Introduction à Oracle Cloud Infrastructure Data Flow
Ce tutoriel présente le service Oracle Cloud Infrastructure Data Flow, qui permet d'exécuter à toute échelle une application Spark Apache sans déployer ni gérer d'infrastructure.
Si vous avez déjà utilisé Spark, ce tutoriel vous en apprendra davantage, mais aucune connaissance antérieure sur Spark n'est requise. Toutes les données et applications Spark vous ont été fournies. Ce tutoriel montre comment Data Flow rend les applications Spark faciles d'utilisation, répétables, sûres et simples à partager dans toute l'entreprise.
- Utilisation de Java pour effectuer des opérations ETL dans une application Data Flow .
- Utilisation de SparkSQL dans une application SQL.
- Création et exécution d'une application Python pour effectuer une tâche simple d'apprentissage automatique.
Vous pouvez également réaliser ce tutoriel à l'aide de spark-submit à partir de l'interface de ligne de commande ou de spark-submit et du kit SDK Java.
- Il est sans serveur, ce qui signifie que vous n'avez pas besoin d'experts pour provisionner, corriger, mettre à niveau ou gérer les clusters Spark. Vous pouvez donc vous concentrer uniquement sur votre code Spark.
- Il propose des réglages et des opérations simples. L'accès à l'interface utilisateur Spark est une sélection et est régi par les stratégies d'autorisation IAM. Si un utilisateur se plaint de la lenteur d'un travail, toute personne ayant accès à l'exécution peut ouvrir l'interface utilisateur Spark et accéder à la cause première. L'accès au serveur d'historique Spark est aussi simple pour les travaux déjà réalisés.
- Il est parfaitement adapté au traitement en batch. La sortie de l'application est automatiquement capturée et rendue disponible par les API REST. Vous avez besoin d'exécuter un travail Spark SQL de quatre heures et de charger les résultats dans votre système de gestion de pipeline ? Dans Data Flow, il vous suffit de deux appels d'API REST.
- Il comporte un contrôle consolidé. Data Flow permet d'obtenir une vue consolidée de toutes les applications Spark, des utilisateurs qui les exécute et de leur consommation. Vous voulez savoir quelles applications écrivent la plupart des données et quels utilisateurs les exécutent ? Il vous suffit de trier les données en fonction de la colonne Données écrites. Un travail est-il en cours d'exécution depuis trop longtemps ? Toute personne disposant des droits d'accès IAM corrects peut visualiser le travail et l'arrêter.
Avant de commencer
Pour exécuter ce tutoriel, vous devez avoir configuré votre location et pouvoir accéder à Data Flow.
Pour pouvoir exécuter Data Flow, vous devez accorder des droits d'accès permettant la capture des journaux et la gestion des exécutions. Reportez-vous à la section Configuration de l'administration dans le guide du service Data Flow et suivez les instructions fournies.
- Dans la console, sélectionnez le menu de navigation pour afficher la liste des services disponibles.
- Sélectionnez Analytics et IA.
- Dans Big Data, sélectionnez Data Flow.
- Sélectionnez Applications.
1. ETL avec Java
Exercice pour apprendre à créer une application Java dans Data Flow
Les étapes décrites dans la section concernent l'utilisation de l'interface utilisateur de la Console. Vous pouvez effectuer cet exercice à l'aide de spark-submit à partir de l'interface de ligne de commande ou de spark-submit avec le kit SDK Java.
La première étape la plus courante dans les applications de traitement des données consiste à prendre des données à partir d'une source et à les convertir dans un format adapté à la génération de rapports et à d'autres formes d'analyse. Dans une base de données, vous chargez un fichier plat dans la base de données et créez des index. Dans Spark, la première étape consiste à nettoyer et à convertir les données d'un format texte au format Parquet. Parquet est un format binaire optimisé prenant en charge les lectures efficaces, ce qui le rend idéal pour la génération de rapports et les analyses. Dans cet exercice, vous prenez les données source, les convertissez au format Parquet, puis les utilisez pour différentes tâches intéressantes. L'ensemble de données est l'ensemble de données Berlin Airbnb Data, téléchargé sur le site Web Kaggle sous les conditions de la licence Creative Commons CC0 1.0 Universal (CC0 1.0) "Public Domain Dedication".

Les données sont fournies au format CSV. La première étape est de les convertir au format Parquet et de les stocker dans la banque d'objets à des fins de traitement en aval. Une application Spark, appelée oow-lab-2019-java-etl-1.0-SNAPSHOT.jar, est fournie pour cette conversion. L'objectif est de créer une application Data Flow qui exécute cette application Spark avec les paramètres appropriés. Etant donné que vous débutez, cet exercice vous guide étape par étape et fournit les paramètres nécessaires. Vous devrez ensuite fournir les paramètres vous-même, pour garantir que vous comprenez bien ce que vous saisissez et pourquoi.
Créez une application Java Data Flow à partir de la console, ou avec Spark-submit à partir de la ligne de commande ou à l'aide du kit SDK.
A partir de la console, créez une application Java dans Data Flow.
Création d'une application Data Flow.
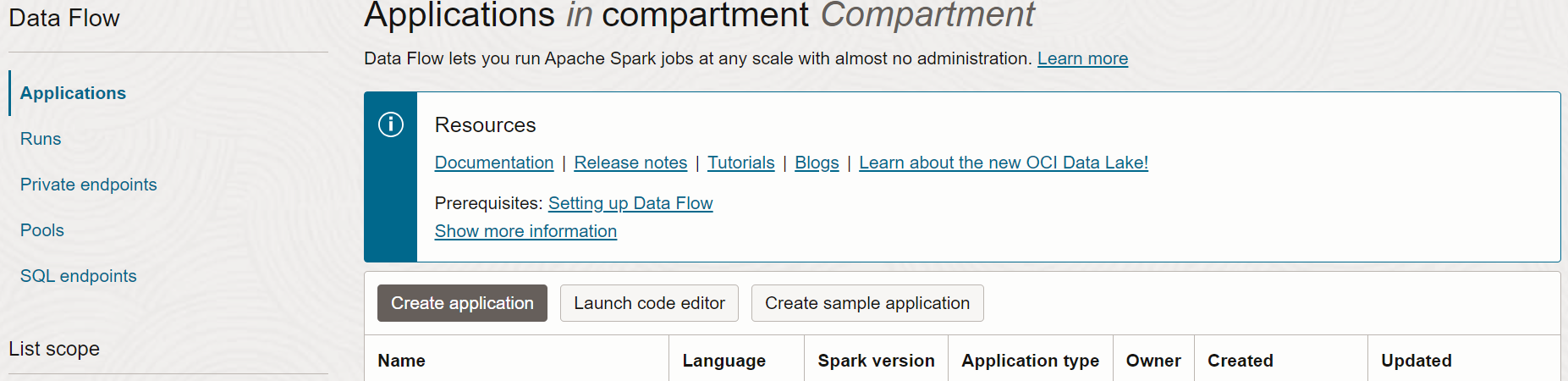
- Accédez au service Data Flow dans la console en développant le menu en haut à gauche et en le déplaçant jusqu'en bas.
- Mettez en surbrillance Flux de données , puis sélectionnez Applications. Sélectionnez le compartiment dans lequel créer les applications Data Flow. Enfin, sélectionnez Créer une application.
- Sélectionnez Application Java et entrez le nom de l'application. Par exemple,
Tutorial Example 1.
- Faites défiler vers le bas jusqu'à Configuration de ressource. Conservez toutes les valeurs par défaut.
