Utilizzo di JupyterHub in Big Data Service 3.0.26 o precedente
Utilizzare JupyterHub per gestire i notebook ODH 1.x Big Data Service 3.0.26 o versioni precedenti per gruppi di utenti.
Prerequisiti
Prima di poter accedere a JupyterHub da un browser, un amministratore deve:
- Rendere il nodo disponibile per le connessioni in entrata dagli utenti. L'indirizzo IP privato del nodo deve essere mappato a un indirizzo IP pubblico. In alternativa, il cluster può essere impostato per utilizzare un bastion host o FastConnect Oracle. Vedere Connessione a nodi cluster con indirizzi IP privati.
- Aprire la porta
8000sul nodo configurando le regole di entrata nella lista di sicurezza di rete. Vedere Definizione delle regole di sicurezza.
JupyterHub Credenziali predefinite
Le credenziali di accesso amministratore predefinite per JupyterHub in Big Data Service 3.0.21 e versioni precedenti sono le seguenti:
- Nome utente:
jupyterhub - Password: Apache Ambari admin password. Si tratta della password amministratore del cluster specificata al momento della creazione del cluster.
- Nome principal per il cluster HA:
jupyterhub - Tabella chiavi per il cluster HA:
/etc/security/keytabs/jupyterhub.keytab
Le credenziali di accesso amministratore predefinite per JupyterHub in Big Data Service da 3.0.22 a 3.0.26 sono le seguenti:
- Nome utente:
jupyterhub - Password: Apache Ambari admin password. Si tratta della password amministratore del cluster specificata al momento della creazione del cluster.
- Nome principal per il cluster HA:
jupyterhub/<FQDN-OF-UN1-Hostname> - Tabella chiavi per il cluster HA:
/etc/security/keytabs/jupyterhub.keytabesempio:Principal name for HA cluster: jupyterhub/pkbdsv2un1.rgroverprdpub1.rgroverprd.oraclevcn.com Keytab for HA cluster: /etc/security/keytabs/jupyterhub.keytab
L'amministratore crea utenti aggiuntivi e le relative credenziali di accesso e fornisce le credenziali di accesso a tali utenti. Per ulteriori informazioni, vedere Gestire utenti e autorizzazioni.
A meno che non si faccia esplicitamente riferimento a un altro tipo di amministratore, l'uso di administrator o admin in questa sezione fa riferimento all'amministratore JupyterHub, jupyterhub.
Accesso a JupyterHub
In alternativa, è possibile accedere al collegamento JupyterHub dalla pagina Dettagli cluster in URL cluster.
Puoi anche creare un load balancer per fornire un front end sicuro per l'accesso ai servizi, tra cui JupyterHub. Vedere Connessione ai servizi in un cluster mediante Load Balancer.
Creazione di blocchi appunti
I prerequisiti devono essere soddisfatti per l'utente che tenta di generare dinamicamente i notebook.
- Accedere a JupyterHub.
- Accedi con le credenziali di amministrazione. L'autorizzazione funziona solo se l'utente è presente sull'host Linux. JupyterHub cerca l'utente sull'host Linux durante il tentativo di generare dinamicamente il server notebook.
- Si viene reindirizzati a una pagina Opzioni server in cui è necessario richiedere un ticket Kerberos. Questo ticket può essere richiesto utilizzando il principal Kerberos e il file keytab o la password Kerberos. L'amministratore del cluster può fornire il nome principale Kerberos e il file keytab o la password Kerberos.
Il ticket Kerberos è necessario per accedere alle directory HDFS e ad altri servizi Big Data che si desidera utilizzare.
I prerequisiti devono essere soddisfatti per l'utente che tenta di generare dinamicamente i notebook.
- Accedere a JupyterHub.
- Accedi con le credenziali di amministrazione. L'autorizzazione funziona solo se l'utente è presente sull'host Linux. JupyterHub cerca l'utente sull'host Linux durante il tentativo di generare dinamicamente il server notebook.
Gestisci JupyterHub
Un utente JupyterHub admin può eseguire i task riportati di seguito per gestire i notebook in JupyterHub sui nodi ODH 1.x di Big Data Service 3.0.26 o versioni precedenti.
