Introduction au service de flux de données pour Oracle Cloud Infrastructure
Ce tutoriel présente Oracle Cloud Infrastructure Data Flow, un service qui vous permet d'exécuter n'importe quelle application Spark Apache à n'importe quelle échelle, sans infrastructure à déployer ou à gérer.
Si vous avez déjà utilisé Spark, vous retirerez davantage de ce tutoriel, mais aucune connaissance préalable de Spark n'est requise. Toutes les applications et données Spark sont fournies pour vous. Ce tutoriel montre comment le service de flux de données rend l'exécution d'applications Spark simple, répétable et sécurisée, et en facilite le partage dans l'ensemble de l'entreprise.
- Comment utiliser Java pour l'ETC dans une application de flux de données Application
- Comment utiliser SparkSQL dans une application SQL.
- Comment créer et exécuter une application Python pour exécuter une tâche d'apprentissage automatique simple.
Vous pouvez également exécuter ce tutoriel à l'aide de spark-submit à partir de l'interface CLI ou à l'aide de spark-submit et de la trousse SDK Java.
- Il est sans serveur, ce qui signifie que vous n'avez pas besoin d'experts pour provisionner, mettre à niveau ou maintenir des grappes Spark. Cela signifie que vous vous concentrez sur votre code Spark et rien d'autre.
- Il est facile à exploiter et à ajuster. L'accès à l'interface utilisateur Spark est limité et est régi par les politiques d'autorisation IAM. Si un utilisateur se plaint qu'une tâche est trop lente, toute personne ayant accès à l'exécution peut ouvrir l'interface utilisateur Spark et découvrir la cause fondamentale. L'accès au serveur d'historique Spark est aussi simple pour les tâches déjà exécutées.
- Il est idéal pour le traitement par lots. La sortie de l'application est automatiquement saisie et mise à disposition par les API REST. Devez-vous exécuter une tâche SQL Spark de quatre heures et charger les résultats dans votre système de gestion du pipeline? Avec le service de flux de données, il suffit de deux appels d'API REST.
- Il offre un contrôle consolidé. Le service de flux de données vous offre une vue consolidée de toutes les applications Spark, de leur exécutant et de leur consommation. Aimeriez-vous savoir quelles applications écrivent la plus grande quantité de données et qui les exécute? Effectuez simplement un tri sur la colonne Écriture de données. Une tâche est en cours depuis trop longtemps? Toute personne disposant des autorisations IAM appropriées peut voir le travail et l'arrêter.

Avant de commencer
Pour exécuter ce tutoriel avec succès, vous devez avoir configuré votre location et pouvoir accéder au service de flux de données.
Avant d'exécuter Flux de données, vous devez accorder des autorisations qui permettent la saisie des journaux et la gestion des exécutions. Reportez-vous à la section Configurer l'administration dans le guide du service de flux de données et suivez les instructions fournies.
- Dans la console, sélectionnez le menu de navigation pour afficher la liste des services disponibles.
- Sélectionnez Analyse et intelligence artificielle.
- Sous Mégadonnées, sélectionnez Flux de données.
- Sélectionnez Applications.
1. Extraction, transformation et chargement avec Java
Exercice pour apprendre à créer une application Java dans le service de flux de données
Ces étapes sont exécutées à partir de l'interface utilisateur de la console. Vous pouvez effectuer cet exercice à l'aide de spark-submit à partir de la CLI ou de spark-submit avec la trousse SDK Java.
La première étape la plus courante dans les applications de traitement des données est de prendre les données d'une source quelconque et de les mettre dans un format adapté à la production de rapports et à d'autres formes d'analyse. Dans une base de données, vous chargeriez un fichier plat dans la base de données et créeriez des index. Dans Spark, votre première étape est de nettoyer et de convertir les données d'un format texte en format Parquet. Parquet est un format binaire optimisé qui prend en charge les lectures efficaces, ce qui en fait un format idéal pour la production de rapports et les analyses. Dans cet exercice, vous convertirez des données sources au format Parquet et les exploiterez au mieux. L'ensemble de données est l'ensemble de données Airbnb de Berlin, téléchargé à partir du site Web de Kaggle sous les termes de la licence Creative Commons CC0 1.0 Universal (CC0 1.0) " Public Domain Dedication ".

Les données sont fournies en format CSV et la première étape consiste à convertir ces données en format Parquet et à les stocker dans le magasin d'objets aux fins de traitement en aval. Une application Spark, appelée oow-lab-2019-java-etl-1.0-SNAPSHOT.jar, est fournie pour effectuer cette conversion. L'objectif est de créer une application de flux de données qui exécute cette application Spark et de l'exécuter avec les paramètres appropriés. Comme vous débutez, cet exercice vous guidera étape par étape et fournira les paramètres dont vous avez besoin. Plus tard, vous devrez fournir les paramètres vous-mêmes, aussi assurez-vous de bien comprendre ce que vous entrez et pourquoi.
Créez une application Java de flux de données à partir de la console, ou avec Spark-submit à partir de la ligne de commande ou à l'aide de la trousse SDK.
Créez une application Java dans le service de flux de données à partir de la console.
Créer une application de flux de données.
- Naviguez jusqu'au service de flux de données dans la console en développant le menu hamburger dans la gauche, puis en le faisant défiler jusqu'à la fin.
- Sélectionnez Flux de données , puis Applications. Sélectionnez le compartiment dans lequel vous souhaitez créer les applications de flux de données. Enfin, sélectionnez Créer une application.
