Proteggi i database critici da errori e disastri utilizzando Autonomous Data Guard
La funzione Autonomous Data Guard consente di mantenere i database di produzione critici disponibili per le applicazioni mission critical nonostante errori, disastri, errori umani o danneggiamento dei dati. Questo tipo di funzionalità è spesso chiamato disaster recovery.
In Autonomous AI Database on Dedicated Exadata Infrastructure, puoi configurare e gestire Autonomous Data Guard a livello di Autonomous Container Database.
Informazioni su Autonomous Data Guard
Autonomous Data Guard crea e gestisce due copie completamente separate del database: un database primario a cui le applicazioni si connettono e utilizzano e un database standby che è una copia sincronizzata del database primario. Quindi, se il database primario non è più disponibile per qualsiasi motivo, Autonomous Data Guard può convertire il database di standby nel database primario e, come tale, inizierà a servire le tue applicazioni.
I database primari e in standby sono spesso chiamati database peer l'uno dell'altro. Puoi avere fino a due database in standby per ogni Autonomous Container Database.
Nota: le applicazioni devono essere configurate in modo da utilizzare Transparent Application Continuity (TAC) per ottenere il vantaggio completo delle funzioni di disponibilità del database fornite da Autonomous Data Guard.
Il diagramma riportato di seguito mostra come ogni database in standby viene mantenuto sincronizzato con il database primario.
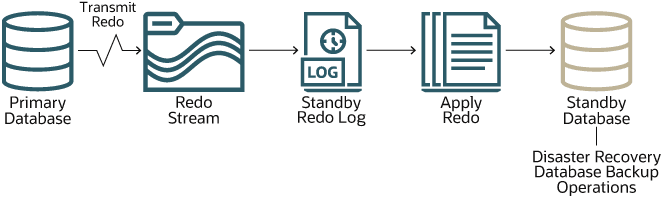
Descrizione dell'illustrazione autonomous-data-guard.png
Le modifiche apportate al database primario vengono registrate nel redo log del database primario. Autonomous Data Guard trasmette questi redo record come flusso sulla rete al redo log del database in standby. Quindi, il database in standby applica questi record al database in standby. In questo modo, il database in standby viene mantenuto sincronizzato con il database primario.
La sincronizzazione è quasi istantanea, ma, come suggerisce il processo appena descritto, ci sono due operazioni che consumano tempo: il trasporto dei redo record nel database in standby e l'applicazione dei redo record al database in standby. Il primo di questi è chiamato ritardo di trasporto, mentre l'altro è chiamato ritardo di applicazione. È possibile visualizzare i valori di ritardo correnti per un Autonomous AI Database dalla pagina Dettagli del database in Autonomous Data Guard. È possibile visualizzare i valori di ritardo correnti in tutti i database AI autonomi in un container database dalla pagina Dettagli del container database in modo simile.
Nota: con più database in standby, il trasporto di redo a catena non è supportato.
Configurazione di Autonomous Data Guard
In Autonomous AI Database on Dedicated Exadata Infrastructure, puoi configurare e gestire Autonomous Data Guard a livello di Autonomous Container Database (ACD). Puoi abilitare Autonomous Data Guard per gli ACD già di cui è stato eseguito il provisioning e aggiungere fino a due ACD in standby dalla pagina Dettagli utilizzando la console di Oracle Cloud Infrastructure. Per istruzioni, vedere Abilita Autonomous Data Guard su un Autonomous Container Database e Aggiungi un secondo Autonomous Container Database in standby.
-
Ora puoi creare e gestire Autonomous Data Guard tra un ACD in Oracle Cloud Infrastructure (OCI) e un ACD in Amazon Web Services (AWS).
-
Puoi aggiungere un ACD in standby dall'area AWS all'ACD di cui è già stato eseguito il provisioning nell'area OCI. In alternativa, puoi aggiungere un ACD in standby nell'area OCI a un ACD già di cui è stato eseguito il provisioning nell'area AWS.
