Utilizzo di JupyterHub in Big Data Service 3.0.27 o versioni successive
Utilizzare JupyterHub per gestire i notebook ODH 2.x Big Data Service 3.0.27 o versioni successive per gruppi di utenti.
Prerequisiti
Accesso a JupyterHub
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale, in Servizi selezionare JupyterHub.
Gestisci JupyterHub
Un utente JupyterHub admin può eseguire i task riportati di seguito per gestire i notebook in JupyterHub sui nodi ODH 2.x di Big Data Service 3.0.27 o versioni successive.
Per gestire i servizi Oracle Linux 7 con il comando systemctl, vedere Working With System Services.
Per collegarsi a un'istanza di Oracle Cloud Infrastructure, vedere Connessione all'istanza.
L'amministratore può arrestare o disabilitare JupyterHub in modo che non utilizzi risorse, ad esempio la memoria. Il riavvio potrebbe essere utile anche per problemi o comportamenti imprevisti.
Arrestare o avviare JupyterHub tramite Ambari per i cluster Big Data Service 3.0.27 o versioni successive.
L'amministratore può aggiungere il server JupyterHub a un nodo del servizio Big Data.
Questa opzione è disponibile per i cluster Big Data Service 3.0.27 o versioni successive.
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale selezionare Host.
- Per aggiungere il server JupyterHub, selezionare un host in cui JupyterHub non è installato.
- Selezionare Aggiungi.
- Selezionare Server JupyterHub.
L'amministratore può spostare il server JupyterHub in un altro nodo del servizio Big Data.
Questa opzione è disponibile per i cluster Big Data Service 3.0.27 o versioni successive.
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale, in Servizi selezionare JupyterHub.
- Selezionare Azioni, quindi Sposta server JupyterHub.
- Selezionare Next.
- Selezionare l'host in cui spostare il server JupyterHub.
- Completare lo spostamento guidato.
L'amministratore può eseguire i controlli di servizio/integrità JupyterHub tramite Ambari.
Questa opzione è disponibile per i cluster Big Data Service 3.0.27 o versioni successive.
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale, in Servizi selezionare JupyterHub.
- Selezionare Azioni, quindi Esegui controllo servizio.
Gestire utenti e autorizzazioni
Utilizzare uno dei due metodi di autenticazione per autenticare gli utenti in JupyterHub in modo che possano creare notebook e, facoltativamente, amministrare JupyterHub nei cluster ODH 2.x di Big Data Service 3.0.27 o versioni successive.
Gli utenti JupyterHub devono essere aggiunti come utenti del sistema operativo su tutti i nodi del cluster Big Data Service per i cluster Big Data Service non Active Directory (AD), in cui gli utenti non vengono sincronizzati automaticamente su tutti i nodi del cluster. Gli amministratori possono utilizzare lo script JupyterHub User Management per aggiungere utenti e gruppi prima di eseguire l'accesso a JupyterHub.
Requisito
Prima di accedere a JupyterHub, completare le operazioni riportate di seguito.
- Collegamento SSH al nodo in cui è installato JupyterHub.
- Passare a
/usr/odh/current/jupyterhub/install. - Per fornire i dettagli di tutti gli utenti e i gruppi nel file
sample_user_groups.json, eseguire:sudo python3 UserGroupManager.py sample_user_groups.json Verify user creation by executing the following command: id <any-user-name>
Tipi di autenticazione supportati
- NativeAuthenticator: questo authenticator viene utilizzato per le applicazioni JupyterHub di piccole o medie dimensioni. L'iscrizione e l'autenticazione vengono implementate come native per JupyterHub senza fare affidamento su servizi esterni.
-
SSOAuthenticator: questo autenticatore fornisce una sottoclasse di
jupyterhub.auth.Authenticatorche funge da provider di servizi SAML2. Indirizzarlo a un provider di identità SAML2 configurato in modo appropriato e abilita Single Sign-On per JupyterHub.
L'autenticazione nativa dipende dal database degli utenti JupyterHub per l'autenticazione degli utenti.
