Introduzione a Oracle Cloud Infrastructure Data Flow
Questa esercitazione ti presenta Oracle Cloud Infrastructure Data Flow, un servizio che ti consente di eseguire qualsiasi applicazione Spark Apache su qualsiasi scala senza alcuna infrastruttura da distribuire o gestire.
Se hai già utilizzato Spark, otterrai di più da questa esercitazione, ma non sono necessarie conoscenze Spark precedenti. Tutte le applicazioni e i dati Spark sono stati forniti per te. Questa esercitazione descrive in che modo Data Flow rende l'esecuzione delle applicazioni Spark facile, ripetibile, sicura e semplice da condividere in tutta l'azienda.
- Come utilizzare Java per eseguire ETL in un'applicazione di Data Flow.
- Come utilizzare SparkSQL in un'applicazione SQL.
- Come creare ed eseguire un'applicazione Python per eseguire un semplice task di Machine Learning.
Puoi anche eseguire questa esercitazione utilizzando spark-submit da CLI o utilizzando spark-submit e Java SDK.
- È serverless, il che significa che non hai bisogno di esperti per eseguire il provisioning, applicare patch, aggiornare o gestire i cluster Spark. Ciò significa che ti concentri sul tuo codice Spark e nient'altro.
- Ha operazioni e tuning semplici. L'accesso all'interfaccia utente di Spark è di sola selezione ed è regolato dai criteri di autorizzazione IAM. Se un utente si lamenta che un job è troppo lento, chiunque abbia accesso all'esecuzione può aprire l'interfaccia utente di Spark e arrivare alla causa principale. L'accesso al server della cronologia Spark è semplice per i job già eseguiti.
- È ottimo per l'elaborazione in batch. L'output dell'applicazione viene acquisito e reso disponibile automaticamente dalle API REST. È necessario eseguire un job Spark SQL di quattro ore e caricare i risultati nel sistema di gestione della pipeline? In Data Flow, mancano solo due chiamate API REST.
- Ha un controllo consolidato. Data Flow offre una vista consolidata di tutte le applicazioni Spark, chi le sta eseguendo e quanto consumano. Vuoi sapere quali applicazioni stanno scrivendo più dati e chi li sta eseguendo? Ordina semplicemente in base alla colonna Dati scritti. Un job è in esecuzione da troppo tempo? Chiunque disponga delle autorizzazioni IAM corrette può visualizzare il job e arrestarlo.
Informazioni preliminari
Per eseguire correttamente questa esercitazione, è necessario disporre di Imposta tenancy e di Accedi a Data Flow.
Per poter eseguire Data Flow, è necessario concedere autorizzazioni che consentano un'acquisizione e una gestione efficaci dei log. Vedere la sezione Imposta amministrazione del manuale Data Flow Service Guide e seguire le istruzioni fornite.
- Dalla console, selezionare il menu di navigazione per visualizzare la lista dei servizi disponibili.
- Selezionare Analytics e AI.
- In Big Data selezionare Flusso di dati.
- Selezionare Applicazioni.
1. ETL con Java
Esercitazione per imparare a creare un'applicazione Java in Data Flow
I passi riportati di seguito consentono di utilizzare l'interfaccia utente della console. Puoi completare questo esercizio utilizzando spark-submit dall'interfaccia CLI o spark-submit con Java SDK.
Il primo passo più comune nelle applicazioni di elaborazione dei dati è quello di prendere i dati da qualche fonte e metterli in un formato adatto per il reporting e altre forme di analisi. In un database è possibile caricare un file sequenziale nel database e creare indici. In Spark, il primo passo è pulire e convertire i dati da un formato di testo in formato Parquet. Parquet è un formato binario ottimizzato che supporta letture efficienti, rendendolo ideale per il reporting e l'analisi. In questo esercizio, prendi i dati di origine, convertili in Parquet e poi fai alcune cose interessanti con esso. Il set di dati è il set di dati di Berlino Airbnb, scaricato dal sito Web Kaggle sotto i termini della licenza Creative Commons CC0 1.0 Universal (CC0 1.0) "Public Domain Dedication".

I dati vengono forniti in formato CSV e il primo passo è convertire questi dati in Parquet e memorizzarli nell'area di memorizzazione degli oggetti per l'elaborazione a valle. Per eseguire questa conversione viene fornita un'applicazione Spark, denominata oow-lab-2019-java-etl-1.0-SNAPSHOT.jar. L'obiettivo è creare un'applicazione di flusso dati che esegua questa applicazione Spark ed eseguirla con i parametri corretti. Poiché si sta iniziando, questo esercizio guida passo dopo passo e fornisce i parametri necessari. Successivamente devi fornire i parametri da solo, quindi devi capire cosa stai entrando e perché.
Crea un'applicazione Java di Data Flow dalla console o con Spark-submit dalla riga di comando o utilizzando l'SDK.
Creare un'applicazione Java in Data Flow dalla console.
Creare un'applicazione Data Flow.
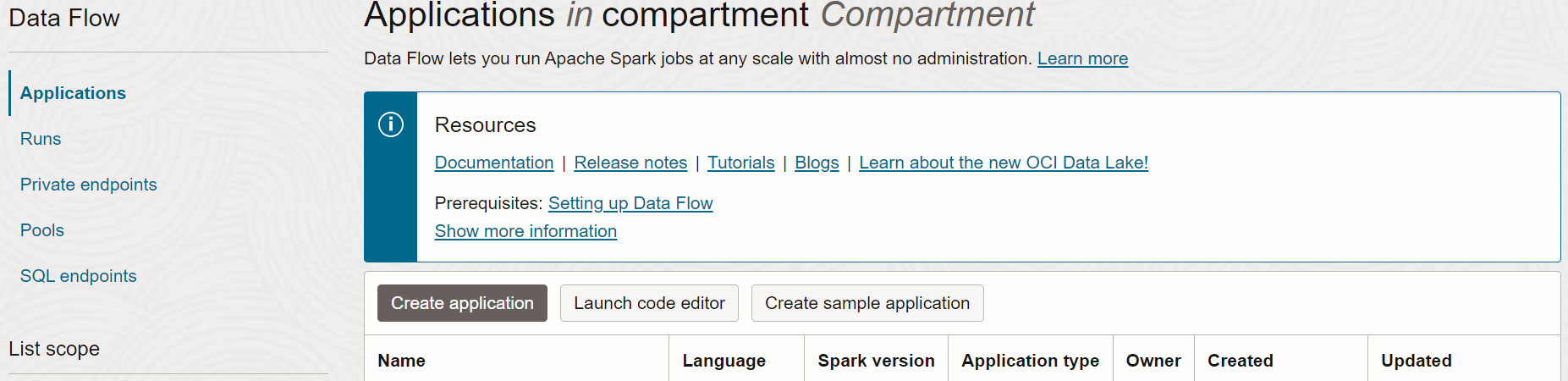
- Andare al servizio Flusso dati nella console espandendo il menu hamburger in alto a sinistra e scorrendo verso il basso.
- Evidenziare Data Flow, quindi selezionare Applicazioni. Selezionare un compartimento in cui si desidera creare le applicazioni di Data Flow. Infine, selezionare Crea applicazione.
