Uso de JupyterHub en Big Data Service 3.0.27 o posterior
Utilice JupyterHub para gestionar blocs de notas de Big Data Service 3.0.27 o posterior de ODH 2.x para grupos de usuarios.
Requisitos
Acceso a JupyterHub
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, en Servicios, seleccione JupyterHub.
Gestionar JupyterHub
Un usuario JupyterHub admin puede realizar las siguientes tareas para gestionar blocs de notas en JupyterHub en nodos de ODH 2.x de Big Data Service 3.0.27 o posterior.
Para gestionar los servicios de Oracle Linux 7 con el comando systemctl, consulte la sección sobre cómo trabajar con servicios del sistema.
Para conectarse a una instancia de Oracle Cloud Infrastructure, consulte Conexión a una instancia.
Como administrador, puede parar o desactivar JupyterHub para que no consuma recursos como, por ejemplo, la memoria. Reiniciar también puede ayudar con problemas o comportamientos inesperados.
Pare o inicie JupyterHub mediante Ambari para clusters de Big Data Service 3.0.27 o posteriores.
Como administrador, puede agregar el servidor JupyterHub a un nodo de Big Data Service.
Está disponible para clusters de Big Data Service 3.0.27 o posteriores.
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, seleccione Hosts (Hosts).
- Para agregar el servidor JupyterHub, seleccione un host en el que JupyterHub no esté instalado.
- Seleccione Agregar.
- Seleccione JupyterHub Server.
Como administrador, puede mover el servidor JupyterHub a un nodo de Big Data Service diferente.
Está disponible para clusters de Big Data Service 3.0.27 o posteriores.
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, en Servicios, seleccione JupyterHub.
- Seleccione Acciones y, a continuación, seleccione Mover servidor JupyterHub.
- Seleccione Next (Siguiente).
- Seleccione el host al que desea mover el servidor JupyterHub.
- Complete el asistente para mover.
Como administrador, puede ejecutar comprobaciones de servicio/estado de JupyterHub mediante Ambari.
Está disponible para clusters de Big Data Service 3.0.27 o posteriores.
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, en Servicios, seleccione JupyterHub.
- Seleccione Acciones y, a continuación, Ejecutar comprobación de servicio.
Gestión de usuarios y permisos
Utilice uno de los dos métodos de autenticación para autenticar usuarios en JupyterHub de modo que puedan crear blocs de notas y, si lo desea, administrar JupyterHub en clusters de ODH 2.x de Big Data Service 3.0.27 o posterior.
Los usuarios de JupyterHub se deben agregar como usuarios del sistema operativo en todos los nodos de cluster de Big Data Service para clusters de Big Data Service que no sean de Active Directory (AD), donde los usuarios no se sincronizan automáticamente entre todos los nodos de cluster. Los administradores pueden utilizar el script de gestión de usuarios JupyterHub para agregar usuarios y grupos antes de conectarse a JupyterHub.
Requisitos
Complete lo siguiente antes de acceder a JupyterHub:
- Inicie sesión SSH en el nodo donde está instalado JupyterHub.
- Vaya a
/usr/odh/current/jupyterhub/install. - Para proporcionar los detalles de todos los usuarios y grupos en el archivo
sample_user_groups.json, ejecute:sudo python3 UserGroupManager.py sample_user_groups.json Verify user creation by executing the following command: id <any-user-name>
Tipos de Autenticación Soportados
- NativeAuthenticator: este autenticador se utiliza para aplicaciones JupyterHub pequeñas o medianas. El registro y la autenticación se implantan como nativos de JupyterHub sin depender de servicios externos.
-
SSOAuthenticator: este autenticador proporciona una subclase de
jupyterhub.auth.Authenticatorque actúa como proveedor de servicios SAML2. Diríjala a un proveedor de identidad SAML2 configurado correctamente y activa la conexión única para JupyterHub.
La autenticación nativa depende de la base de datos de usuarios JupyterHub para autenticar usuarios.