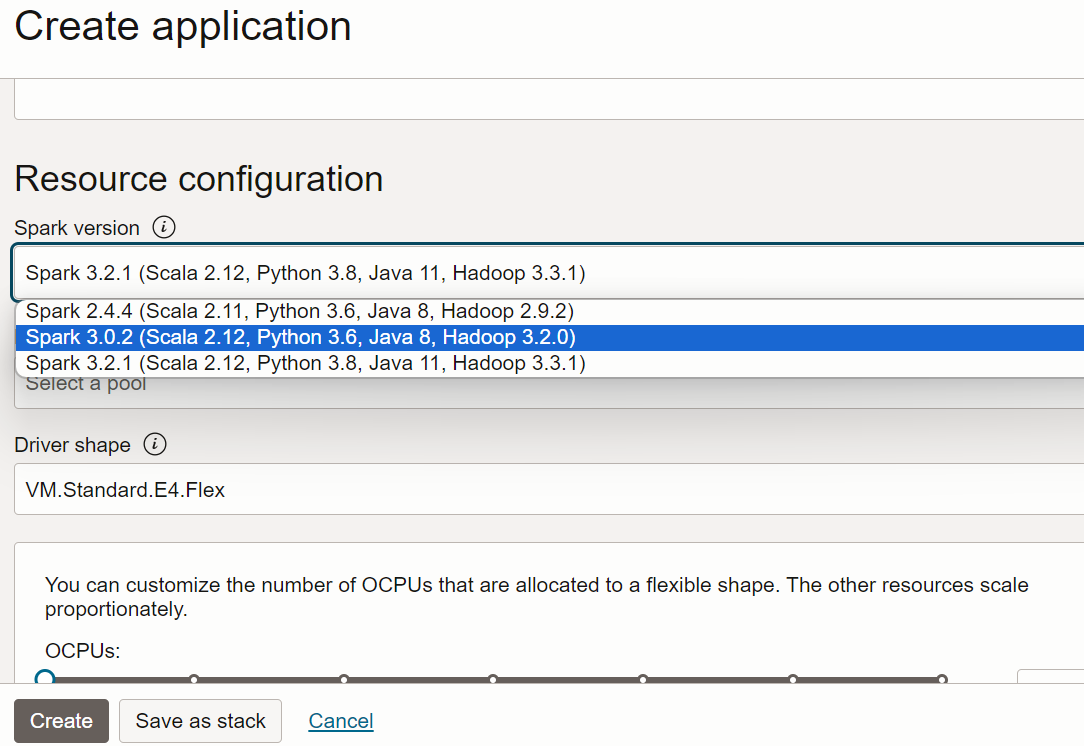
- Faites défiler la page jusqu'à Configuration de l'application. Configurez l'application comme suit :
-
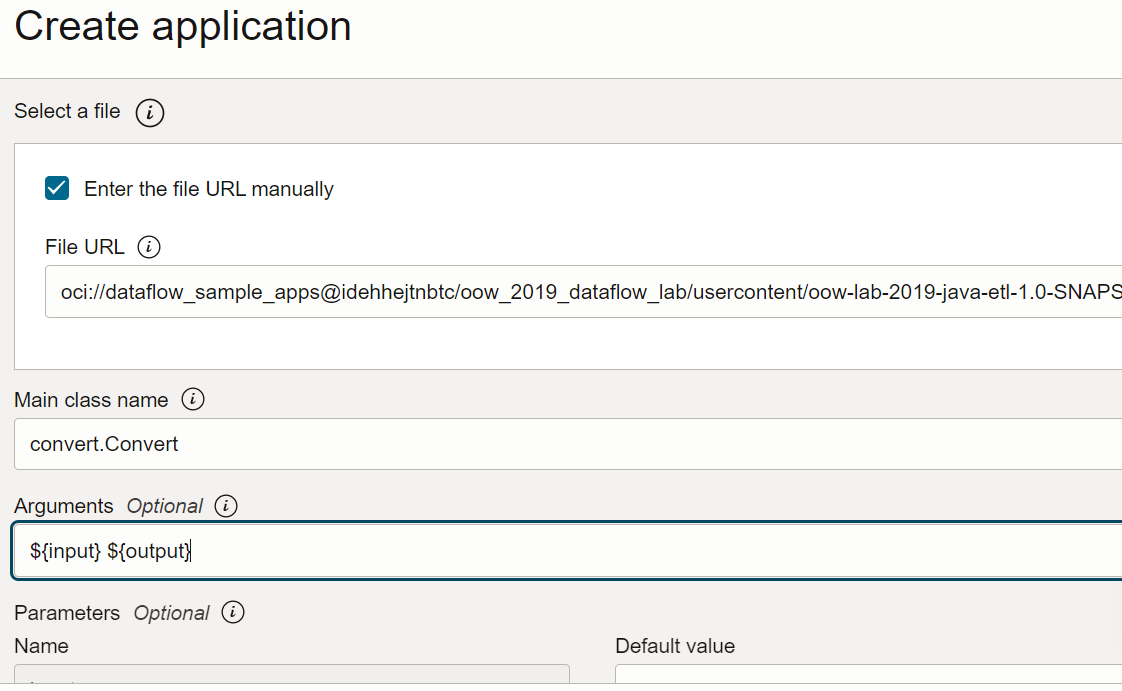
URL du fichier : emplacement du fichier JAR dans le stockage d'objet. L'emplacement de cette application est le suivant :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar -
Nom de classe principale : les applications Java ont besoin d'un nom de classe principale qui dépend de l'application. Pour cet exercice, entrez la valeur suivante :
convert.Convert -
Arguments : l'application Spark attend deux paramètres de ligne de commande, un pour l'entrée et un pour la sortie. Dans le champ Arguments, entrez ce qui suit : Vous êtes invité à saisir des valeurs par défaut. Nous vous recommandons de les saisir maintenant.
${input} ${output}
-
URL du fichier : emplacement du fichier JAR dans le stockage d'objet. L'emplacement de cette application est le suivant :
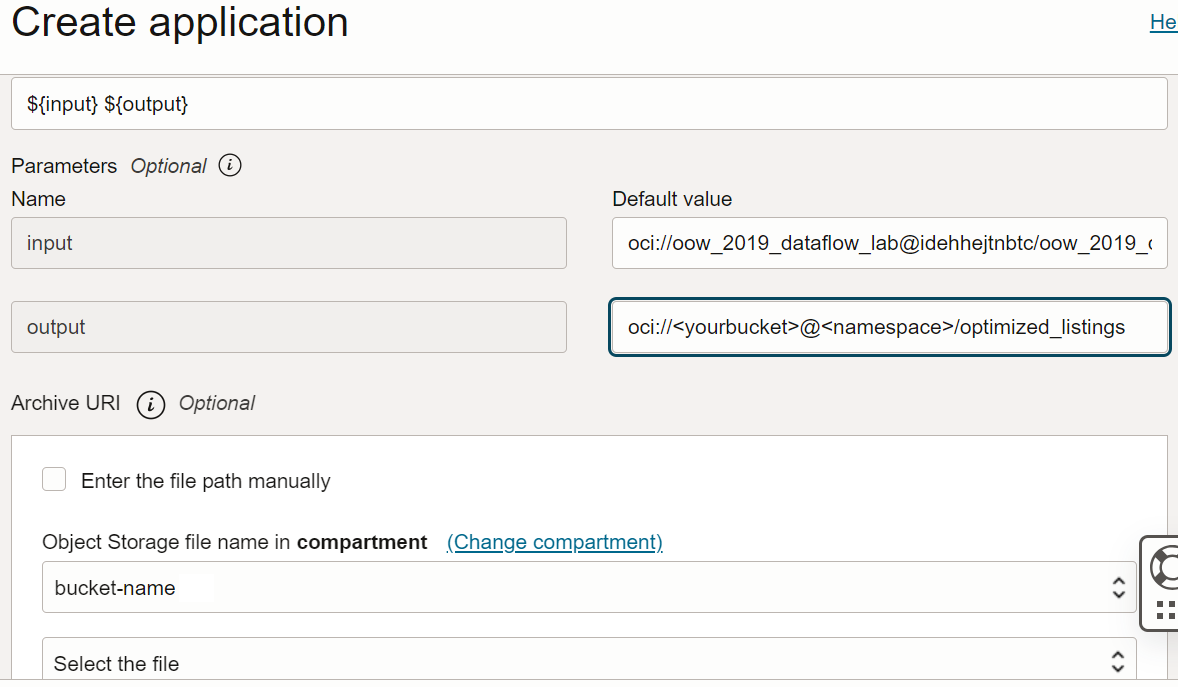
- Les arguments d'entrée et de sortie sont les suivants :
-
Entrée :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv -
Sortie :
oci://<yourbucket>@<namespace>/optimized_listings
Vérifiez de nouveau la configuration d'application pour vous assurer qu'elle se présente comme suit :
 Remarque
Remarque
Vous devez personnaliser le chemin de sortie pour qu'il pointe vers un bucket dans le locataire. -
Entrée :
- Lorsque vous avez terminé, sélectionnez Créer. Lorsque l'application est créée, elle apparaît dans la liste Application.