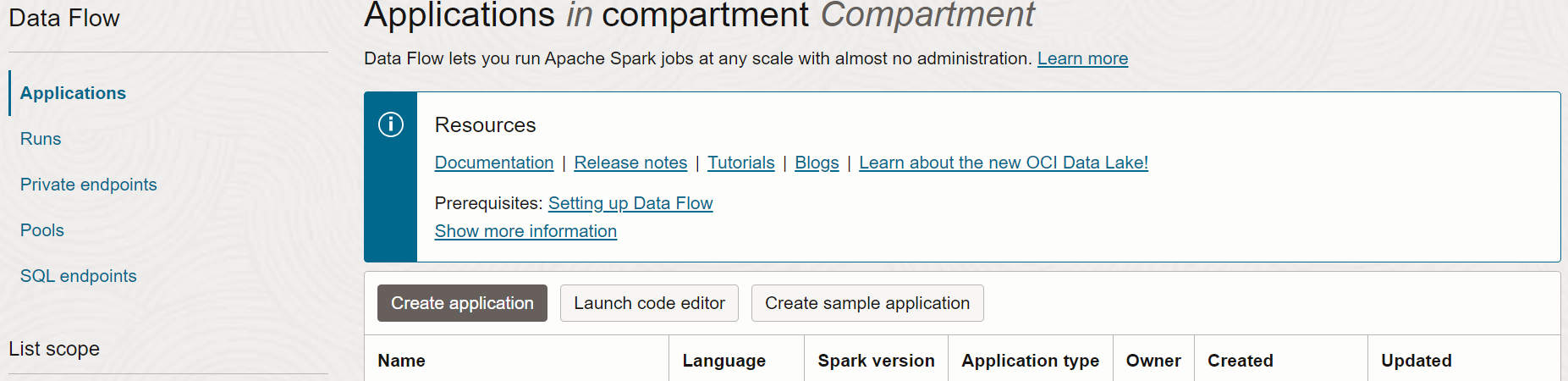
- Sélectionnez Application Java et entrez un nom pour l'application, par exemple
Tutorial Example 1.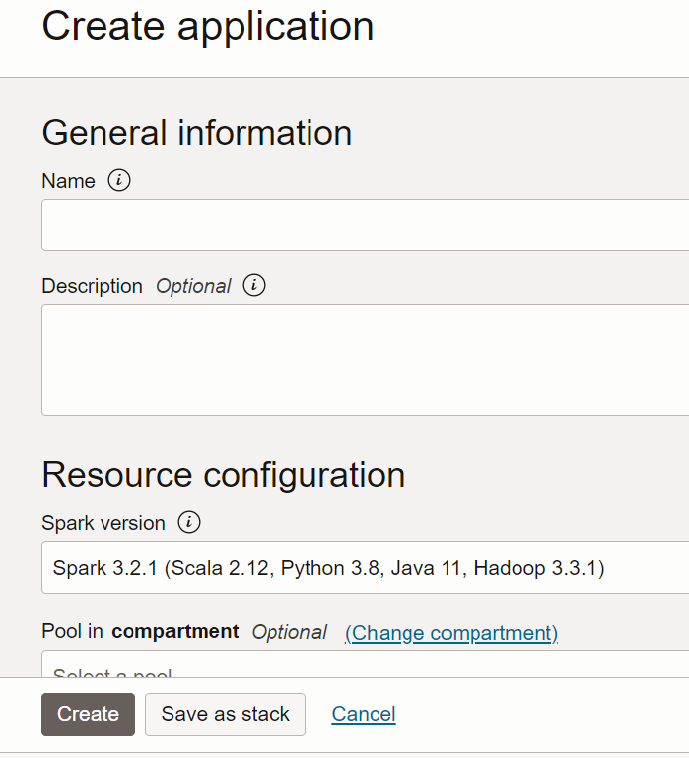
- Accédez à Configuration des ressources. Ne modifiez pas les valeurs par défaut.
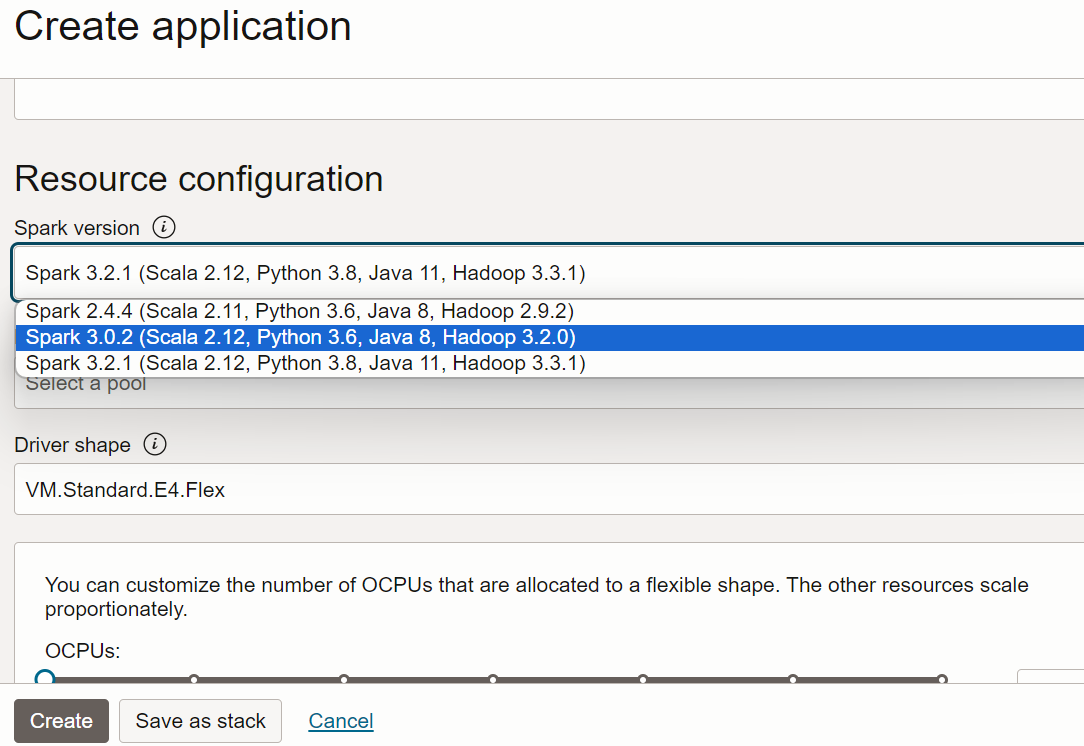
- Défilez vers le bas jusqu'à Configuration de l'application. Configurez l'application de la façon suivante :
-
URL de fichier : Emplacement du fichier JAR dans le stockage d'objets. Emplacement de cette application :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar -
Nom de la classe principale : Les applications Java nécessitent un nom de classe principale qui dépend de l'application. Pour cet exercice, entrez :
convert.Convert -
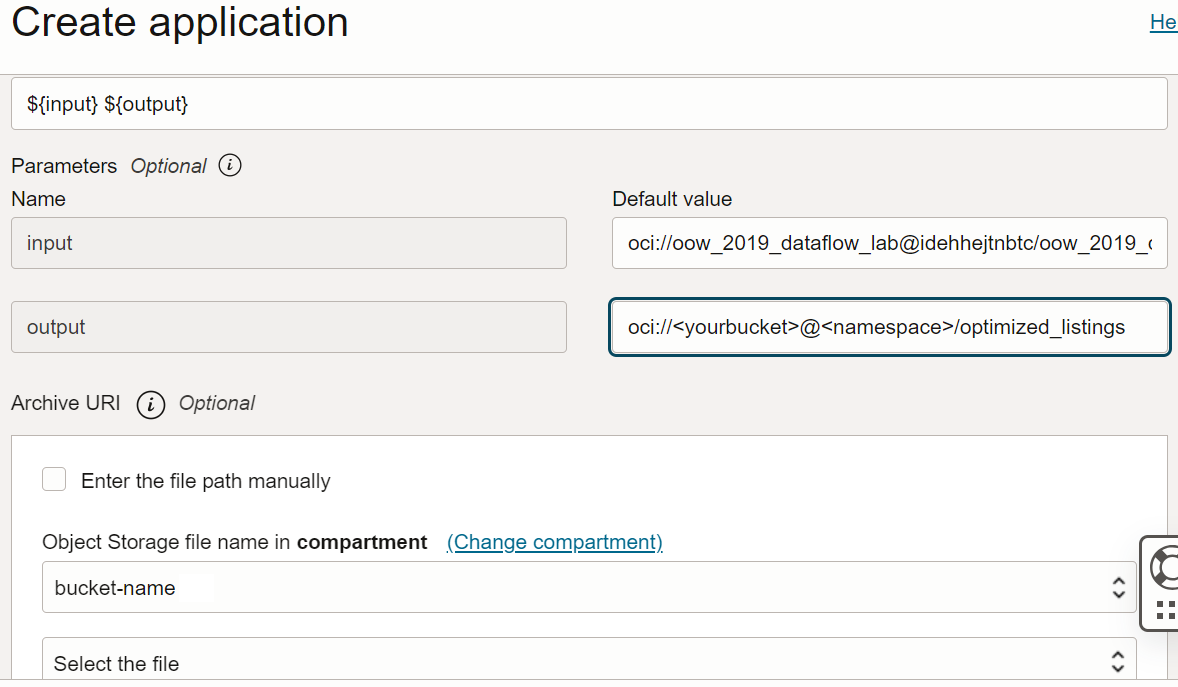
Arguments : L'application Spark attend deux paramètres de ligne de commande, un pour l'entrée et un pour la sortie. Dans le champ Arguments, entrez Vous êtes invité à entrer des valeurs par défaut et c'est une bonne idée de les entrer maintenant.
