Protéger les bases de données critiques contre les défaillances et les sinistres à l'aide d'Autonomous Data Guard
La fonction Autonomous Data Guard vous permet d'assurer la disponibilité de vos bases de données de production critiques pour les applications stratégiques, même en cas de panne, de sinistre, d'erreur humaine ou de corruption de données. Ce type de capacité est souvent appelé reprise après sinistre.
Dans une base de données d'intelligence artificielle autonome sur une infrastructure Exadata dédiée, vous configurez et gérez Autonomous Data Guard au niveau de la base de données conteneur autonome.
À propos d'Autonomous Data Guard
Autonomous Data Guard crée et gère deux copies complètement distinctes de votre base de données : une base de données principale à laquelle vos applications se connectent et l'utilisent, et une base de données de secours qui est une copie synchronisée de la base de données principale. Ensuite, si la base de données principale n'est plus disponible pour une raison quelconque, Autonomous Data Guard peut convertir la base de données de secours en base de données principale et, par conséquent, il commencera à traiter vos applications.
Les bases de données principale et de secours sont souvent appelées bases de données pair les unes des autres. Vous pouvez avoir jusqu'à deux bases de données de secours par base de données conteneur autonome.
Note : Les applications doivent être configurées pour utiliser Transparent Application Continuity (TAC) afin de tirer pleinement parti des fonctions de disponibilité des bases de données fournies par Autonomous Data Guard.
Le diagramme suivant montre comment chaque base de données de secours est synchronisée avec la base principale.
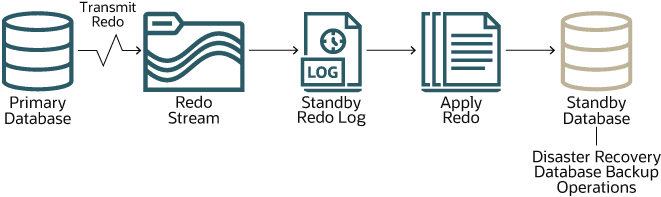
Description de l'illustration autonomous-data-guard.png
Les modifications apportées à la base principale sont enregistrées dans le fichier de journalisation de celle-ci. Autonomous Data Guard transmet ces enregistrements de journalisation au fichier de journalisation de la base de secours sous forme de flux par le réseau. Ensuite, ces enregistrements sont appliqués à la base de secours. Ainsi, la base de secours est synchronisée avec la base principale.
La synchronisation est presque instantanée mais, comme l'implique le processus qui vient d'être décrit, deux opérations prennent du temps : le transport des enregistrements de journalisation vers la base de secours et l'application de ces enregistrements à la base de secours. Le premier d'entre eux est appelé décalage de transport et l'autre est appelé décalage d'application. Vous pouvez voir les valeurs de décalage courantes pour une base de données avec intelligence artificielle autonome à partir de la page Détails de la base de données sous Autonomous Data Guard. Vous pouvez voir les valeurs de décalage courantes dans toutes les bases de données autonomes d'une base de données conteneur à partir de la page Détails de la base de données conteneur de la même manière.
Note : Avec plusieurs bases de données de secours, le transport des données de journalisation en cascade n'est pas pris en charge.
Configuration d'Autonomous Data Guard
Dans une base de données d'IA autonome sur une infrastructure Exadata dédiée, vous configurez et gérez Autonomous Data Guard au niveau de la base de données conteneur autonome. Vous pouvez activer Autonomous Data Guard pour les bases de données conteneur autonomes déjà provisionnées et ajouter jusqu'à deux bases de données conteneur autonomes de secours à partir de sa page Détails à l'aide de la console Oracle Cloud Infrastructure. Pour obtenir des instructions, voir Activer Autonomous Data Guard sur une base de données conteneur autonome et Ajouter une deuxième base de données conteneur autonome de secours.
-
Vous pouvez maintenant créer et gérer Autonomous Data Guard entre une base de données conteneur autonome dans Oracle Cloud Infrastructure (OCI) et une base de données conteneur autonome dans Amazon Web Services (AWS).
-
Vous pouvez ajouter une base de données conteneur autonome de secours à partir de la région AWS à la base de données conteneur autonome déjà provisionnée dans la région OCI. Vous pouvez également ajouter une base de données conteneur autonome de secours dans la région OCI à une base de données conteneur autonome déjà provisionnée dans la région AWS.