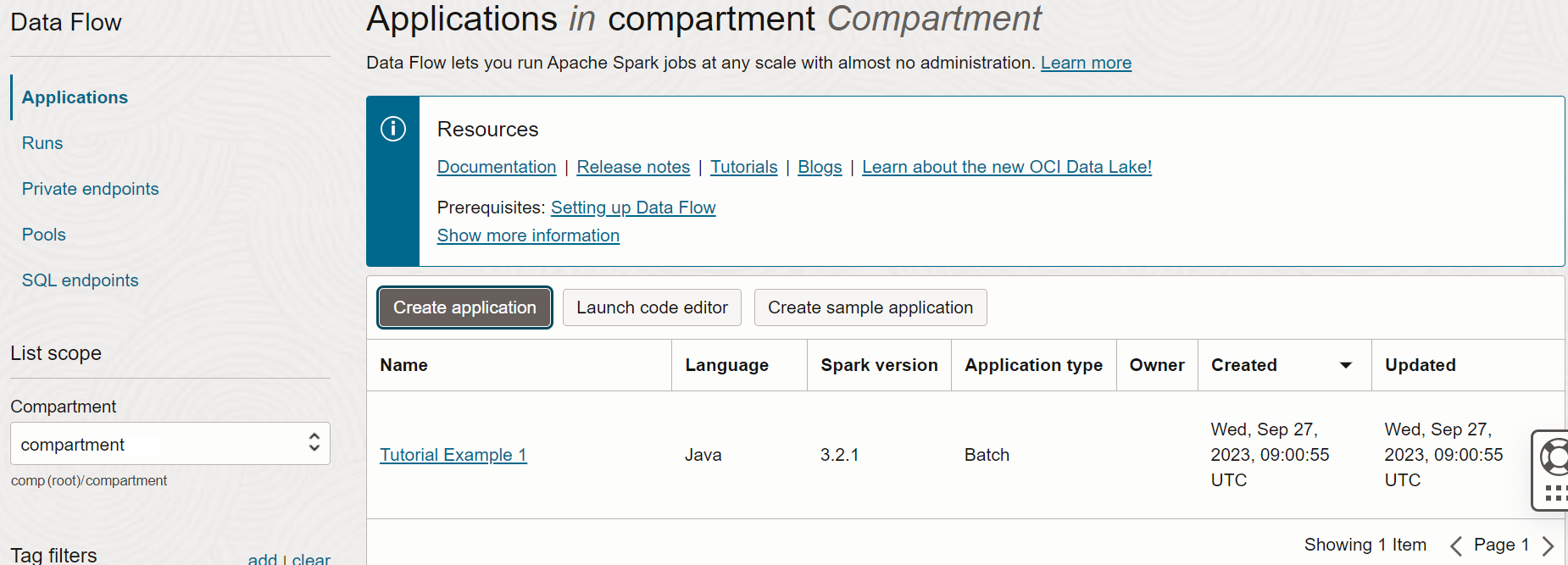
Félicitations ! Vous avez créé votre première application Data Flow. Maintenant, vous pouvez l'exécuter.
Utilisez spark-submit et l'interface de ligne de commande pour créer une application Java.
Effectuez cet exercice pour créer une application Java dans Data Flow à l'aide de spark-submit et du kit SDK Java.
Voici les fichiers pour exécuter cet exercice. Ils sont disponibles sur les URI Object Storage publics suivants :
- Fichiers d'entrée au format CSV :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - Fichier JAR:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Une fois l'application Java créée, exécutez-la.
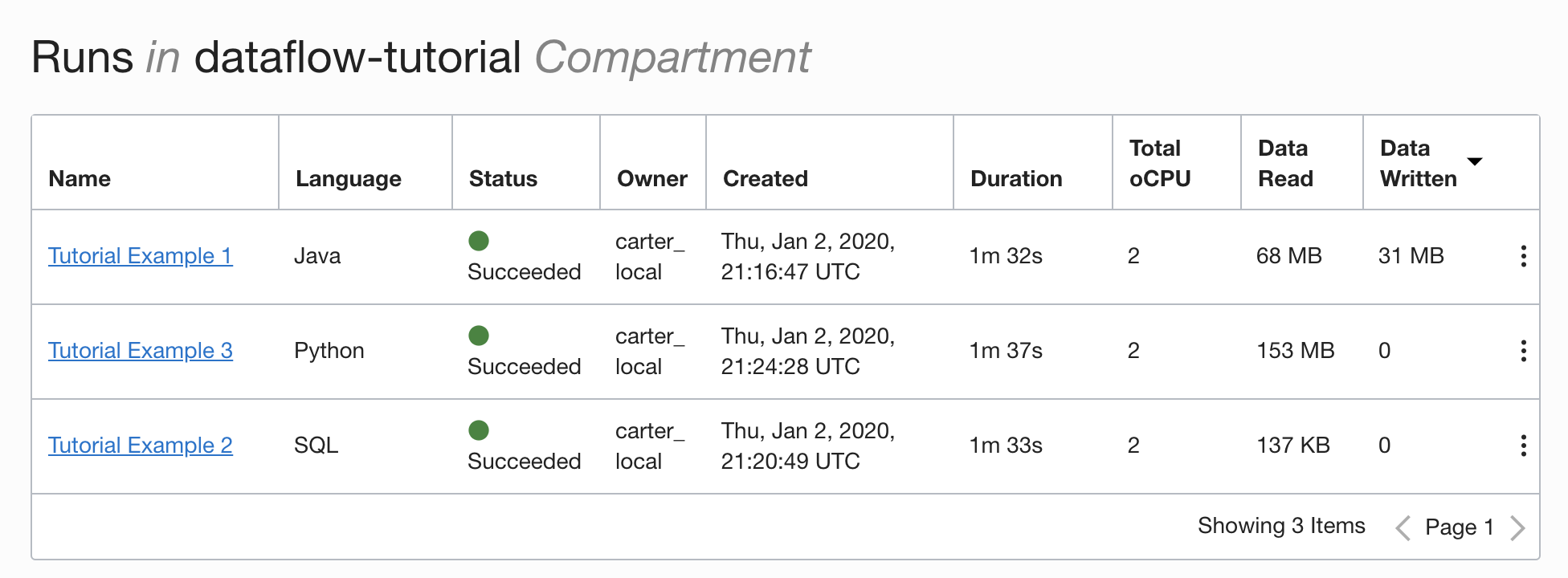
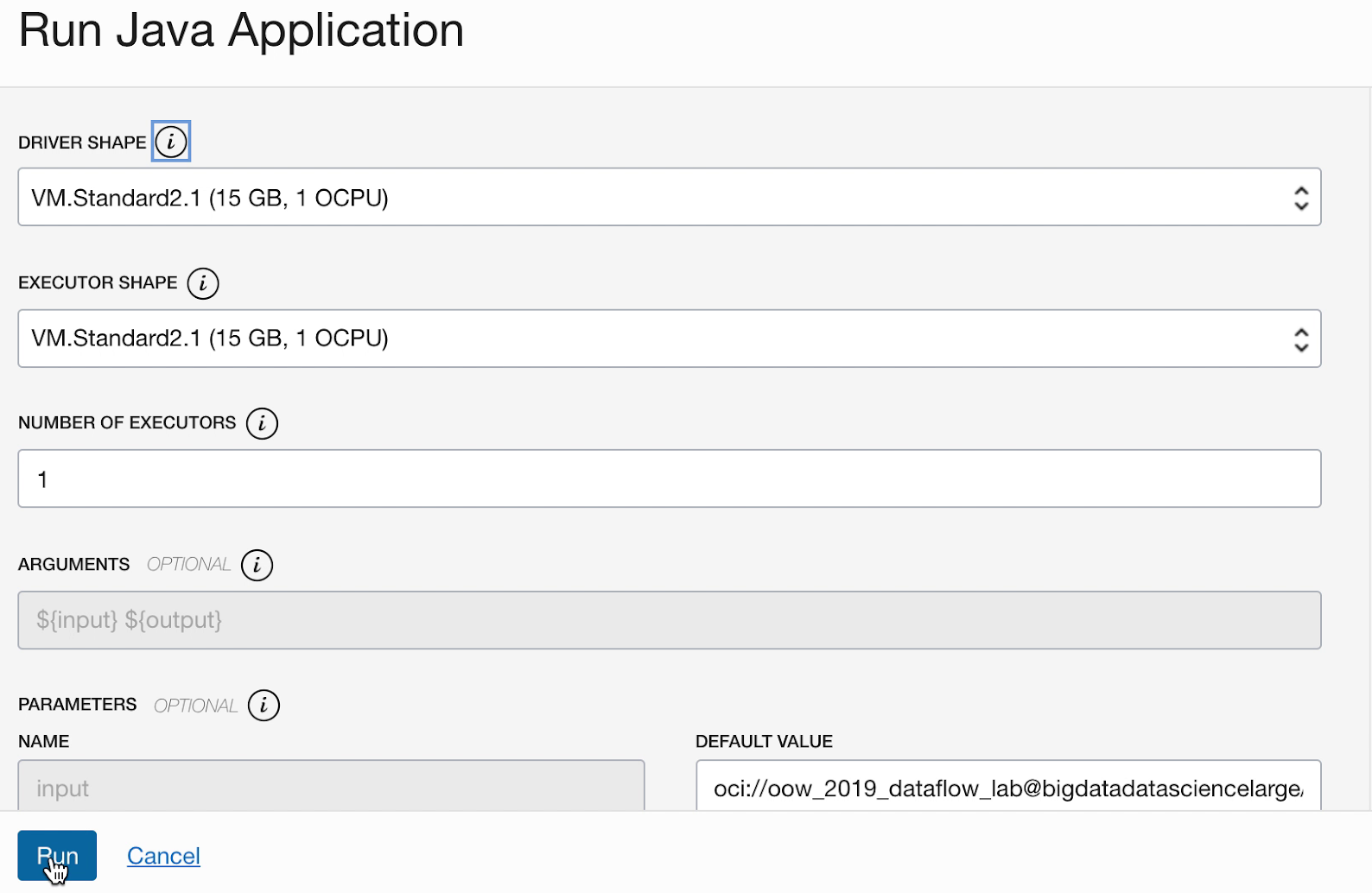
