Uso de JupyterHub en Big Data Service 3.0.26 o versiones anteriores
Utilice JupyterHub para gestionar blocs de notas de Big Data Service 3.0.26 o versiones anteriores de ODH 1.x para grupos de usuarios.
Requisitos
Para poder acceder a JupyterHub desde un explorador, un administrador debe:
- Haga que el nodo esté disponible para las conexiones entrantes de los usuarios. La dirección IP privada del nodo se debe asignar a una dirección IP pública. Como alternativa, el cluster se puede configurar para utilizar un bastion host u Oracle FastConnect. Consulte Conexión a nodos de cluster con direcciones IP privadas.
- Abra el puerto
8000en el nodo configurando las reglas de entrada en la lista de seguridad de la red. Consulte Definición de reglas de seguridad.
JupyterHub Credenciales por defecto
Las credenciales de conexión de administrador por defecto para JupyterHub en Big Data Service 3.0.21 y anteriores son:
- Nombre de usuario:
jupyterhub - Contraseña: contraseña del administrador de Apache Ambari. Se trata de la contraseña del administrador del cluster que se especificó cuando se creó el cluster.
- Nombre de principal para el cluster de HA:
jupyterhub - Tabla de claves para un cluster de HA:
/etc/security/keytabs/jupyterhub.keytab
Las credenciales de inicio de sesión de administrador por defecto para JupyterHub en Big Data Service 3.0.22 a 3.0.26 son:
- Nombre de usuario:
jupyterhub - Contraseña: contraseña del administrador de Apache Ambari. Se trata de la contraseña del administrador del cluster que se especificó cuando se creó el cluster.
- Nombre de principal para el cluster de HA:
jupyterhub/<FQDN-OF-UN1-Hostname> - Tabla de claves para un cluster de HA:
/etc/security/keytabs/jupyterhub.keytabEjemplo:Principal name for HA cluster: jupyterhub/pkbdsv2un1.rgroverprdpub1.rgroverprd.oraclevcn.com Keytab for HA cluster: /etc/security/keytabs/jupyterhub.keytab
El administrador crea usuarios adicionales y sus credenciales de conexión, y proporciona las credenciales de conexión a esos usuarios. Para obtener más información, consulte Gestión de usuarios y permisos.
A menos que se haga referencia explícita a algún otro tipo de administrador, el uso de administrator o de admin en esta sección hace referencia al administrador de JupyterHub, jupyterhub.
Acceso a JupyterHub
También puede acceder al enlace JupyterHub desde la página de detalles del cluster en URL de cluster.
También puede crear un equilibrio de carga para proporcionar un front-end seguro para acceder a servicios, incluido JupyterHub. Consulte Conexión a servicios en un cluster mediante un equilibrador de carga.
Generación de blocs de notas
Se deben cumplir los requisitos para que el usuario intente generar blocs de notas.
- Acceda a JupyterHub.
- Conéctese con las credenciales de administración. La autorización solo funciona si el usuario está presente en el host de Linux. JupyterHub busca el usuario en el host de Linux al intentar generar el servidor del bloc de notas.
- Se le redirigirá a una página de opciones de servidor en la que debe solicitar un ticket de Kerberos. Este ticket se puede solicitar mediante el principal de Kerberos y el archivo keytab, o la contraseña de Kerberos. El administrador del cluster puede proporcionar el principal de Kerberos y el archivo keytab, o la contraseña de Kerberos.
El ticket de Kerberos es necesario para obtener acceso a los directorios de HDFS y otros servicios de big data que desea utilizar.
Se deben cumplir los requisitos para que el usuario intente generar blocs de notas.
- Acceda a JupyterHub.
- Conéctese con las credenciales de administración. La autorización solo funciona si el usuario está presente en el host de Linux. JupyterHub busca el usuario en el host de Linux al intentar generar el servidor del bloc de notas.
Gestionar JupyterHub
Un usuario JupyterHub admin puede realizar las siguientes tareas para gestionar blocs de notas en JupyterHub en nodos ODH 1.x de Big Data Service 3.0.26 o anteriores.