Come admin, è possibile configurare JupyterHub.
Configurare JupyterHub tramite il browser per i cluster Big Data Service 3.0.26 o versioni precedenti.
Arrestare o avviare JupyterHub tramite il browser per i cluster Big Data Service 3.0.26 o versioni precedenti.
In qualità di utente admin, è possibile arrestare o disabilitare l'applicazione in modo che non utilizzi risorse, ad esempio la memoria. Il riavvio potrebbe essere utile anche per problemi o comportamenti imprevisti.
L'amministratore può limitare il numero di server notebook attivi nel cluster Big Data Service.
Per impostazione predefinita, i notebook vengono memorizzati nella directory HDFS di un cluster.
È necessario avere accesso alla directory HDFS hdfs:///user/<username>/. I notebook vengono salvati in hdfs:///user/<username>/notebooks/.
- Connettersi come utente
opcal nodo di utility in cui è installato JupyterHub (il secondo nodo di utility di un cluster HA (altamente disponibile) o il primo e unico nodo di utility di un cluster non HA). - Utilizzare
sudoper gestire le configurazioni JupyterHub memorizzate in/opt/jupyterhub/jupyterhub_config.py.c.Spawner.args = ['--ServerApp.contents_manager_class="hdfscm.HDFSContentsManager"'] - Utilizzare
sudoper riavviare JupyterHub.sudo systemctl restart jupyterhub.service
Un utente amministratore può memorizzare i singoli notebook utente nello storage degli oggetti anziché in HDFS. Quando si modifica il content manager da HDFS a Object Storage, i notebook esistenti non vengono copiati nello storage degli oggetti. I nuovi notebook vengono salvati nello storage degli oggetti.
- Connettersi come utente
opcal nodo di utility in cui è installato JupyterHub (il secondo nodo di utility di un cluster HA (altamente disponibile) o il primo e unico nodo di utility di un cluster non HA). - Utilizzare
sudoper gestire le configurazioni JupyterHub memorizzate in/opt/jupyterhub/jupyterhub_config.py. Per informazioni su come generare le chiavi necessarie, vedere Genera accesso e chiave segreta.c.Spawner.args = ['--ServerApp.contents_manager_class="s3contents.S3ContentsManager"', '--S3ContentsManager.bucket="<bucket-name>"', '--S3ContentsManager.access_key_id="<accesskey>"', '--S3ContentsManager.secret_access_key="<secret-key>"', '--S3ContentsManager.endpoint_url="https://<object-storage-endpoint>"', '--S3ContentsManager.region_name="<region>"','--ServerApp.root_dir=""'] - Utilizzare
sudoper riavviare JupyterHub.sudo systemctl restart jupyterhub.service
Integrazione con lo storage degli oggetti
Integra Spark con lo storage degli oggetti per l'uso con i cluster Big Data Service.
In JupyterHub, affinché Spark possa utilizzare lo storage degli oggetti, è necessario definire alcune proprietà di sistema e inserirle nelle proprietà spark.driver.extraJavaOption e spark.executor.extraJavaOptions nelle configurazioni Spark.
Prima di poter integrare correttamente JupyterHub con lo storage degli oggetti, devi:
- Creare un bucket nell'area di memorizzazione degli oggetti per memorizzare i dati.
- Creare una chiave API di storage degli oggetti.
Le proprietà da definire nelle configurazioni Spark sono le seguenti:
-
TenantID -
Userid -
Fingerprint -
PemFilePath -
PassPhrase -
Region
È possibile recuperare i valori per le seguenti proprietà:
- Aprire il menu di navigazione e selezionare Analytics e AI. In Data lake, selezionare Big Data Service.
- Nella pagina della lista Cluster selezionare il cluster che si desidera utilizzare. Se è necessaria assistenza per trovare la pagina della lista o il cluster, vedere Elenca cluster in un compartimento.
-
Per visualizzare i cluster in un compartimento diverso, cambiare il compartimento.
È necessario disporre dell'autorizzazione per lavorare in un compartimento e visualizzare le risorse al suo interno. In caso di dubbi su quale compartimento utilizzare, contattare un amministratore. Per ulteriori informazioni, vedere Introduzione ai compartimenti.