Prima di configurare Autonomous Data Guard, tenere presente quanto riportato di seguito.
-
I database AI autonomi distribuiti su Exadata Cloud@Customer devono avere la porta 1522 aperta per consentire il traffico TCP tra il database primario e il database di standby in un'impostazione di Autonomous Data Guard.
-
Autonomous Data Guard non può essere abilitato in un ACD con un'esecuzione di manutenzione attiva pianificata entro i tre giorni successivi. È possibile eseguire prima la manutenzione attiva, quindi abilitare Autonomous Data Guard o modificare la pianificazione dell'esecuzione della manutenzione in modo che non inizi fino a quando non viene aggiunto il secondo database di standby.
-
L'aggiunta di un secondo database di standby richiede un riavvio automatico in sequenza per il primo database di standby. Il database primario non è interessato da questo riavvio in sequenza.
Configura Autonomous Data Guard con chiavi gestite dal cliente
In Autonomous AI Database on Dedicated Exadata Infrastructure, puoi configurare e gestire Autonomous Data Guard con chiavi gestite dal cliente a livello di Autonomous Container Database (ACD). Puoi abilitare Autonomous Data Guard per gli ACD già di cui è stato eseguito il provisioning e aggiungere fino a due ACD in standby dalla pagina Dettagli utilizzando la console di Oracle Cloud Infrastructure. Per istruzioni, vedere Abilita Autonomous Data Guard su un Autonomous Container Database e Aggiungi un secondo Autonomous Container Database in standby.
Tenere presente quanto riportato di seguito prima di configurare Autonomous Data Guard con chiavi gestite dal cliente.
-
Se stai utilizzando il sistema Oracle Cloud Infrastructure Key Management System (OCI KMS) e desideri abilitare Autonomous Data Guard tra più aree:
-
Prima devi replicare il vault OCI nell'area in cui desideri aggiungere il database in standby. Per ulteriori dettagli, vedere Replica di vault e chiavi.
-
Puoi avere solo i database primari e in standby in un massimo di 2 region. In altre parole, se si desidera aggiungere un secondo standby e si è già utilizzato cross-region per il primo standby, il secondo standby deve trovarsi nell'area primaria o nella prima standby region.
Nota: i vault virtuali creati prima dell'introduzione della funzione di replica del vault tra più aree non possono essere replicati in più aree. Creare un nuovo vault e nuove chiavi se si dispone di un vault che è necessario replicare in un'altra area e la replica non è supportata per tale vault. Tuttavia, tutti i vault privati supportano la replica tra più aree. Per i dettagli, vedere Replica del vault virtuale tra più aree.
-
-
Se si utilizza Oracle Key Vault (OKV) e si desidera abilitare Autonomous Data Guard tra più aree, assicurarsi di aver aggiunto gli indirizzi IP di connessione per il cluster OKV nel keystore.
-
Se si utilizza AWS Key Management System ( AWS KMS) e si desidera abilitare Autonomous Data Guard tra più aree:
- È necessario disporre di una chiave multiregione AWS registrata nell'area primaria. Puoi selezionare il tipo di chiave AWS come multiregione solo quando la crei e non può essere modificata in seguito.
- È necessario impostare i criteri necessari nell'area replicata poiché i criteri non vengono replicati automaticamente.
- La chiave multiregione AWS KMS deve essere replicata dall'area di origine all'area di destinazione dalla console AWS. Per i dettagli, vedere Replica le chiavi AWS KMS nella console AWS.
- La chiave multiregione AWS KMS deve essere replicata dall'area primaria all'area di destinazione dalla console OCI. Per ulteriori dettagli, consulta la sezione Replica chiavi AWS KMS nella console OCI.
Transizioni e operazioni ruolo
Dopo aver creato un Autonomous Container Database (ACD), è possibile modificare il ruolo dei database peer utilizzando uno switchover o un'operazione di failover. Se il failover automatico è abilitato, Autonomous Data Guard esegue automaticamente un'operazione di failover ogni volta che il database primario non è più disponibile, per qualsiasi motivo.