Como admin, puede configurar JupyterHub.
Configure JupyterHub mediante el explorador para clusters de Big Data Service 3.0.26 o anteriores.
Pare o inicie JupyterHub mediante el explorador de clusters de Big Data Service 3.0.26 o anteriores.
Como admin, puede parar o desactivar la aplicación para que no consuma recursos como, por ejemplo, la memoria. Reiniciar también puede ayudar con problemas o comportamientos inesperados.
Como administrador, puede limitar el número de servidores de blocs de notas activos del cluster de Big Data Service.
Por defecto, los blocs de notas se almacenan en el directorio de HDFS de un cluster.
Debe tener acceso al directorio de HDFS hdfs:///user/<username>/. Los blocs de notas se guardan en hdfs:///user/<username>/notebooks/.
- Conéctese como usuario
opcal nodo de utilidad donde está instalado JupyterHub (el segundo nodo de utilidad de un cluster de HA [alta disponibilidad] o el primer y único nodo de utilidad de un cluster sin HA). - Utilice
sudopara gestionar las configuraciones de JupyterHub que se almacenan en/opt/jupyterhub/jupyterhub_config.py.c.Spawner.args = ['--ServerApp.contents_manager_class="hdfscm.HDFSContentsManager"'] - Utilice
sudopara reiniciar JupyterHub.sudo systemctl restart jupyterhub.service
Como usuario administrador, puede almacenar los blocs de notas de usuario individual en Object Storage en lugar de HDFS. Al cambiar el gestor de contenido de HDFS a Object Storage, los blocs de notas existentes no se copian en Object Storage. Los nuevos blocs de notas se guardan en Object Storage.
- Conéctese como usuario
opcal nodo de utilidad donde está instalado JupyterHub (el segundo nodo de utilidad de un cluster de HA [alta disponibilidad] o el primer y único nodo de utilidad de un cluster sin HA). - Utilice
sudopara gestionar las configuraciones de JupyterHub que se almacenan en/opt/jupyterhub/jupyterhub_config.py. Consulte la sección sobre la generación de la clave secreta y la de acceso para obtener información sobre cómo generar las claves necesarias.c.Spawner.args = ['--ServerApp.contents_manager_class="s3contents.S3ContentsManager"', '--S3ContentsManager.bucket="<bucket-name>"', '--S3ContentsManager.access_key_id="<accesskey>"', '--S3ContentsManager.secret_access_key="<secret-key>"', '--S3ContentsManager.endpoint_url="https://<object-storage-endpoint>"', '--S3ContentsManager.region_name="<region>"','--ServerApp.root_dir=""'] - Utilice
sudopara reiniciar JupyterHub.sudo systemctl restart jupyterhub.service
Integrar con Object Storage
Integre Spark con el almacenamiento de objetos para utilizarlo con clusters de Big Data Service.
En JupyterHub, para que Spark funcione con Object Storage, debe definir algunas propiedades del sistema y rellenarlas en las propiedades spark.driver.extraJavaOption y spark.executor.extraJavaOptions en las configuraciones de Spark.
Para integrar correctamente JupyterHub con Object Storage, debe:
- Crear un cubo en Object Store para almacenar datos.
- Crear una clave de API de Object Storage.
Las propiedades que debe definir en las configuraciones de Spark son:
-
TenantID -
Userid -
Fingerprint -
PemFilePath -
PassPhrase -
Region
Recuperan los valores de estas propiedades:
- Abra el menú de navegación y seleccione Analytics & AI. En Lago de datos, seleccione Big Data Service.
- En la página de lista Clusters, seleccione el cluster con el que desea trabajar. Si necesita ayuda para buscar la página de lista o el cluster, consulte Lista de clusters en un compartimento.
-
Para ver clusters en un compartimento diferente, cambie el compartimento.
Debe tener permiso para trabajar en un compartimento para ver los recursos que contiene. Si no está seguro de qué compartimiento utilizar, póngase en contacto con un administrador. Para obtener más información, consulte Descripción de los compartimentos.
