
Exportation de données généralisée
La méthode d'exportation de données généralisée permet d'exporter des données sous forme de fichier au format JSON. L'exportation des données d'un objet de maintenance à l'aide de cette méthode implique une exportation initiale de l'ensemble des données de l'entité, suivie d'une exportation en cours des modifications apportées au fil du temps. Ces processus sont illustrés dans le diagramme suivant :
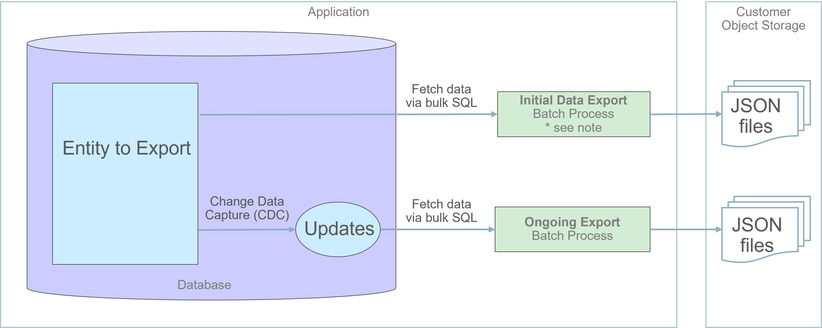
-
Activer les entités à exporter dans le portail Tableau de bord d'exportation généralisée. Vous pouvez activer plusieurs entités simultanément. Cette étape vous permet également d'activer l'exportation en cours de ces entités.
-
Soumettre le processus en mode batch Initiateur d'exportation initiale généralisée (F1-GEXPI) pour exporter le contenu actuel de toutes les entités activées. Cette étape soumet un processus en mode batch distinct pour chaque entité que vous avez activée pour l'exportation.
Remarque :Une exportation complète de la base de données peut être utilisée à la place. Le fichier d'exportation peut être importé dans l'environnement cible pour établir la référence initiale. Les clients cloud peuvent contacter les opérations cloud pour demander une exportation de ce type pour une utilisation sur site. Cette exportation de schéma est limitée à un usage de génération de rapports et est destinée à l'extraction initiale uniquement. -
Planifiez l'exécution périodique du processus en mode batch Exportation en cours généralisée (F1-GEEXO).
Les sections suivantes décrivent en outre les concepts et les directives liés à la méthode d'exportation de données généralisée.
Admissibilité
-
L'entité gère un volume de données extrêmement élevé. Suivre les modifications apportées à cette entité multiplierait par deux le volume de données gérées et impacterait les performances globales.
-
L'entité est mise à jour très fréquemment. Le suivi de ces événements peut avoir une incidence sur les performances globales.
-
L'entité est utilisée par l'infrastructure et les processus opérationnels du produit. Ces entités sont gérées différemment et ne peuvent pas être soumises aux méthodes d'exportation généralisée de données.
Par défaut, un objet de maintenance est admissible à la méthode d'exportation de données généralisée, sauf s'il est explicitement marqué autrement par l'option Classe d'exportation de données. Cette option peut être utilisée pour marquer une entité comme non autorisée à effectuer d'exportations, ou uniquement autorisée à exécuter une exportation spécialisée. L'absence d'une telle option explicite signifie que l'objet de maintenance est admissible pour l'exportation généralisée.
Une méthode unique pour tout
La méthode d'exportation de données généralisée est conçue pour prendre en charge de nombreux objets de maintenance admissibles d'une manière générique qui doit également tenir compte des considérations de performances. Pour cette raison, cette méthode ne prend pas en charge les options de filtrage propres aux entités ni les règles personnalisées de quelque nature que ce soit.
-
L'intégralité des données est exportée.
-
Tous les champs de toutes les tables appartenant à l'objet de maintenance sont exportés, à l'exception des tables de "clé" et de "journal", le cas échéant.
-
Les tables de journal des objets de maintenance ne contiennent généralement pas d'informations métier utiles et sont donc omises de l'exportation pour des raisons de performances et de volume de données. Toutefois, il existe des entités pour lesquelles les enregistrements de journal fournissent une valeur d'analyse. Le cas échéant, utilisez l'option Tables du journal d'exportation pour inclure explicitement les tables de journal d'un objet de maintenance spécifique.
-
-
La même structure de données et le même format sont utilisés pour toutes les entités. Pour plus d'informations, voir la section Format d'enregistrement.
-
Les données sont exportées vers des fichiers uniquement. Pour plus d'informations, voir la section Exporter vers des fichiers uniquement.