${input} ${output}
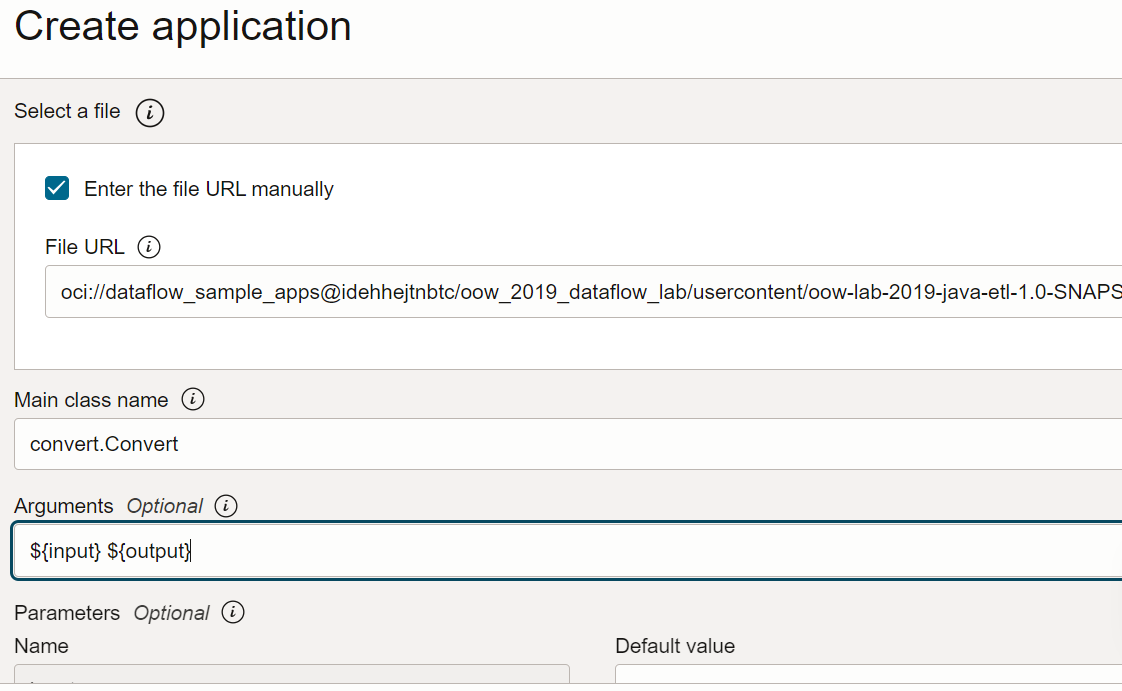
-
URL de fichier : Emplacement du fichier JAR dans le stockage d'objets. Emplacement de cette application :
- Les arguments d'entrée et de sortie sont les suivants :
-
Entrée :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv -
Sortie :
oci://<yourbucket>@<namespace>/optimized_listings
Vérifiez deux fois la configuration de l'application pour vous assurer qu'elle ressemble à ceci :
 Note
Note
Vous devez personnaliser le chemin de la sortie pour qu'il pointe vers un seau du client. -
Entrée :
- Lorsque vous avez terminé, sélectionnez Créer. Une fois créée, l'application figure dans la liste d'applications.
Félicitations! Votre première application de flux de données a été créée. Vous pouvez maintenant l'exécuter.
Utilisez spark-submit et l'interface de ligne de commande pour créer une application Java.