Notez les points suivants avant de configurer Autonomous Data Guard :
-
Les bases de données d'intelligence artificielle autonomes déployées sur Exadata Cloud@Customer doivent avoir un port 1522 ouvert pour permettre le trafic TCP entre la base de données principale et la base de secours dans une configuration Autonomous Data Guard.
-
Autonomous Data Guard ne peut pas être activé sur une base de données conteneur autonome avec une exécution de maintenance active programmée dans les trois prochains jours. Vous pouvez d'abord exécuter la maintenance active, puis activer Autonomous Data Guard ou modifier le programme d'exécution de la maintenance afin qu'elle ne commence pas avant l'ajout de la deuxième base de données de secours.
-
L'ajout d'une deuxième base de données de secours nécessite un redémarrage de repositionnement automatique pour la première base de données de secours. La base principale n'est pas affectée par ce redémarrage de repositionnement.
Configurer Autonomous Data Guard à l'aide de clés gérées par le client
Dans Autonomous AI Database sur une infrastructure Exadata dédiée, vous pouvez configurer et gérer Autonomous Data Guard à l'aide de clés gérées par le client au niveau de la base de données conteneur autonome. Vous pouvez activer Autonomous Data Guard pour les bases de données conteneur autonomes déjà provisionnées et ajouter jusqu'à deux bases de données conteneur autonomes de secours à partir de sa page Détails à l'aide de la console Oracle Cloud Infrastructure. Voir Activer Autonomous Data Guard sur une base de données conteneur autonome et Ajouter une deuxième base de données conteneur autonome de secours pour obtenir des instructions.
Notez les points suivants avant de configurer Autonomous Data Guard avec des clés gérées par le client :
-
Si vous utilisez le système Oracle Cloud Infrastructure Key Management (OCI KMS) et souhaitez activer Autonomous Data Guard inter-régions :
-
Vous devez d'abord répliquer la chambre forte OCI dans la région où vous voulez ajouter la base de données de secours. Pour plus de détails, voir Réplication des chambres fortes et des clés.
-
Vous ne pouvez avoir que les bases de données principale et de secours dans un maximum de 2 régions. Autrement dit, si vous voulez ajouter une deuxième base de données de secours et que vous avez déjà utilisé une inter-région pour la première base de données de secours, la deuxième base de données de secours doit se trouver dans la région principale ou la première région de secours.
Note : Les chambres fortes virtuelles créées avant l'introduction de la fonction de réplication de chambre forte inter-région ne peuvent pas être répliquées entre les régions. Créez une chambre forte et de nouvelles clés si vous avez une chambre forte que vous devez répliquer dans une autre région et que la réplication n'est pas prise en charge pour cette chambre forte. Toutefois, toutes les chambres fortes privées prennent en charge la réplication inter-région. Voir Réplication inter-région de chambre forte virtuelle pour plus de détails.
-
-
Si vous utilisez Oracle Key Vault (OKV) et souhaitez activer Autonomous Data Guard inter-régions, assurez-vous d'avoir ajouté des adresses IP de connexion pour votre grappe OKV dans le magasin de clés.
-
Si vous utilisez AWS Key Management System (AWS KMS) et souhaitez activer Autonomous Data Guard inter-régions :
- Une clé multi-région AWS doit être enregistrée dans la région principale. Vous ne pouvez sélectionner le type de clé AWS comme multi-région que lorsque vous le créez et qu'il ne peut pas être modifié ultérieurement.
- Vous devez définir les politiques requises dans la région répliquée car les politiques ne sont pas répliquées automatiquement.
- La clé multi-région AWS KMS doit être répliquée de la région source vers la région cible à partir de la console AWS. Pour plus de détails, voir Répliquer les clés KMS AWS dans la console AWS.
- La clé multi-région AWS KMS doit être répliquée de la région principale vers la région cible à partir de la console OCI. Pour plus de détails, voir Répliquer les clés KMS AWS dans la console OCI.
Changements de rôle et opérations
Une fois une base de données conteneur autonome créée, vous pouvez modifier le rôle des bases de données pairs à l'aide d'une permutation ou d'une opération de basculement. Si le basculement automatique est activé, Autonomous Data Guard effectue automatiquement une opération de basculement chaque fois que la base de données principale devient indisponible, pour quelque raison que ce soit.