La autenticación nativa se aplica tanto a los clusters de HA como a los clusters sin HA. Consulte la sección sobre el autenticador nativo para obtener más información sobre el autenticador nativo.
Estos requisitos se deben cumplir para autorizar a un usuario en un cluster de HA de Big Data Service mediante autenticación nativa.
Estos requisitos se deben cumplir para autorizar a un usuario en un cluster sin HA de Big Data Service mediante autenticación nativa.
Los usuarios administradores son los responsables de configurar y gestionar JupyterHub. Los usuarios administradores también son responsables de autorizar a los usuarios recién registrados en JupyterHub.
Antes de agregar un usuario administrador, se deben cumplir los requisitos de un cluster sin HA.
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, en Servicios, seleccione JupyterHub.
- Seleccione Configuración y, a continuación, seleccione Configuraciones avanzadas.
- Seleccione Advanced jupyterhub-config.
-
Agregue el usuario administrador a
c.Authenticator.admin_users. - Seleccione Guardar.
Antes de agregar otros usuarios, se deben cumplir los requisitos para un cluster de Big Data Service.
-
El usuario administrador debe conectarse a JupyterHub y desde la nueva opción de menú para autorizar a los usuarios conectados, debe autorizar al nuevo usuario.
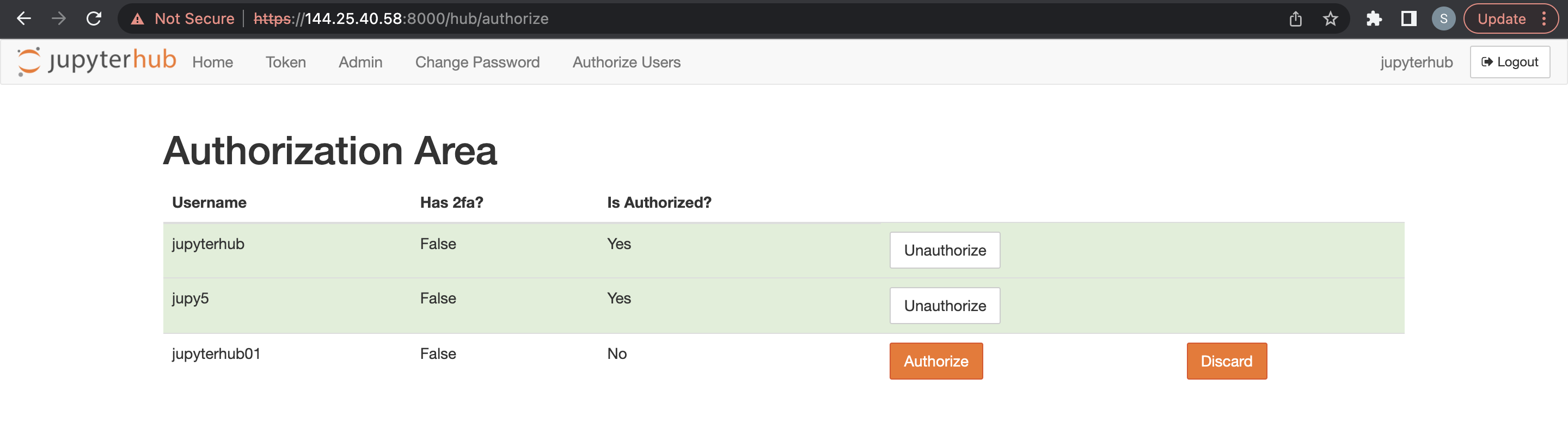
Un usuario administrador puede suprimir usuarios JupyterHub.
- Acceda a JupyterHub.
- Abra Archivo > HubControlPanel.
- Vaya a la página Authorize Users.
- Suprima los usuarios que desea eliminar.
Puede utilizar la autenticación LDAP mediante Ambari para clusters de ODH 2.x de Big Data Service 3.0.27 o posterior.