L'autenticazione nativa si applica sia ai cluster HA che a quelli non HA. Per informazioni dettagliate sull'autenticatore nativo, vedere autenticatore nativo.
Questi prerequisiti devono essere soddisfatti per autorizzare un utente in un cluster HA di Big Data Service utilizzando l'autenticazione nativa.
Questi prerequisiti devono essere soddisfatti per autorizzare un utente in un cluster non HA del servizio Big Data utilizzando l'autenticazione nativa.
Gli utenti amministratori sono responsabili della configurazione e della gestione JupyterHub. Gli utenti amministratori sono inoltre responsabili dell'autorizzazione dei nuovi utenti registrati su JupyterHub.
Prima di aggiungere un utente amministratore, è necessario soddisfare i prerequisiti per un cluster non HA.
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale, in Servizi selezionare JupyterHub.
- Selezionare Config, quindi Configurazioni avanzate.
- Selezionare Advanced jupyterhub-config.
-
Aggiungere un utente di amministrazione a
c.Authenticator.admin_users. - Selezionare Salva.
Prima di aggiungere altri utenti, è necessario soddisfare i prerequisiti per un cluster Big Data Service.
-
L'utente Admin deve accedere a JupyterHub e, dalla nuova opzione di menu, autorizzare gli utenti collegati, autorizzare il nuovo utente.
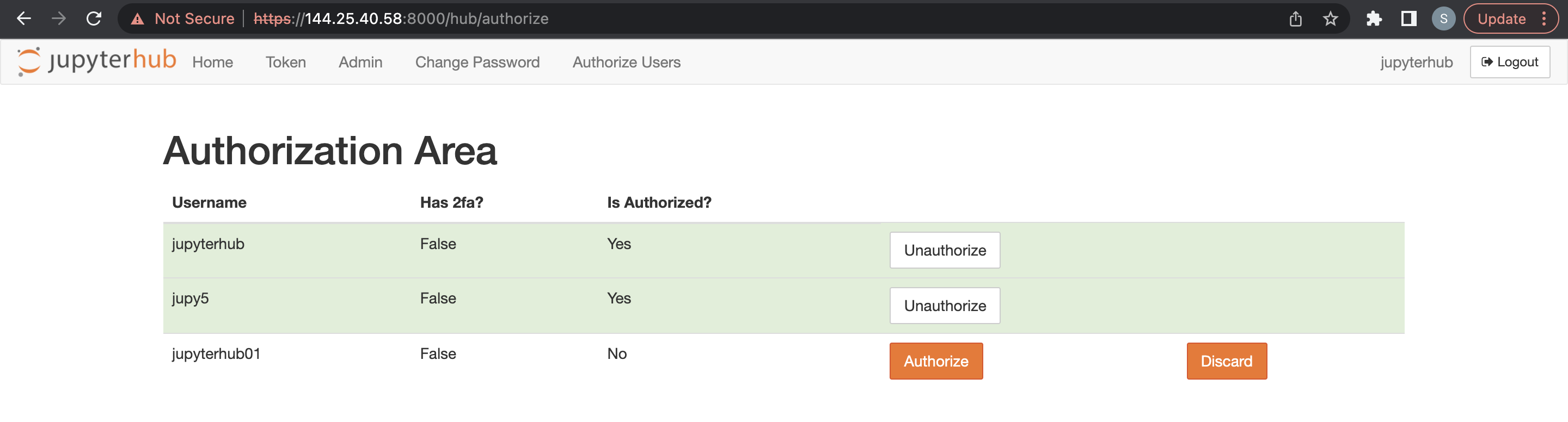
Un utente amministratore può eliminare gli utenti JupyterHub.
- Accedi JupyterHub.
- Aprire File > HubControlPanel.
- Passare alla pagina Autorizza utenti.
- Eliminare gli utenti che si desidera rimuovere.
È possibile utilizzare l'autenticazione LDAP tramite Ambari per i cluster Big Data Service 3.0.27 o versioni successive ODH 2.x.