- Selezionare Applicazione Java e immettere un nome per l'applicazione, ad esempio
Tutorial Example 1.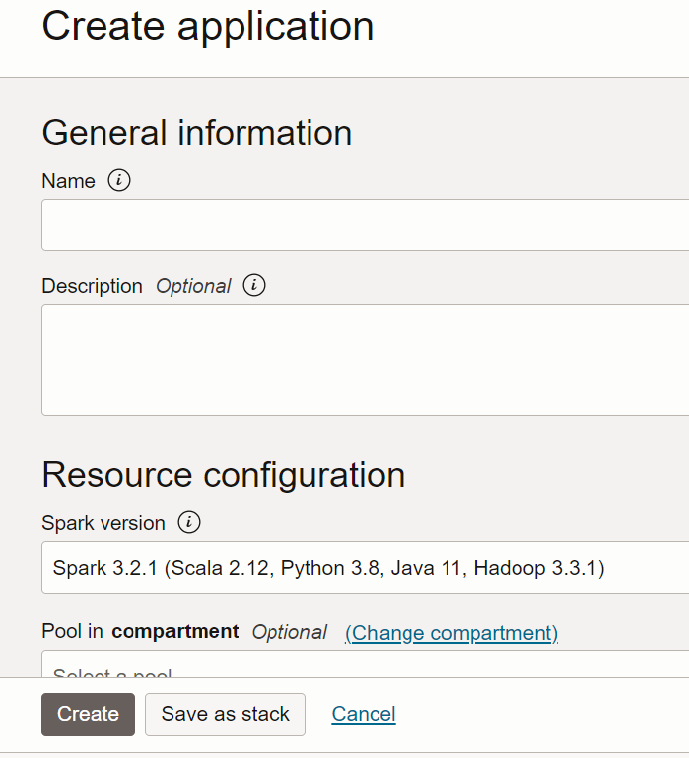
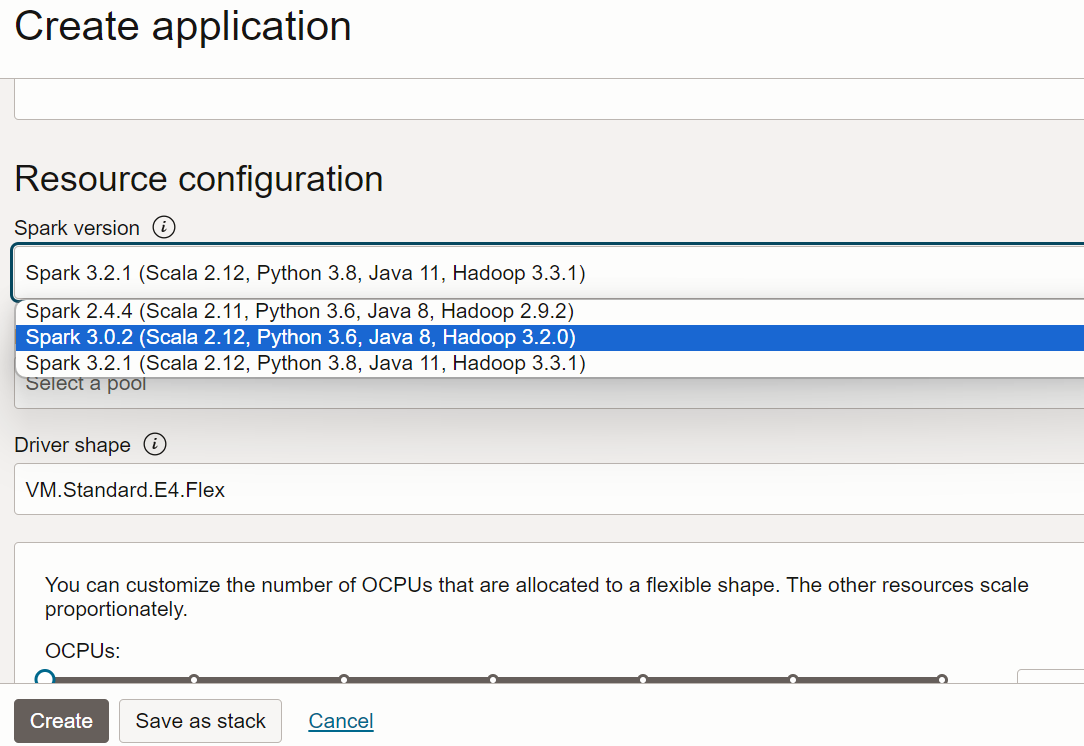
- Scorrere fino a Configurazione risorsa. Lasciare l'impostazione predefinita per tutti questi valori.
- Scorrere fino a Configurazione applicazione. Configurare l'applicazione come indicato di seguito.
-
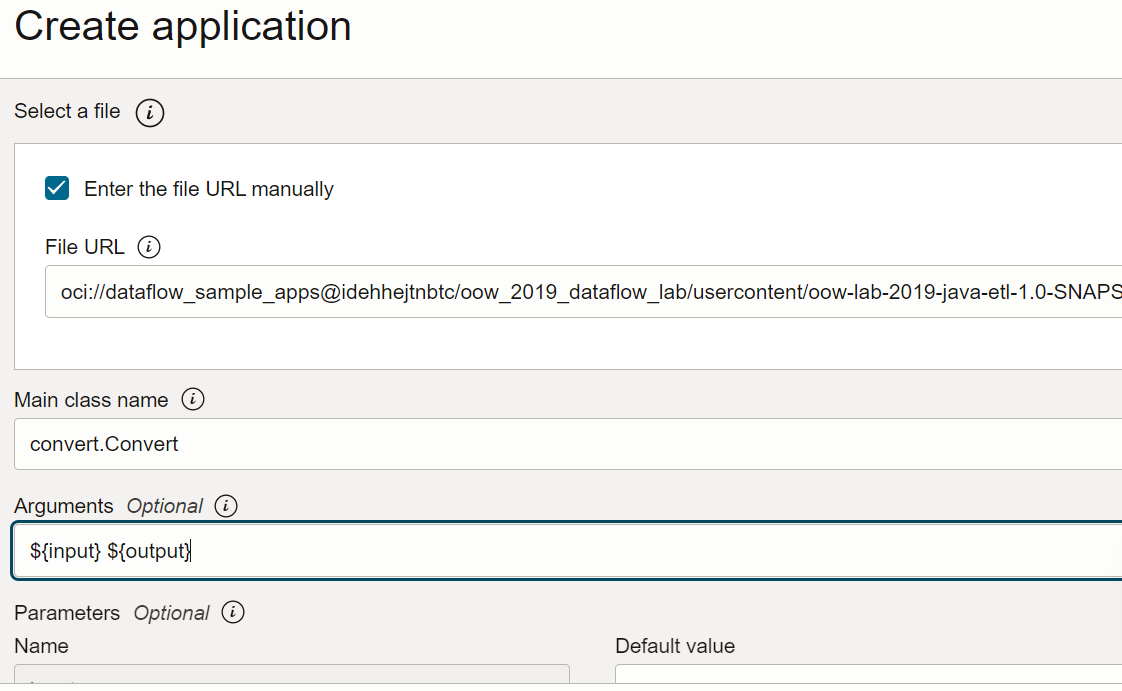
URL file: la posizione del file JAR nello storage degli oggetti. La posizione per questa applicazione è:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar -
Nome classe principale: le applicazioni Java richiedono un nome classe principale che dipende dall'applicazione. Per questo esercizio, inserire
convert.Convert -
Argomenti: l'applicazione Spark prevede due parametri della riga di comando, uno per l'input e uno per l'output. Nel campo Argomenti immettere Viene richiesto di immettere i valori predefiniti. È consigliabile immetterli ora.
