Utilizzo di JupyterHub con i notebook
JupyterHub consente a più utenti di lavorare insieme fornendo un singolo server notebook Jupyter per ogni utente. Quando si crea un cluster Big Data Service, JupyterHub viene installato e configurato sui nodi del cluster.
Nota
JupyterHub è disponibile solo nei cluster Big Data Service 3.0.7 e versioni successive.
Per informazioni specifiche sui cluster ODH 1.x o versioni precedenti di Big Data Service 3.0.26, vedere Uso di JupyterHub in Big Data Service 3.0.26 o versioni precedenti.
Per informazioni specifiche sui cluster ODH 2.x o versione successiva di Big Data Service 3.0.27, vedere Using JupyterHub in Big Data Service 3.0.27 or Later.
Avvio di Kernels ed esecuzione di job Spark
- Accedi a JupyterHub.
- Aprire un notebook server. Si viene reindirizzati alla pagina Launcher.
- È possibile aprire uno dei diversi kernel disponibili per impostazione predefinita, ad esempio Python, PySpark, Spark e SparkR. Per avviare un blocco note, selezionare File > Nuovo > Notebook, quindi selezionare Seleziona kernel o selezionare l'icona corrispondente in Blocco appunti.
Codice di esempio per il kernel Python:
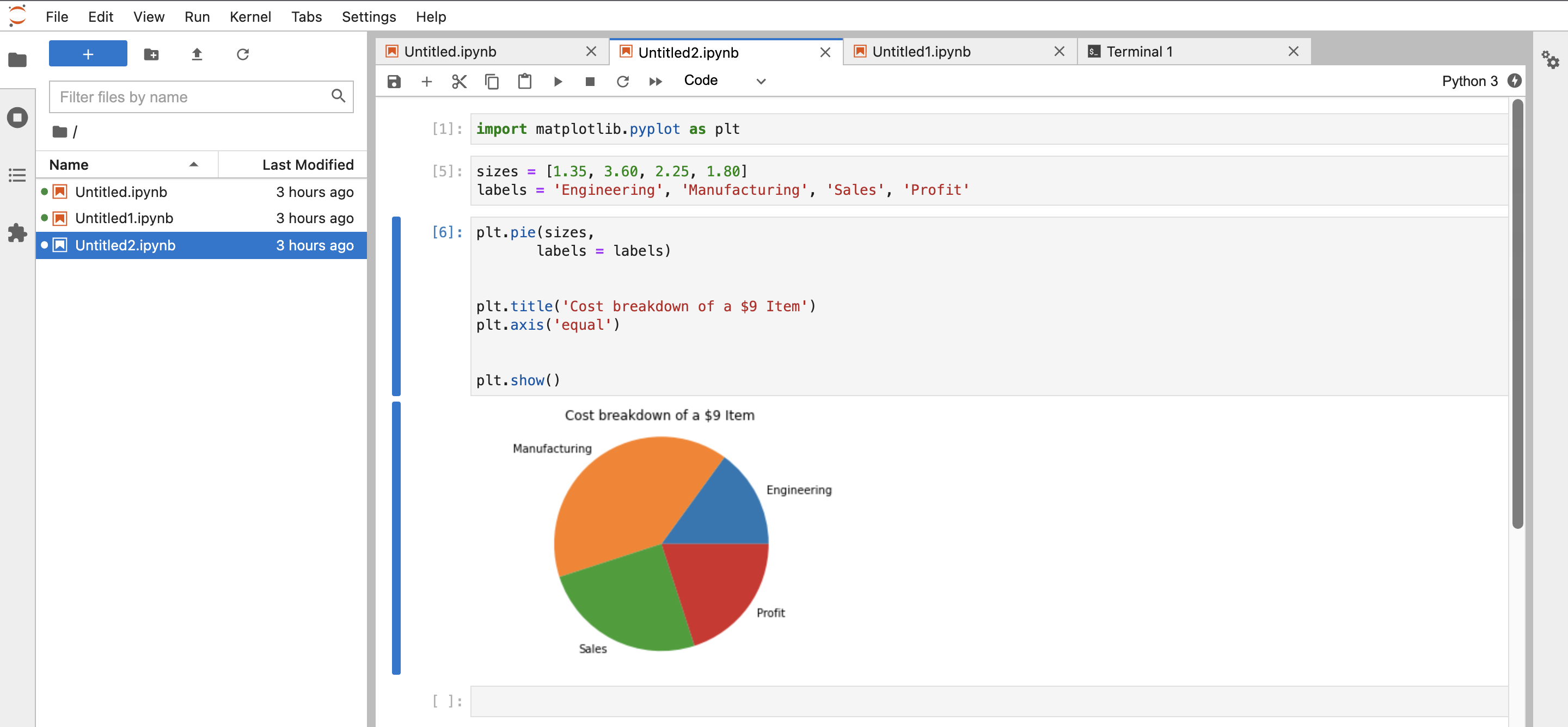
Codice di esempio per Sparkmagic nel kernel PySpark