Effectuez l'exercice pour créer une application Java dans le service de flux de données à l'aide de spark-submit et de la trousse SDK Java.
Ces fichiers permettent d'exécuter cet exercice et sont disponibles sur les URI de stockage d'objets publics suivants :
- Fichiers d'entrée au format CSV :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - Fichier JAR :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Maintenant que vous avez créé une application Java, vous pouvez l'exécuter.
- Si vous avez suivi les étapes avec précision, il vous suffit de mettre en surbrillance votre application dans la liste, de sélectionner le menu Actions et de sélectionner Exécuter.
- Vous avez la possibilité de personnaliser des paramètres avant d'exécuter l'application. Dans votre cas, vous avez entré les valeurs précises à l'avance et vous pouvez lancer l'exécution en cliquant sur Exécuter.
-
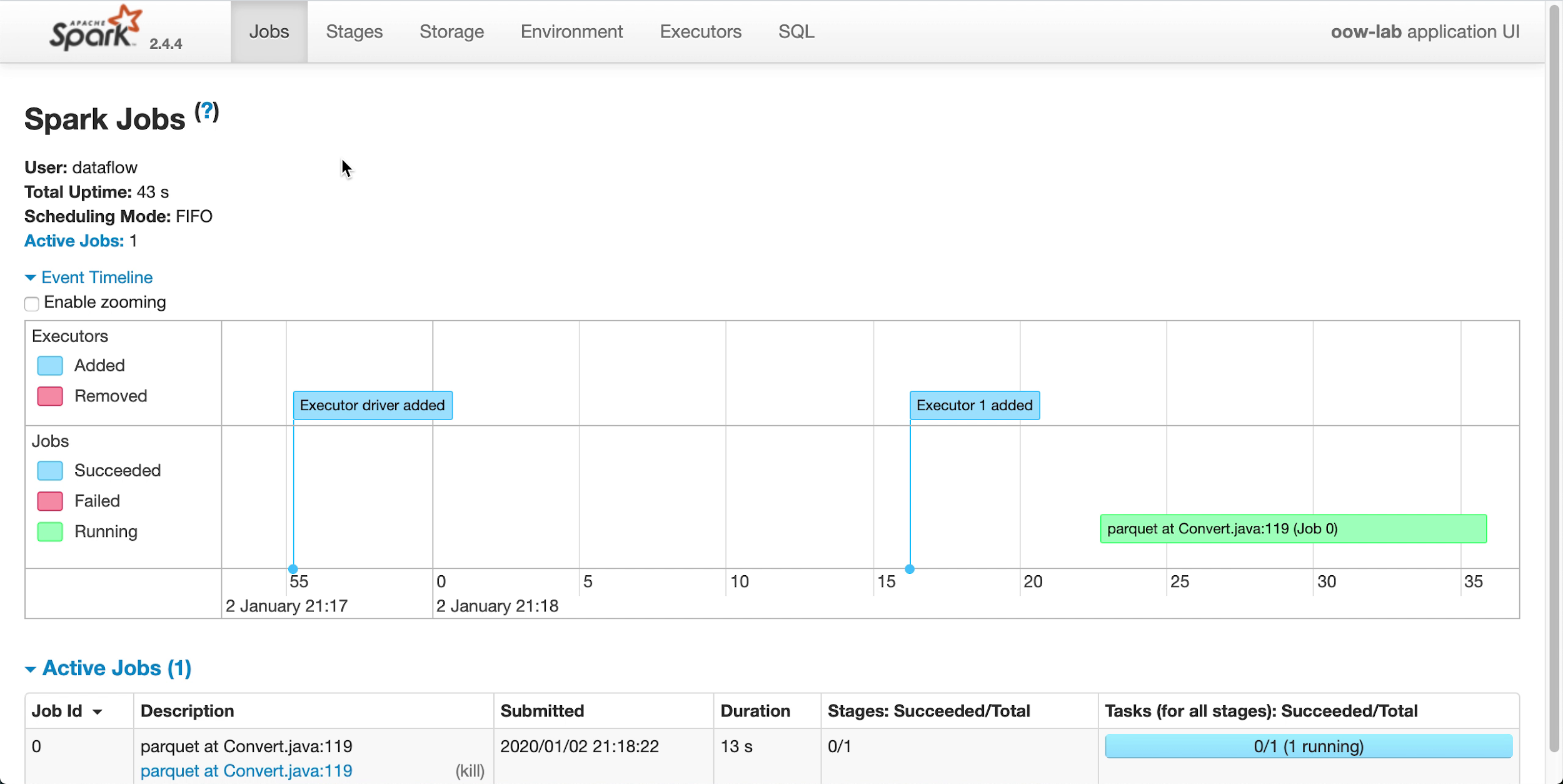
Pendant l'exécution de l'application, vous pouvez charger l'interface utilisateur Spark pour surveiller l'avancement. Dans le menu Actions pour l'exécution en question, sélectionnez Interface Spark.

- Vous êtes automatiquement redirigé vers l'interface utilisateur d'Apache Spark, qui est utile pour le débogage et le réglage de la performance.
-
Au bout d'environ une minute, votre exécution s'est terminée avec l'état
Succeeded:
-
Forez dans l'exécution pour voir des détails supplémentaires et faites défiler jusqu'en bas pour voir la liste des journaux.

-
Lorsque vous sélectionnez le fichier spark_application_stdout.log.gz, vous voyez la sortie du journal,
Conversion was successful:
- Vous pouvez également naviguer jusqu'au seau de stockage d'objets de la sortie pour confirmer que de nouveaux fichiers ont été créés.