Uno switchover è un'inversione di ruolo tra il database primario e il relativo database di standby. Lo switchover non garantisce alcuna perdita di dati. Durante uno switchover, il database primario esegue la transizione al ruolo di standby e il database di standby esegue la transizione al ruolo primario. Per eseguire un'operazione di switchover, vedere Cambia ruoli in una configurazione Autonomous Data Guard.
Un failover si verifica quando il database primario non è disponibile. Il failover determina una transizione del database di standby al ruolo primario. Se il failover automatico non è abilitato, è possibile eseguire un failover manuale come descritto in Failover to the Standby in an Autonomous Data Guard Configuration.
La disponibilità e lo stato del database dopo un'operazione di failover sono caratterizzati da due obiettivi di recupero:
-
Recovery Time Objective (RTO). L'RTO indica il periodo di tempo massimo necessario affinché il database diventi disponibile per le applicazioni dopo un failover ed è in qualche modo correlato al ritardo di applicazione al momento dell'errore. Per Autonomous Data Guard, l'RTO è in secondi fino a due minuti.
-
Recovery Point Objective (RPO). L'RPO è la durata massima della potenziale perdita di dati dal database primario non riuscito ed è correlata in qualche misura al ritardo del trasporto al momento dell'errore. Per Autonomous Data Guard, l'RPO è quasi zero.
Dopo un failover, il database primario non riuscito diventa un standby disabilitato e rimane non disponibile per qualsiasi connessione al database. Puoi riabilitarlo e trasformarlo in uno standby in buono stato eseguendo un'operazione di reintegrazione. Una volta che un primario non riuscito è stato ripristinato come standby, puoi eseguire uno switchover per riportarlo al ruolo primario originale. Per eseguire un'operazione di ripristino, vedere Ripristinare il standby disabilitato in una configurazione Autonomous Data Guard.
Failover automatico o Fast-Start Failover
Con il failover automatico, ogni volta che l'ACD primario diventa non disponibile a causa di un errore dell'area, di un errore del dominio di disponibilità, di un errore dell'infrastruttura Exadata o del cluster VM Autonomous Exadata (AVMC) o del guasto dell'ACD stesso, il failover viene eseguito automaticamente sull'ACD in standby. Questo è anche noto come Fast-Start Failover.
Non puoi abilitare il failover automatico durante la configurazione di Autonomous Data Guard su un ACD. Il failover automatico può essere abilitato o disabilitato solo durante l'aggiornamento delle impostazioni di Autonomous Data Guard dalla pagina Dettagli ACD.
Nota: il failover automatico non può essere abilitato per Autonomous AI Database distribuiti in Exadata Cloud@Customer con l'impostazione di Autonomous Data Guard tra più aree.
Non è possibile aggiungere un secondo ACD in standby con failover automatico abilitato per il primo ACD in standby. Pertanto, disabilitare il failover automatico utilizzando Aggiorna impostazioni di Autonomous Data Guard prima di creare il secondo ACD in standby e riabilitarlo in un secondo momento, se necessario.
Sia le massime prestazioni che le modalità di protezione della massima disponibilità supportano il failover automatico:
-
Nella modalità Massima disponibilità, il failover automatico garantisce l'assenza di perdita di dati.
-
Nella modalità Prestazioni massime, il failover automatico garantisce che il database di standby non sia in ritardo rispetto al database primario oltre il valore specificato per il limite di ritardo del failover di avvio rapido. Per impostazione predefinita, l'opzione Limite ritardo failover avvio rapido è impostata su 30 secondi ed è applicabile solo alla modalità Prestazioni massime. In questo caso, il failover automatico è possibile solo quando il ritardo di applicazione (potenziale perdita di dati) dello standby non supera il limite di ritardo configurato. È possibile modificare il limite di ritardo Fast Start failover impostandolo su un valore compreso tra 5 e 3600.
Per ulteriori dettagli, vedere Aggiorna impostazioni Autonomous Data Guard.
