizierung Daten aus einer JSON-Datei in der OCI Object Storage-Tabelle in Oracle NoSQL Database Cloud Service kopieren.
Anwendungsfall
Als Entwickler untersuchen Sie eine Option zum Wiederherstellen von Daten aus einer JSON-Datei im OCI Object Storage-(OCI OS-)Bucket in der Oracle NoSQL Database Cloud Service-(NDCS-)Tabelle mit NoSQL Database Migrator in einer containerisierten Anwendung. Eine Containerisierte Anwendung ist eine virtualisierte Umgebung, in der die Anwendung und alle ihre Abhängigkeiten (wie Bibliotheken, Binärdateien und Konfigurationsdateien) in einem Package gebündelt werden. Dadurch kann die Anwendung unabhängig von der zugrunde liegenden Infrastruktur konsistent in verschiedenen Umgebungen ausgeführt werden.
Sie möchten NoSQL Database Migrator in einem Oracle Cloud Infrastructure Container Engine for Kubernetes-(OKE-)Pod ausführen. Um über den OKE-Pod sicher auf OCI-BS- und NDCS-Services zuzugreifen, verwenden Sie die Workload Identity Authentication-(WIA-)Methode.
In dieser Demonstration erstellen Sie ein Docking-Image für NoSQL Database Migrator, kopieren das Image in ein Repository in der Container Registry, erstellen ein OKE-Cluster und stellen das Migrator-Image im OKE-Clusterpod bereit, um das Utility Migrator auszuführen. Hier geben Sie eine manuell erstellte NoSQL Database Migrator-Konfigurationsdatei an, um das Migrator-Utility als containerisierte Anwendung auszuführen.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: JSON-Dateien und Schemadatei im OCI-BS-Bucket.
Identifizieren Sie den Regionsendpunkt, den Namespace, den Bucket und das Präfix für den OCI-BS-Bucket, in dem die Quell-JSON-Dateien und das Quellschema verfügbar sind. Weitere Informationen finden Sie unter Auf Oracle Cloud Object Storage zugreifen. Die Liste der OCI-BS-Serviceendpunkte finden Sie unter Object Storage-Endpunkte.
-
Endpunkt:
us-ashburn-1 -
Bucket:
Migrate_oci -
Präfix:
userSession -
Namespace:
idhkv1iewjzj
Der Namespace-Name für einen Bucket stimmt mit dem Namespace seines Mandanten überein und wird beim Erstellen Ihres Mandanten automatisch generiert. Sie können den Namespace-Namen wie folgt abrufen:
-
Navigieren Sie in der Oracle NoSQL Database Cloud Service-Konsole zu Speicher > Buckets.
-
Wählen Sie das Compartment unter Listengeltungsbereich aus, und wählen Sie den Bucket aus. Auf der Seite "Bucket-Details" wird der Name im Namespace-Parameter angezeigt.
Wenn Sie keinen OCI-BS-Namespace-Namen angeben, verwendet das Migrator-Utility den Standard-Namespace des Mandanten.
-
-
Sink: Tabelle
usersin Oracle NoSQL Database Cloud Service.Geben Sie entweder den Regionsendpunkt oder den Serviceendpunkt und den Compartment-Namen für die Sink an:
-
Endpunkt:
us-ashburn-1 -
Compartment:
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Geben Sie das Schema der Sink-Tabelle an.
Um den Tabellennamen und das im OCI-BS-Bucket gespeicherte Schema zu verwenden, setzen Sie den Parameter
useSourceSchemaauf "true". Weitere Informationen zu anderen Schemaoptionen finden Sie im Thema "Quelle und Sink identifizieren" in Workflow für Oracle NoSQL Database-Migrator.Hinweis: Stellen Sie sicher, dass Sie über die Schreibberechtigungen für das Compartment verfügen, in dem Sie Daten in der NDCS-Tabelle wiederherstellen. Weitere Informationen finden Sie unter Compartments verwalten.
-
-
-
Bereiten Sie ein Docker-Image für NoSQL Database Migrator vor, und verschieben Sie es in Container Registry.
-
Rufen Sie den Mandanten-Namespace über die OCI-Konsole ab.
Melden Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole an. Wählen Sie in der Navigationsleiste das Menü Profil und dann Mandant: <Mandantenname> aus.
Kopieren Sie den Object Storage-Namespace-Namen (den Mandanten-Namespace) in die Zwischenablage.
-
Erstellen Sie ein Docker-Image für das Migrator-Utility.
Navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben. Das Migrator-Package enthält eine Docker-Datei namens Dockerfile. Verwenden Sie über eine Befehlsschnittstelle den folgenden Befehl, um ein Docker-Image des Migrator-Utilitys zu erstellen:
#Command: docker build -t nosqlmigrator:<tag> .#Example: docker build -t nosqlmigrator:1.0 .Sie können eine Versions-ID für das Docker-Image in der Option
tagangeben. Prüfen Sie Ihr Docker-Image mit dem folgenden Befehl:#Command: Docker images#Example output ------------------------------------------------------------------------------------------ REPOSITORY TAG IMAGE ID CREATED SIZE localhost/nosqlmigrator 1.0 e1dcec27a5cc 10 seconds ago 487 MB quay.io/podman/hello latest 83fc7ce1224f 10 months ago 580 kB docker.io/library/openjdk 17-jdk-slim 8a3a2ffec52a 2 years ago 406 MB ------------------------------------------------------------------------------------------ -
Generieren Sie ein Autorisierungstoken.
Sie benötigen ein Authentifizierungstoken, um sich bei der Container Registry anzumelden und das Migrator-Docker-Image zu speichern. Wenn Sie noch kein Authentifizierungstoken haben, müssen Sie eines generieren. Weitere Informationen finden Sie unter Authentifizierungstoken abrufen.
-
Speichern Sie das Migrator-Docker-Image in Container Registry.
Um über den Kubernetes-Pod auf das Migrator-Docker-Image zuzugreifen, müssen Sie das Image in einer öffentlichen oder privaten Registry speichern. Beispiel: Docker, Artifact Hub, OCI Container Registry usw. sind einige Registrys. In dieser Demonstration verwenden wir Container Registry. Weitere Informationen finden Sie unter Überblick über Container Registry.
-
Erstellen Sie in der OCI-Konsole ein Repository in der Container Registry. Weitere Informationen finden Sie unter Repository erstellen.
Für diese Demonstration erstellen Sie das Repository
okemigrator.Abbildung - Repository in Container Registry
-
Melden Sie sich über die Befehlsschnittstelle mit dem folgenden Befehl bei der Container Registry an:
#Command: docker login <region-key>.ocir.io -u <tenancy-namespace>/<user name>password: <Auth token>#Example: docker login iad.ocir.io -u idhx..xxwjzj/rx..xxxxh@oracle.com password: <Auth token>#Output: Login Succeeded!Im obigen Befehl gilt Folgendes:
region-key: Gibt den Schlüssel für die Region an, in der Sie Container Registry verwenden. Weitere Informationen finden Sie unter Verfügbarkeit nach Region.tenancy-namespace: Gibt den Mandanten-Namespace an, den Sie aus der OCI-Konsole kopiert haben.user name: Gibt den Benutzernamen der OCI-Konsole an.password: Gibt das Authentifizierungstoken an. -
Taggen und übertragen Sie Ihr Migrator-Docker-Image mit den folgenden Befehlen in Container Registry:
#Command: docker tag <Migrator Docker image> <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag> docker push <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag>#Example: docker tag localhost/nosqlmigrator:1.0 iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 docker push iad.ocir.io/idhx..xxwjzj/okemigrator:1.0Im obigen Befehl gilt Folgendes:
repo: Gibt den Namen des Repositorys an, das Sie in Container Registry erstellt haben.tag: Gibt die Versions-ID für das Docker-Image an.#Output: Getting image source signatures Copying blob 0994dbbf9a1b done | Copying blob 37849399aca1 done | Copying blob 5f70bf18a086 done | Copying blob 2f263e87cb11 done | Copying blob f941f90e71a8 done | Copying blob c82e5bf37b8a done | Copying blob 2ad58b3543c5 done | Copying blob 409bec9cdb8b done | Copying config e1dcec27a5 done | Writing manifest to image destination
-
-
-
Konfigurieren Sie ein OKE-Cluster mit WIA zu NDCS und OCI OS.
-
Erstellen Sie ein Kubernetes-Cluster mit OKE.
Definieren und erstellen Sie in der OCI-Konsole ein Kubernetes-Cluster basierend auf der Verfügbarkeit von Netzwerkressourcen mit OKE. Sie benötigen ein Kubernetes-Cluster, um das Migrator-Utility als containerisierte Anwendung auszuführen. Details zur Clustererstellung finden Sie unter Kubernetes-Cluster mit Konsolenworkflows erstellen.
Für diese Demonstration können Sie ein verwaltetes Cluster mit einem Knoten mit dem im obigen Link beschriebenen Workflow "Schnellerstellung" erstellen.