Uso de la autenticación de LDAP mediante Ambari
Para utilizar el autenticador de LDAP, debe actualizar el archivo de configuración de JupyterHub con los detalles de conexión de LDAP.
Utilice Ambari para la autenticación LDAP en clusters de Big Data Service 3.0.27 o posteriores.
Consulte la sección sobre el autenticador de LDAP para obtener detalles sobre el autenticador de LDAP.
pConfigure Autenticación de SSO en el servicio Big Data Service 3.0.27 o posterior ODH 2.x JupyterHub.
Puede utilizar el dominio de identidad de Oracle para configurar la autenticación de SSO en clusters JupyterHub de ODH 2.x de Big Data Service 3.0.27 o posterior.
Puede utilizar OKTA para configurar la autenticación de SSO en los clusters JupyterHub de ODH 2.x de Big Data Service 3.0.27 o posterior.
Como administrador, puede gestionar las configuraciones de JupyterHub mediante Ambari para clusters de ODH 2.x de Big Data Service 3.0.27 o posterior.
Generación de blocs de notas
Las siguientes configuraciones de Spawner están soportadas en los clusters de Big Data Service 3.0.27 y posteriores de ODH 2.x.
Complete lo siguiente:
- Autenticación Nativa:
- Iniciar sesión con credenciales de usuario conectado
- Introducir usuario.
- Introduzca la contraseña.
- Uso de SamlSSOAuthenticator:
- Conéctese con SSO.
- Complete el inicio de sesión con la aplicación SSO configurada.
Generación de blocs de notas en un cluster de HA
Para el cluster integrado de AD:
- Inicie sesión con cualquiera de los métodos anteriores. La autorización solo funciona si el usuario está presente en el host de Linux. JupyterHub busca el usuario en el host de Linux al intentar generar el servidor del bloc de notas.
- Se le redirigirá a una página de opciones de servidor en la que debe solicitar un ticket de Kerberos. Este ticket se puede solicitar mediante el principal de Kerberos y el archivo keytab, o la contraseña de Kerberos. El administrador del cluster puede proporcionar el principal de Kerberos y el archivo keytab, o la contraseña de Kerberos. El ticket de Kerberos es necesario para obtener acceso a los directorios de HDFS y otros servicios de big data que desea utilizar.
Generación de Notebooks en un cluster sin HA
Para el cluster integrado de AD:
Inicie sesión con cualquiera de los métodos anteriores. La autorización solo funciona si el usuario está presente en el host de Linux. JupyterHub busca el usuario en el host de Linux al intentar generar el servidor del bloc de notas.
- Configure claves SSH/tokens de acceso para el nodo de cluster de Big Data Service.
- Seleccione el modo de persistencia de bloc de notas como Git.
Para configurar la conexión de Git para JupyterHub, complete lo siguiente:
- Tokens de acceso para el nodo de cluster de Big Data Service.
- Seleccionar modo de persistencia de bloc de notas como Git
Generación de Par de Claves SSH
Uso de tokens de acceso
Puede utilizar tokens de acceso de las siguientes formas:
- GitHub:
- Conéctese a su cuenta de GitHub.
- Vaya a Configuración > Configuración de desarrollador > Tokens de acceso personal.
- Genere un nuevo token de acceso con los permisos adecuados.
- Utilice el token de acceso como contraseña cuando se le solicite autenticación.
- GitLab:
- Conéctese a su cuenta de GitHub.
- Vaya a Configuración > Tokens de acceso.
- Genere un nuevo token de acceso con los permisos adecuados.
- Utilice el token de acceso como contraseña cuando se le solicite autenticación.
- BitBucket:
- Conéctese a su cuenta de BitBucket.
- Vaya a Configuración > Contraseñas de aplicación.
- Genere un nuevo token de contraseña de aplicación con los permisos adecuados.
- Utilice la nueva contraseña de aplicación como contraseña cuando se le solicite autenticación.
Selección del Modo de Persistencia como Git
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, en Servicios, seleccione JupyterHub.
