Develop Applications with Oracle Database API for MongoDB
Considerations when developing or migrating applications — a combination of (1) how-to information and (2) descriptions of differences and possible adjustments.
Indexing and Performance Tuning
Oracle AI Database offers multiple technologies to accelerate queries over JSON data, including indexes, materialized views, in-memory column storage, and Exadata storage-cell pushdown. Which performance-tuning approaches you take depend on the needs of your application.
If your Oracle AI Database compatible parameter is 23 or greater, then you can use MongoDB index operations createIndex and dropIndex to automatically create and drop the relevant Oracle indexes. If parameter compatible parameter is less than 23, then such MongoDB index operations are not supported; they are ignored.
Regardless of your database release you can create whatever Oracle Database indexes you need directly, using (1) the JSON Page of Using Oracle AI Database Actions (see Creating Indexes for JSON Collections), (2) Simple Oracle Document Access (SODA), or (3) SQL — see Indexes for JSON Data in Oracle AI Database JSON Developer’s Guide. Using the JSON page is perhaps the easiest approach to indexing JSON data.
MongoDB allows different collections in the same “database” to have indexes of the same name. This is not allowed in Oracle AI Database — the name of an index must be unique across all collections of a given database schema (“database”).
Consider, for example, indexing a collection, named orders, of purchase-order documents such as this one:
{ "PONumber" : 1600,
"User" : "ABULL",
"LineItems" : [{ "Part" : { "Description" : "One Magic Christmas",
"UnitPrice" : 19.95,
"UPCCode" : 13131092899 },
"Quantity" : 9.0 },
{ "Part" : { "Description" : "Lethal Weapon",
"UnitPrice" : 19.95,
"UPCCode" : 85391628927
},
"Quantity" : 5.0 } ]}Two important use cases are (1) indexing a singleton scalar field, that is, a field that occurs only once in a document (2) indexing a scalar field in objects within the elements of an array. Indexing the value of field PONumber is an example of the first case. Indexing the value of field UPCCode is an example of the second case.
Example 2-1, Example 2-2, and Example 2-3 illustrate the first case. Example 2-5 illustrates the second case.
You can also index GeoJSON (spatial) data, using a function-based SQL index that returns SDO_GEOMETRY data. And for all JSON data you can create a JSON search index, and then perform full-text queries using SQL/JSON condition json_textcontains.
Example 1 Indexing a Singleton Scalar Field Using the JSON Page of Database Actions
To create an index for field PONumber using the JSON Page, do the following.
-
Right-click the collection name (
orders) and select Indexes from the popup menu.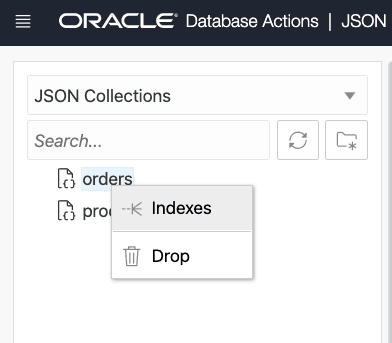
Description of the illustration json_page_create_index_001.png
- In the New Index page:
-
Type * in the Properties search box.
This populates the Properties list with paths to all scalar fields in your collection. These paths are provided by sampling the collection data using a JSON data guide — see JSON_DATAGUIDE in Oracle AI Database SQL Language Reference.
If you turn on option Advanced, by pushing its slider to the right, then the types of the listed scalar fields are also shown. The types shown are those picked up by sampling the collection. But you can change the type of a field for indexing purposes.
-
Select the paths of the fields to be indexed. In this case we want only a single scalar field indexed,
PONumber, so select that.Note: This dialog box lets you select multiple paths. If you select more than one path then a composite index is created for the data at those paths.Foot 1 But if you want to index two different fields separately then create two indexes, not one composite index (which indexes both fields together).