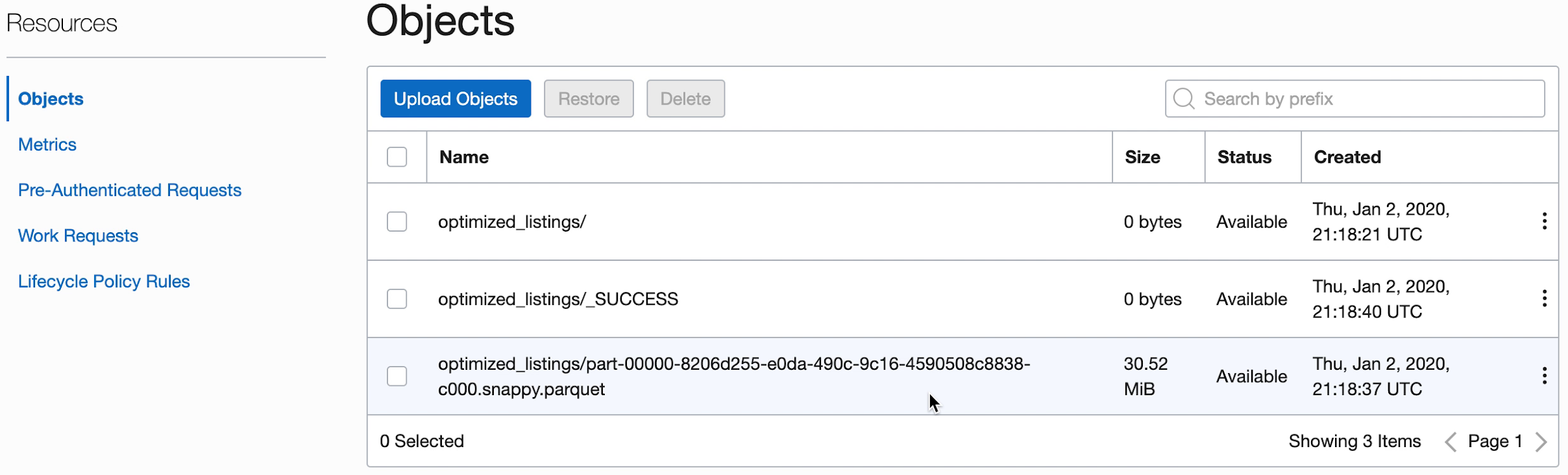
Ces nouveaux fichiers seront utilisés par les applications ultérieures. Assurez-vous qu'ils se trouvent dans votre seau avant de passer aux exercices suivants.
2. SparkSQL simplifié
Dans cet exercice, vous exécuterez un script SQL pour réaliser le profilage de base d'un jeu de données.
Cet exercice utilise la sortie générée dans 1. Extraction, transformation et chargement avec Java. Vous devez l'avoir terminé avec succès avant de pouvoir essayer celui-ci.
Ces étapes sont exécutées à partir de l'interface utilisateur de la console. Vous pouvez effectuer cet exercice à l'aide de spark-submit à partir de la CLI ou de spark-submit avec la trousse SDK Java.
Comme pour d'autres applications de flux de données, les fichiers SQL sont stockés dans le stockage d'objets et peuvent être partagés entre plusieurs utilisateurs SQL. Pour ce faire, le service de flux de données vous permet de paramétrer les scripts SQL et de les personnaliser lors de l'exécution. Comme pour d'autres applications, vous pouvez fournir des valeurs par défaut pour les paramètres, qui servent souvent d'indices utiles aux personnes exécutant ces scripts.
Le script SQL est disponible pour utilisation directement dans l'application de flux de données, il n'est pas nécessaire d'en créer une copie. Le script est reproduit ici pour illustrer certains points.
Texte de référence du script SparkSQL : 
- Le script commence par créer les tables SQL dont nous avons besoin. Actuellement, le service de flux de données ne comporte pas de catalogue SQL persistant, donc tous les scripts doivent commencer par définir les tables dont ils ont besoin.