Une passerelle de permutation est une annulation de rôle entre la base de données principale et sa base de données de secours. Une permutation garantit qu'il n'y aura aucune perte de données. Lors d'une permutation, la base principale prend le rôle de base de secours et la base de secours prend le rôle de base principale. Pour effectuer une opération de permutation, voir Changer de rôle dans une configuration d'Autonomous Data Guard.
Un basculement se produit lorsque la base de données principale n'est pas disponible. Lors d'un basculement, la base de secours devient la base principale. Si le basculement automatique n'est pas activé, vous pouvez effectuer un basculement manuel, comme décrit sous Basculer vers la base de données de secours dans une configuration Autonomous Data Guard.
La disponibilité et le statut de la base de données après une opération de basculement se caractérisent par deux objectifs de récupération :
-
Objectif de temps de récupération (ODR). Il s'agit du délai maximal autorisé pour que la base de données soit disponible pour les applications après un basculement. Elle est liée dans une certaine mesure au décalage d'application au moment de la panne. Pour Autonomous Data Guard, l'objectif de délai de récupération va de quelques secondes à deux minutes au maximum.
-
Objectif de point de reprise (OPR). Il s'agit de la durée maximale de perte de données potentielle de la base principale défaillante. Elle est liée dans une certaine mesure au décalage de transport au moment de la défaillance. Pour Autonomous Data Guard, l'objectif de point de récupération est proche de zéro.
Après un basculement, la base principale en échec devient une base de secours désactivée et reste indisponible pour toute connexion à la base de données. Vous pouvez la réactiver et la transformer en base de données de secours saine en effectuant une opération de remise en service. Une fois qu'une base principale défaillante a été rétablie en tant que base de données de secours, vous pouvez effectuer une permutation pour la rétablir dans son rôle principal initial. Pour effectuer une opération reinstate, voir Rétablir la base de secours désactivée dans une configuration Autonomous Data Guard.
Basculement automatique ou basculement à démarrage rapide
Avec le basculement automatique, chaque fois que la base de données conteneur autonome principale devient indisponible en raison d'une défaillance de région, d'un domaine de disponibilité, d'une défaillance de l'infrastructure Exadata ou de la grappe de machines virtuelles Exadata autonome (AVMC), ou de la défaillance de la base de données conteneur autonome elle-même, elle bascule automatiquement vers la base de données conteneur autonome de secours. Cette fonction est appelée basculement à démarrage rapide.
Vous ne pouvez pas activer le basculement automatique lors de la configuration d'Autonomous Data Guard sur une base de données conteneur autonome. Le basculement automatique ne peut être activé ou désactivé que lors de la mise à jour des paramètres Autonomous Data Guard à partir de la page Détails de la base de données conteneur autonome.
Note : Le basculement automatique ne peut pas être activé pour les bases de données d'intelligence artificielle autonomes déployées dans Exadata Cloud@Customer avec une configuration Autonomous Data Guard inter-région.
Vous ne pouvez pas ajouter une deuxième base de données conteneur autonome de secours lorsque le basculement automatique est activé pour la première base de données conteneur autonome de secours. Désactivez donc le basculement automatique à l'aide de Mettre à jour les paramètres Autonomous Data Guard avant la création de la deuxième base de données conteneur autonome de secours et réactivez-la ultérieurement, si nécessaire.
Les modes de protection Performance maximale et Disponibilité maximale prennent en charge le basculement automatique :
-
En mode Disponibilité maximale, le basculement automatique garantit qu'il n'y a aucune perte de données.
-
En mode Performance maximale, le basculement automatique garantit que la base de données de secours n'est pas en retard par rapport à la base principale au-delà de la valeur spécifiée pour Limite de décalage pour le basculement à démarrage rapide. Par défaut, la limite du décalage pour le basculement à démarrage rapide est réglée à 30 secondes et s'applique uniquement au mode de performance maximale. Dans ce cas, le basculement automatique n'est possible que lorsque le décalage d'application (perte de données potentielle) de la base de secours ne dépasse pas la limite de décalage configurée. Vous pouvez modifier la limite du décalage pour le basculement rapide à une valeur comprise entre 5 et 3600.