- Nella pagina Dettagli cluster selezionare Chiavi API di storage degli oggetti.
- Dal menu della chiave API che si desidera visualizzare, selezionare Visualizza file di configurazione.
Il file di configurazione include tutti i dettagli delle proprietà di sistema, ad eccezione della passphrase. La passphrase viene specificata durante la creazione della chiave API di storage degli oggetti ed è necessario ricordare e utilizzare la stessa passphrase.
- Accedere a JupyterHub.
- Aprire un nuovo notebook.
- Copiare e incollare i seguenti comandi per connettersi a Spark.
import findspark findspark.init() import pyspark - Copiare e incollare i comandi seguenti per creare una sessione Spark con le configurazioni specificate. Sostituire le variabili con i valori delle proprietà di sistema recuperati in precedenza.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("spark.driver.extraJavaOptions", "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .config("spark.executor.extraJavaOptions" , "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .appName("<appname>") \ .getOrCreate() - Copiare e incollare i comandi seguenti per creare le directory e il file dello storage degli oggetti e memorizzare i dati in formato Parquet.
demoUri = "oci://<BucketName>@<Tenancy>/<DirectoriesAndSubDirectories>/" parquetTableUri = demoUri + "<fileName>" spark.range(10).repartition(1).write.mode("overwrite").format("parquet").save(parquetTableUri) - Copiare e incollare il comando seguente per leggere i dati dallo storage degli oggetti.
spark.read.format("parquet").load(parquetTableUri).show() - Eseguire il notebook con tutti questi comandi.
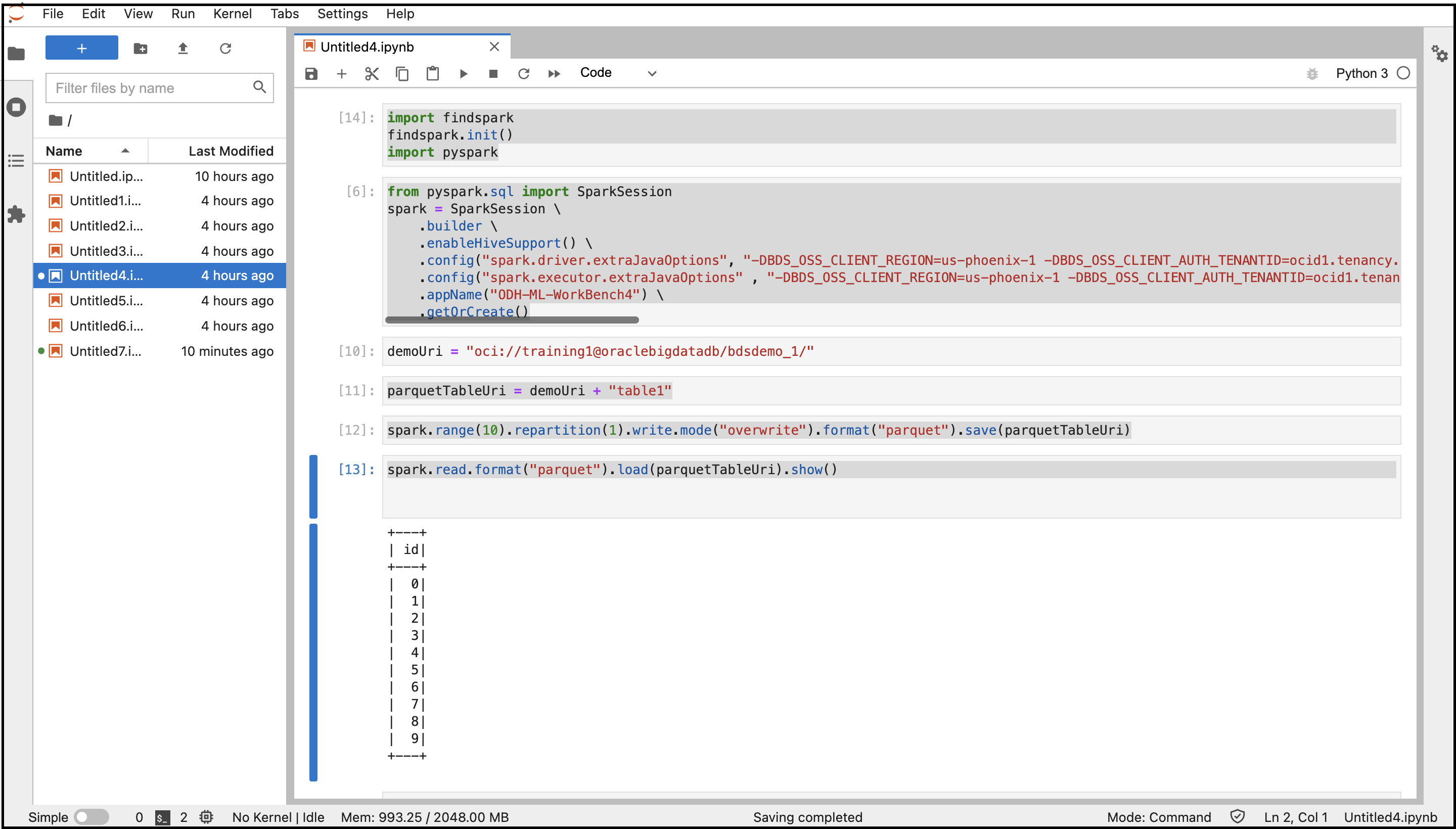
Viene visualizzato l'output del codice. Puoi passare al bucket di storage degli oggetti dalla console e trovare il file creato nel bucket.
Gestire utenti e autorizzazioni
Utilizzare uno dei due metodi di autenticazione per autenticare gli utenti in JupyterHub in modo che possano creare notebook e, facoltativamente, amministrare JupyterHub.