The index data type is determined automatically by the types of the data at the selected paths, but you can control this by turning on Automatic and changing the data types. For example, JSON numbers in the collection data for a given field cause a type of
numberto be listed, but you can edit this toVARCHAR2to force indexing as a string value.
The values of field
PONumberare unique — the same numeric value is not used for the field more than once in the collection, so select Unique index.Select Index Nulls also. This is needed for queries that use
ORDER BYto sort the results. It causes every document to have an entry in the index.The values in field
PONumberare JSON numbers, which means the index can be used for numerical comparison.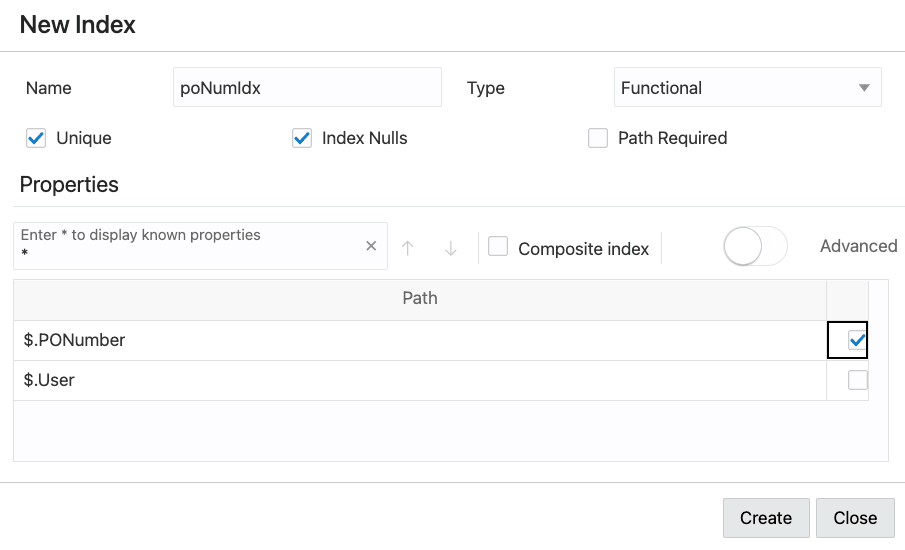
Description of the illustration json_page_create_index_002.png
Example 2-2 Indexing a Singleton Scalar Field Using SODA
Each SODA implementation (programming language or framework) that supports indexing provides a way to create an index. They all use a SODA index specification to define the index to be created. For example, with SODA for REST you use an HTTP POST request, passing URI argument action=index, and providing the index specification in the POST body.
This is a SODA index specification for a unique index named poNumIdx on field PONumber:
{ "name" : "**poNumIdx**",
"unique" : true,
"fields" : [ { "path" : "**PONumber**",
"dataType" : "NUMBER",
"order" : "ASC" } ] }Example 2-3 Indexing a Singleton Scalar Field Using SQL
You can use Database Actions to create an index for field PONumber in column data of tableorders with this SQL code. This uses SQL/JSON function json_value to extract values of field PONumber.
The code uses ERROR ON ERROR handling, to raise an error if a document has no PONumber field or it has more than one.
Item method numberOnly() is used in the path expression that identifies the field to index, to ensure that the field value is numeric.
Method numberOnly() is used instead of method number(), because number() allows also for conversion of non-numeric fields to numbers. For example, number() converts a PONumber string value of "42" to the number 42.
Other such “only” item methods, which similarly provide strict type checking, include stringOnly(), dateTimeOnly(), and binaryOnly(), for strings, dates, and binary values, respectively.
CREATE UNIQUE INDEX **"poNumIdx"** ON **orders**
(json_value(**data**, '$.PONumber.**numberOnly()**' **ERROR ON ERROR**))See Also: SQL/JSON Path Expression Item Methods in Oracle AI Database JSON Developer’s Guide
Example 2-4 Creating a Multivalue Index For Fields Within Elements of an Array
Starting with Oracle AI Database 21c you can create a multivalue index for the values of fields that can occur multiple times in a document because they are contained in objects within an array (objects as elements or at lower levels within elements).
