Interrogation des données externes avec AWS Glue Data Catalog
Autonomous AI Database prend en charge un système de synchronisation avec une instance Amazon AWS Glue Data Catalog.
A propos de l'interrogation avec AWS Glue Data Catalog
Autonomous AI Database vous permet de synchroniser vos données avec les métadonnées d'Amazon Web Service (AWS) Glue Data Catalog. Une table externe de base de données est automatiquement créée par Autonomous AI Database pour chaque table collectée par AWS Glue sur les données stockées dans Amazon Simple Storage Service (S3). Les utilisateurs peuvent interroger les données stockées dans S3 à partir d'une base de données Autonomous AI sans avoir à dériver manuellement le schéma pour les sources de données externes et à créer des tables externes.
Amazon AWS Glue Data Catalog est un service de gestion de métadonnées centralisé qui aide les professionnels des données à découvrir les données et prend en charge la gouvernance des données dans le cloud AWS. Une instance de base de données Autonomous AI peut synchroniser automatiquement les métadonnées de catalogue de données avec AWS Glue Data Catalog, ce qui permet aux utilisateurs de base de données d'utiliser immédiatement Autonomous AI Database pour interroger les données stockées dans le cloud AWS.
La synchronisation avec AWS Glue Data Catalog possède les mêmes propriétés que la synchronisation avec OCI Data Catalog. La synchronisation est dynamique, ce qui permet de maintenir la base de données à jour en ce qui concerne les modifications apportées aux données sous-jacentes, ce qui réduit les coûts d'administration car elle gère automatiquement des centaines à des milliers de tables.
Concepts liés à l'interrogation avec AWS Glue Data Catalog
Une compréhension des concepts suivants est nécessaire pour l'interrogation avec les catalogues de données Amazon Web Service (AWS) Glue.
Catalogue de données AWS Glue : Base de données
Une base de données AWS Glue représente un ensemble de définitions de table relationnelle, organisées en un groupe logique. Chaque instance de catalogue de données AWS Glue gère plusieurs bases de données.
Catalogue de données AWS Glue : Table
Une table AWS Glue représente une table relationnelle sur les données stockées dans le cloud AWS. Une table AWS Glue définit le schéma des données sous-jacentes et se compose d'informations de colonne, de partition, de sérialisation, de stockage, de statistiques, de métadonnées définies par l'utilisateur et d'autres métadonnées. Les tables du catalogue de données AWS Glue peuvent être créées manuellement ou automatiquement à l'aide d'un robot AWS Glue.
Glue Data Catalog : analyseur de liens
Vous pouvez utiliser un robot pour remplir le catalogue de données AWS Glue avec des tables. Il s'agit de la méthode principale utilisée par la plupart des utilisateurs AWS Glue. Un robot peut analyser plusieurs banques de données en une seule exécution. Une fois l'analyseur de liens terminé, il crée ou met à jour des tables dans votre catalogue de données. Les travaux d'extraction, de transformation et de chargement (ETL) que vous définissez dans AWS Glue utilisent ces tables de catalogue de données comme sources et cibles. Le travail ETL lit et écrit dans les banques de données indiquées dans les tables de catalogue de données source et cible.
Les tables AWS Glue peuvent être créées manuellement par l'utilisateur ou automatiquement à l'aide d'un robot prédéfini ou personnalisé. Les analyseurs de liens se connectent aux banques de données sous-jacentes (par exemple, Amazon S3), appellent des classificateurs pour dériver le schéma des données et créent des tables AWS Glue pour stocker les métadonnées inférées. AWS Glue fournit des classificateurs pour les types de fichiers courants, tels que CSV, JSON, Parquet et AVRO.
Mappage entre la base de données d'IA autonome et AWS Glue
Au cours du processus de synchronisation, des tables externes sont créées dans une base de données Autonomous AI dérivée des bases de données AWS Glue Data Catalog et des tables sur Amazon S3.
AWS Glue organise les métadonnées collectées dans les bases de données et les tables. Une base de données AWS Glue est un ensemble de définitions de table relationnelle. Tables AWS Glue qui décrivent le schéma commun et les propriétés des fichiers associés à la table.
AWS Glue suit le modèle relationnel de représentation des attributs. Pour mapper des schémas hiérarchiques avec des schémas relationnels, AWS Glue infère le schéma des données semi-structurées et les met à plat en un schéma relationnel à l'aide d'un processus ETL.