Pour plus de détails, voir Mettre à jour les paramètres Autonomous Data Guard.
Outre les défaillances matérielles, les pannes de domaine de disponibilité et les pannes régionales, d'autres états de base de données peuvent déclencher un basculement à démarrage rapide, comme indiqué ci-dessous :
| État de base de données | Description |
|---|---|
| Fichier de contrôle corrompu | Le fichier de contrôle est définitivement endommagé en raison d'une défaillance du disque. |
| Dictionnaire corrompu | Corruption du dictionnaire d'une base de données critique. Actuellement, cet état ne peut être détecté que lorsque la base de données est ouverte. |
| Erreurs d'écriture du fichier de données | Des erreurs d'écriture se produisent dans des fichiers de données, y compris les fichiers temporaires, les fichiers de données système et les fichiers d'annulation. |
Après un basculement automatique, le rôle de la base principale défaillante devient Base de secours désactivée et, après une brève période, la base de données de secours devient la base principale. Une fois le basculement automatique terminé, un message s'affiche dans la page de détails de la base de données de secours désactivée pour vous informer que le basculement a eu lieu.
Une fois que le service a résolu les problèmes liés à l'ancienne base de données conteneur autonome principale, vous pouvez effectuer une permutation manuelle pour rétablir le rôle initial des deux bases de données. Une fois la base de données de secours provisionnée, vous pouvez effectuer diverses tâches de gestion liées à la base de données de secours, notamment :
-
Basculer manuellement d'une base de données principale vers une base de secours.
-
Basculer manuellement d'une base de données principale vers une base de secours.
-
Rétablir une base de données principale en tant que base de secours après un basculement.
-
Mettre fin à une base de données de secours.
Dans une configuration Autonomous Data Guard avec plusieurs bases de données de secours et basculement automatique :
-
Les basculements manuels nécessitent la remise en service manuelle de la base principale d'origine, qui devient la nouvelle base de secours.
-
Lorsqu'un basculement automatique se produit, la base de données autonome avec intelligence artificielle sur une infrastructure Exadata dédiée tente de rétablir l'ancienne base principale en tant que base de secours. Toutefois, si cette tentative échoue, elle doit être remise en service manuellement.
Base de données de secours instantanée
Une base de données de secours instantanée est une base de données de secours pouvant être mise à jour en convertissant une base de données conteneur autonome de secours en base de données de secours instantanée. Voir Convertir la base de données de secours physique en base de données de secours instantanée pour obtenir des instructions étape par étape.
Une base de secours instantanée reçoit et archive, mais n'applique pas, les données de journalisation de la base principale. Toutefois, il augmente l'objectif de délai de récupération (ODR) car les modifications en temps réel de la base principale ne sont pas appliquées.
La fonction de secours instantané prend en charge divers cas d'utilisation, mais voici les principaux cas d'utilisation :
-
Connectez les instances d'application principale et de secours aux bases de données principale et de secours en mode lecture-écriture pour effectuer les configurations initiales.
-
Appliquez d'abord un correctif à la base de données de secours instantanée et testez-la avec votre instance d'application de secours pour vérifier la stabilité des correctifs. Cela nécessite la conversion de la base de secours physique en base de secours instantanée en premier, de sorte que le correctif puisse être appliqué à la base de secours instantanée.
Note : Vous ne pouvez pas convertir une base de données conteneur autonome de secours physique en base de données de secours instantanée avec basculement automatique activé.
Lors de la conversion en base de données de secours instantanée, vous pouvez activer de nouveaux services de base de données qui ne sont actifs qu'en mode instantané ou utiliser le même jeu de services utilisé avec la base de données principale. Toutefois, l'activation des services de base de données principale sur la base de secours instantanée peut entraîner la transmission des demandes de connexion à la base de données principale ou vice versa si vous utilisez des chaînes de connexion de base de données incorrectes. Par conséquent, vous devez veiller à utiliser la chaîne de connexion appropriée lors de la connexion à la base de données principale et à la base de secours instantanée.
Note : Lorsque vous créez de nouveaux services avec une base de données de secours instantanée, les portefeuilles pour toutes les bases de données conteneur autonome d'IA autonome de la base de données conteneur autonome de secours instantanée sont mis à jour. Pour accéder à la base de données, rechargez les portefeuilles des bases de données autonomes d'IA de secours et utilisez des chaînes de connexion de secours instantanées.