- Si vous avez suivi les étapes avec précision, il vous suffit de mettre en surbrillance votre application dans la liste, de sélectionner le menu Actions et de sélectionner Exécuter.
- Vous pouvez personnaliser les paramètres avant d'exécuter l'application. Dans votre cas, vous avez saisi les valeurs précises à l'avance. Vous pouvez donc commencer l'exécution en cliquant sur Run.
-
Pendant l'exécution de l'application, vous pouvez éventuellement charger l'interface utilisateur Spark afin de surveiller la progression. Dans le menu Actions de l'exécution en question, sélectionnez Interface utilisateur Spark.
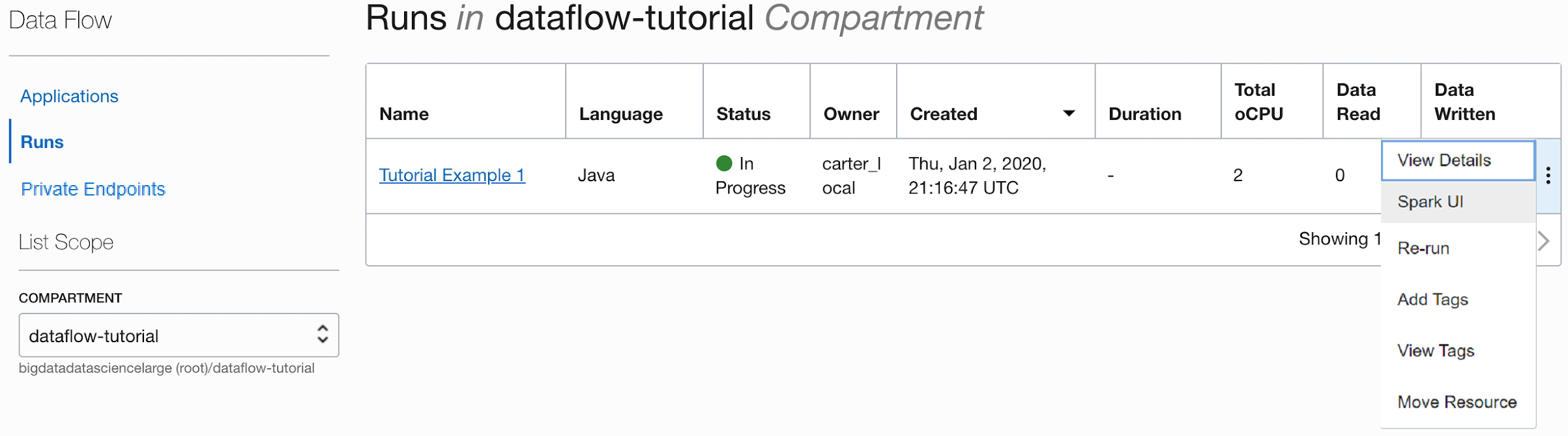
- Vous êtes automatiquement redirigé vers l'interface utilisateur Apache Spark, qui est utile pour le débogage et le réglage des performances.