This example creates a multivalue index on collection orders for values of field UPCCode. It example uses item method numberOnly(), so it applies only to numeric UPCCode fields.
CREATE MULTIVALUE INDEX **mvi_UPCCode** ON orders o
(o.data.LineItems.Part.**UPCCode.numberOnly()**);See Also: Creating Multivalue Function-Based Indexes for JSON_EXISTS in Oracle AI Database JSON Developer’s Guide
Example 2-5 Creating a Materialized View And an Index For Fields Within Elements of an Array
Prior to Oracle Database 21c you cannot create a multivalue index for fields such as UPCCode, which can occur multiple times in a document because they are contained in objects within an array (objects as elements or at lower levels within elements).
You can instead, as in this example, create a materialized view that extracts the data you want to index, and then create a function-based index on that view data.
This example creates materialized view mv_UPCCode with column upccode, which is a projection of field UPCCode from within the Part object in array LineItems of column data of table orders. It then creates index mv_UPCCode_idx on column upccode of the materialized view (mv_UPCCode).
CREATE MATERIALIZED VIEW **mv_UPCCode**
BUILD IMMEDIATE
REFRESH FAST ON STATEMENT WITH PRIMARY KEY
AS SELECT o.id, jt.**upccode**
FROM **orders** o,
json_table(**data**, '$.**LineItems[*]**'
ERROR ON ERROR NULL ON EMPTY
COLUMNS (**upccode** NUMBER PATH '$.**Part**.**UPCCode**')) jt;
CREATE INDEX **mv_UPCCode_idx** ON **mv_UPCCode**(**upccode**);The query optimizer is responsible for finding the most efficient method for a SQL statement to access requested data. In particular, it determines whether to use an index that applies to the queried data, and which index to use if more than one is relevant. In most cases the best guideline is to rely on the optimizer.
In some cases, however, you might prefer to specify that a particular index be picked up for a given query. You can do this with a MongoDB hint that names the index. (Oracle does not support the use of MongoDB index specifications — just provide the index name.)
For example, this query uses index poNumIdx on collection orders, created in Example 2-1.
db.orders.find({"PONumber":1600})**.hint("poNumIdx")**Alternatively, you can specify an index to use by passing an Oracle SQL hint, using query-by-example (QBE) operator $native, which is an Oracle extension to the MongoDB hint syntax.
The argument for $native has the same syntax as a SQL hint string (that is, the actual hint text, without the enclosing SQL comment syntax /*+...*/). You can pass any SQL hint using $native. In particular, you can turn on monitoring for the current SQL statement using hint MONITOR. This code does that for a find() query:
db.orders.find()**.hint({"$native":"MONITOR"})**Related Topics
See Also:
-
The JSON Page in Using Oracle AI Database Actions
-
Overview of SODA Indexing in Oracle AI Database Introduction to Simple Oracle Document Access (SODA)
-
Creating Multivalue Function-Based Indexes for JSON_EXISTS in Oracle AI Database JSON Developer’s Guide
-
Performance Tuning for JSON in Oracle AI Database JSON Developer’s Guide for detailed information about improving performance when using JSON data
-
JSON Search Index for Ad Hoc Queries and Full-Text Search in Oracle AI Database JSON Developer’s Guide for information about JSON search indexes
-
Creating a Spatial Index For Scalar GeoJSON Data in Oracle AI Database JSON Developer’s Guide
-
Influencing the Optimizer with Hints in Oracle AI Database SQL Tuning Guide
-
Monitoring Database Operations in Oracle AI Database SQL Tuning Guide for complete information about monitoring database operations
-
MONITOR and NO_MONITOR Hints in Oracle AI Database SQL Tuning Guide for information about the syntax and behavior of SQL hints
MONITORandNO_MONITOR
Users, Authentication, and Authorization
MongoDB Aggregation Pipeline Support
MongoDB Documents and Oracle Database
Presented here is the relationship between a JSON document used by MongoDB and the same content as a JSON document stored in, and used by, Oracle AI Database.