Uso dell'autenticazione LDAP mediante Ambari
Per utilizzare l'autenticatore LDAP, è necessario aggiornare il file di configurazione JupyterHub con i dettagli di connessione LDAP.
Utilizzare Ambari per l'autenticazione LDAP nei cluster Big Data Service 3.0.27 o versioni successive.
Fare riferimento all'autenticatore LDAP per i dettagli sull'autenticazione LDAP.
pConfigure Autenticazione SSO nel servizio Big Data 3.0.27 o versione successiva del servizio ODH 2.x JupyterHub.
È possibile utilizzare il dominio Oracle Identity per impostare l'autenticazione SSO nei cluster Big Data Service 3.0.27 o versioni successive di ODH 2.x JupyterHub.
È possibile utilizzare OKTA per impostare l'autenticazione SSO nei cluster JupyterHub di Big Data Service 3.0.27 o versioni successive di ODH 2.x.
L'amministratore può gestire le configurazioni JupyterHub tramite Ambari per i cluster Big Data Service 3.0.27 o versioni successive ODH 2.x.
Creazione di blocchi appunti
Le seguenti configurazioni di Spawner sono supportate nei cluster Big Data Service 3.0.27 e versioni successive di ODH 2.x.
Specificare quanto segue:
- Autenticazione nativa:
- Connettersi utilizzando le credenziali utente collegate
- Immettere nome utente.
- Immettere password.
- Utilizzando SamlSSOAuthenticator:
- Accedi con accesso SSO.
- Completare l'accesso con l'applicazione SSO configurata.
Generazione di notebook su un cluster HA
Per il cluster integrato AD:
- Eseguire l'accesso utilizzando uno dei metodi precedenti. L'autorizzazione funziona solo se l'utente è presente sull'host Linux. JupyterHub cerca l'utente sull'host Linux durante il tentativo di generare dinamicamente il server notebook.
- Si viene reindirizzati a una pagina Opzioni server in cui è necessario richiedere un ticket Kerberos. Questo ticket può essere richiesto utilizzando il principal Kerberos e il file keytab o la password Kerberos. L'amministratore del cluster può fornire il nome principale Kerberos e il file keytab o la password Kerberos. Il ticket Kerberos è necessario per accedere alle directory HDFS e ad altri servizi Big Data che si desidera utilizzare.
Generazione di blocchi appunti in un cluster non HA
Per il cluster integrato AD:
Eseguire l'accesso utilizzando uno dei metodi precedenti. L'autorizzazione funziona solo se l'utente è presente sull'host Linux. JupyterHub cerca l'utente sull'host Linux durante il tentativo di generare dinamicamente il server notebook.
- Configurare le chiavi SSH/token di accesso per il nodo cluster Big Data Service.
- Selezionare la modalità di persistenza del notebook come Git.
Per impostare la connessione Git per JupyterHub, completare quanto segue:
- Token di accesso per il nodo cluster del servizio Big Data.
- Selezionare la modalità di persistenza del notebook come Git
Generazione della coppia di chiavi SSH
Uso dei token di accesso
È possibile utilizzare i token di accesso come riportato di seguito.
- GitHub:
- Collegarsi all'account GitHub.
- Passare a Impostazioni > Impostazioni sviluppatore > Token di accesso personale.
- Generare un nuovo token di accesso con le autorizzazioni appropriate.
- Utilizzare il token di accesso come password quando viene richiesta l'autenticazione.
- GitLab:
- Collegarsi all'account GitHub.
- Passare a Impostazioni > Token di accesso.
- Generare un nuovo token di accesso con le autorizzazioni appropriate.
- Utilizzare il token di accesso come password quando viene richiesta l'autenticazione.
- BitBucket:
- Collegarsi all'account BitBucket.
- Passare a Impostazioni > Password applicazione.
- Generare un nuovo token password applicazione con le autorizzazioni appropriate.
- Utilizzare la nuova password dell'applicazione come password quando viene richiesta l'autenticazione.
Selezione della modalità di persistenza come Git
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale, in Servizi selezionare JupyterHub.
- Selezionare Config, quindi Impostazioni.