- En la página Detalles de cluster, seleccione Claves de API de Object Storage.
- En el menú de la clave de API que desea ver, seleccione Ver archivo de configuración.
El archivo de configuración tiene todos los detalles de las propiedades del sistema, excepto la frase de contraseña. La frase de contraseña se especifica cuando se crea la clave de API de Object Storage. Debe recordar y utilizar la misma frase de contraseña.
- Acceda a JupyterHub.
- Abra un nuevo bloc de notas.
- Copie y pegue los siguientes comandos para conectarse a Spark.
import findspark findspark.init() import pyspark - Copie y pegue los siguientes comandos para crear una sesión de Spark con las configuraciones especificadas. Cambie las variables por los valores de propiedades del sistema que ha recuperado antes.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("spark.driver.extraJavaOptions", "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .config("spark.executor.extraJavaOptions" , "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .appName("<appname>") \ .getOrCreate() - Copie y pegue los siguientes comandos para crear el archivo y los directorios de Object Storage y almacenar datos en formato de Parquet.
demoUri = "oci://<BucketName>@<Tenancy>/<DirectoriesAndSubDirectories>/" parquetTableUri = demoUri + "<fileName>" spark.range(10).repartition(1).write.mode("overwrite").format("parquet").save(parquetTableUri) - Copie y pegue el siguiente comando para leer los datos de Object Storage.
spark.read.format("parquet").load(parquetTableUri).show() - Ejecute el bloc de notas con todos estos comandos.
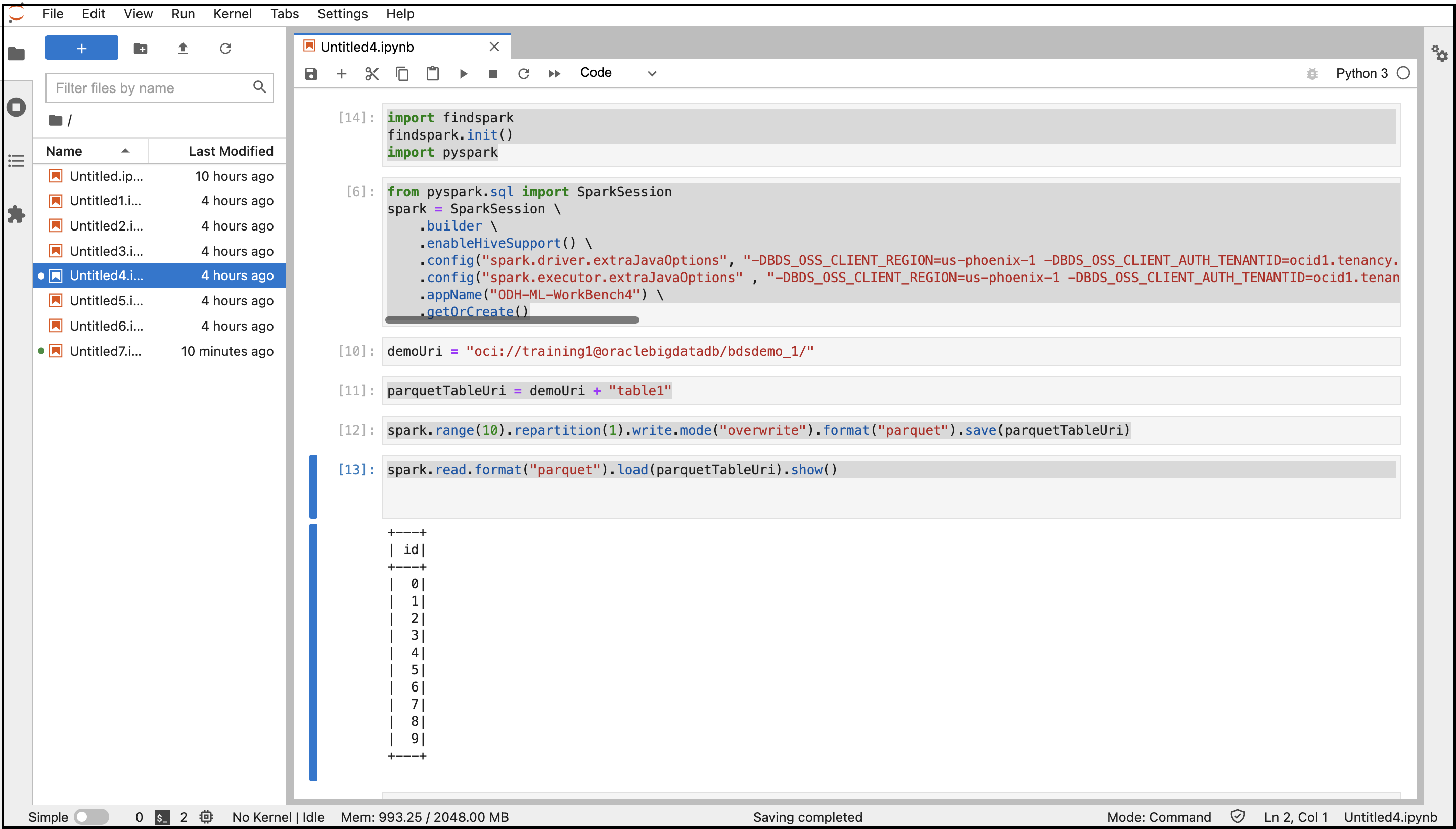
Se mostrará la salida del código. Puede desplazarse hasta el bucket de Object Storage desde la consola y buscar el archivo creado en el bucket.
Gestión de usuarios y permisos
Utilice uno de los dos métodos de autenticación para autenticar usuarios en JupyterHub de modo que puedan crear blocs de notas y, si lo desea, administrar JupyterHub.