Note: This topic applies to JSON documents that you migrate from MongoDB and store in Oracle AI Database. It does not apply to JSON documents that are generated/supported by JSON-relational duality views. For information about MongoDB-compatible duality views see Using the Mongo DB API with JSON-Relational Duality Views.
You can migrate an existing application and its data from MongoDB to Oracle AI Database, or you can develop new applications on Oracle AI Database, which use the same or similar data as applications on MongoDB. JSON data in both cases is stored in documents.
It’s helpful to have a general understanding of the differences between the documents used by MongoDB and those used by Oracle AI Database. In particular, it helps to understand what happens to a MongoDB document that you import, to make it usable with Oracle AI Database.
Some of the information here presents details that you can ignore if you read this topic just to get a high-level view. But it’s good to be aware of what’s involved; you may want to revisit this at some point.
When you import a collection of MongoDB documents, the key and the content of each document are converted to forms appropriate for Oracle AI Database.
A MongoDB document has a native binary JSON format called BSON. An Oracle AI Database document has a native binary JSON format called OSON. So one change that’s made to your MongoDB document is to translate its binary format from BSON to OSON. This translation applies to both the key and the content of a document
Note: For Oracle Database API for MongoDB, as for MongoDB itself, a stage receives input, and produces output, in the form of BSON data, that is, binary JSON data in the MongoDB format.
Document Key: Differences and Conversion (Oracle Database Prior to 26ai)
This section applies only to Oracle Database releases prior to 26ai.
For MongoDB, the unique key of a document, which identifies it, is the value of mandatory field _id, in the document itself. For Oracle Database releases prior to 26ai, the unique key that identifies a document is separate from the document; the key is stored in a separate database column from the column that stores the document. The key column has is named id, and it is the primary key column for the table that stores your collection data.
When you import a collection into Oracle Database prior to 26ai, Oracle Database API for MongoDB creates id column values from the values of field _id in your MongoDB documents. MongoDB field _id can have values of several different data types. The Oracle Database id column that corresponds to that field is always of SQL data type VARCHAR2 (character data; in other words, a string).
The _id field in your imported documents is untouched during import or thereafter. Oracle Database doesn’t use it — it uses column id instead. But it also doesn’t change it, so any use your application might make of that field is still valid. Field _id in your documents is never changed; even applications cannot change (delete or update) it.
If you need to work with your documents using SQL or Simplified Oracle Document Access (SODA) then you can directly use column id. You can easily use that primary-key column to join JSON data with other database data, for instance. The documents that result from importing from MongoDB are SODA documents (with native binary OSON data).
Be aware of these considerations that result from the separation of document key from document:
-
Though all documents imported from MongoDB will continue to have their
_idfields, for Oracle Database prior to 26ai the documents in a JSON collection need not have an_idfield. And because, for Oracle Database prior to 26ai, a document and its key are separate, a document other than one imported from MongoDB could have an_idfield that has no relation whatsoever with the document key. -
Because MongoDB allows
_idvalues of different types, and these are all converted to string values (VARCHAR2), if for some reason your collection has documents with_idvalues"123"(JSON string) and123(JSON number) then importing the collection will raise a duplicate-key error, because those values would each be translated as the same string value for columnid.
BSON values of field _id are converted to VARCHAR2 column id values according to Table 2-1. If an _id field value is any type not listed in the table then it is replaced by a generated ObjectId value, which is then converted to the id column value.