Le tableau suivant représente le mappage entre les concepts OCI Data Catalog et AWS Glue Data Catalog.
| OCI Data Catalog | Catalogue de données AWS Glue | Oracle AI Database |
|---|---|---|
| Ressource de données | Base de données | Schéma |
| Dossier | (Bucket) | Schéma |
| Entité logique | Table | Table |
Workflow utilisateur pour les requêtes avec AWS Glue Data Catalog
Le workflow utilisateur de base pour interroger les données AWS S3 avec AWS Glue Data Catalog consiste à se connecter à AWS Glue Data Catalog, à se synchroniser avec Autonomous AI Database pour créer automatiquement des tables externes, puis à interroger les données S3.
L'administrateur de catalogue de données de base de données crée une connexion entre l'instance Autonomous AI Database et une instance AWS Glue Data Catalog, puis configure et exécute une synchronisation (synchronisation) entre AWS Glue Data Catalog et Autonomous AI Database. Autonomous AI Database crée automatiquement une table externe pour les tables collectées par AWS Glue sur les données stockées dans S3.
L'administrateur des requêtes Database Data Catalog ou l'administrateur de base de données accorde l'accès READ aux tables externes générées afin que les analystes de données et les autres utilisateurs de base de données puissent parcourir et interroger la base de données Autonomous AI sans avoir à dériver manuellement le schéma pour les sources de données externes et à créer des tables externes.
Utilisateurs
Le tableau ci-dessous décrit les différents types d'utilisateur qui exécutent les actions de workflow utilisateur.
| Utilisateur | Description |
|---|---|
| Administrateur Database Data Catalog | Utilisateur de base de données doté du rôle DCAT_SYNC. |
| Administrateur de requête de catalogue de données de base de données | L'utilisateur de base de données peut accorder l'accès aux tables externes créées automatiquement à d'autres utilisateurs. |
| Analyste de données | Utilisateur de base de données sur la base de données Autonomous AI interrogeant des données dans AWS S3 soit en interrogeant des tables externes créées automatiquement, soit en interagissant directement avec AWS Glue Data Catalog. |
| Utilisateur du catalogue de données AWS Glue | Utilisateur AWS ayant accès à un catalogue de données AWS Glue. |
| Utilisateur AWS S3 Object Storage | Utilisateur AWS ayant accès aux données stockées dans AWS S3 |
Workflow d'utilisateur
Le tableau ci-dessous décrit chaque action incluse dans le workflow et le type d'utilisateur qui peut effectuer l'action.
Remarque
Remarque : le package DBMS_DCAT est disponible pour effectuer les tâches requises pour interroger le stockage d'objets AWS S3 à l'aide d'AWS Glue Data Catalog. Reportez-vous à Package DBMS_DCAT.
| Action | Qui est l'utilisateur ? | Description |
|---|---|---|
| Créer des politiques | Administrateur Database Data Catalog | Les informations d'identification utilisateur de la base de données Autonomous AI doivent disposer des droits d'accès appropriés pour accéder à AWS Glue Data Catalog et lire le stockage d'objets S3. Plus d'informations : informations d'identification requises et stratégies IAM. |
| Créer des informations d'identification | Administrateur Database Data Catalog | Assurez-vous que les informations d'identification de base de données sont en place pour accéder à AWS Glue Data Catalog et pour interroger le stockage d'objets S3. L'utilisateur appelle `DBMS_CLOUD.CREATE_CREDENTIAL` pour créer les informations d'identification de l'utilisateur. Remarque : seules les informations d'identification Amazon Web Services (AWS) sont prises en charge. Les informations d'identification AWS Amazon Resource Names (ARN) ne sont pas prises en charge. Plus d'informations : [DBMS_CLOUD CREATE_CREDENTIAL Procedure](dbms-cloud-subprograms.html#GUID-742FC365-AA09-48A8-922C-1987795CF36A) |