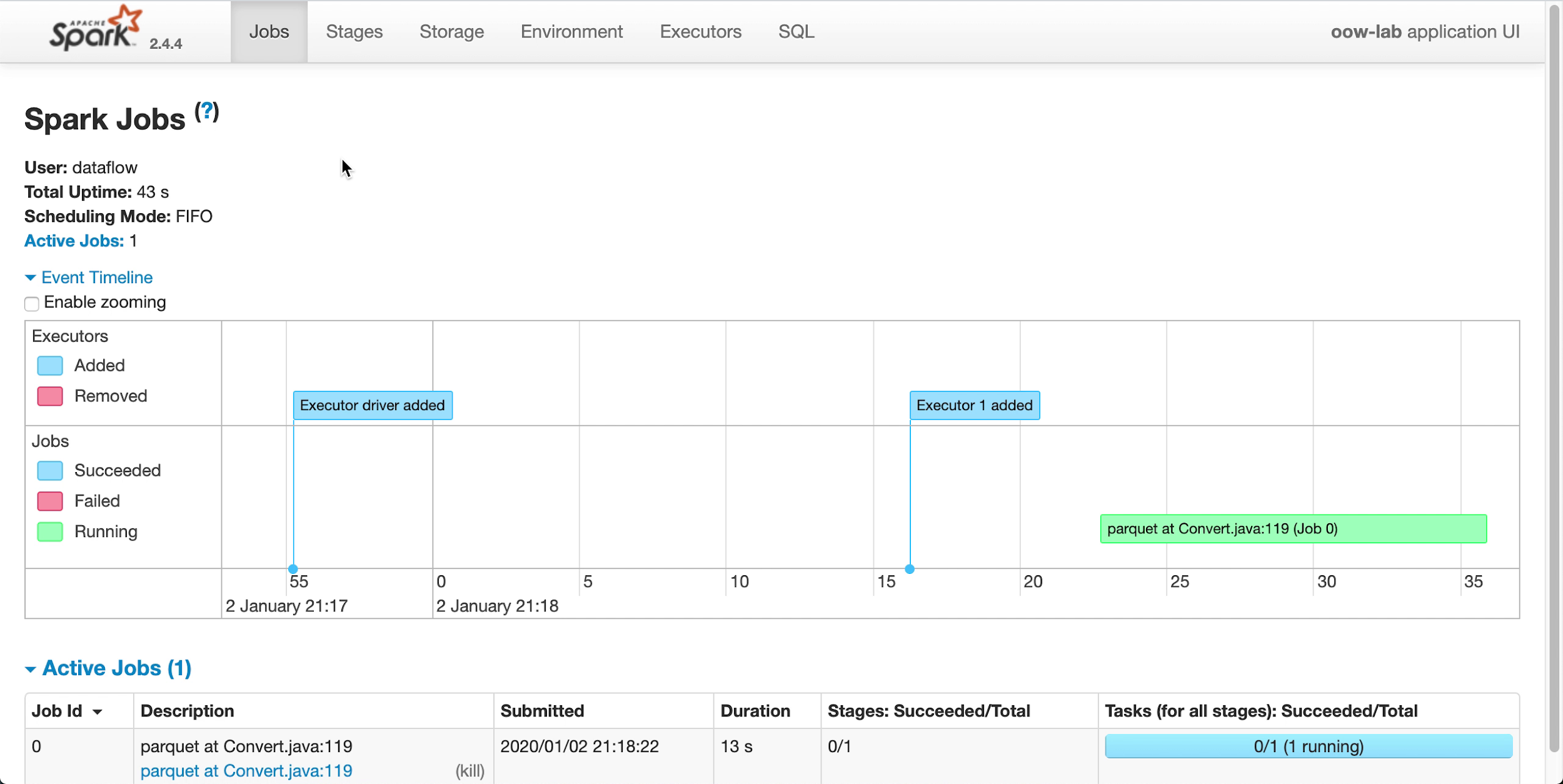
-
Après environ une minute, votre exécution se termine avec l'état
Succeeded:
-
Explorez l'exécution pour voir des détails supplémentaires et faites défiler vers le bas pour consulter la liste des journaux.

-
Lorsque vous sélectionnez le fichier spark_application_stdout.log.gz, la sortie de journal
Conversion was successfulapparaît :
- Vous pouvez également accéder au bucket de stockage d'objet de la sortie pour vérifier que des fichiers ont été créés.
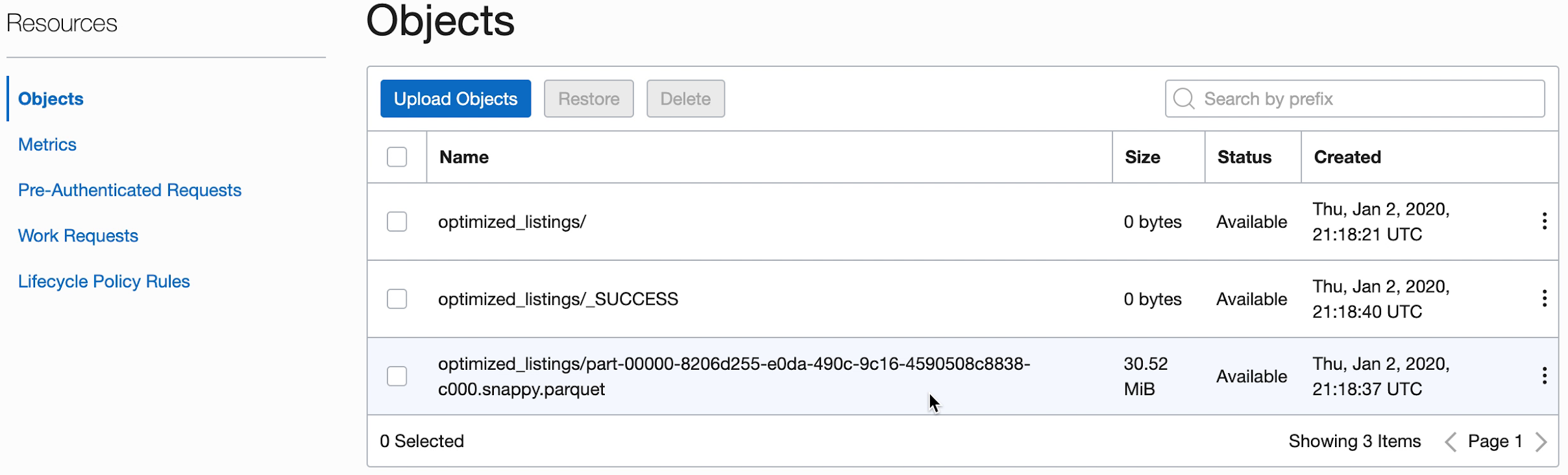
Ces nouveaux fichiers sont utilisés par les applications ultérieures. Assurez-vous qu'ils apparaissent dans votre bucket avant de passer aux exercices suivants.
2. SparkSQL simplifié
Dans cet exercice, vous exécutez un script SQL pour effectuer le profilage de base d'ensemble de données.
Cet exercice utilise la sortie que vous avez générée dans l'exercice 1. ETL avec Java. Vous devez l'avoir terminé avec succès avant de pouvoir essayer celui-ci.
Les étapes décrites dans la section concernent l'utilisation de l'interface utilisateur de la Console. Vous pouvez effectuer cet exercice à l'aide de spark-submit à partir de l'interface de ligne de commande ou de spark-submit avec le kit SDK Java.
Comme pour d'autres applications Data Flow, les fichiers SQL sont stockés dans le stockage d'objet et peuvent être partagés entre plusieurs utilisateurs SQL. Pour cela, Data Flow vous permet de paramétrer des scripts SQL et de les personnaliser lors de l'exécution. Comme pour les autres applications, vous pouvez fournir des valeurs par défaut pour les paramètres qui servent souvent d'indications précieuses aux utilisateurs exécutant ces scripts.
Le script SQL est disponible et peut être utilisé directement dans l'application Data Flow. Il n'est pas nécessaire de créer une copie. Le script est reproduit ici pour illustrer quelques points.
Texte de référence du script SparkSQL : 
- Le script commence par créer les tables SQL dont nous avons besoin. Actuellement, Data Flow ne comporte pas de catalogue SQL persistant. Tous les scripts doivent donc commencer par définir les tables nécessaires.