- Cercare la modalità di persistenza blocco note, quindi selezionare Git dall'elenco a discesa.
- Selezionare Azioni, quindi Riavvia tutto.
- Accedi ad Apache Ambari.
- Nella barra degli strumenti laterale, in Servizi selezionare JupyterHub.
- Selezionare Config, quindi Impostazioni.
- Cercare la modalità di persistenza Notebook, quindi selezionare HDFS dall'elenco a discesa.
- Selezionare Azioni, quindi Riavvia tutto.
Un utente amministratore può memorizzare i singoli notebook utente nello storage degli oggetti anziché in HDFS. Quando si modifica il content manager da HDFS a Object Storage, i notebook esistenti non vengono copiati nello storage degli oggetti. I nuovi notebook vengono salvati nello storage degli oggetti.
Esecuzione del MOUNT del bucket di storage degli oggetti Oracle mediante rclone con l'autenticazione del principal utente
È possibile eseguire il MOUNT dello storage degli oggetti Oracle utilizzando rclone con le chiavi API (User Principal Authentication) su un nodo cluster Big Data Service utilizzando rclone e fuse3, personalizzate per gli utenti JupyterHub.
Gestire gli ambienti Conda in JupyterHub
È possibile gestire gli ambienti Conda nei cluster ODH 2.x di Big Data Service 3.0.28 o versioni successive.
- Crea un ambiente Conda con dipendenze specifiche e crea quattro kernel (Python/PySpark/Spark/SparkR) che puntano all'ambiente Conda creato.
- Gli ambienti e i kernel Conda creati utilizzando questa operazione sono disponibili per tutti gli utenti del server notebook.
- L'operazione di creazione ambiente Conda separata consente di scollegare l'operazione con il riavvio del servizio.
- JupyterHub viene installato tramite l'interfaccia utente di Ambari.
- Verificare l'accesso Internet al cluster per scaricare le dipendenze durante la creazione del Conda.
- Gli ambienti e i kernel Conda creati con questa operazione sono disponibili per tutti gli utenti dei server notebook".
- Fornire:
- Conda configurazioni aggiuntive per evitare errori di creazione Conda. Per ulteriori informazioni, vedere conda create.
- Dipendenze nel formato dei requisiti standard
.txt. - Nome di ambiente Conda inesistente.
- Eliminare manualmente envs o kernel conda.
Questa operazione crea un ambiente Conda con dipendenze specificate e crea il kernel specificato (Python/PySpark/Spark/SparkR) che punta all'ambiente Conda creato.
- Se l'ambiente Conda specificato esiste già, l'operazione passa direttamente al passo di creazione del kernel
- Gli ambienti o i kernel Conda creati utilizzando questa operazione sono disponibili solo per un utente specifico
- Eseguire manualmente lo script python
kernel_install_script.pyin modalità sudo:'/var/lib/ambari-server/resources/mpacks/odh-ambari-mpack-2.0.8/stacks/ODH/1.1.12/services/JUPYTER/package/scripts/'Ad esempio:
sudo python kernel_install_script.py --conda_env_name conda_jupy_env_1 --conda_additional_configs '--override-channels --no-default-packages --no-pin -c pytorch' --custom_requirements_txt_file_path ./req.txt --kernel_type spark --kernel_name spark_jupyterhub_1 --user jupyterhub
Prerequisiti
- Verificare l'accesso Internet al cluster per scaricare le dipendenze durante la creazione del Conda. In caso contrario, la creazione non riesce.
- Se esiste un kernel denominato
--kernel_name, viene restituita un'eccezione. - Fornire i seguenti dati:
- Configurazioni Conda per evitare errori di creazione. Per ulteriori informazioni, vedere https://conda.io/projects/conda/en/latest/commands/create.html.
- Dipendenze fornite nel formato dei requisiti standard
.txt.
- Eliminare manualmente envs o kernel conda per qualsiasi utente.