- L'emplacement de la table est défini à
${location}. Il s'agit d'un paramètre que l'utilisateur doit fournir au moment de l'exécution. Cela donne au service de flux de données la flexibilité d'utiliser un script pour traiter de nombreux emplacements et pour partager du code entre différents utilisateurs. Pour cet exercice, vous devez personnaliser la variable${location}afin qu'elle pointe vers l'emplacement de sortie utilisé dans l'exercice 1. - Comme on le verra, la sortie du script SQL est saisie et mise à notre disposition à la suite de l'exécution.
- Dans le service Flux de données, créez une application SQL, sélectionnez le type SQL et acceptez les ressources par défaut.
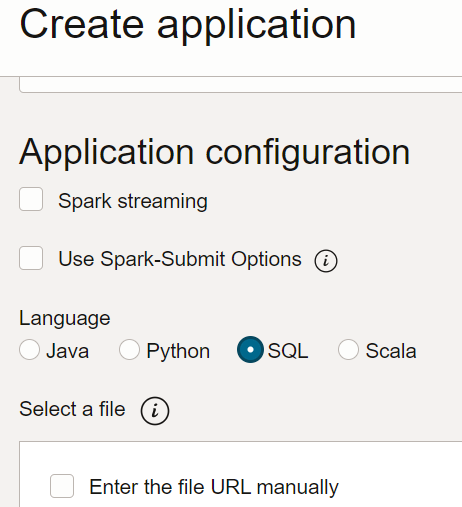
- Sous Configuration de l'application, configurez l'application SQL comme suit :
-
URL de fichier : Emplacement du fichier SQL dans le stockage d'objets. Emplacement de cette application :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql -
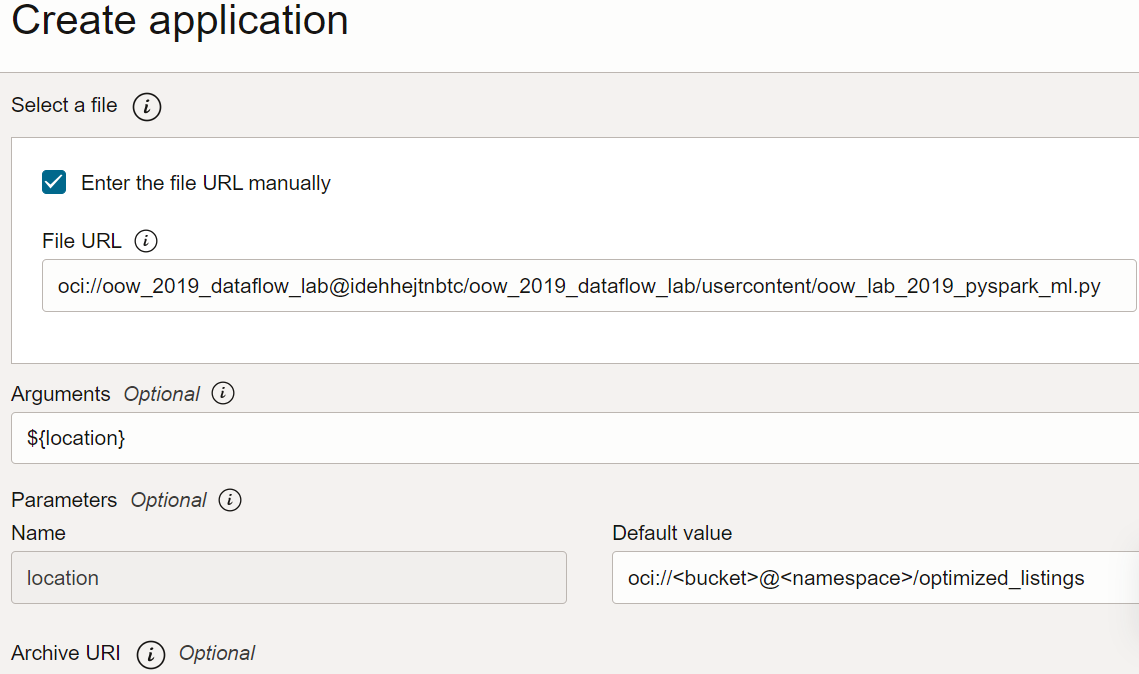
Arguments : Le script SQL attend un paramètre, soit l'emplacement de sortie de l'étape précédente. Sélectionnez Ajouter un paramètre et entrez un paramètre nommé
locationavec la valeur que vous avez utilisée comme chemin de sortie à l'étape a, en fonction du modèleoci://[bucket]@[namespace]/optimized_listings
Lorsque vous avez terminé, assurez-vous que la configuration de l'application ressemble à ceci :

-