- L'emplacement de la table est défini sur
${location}. Il s'agit d'un paramètre que l'utilisateur doit fournir au moment de l'exécution. Cela permet à Data Flow d'utiliser un seul script pour traiter de nombreux emplacements et partager du code entre différents utilisateurs. Pour cet exercice, nous devons personnaliser${location}afin qu'il pointe vers l'emplacement de sortie utilisé dans l'exercice 1. - Comme nous le verrons, la sortie du script SQL est capturée et nous est rendue disponible dans le cadre de l'exécution.
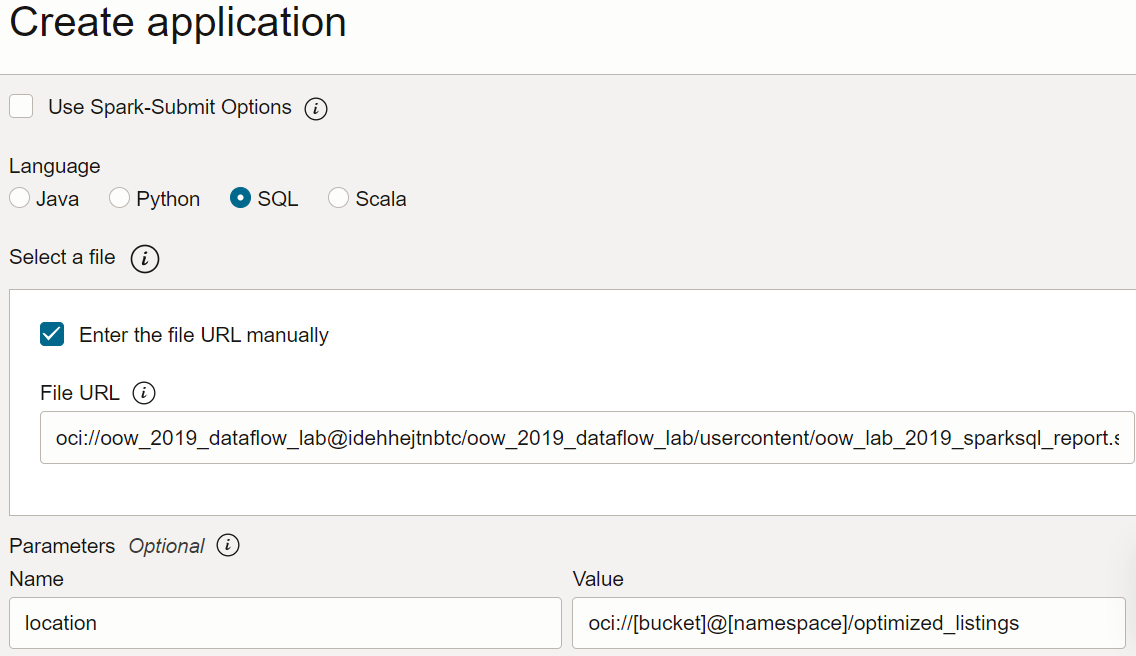
- Dans Data Flow, créez une application SQL, sélectionnez SQL comme type et acceptez les ressources par défaut.
- Sous Configuration de l'application, configurez l'application SQL comme suit :
-
URL du fichier : emplacement du fichier SQL dans le stockage d'objet. L'emplacement de cette application est le suivant :
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql -
Arguments : le script SQL attend un paramètre, l'emplacement de sortie de l'étape précédente. Sélectionnez Ajouter un paramètre et saisissez un paramètre nommé
locationavec la valeur que vous avez utilisée comme chemin de sortie à l'étape a, en fonction du modèle.oci://[bucket]@[namespace]/optimized_listings
Une fois que vous avez terminé, vérifiez que la configuration de l'application est semblable à la suivante :
-
URL du fichier : emplacement du fichier SQL dans le stockage d'objet. L'emplacement de cette application est le suivant :
- Personnalisez la valeur d'emplacement avec un chemin valide dans votre location.
- Enregistrez l'application et exécutez-la dans la liste Applications.
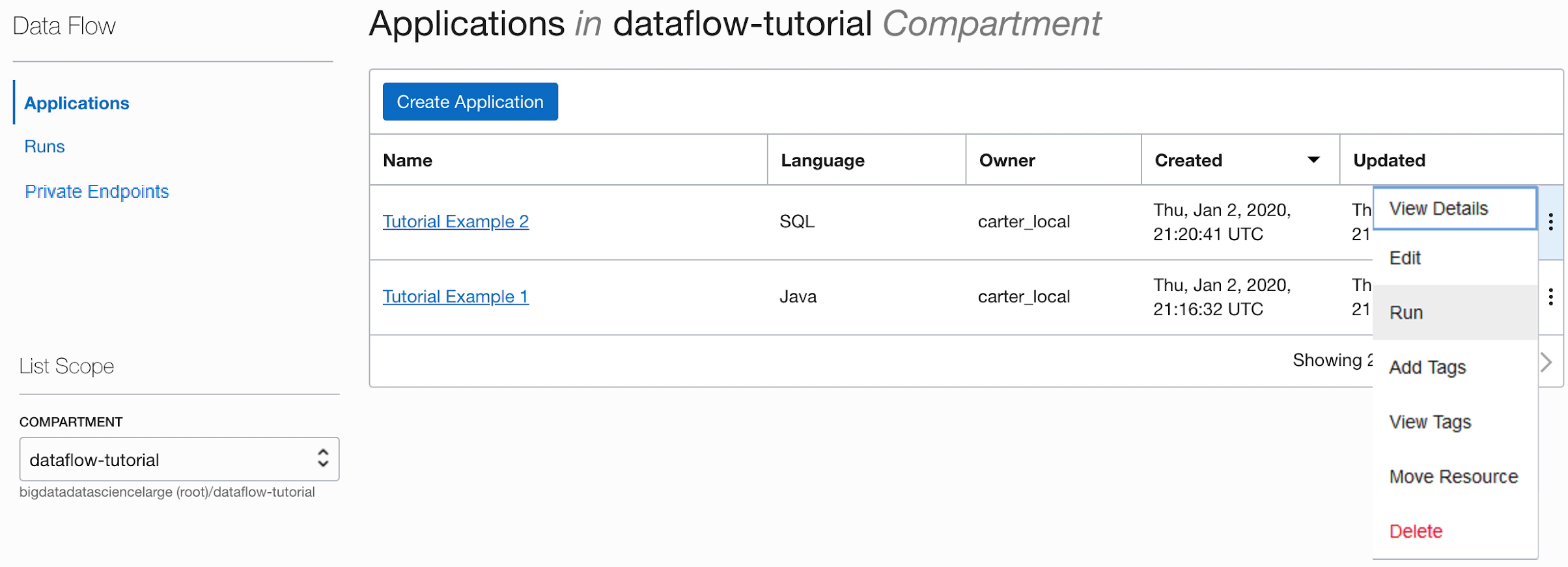
- Une fois l'exécution terminée, ouvrez l'exécution :
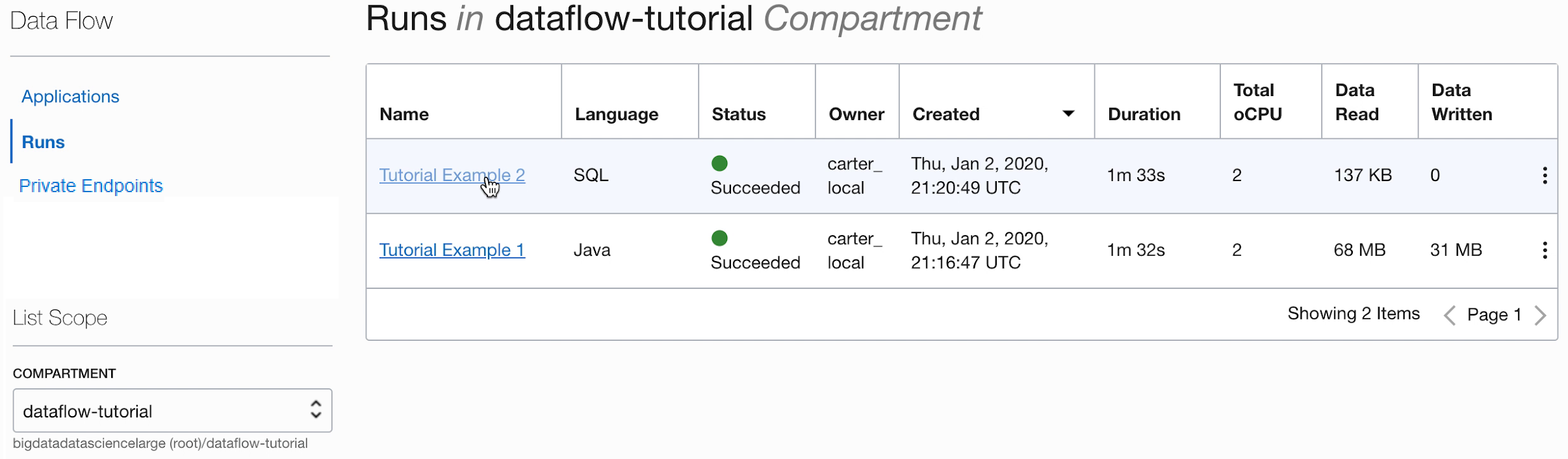
- Accédez aux journaux de l'exécution :

- Ouvrez spark_application_stdout.log.gz et vérifiez que la sortie correspond à celle ci-dessous. Remarque