${input} ${output}
-
URL file: la posizione del file JAR nello storage degli oggetti. La posizione per questa applicazione è:
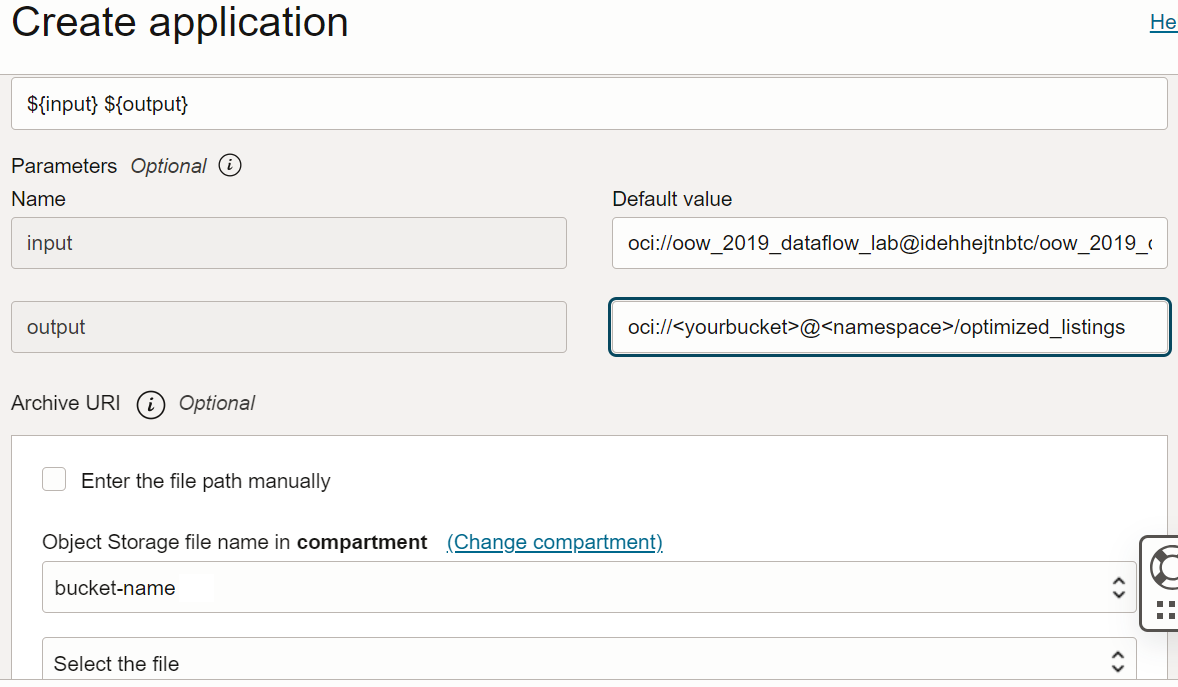
- Gli argomenti di input e output sono:
-
Input:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv -
Output:
oci://<yourbucket>@<namespace>/optimized_listings
Verificare che la configurazione dell'applicazione sia simile a quella indicata di seguito.
 Nota
Nota
È necessario personalizzare il percorso di output in modo che punti a un bucket nel tenant. -
Input:
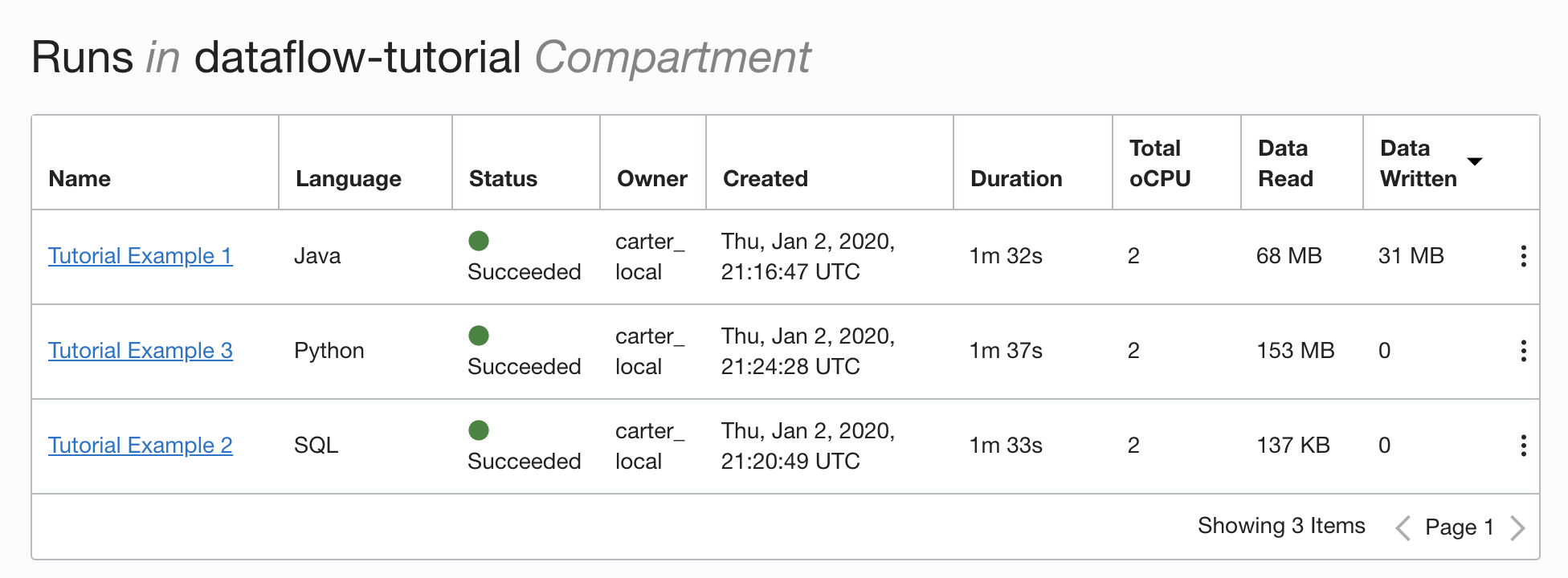
- Al termine, selezionare Crea. Quando l'applicazione viene creata, viene visualizzata nell'elenco Applicazione.
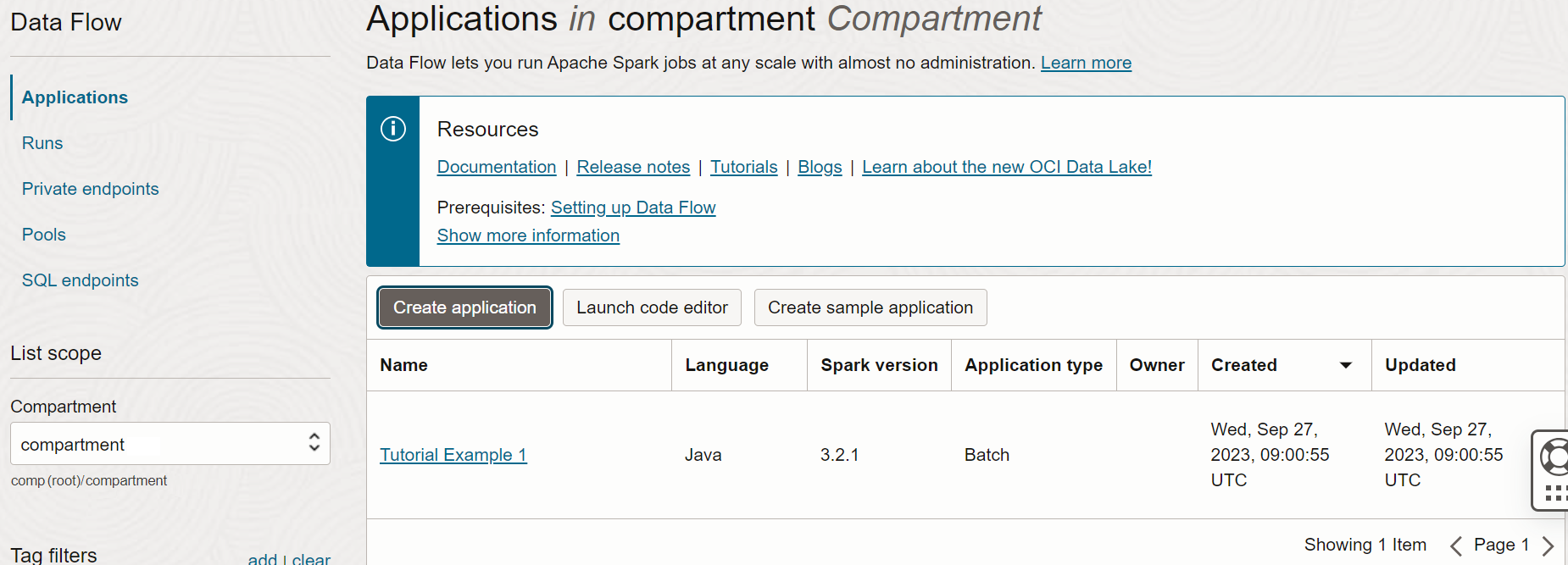
Complimenti. La prima applicazione di flusso dati è stata creata. Ora è possibile eseguirlo.