URL de fichier : Emplacement du fichier SQL dans le stockage d'objets. Emplacement de cette application :
- Personnalisez la valeur d'emplacement en indiquant un chemin valide dans votre location.
- Enregistrer l'application et l'exécuter à partir de la liste Applications.
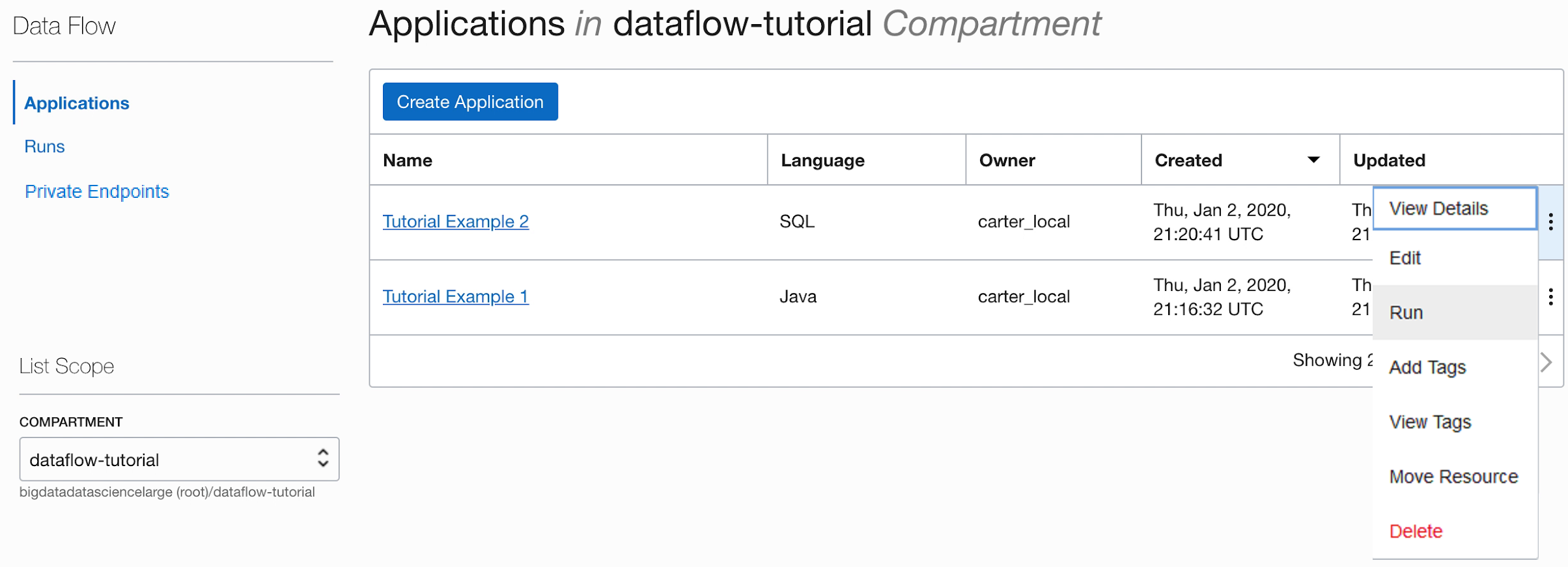
- Une fois l'exécution terminée, ouvrez-la :
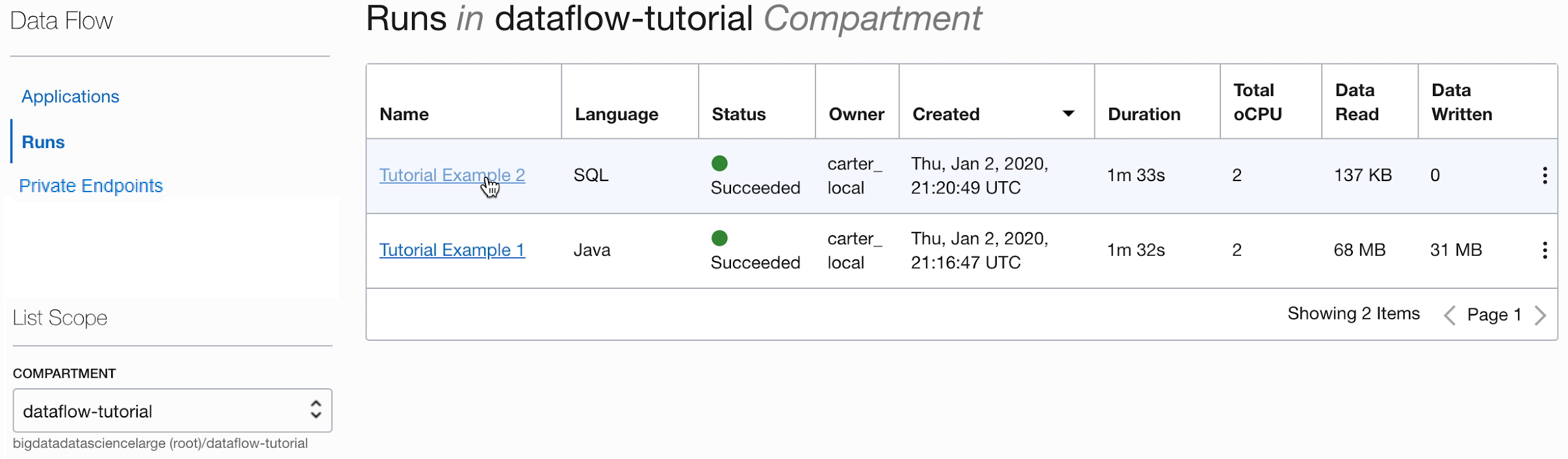
- Naviguez jusqu'aux journaux d'exécution :

- Ouvrez spark_application_stdout.log.gz et vérifiez que la sortie est conforme à la sortie suivante. Note
L'ordre de vos rangées peut être différent de celui de l'image, mais les valeurs doivent correspondre.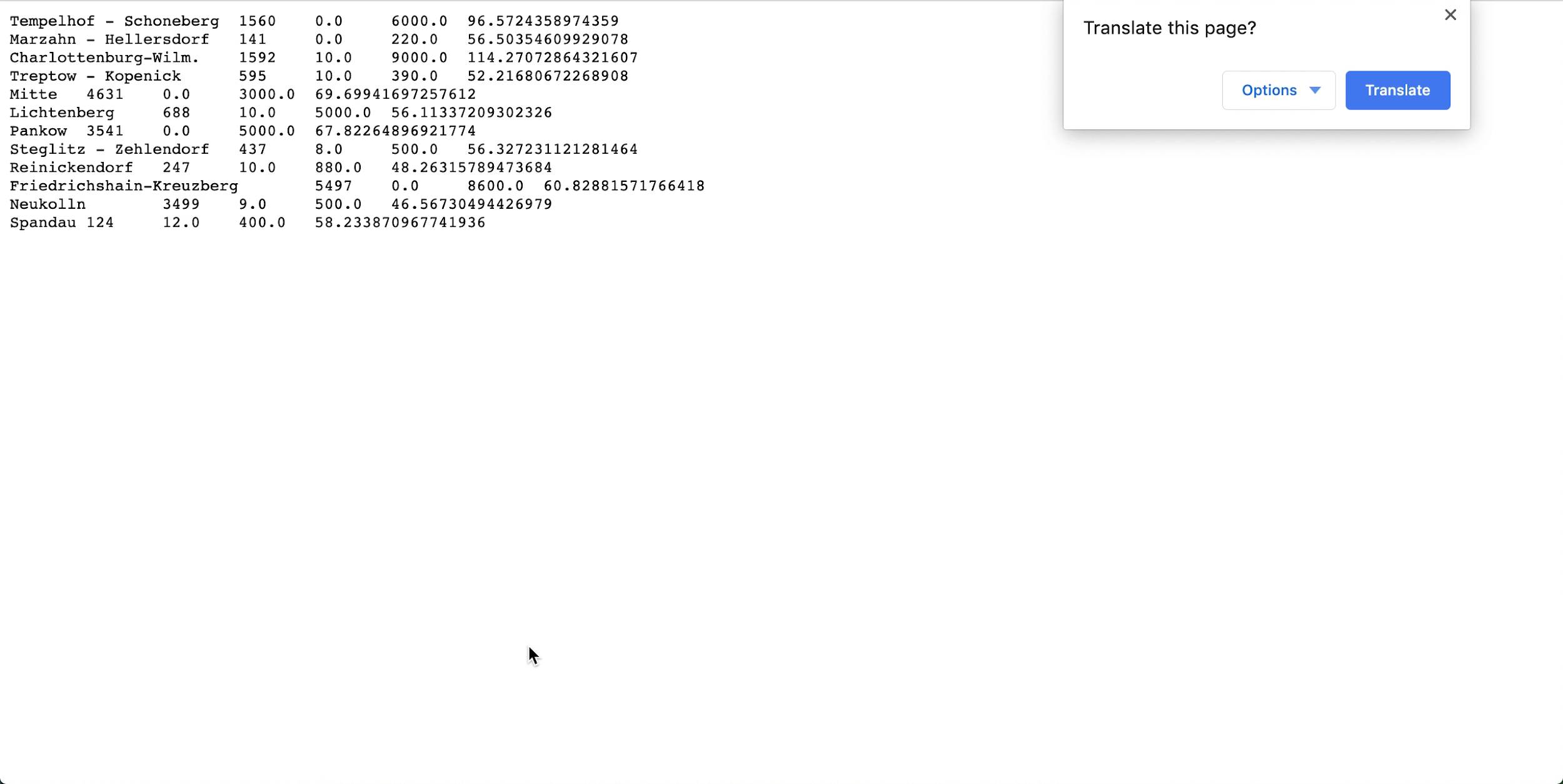
- Selon votre profilage SQL, vous concluez que dans ce jeu de données Neukolln a le prix de catalogue moyen le plus faible à 46,57 $ alors que Charlottenburg-Wilmersdorf a la moyenne la plus élevée à 114,27 $ (Note : Le jeu de données source contient des prix en USD plutôt qu'en EUR).
Cet exercice a montré certains aspects clés du service de flux de données. Lorsqu'une application SQL est en place, n'importe qui peut facilement l'exécuter sans se soucier de la capacité de la grappe, de l'accès aux données et de leur conservation, de la gestion des données d'identification ou d'autres considérations de sécurité. Par exemple, un analyste d'affaires peut facilement utiliser les rapports basés sur Spark avec le service de flux de données.
3. Apprentissage automatique avec PySpark
Utilisez PySpark pour appliquer une tâche d'apprentissage automatique simple à des données d'entrée.