- Seleccione Configuración y, a continuación, seleccione Configuración.
- Busque Modo de persistencia de bloc de notas y, a continuación, seleccione Git en la lista desplegable.
- Seleccione Acciones y, a continuación, seleccione Reiniciar todo.
- Acceda a Apache Ambari.
- En la barra de herramientas lateral, en Servicios, seleccione JupyterHub.
- Seleccione Configuración y, a continuación, seleccione Configuración.
- Busque Modo de persistencia de bloc de notas y, a continuación, seleccione HDFS en la lista desplegable.
- Seleccione Acciones y, a continuación, seleccione Reiniciar todo.
Como usuario administrador, puede almacenar los blocs de notas de usuario individual en Object Storage en lugar de HDFS. Al cambiar el gestor de contenido de HDFS a Object Storage, los blocs de notas existentes no se copian en Object Storage. Los nuevos blocs de notas se guardan en Object Storage.
Montaje del cubo de Oracle Object Storage mediante rclone con autenticación de principal de usuario
Puede montar Oracle Object Storage mediante rclone con autenticación de principal de usuario (claves de API) en un nodo de cluster de Big Data Service mediante rclone y fuse3, adaptados para los usuarios de JupyterHub.
Gestionar entornos conda en JupyterHub
Puede gestionar entornos conda en clusters de ODH 2.x de Big Data Service 3.0.28 o posterior.
- Cree un entorno conda con dependencias específicas y cuatro núcleos (Python/PySpark/Spark/SparkR) que apunten al entorno conda creado.
- Los entornos conda y los núcleos creados mediante esta operación están disponibles para todos los usuarios del servidor de bloc de notas.
- La operación de creación de entorno conda independiente consiste en disociar la operación con el reinicio del servicio.
- JupyterHub se instala mediante la interfaz de usuario de Ambari.
- Verifique el acceso de Internet al cluster para descargar dependencias durante la creación del conda.
- Los entornos conda y los núcleos creados con esta operación están disponibles para todos los usuarios del servidor de bloc de notas".
- Proporcione:
- Configuraciones adicionales de Conda para evitar fallos de creación de conda. Para obtener más información, consulte conda create.
- Dependencias en el formato
.txtde requisitos estándar. - Nombre de entorno conda que no existe.
- Suprima manualmente los núcleos o entornos conda.
Esta operación crea un entorno conda con dependencias especificadas y crea el núcleo especificado (Python/PySpark/Spark/SparkR) que apunta al entorno conda creado.
- Si el entorno conda especificado ya existe, la operación continúa directamente con el paso de creación del núcleo
- Los entornos conda o los núcleos creados mediante esta operación solo están disponibles para un usuario específico
- Ejecute manualmente el script de python
kernel_install_script.pyen modo sudo:'/var/lib/ambari-server/resources/mpacks/odh-ambari-mpack-2.0.8/stacks/ODH/1.1.12/services/JUPYTER/package/scripts/'Ejemplo:
sudo python kernel_install_script.py --conda_env_name conda_jupy_env_1 --conda_additional_configs '--override-channels --no-default-packages --no-pin -c pytorch' --custom_requirements_txt_file_path ./req.txt --kernel_type spark --kernel_name spark_jupyterhub_1 --user jupyterhub
Requisitos
- Verifique el acceso de Internet al cluster para descargar dependencias durante la creación del conda. De lo contrario, falla la creación.
- Si existe un núcleo con el nombre
--kernel_name, se devuelve una excepción. - Proporcione lo siguiente:
- Configuraciones conda para evitar fallos de creación. Para obtener más información, consulte https://conda.io/projects/conda/en/latest/commands/create.html.
- Dependencias proporcionadas en el formato
.txtde requisitos estándar.
- Suprima manualmente los entornos conda o los núcleos de cualquier usuario.