Configurazioni disponibili per la personalizzazione
-
--user(obbligatorio): utente OS e JupyterHub per il quale vengono creati kernel e ambiente conda. -
--conda_env_name(obbligatorio): fornire un nome univoco per l'ambiente Conda ogni volta che viene creato un nuovo en per--user. -
--kernel_name: (obbligatorio) Fornire un nome kernel univoco. -
--kernel_type: (obbligatorio) deve essere uno dei seguenti (python / PysPark / Spark / SparkR) -
--custom_requirements_txt_file_path: (facoltativo) Se qualsiasi Python/R/Ruby/Lua/Scala/Java/JavaScript/C/C++/FORTRAN e così via, le dipendenze vengono installate utilizzando canali Conda, è necessario specificare tali librerie in un file.txtdei requisiti e fornire il percorso completo.Per ulteriori informazioni su un formato standard per la definizione del file
.txtdei requisiti, vedere https://pip.pypa.io/en/stable/reference/requirements-file-format/. -
--conda_additional_configs: (facoltativo)- Questo campo fornisce parametri aggiuntivi da aggiungere al comando di creazione Conda predefinito.
- Il comando di creazione Conda predefinito è:
'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8'. - Se
--conda_additional_configsviene fornito come'--override-channels --no-default-packages --no-pin -c pytorch', l'esecuzione finale del comando di creazione del Conda è'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8 --override-channels --no-default-packages --no-pin -c pytorch'.
Impostazione di un ambiente Conda specifico dell'utente
Creare un load balancer e un set backend
Per ulteriori informazioni sulla creazione dei set backend, vedere Creazione di un set backend del load balancer.
Per ulteriori informazioni sulla creazione di un load balancer pubblico, vedere Creazione di un load balancer e completare i dettagli riportati di seguito.
Per ulteriori informazioni sulla creazione di un load balancer pubblico, vedere Creazione di un load balancer e completare i dettagli riportati di seguito.
- Aprire il menu di navigazione, selezionare Networking e quindi Load balancer. Selezionare Load balancer. Viene visualizzata la pagina Load balancer.
- Selezionare il compartimento dalla lista. Tutti i load balancer in tale compartimento sono elencati in formato di tabella.
- Selezionare il load balancer a cui si desidera aggiungere un backend. Viene visualizzata la pagina dei dettagli del load balancer.
- Selezionare Set backend, quindi selezionare il set backend creato in Creazione del load balancer.
- Selezionare gli indirizzi IP, quindi immettere l'indirizzo IP privato richiesto del cluster.
- Immettere 8000 per la porta.
- Selezionare Aggiungi.
Per ulteriori informazioni sulla creazione di un load balancer pubblico, vedere Creazione di un load balancer e completare i dettagli riportati di seguito.
-
Aprire un browser e immettere
https://<loadbalancer ip>:8000. - Selezionare il compartimento dalla lista. Tutti i load balancer in tale compartimento sono elencati in formato di tabella.
- Assicurarsi che venga eseguito il reindirizzamento a uno dei server JupyterHub. Per verificare, aprire una sessione terminale sul JupyterHub per trovare il nodo raggiunto.
- Dopo l'operazione di aggiunta del nodo, l'amministratore del cluster deve aggiornare manualmente la voce host del load balancer nei nodi appena aggiunti. Applicabile a tutte le aggiunte nodo al cluster. Ad esempio, nodo di lavoro, solo calcolo e nodi.
- In caso di scadenza, il certificato deve essere aggiornato manualmente al load balancer. Questo passo garantisce che il load balancer non utilizzi certificati obsoleti ed evita errori di controllo dello stato/comunicazione nei set backend. Per ulteriori informazioni, vedere Aggiornamento di un certificato load balancer in scadenza per aggiornare il certificato scaduto.
Avvia Trino-SQL Kernels
Il kernel JupyterHub PyTrino fornisce un'interfaccia SQL che consente di eseguire query Trino utilizzando JupyterHub SQL. È disponibile per i cluster ODH 2.x Big Data Service 3.0.28 o versioni successive.
Per ulteriori informazioni sui parametri SqlMagic, vedere https://jupysql.ploomber.io/en/latest/api/configuration.html#changing-configuration.