Cet exercice utilise la sortie de 1. Extraction, transformation et chargement avec Java comme données d'entrée. Vous devez avoir exécuté le premier exercice avec succès avant de pouvoir essayer celui-ci. Cette fois, votre objectif est d'identifier les meilleures affaires parmi les différentes fiches descriptives de Airbnb grâce aux algorithmes d'apprentissage automatique de Spark.
Ces étapes sont exécutées à partir de l'interface utilisateur de la console. Vous pouvez effectuer cet exercice à l'aide de spark-submit à partir de la CLI ou de spark-submit avec la trousse SDK Java.
Une application PySpark est disponible pour être utilisée directement dans vos applications de flux de données. Vous n'avez pas besoin de créer une copie.
Le texte de référence du script PySpark est fourni ici pour illustrer quelques points :
- Le script Python attend un argument de ligne de commande (en rouge). Lors de la création de l'application Flux de données, vous devez créer un paramètre qui sera réglé au chemin d'entrée par l'utilisateur.
- Le script utilise une régression linéaire pour prédire un prix par fiche descriptive et recherche les meilleures offres en retirant le prix de catalogue de la prévision. La valeur la plus négative indique la meilleure valeur, selon le modèle.
- Le modèle de ce script est simplifié et tient uniquement compte de la superficie en pieds carrés. Dans une situation réelle, vous utiliseriez plus de variables, comme le voisinage et d'autres variables importantes pour la prédiction.
Créez une application PySpark à partir de la console ou avec spark-submit à partir de la ligne de commande ou à l'aide de la trousse SDK.
Créez une application PySpark dans Data Flow à l'aide de la console.
-
Créez une application et sélectionnez le type Python.
-
Vérifiez la configuration de l'application et vérifiez qu'elle est similaire à ce qui suit :
Créez une application PySpark dans le service de flux de données à l'aide de Spark-submit et de l'interface de ligne de commande.
Créez une application PySpark dans le service de flux de données à l'aide de Spark-submit et de la trousse SDK.
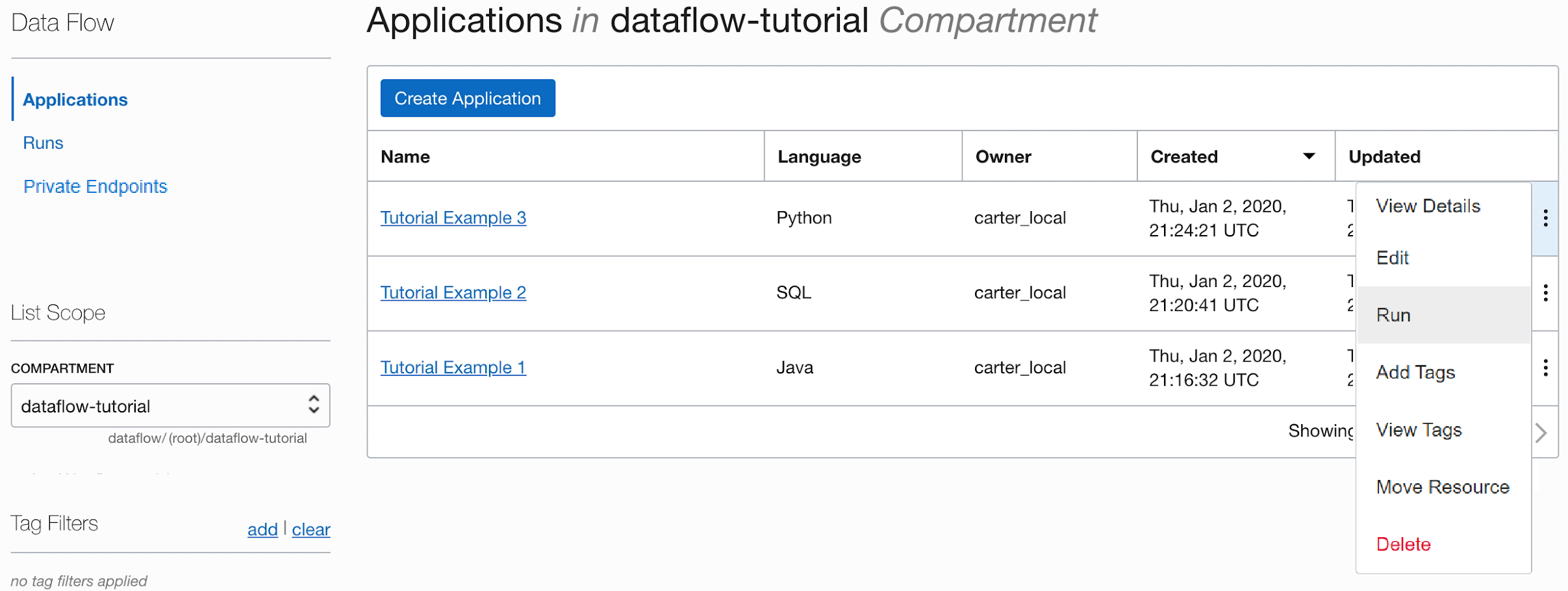
- Exécutez l'application à partir de la liste Application.
-
Une fois l'exécution terminée, ouvrez-la et naviguez jusqu'aux journaux.

- Ouvrez le fichier spark_application_stdout.log.gz. Votre sortie doit être identique à la suivante :

-
Dans cette sortie, vous voyez que l'ID fiche descriptive 690578 est la meilleure offre avec un prix prévu de 313,70 $ par rapport au prix de catalogue 35,00 $, pour une superficie de 4 639 pieds carrés. Si cela semble trop beau pour être vrai, l'ID unique vous permet de forer dans les données afin de mieux comprendre si cette offre est vraiment très avantageuse ou non. Ainsi, un analyste d'affaires pourrait facilement utiliser la sortie de cet algorithme d'apprentissage automatique pour approfondir son analyse.
Étape suivante
Vous pouvez maintenant créer et exécuter des applications Java, Python ou SQL avec le service Flux de données et explorer les résultats.
Le service de flux de données prend en charge tous les détails du déploiement, de la panne, de la gestion des journaux, de la sécurité et de l'accès à l'interface utilisateur. Avec le service de flux de données, vous pouvez vous concentrer sur le développement d'applications Spark sans vous soucier de l'infrastructure.