Oltre a guasti hardware, indisponibilità del dominio di disponibilità e indisponibilità regionali, ci sono altre condizioni di integrità del database che possono attivare un failover Fast-Start, come elencato di seguito:
| Condizione stato database | Descrizione |
|---|---|
| Control file danneggiato | Controlfile è stato danneggiato in modo permanente, a causa di un errore nel disco. |
| Dizionario danneggiato | Danneggiamento del dizionario di un database critico. Attualmente, questo stato può essere rilevato solo quando il database è aperto. |
| Errori di scrittura del file di dati | Si verificano errori di scrittura in qualsiasi file di dati, inclusi i file temporanei, i file di dati di sistema e i file di annullamento. |
Come risultato del failover automatico, il ruolo del database primario non riuscito diventa Standby disabilitato e, dopo un breve periodo, il database di standby assume il ruolo del database primario. Al termine del failover automatico, viene visualizzato un messaggio nella pagina dei dettagli del database di standby disabilitato in cui viene indicato che si è verificato il failover.
Dopo che il servizio ha risolto i problemi primari di Autonomous Container Database, è possibile eseguire uno switchover manuale per restituire entrambi i database ai ruoli iniziali. Una volta eseguito il provisioning del database in standby, puoi eseguire vari task di gestione correlati al database in standby, tra cui:
-
Passaggio manuale da un database primario a un database in standby.
-
failover manuale di un database primario in un database in standby.
-
Ripristino di un ruolo database primario in standby dopo il failover.
-
Arresto di un database in standby.
In un'impostazione di Autonomous Data Guard con più database in standby e failover automatico:
-
I failover manuali richiedono di ripristinare manualmente il database primario originale, che diventa il nuovo database in standby.
-
Ogni volta che si verifica un failover automatico, Autonomous AI Database on Dedicated Exadata Infrastructure tenta di ripristinare il vecchio database primario come standby. Tuttavia, se il tentativo non riesce, deve essere ripristinato manualmente.
Database in standby snapshot
Un database di standby snapshot è un database di standby completamente aggiornabile creato convertendo un Autonomous Container Database (ACD) in un ACD di standby snapshot. Per istruzioni dettagliate, vedere Convert Physical Standby to Snapshot Standby.
Un database di standby snapshot riceve e archivia, ma non applica, i dati di redo dal database primario. Tuttavia, aumenta l'obiettivo RTO (Recovery Time Objective) perché le modifiche in tempo reale dal database primario non vengono applicate.
La funzione di standby snapshot supporta vari casi d'uso, ma di seguito sono riportati i casi d'uso principali.
-
Connettere le istanze dell'applicazione primaria e in standby ai database primari e in standby in modalità di lettura-scrittura per eseguire le configurazioni iniziali.
-
Applicare prima una patch al database di standby snapshot ed eseguire il test con l'istanza dell'applicazione di standby per confermare la stabilità delle patch. Ciò richiede prima la conversione dello standby fisico in uno standby snapshot, in modo che la patch possa essere applicata nello standby snapshot.
Nota: non è possibile convertire un Autonomous Container Database in standby fisico in uno standby snapshot con failover automatico abilitato.
Durante la conversione in standby snapshot, è possibile attivare nuovi servizi di database attivi solo in modalità snapshot o utilizzare lo stesso set di servizi utilizzato con il database primario. Tuttavia, l'attivazione dei servizi di database primario nel database di standby snapshot può comportare l'inoltro delle richieste di connessione di standby snapshot al database primario o viceversa se si utilizzano stringhe di connessione del database errate. Pertanto, è necessario fare attenzione a utilizzare la stringa di connessione appropriata durante la connessione al database di standby primario e snapshot.
Nota: quando si creano nuovi servizi con standby snapshot, vengono aggiornati i wallet per tutti i database AI autonomi nell'ACD di standby snapshot. Per accedere al database, ricaricare i wallet dai database AI autonomi di standby e utilizzare le stringhe di connessione di standby snapshot.