Utilizza spark-submit e CLI per creare un'applicazione Java.
Completa l'esercitazione per creare un'applicazione Java in Data Flow utilizzando spark-submit e Java SDK.
Questi sono i file per eseguire questo esercizio e sono disponibili nei seguenti URI di storage degli oggetti pubblici:
- File di input in formato CSV:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - File JAR:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Dopo aver creato un'applicazione Java, è possibile eseguirla.
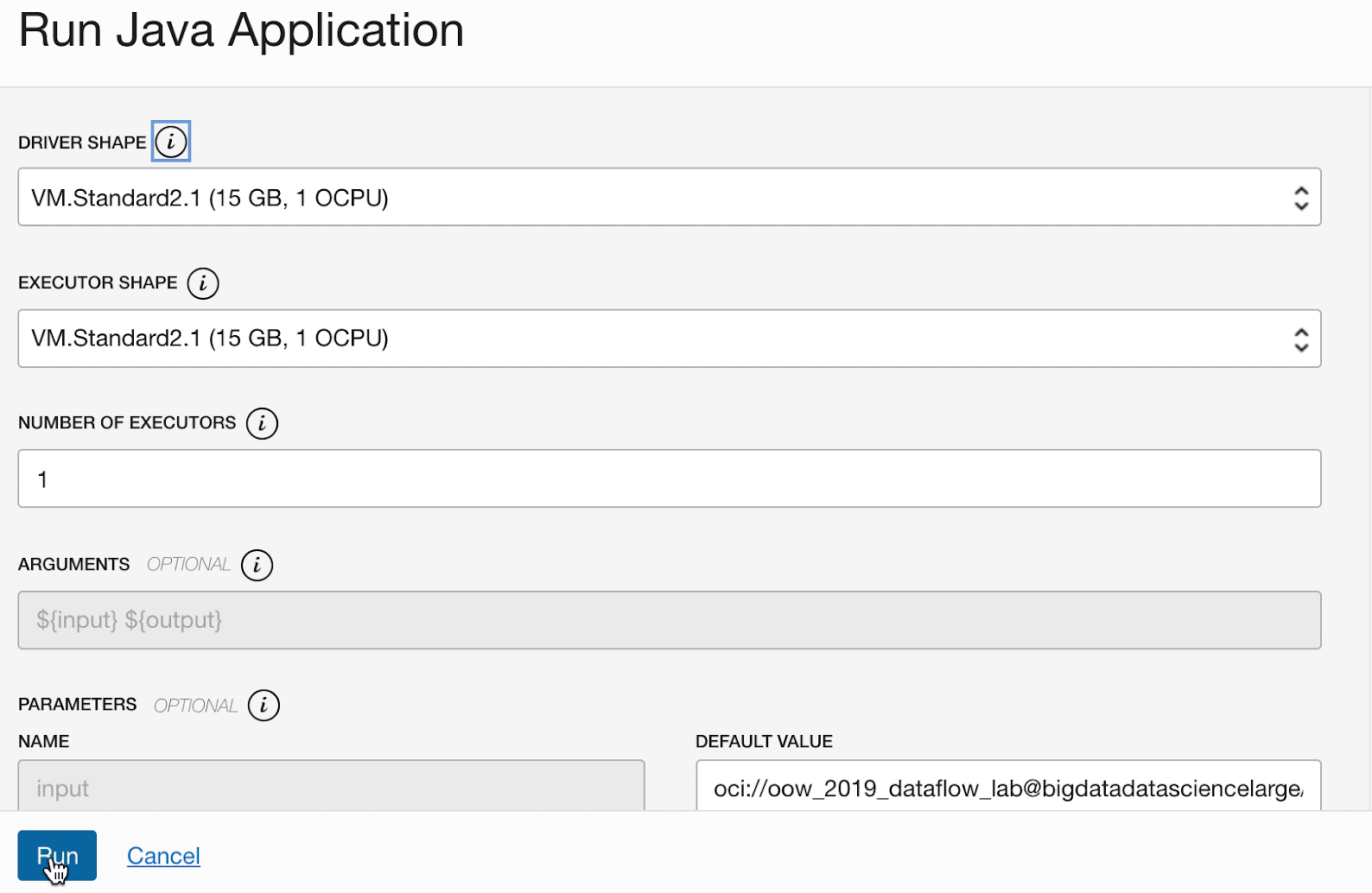
- Se i passi sono stati eseguiti con precisione, è sufficiente evidenziare l'applicazione nell'elenco, selezionare il menu Azioni e selezionare Esegui.
- È possibile personalizzare i parametri prima di eseguire l'applicazione. Nel tuo caso, hai inserito i valori precisi in anticipo e puoi iniziare a eseguire facendo clic su Esegui.
-
Durante l'esecuzione dell'applicazione, è possibile caricare facoltativamente l'interfaccia utente di Spark per monitorare lo stato di avanzamento. Dal menu Azioni per l'esecuzione in questione, selezionare Interfaccia utente Spark.
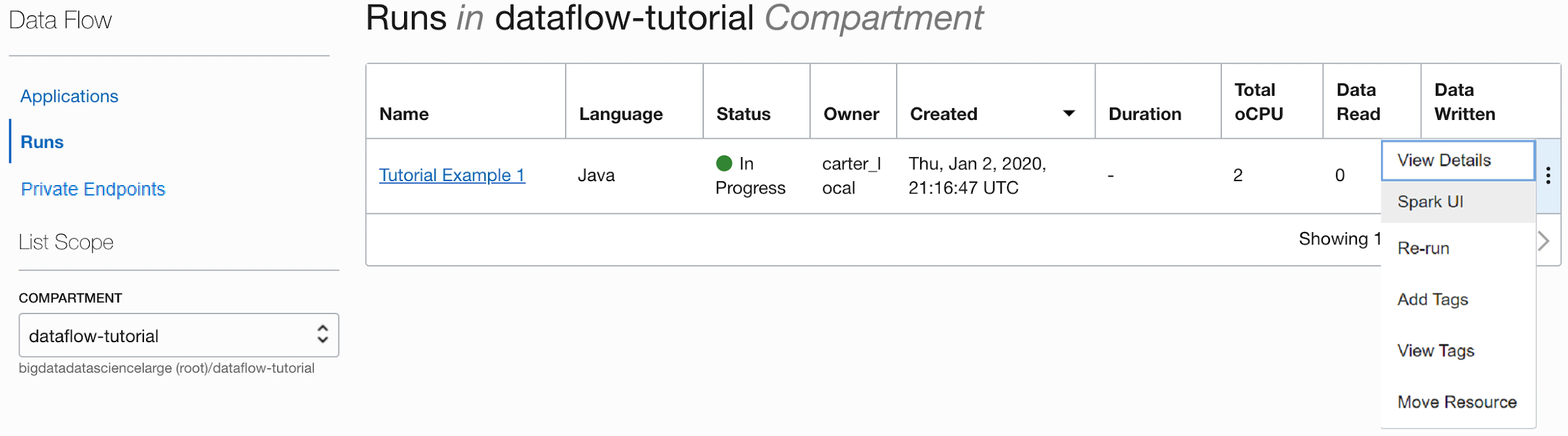
- Si viene reindirizzati automaticamente all'interfaccia utente di Apache Spark, utile per il debug e l'ottimizzazione delle prestazioni.