Abbildung - Kubernetes-Cluster für Migratorcontainer
-
Richten Sie WIA über die OCI-Konsole ein, um über das Kubernetes-Cluster auf andere OCI-Ressourcen zuzugreifen.
Um Migrator-Utilityzugriff auf NDCS- und OCI-BS-Bucket bei der Ausführung über die Kubernetes-Clusterpods zu erteilen, müssen Sie WIA einrichten. Gehen Sie wie folgt vor:
-
Richten Sie die kubeconfig-Konfigurationsdatei des Clusters ein.
-
Öffnen Sie in der OCI-Konsole das von Ihnen erstellte Kubernetes-Cluster, und klicken Sie auf die Schaltfläche Auf Cluster zugreifen.
-
Klicken Sie im Dialogfeld Auf Cluster zugreifen auf Cloud Shell-Zugriff.
-
Klicken Sie auf Cloud Shell starten, um das Cloud Shell-Fenster anzuzeigen.
-
Führen Sie den Oracle Cloud Infrastructure-CLI-Befehl zum Einrichten der kubeconfig-Datei aus. Sie können den Befehl im Dialogfeld Auf Cluster zugreifen kopieren. Sie können die folgende Ausgabe erwarten:
#Example: oci ce cluster create-kubeconfig --cluster-id ocid1.cluster.oc1.iad.aaa...muqzq --file $HOME/.kube/config --region us-ashburn-1 --token-version 2.0.0 --kube-endpoint PUBLIC_ENDPOINT#Output: New config written to the Kubeconfig file /home/<user>/.kube/config
-
-
Kopieren Sie die OCID des Clusters aus der Option
cluster-idim obigen Befehl, und speichern Sie sie, um sie in weiteren Schritten zu verwenden.ocid1.cluster.oc1.iad.aaa...muqzq -
Erstellen Sie einen Namespace für den Kubernetes-Serviceaccount mit dem folgenden Befehl im Cloud-Shellfenster:
#Command: kubectl create namespace <namespace-name>#Example: kubectl create namespace migrator#Output: namespace/migrator created -
Erstellen Sie einen Kubernetes-Serviceaccount für die Migrator-Anwendung in einem Namespace mit dem folgenden Befehl im Cloud-Shellfenster:
#Command: kubectl create serviceaccount <service-account-name> --namespace <namespace-name>#Example: kubectl create serviceaccount migratorsa --namespace migrator#Output: serviceaccount/migratorsa created -
Definieren Sie eine IAM-Policy über die OCI-Konsole, damit die Workload über das Kubernetes-Cluster auf die OCI-Ressourcen zugreifen kann.
Navigieren Sie in der OCI-Konsole durch die Menüs Identität und Sicherheit > Identität > Policys. Erstellen Sie die folgenden Policys, um den Zugriff auf
nosql-family- undobject-family-Ressourcen zuzulassen. Verwenden Sie die OCID der Cluster-, Namespace- und Serviceaccountwerte aus den vorherigen Schritten.#Command: Allow <subject> to <verb> <resource-type> in <location> where <conditions>#Example: Allow any-user to manage nosql-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'} Allow any-user to manage object-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'}Weitere Informationen zum Erstellen von Policys finden Sie unter Policy mit der Konsole erstellen.
-
-
Vorgehensweise
Um aus der JSON-Datei im OCI-BS-Bucket in die NDCS-Tabelle zu migrieren, führen Sie im Cloud Shell-Fenster Folgendes aus:
-
Bereiten Sie eine Migrator-Konfigurationsdatei,
migrator-config.json, mit OCI-BS-Quelle und NDCS-Senke vor. Informationen zu Vorlagen finden Sie unter Quellkonfigurationsvorlagen und Sinkkonfigurationsvorlagen.Um OKE WIA für den Zugriff auf OCI-BS-Bucket und NDCS zu verwenden, setzen Sie den Parameter
useOKEWorkloadIdentitysowohl in Quell- als auch in Sink-Konfigurationsvorlagen auf "true". Hier verwenden Sie das Quellschema aus der Schema-DDL-Datei im OCI-BS-Bucket. Setzen Sie daher den ParameteruseSourceSchemain der Sink-Konfigurationsvorlage auf "true".Hinweis: Wenn Sie OKE WIA verwenden, können Sie die Migrator-Konfigurationsdatei nicht interaktiv generieren. Sie müssen die Konfigurationsdatei manuell vorbereiten, indem Sie sich auf die Vorlagen für die Quell- und Sink-Konfiguration beziehen.
