Logistic regression is a statistical tool for modeling how the probability of a response depends on the presence of multiple predictors, or risk factors. In the Empirica Signal application, the predictors are products and, optionally, covariates such as report year, gender, or age group, and the responses are adverse events.
The main statistical scores computed for the predictors and responses in a logistic regression run are LROR, LR05, and LR95, representing the Logistic Regression Odds Ratio and the 90% confidence interval (LR05, LR95). The scores from a logistic regression run, when compared to the results of an MGPS run, can help identify confounding or masking effects.
To create a logistic regression run, you select a data configuration and one drug variable (the predictor) and one event variable (the response) variable to combine for score generation. You can also explicitly specify drug and event values to include in the computation. Because the logistic regression computation assesses the results of polytherapy, selecting configurations that include concomitant as well as suspect products, and drug variables, such as Single Ingredient, that treat combination products as if the patient had taken separate products, are recommended.
You can also select one or more other variables, such as gender, age group, and report receipt year, as covariates (additional predictor variables) for the computation. Each value of a covariate is used in the logistic regression computation as its own predictor, except for the value with the highest frequency among all reports in the analysis, which is used as the standard to which the other values are compared. For example, if you select Gender as a covariate and Gender has the unique values F, M, and U, with M occurring most frequently, computations are made for the two predictor values GENDER_F and GENDER_U. For the relatively rare situations in which the covariate value that occurs most frequently overall, such as M, does not occur in combination with a certain event, such as Uterine cancer, then the value occurring most frequently with that event is used instead. Logistic regression is then performed with product values and these covariate values as predictors for each response.
For more information about logistic regression computations, see Logistic regression computations.
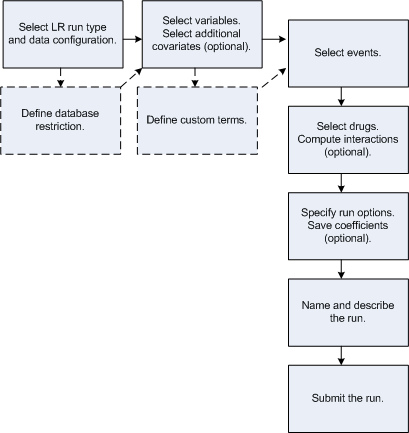
In addition to selecting the variables for the run, you also have options to:
· Use either extended logistic regression, which includes the computation of the best alpha value to use for each response, or standard logistic regression, which uses 0.5 as the alpha value for every response.
· Define a database restriction, which limits the cases in the source data that are included in the run.
· Define custom terms, which are pseudo-values.
· Specify events of interest for the run.
· Explicitly supply drugs and/or provide the application with guidelines (minimum number of occurrences with the event, total number of drugs to include) for selecting drugs that occur frequently with specified events.
· Include computations for interactions, such as drug+drug+event or drug+covariate+event, for each response.
· Include the computed coefficients and standard errors of the run in the lr_coefficients.log log file.
The execution of a logistic regression run includes the following steps. Dotted lines represent optional steps.