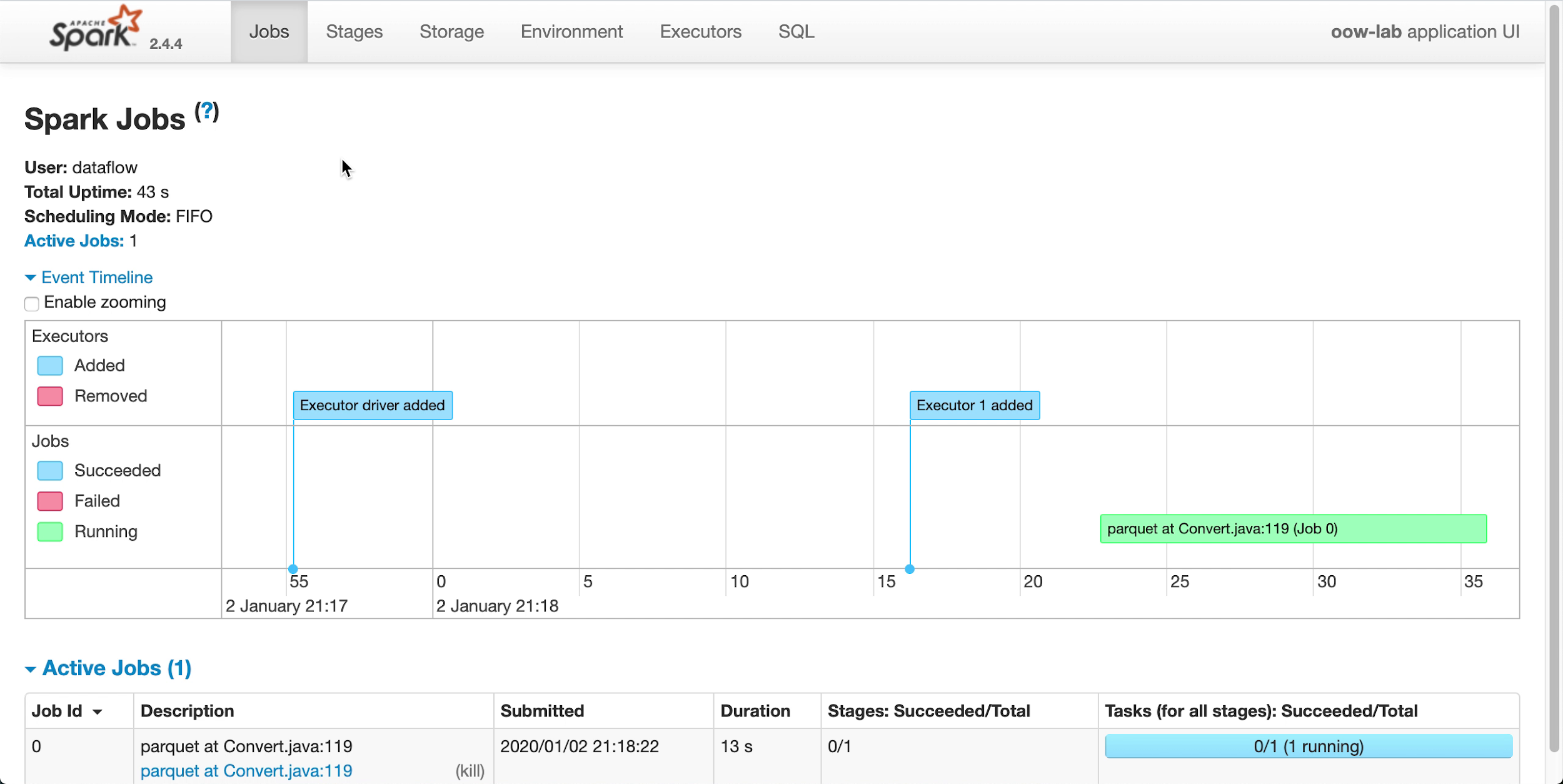
-
Dopo circa un minuto in Esegui viene visualizzato il completamento riuscito con lo stato
Succeeded:
-
Eseguire il drill-down dell'esecuzione per visualizzare ulteriori dettagli e scorrere fino alla parte inferiore per visualizzare un elenco di log.

-
Quando si seleziona il file spark_application_stdout.log.gz, viene visualizzato l'output del log,
Conversion was successful:
- Inoltre, puoi passare al bucket di storage degli oggetti di output per confermare che i nuovi file sono stati creati.
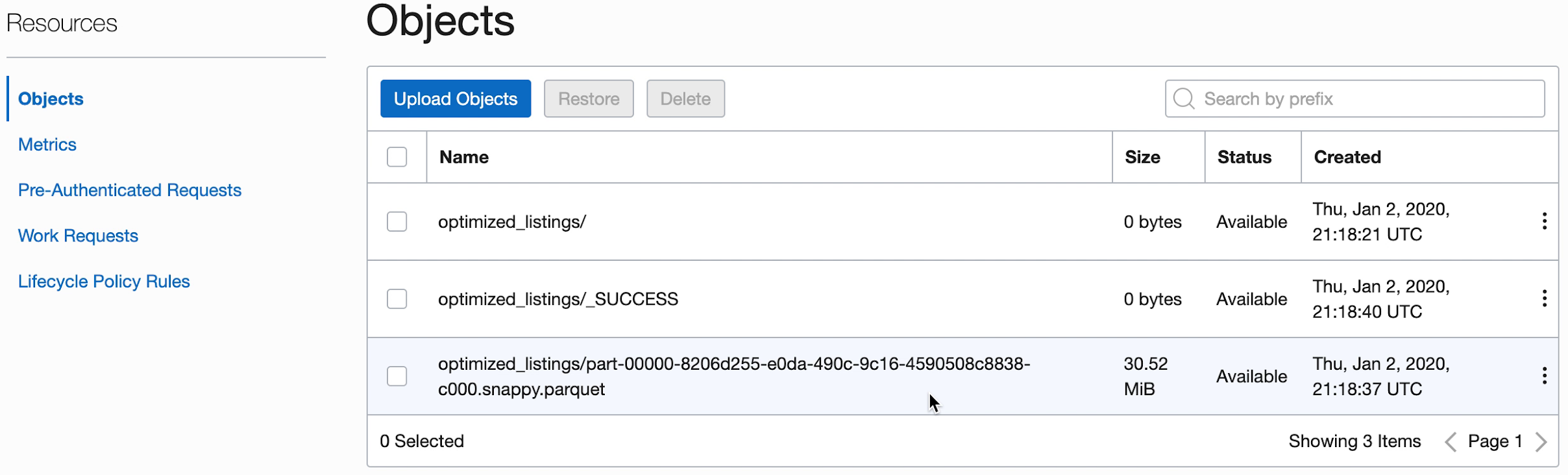
Questi nuovi file vengono utilizzati da applicazioni successive. Assicurati di poterli vedere nel tuo secchio prima di passare agli esercizi successivi.
2. SparkSQL semplificato
In questo esercizio viene eseguito uno script SQL per eseguire il profiling di base di un data set.
Questo esercizio utilizza l'output generato in 1. ETL con Java. Devi averlo completato con successo prima di poter provare questo.
I passi riportati di seguito consentono di utilizzare l'interfaccia utente della console. Puoi completare questo esercizio utilizzando spark-submit dall'interfaccia CLI o spark-submit con Java SDK.
Come con altre applicazioni di flusso dati, i file SQL vengono memorizzati nello storage degli oggetti e potrebbero essere condivisi tra molti utenti SQL. A tale scopo, Data Flow consente di parametrizzare gli script SQL e personalizzarli in fase di esecuzione. Come con altre applicazioni, è possibile fornire valori predefiniti per i parametri che spesso fungono da preziosi indizi per chi esegue questi script.