| Connexion | Administrateur Database Data Catalog | Etablissez une connexion entre une instance Autonomous AI Database et une instance AWS Glue Data Catalog. La connexion utilise les privilèges de l'utilisateur AWS Glue Data Catalog. Les connexions d'une instance de base de données Autonomous AI à plusieurs instances AWS Glue Data Catalog sont prises en charge. Pour lancer une connexion entre une instance de base de données Autonomous AI et une instance AWS Glue Data Catalog, l'utilisateur :
Une fois la connexion établie, la base de données Autonomous AI stocke les métadonnées associées, telles que l'ID de catalogue, la région, l'adresse et les objets d'informations d'identification AWS Glue. Plus d'informations : Procédure SET_DATA_CATALOG_CONN, Procédure UNSET_DATA_CATALOG_CONN, Procédure SET_DATA_CATALOG_CREDENTIAL, Procédure SET_OBJECT_STORE_CREDENTIAL. |
| Synchroniser | Administrateur Database Data Catalog | L'utilisateur peut démarrer manuellement une synchronisation avec les catalogues de données AWS Glue connectés à l'aide de La synchronisation effectue les opérations suivantes :
|
| Surveillance de la synchronisation | Administrateur Database Data Catalog | L'utilisateur peut visualiser le statut de synchronisation en interrogeant la vue USER_LOAD_OPERATIONS. Une fois le processus de synchronisation terminé, l'utilisateur peut consulter un journal des résultats de la synchronisation, y compris des détails sur les mappages avec des tables externes.Plus d'informations : [Surveillance et dépannage des chargements](load-data-cloud-monitor.html#GUID-657A579F-CF44-458B-8C97-3E50D0C98006) |
| Accorder des privilèges | Administrateur de requête de catalogue de données de base de données, administrateur de base de données | L'administrateur de requête de catalogue de données de base de données ou l'administrateur de base de données doit accorder des privilèges READ sur les tables externes générées aux utilisateurs des analystes de données. Cela permet aux analystes de données d'interroger les tables externes générées. |
| Requête | Analyste de données | Les analystes de données peuvent examiner les schémas et les tables synchronisés dans les schémas GLUE$* et interroger les tables externes via n'importe quel outil ou application prenant en charge Oracle SQL. Les données de S3 sont accessibles à l'aide des privilèges de l'utilisateur de stockage d'objets AWS S3. Plus d'informations : Exemple : requête avec AWS Glue Data Catalog |
| Interrompre les connexions | Administrateur Database Data Catalog | Pour enlever une association Data Catalog existante, l'utilisateur appelle la procédure Cette action est uniquement effectuée lorsque vous ne prévoyez plus d'utiliser le catalogue de données AWS Glue connecté et les tables externes dérivées du catalogue. Cette action supprime les métadonnées AWS Glue Data Catalog et supprime les tables externes synchronisées de l'instance Autonomous AI Database. Plus d'informations : Procédure UNSET_DATA_CATALOG_CONN |
Exemple : requête avec AWS Glue Data Catalog
Cet exemple vous guide tout au long du processus d'exécution de requêtes sur des ensembles de données stockés dans Amazon Simple Storage Service (Amazon S3) à l'aide d'un catalogue de données AWS Glue.
Dans cet exemple, les métadonnées d'un catalogue de données AWS Glue sont inspectées pour voir quels objets Amazon S3 ont été précédemment analysés et existent dans le catalogue de données. Autonomous AI Database est ensuite associé au catalogue de données AWS Glue et à Amazon S3. Le catalogue de données est synchronisé avec Autonomous AI Database pour créer des tables externes sur les ensembles de données stockés dans Amazon S3. Les tables externes sont utilisées pour interroger les jeux de données dans Amazon S3.
-
Inspectez les métadonnées dans AWS Glue Data Catalog.
-
Lancez la console AWS Glue.
-
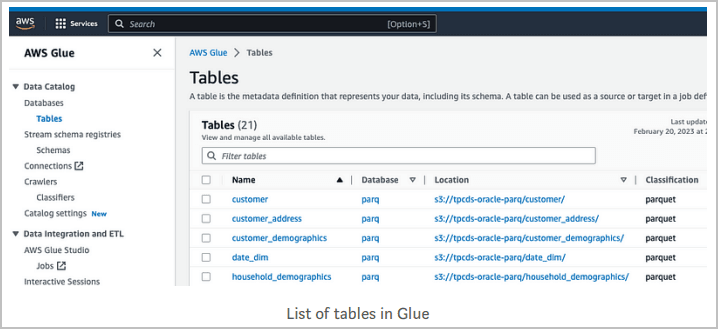
Accédez au catalogue de données, aux bases de données et aux tables pour rechercher des objets existants.
Dans cet exemple, il existe des objets dans Amazon S3 pour lesquels AWS Glue a précédemment analysé et créé des tables, comme indiqué ci-dessous :
-
-
Associez AWS Glue à la base de données Autonomous AI.
-
Créez des informations d'identification dans la base de données Autonomous AI.