Per impostazione predefinita, i cluster ODH 1.x supportano l'autenticazione nativa. Tuttavia, l'autenticazione per JupyterHub e altri servizi Big Data deve essere gestita in modo diverso. Per generare dinamicamente i notebook utente singolo, l'utente che accede a JupyterHub deve essere presente nell'host Linux e deve disporre delle autorizzazioni per scrivere nella directory radice in HDFS. In caso contrario, il generatore di dati non riesce poiché il processo del notebook viene attivato come utente Linux.
Per informazioni sull'autenticazione nativa, vedere Autenticazione nativa.
Per informazioni sull'autenticazione LDAP per Big Data Service 3.0.26 o versioni precedenti, vedere Autenticazione LDAP.
L'autenticazione nativa dipende dal database degli utenti JupyterHub per l'autenticazione degli utenti.
L'autenticazione nativa si applica sia ai cluster HA che a quelli non HA. Per informazioni dettagliate sull'autenticatore nativo, vedere autenticatore nativo.
Questi prerequisiti devono essere soddisfatti per autorizzare un utente in un cluster HA di Big Data Service utilizzando l'autenticazione nativa.
Questi prerequisiti devono essere soddisfatti per autorizzare un utente in un cluster non HA del servizio Big Data utilizzando l'autenticazione nativa.
Gli utenti amministratori sono responsabili della configurazione e della gestione JupyterHub. Gli utenti amministratori sono inoltre responsabili dell'autorizzazione dei nuovi utenti registrati su JupyterHub.
Prima di aggiungere un utente amministratore, è necessario soddisfare i prerequisiti per un cluster non HA.
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale, in Servizi selezionare JupyterHub.
- Selezionare Config, quindi Configurazioni avanzate.
- Selezionare Advanced jupyterhub-config.
-
Aggiungere un utente di amministrazione a
c.Authenticator.admin_users. - Selezionare Salva.
Prima di aggiungere altri utenti, è necessario soddisfare i prerequisiti per un cluster Big Data Service.
-
L'utente Admin deve accedere a JupyterHub e, dalla nuova opzione di menu, autorizzare gli utenti collegati, autorizzare il nuovo utente.