Por defecto, los clusters de ODH 1.x admiten la autenticación nativa. Sin embargo, la autenticación para JupyterHub y otros servicios de big data se deben manejar de forma diferente. Para generar blocs de notas de un solo usuario, el usuario que se conecta a JupyterHub debe estar presente en el host de Linux y debe tener permisos para escribir en el directorio raíz de HDFS. De lo contrario, el generador falla cuando se dispara el proceso de bloc de notas como usuario de Linux.
Para obtener información sobre la autenticación nativa, consulte Autenticación nativa.
Para obtener información sobre la autenticación LDAP para Big Data Service 3.0.26 o una versión anterior, consulte LDAP Authentication.
La autenticación nativa depende de la base de datos de usuarios JupyterHub para autenticar usuarios.
La autenticación nativa se aplica tanto a los clusters de HA como a los clusters sin HA. Consulte la sección sobre el autenticador nativo para obtener más información sobre el autenticador nativo.
Estos requisitos se deben cumplir para autorizar a un usuario en un cluster de HA de Big Data Service mediante autenticación nativa.
Estos requisitos se deben cumplir para autorizar a un usuario en un cluster sin HA de Big Data Service mediante autenticación nativa.
Los usuarios administradores son los responsables de configurar y gestionar JupyterHub. Los usuarios administradores también son responsables de autorizar a los usuarios recién registrados en JupyterHub.
Antes de agregar un usuario administrador, se deben cumplir los requisitos de un cluster sin HA.
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, en Servicios, seleccione JupyterHub.
- Seleccione Configuración y, a continuación, seleccione Configuraciones avanzadas.
- Seleccione Advanced jupyterhub-config.
-
Agregue el usuario administrador a
c.Authenticator.admin_users. - Seleccione Guardar.
Antes de agregar otros usuarios, se deben cumplir los requisitos para un cluster de Big Data Service.
-
El usuario administrador debe conectarse a JupyterHub y desde la nueva opción de menú para autorizar a los usuarios conectados, debe autorizar al nuevo usuario.