Vous pouvez convertir manuellement la base de données conteneur autonome de secours instantanée en base de données conteneur autonome de secours physique à partir d'Oracle Cloud Infrastructure (OCI). Voir Convertir la base de données de secours instantanée en base de données de secours physique pour des instructions détaillées. Si une base de secours instantanée n'est pas convertie manuellement en base de secours physique, elle sera automatiquement reconvertie en base de secours physique après 7 jours à compter de sa création. Dans tous les cas, la conversion de la base de secours instantanée en base de secours physique entraînera l'abandon de toutes les mises à jour locales de vos bases de secours instantanées et l'application des données de journalisation reçues des bases de données principales.
Lorsqu'une base de données conteneur autonome de secours est en mode de secours instantané, vous ne pouvez pas effectuer les opérations suivantes sur la base de données conteneur autonome principale :
-
Créer ou mettre fin à des bases de données autonomes basées sur l'IA
-
Augmenter ou réduire les bases de données autonomes sur l'IA
-
Restaurer des bases de données IA autonomes
Si la situation l'exige, vous pouvez effectuer manuellement un basculement vers une base de données de secours instantanée à partir de la base de données principale. Dans ce cas, le basculement convertit la base de secours instantanée en base de secours physique en supprimant toutes les mises à jour locales apportées à la base de secours instantanée et en appliquant les données de la base principale. Voir Passer à la base de données de secours dans une configuration Autonomous Data Guard pour obtenir des instructions étape par étape.
Une passerelle entre la base de données principale et sa base de données de secours instantanée n'est pas autorisée. Vous devez convertir manuellement votre base de données de secours instantanée en base de données de secours physique avant de tenter une permutation.
Accès aux bases de données de secours à partir des applications clients
Dans une configuration d'Autonomous Data Guard, les applications clients se connectent normalement à la base principale et effectuent des opérations sur celle-ci.
Connexion à la base de secours physique
En plus de cette connectivité normale, Autonomous Data Guard vous permet de connecter des applications clients qui effectuent des opérations en lecture seule sur la base de données de secours. Pour tirer parti de cette option, les applications clients se connectent à la base de données à l'aide des noms de service de base de données qui incluent "_RO" (en lecture seule), comme décrit dans Noms de service de base de données prédéfinis pour une base de données d'intelligence artificielle autonome.
Connexion à la base de données de secours instantanée
Autonomous Data Guard vous permet également de connecter des applications client qui effectuent des opérations de lecture-écriture à la base de données de secours instantanée. Ces opérations sont locales à la base de secours instantanée et ne modifient pas sa base principale. Pour se connecter à une base de données de secours instantanée, les applications client peuvent utiliser des noms de service de base de données qui incluent "_SS" (pour "base de secours instantanée"), comme décrit dans Noms de service de base de données prédéfinis pour les bases de données IA autonomes.
Note : Lorsque la base de données de secours est en mode de secours instantané, tous les services de base de données qui incluent les services "_RO" dans leur nom sont inactifs et ne peuvent pas être utilisés pour les connexions.
Surveillance des délais de décalage
Pendant l'exécution de vos bases de données qui utilisent Autonomous Data Guard, vous pouvez surveiller le décalage de transport et le délai d'application à partir de la page Détails de la base de données (ou de la base de données conteneur) en choisissant Groupes Autonomous Data Guard. Vous pouvez également utiliser la console OCI ou les API d'observabilité pour surveiller le décalage de transport et configurer les alarmes et les avis. Pour plus d'informations, voir Observabilité des bases de données avec les mesures de base de données d'IA autonome.
Vous devez vous attendre à observer des fluctuations mineures au fil du temps à mesure que la charge de travail de la base de données varie. Toutefois, si vous constatez que le décalage augmente régulièrement, vous pouvez prendre les mesures suivantes pour résoudre le problème :
-
Tendance à la hausse du décalage d'application. Une tendance à la hausse continue du décalage d'application indique que la base de données de secours ne dispose pas d'une capacité suffisante pour suivre le rythme des enregistrements de journalisation provenant de la base principale. Pour résoudre ce problème, augmentez les OCPU de la base de données, comme décrit sous Ajouter des ressources d'UC ou de stockage à une base de données dédiée d'IA autonome.