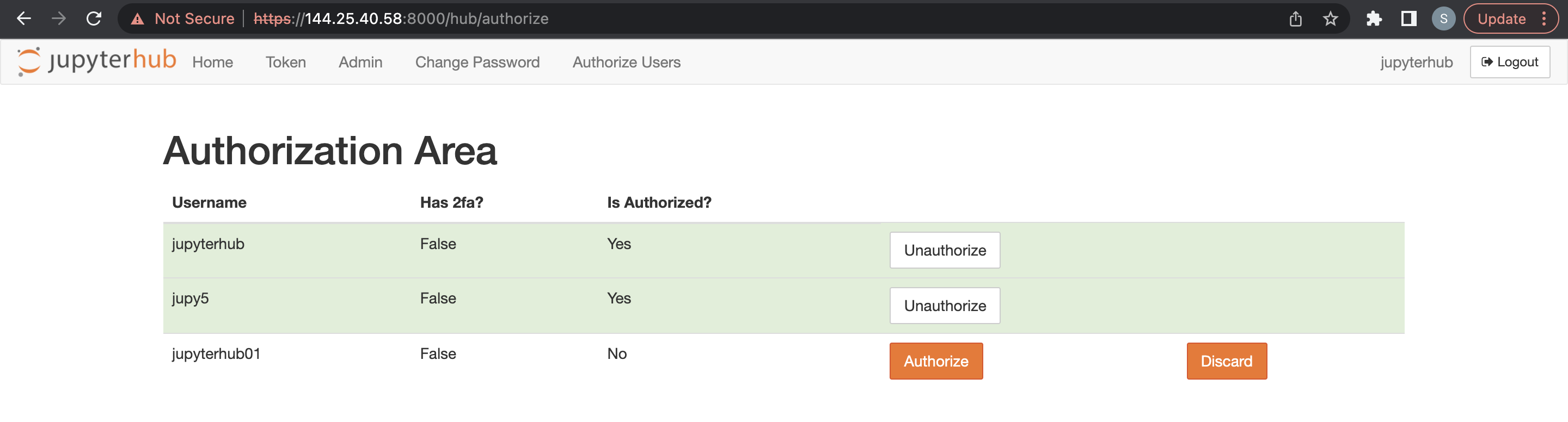
Un utente amministratore può eliminare gli utenti JupyterHub.
- Accedi JupyterHub.
- Aprire File > HubControlPanel.
- Passare alla pagina Autorizza utenti.
- Eliminare gli utenti che si desidera rimuovere.
È possibile utilizzare l'autenticazione LDAP tramite un browser per i cluster Big Data Service 3.0.26 o versioni precedenti di ODH 1.x.
Integra con Trino
- Trino deve essere installato e configurato nel cluster Big Data Service.
- Installare il seguente modulo Python nel nodo JupyterHub (un1 per HA / un0 per cluster non HA) Nota
Ignorare questo passo se il modulo Trino-Python è già presente nel nodo.python3.6 -m pip install trino[sqlalchemy] Offline Installation: Download the required python module in any machine where we have internet access Example: python3 -m pip download trino[sqlalchemy] -d /tmp/package Copy the above folder content to the offline node & install the package python3 -m pip install ./package/* Note : trino.sqlalchemy is compatible with the latest 1.3.x and 1.4.x SQLAlchemy versions. BDS cluster node comes with python3.6 and SQLAlchemy-1.4.46 by default.
Se Trino-Ranger-Plugin è abilitato, assicurarsi di aggiungere l'utente keytab fornito nei rispettivi criteri Trino Ranger. Vedere Integrazione di Trino con Ranger.
Per impostazione predefinita, Trino utilizza come utente il nome principale Kerberos completo. Pertanto, quando si aggiungono/aggiornano i criteri trino-ranger, è necessario utilizzare il nome principale Kerberos completo come nome utente.
Per il seguente esempio di codice, utilizzare jupyterhub@BDSCLOUDSERVICE.ORACLE.COM come utente nei criteri trino-ranger.
Se Trino-Ranger-Plugin è abilitato, assicurarsi di aggiungere l'utente keytab fornito nei rispettivi criteri Trino Ranger. Per ulteriori dettagli, vedere Abilitazione di Ranger per Trino.
Fornire le autorizzazioni Ranger per JupyterHub ai criteri seguenti:
-
all - catalog, schema, table, column -
all - function