Table 1 Conversion of BSON Field _id
| _id Field Type | ID Column VARCHAR2 Value |
|---|---|
Double |
Canonical numeric format string |
32-bit integer |
Canonical numeric format string |
64-bit integer |
Canonical numeric format string |
Decimal128 |
Canonical numeric format string |
String |
No conversion, including no character escaping |
ObjectId |
Lowercase hexadecimal string |
Binary data (UUID) |
Lowercase hexadecimal string |
Binary data (non-UUID) |
Uppercase hexadecimal string |
The canonical numeric format for a VARCHAR2 value is as follows:
-
If the input number has no fractional part (it is integral), and if it can be rendered in 40 digits or less, then it is rendered as an integer. If necessary, trailing zeros are used, to avoid notation with an exponent. For example,
1000000000is used instead of1E+9. -
If the input number has a fractional part, the number is rendered in 40 digits or less with a decimal point separator. If necessary, zeros are used to avoid notation with an exponent. For example,
0.00001is used instead of1E-5. -
If conversion of the input number would result in a loss of digit precision in the 40-digit format, the number is instead rendered with an exponent. This can happen for a number whose absolute value is extremely small or extremely large, even if the number is integral. For example,
1E100is used, to avoid a 1 followed by 100 zeros.
In practice, this canonical numeric format means that in most cases the numeric _id field value results in an obvious, or “pretty” VARCHAR2 value for column id. A format that uses an exponent is used only when necessary, which generally means infrequently.
Document Content Conversion
Two general considerations:
-
BSON format allows duplicate field values in the same object. OSON format does not. When converting to OSON, detection of duplicate fields in BSON data raises an error.
-
OSON format has no notion of the order of fields in an object; applications cannot depend on or expect any particular order (in keeping with the JSON standard). BSON format maintains the order of object fields; applications can depend on the order not changing.
Table 2-2 specifies the type mappings that are applied when converting scalar BSON data to scalar OSON data. The OSON scalar types used are SQL data types, except as noted. Any BSON types not listed are not converted; instead, an error is raised when they are encountered. This includes BSON types regex, and JavaScript.
Table 2 JSON Scalar Type Conversions:
| BSON Type | OSON TypeFoot 2 | Notes |
|---|---|---|
Double |
BINARY_DOUBLE |
NA |
32-bit integer |
NUMBER (Oracle number) |
Flagged as int. |
64-bit integer |
NUMBER (Oracle number) |
Flagged as long. |
Decimal128 |
NUMBER (Oracle number) |
Flagged as decimal. Note: This conversion can be lossy. |
Date |
TIMESTAMP WITH TIME ZONE |
Always UTC time zone. |
String |
VARCHAR2 |
Always in character set AL32UTF8 (Unicode UTF-8). |
Boolean |
BOOLEAN |
Supported only if initialization parameter compatible has value 23 or larger. (There is no Oracle SQL BOOLEAN type in releases prior to 26ai.) |
ObjectId |
ID (RAW(12)) |
NA |
Binary data (UUID) |
ID (RAW(16)) |
NA |
Binary data (non-UUID) |
RAW |
NA |
Null |
NULL |
Used for JSON null. |
Footnote 2 These are SQL data types, except as noted.
Related Topics
See Also:
-
Overview of SODA Documents in Oracle AI Database Introduction to Simple Oracle Document Access (SODA)
-
BSON types (MongoDB)
-
Data Types (MongoDB shell)
Other Differences Between MongoDB and Oracle AI Database
Various differences between MongoDB and Oracle AI Database are described. These differences are generally not covered in other topics. Consider these differences when you migrate an application to Oracle AI Database or you develop a new application for Oracle AI Database that uses MongoDB commands.
