Instructions Object Storage de l'outil RAG pour les agents d'IA générative
Consultez les sections suivantes pour préparer les données Object Storage pour les outils RAG dans les agents d'IA générative.
Instructions générales
Suivez ces instructions pour préparer les données des sources de données des agents d'IA générative avant de les télécharger vers Object Storage :
- Sources de données : les données des agents Generative AI doivent être téléchargées en tant que fichiers vers un bucket Object Storage.
- Nombre de buckets : un seul bucket est autorisé par source de données.
- Types de fichier pris en charge : les fichiers
PDF,txt,JSON,HTMLet Markdown (MD) sont pris en charge. - Limite de taille de fichier : chaque fichier ne doit pas dépasser 100 Mo. Les fichiers qui dépassent la limite sont ignorés. Pour connaître les autres conditions requises, reportez-vous à la section File Type Requirements and Support.
- URL : Tous les liens hypertexte présents dans les documents sont extraits et affichés sous forme de liens hypertexte dans la réponse à la discussion.
- Données non prêtes : si vos données ne sont pas encore disponibles, créez un dossier vide pour la source de données et renseignez-le ultérieurement. De cette façon, vous pouvez ingérer des données dans la source une fois le dossier renseigné.
Configurez les droits d'accès Object Storage suivants avant de continuer.
- Accès utilisateur aux fichiers Object Storage
- Accès aux travaux d'ingestion de données aux fichiers Object Storage pour les travaux à longue durée d'exécution
Pour obtenir les droits d'accès, reportez-vous à Obtention de l'accès.
Exigences et prise en charge des types de fichiers
Les fichiers de source de données doivent être téléchargés vers Object Storage. Assurez-vous que les conditions requises pour le type de fichier à inclure sont remplies.
Les exigences et la prise en charge de l'inclusion des fichiers PDF sont les suivantes :
- Extension de fichier : doit être
.pdf - Taille du fichier : un seul fichier ne doit pas dépasser 100 Mo.
- Mot de passe du fichier : si un fichier PDF est protégé par mot de passe, l'échec d'un fichier est enregistré dans les journaux de statut.
- Sommaire : un fichier PDF peut inclure des images, des graphiques et des tables de référence, mais ces derniers ne doivent pas dépasser 8 Mo.
- Préparation de graphique : aucune préparation spéciale n'est nécessaire pour les graphiques, à condition qu'ils soient bidimensionnels avec des axes étiquetés. Le modèle peut répondre aux questions sur les graphiques sans explications explicites.
- Préparation de table : utilisez des tables de référence comportant plusieurs lignes et colonnes. Par exemple, l'agent peut lire la table sur la page Limites.
txt
Les exigences et la prise en charge de l'inclusion des fichiers txt sont les suivantes :
- Extension de fichier : doit être
.txt - Taille du fichier : un seul fichier ne doit pas dépasser 100 Mo.
JSON
Les exigences et la prise en charge de l'inclusion des fichiers JSON sont les suivantes :
- Extension de fichier : doit être
.json - Taille du fichier : un seul fichier ne doit pas dépasser 100 Mo.
- Encodage : seul le codage UTF-8 en anglais est pris en charge. Les données structurées JSON peuvent contenir des paires clé-valeur, des tableaux et des objets imbriqués.
- Profondeur de l'imbrication : la profondeur de la structure ne doit pas dépasser 50.
- Limite de liste : une liste dans la structure JSON ne doit pas dépasser 10000 éléments.
HTML
Les exigences et la prise en charge de l'inclusion des fichiers HTML sont les suivantes :
- Extension de fichier : doit être
.html - Taille du fichier : un seul fichier ne doit pas dépasser 100 Mo.
- Sommaire : seul le contenu visible est inclus. Tout contenu dynamique n'est pas inclus et les balises de script sont supprimées.
- Images : les images référencées dans un fichier peuvent être traitées si la source d'image n'est pas un chemin absolu ou
HTTPexterne. Toutes les images qui ne répondent pas aux exigences suivantes sont ignorées.- Seules les images
JPEG(.jpgou.jpeg) sont prises en charge. - La taille des images ne doit pas dépasser 6 Mo. Toutes les images dépassant la limite sont ignorées.
- Les images doivent être téléchargées vers Object Storage au même niveau que le fichier HTML téléchargé ou en dessous.
- Le chemin source (attribut
src) de chaque image doit être un chemin relatif au fichier HTML parent. Par exemple :<img src="./my-image.jpg"> <img src="./myfolder/my-imagetwo.jpg"> - Le chemin source (attribut
src) de chaque image ne doit pas indiquer d'URL (http,httpsoudata)
- Seules les images
MD (Markdown)
Les exigences et la prise en charge de l'assimilation des fichiers MD (Markdown) sont les suivantes :
- Extension de fichier : doit être
.md - Taille du fichier : un seul fichier ne doit pas dépasser 100 Mo.
- Images : les images sont ignorées et ne sont pas traitées.