Lo script SQL è disponibile per l'uso direttamente nell'applicazione Data Flow. Non è necessario crearne una copia. La sceneggiatura è qui riprodotta per illustrare alcuni punti.
Testo di riferimento dello script SparkSQL: 
- Lo script inizia creando le tabelle SQL necessarie. Attualmente, Data Flow non dispone di un catalogo SQL persistente, pertanto tutti gli script devono iniziare definendo le tabelle necessarie.
- La posizione della tabella è impostata su
${location}Si tratta di un parametro che l'utente deve fornire in fase di esecuzione. In questo modo, Data Flow ha la flessibilità di utilizzare uno script per elaborare più posizioni diverse e condividere il codice tra utenti diversi. Per questo laboratorio, dobbiamo personalizzare${location}per puntare alla posizione di output che abbiamo usato nell'Esercizio 1 - Come vedremo, l'output dello script SQL viene acquisito e reso disponibile sotto l'Esegui.
- In Flusso dati creare un'applicazione SQL, selezionare SQL come tipo e accettare le risorse predefinite.
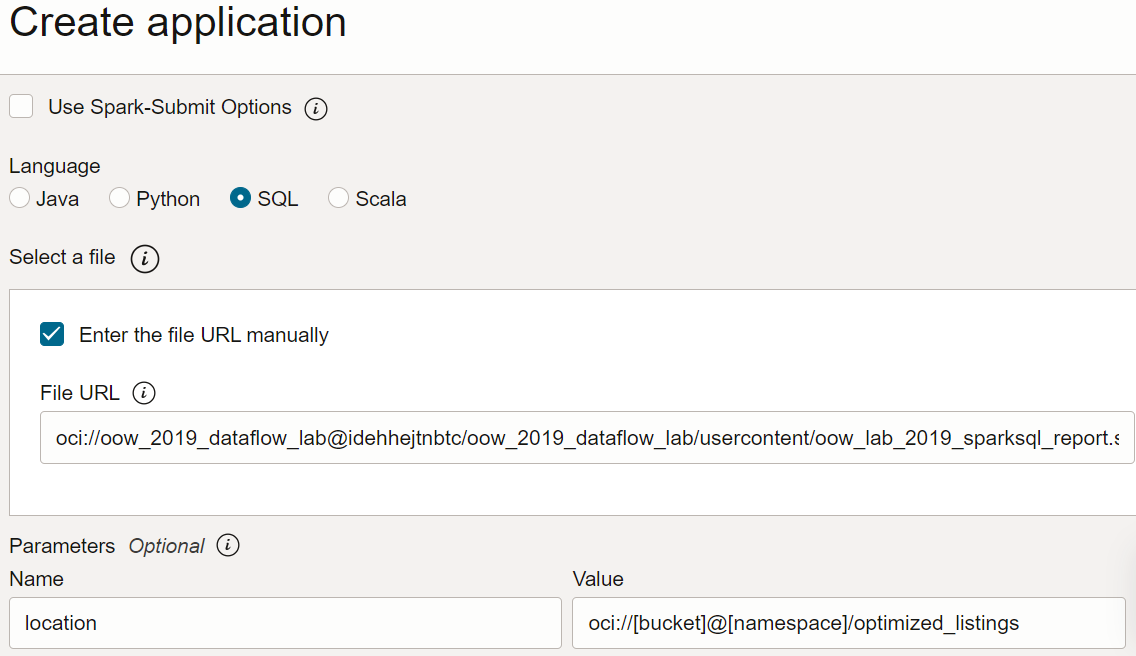
- In Configurazione applicazione, configurare l'applicazione SQL come indicato di seguito.
-
URL file: la posizione del file SQL nello storage degli oggetti. La posizione per questa applicazione è:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql -
Argomenti: lo script SQL prevede un parametro, ovvero la posizione dell'output del passo precedente. Selezionare Aggiungi parametro e immettere un parametro denominato
locationcon il valore utilizzato come percorso di output nel passo a, in base al modellooci://[bucket]@[namespace]/optimized_listings
Al termine, verificare che la configurazione dell'applicazione abbia un aspetto simile al seguente:
-
URL file: la posizione del file SQL nello storage degli oggetti. La posizione per questa applicazione è:
- Personalizzare il valore della posizione in un percorso valido nella tenancy.
- Salvare l'applicazione ed eseguirla dalla lista Applicazioni.
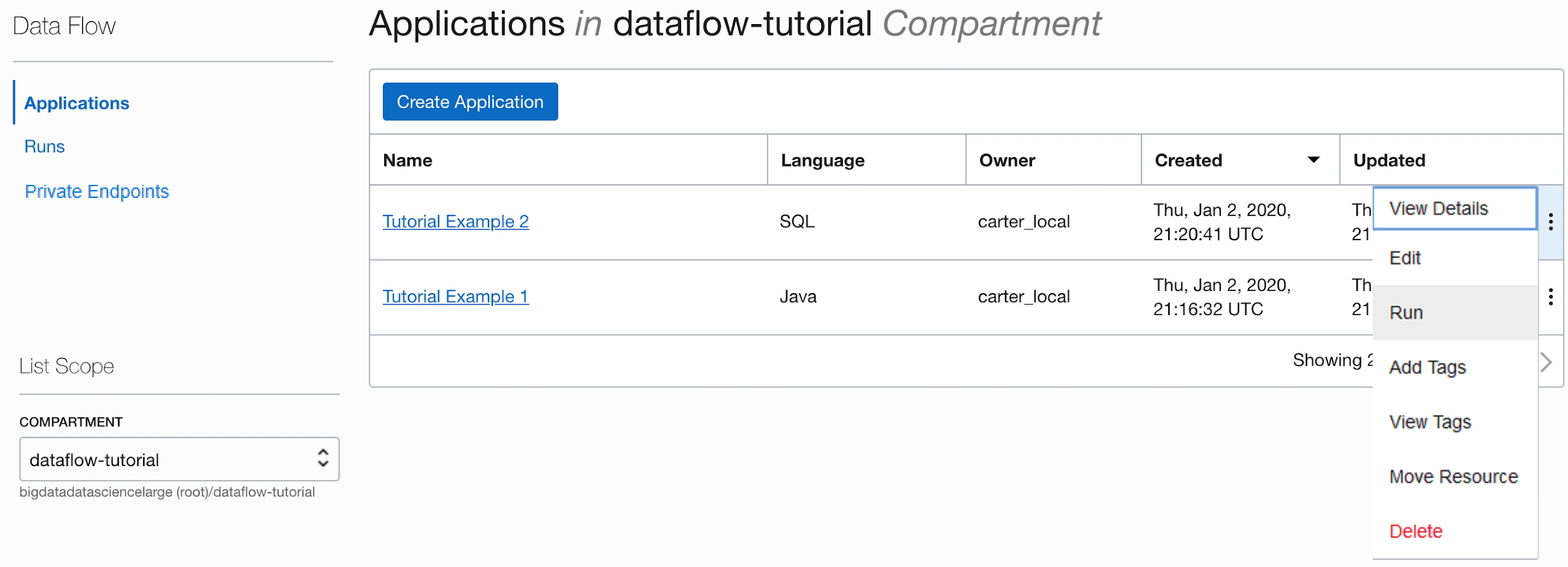
- Al termine dell'esecuzione, aprire l'esecuzione:
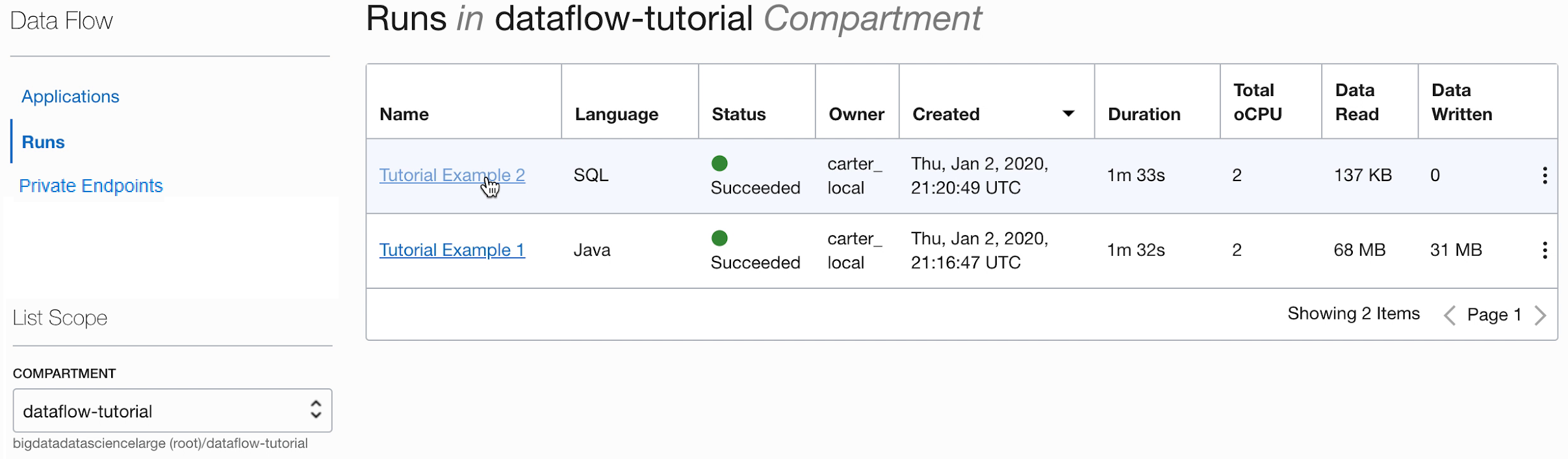
- Passare ai log di esecuzione:

- Aprire spark_application_stdout.log.gz e verificare che l'output sia conforme all'output riportato di seguito. Nota
Le righe potrebbero essere in un ordine diverso da quello dell'immagine, ma i valori devono essere in linea.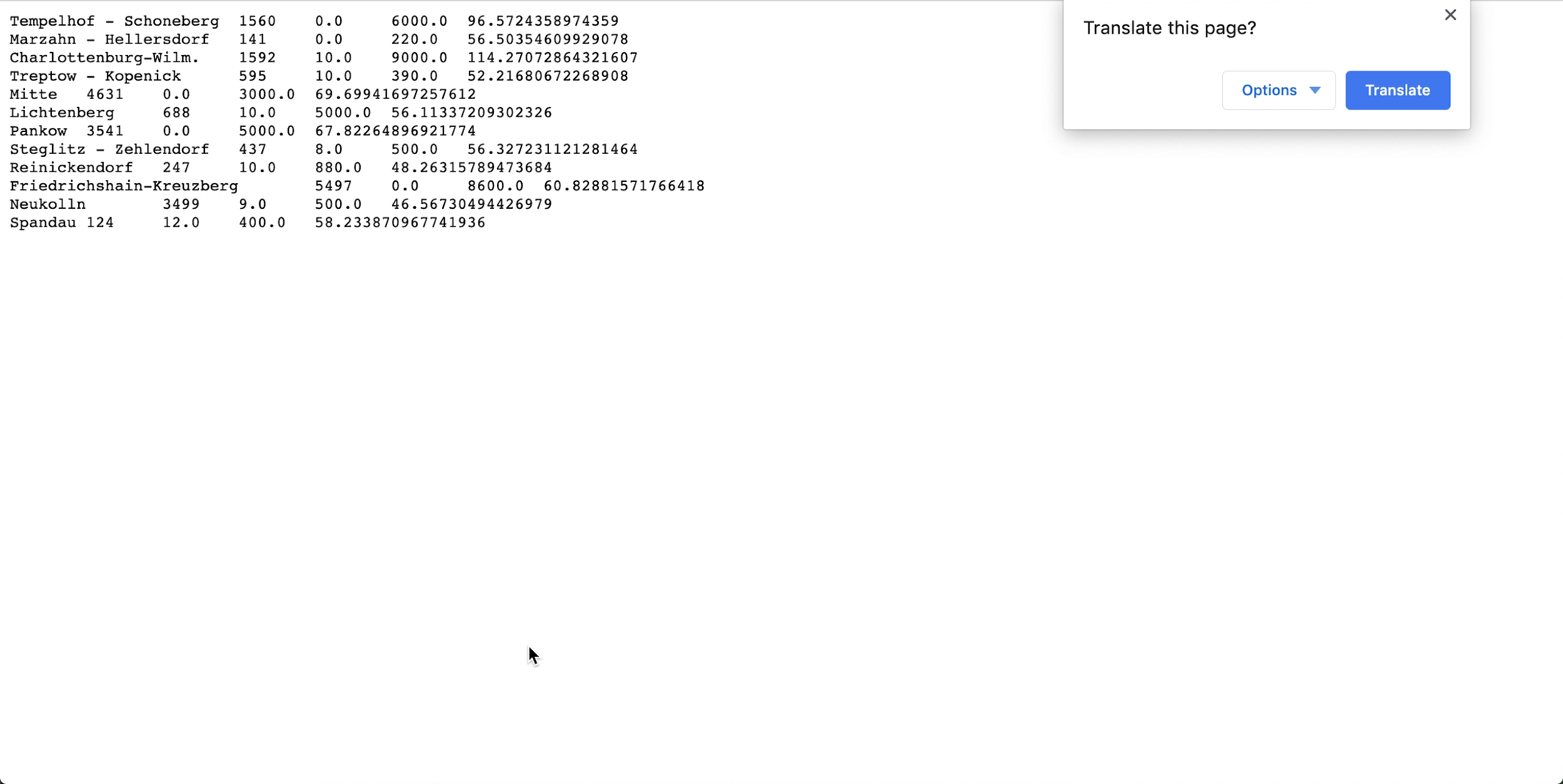
- Sulla base del tuo profilo SQL, puoi concludere che, in questo set di dati, Neukolln ha il prezzo di listino medio più basso a $ 46,57, mentre Charlottenburg-Wilmersdorf ha la media più alta a $ 114,27 (Nota: il set di dati di origine ha prezzi in USD anziché in EUR).
Questo esercizio ha mostrato alcuni aspetti chiave del flusso di dati. Quando è presente un'applicazione SQL, chiunque può eseguirla facilmente senza preoccuparsi della capacità del cluster, dell'accesso e della conservazione dei dati, della gestione delle credenziali o di altre considerazioni sulla sicurezza. Ad esempio, un analista aziendale può utilizzare facilmente i report basati su Spark con Data Flow.
3. Machine Learning con PySpark
Utilizzare PySpark per eseguire un semplice task di apprendimento automatico sui dati di input.
Questo esercizio utilizza l'output di 1. ETL con Java come dati di input. Devi aver completato con successo il primo esercizio prima di poter provare questo. Questa volta, il tuo obiettivo è quello di identificare le migliori occasioni tra i vari annunci Airbnb utilizzando gli algoritmi di machine learning Spark.
I passi riportati di seguito consentono di utilizzare l'interfaccia utente della console. Puoi completare questo esercizio utilizzando spark-submit dall'interfaccia CLI o spark-submit con Java SDK.
È disponibile un'applicazione PySpark da utilizzare direttamente nelle applicazioni di flusso dati. Non è necessario creare una copia.
Il testo di riferimento dello script PySpark viene fornito qui per illustrare alcuni punti: 
- Lo script Python prevede un argomento della riga di comando (evidenziato in rosso). Quando si crea l'applicazione Flusso dati, è necessario creare un parametro con il quale l'utente imposta il percorso di input.
- Lo script utilizza la regressione lineare per prevedere un prezzo per listino e trova le occasioni migliori sottraendo il prezzo di listino dalla previsione. Il valore più negativo indica il valore migliore, per modello.