Puoi convertire l'ACD in standby snapshot in un ACD in standby fisico da Oracle Cloud Infrastructure (OCI) manualmente. Per istruzioni dettagliate, vedere Convert Snapshot Standby to Physical Standby. Se uno standby snapshot non viene convertito manualmente in uno standby fisico, verrà riconvertito automaticamente in uno standby fisico dopo 7 giorni dalla sua creazione. In ogni caso, la conversione dello standby snapshot in standby fisico eliminerà tutti gli aggiornamenti locali nei database di standby snapshot e applicherà i redo data ricevuti dai database primari.
Quando un ACD in standby è in modalità standby snapshot, non è possibile eseguire le seguenti operazioni sull'ACD primario:
-
Crea o arresta i database AI autonomi
-
Esegui lo scale-up o lo scale-down dei database AI autonomi
-
Ripristina database AI autonomi
Se la situazione lo richiede, puoi eseguire manualmente il failover in uno standby snapshot dal database primario. In tal caso, il failover converte il database di standby snapshot in un database di standby fisico eliminando tutti gli aggiornamenti locali apportati allo standby snapshot e applicando i dati dal database primario. Per istruzioni dettagliate, vedere Failover to the Standby in a Autonomous Data Guard Configuration.
Non è consentito uno switchover tra il database primario e il relativo database di standby snapshot. Prima di tentare uno switchover, è necessario convertire manualmente lo standby snapshot in uno standby fisico.
Accesso ai database in standby dalle applicazioni client
In una configurazione Autonomous Data Guard, le applicazioni client in genere si connettono ed eseguono operazioni sul database primario.
Connessione al database in standby fisico
Oltre a questa normale connettività, Autonomous Data Guard ti offre la possibilità di connettere le applicazioni client che eseguono operazioni di sola lettura sul database di standby. Per usufruire di questa opzione, le applicazioni client si connettono al database utilizzando i nomi dei servizi di database che includono "_RO" (per "sola lettura"), come descritto in Nomi dei servizi di database predefiniti per Autonomous AI Database.
Connessione al database di standby snapshot
Autonomous Data Guard consente inoltre di connettere le applicazioni client che eseguono operazioni di lettura-scrittura al database di standby snapshot. Queste operazioni sono locali al database di standby snapshot e non ne modificano il database primario. Per connettersi a un database di standby snapshot, le applicazioni client possono utilizzare i nomi dei servizi di database che includono "_SS" (per "standby snapshot"), come descritto in Nomi dei servizi di database predefiniti per i database AI autonomi.
Nota: quando il database di standby è in modalità standby snapshot, tutti i servizi di database che includono i servizi "_RO" nel loro nome sono inattivi e non possono essere utilizzati per le connessioni.
Tempi di ritardo monitoraggio
Man mano che i database che utilizzano Autonomous Data Guard sono in esecuzione, puoi monitorare i ritardi di trasporto e applicare i tempi di ritardo dalla pagina Dettagli del database (o del container database) scegliendo Gruppi Autonomous Data Guard. Puoi anche utilizzare la console OCI o le API di osservabilità per monitorare i ritardi di trasporto e configurare allarmi e notifiche. Per ulteriori informazioni, consulta la sezione relativa all'osservabilità del database con Autonomous AI Database Metrics.
Dovresti aspettarti di vedere fluttuazioni minori nel tempo man mano che il carico di lavoro sul tuo database diminuisce e scorre. Tuttavia, se si nota una tendenza al rialzo continua nel tempo di ritardo, è possibile eseguire queste azioni per risolvere la situazione:
-
Andamento al rialzo in ritardo applicazione. Una tendenza al rialzo continua del ritardo di applicazione indica che il database di standby non dispone di capacità sufficiente per tenere il passo con i redo record provenienti dal database primario. Per risolvere questa situazione, eseguire lo scale-up delle OCPU del database, come descritto in Aggiungere risorse di CPU o storage a un database AI autonomo dedicato.