{ "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Erstellen Sie eine Konfigurationszuordnungsressource (configmap), um die
migrator-config.json-Konfigurationseingabedatei zur Laufzeit im Kubernetes-Pod an den Migrator-Container zu übergeben. Die Konfigurationsdatei Migrator wird im Dateisystem des Containers als Mount Volume gemountet.#Command: kubectl create configmap oci-migrator-config --from-file=<Migrator configuration file> -n <namespace-name>#Example: kubectl create configmap oci-migrator-config --from-file=migrator-config.json -n migrator#Output: configmap/oci-migrator-config created -
Erstellen Sie ein Docker-Registry Secret, das die OCI-Zugangsdaten enthält, die beim Abrufen des Migrator-Docker-Images aus Container Registry in den Kubernetes-Pod verwendet werden sollen.
#Command: kubectl create secret docker-registry ocirsecret --docker-server=<region-key>.ocir.io --docker-username='tenancy-namespace/username' --docker-password='auth token' --docker-email='<user Email>' -n <namespace-name>#Example: kubectl create secret docker-registry ocirsecret --docker-server=iad.ocir.io --docker-username='idhx..xxwjzj/rx..xxxxh@oracle.com' --docker-password='<Auth token>' --docker-email='rx..xxxxh@oracle.com' -n migrator#Output: secret/ocirsecret created -
Erstellen Sie eine Manifestdatei, mit der Sie das Migrator-Docker-Image angeben. Stellen Sie sicher, dass Sie die Werte aus den vorherigen Schritten für Namespace, Kubernetes-Serviceaccountname, Docker-Imagename, Docker-Registry Secret und configmap angeben. Sie können die folgende Beispielmanifestdatei referenzieren:
#migrator-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nosql-migrator spec: replicas: 1 selector: matchLabels: app: nosql-migrator template: metadata: labels: app: nosql-migrator spec: serviceAccountName: migratorsa automountServiceAccountToken: true containers: - name: nosqlmigrator image: iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 imagePullPolicy: Always args: ["--config", "/config/migrator-config.json", "--log-level", "DEBUG"] volumeMounts: - name: config-volume mountPath: /config # Mount the file here imagePullSecrets: - name: ocirsecret volumes: - name: config-volume configMap: name: oci-migrator-config -
Stellen Sie das Docker-Image des Migrators im Kubernetes-Pod mit dem folgenden Befehl bereit. OKE führt das Utility Migrator in einem Container auf einem der Knoten des Kubernetes-Clusters aus.
#Command: kubectl create -f <manifest file> -n <namespace-name>#Example: kubectl create -f migrator-deployment.yaml -n migrator#Output: deployment.apps/nosql-migrator created -
Sie können die Logs mit den folgenden Befehlen prüfen:
-
Rufen Sie den Podnamen ab, auf dem das Migrator-Utility ausgeführt wird.
#Command: kubectl get pods -n <namespace-name>#Example: kubectl get pods -n migrator#Output: NAME READY STATUS RESTARTS AGE nosql-migrator-ccdbf549-6sjjg 1/1 Running 0 56s -
Verwenden Sie den Podnamen, um die Migratorlogs abzurufen.
#Command: kubectl logs -f <kubernetes cluster pod name> -n <namespace-name>#Example: kubectl logs -f nosql-migrator-ccdbf549-6sjjg -n migrator#Output: SLF4J(I): Connected with provider of type [org.apache.logging.slf4j.SLF4JServiceProvider] [INFO] Configuration for migration: { "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : completed loading DDLs [INFO] [cloud sink] : start loading records [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_1_5_0.json [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_6_10_0.json [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 1sec 15ms Migration completed.
Hinweis:
Sie können die Datenmigration wie folgt iterativ ausführen:
-
Löschen Sie den Container
nosql-migratormit dem folgenden Befehl:#Command: kubectl delete -f <manifest file> -n <namespace-name>#Example: kubectl delete -f migrator-deployment.yaml -n migrator#Output: deployment.apps "nosql-migrator" deleted -
Aktualisieren Sie die Konfigurationseingabedatei
migrator-config.json. -
Löschen und erstellen Sie die configmap mit den Befehlen aus Schritt 2 neu.
Es ist nicht erforderlich, das Docker-Registry Secret und die Manifestdatei erneut zu erstellen.
-
Stellen Sie das Docker-Image des Migrators im Kubernetes-Pod mit der Manifestdatei bereit (Schritt 5).
-
Verifizierung
Um die Datenwiederherstellung zu prüfen, melden Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole an. Navigieren Sie in der Navigationsleiste zu Datenbanken > NoSQL Database. Wählen Sie Ihr Compartment in der Dropdown-Liste aus, um die Tabelle users anzuzeigen. Informationen zum Zugriff auf die Konsole finden Sie unter Über die Infrastructure-Konsole auf den Service zugreifen.