-
Tendance à la hausse du décalage de transport. Une tendance à la hausse continue du décalage de transport indique un problème de performance du réseau. Le personnel des opérations Oracle Cloud surveille en permanence la performance du réseau, de sorte que le problème devrait se résoudre sans que vous ayez à intervenir. Toutefois, si vous le souhaitez, vous pouvez informer le personnel des opérations de la situation en ouvrant une demande de service, comme décrit dans Créer une demande de service dans My Oracle Support.
Options de configuration d'Autonomous Data Guard
Lorsque vous configurez Autonomous Data Guard, vous spécifiez les ressources d'infrastructure Exadata et de grappe de machines virtuelles Exadata autonome dans lesquelles vous voulez créer la base de données de secours et vous spécifiez le mode de protection des données à utiliser.
Vous disposez des choix suivants lorsque vous spécifiez les ressources d'infrastructure Exadata et de grappe de machines virtuelles Exadata autonome à utiliser pour la base de secours :
-
Dans une autre région de l'infrastructure Exadata et de la grappe de machines virtuelles Exadata autonome de la base de données principale :
Cette option offre le plus haut niveau de protection contre les sinistres, y compris une perte de connectivité réseau externe ou une coupure d'alimentation dans toute une région.
Pour tirer le meilleur parti de cette protection inter-région, vous devez également configurer le niveau des applications pour prendre en charge la protection inter-région. Par conséquent, Oracle vous recommande de choisir cette option si le niveau des applications est déjà configuré de cette manière ou si vous êtes prêt à le reconfigurer pour prendre en charge la protection inter-région.
Si vous choisissez de localiser la base de données de secours dans une autre région, Oracle recommande d'utiliser le mode de protection Performance maximale.
-
Dans un domaine de disponibilité différent de l'infrastructure Exadata et de la grappe de machines virtuelles Exadata autonome de la base de données principale :
Ce choix offre un niveau élevé de protection contre les sinistres, notamment une perte catastrophique de connectivité réseau externe ou d'alimentation vers un domaine de disponibilité dans une région.
Elle offre un bon équilibre entre la protection des données et la simplicité de la configuration au niveau des applications.
Si vous choisissez de localiser la base de données de secours dans un autre domaine de disponibilité, Oracle recommande d'utiliser le mode de protection Disponibilité maximale.
-
Dans le même domaine de disponibilité que l'infrastructure Exadata et la grappe de machines virtuelles Exadata autonome de la base de données principale :
Cette option offre un niveau minimal de protection contre les sinistres, et Oracle vous recommande de ne pas la choisir.
Si les ressources d'infrastructure Exadata et de grappe de machines virtuelles Exadata autonome de la base de données principale se trouvent dans une région qui ne comporte qu'un seul domaine de disponibilité, Oracle recommande d'utiliser l'option "dans une autre région".
Si vous choisissez de localiser la base de données de secours dans le même domaine de disponibilité, Oracle recommande d'utiliser le mode de protection Disponibilité maximale.
-
Dans une location différente de l'infrastructure Exadata et de la grappe de machines virtuelles Exadata autonome de la base de données principale :
S'APPLIQUE À :
 Oracle Public Cloud seulement
Oracle Public Cloud seulementCette option vous permet d'ajouter une base de données de secours dans une location différente de la base de données principale, ce qui permet le basculement ou la permutation de votre base de données vers cette base de données de secours interlocation. Vous pouvez également créer une base de données de secours instantanée dans la location distante. Il peut être utile de disposer d'une base de données de secours interlocation pour la migration de bases de données entre plusieurs locations.
Bases de données de secours interlocation :
-
Peut être activé avec le modèle de calcul ECPU ou OCPU. La base de données de secours doit utiliser le même modèle de calcul que la base de données principale.
-
Prend en charge le basculement automatique. Toutefois, le basculement automatique ne peut pas être activé pour les bases de données d'intelligence artificielle autonomes déployées dans Exadata Cloud@Customer avec une configuration Autonomous Data Guard inter-régions.
-
Impossible d'ajouter à l'aide de la console Oracle Cloud Infrastructure. Vous ne pouvez ajouter une base de données de secours interlocation qu'à l'aide de l'interface de ligne de commande ou de l'API REST. Une fois la base de données de secours ajoutée, vous pouvez voir la base de données de secours interlocation, effectuer un basculement ou une permutation vers la base de données de secours interlocation à partir de la console Oracle Cloud Infrastructure.