-
Andamento al rialzo in ritardo trasporto. Una continua tendenza al rialzo del ritardo dei trasporti indica un problema di prestazioni della rete. Il personale operativo di Oracle Cloud monitora costantemente le prestazioni della rete, quindi dovresti vedere la situazione risolversi da sola senza intraprendere alcuna azione. Tuttavia, se lo si desidera, è possibile portare la situazione al personale operativo inviando una richiesta di servizio, come descritto in Creare una richiesta di servizio in My Oracle Support.
Opzioni di configurazione di Autonomous Data Guard
Quando configuri Autonomous Data Guard, specifichi l'infrastruttura Exadata e le risorse del cluster VM Autonomous Exadata in cui desideri creare il database di standby e specifica la modalità di protezione dei dati che desideri utilizzare.
Quando si specificano le risorse dell'infrastruttura Exadata e del cluster VM Autonomous Exadata da utilizzare per lo standby, sono disponibili le opzioni riportate di seguito.
-
In un'area diversa dall'infrastruttura Exadata e dal cluster VM Autonomous Exadata del database primario:
Questa scelta fornisce il massimo livello di protezione contro i disastri, tra cui una perdita catastrofica della connettività di rete esterna o dell'alimentazione a un'intera regione.
Per utilizzare al meglio questa protezione tra più aree, è necessario configurare il livello dell'applicazione per supportare la protezione tra più aree. Pertanto, Oracle consiglia di scegliere questa opzione se il livello dell'applicazione è già configurato in questo modo o se si desidera riconfigurarlo per supportare la protezione tra più aree.
Se si sceglie di individuare il database in standby in un'area diversa, Oracle consiglia di utilizzare la modalità di protezione Prestazioni massime.
-
In un dominio di disponibilità (AD) diverso dall'infrastruttura Exadata e dal cluster VM Autonomous Exadata del database primario:
Questa scelta offre un elevato livello di protezione contro i disastri, tra cui una perdita irreversibile della connettività di rete esterna o dell'alimentazione a un dominio di disponibilità all'interno di un'area geografica.
Questa scelta offre un buon equilibrio tra la protezione dei dati e la semplicità di configurazione nel livello dell'applicazione.
Se si sceglie di individuare il database in standby in un dominio di disponibilità diverso, Oracle consiglia di utilizzare la modalità di protezione Massima disponibilità.
-
Nello stesso dominio di disponibilità (AD) dell'infrastruttura Exadata e del cluster VM Autonomous Exadata del database primario:
Questa scelta fornisce un livello minimo di protezione contro le calamità e Oracle consiglia di non sceglierla.
Se le risorse dell'infrastruttura Exadata e del cluster VM Autonomous Exadata del database primario si trovano in un'area che dispone di un solo dominio di disponibilità, Oracle consiglia di utilizzare l'opzione "in un'area diversa".
Se si sceglie di individuare il database in standby nello stesso dominio di disponibilità, Oracle consiglia di utilizzare la modalità di protezione Massima disponibilità.
-
In una tenancy diversa dall'infrastruttura Exadata e dal cluster VM Autonomous Exadata del database primario:
SI APPLICA A:
 Solo Oracle Public Cloud
Solo Oracle Public CloudQuesta scelta ti consente di aggiungere un database in standby in una tenancy diversa dal database primario, consentendoti di eseguire il failover o lo switchover del database in quel database in standby cross-tenancy. È inoltre possibile creare uno standby snapshot nella tenancy remota. Avere un database di standby cross-tenancy può essere utile con la migrazione del database tra le tenancy.
Database di standby cross-tenancy:
-
Può essere abilitato con il modello di computazione ECPU o OCPU. Il database di standby deve utilizzare lo stesso modello di computazione del database primario.
-
Supporta il failover automatico. Tuttavia, il failover automatico non può essere abilitato per i database AI autonomi distribuiti in Exadata Cloud@Customer con l'impostazione di Autonomous Data Guard tra più aree.