Les lignes peuvent être dans un ordre différent de celui de l'image, mais les valeurs doivent correspondre.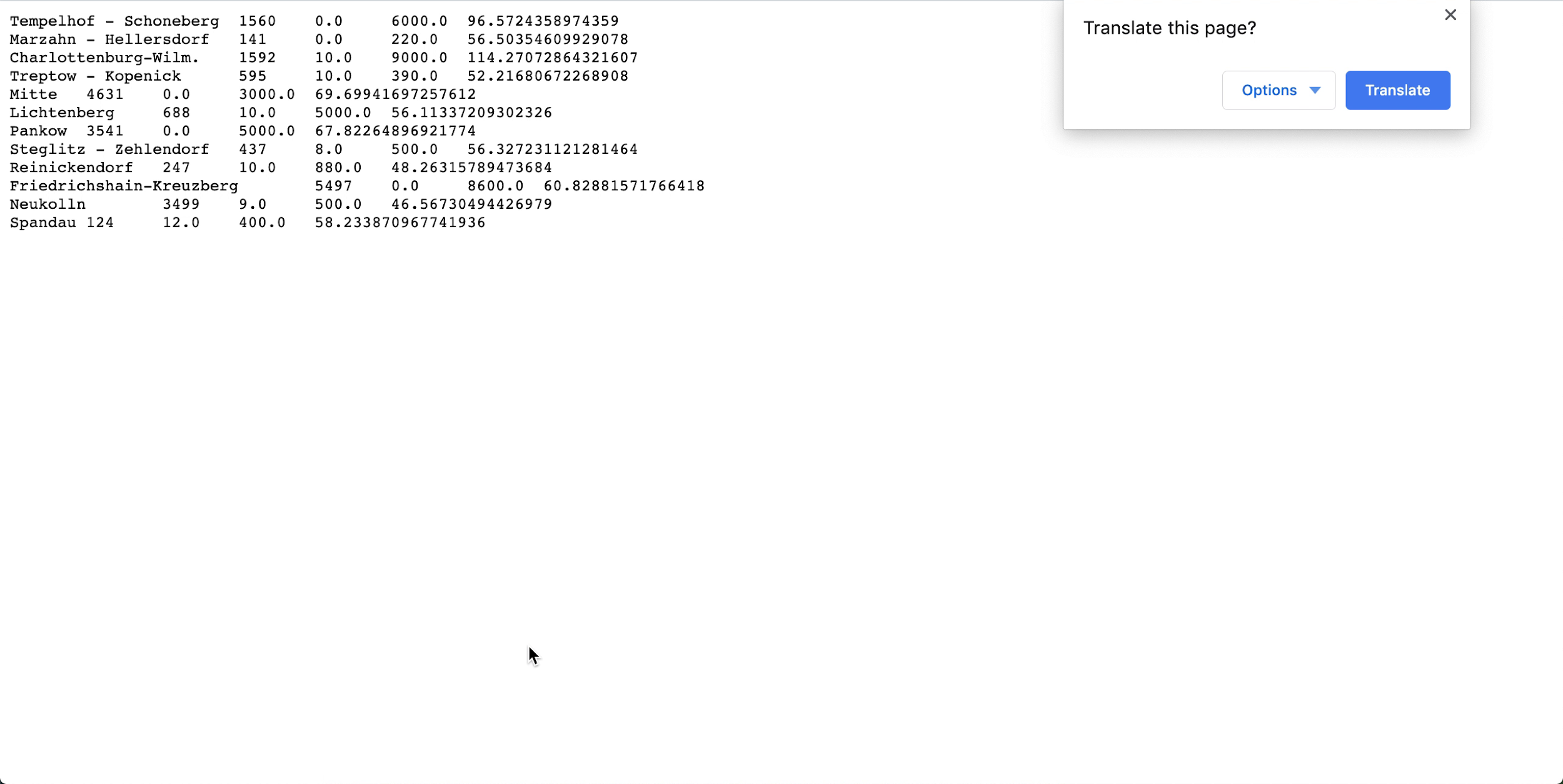
- Suite à votre profilage SQL, vous pouvez conclure que, dans cet ensemble de données, Neukolln possède le prix moyen le plus bas avec 46,57 $, tandis que Charlottenburg-Wilmersdorf possède le prix moyen le plus élevé avec 114,27 $ (remarque : l'ensemble de données source comporte des prix en dollars US et non en euros).
Cet exercice a montré certains aspects clés de Data Flow. Lorsqu'une application SQL est en place, n'importe qui peut facilement l'exécuter sans se soucier de la capacité du cluster, de l'accès aux données et de leur conservation, de la gestion des informations d'identification ou d'autres considérations relatives à la sécurité. Par exemple, un analyste peut facilement utiliser les rapports basés sur Spark grâce à Data Flow.
3. Apprentissage automatique avec PySpark
Utilisez PySpark pour effectuer une tâche simple d'apprentissage automatique sur les données d'entrée.
Cet exercice utilise la sortie de l'exercice 1. ETL avec Java comme données d'entrée. Vous devez avoir terminé le premier exercice pour pouvoir commencer celui-ci. Cette fois-ci, votre objectif est de déterminer les meilleures affaires parmi les différentes annonces Airbnb à l'aide des algorithmes d'apprentissage automatique de Spark.
Les étapes décrites dans la section concernent l'utilisation de l'interface utilisateur de la Console. Vous pouvez effectuer cet exercice à l'aide de spark-submit à partir de l'interface de ligne de commande ou de spark-submit avec le kit SDK Java.
Une application PySpark peut être utilisée directement dans vos applications Data Flow. Vous n'avez pas besoin de créer une copie.
Le texte de référence du script PySpark est fourni ici pour illustrer quelques points : 
- Le script Python attend un argument de ligne de commande (en rouge). Lorsque vous créez l'application Data Flow, vous devez créer un paramètre que l'utilisateur définit sur le chemin d'entrée.