-
With MongoDB, fields in a JSON object are ordered. With Oracle AI Database, they are not ordered. For example, field
_idis not necessarily the first field in an object. Applications must not expect or rely on any particular field order. According to the JSON language standard, object fields are not ordered; only array elements are ordered. See JSON Syntax and the Data It Represents in Oracle AI Database JSON Developer’s Guide. -
With MongoDB, the value of field
_idcan be a JSON object. Oracle Database API for MongoDB supports only BSON typesObjectId,String,Double,32-bit integer,64-bit integer,Decimal128, andBinary data(subtype for UUID) for field_id; an error is raised for any other type. See BSON Types.If you are migrating an existing application that expects object values for
_idthen consider copying the values of field_idin your data to some new field and using a string value for_id. -
Read and write concerns regarding MongoDB transactions do not apply to Oracle AI Database. Oracle AI Database transactions are fully ACID-compliant, and thus reliable — atomicity, consistency, isolation, and durability. ACID compliance ensures that your data remains accurate and consistent despite any failure that might occur while processing a transaction.
-
Oracle API for MongoDB does not support the following MongoDB transaction capabilities:
-
Inclusion of DDL operations, such as
createCollection, within a transaction. Attempts to create a collection or an index within a transaction raise an error. -
Inclusion of operations across multiple databases. All operations within a transaction must be confined to a single database (schema). Otherwise, an error is raised.
-
-
Retryable writes or commits when an error is raised.
MongoDB
retryWriteoperations raise an error. If you use a driver that hasretryWriteturned on by default, then setretryWrites=falsein your connection string to turn this off. -
Oracle AI Database and MongoDB have different read isolation and consistency levels. Oracle Database API for MongoDB uses read-committed consistency as described in Data Concurrency and Consistency of Oracle AI Database Concepts.
-
Oracle Database API for MongoDB supports only the PLAIN (LDAP SASL) authentication mechanism, and it relies on Oracle AI Database authentication and authorization.
-
Oracle AI Database does not support the MongoDB
collationfield for any command (such asfind). An error is raised if you use fieldcollation. Oracle collates values using the Unicode binary collation order. -
MongoDB allows different collections in the same “database” to have indexes of the same name. This is not allowed in Oracle AI Database — the name of an index must be unique across all collections of a given database schema (“database”).
-
The maximum size of a document for MongoDB is 16 MB. The maximum size for Oracle AI Database (and thus for the MongoDB API) is 32 MB.
Related Topics
Accessing Collections Owned By Other Users (Database Schemas)
You can directly access a MongoDB API collection owned by another user (database schema) if you log into that schema. You can indirectly access a collection owned by another user, without logging into that schema, if that collection has been mapped to a collection in your schema.
A MongoDB API collection of JSON documents consists of (1) a collection backing table , which contains the JSON documents in the collection, and (2) some JSON-format collection metadata , which is stored in the data dictionary and specifies various collection-configuration properties. The backing table belongs to a given database user/schema. The metadata is stored in the database data dictionary.
A mapped collection is a collection that is defined (mapped) on top of an existing table, which can belong to any database schema and which could also back one or more other collections.
You can control which operations on a collection — including a mapped collection — are allowed for various users (schemas), by granting those users different privileges or roles on the backing table. Example 2-9 illustrates this.
Example 2-9 Creating a Collection in One Schema and Mapping a Collection To It in Another Schema
In this example user john creates collection john_coll (in database schema john), and adds a document to it. User john then grants user janet some access privileges to the backing table of collection john_coll.
User janet then maps a new collection, janet_coll (in schema janet) to collection john_coll in schema john. (The original and mapped collections need not have different names, such as john_coll and janet_coll; they could both have the same name.)
User janet then lists the collections available to schema janet, and reads the content of mapped collection janet_coll, which is the same as the content of collection john_coll.
(The commands submitted to mongosh are each a single line (string), but they are shown here continued across multiple lines for clarity.)
Examples in this documentation of input to, and output from, Oracle Database API for MongoDB use the syntax of shell mongosh.