-
Impossibile aggiungere utilizzando la console di Oracle Cloud Infrastructure. È possibile aggiungere un database in standby tra tenancy solo utilizzando l'interfaccia CLI o l'API REST. Una volta aggiunto il database di standby, puoi visualizzare il database di standby cross-tenancy, eseguire un failover o eseguire lo switchover al database di standby cross-tenancy dalla console di Oracle Cloud Infrastructure.
-
Informazioni sulle modalità di protezione
Autonomous Data Guard fornisce queste modalità di protezione dei dati:
-
Disponibilità massima. Questa modalità protezione fornisce il livello più alto di protezione dei dati possibile senza compromettere la disponibilità del database primario.
Il database primario non esegue il commit delle transazioni finché non riceve la conferma che i dati sono stati ricevuti in standby (non che sono stati scritti su disco). Se il database primario non riceve questa conferma entro 30 secondi, funziona come se fosse in modalità prestazioni massime per preservare la disponibilità del database primario fino a quando non riceve di nuovo le conferme in modo tempestivo.
Questa modalità di protezione garantisce l'assenza di perdita di dati, tranne nel caso di determinati errori doppi, come l'errore di un database primario dopo l'errore del database di standby.
-
Prestazioni massime. Questa è la modalità di protezione predefinita. Offre il livello più alto di protezione dei dati possibile senza influire sulle prestazioni del database primario.
Il database primario esegue il commit delle transazioni non appena tutti i redo data generati da tali transazioni sono stati scritti nel redo log in linea. Invia anche dati di redo al database in standby, ma ciò viene eseguito in modo asincrono rispetto all'impegno delle transazioni, pertanto le prestazioni del database primario non sono interessate da ritardi nella scrittura dei dati di redo nel database in standby.
Questa modalità di protezione offre una protezione dei dati leggermente inferiore rispetto alla modalità di massima disponibilità e ha un impatto minimo sulle prestazioni del database primario.
Puoi modificare la modalità di protezione in un'impostazione di Autonomous Data Guard dalla console di Oracle Cloud Infrastructure (OCI). Per istruzioni dettagliate, vedere Aggiorna impostazioni Autonomous Data Guard.
Per ulteriori informazioni sulle modalità di protezione in Oracle Data Guard (che è alla base della funzione Autonomous Data Guard), vedere Modalità di protezione di Oracle Data Guard in Oracle Data Guard Concepts and Administration.
Best practice durante la configurazione di Autonomous Data Guard
Sebbene Autonomous AI Database ti consenta di creare fino a due ACD in standby con Autonomous Data Guard, puoi scegliere di utilizzare uno o più ACD in standby, a seconda delle tue esigenze. Tuttavia, per utilizzare l'opzione di disaster recovery più resiliente offerta da un Autonomous AI Database, puoi aggiungere un ACD di standby locale e un ACD di standby remoto o tra più aree con massima disponibilità come modalità di protezione dei dati.
Comprendiamo i vantaggi di questo design:
-
Standby locale:
-
Il failover automatico a uno standby locale nella stessa area fornisce un isolamento dalle calamità locali significativo e una semplicità di failover delle applicazioni.
-
Il valore aziendale di un database in standby locale è visto in zero data loss failover e tempi di inattività delle applicazioni ridotti a secondi.
-
Le applicazioni eseguono automaticamente e in modo trasparente il failover allo standby locale, mantenendo la stessa latenza tra gli application server e il database. Ciò è particolarmente importante per le applicazioni OLTP e dei package perché una latenza più elevata può influire in modo significativo sul throughput e sul tempo di risposta complessivo delle applicazioni.
-
-
Standby remoto:
-
Se un errore irreversibile a livello regionale rende inaccessibili i sistemi di standby primario e locale, l'applicazione e il database possono eseguire il failover in standby remoto.
-
Anche se i tempi di inattività del database sono ancora molto bassi quando si verifica un disastro regionale, i tempi di inattività dell'applicazione possono essere più elevati a causa dell'orchestrazione aggiuntiva richiesta per le operazioni di failover DNS, applicazioni e database nell'area secondaria.