- Le script utilise la régression linéaire pour prévoir un prix par annonce et trouve les meilleures affaires en soustrayant le prix de base à la prédiction. La plus grande valeur négative indique la meilleure valeur, en fonction du modèle.
- Le modèle dans ce script est simplifié et ne prend en compte que la superficie. Dans un contexte réel, vous utilisez davantage de variables, telles que le quartier et d'autres variables prédictives importantes.
Créez une application PySpark à partir de la console, ou avec spark-submit à partir de la ligne de commande ou à l'aide du kit SDK.
Créez une application PySpark dans Data Flow à l'aide de la console.
-
Créez une application et sélectionnez le type Python.
-
Vérifiez à nouveau la configuration de l'application et vérifiez qu'elle est semblable à la suivante :
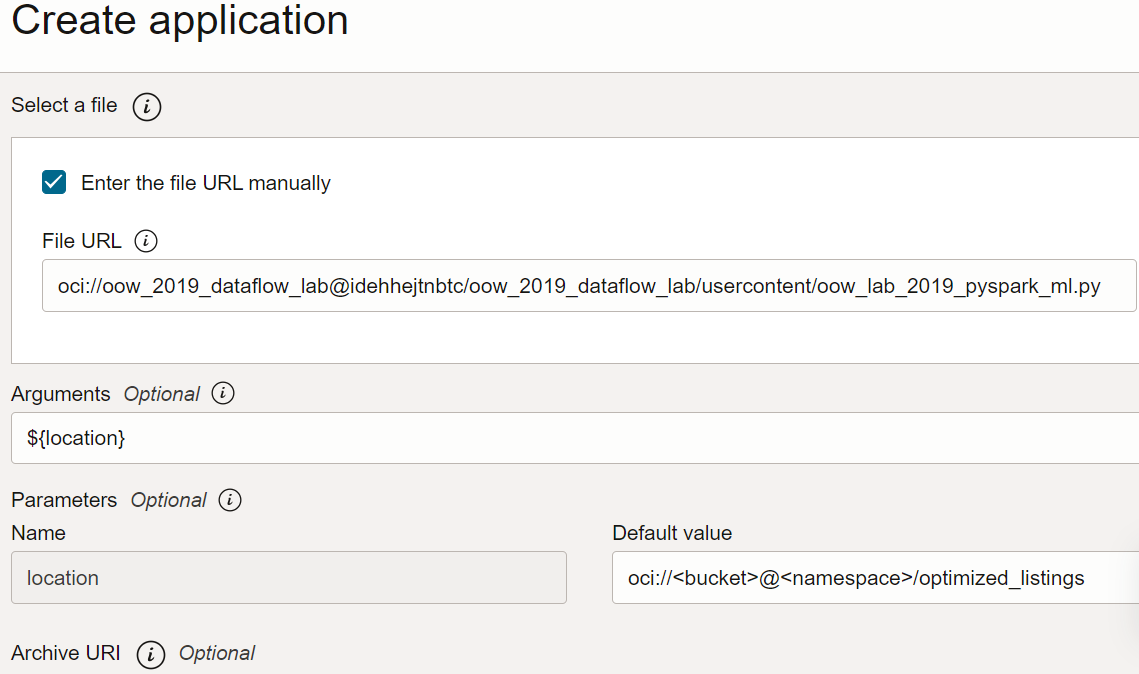
Créez une application PySpark dans Data Flow à l'aide de l'interface de ligne de commande et de la soumission Spark.
Créez une application PySpark dans Data Flow à l'aide de Spark-submit et du kit SDK.
- Exécutez l'application à partir de la liste Application.
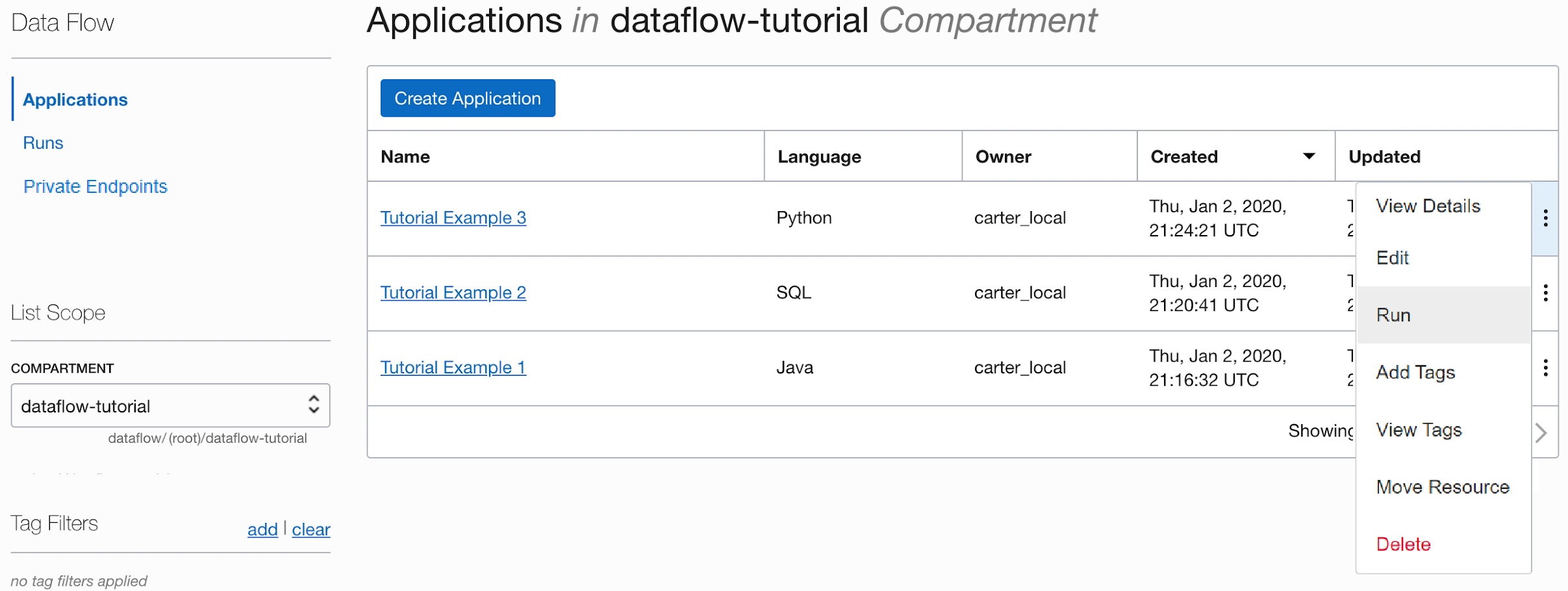
-
Une fois l'exécution terminée, ouvrez-la et accédez aux journaux.

- Ouvrez le fichier spark_application_stdout.log.gz. La sortie doit être identique à ce qui suit :

-
Dans cette sortie, vous constatez que l'ID d'annonce 690578 représente la meilleure affaire avec un prix prévu de 313,70 $ par rapport au prix de base de 35,00 $, pour une superficie indiquée de 430 mètres carrés. Si cela semble trop beau pour être vrai, l'ID unique vous permet d'explorer les données pour mieux comprendre s'il s'agit ou non d'une bonne affaire. Un analyste peut donc facilement utiliser la sortie de cet algorithme d'apprentissage automatique pour compléter son analyse.
Etapes suivantes
Vous pouvez maintenant créer et exécuter des applications Java, Python ou SQL avec Data Flow, et explorer les résultats.
Data Flow gère tous les détails du déploiement, de la désactivation, de la gestion des journaux, de la sécurité et de l'accès utilisateur. Avec Data Flow, vous pouvez vous concentrer sur le développement d'applications Spark sans vous soucier de l'infrastructure.