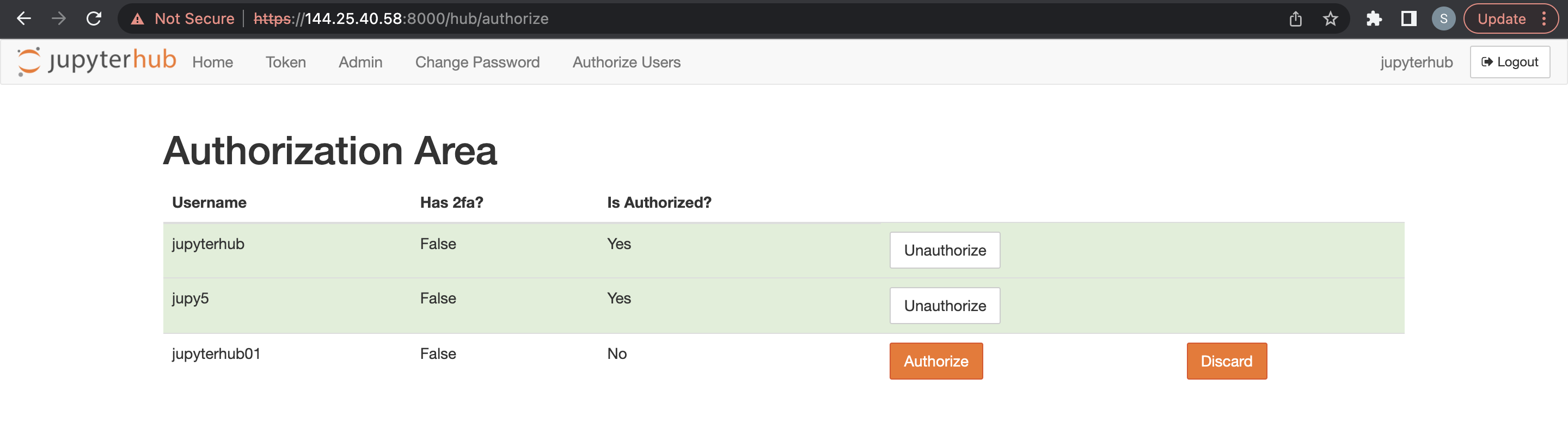
Un usuario administrador puede suprimir usuarios JupyterHub.
- Acceda a JupyterHub.
- Abra Archivo > HubControlPanel.
- Vaya a la página Authorize Users.
- Suprima los usuarios que desea eliminar.
Puede utilizar la autenticación LDAP mediante un explorador para clusters de ODH 1.x de Big Data Service 3.0.26 o anteriores.
Integración con Trino
- Trino se debe instalar y configurar en el cluster de Big Data Service.
- Instale el siguiente módulo de Python en el nodo JupyterHub (un1 para HA / un0 para cluster sin HA) Nota
Ignore este paso si el módulo Trino-Python ya está presente en el nodo.python3.6 -m pip install trino[sqlalchemy] Offline Installation: Download the required python module in any machine where we have internet access Example: python3 -m pip download trino[sqlalchemy] -d /tmp/package Copy the above folder content to the offline node & install the package python3 -m pip install ./package/* Note : trino.sqlalchemy is compatible with the latest 1.3.x and 1.4.x SQLAlchemy versions. BDS cluster node comes with python3.6 and SQLAlchemy-1.4.46 by default.
Si el Trino-Ranger-Plugin está activado, asegúrese de agregar el usuario keytab proporcionado en las respectivas políticas de Trino Ranger. Consulte Integración de Trino con Ranger.
De manera predeterminada, Trino utiliza el nombre principal de Kerberos completo como usuario. Por lo tanto, al agregar/actualizar políticas de trino-ranger, debe utilizar el nombre principal de Kerberos completo como nombre de usuario.
Para el siguiente ejemplo de código, utilice jupyterhub@BDSCLOUDSERVICE.ORACLE.COM como usuario en las políticas de trino-ranger.
Si Trino-Ranger-Plugin está activado, asegúrese de agregar el usuario keytab proporcionado en las respectivas políticas de Trino Ranger. Para obtener más información, consulte Enabling Ranger for Trino.
Proporcione permisos de Ranger para JupyterHub a las siguientes políticas:
-
all - catalog, schema, table, column -
all - function