-
À propos des modes de protection
Autonomous Data Guard fournit les modes de protection des données suivants :
-
Disponibilité maximale. Ce mode de protection fournit le plus haut niveau de protection des données possible sans compromettre la disponibilité d'une base de données principale.
La base de données principale ne valide pas les transactions tant qu'elle n'a pas reçu d'accusé de réception indiquant que les données ont été reçues sur la base de secours (pas qu'elles ont été écrites sur le disque). Si la base principale ne reçoit pas cet accusé de réception dans les 30 secondes, elle fonctionne comme si elle était en mode de performance maximale pour préserver la disponibilité de la base principale jusqu'à ce qu'elle reçoive à nouveau les accusés de réception en temps opportun.
Ce mode de protection garantit une perte de données nulle, sauf dans le cas de défaillances doubles, telles que la défaillance d'une base de données principale après celle de la base de secours.
-
Performance maximale. Il s'agit du mode de protection par défaut. Il offre le plus haut niveau de protection des données possible sans nuire à la performance de la base de données principale.
La base principale valide les transactions dès que toutes les données de journalisation générées par ces transactions ont été écrites dans son fichier de journalisation en ligne. Elle envoie également les données de journalisation à la base de secours, mais cette opération est effectuée de manière asynchrone par rapport à la validation des transactions. La performance de la base principale n'est donc pas affectée par les délais d'écriture des données de journalisation dans la base de secours.
Ce mode de protection offre une protection des données légèrement inférieure au mode de disponibilité maximale et a un impact minimal sur la performance de la base principale.
Vous pouvez modifier le mode de protection dans une configuration Autonomous Data Guard à partir de la console Oracle Cloud Infrastructure (OCI). Voir Mettre à jour les paramètres Autonomous Data Guard pour obtenir des instructions étape par étape.
Pour plus d'informations sur les modes de protection dans Oracle Data Guard (qui s'appuie sur la fonction Autonomous Data Guard), voir Modes de protection d'Oracle Data Guard dans Concepts et administration d'Oracle Data Guard.
Meilleures pratiques lors de la configuration d'Autonomous Data Guard
Alors qu'Autonomous AI Database vous permet de créer jusqu'à deux bases de données conteneur autonomes de secours avec Autonomous Data Guard, vous pouvez choisir d'utiliser une ou plusieurs bases de données conteneur autonomes de secours, selon vos besoins. Toutefois, pour utiliser l'option de récupération après sinistre la plus résiliente offerte par une base de données autonome d'IA, vous pouvez ajouter une base de données conteneur autonome de secours locale et une base de données conteneur autonome de secours distante ou inter-région avec disponibilité maximale en tant que mode de protection des données.
Comprenons les avantages de ce design :
-
Base de secours locale :
-
Le basculement automatique vers une base de données de secours locale dans la même région assure un isolement local important en cas de sinistre et une simplicité de basculement des applications.
-
La valeur métier d'une base de données de secours locale se traduit par un basculement sans perte de données et un temps d'arrêt des applications réduit à quelques secondes.
-
Les applications basculent automatiquement et de manière transparente vers la base de données de secours locale, en maintenant la même latence entre les serveurs d'applications et la base de données. Cela est particulièrement important pour les applications OLTP et les ensembles, car une latence plus élevée peut avoir une incidence importante sur le débit et le temps de réponse global des applications.
-
-
Base de données de secours distante :
-
Si un sinistre régional rend les systèmes de secours principal et local inaccessibles, l'application et la base de données peuvent basculer vers la base de données de secours distante.
-
Même si le temps d'arrêt de la base de données est encore très faible lorsqu'un sinistre régional se produit, le temps d'arrêt de l'application peut être plus élevé en raison d'une orchestration supplémentaire requise pour les opérations de DNS, d'application et de basculement de base de données vers la région secondaire.
-
-
Disponibilité maximale :
-
Si le basculement automatique ou le basculement à démarrage rapide (FSFO) est activé, chaque fois que la base de données conteneur autonome principale devient indisponible, Autonomous Data Guard bascule vers la base de données de secours locale sans perte de données et sans modification de la latence de la base de données dans l'application.