Mit Sessiontokenauthentifizierung von Oracle NoSQL Database zu OCI Object Storage migrieren
In diesem Beispiel wird gezeigt, wie Sie Oracle NoSQL Database Migrator mit Sessiontokenauthentifizierung verwenden, um Daten aus der Oracle NoSQL Database-Tabelle in eine JSON-Datei in einem OCI Object Storage-Bucket zu kopieren.
Anwendungsfall
Als Entwickler untersuchen Sie eine Option zum Sichern von Oracle NoSQL Database-Tabellendaten in OCI Object Storage (OCI-BS). Sie möchten die tokenbasierte Sessionauthentifizierung verwenden.
In dieser Demonstration verwenden Sie die OCI Command Line Interface-Befehle (CLI), um ein Sessiontoken zu erstellen. Sie erstellen manuell eine Migrator-Konfigurationsdatei und führen die Datenmigration aus.
Voraussetzungen
-
Identifizieren Sie Quelle und Sink für die Migration.
-
Quelle: Tabelle
usersin Oracle NoSQL Database. -
Sink: JSON-Datei im OCI-BS-Bucket
Identifizieren Sie Endpunkt, Namespace, Bucket und Präfix der Region für das OCI-BS. Weitere Informationen finden Sie unter Auf Oracle Cloud Object Storage zugreifen. Die Liste der OCI-BS-Serviceendpunkte finden Sie unter Object Storage-Endpunkte.
-
Endpunkt:
us-ashburn-1 -
Bucket:
Migrate_oci -
Präfix:
userSession -
Namespace:
idhkv1iewjzjDer Namespace-Name für einen Bucket stimmt mit dem Namespace des Mandanten überein und wird beim Erstellen Ihres Mandanten automatisch generiert. Sie können den Namespace-Namen wie folgt abrufen:
-
Navigieren Sie in der Oracle NoSQL Database Cloud Service-Konsole zu Speicher > Buckets.
-
Wählen Sie im Listengeltungsbereich das Compartment aus, und wählen Sie den Bucket aus. Auf der Seite Bucket-Details wird der Name im Parameter Namespace angezeigt.
Wenn Sie keinen OCI-BS-Namespace-Namen angeben, verwendet das Migrator-Utility den Standard-Namespace des Mandanten.
-
-
Hinweis: Stellen Sie sicher, dass Sie über die Berechtigungen zum Schreiben von Objekten im OCI-BS-Bucket verfügen. Weitere Informationen zum Festlegen der Policys finden Sie unter In Object Storage schreiben.
-
Generieren Sie ein Sessiontoken wie folgt:
-
OCI-CLI installieren und konfigurieren Siehe Schnellstart.
-
Verwenden Sie einen der folgenden OCI-CLI-Befehle, um ein Sessiontoken zu generieren. Weitere Informationen zu den verfügbaren Optionen finden Sie unter Tokenbasierte Authentifizierung für die CLI.
# Create a session token using OCI CLI from a web browser: oci session authenticate --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --region us-ashburn-1 --profile-name SESSIONPROFILEOder
# Create a session token using OCI CLI without a web browser: oci session authenticate --no-browser --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --no-browser --region us-ashburn-1 --profile-name SESSIONPROFILEFühren Sie im obigen Befehl folgende Schritte aus:
region_name: Gibt den Regionsendpunkt für Ihr OCI-BS an. Eine Liste der in Oracle NoSQL Database Cloud Service unterstützten Datenregionen finden Sie unter Datenregionen und zugehörige Service-URLs.profile_name: Gibt das Profil an, mit dem der OCI-CLI-Befehl ein Sessiontoken generiert.Der OCI-CLI-Befehl erstellt einen Eintrag in der OCI-Konfigurationsdatei unter dem Pfad
$HOME/.oci/config, wie im folgenden Beispiel dargestellt:[SESSIONPROFILE] fingerprint=f1:e9:b7:e6:25:ff:fe:05:71:be:e8:aa:cc:3d:0d:23 key_file=$HOME/.oci/sessions/SESSIONPROFILE/oci_api_key.pem tenancy=ocid1.tenancy.oc1..aaaaa ... d6zjq region=us-ashburn-1 security_token_file=$HOME/.oci/sessions/SESSIONPROFILE/tokenDie
security_token_fileverweist auf den Pfad des Sessiontokens, das Sie mit dem oben angegebenen OCI-CLI-Befehl generiert haben.Hinweis:
-
Wenn das Profil bereits in der OCI-Konfigurationsdatei vorhanden ist, überschreibt der OCI-CLI-Befehl das Profil bei der Generierung des Sessiontokens mit der Sessiontoken-Konfiguration.