Amélioration de la compréhension des tables
Une meilleure compréhension des tables, une fonctionnalité des outils RAG, vise à améliorer la précision des réponses aux requêtes avec des réponses intégrées dans les données des tables PDF. Il traite ces tables pour générer des réponses plus précises et pertinentes alignées sur les informations qu'elles contiennent. En général, les outils RAG peuvent lire les tableaux. Pour que l'outil RAG puisse lire les tables avec une meilleure compréhension des tables, assurez-vous que les tables présentent les fonctionnalités suivantes :
- Toutes les cellules du tableau sont séparées par des lignes visibles ou des limites d'objet des autres cellules, y compris les noms d'en-tête de la première ligne.
- Toutes les colonnes, y compris la première colonne, ont un nom d'en-tête.
- Chaque table comporte plusieurs colonnes et plusieurs lignes, à l'exception de la ligne avec des noms d'en-tête.
Count of tables that support enhanced table understanding in following PDFs:
- enhanced_table_test_data/2025_Report1.pdf has 4 tables processed successfully
- enhanced_table_test_data/2025_Report2.pdf has 3 tables processed successfully
- enhanced_table_test_data/2025_Report3.pdf has 3 tables processed successfully
Amélioration des réponses avec le filtrage des métadonnées
Utilisez des métadonnées prédéfinies pour appliquer des filtres lors d'une discussion. Lorsque des filtres sont appliqués, les recherches d'un agent dans une session de discussion sont limitées aux fichiers de données associés aux métadonnées, ce qui aide le modèle à générer des réponses pertinentes pour la portée du contenu, améliorant ainsi la précision et la pertinence des réponses de l'agent.
Les étapes suivantes décrivent l'utilisation de la fonctionnalité de filtrage des métadonnées. Une fois que vous avez compris l'aperçu du workflow, vérifiez les détails de votre cas d'emploi dans les sections fournies après les étapes d'aperçu.
- Dans un éditeur de texte, créez le schéma de métadonnées, qui est requis pour les filtres que vous voulez rendre disponibles. Ecrivez le schéma au format JSON. Nommez le fichier
_metadata_schema.json.Exemple :
{ "metadataSchema": [ { "name": "publication_year", "type": "integer" }, { "name": "title", "type": "string" } ] } - Téléchargez le fichier
_metadata_schema.jsoncréé à l'étape 1 vers le niveau racine du bucket Object Storage qui contient les fichiers de données d'une base de connaissances. - Créez des fichiers JSON pour associer des fichiers de données aux métadonnées prédéfinies et fournir les valeurs de métadonnées.
Exemple :
{ "metadataAttributes": { "publication_year": 2020 } }Vous pouvez associer des fichiers de données ou tous les fichiers d'un bucket aux métadonnées. Pour plus d'informations sur les conventions de nom de fichier JSON à utiliser pour les options que vous choisissez, reportez-vous à Options de filtre de métadonnées (nom de fichier et emplacement).
- Téléchargez les fichiers JSON créés à l'étape 3 vers le bucket Object Storage qui contient les fichiers de données d'une base de connaissances. Pour chaque option, veillez à enregistrer le fichier à l'emplacement correct dans la hiérarchie.
- Créez une base de connaissances. Sélectionnez Object Storage en tant que type de banque de données et choisissez de démarrer automatiquement le travail d'inclusion.
Lorsque les fichiers de données sont ingérés, les agents d'IA générative créent une liste des noms de métadonnées et des valeurs pouvant être sélectionnées dans une discussion. Pour afficher les noms et les valeurs des métadonnées incluses, reportez-vous à Obtention des détails d'une base de connaissances dans les agents d'IA générative.
- Créez un agent avec un outil RAG, en sélectionnant la base de connaissances créée à l'étape 5. Dans l'agent, sélectionnez l'option permettant de créer automatiquement une adresse. Si vous avez besoin d'aide, reportez-vous à Création d'un agent et à Création d'un outil RAG.
- Dans une fenêtre de discussion, ajoutez des filtres de métadonnées prédéfinis et sélectionnez les valeurs à appliquer. Reportez-vous à Utilisation des filtres de métadonnées dans une discussion.
Consultez les sections suivantes pour en savoir plus sur la préparation des fichiers JSON de métadonnées pour votre cas d'emploi et sur l'ajout et l'application de filtres de métadonnées dans une session de discussion.
Sélectionnez une ou plusieurs des méthodes suivantes qui vous conviennent le mieux.
| Méthode | Nom et emplacement du fichier | Syntaxe |
|---|---|---|
| Incluez des métadonnées pour tous les fichiers d'un bucket sans mentionner leur nom. | Créez un fichier _common.metadata.json au niveau racine Object Storage. |
Utilisez ce fichier pour les métadonnées communes à tous les fichiers du bucket. Cette méthode évite d'entrer des doublons de métadonnées entre les objets. |
| Dans un fichier, créez une entrée de métadonnées pour chaque fichier d'un bucket et incluez les noms de fichier. | Créez un fichier _all.metadata.json au niveau racine Object Storage. |
Utilisez cette méthode si vous avez beaucoup de fichiers et la création d'un fichier qui inclut tous les noms de fichier est plus pratique pour vous que la création d'un fichier de métadonnées par fichier. |
| Créez un fichier de métadonnées pour chaque fichier d'un bucket. | Créez un fichier <file-name>.metadata.json pour chaque fichier, au niveau du fichier.