Configuraciones disponibles para personalización
-
--user(obligatorio): sistema operativo y usuario JupyterHub para el que se crea el núcleo y el entorno conda. -
--conda_env_name(obligatorio): proporcione un nombre único para el entorno conda cada vez que se cree un nuevo en para--user. -
--kernel_name: (obligatorio) proporcione un nombre de núcleo único. -
--kernel_type: (obligatorio) debe ser uno de los siguientes (python / PysPark / Spark / SparkR) -
--custom_requirements_txt_file_path: (opcional) si algún Python/R/Ruby/Lua/Scala/Java/JavaScript/C/C++/FORTRAN, etc., las dependencias se instalan mediante canales conda, debe especificar esas bibliotecas en un archivo.txtde requisitos y proporcionar la ruta completa.Para obtener más información sobre un formato estándar para definir el archivo
.txtde requisitos, consulte https://pip.pypa.io/en/stable/reference/requirements-file-format/. -
--conda_additional_configs: (opcional)- Este campo proporciona parámetros adicionales que se agregarán al comando predeterminado de creación de conda.
- El comando de creación conda por defecto es:
'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8'. - Si
--conda_additional_configsse proporciona como'--override-channels --no-default-packages --no-pin -c pytorch', la ejecución final del comando de creación de conda es'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8 --override-channels --no-default-packages --no-pin -c pytorch'.
Configuración de un entorno conda específico del usuario
Creación de un equilibrador de carga y un juego de backend
Para obtener más información sobre la creación de juegos de backends, consulte Creación de un juego de backends del equilibrador de carga.
Para obtener más información sobre la creación de un equilibrador de carga público, consulte Creación de un equilibrador de carga y complete los siguientes detalles.
Para obtener más información sobre la creación de un equilibrador de carga público, consulte Creación de un equilibrador de carga y complete los siguientes detalles.
- Abra el menú de navegación, seleccione Networking y, a continuación, seleccione Load balancers. Seleccione Equilibrador de carga. Aparecerá la página Equilibradores de carga.
- Seleccione el compartimento en la lista. Todos los equilibradores de carga de ese compartimento se muestran en formato tabular.
- Seleccione el equilibrador de carga al que desea agregar un backend. Aparece la página de detalles del equilibrador de carga.
- Seleccione Juegos de backends y, a continuación, seleccione el juego de backends que ha creado en Creación del equilibrador de carga.
- Seleccione las direcciones IP y, a continuación, introduzca la dirección IP privada necesaria del cluster.
- Introduzca 8000 para el Puerto.
- Seleccione Agregar.
Para obtener más información sobre la creación de un equilibrador de carga público, consulte Creación de un equilibrador de carga y complete los siguientes detalles.
-
Abra un explorador e introduzca
https://<loadbalancer ip>:8000. - Seleccione el compartimento en la lista. Todos los equilibradores de carga de ese compartimento se muestran en formato tabular.
- Asegúrese de que redirige a uno de los servidores JupyterHub. Para verificarlo, abra una sesión de terminal en JupyterHub para buscar el nodo al que se ha llegado.
- Después de agregar la operación de nodo, el administrador del cluster debe actualizar manualmente la entrada de host del equilibrador de carga en los nodos recién agregados. Aplicable a todas las adiciones de nodos al cluster. Por ejemplo, nodo de trabajador, solo cálculo y nodos.
- El certificado se debe actualizar manualmente al equilibrador de carga en caso de caducidad. Este paso garantiza que el equilibrador de carga no utilice certificados anticuados y evita fallos de comprobación del sistema/comunicación en los juegos de backends. Para obtener más información, consulte Actualización de un certificado de equilibrador de carga que caduca para actualizar el certificado caducado.
Iniciar núcleos Trino-SQL
El núcleo JupyterHub PyTrino proporciona una interfaz SQL que permite ejecutar consultas Trino mediante JupyterHub SQL. Está disponible para clusters ODH 2.x de Big Data Service 3.0.28 o posterior.
Para obtener más información sobre los parámetros SqlMagic, consulte https://jupysql.ploomber.io/en/latest/api/configuration.html#changing-configuration.