-
Toutes les modifications sont capturées. Il n'est pas possible d'exclure certaines modifications du suivi de l'exportation en cours sur la base de règles métier personnalisées.
-
Lorsque les données changent, un instantané complet des données associées à cette entité est exporté afin d'éviter une fusion importante des données côté cible.
-
Lorsque l'entité est supprimée, seule sa clé primaire est exportée avec une indication qu'elle a été est supprimée.
Exporter vers des fichiers uniquement
La destination immédiate des processus d'exportation, qu'ils soient initiaux ou en cours, est un fichier situé dans un emplacement spécifié par le client. Dans une installation cloud, des fichiers sont créés dans un stockage d'objets appartenant au client.
En fonction des besoins de votre entreprise, ces fichiers peuvent être utilisés par des applications en aval, telles que des lacs de données, etc.
Activer l'exportation de données
Pour activer l'exportation de données pour un objet de maintenance admissible, un enregistrement de contrôle d'exportation de données doit être créé. L'enregistrement indique si l'exportation initiale de l'objet de maintenance a été effectuée ou non et si les modifications apportées à l'entité doivent être suivies et exportées de manière continue. Un portail désigné vous permet d'activer l'exportation de données généralisée pour de nombreux objets de maintenance en même temps et de surveiller leur état d'exportation en cours d'un coup d'oeil. Pour plus d'informations, voir le portail Tableau de bord d'exportation généralisée.
Les options d'export en cours sont mises en cache dans divers caches en ligne et batch. Pour que ces options prennent effet et suivent les modifications d'entité effectuées par n'importe quel processus en ligne ou en mode batch, les différents caches doivent être vidés correctement lorsque ces options sont modifiées. L'utilisation des portails désignés pour activer les entités pour l'exportation déclenche un vidage "global" des caches. Si les processus de pool de threads sont configurés pour actualiser leurs caches lorsqu'un vidage global est demandé, il n'y a rien d'autre à faire. Si ce n'est pas le cas, le traitement batch F1–FLUSH doit également être soumis pour actualiser les caches utilisés dans le traitement batch. Pour plus d'informations, voir Mise en cache - Généralités.
Exportation de données initiale
Chaque objet de maintenance admissible pour la méthode d'exportation de données généralisée est associé à un contrôle de batch d'exportation de données initiale référencé sur l'objet de maintenance à l'aide de l'option Contrôle de batch d'exportation. Le même programme batch commun est utilisé par tous ces contrôles de batch pour exporter l'ensemble des données d'une entité vers des fichiers. Le processus est multithread et génère un fichier par thread par défaut. Un paramètre de batch facultatif permet de générer plusieurs petits fichiers par thread en définissant une limite du nombre d'enregistrements écrits dans chaque fichier. Pour plus d'informations, voir la section Taille de fichier.
Au lieu de soumettre manuellement le processus en mode batch d'exportation initiale généralisée pour chaque objet de maintenance que vous avez activé pour l'exportation, soumettez le processus en mode batch F1-GEXPI Initiateur d'exportation initiale généralisée pour soumettre automatiquement tous les objets à la fois.
Le processus d'exportation initiale pour chaque objet de maintenance met à jour l'enregistrement de contrôle d'exportation de données correspondant pour l'objet de maintenance afin d'indiquer que le processus a commencé et le met à nouveau à jour à la fin. Vous pouvez ainsi visualiser l'état global de l'exportation initiale dans toutes les entités activées sur le portail Tableau de bord d'exportation généralisée.
Notez que le processus en mode batch initiateur ne soumet des processus en mode batch que pour les objets de maintenance activés dont l'exportation initiale n'a pas encore commencé selon leur enregistrement de contrôle d'exportation de données. Si vous devez exporter à nouveau une ou plusieurs entités, réinitialisez l'indication d'état de l'exportation initiale sur leurs enregistrements de contrôle d'exportation de données et soumettez à nouveau le processus en mode batch initiateur.
INIT_EXPORT[_file prefix(optional)]_[maintenance object]_[batch run]_[thread]_[thread count]_[timestamp][_file sequence].json.gz
Pour plus d'informations, voir l'un des contrôles de batch d'exportation initiale généralisée et le contrôle de batch initiateur.
Limiter l'exportation initiale par date
Par défaut, le processus en mode batch d'exportation initiale de données exporte l'ensemble des données d'une entité. Dans certains cas, impliquant généralement des volumes élevés de données historiques, il peut s'avérer nécessaire de limiter l'exportation à des données plus récentes, par exemple les quelques derniers mois de données.