-
Geben Sie Folgendes in der Sink-Konfigurationsvorlage an:
-
Der Pfad zur OCI-Konfigurationsdatei im Parameter "Zugangsdaten".
-
Das Profil, das beim Generieren des Sessiontokens im Parameter "zugangsdatenProfile" verwendet wird.
"credentials" : "$HOME/.oci/config" "credentialsProfile" : "SESSIONPROFILE"Das Migrator-Utility ruft automatisch die Details des Sessiontokens ab, das mit den oben genannten Parametern generiert wurde. Wenn Sie den Parameter für Zugangsdaten nicht angeben, sucht das Migrator-Utility nach der Zugangsdatendatei im Pfad
$HOME/.oci. Wenn Sie den Parameter "zugangsdatenProfile" nicht angeben, verwendet das Migrator-Utility den Standardprofilnamen (DEFAULT) aus der OCI-Konfigurationsdatei.- Das Sessiontoken ist 60 Minuten lang gültig. Um die Sessiondauer zu verlängern, können Sie die Session aktualisieren. Weitere Informationen finden Sie unter Token aktualisieren.
-
-
Vorgehensweise
So migrieren Sie von der Oracle NoSQL Database-Tabelle in eine JSON-Datei im OCI-BS-Bucket:
-
Bereiten Sie die Konfigurationsdatei (im JSON-Format) mit der Oracle NoSQL Database-Quelle und der JSON-Datei in der OCI-BS-Bucket-Senke vor. Informationen zu Vorlagen finden Sie unter Quellkonfigurationsvorlagen und Konfigurationsvorlagen verknüpfen.
Um die Sessiontokenauthentifizierung für den Zugriff auf den OCI-BS-Bucket zu verwenden, setzen Sie den Parameter useSessionToken in der Sink-Konfigurationsvorlage auf "true". Geben Sie entsprechend den Konfigurationspfad im Parameter "Zugangsdaten" und den Profilnamen im Parameter "ZugangsdatenProfile" an.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:<port>"], "table" : "users", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "chunkSize" : 32, "compression" : "", "useSessionToken" : true, "credentials" : "$/home/.oci/config", "credentialsProfile" : "SESSIONPROFILE" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility NoSQL Database Migrator extrahiert haben.
-
Führen Sie den Befehl runMigrator aus, indem Sie die Konfigurationsdatei übergeben. Verwenden Sie die Option
--configoder-c, um die Konfigurationsdatei wie folgt zu übergeben:./runMigrator --config ./migrator-config.json -
Das Migrator-Utility fährt mit der Datenmigration fort. Eine Beispielausgabe ist unten dargestellt.
Wenn der Parameter useSessionToken auf "true" gesetzt ist, authentifiziert das Migrator-Utility automatisch mit dem Sessiontoken. Das Migrator-Utility kopiert Ihre Daten aus der Tabelle
usersin eine JSON-Datei im OCI-BS-BucketMigrate_oci. Prüfen Sie die Logs auf ein erfolgreiches Datenbackup.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [OCI OS sink] : writing table schema to userSession/Schema/schema.ddl [INFO] migration started [INFO] Migration success for source users_6_10. read=2,written=2,failed=0 [INFO] Migration success for source users_1_5. read=3,written=3,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 982ms Migration completed.Hinweis:
Je nach Parameter chunkSize in der Sink-Konfigurationsvorlage teilt das Migrator-Utility die Quelldaten in mehrere JSON-Dateien im selben Verzeichnis auf. In diesem Beispiel kopiert das Migrator-Utility Daten in die Dateien
users_1_5_0.jsonundusers_6_10_0.jsonim VerzeichnisMigrate_oci/userSession/Data.Das Quelltabellenschema wird in die Datei
schema.ddlim VerzeichnisMigrate_oci/userSession/Schemakopiert.
Verifizierung
Um das Datenbackup zu prüfen, melden Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole an. Navigieren Sie durch die Menüs, Storage > Object Storage & Archive Storage > Buckets. Greifen Sie über das Verzeichnis userSession im Bucket Migrate_oci auf die Dateien zu. Informationen zum Zugriff auf die Konsole finden Sie unter Über die Infrastructure-Konsole auf den Service zugreifen
Von CSV-Datei zu Oracle NoSQL Database Cloud Service migrieren
In diesem Beispiel wird die Verwendung von Oracle NoSQL Database Migrator zum Kopieren von Daten aus einer CSV-Datei in Oracle NoSQL Database Cloud Service gezeigt.
