Overview of SODA
Simple Oracle Document Access (SODA) provides NoSQL-style APIs for Oracle Database.
SODA implements the document model. Documents contain JSON content, a unique key, and a version (eTag). Documents are organized into collections, which belong to a database schema - referred to as a database in some SODA implementations.
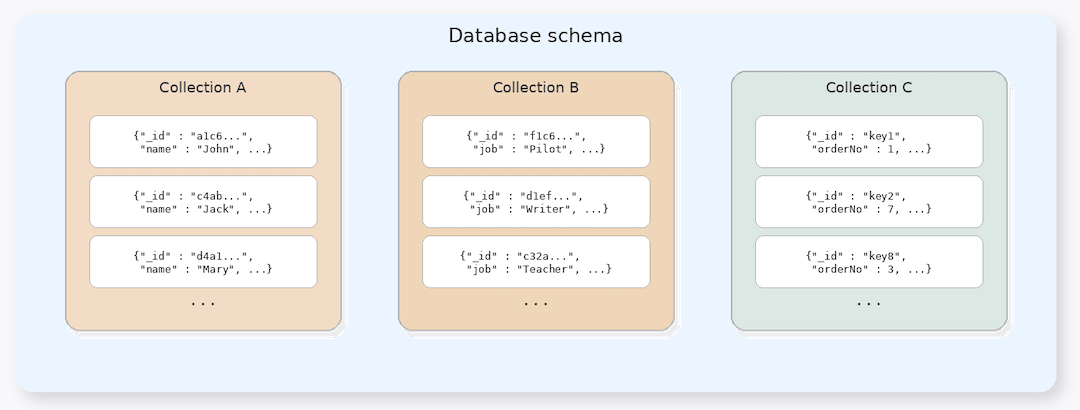
Figure 1: JSON Collection and Documents
You use SODA to perform read and write operations on document collections. These operations can identify documents by key or by filter, where filters are JSON-based pattern expressions. Sections Documents and Collections describe documents and collections in detail, and Chapters Overview of SODA Filter Specifications and SODA Filter Specifications Reference introduce and document filters.
Common SODA operations include:
- Create, open, drop, and list collections
- Insert and save (upsert) documents
- Find documents
- Update documents using JSON Merge Patch (RFC 7396) or JSON Patch (RFC 6902)
- Replace documents
- Remove documents
- Perform text search
- Perform geospatial search using GeoJSON filters
- Create and list B-tree, text, and spatial indexes
Each SODA operation runs as a transaction. Most implementations support auto-commit, and all except REST also support multi-operation transactions.
Both optimistic and pessimistic locking are supported for document write operations such as replace, JSON Merge Patch, JSON Patch, and remove: optimistic locking uses document versions to detect conflicts; pessimistic locking locks a document before modification.
When using SODA, documents and collections are accessed through client-side representations available in a given implementation. In implementations other than REST (for example, Java, Node.js, or Python), documents and collections are exposed as programmatic objects. In SODA REST, collections are identified as part of the request URL, and documents are conveyed in HTTP request and response payloads.
At the database level, collections are backed by tables or views, and documents are stored as rows in those tables or views. Under the covers, SODA automatically translates operations on documents and collections into SQL statements that are executed against these underlying tables or views.
Starting with 26ai, SODA collections are, at the database level, JSON collection tables and views. These are tables and views with a column of type JSON. New SODA applications should use these collections. This book focuses on 26ai JSON collection tables and views, but much of the material applies to pre-26ai collections as well. Differences are noted where relevant and fully expanded in Pre-26ai Collections.
Because collections are backed by tables or views, SQL and SODA can be used together on the same data. SQL, with SQL/JSON operators, provides the full power of Oracle SQL - including joins, aggregations, analytics, and reporting - while SODA provides document-oriented access. This also means standard Oracle Database features such as partitioning, compression, and encryption can be used with collections.
SODA is available for multiple programming languages and for REST:
| Language / Platform | Availability |
|---|---|
| Java | Separate JAR, works with Oracle JDBC |
| Node.js, Python, C | Included with Oracle Database drivers |
| PL/SQL | Included with the database |
| REST | Part of ORDS (Oracle REST Data Services) |
The Java, Python, and Node.js implementations are open source and are available on GitHub.