|
Utilisez cette méthode lorsque les métadonnées diffèrent pour chaque fichier et qu'il n'y a pas beaucoup de fichiers pour lesquels créer un fichier de métadonnées, ou si vous automatisez la création des fichiers de métadonnées. |
| Ajoutez des en-têtes de métadonnées Object Storage à chaque fichier. | Ajoutez un en-tête de métadonnées via la propriété de métadonnées Object Storage de chaque fichier. | Utilisez cette méthode si vous avez peu de propriétés de métadonnées à inclure. Nous vous recommandons d'utiliser les autres méthodes avec les fichiers JSON, car les fichiers sont plus faciles à mettre à jour et à gérer et les en-têtes de métadonnées sont difficiles à mettre à jour. |
Pour toutes les méthodes, vous devez définir un fichier de schéma de métadonnées nommé _metadata_schema.json au niveau racine du bucket Object Storage.
Voici un exemple de hiérarchie dans laquelle vous enregistrez les fichiers de métadonnées dont vous avez besoin.
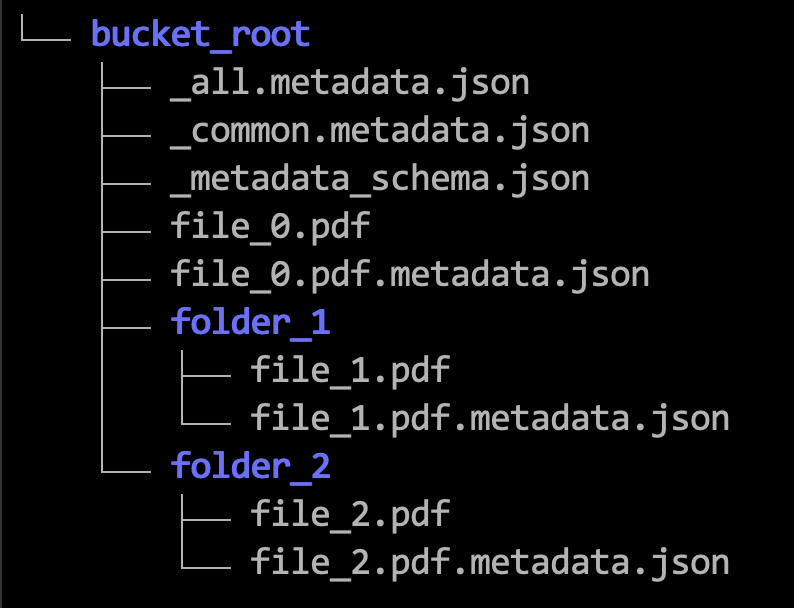
Les étapes suivantes utilisent des exemples pour montrer comment formater les fichiers JSON de métadonnées. Reportez-vous également à Limites pour le filtrage des métadonnées.
Vous ne pouvez pas modifier ou enlever les champs de métadonnées une fois les données de la base de connaissances incluses. Vous pouvez ajouter de nouveaux champs à la limite autorisée. Pour supprimer ou mettre à jour un champ, recréez la base de connaissances.
La procédure suivante suppose que vous avez créé le schéma de métadonnées requis et les fichiers JSON facultatifs de filtre de métadonnées, une base de connaissances et un agent doté d'un outil RAG et d'une adresse.
| Description | Limite |
|---|---|
Nombre maximal d'entrée dans _all.metadata.json |
10 000 |
| Nombre maximal de champs de métadonnées pouvant être spécifiés pour chaque fichier | 20 |
Nombre maximal d'éléments dans un fichier list_of_string type |
10 |
Longueur maximale d'un élément individuel dans un type list_of_string |
50 |
| Longueur maximale d'une clé de métadonnées en caractères | 25 |
| Longueur maximale de la valeur de métadonnées en caractères | 50 |
Ajout de métadonnées à un en-tête de métadonnées Object Storage
Ajout de données avec une URL personnalisée à un compartiment Object Storage
Clients bêta :
Si vous avez créé une base de connaissances au cours de la phase bêta, vous devrez peut-être supprimer et recréer la source de données pour que la fonctionnalité de gestion des URL fonctionne.
Affectation d'une URL personnalisée à une citation
metadata pour ce fichier.Cette rubrique explique comment ajouter ou mettre à jour l'objet metadata via l'interface de ligne de commande OCI.
- L'objet
metadataqui remplace la citation par défaut doit avoir le nomcustomized_url_source. - Vous pouvez avoir un objet
metadataavec le nomcustomized_url_source - Chaque
customized_url_sourcene peut avoir qu'une seule URL. - Les commandes de l'étape 5 permettent d'ajouter et de mettre à jour l'objet
metadata, car elles remplacent la valeur de l'objetmetadataen cours. - Veillez à transmettre les valeurs de l'objet
--metadataavec le format indiqué dans les commandes de l'étape 5.