-
-
Disponibilità massima:
-
Se il failover automatico o il Fast Start Failover (FSFO) è abilitato, ogni volta che l'ACD primario diventa non disponibile, Autonomous Data Guard non riesce al database in standby locale senza alcuna perdita di dati e nessuna modifica alla latenza del database nell'applicazione.
-
Se il failover automatico o il Fast Start Failover (FSFO) sono abilitati, ogni volta che l'intera region primaria diventa inaccessibile, il sistema non riesce a eseguire il backup in standby remoto con una potenziale perdita di dati.
-
In che modo Autonomous Data Guard influisce sulle operazioni di gestione standard
In alcuni casi, le operazioni di gestione standard eseguite sugli Autonomous Container Database funzionano in modo diverso sui container database primari e in standby in una configurazione Autonomous Data Guard rispetto ai container database standard. L'elenco seguente descrive queste differenze.
-
Modificare la pianificazione della manutenzione
La pianificazione della manutenzione di un container database primario e del relativo standby sono collegati: la manutenzione in standby viene eseguita alcuni giorni prima della manutenzione sul database primario. L'impostazione predefinita è 7 giorni; è possibile scegliere tra 1 e 7 giorni quando si crea il container database primario o in un secondo momento modificandone i dettagli di manutenzione.
-
Modificare il tipo di manutenzione
Il tipo di manutenzione di un container database primario e del relativo standby deve essere lo stesso. È possibile scegliere il tipo di manutenzione sia per il database primario che per quello in standby quando si crea il container database primario o in un secondo momento modificandone i dettagli di manutenzione.
-
Disabilita backup automatici
Non puoi disabilitare i backup automatici durante il provisioning di un Autonomous Container Database (ACD) con Autonomous Data Guard.
-
Gestisci manutenzione pianificata
Puoi gestire separatamente la manutenzione pianificata di un container database primario e il relativo standby. Tuttavia, poiché la manutenzione dei due è collegata, è necessario eseguire la manutenzione pianificata in standby prima del database primario se si sceglie di eseguire l'override dell'ora di manutenzione pianificata.
-
Sposta in un altro compartimento
Puoi spostare i container database primari e in standby in compartimenti diversi separatamente e in modo indipendente, proprio come se fossero container database standard. Tuttavia, come per i container database standard, dovresti prestare estrema attenzione quando sposti un container database per garantire che il container database rimanga accessibile ai gruppi appropriati di utenti cloud.
-
Riavvia
Puoi riavviare i container database primari e in standby separatamente e in modo indipendente, proprio come se fossero container database standard.
-
Ruotare la chiave di cifratura
È possibile ruotare le chiavi di cifratura dall'ACD primario o dal database primario.
-
Termina
Puoi arrestare separatamente i database dei container primari e in standby. Tuttavia, le conseguenze dell'interruzione di un container database primario e dell'interruzione di un container database in standby sono diverse:
-
L'arresto di un container database primario termina sia il container database primario che quello di standby. Non è possibile arrestare un container database primario contenente Autonomous AI Database.
-
L'arresto di un container database in standby termina il container database di standby e lo rimuove dalla configurazione di Autonomous Data Guard. Se dispone solo di un database primario rimanente, la configurazione di Autonomous Data Guard viene rimossa, trasformando il database primario in un container database standalone.
-
Guide dettagliate
Per istruzioni dettagliate sulla gestione della configurazione di Autonomous Data Guard in un Autonomous Container Database, vedere:
-
Abilita Autonomous Data Guard in un Autonomous Container Database
-
Visualizza lo stato di una configurazione Autonomous Data Guard
-
Failover in standby in una configurazione Autonomous Data Guard
-
Ripristinare il standby disabilitato in una configurazione Autonomous Data Guard
-
Aggiungi un secondo Autonomous Container Database in standby
Puoi anche utilizzare l'API per visualizzare e gestire la configurazione di Autonomous Data Guard. Per ulteriori dettagli, vedere API per gestire la configurazione di Autonomous Data Guard.