- Il modello in questo script è semplificato e considera solo il metraggio quadrato. In un ambiente reale si userebbero più variabili, come il quartiere e altre importanti variabili predittive.
Crea un'applicazione PySpark dalla console o con Spark-submit dalla riga di comando o utilizzando l'SDK.
Creare un'applicazione PySpark in Data Flow utilizzando la console.
-
Creare un'applicazione e selezionare il tipo Python.
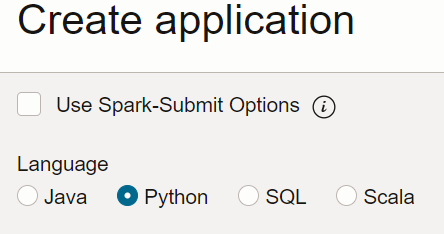
-
Verificare la configurazione dell'applicazione e verificare che sia simile alla seguente:
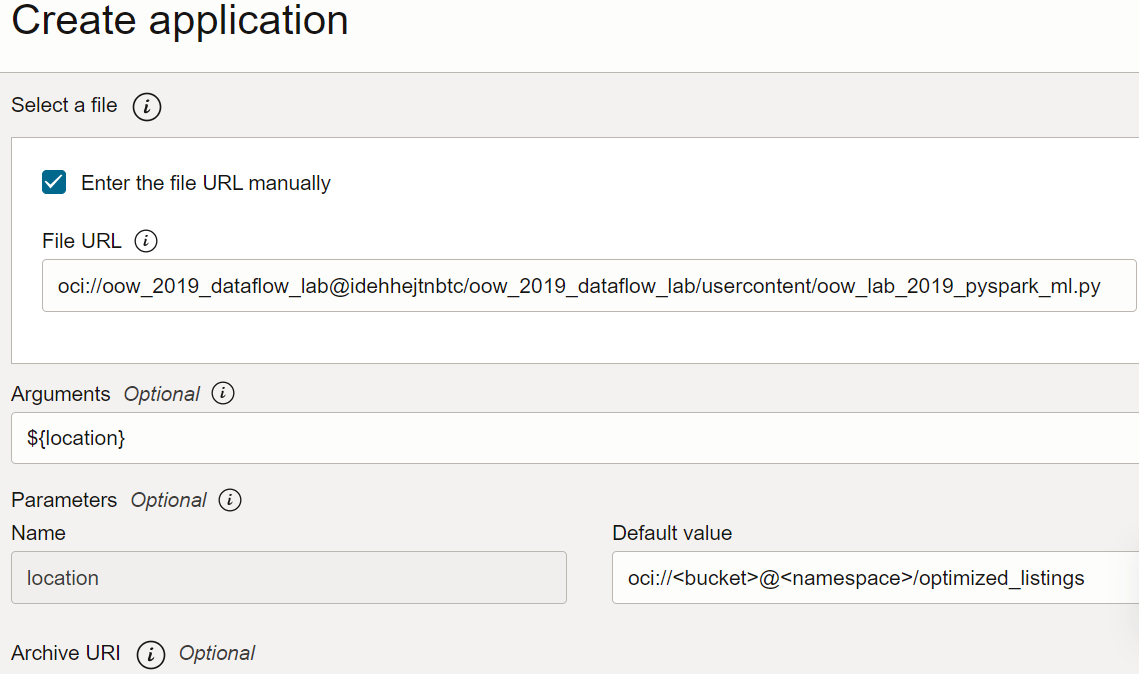
Crea un'applicazione PySpark in Data Flow utilizzando Spark-submit e CLI.
Crea un'applicazione PySpark in Data Flow utilizzando Spark-submit e SDK.
- Eseguire l'applicazione dalla lista di applicazioni.
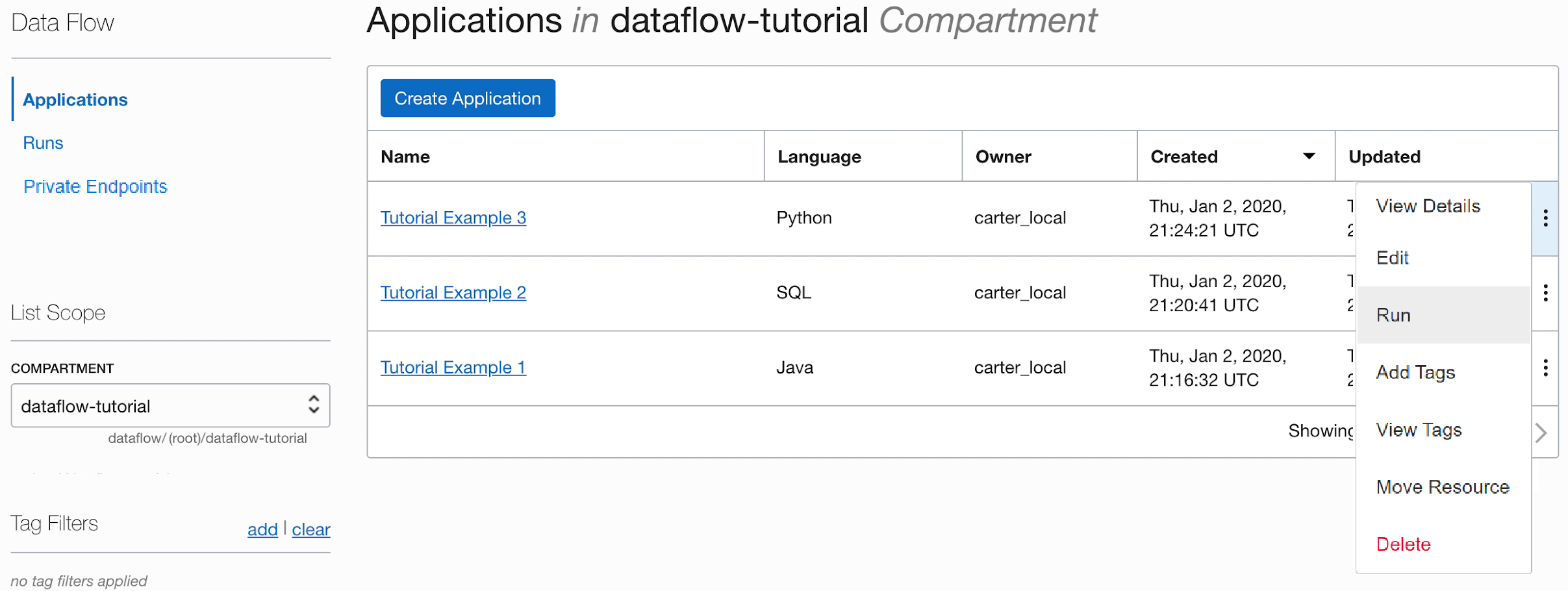
-
Al termine dell'esecuzione, aprirla e andare ai log.

- Aprire il file spark_application_stdout.log.gz. L'output deve essere identico al seguente:

-
Da questo output, si vede che l'elenco ID 690578 è il miglior affare con un prezzo previsto di $ 313,70, rispetto al prezzo di listino di $ 35,00 con filmati quadrati elencati di 4639 piedi quadrati. Se sembra un po' troppo bello per essere vero, l'ID univoco significa che puoi scavare nei dati, per capire meglio se è davvero il furto del secolo. Ancora una volta, un analista aziendale potrebbe facilmente utilizzare l'output di questo algoritmo di machine learning per promuovere la loro analisi.
Pagina successiva
Ora puoi creare ed eseguire applicazioni Java, Python o SQL con Data Flow ed esplorare i risultati.
Data Flow gestisce tutti i dettagli di distribuzione, eliminazione, gestione dei log, sicurezza e accesso all'interfaccia utente. Data Flow ti consente di sviluppare applicazioni Spark senza preoccuparti dell'infrastruttura.