Le processus en mode batch d'exportation initiale prend en charge un paramètre de batch facultatif Limiter par date qui peut être utilisé pour limiter le volume des données à exporter. Le paramètre référence un champ de date et une période demandée en nombre de jours avant la date commerciale. Pour plus d'informations, voir le contrôle de batch Modèle d'exportation initiale généralisée F1-GEIXP.
Exportation de données en cours
Les modifications de données font l'objet d'un suivi par l'algorithme Objet de maintenance - Audit - Capturer les modifications pour une exportation en cours (F1-MO-REGCHN). L'algorithme enregistre la clé primaire d'une entité modifiée dans une table Mise à jour de l'exportation de données désignée qui sert de file d'attente d'entités modifiées à exporter. La file d'attente est ensuite utilisée par le processus en mode batch d'exportation de données en cours.
La règle d'audit est ajoutée à un objet de maintenance lorsque l'option d'exportation de données en cours sur l'enregistrement de contrôle d'exportation de données correspondant est activée. De la même manière, la règle d'audit est supprimée de l'objet de maintenance lorsque l'option d'exportation en cours est désactivée.
Contrairement au processus en mode batch d'exportation initiale qui nécessite la définition d'un contrôle de batch pour chaque objet de maintenance admissible, un seul processus en mode batch est utilisé pour exporter les modifications en cours apportées à toutes les entités.
-
Toutes les modifications mises en file d'attente dans la table Mise à jour de l'exportation de données sont exportées vers un fichier d'exportation en cours désigné. Pour plus d'informations, voir la section Gérer un gros volume de travail en attente.
-
Un cliché complet des données relatives à l'entité modifiée est exporté afin d'éviter une fusion importante des données côté cible.
-
Une fois exportés, les enregistrements sont supprimés de la table Mise à jour de l'exportation de données.
Le processus est multithread et par défaut, un fichier distinct est créé pour chaque thread. Un paramètre de batch facultatif permet de générer plusieurs petits fichiers par thread en définissant une limite du nombre d'enregistrements écrits dans chaque fichier. Pour plus d'informations, voir la section Taille de fichier.
INC_EXPORT_[batch run]_[thread]_[thread count]_[timestamp][_file sequence].json.gz Pour plus d'informations, voir le contrôle de batch Exportation en cours généralisée (F1-GEEXO).
Taille de fichier
Par défaut, le processus d'exportation en mode batch initial génère un seul fichier par thread. Pour certaines entités à volume élevé, cela peut entraîner des fichiers trop volumineux pour être gérés. Pour produire des fichiers multiples et plus petits pour une entité spécifique, limitez le nombre d'enregistrements écrits dans chaque fichier en définissant le paramètre correspondant sur le contrôle de batch d'exportation initial défini pour l'entité. Le même paramètre peut être fourni lors de la soumission du processus en mode batch Initiateur d'exportation initiale, auquel cas la valeur de l'initiateur n'est utilisée que lorsqu'aucune valeur correspondante n'a été définie dans l'enregistrement de contrôle de batch spécifique de l'entité.
De la même manière, le processus d'exportation en mode batch en cours génère un seul fichier par thread par défaut. Pour produire des fichiers multiples et plus petits, limitez le nombre d'enregistrements écrits dans chaque fichier en définissant le paramètre correspondant dans le contrôle de batch.
Pour éviter la création d'un trop grand nombre de fichiers par exécution de batch, le système définit une limite d'environ 500 fichiers par exécution. Lorsque le nombre demandé d'enregistrements par fichier déterminé aboutit à ce que le nombre de fichiers générés dépasse la limite du système, la valeur réelle utilisée est ajustée pour répondre à la limite du système.
Gérer un gros volume de travail en attente
Lorsque des modifications en attente s'accumulent dans la file d'attente d'exportation en cours pour une raison quelconque, l'exportation du batch suivant prend plus de temps, ce qui retarde l'étape d'importation en aval. Une meilleure solution consiste à résorber le travail en attente par petits "blocs", ce qui permet au processus en aval de les importer au fur et à mesure qu'ils sont mis à disposition.
Vous pouvez limiter le nombre d'enregistrements exportés par le processus en mode batch à l'aide du paramètre de batch Limite de traitement des threads. Lorsqu'il est indiqué, le nombre d'enregistrements exportés par chaque thread est restreint par la limite spécifiée, les enregistrements restants étant traités par les exécutions de batch suivantes. Au lieu d'attendre la prochaine exécution de batch planifiée, un nouveau processus en mode batch peut être automatiquement soumis, s'il est explicitement demandé de le faire à l'aide du paramètre de batch Traitement automatique du travail en attente.