Beispiel
Nach der Auswertung mehrerer Optionen schließt eine Organisation Oracle NoSQL Database Cloud Service als NoSQL Database-Plattform ab. Da die Quellinhalte im CSV-Dateiformat vorliegen, suchen sie nach einer Möglichkeit, sie in Oracle NoSQL Database Cloud Service zu migrieren.
In diesem Beispiel lernen Sie, die Daten aus einer CSV-Datei namens course.csv zu migrieren, die Informationen zu verschiedenen Kursen enthält, die von einer Universität angeboten werden. Sie generieren die Konfigurationsdatei interaktiv mit dem Utility runMigrator.
Sie können die Konfigurationsdatei auch mit den identifizierten Quell- und Sink-Details vorbereiten. Siehe Oracle NoSQL Database-Migrator-Referenz.
Voraussetzungen
-
Identifizieren Sie die Quelle für die Migration.
-
Quelle: CSV-Datei
In diesem Beispiel lautet die Quelldatei
course.csv1,"Computer Science", "San Francisco", "2500" 2,"Bio-Technology", "Los Angeles", "1200" 3,"Journalism", "Las Vegas", "1500" 4,"Telecommunication", "San Francisco", "2500" -
Die CSV-Datei muss dem Format
RFC4180entsprechen. -
Erstellen Sie eine Datei mit den DDL-Befehlen für das Schema der Zieltabelle,
course. Die Tabellendefinition muss mit der CSV-Datendatei hinsichtlich der Anzahl der Spalten und ihrer Typen übereinstimmen.In diesem Beispiel lautet die DDL-Datei
mytable_schema.ddlcreate table course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id));
-
-
Identifizieren Sie die Sink für die Migration.
-
Sink: Oracle NoSQL Database Cloud Service
-
Identifizieren Sie Ihre OCI-Cloud-Zugangsdaten, und erfassen Sie sie in der Konfigurationsdatei. Speichern Sie die Konfigurationsdatei in
/home/<user>/.oci/config. Weitere Informationen finden Sie unter Zugangsdaten anfordern.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Geben Sie den Regionsendpunkt und den Compartment-Namen für Oracle NoSQL Database Cloud Service an.
-
Endpunkt:
us-ashburn-1 -
Compartment:
ocid1.compartment.oc1..aaaaaaaavjikiwmylfnpofefbdaleg6rqyf7cdnr5o6vozg4lyajeunrhsmq
-
-
Vorgehensweise
Um Daten aus der Datei course.csv in Oracle NoSQL Database Cloud Service zu migrieren, führen Sie die folgenden Schritte aus:
-
Öffnen Sie die Eingabeaufforderung, und navigieren Sie zu dem Verzeichnis, in das Sie das Utility Oracle NoSQL Database Migrator extrahiert haben.
-
Um die Konfigurationsdatei mit dem Oracle NoSQL Database-Migrator zu generieren, führen Sie den Befehl
runMigratorohne Laufzeitparameter aus.[~/nosql-migrator-1.8.0]$./runMigrator -
Da Sie die Konfigurationsdatei nicht als Laufzeitparameter angegeben haben, fordert das Utility Sie auf, die Konfiguration jetzt zu generieren. Geben Sie
yein.Sie können einen Speicherort für die Konfigurationsdatei auswählen oder den Standardspeicherort beibehalten, indem Sie auf
Enter keyklicken.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. Enter a location for your config [./migrator-config.json]: ./migrator-config.json already exist. Do you want to overwrite?(y/n) [n]: y -
Wählen Sie basierend auf den Eingabeaufforderungen des Utilitys Ihre Optionen für die Quellkonfiguration aus.
Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 3 Configuration for source type=file Select the source file format: 1) json 2) mongodb_json 3) dynamodb_json 4) csv #? 4 -
Geben Sie den Pfad zur CSV-Quelldatei an. Darüber hinaus können Sie basierend auf den Prompts des Utilitys die Spaltennamen neu anordnen, die Codierungsmethode auswählen und die Tailing-Bereiche aus der Zieltabelle kürzen.
Enter path to a file or directory containing csv data: [~/nosql-migrator]/course.csv Does the CSV file contain a headerLine? (y/n) [n]: n Do you want to reorder the column names of NoSQL table with respect to CSV file columns? (y/n) [n]: n Provide the CSV file encoding. The supported encodings are: UTF-8,UTF-16,US-ASCII,ISO-8859-1. [UTF-8]: Do you want to trim the tailing spaces? (y/n) [n]: n -
Wählen Sie basierend auf den Eingabeaufforderungen des Utilitys die Option
nosqldb_cloudfür die Sink-Konfiguration aus.Select the sink: 1) nosqldb 2) nosqldb_cloud #? 2 -
Geben Sie die Endpunkt-URL oder Regions-ID Ihres Mandanten an, und wählen Sie den Authentifizierungstyp für das Migrator-Utility für den Zugriff auf Oracle NoSQL Database Cloud Service aus.