L'appel de procédure suivant inclut l'ID d'accès et la clé secrète pour fournir à la base de données Autonomous AI un accès aux données sous-jacentes dans Amazon S3.
<pre class="copy"><code>exec dbms_cloud.create_credential('CRED_AWS','<access id>', '<access key>');</code></pre> -
Associez les informations d'identification au catalogue de données AWS Glue et au stockage d'objets Amazon S3.
Ces appels de procédure associent respectivement le catalogue de données et le stockage d'objets aux informations d'identification.
<pre class="copy"><code>exec dbms_dcat.set_data_catalog_credential('CRED_AWS'); exec dbms_dcat.set_object_store_credential('CRED_AWS');</code></pre> -
Configurez une région AWS dans laquelle Glue est exécuté.
<pre class="copy"><code>exec dbms_dcat.set_data_catalog_conn(region => 'us-west-2', catalog_type=>'AWS_GLUE');</code></pre>
-
-
Synchronisez les métadonnées pour créer des tables externes dans la base de données Autonomous AI dérivée des bases de données et des tables AWS Glue.
-
Une fois l'association effectuée, utilisez la vue
all_glue_databasespour rechercher les bases de données qui se trouvent dans un catalogue de données AWS Glue.<pre class="copy"><code>select * from all_glue_databases order by name;</code></pre> -
Utilisez la vue
all_glue_tablespour obtenir la liste des tables disponibles pour la synchronisation.<pre class="copy"><code>select * from all_glue_tables order by database_name, name;</code></pre>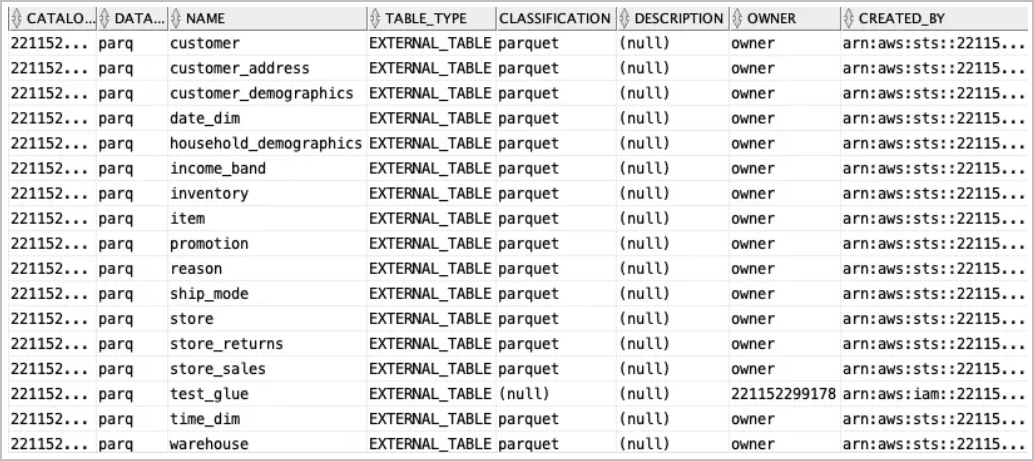
-
Synchronisez la base de données Autonomous AI avec deux tables,
storeetitem, trouvées dans la base de donnéesparq.<pre class="copy"><code>begin dbms_dcat.run_sync( synced_objects => ' { "database_list": [ { "database": "parq", "table_list": ["store","item"] } ] }', error_semantics => 'STOP_ON_ERROR'); end; /</code></pre>
-
-
Inspectez les nouveaux objets dans la base de données Autonomous AI et exécutez une requête sur S3.
-
Utilisez SQL Developer pour visualiser les nouveaux objets créés par l'opération de synchronisation précédente.
Le schéma
GLUE$PARQ_TPCDS_ORACLE_PARQa été généré et nommé automatiquement par l'appel de procéduredbms_dcat.run_sync.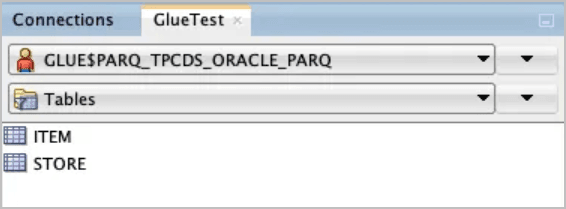
-
Exécutez une requête SQL sur des banques de jeux de données dans Amazon S3.
<pre class="copy"><code>SELECT * FROM glue$parq_tpcds_oracle_parq.store;</code></pre>
-