Il est important de s'assurer que le travail en attente se résorbe progressivement et que la file d'attente reprend sa taille normale en temps opportun. La limite de traitement doit donc être fixée à une valeur appropriée qui favorise un bon apurement de la file d'attente. Pour ce faire, au moins 20 % de la file d'attente et pas moins de 100 000 enregistrements doivent être consommés par chaque exécution de batch sur tous les threads. Si la limite spécifiée ne satisfait pas à l'exigence de volume d'exécution minimum, la limite de traitement est ajustée en conséquence.
Format d'enregistrement
Les données sont extraites et exportées directement à partir de la base de données lors d'opérations de lecture en masse pour des raisons de performances. De fait, la structure utilisée ne reflète pas le modèle de données logique de l'entité, mais sa liste physique de tables. Les données d'une instance donnée sont organisées en tables, suivies de lignes dans chaque table et, pour chaque ligne, de sa liste de champs au format JSON.
Les sections suivantes décrivent le format et la structure utilisés :
{
"OBJ": "<mo name>",
"TIMESTAMP": "<export time in ISO format for example 2019-07-25T11:06:04.740615Z>",
"PK1": "<mo pk1 value>",
"PK2": "<mo pk2 value if any>", ← PK2-5 should only be included when applicable
"PK3": "<mo pk3 value if any>",
"PK4": "<mo pk4 value if any>",
"PK5": "<mo pk5 value if any>",
"DELETED": true, ← should only be included when the entity is deleted
"DATA":
{
"<MO table name 1>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>},...
],
"<MO table name 2>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>}
],...
"<MO table name n>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>}
]
}
Remarques sur les valeurs et les formats des champs :
-
Tous les champs d'une ligne sont inclus même si le champ est vide ou a la valeur NULL.
-
Les espaces de fin excédentaires sont tronqués dans toutes les valeurs de chaîne, mais si un champ est vide, il est exporté sous la forme d'une chaîne de caractères vide "" et non en tant que valeur NULL.
-
Un tableau vide est utilisé pour un noeud de table lorsqu'il n'existe aucun enregistrement pour l'entité dans la table.
-
Les informations de date/heure sont converties en fuseau horaire UTC et exportées au format ISO, par exemple 2019-07-25T11:06:04.740615Z.
-
Les suppressions ont un indicateur explicite dans l'en-tête.
Ordre d'utilisation des fichiers
Il est important d'appliquer tous les fichiers d'exportation initiale pour un objet de maintenance avant d'appliquer les fichiers de modification en cours afin de garantir la cohérence des données.
-
Appliquer tous les fichiers d'exportation de données initiale avant les fichiers d'exportation en cours.
-
Appliquer les fichiers initiaux pour un objet de maintenance dans l'ordre des numéros d'exécution.
-
Appliquer les fichiers d'exportation en cours dans l'ordre des numéros d'exécution.
-
Si une nouvelle exportation initiale est disponible, la procédure d'utilisation des fichiers doit être modifiée temporairement comme suit :
-
Arrêter l'utilisation des fichiers d'exportation en cours.
-
Appliquer les nouveaux fichiers d'exportation initiale.
-
Reprendre l'utilisation des fichiers d'exportation en cours.
-
Récupérer à partir d'un fichier d'export en cours perdu
Le processus en mode batch d'exportation en cours conserve une sauvegarde de toutes les clés d'entité qui ont été exportées lors une exécution de batch spécifique dans une table de sauvegarde désignée. Dans de rares cas où un fichier d'export en cours est supprimé ou est endommagé avant son traitement, la table de sauvegarde peut être utilisée pour identifier les modifications manquantes et les exporter à nouveau.
Utilisez le processus en mode batch Restaurer les clés d'exportation généralisées (F1-GERST) pour résoudre cette situation. Le processus identifie les entités qui ont été exportées au cours d'une exécution de batch spécifiée et les ajoute à la file d'attente des modifications en cours à partir de la table de sauvegarde. Les entités sont ensuite réexportées lors des exécutions d'exportation en cours suivantes. Cette méthode ne restaure pas le contenu exact du fichier initial qui a été perdu car celui-ci ne peut pas être reproduit. Au lieu de cela, le processus garantit que les entités qui étaient incluses dans le fichier perdu soient de nouveau exportées.