Configuration for sink type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-ashburn-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 -
Geben Sie basierend auf den Eingabeaufforderungen des Utilitys den Namen der Zugangsdatendatei an, die für die Authentifizierung verwendet werden soll, das Zugangsdatenprofil, die Compartment-ID und den Namen der Tabelle, in die Daten in der Sink kopiert werden sollen.
Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: ua_nosql Enter table name: course -
Geben Sie Ihre Auswahl ein, um den TTL-Wert festzulegen. Der Standardwert ist
n.Include TTL data? If you select 'yes' TTL value provided by the source will be set on imported rows. (y/n) [n]: y Would you like to provide TTL reference time?(y/n) [n]: n -
Geben Sie basierend auf den Prompts aus dem Utility an, ob die Zieltabelle mit dem Oracle NoSQL Database Migrator-Tool erstellt werden muss. Wenn die Tabelle bereits erstellt wurde, wird empfohlen,
nanzugeben. Wenn die Tabelle nicht erstellt wird, fordert das Utility den Pfad für die Datei mit den DDL-Befehlen für das Schema der Zieltabelle an.Would you like to create table as part of migration process? Use this option if you want to create table through the migration tool. If you select yes, you will be asked to provide a file that contains table DDL or to use schema provided by the source or default schema. (y/n) [n]: y Enter path to a file containing table DDL: [~/nosql-migrator]/mytable_schema.ddl -
Geben Sie die Durchsatzwerte und die Speicherzuweisung für die Sink-Tabelle ein.
Would you like to use on demand read and write units? (y/n) [n]: n Enter read throughput in KB of new table: 100 Enter write throughput in KB of new table: 60 Enter storage size in GB of new table: 1 Enter percentage of table write units to be used for migration operation. (1-100) [90]: 90 -
Geben Sie Ihre Auswahl ein, um zu bestimmen, ob die Datensätze überschrieben werden sollen, wenn die Tabelle bereits in der Spüle verfügbar ist. Sie können auch Transformationen zu den Quelldaten hinzufügen.
would you like to overwrite records which are already present? If you select 'no' records with same primary key will be skipped [y/n] [y]: y Enter store operation timeout in milliseconds. [5000]: Would you like to add transformations to source data? (y/n) [n]: n Would you like to continue migration if any data fails to be migrated? (y/n) [n]: n -
Das Utility zeigt die generierte Konfiguration auf dem Bildschirm an.
{ "source" : { "type" : "file", "format" : "csv", "dataPath" : "[~/nosql-migrator]/course.csv", "hasHeader" : false, "csvOptions" : { "encoding" : "UTF-8", "trim" : false } }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "course", "compartment" : "ua_nosql", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "schemaPath" : "[~/nosql-migrator]/mytable_schema.ddl" }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Schließlich werden Sie vom Utility aufgefordert, anzugeben, ob die Migration mit der generierten Konfigurationsdatei fortgesetzt werden soll. Die Standardoption ist
y.Hinweis:
Wenn Sie
nauswählen, wird die Datenmigration nicht initiiert. Die generierte Konfigurationsdatei wird im Verzeichnis Migrator gespeichert. Verwenden Sie einen der folgenden Befehle, um das Migrationsutility mit der Option "Konfigurationsdatei" auszuführen../runMigrator -c ./migrator-config.json./runMigrator --config ./migrator-config.jsonWould you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config ./migrator-config.json (y/n) [y]: y -
Der NoSQL-Datenbankmigrator kopiert Ihre Daten aus der CSV-Datei in Oracle NoSQL Database Cloud Service.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table if not exists course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [csv file source] : start parsing CSV records from file: course.csv Migration success for source course. read=4,written=4,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=4, Records written to sink=4, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 395ms Migration completed.
Verifizierung
Um die Migration zu prüfen, können Sie sich bei der Oracle NoSQL Database Cloud Service-Konsole anmelden und auf die Tabelle course zugreifen. Die Tabelle enthält die Quelldaten. Die Vorgehensweise für den Zugriff auf die Konsole finden Sie im Artikel Über die Infrastructure-Konsole auf den Service zugreifen im Oracle NoSQL Database Cloud Service-Dokument.