-
Si le basculement automatique ou le basculement à démarrage rapide (FSFO) est activé, chaque fois que l'ensemble de la région principale devient inaccessible, le système bascule vers la base de secours distante avec une perte de données potentielle.
-
Incidence d'Autonomous Data Guard sur les opérations de gestion standard
Dans certains cas, les opérations de gestion standard que vous effectuez sur les bases de données conteneur autonomes fonctionnent différemment sur les bases de données conteneur principale et de secours d'une configuration Autonomous Data Guard, par rapport aux bases de données conteneur standard. La liste suivante décrit ces différences.
-
Modifier le programme de maintenance
La planification de la maintenance d'une base de données conteneur principale et de sa base de secours sont liées : la maintenance sur la base de secours est effectuée un certain nombre de jours avant la maintenance sur la base principale. La valeur par défaut est de 7 jours. Vous pouvez choisir de 1 à 7 jours lors de la création de la base de données conteneur principale, ou ultérieurement en modifiant ses données de maintenance.
-
Modifier le type de maintenance
Le type de maintenance d'une base de données conteneur principale et de sa base de secours doivent être identiques. Vous choisissez le type de maintenance pour la base principale et la base de secours lors de la création de la base de données conteneur principale, ou ultérieurement en modifiant ses données de maintenance.
-
Désactiver les sauvegardes automatiques
Vous ne pouvez pas désactiver les sauvegardes automatiques lors du provisionnement d'une base de données conteneur autonome avec Autonomous Data Guard.
-
Gérer la maintenance programmée
Vous pouvez gérer la maintenance programmée d'une base de données conteneur principale et de sa base de secours séparément. Toutefois, comme la maintenance des deux bases est liée, vous devez effectuer une maintenance programmée sur la base de secours avant la base principale si vous choisissez de programmer la maintenance à un autre moment.
-
Déplacer vers un autre compartiment
Vous pouvez déplacer les bases de données conteneur principale et de secours vers différents compartiments séparément et indépendamment, comme s'il s'agissait de bases de données conteneur standard. Toutefois, comme pour les bases de données conteneur standard, vous devez faire preuve d'une extrême prudence lors du déplacement d'une base de données conteneur. N'oubliez pas que celle-ci doit rester accessible aux groupes appropriés d'utilisateurs Oracle Cloud.
-
Redémarrer
Vous pouvez redémarrer les bases de données conteneur principale et de secours séparément et indépendamment, comme s'il s'agissait de bases de données conteneur standard.
-
Faire pivoter la clé de chiffrement
Vous pouvez effectuer une rotation des clés de chiffrement à partir de la base de données conteneur autonome principale ou de la base de données principale.
-
Mettre fin
Vous pouvez mettre fin aux bases de données conteneur principale et de secours séparément. Toutefois, les conséquences de l'arrêt d'une base de données conteneur principale et d'une base de données conteneur de secours diffèrent :
-
L'arrêt d'une base de données conteneur principale met fin à la fois aux bases de données conteneur principale et de secours. Vous ne pouvez pas mettre fin à une base de données conteneur principale qui contient des bases de données d'intelligence artificielle autonomes.
-
L'arrêt d'une base de données conteneur de secours met fin à la base de données conteneur de secours et la supprime de la configuration Autonomous Data Guard. S'il ne reste qu'une base principale, la configuration Autonomous Data Guard est supprimée et la base principale devient une base de données conteneur autonome.
-
Guides étape par étape
Pour obtenir une assistance étape par étape sur la gestion de la configuration Autonomous Data Guard dans une base de données conteneur autonome, voir :
-
Activer Autonomous Data Guard sur une base de données conteneur autonome
-
Changer de rôle dans une configuration Autonomous Data Guard
-
Basculement vers la base de secours dans une configuration Autonomous Data Guard
-
Rétablir la base de secours désactivée dans une configuration Autonomous Data Guard
-
Convertir la base de secours physique en base de secours instantanée
-
Convertir la base de données de secours instantanée en base de secours physique
-
Ajouter une deuxième base de données conteneur autonome de secours
Vous pouvez également utiliser une API pour voir et gérer la configuration Autonomous Data Guard. Pour plus de détails, voir API pour gérer la configuration Autonomous Data Guard.