1. When connected to the database as user john, run PL/SQL code to create collection john_coll backed by table john_coll. The second argument to create_collection is the metadata needed for a MongoDB-compatible collection. (The backing table name is derived from the collection name — see Default Naming of a Collection Table.)
col SODA_COLLECTION_T;
BEGIN
col := DBMS_SODA.**create_collection**(
'**john_coll**',
'{"contentColumn" : {"name" : "DATA",
"sqlType" : "BLOB",
"jsonFormat" : "OSON"},
"keyColumn" : {"name" : "ID",
"assignmentMethod" : "EMBEDDED_OID",
"sqlType" : "VARCHAR2"},
"versionColumn" : {"name" : "VERSION", "method" : "UUID"},
"lastModifiedColumn" : {"name" : "LAST_MODIFIED"},
"creationTimeColumn" : {"name" : "CREATED_ON"}}');
END;2. Connect to the database using shell mongosh as user john, list the collections in that schema (John’s collections), insert a document into collection john_coll, and show the result of the insertion.
mongosh 'mongodb://**john**:...
@MQSSYOWMQVGAC1Y-CTEST.adb.us-ashburn-1.oraclecloudapps.com:27017/**john**
?authMechanism=PLAIN&authSource=$external&ssl=true&retryWrites=false&loadBalanced=true'john> show collections;Output:
john> **db.john_coll**.**insert**({"hello" : "world"});
john> **db.john_coll**.**find**()Output:
[ { _id: ObjectId("6318b0060a51240e4bf3b001"), hello: 'world' } ]3. In schema john, grant user janet access privileges to collection john_coll and its backing table of the same name, john_coll.
GRANT SELECT, INSERT, UPDATE, DELETE ON **john**.**john_coll** TO **janet**;4. When connected to the database as user (schema) janet, Create a new collection janet_coll in schema janet that’s mapped to collection john_coll in schema john.
The second argument to method create_collection() is the collection metadata. Among the things it specifies here are the schema and backing-table names of the collection to be mapped to. The last argument, CREATE_MODE_MAP, specifies that the new collection is to be mapped on top of the table that backs the original collection.
col SODA_COLLECTION_T;
BEGIN
col := DBMS_SODA.**create_collection**(
'**janet_coll**',
'{"**schemaName**" : "**JOHN**",
"**tableName**" : "**JOHN_COLL**",
"contentColumn" : {"name" : "DATA",
"sqlType" : "BLOB",
"jsonFormat" : "OSON"},
"keyColumn" : {"name" : "ID",
"assignmentMethod" : "EMBEDDED_OID",
"sqlType" : "VARCHAR2"},
"versionColumn" : {"name" : "VERSION", "method" : "UUID"},
"lastModifiedColumn" : {"name" : "LAST_MODIFIED"},
"creationTimeColumn" : {"name" : "CREATED_ON"}}',
**DBMS_SODA.CREATE_MODE_MAP**);
END;Note:
The schema and table names used in the collection metadata argument must be as they appear in the data dictionary, which in this case means they must be uppercase. You can use these queries to obtain the correct schema and table names for collection <collection> (when connected as the owner of <collection>):
SELECT c.json_descriptor.**schemaName** FROM USER_SODA_COLLECTIONS c
WHERE uri_name = '*<collection>*';
SELECT c.json_descriptor.**tableName** FROM USER_SODA_COLLECTIONS c
WHERE uri_name = '*<collection>*';5. Connect to the database using shell mongosh as user janet, list the available collections, and show the content of collection janet_coll (which is the same as the content of John’s collection john_coll).
mongosh 'mongodb://**janet**:...
@MQSSYOWMQVGAC1Y-CTEST.adb.us-ashburn-1.oraclecloudapps.com:27017/**janet**
?authMechanism=PLAIN&authSource=$external&ssl=true&retryWrites=false&loadBalanced=true'
janet> **show collections**;**janet_coll**janet> **db.janet_coll.find**()[ { _id: ObjectId("6318b0060a51240e4bf3b001"), **hello: 'world'** } ]Footnote Legend
Footnote 1: MongoDB calls a composite index a compound index. A composite index is also sometimes called a concatenated index.