Uso di Oracle NoSQL Database Migrator
Scopri di più su Oracle NoSQL Database Migrator e come utilizzarlo per la migrazione dei dati.
Oracle NoSQL Database Migrator è uno strumento che consente di eseguire la migrazione delle tabelle Oracle NoSQL da un'origine dati a un'altra. Questo strumento può operare su tabelle in Oracle NoSQL Database Cloud Service, Oracle NoSQL Database on-premise e AWS S3. Lo strumento Migrator supporta diversi formati di dati e tipi di supporti fisici. I formati di dati supportati sono JSON, Parquet, JSON in formato MongoDB, JSON in formato DynamoDB e file CSV. I tipi di supporti fisici supportati sono file, OCI Object Storage, Oracle NoSQL Database on-premise, Oracle NoSQL Database Cloud Service e AWS S3.
Questo articolo contiene i seguenti argomenti:
Panoramica
Oracle NoSQL Database Migrator ti consente di spostare le tabelle Oracle NoSQL da un'origine dati a un'altra, ad esempio Oracle NoSQL Database on-premise o cloud o anche un semplice file JSON.
Possono verificarsi molte situazioni in cui è necessario eseguire la migrazione delle tabelle NoSQL da o a Oracle NoSQL Database. Ad esempio, un team di sviluppatori che migliora un'applicazione NoSQL Database potrebbe voler testare il proprio codice aggiornato nell'istanza locale di Oracle NoSQL Database Cloud Service (NDCS) utilizzando cloudim. Per verificare tutti i possibili casi di prova, essi devono impostare i dati di prova simili ai dati effettivi. A tale scopo, devono copiare le tabelle NoSQL dall'ambiente di produzione all'istanza NDCS locale, l'ambiente cloudim. In un'altra situazione, gli sviluppatori NoSQL potrebbero dover spostare i dati delle applicazioni da on-premise al cloud e viceversa, sia per lo sviluppo che per il test.
In tutti questi casi e molti altri, è possibile utilizzare Oracle NoSQL Database Migrator per spostare le tabelle NoSQL da un'origine dati a un'altra, ad esempio Oracle NoSQL Database on-premise o cloud o anche un semplice file JSON. Puoi anche copiare le tabelle NoSQL da un file di input JSON in formato MongoDB, da un file di input JSON in formato DynamoDB (archiviato nell'origine AWS S3 o dai file) o da un file CSV nel tuo database NoSQL on-premise o nel cloud.
Come illustrato nella figura riportata di seguito, la utility NoSQL Database Migrator funge da connettore o pipe tra l'origine dati e la destinazione (indicata come sink). In sostanza, questa utility esporta i dati dall'origine selezionata e li importa nel sink. Questo strumento è orientato alla tabella, ovvero è possibile spostare i dati solo a livello di tabella. Un singolo task di migrazione opera su un'unica tabella e supporta la migrazione dei dati delle tabelle dall'origine all'affondamento in vari formati di dati.
Oracle NoSQL Database Migrator è progettato in modo da poter supportare origini e sink aggiuntivi in futuro. Per un elenco delle origini e degli sink supportati da Oracle NoSQL Database Migrator alla release corrente, vedere Origini e sink supportati. 
Descrizione dell'immagine migrator_overview.png
Terminologia utilizzata con Oracle NoSQL Database Migrator
Scopri i diversi termini utilizzati nel diagramma di cui sopra, in dettaglio.
-
Origine: un'entità da cui vengono esportate le tabelle NoSQL per la migrazione. Alcuni esempi di origini sono Oracle NoSQL Database on-premise o cloud, file JSON, file JSON in formato MongoDB, file JSON in formato DynamoDB e file CSV.
-
Sink: un'entità che importa le tabelle NoSQL da NoSQL Database Migrator. Alcuni esempi di sink sono Oracle NoSQL Database on-premise o cloud e file JSON.
Lo strumento NoSQL Database Migrator supporta diversi tipi di origini e sink (ovvero supporti fisici o repository di dati) e formati di dati (ovvero il modo in cui i dati vengono rappresentati nell'origine o nel sink). I formati di dati supportati sono JSON, Parquet, JSON in formato MongoDB, JSON in formato DynamoDB e file CSV. I tipi di origine e sink supportati sono file, OCI Object Storage, Oracle NoSQL Database on-premise e Oracle NoSQL Database Cloud Service.
-
Tubo di migrazione: i dati di un'origine verranno trasferiti al sink da NoSQL Database Migrator. Può essere visualizzato come pipe di migrazione.
-
Trasformazioni: è possibile aggiungere regole per modificare i dati della tabella NoSQL nella pipe di migrazione. Queste regole sono chiamate trasformazioni. Oracle NoSQL Database Migrator consente le trasformazioni dei dati solo nei campi o nelle colonne di livello superiore. Non consente di trasformare i dati nei campi nidificati. Alcuni esempi di trasformazioni consentite sono:
-
Eliminare o ignorare una o più colonne,
-
Rinominare una o più colonne oppure
-
Aggrega più colonne in un singolo campo, in genere un campo JSON.
-
-
File di configurazione: un file di configurazione consente di definire tutti i parametri necessari per l'attività di migrazione in formato JSON. In un secondo momento, passare questo file di configurazione come parametro singolo al comando
runMigratordall'interfaccia CLI. Un tipico formato di file di configurazione è simile a quello mostrato di seguito.{ "source": { "type" : <source type>, //source-configuration for type. }, "sink": { "type" : <sink type>, //sink-configuration for type. }, "transforms" : { //transforms configuration. }, "migratorVersion" : "<migrator version>", "abortOnError" : <true|false> }Raggruppa Parametri Obbligatorio (S/N) Scopo Valori supportati sourcetypeS Rappresenta l'origine da cui eseguire la migrazione dei dati. L'origine fornisce dati e metadati (se presenti) per la migrazione. Per conoscere il valore typeper ogni origine, vedere Origini e lavandini supportati.sourceconfigurazione_origine per tipo S Definisce la configurazione per l'origine. Questi parametri di configurazione sono specifici del tipo di origine selezionato in precedenza. Per l'elenco completo dei parametri di configurazione per ciascun tipo di origine, vedere Modelli di configurazione di origine. sinktypeS Rappresenta il sink in cui eseguire la migrazione dei dati. Il sink è la destinazione o la destinazione per la migrazione. Per conoscere il valore typeper ogni origine, vedere Origini e lavandini supportati.sinkconfigurazione sink per tipo S Definisce la configurazione per il lavandino. Questi parametri di configurazione sono specifici del tipo di sink selezionato in precedenza. Per la lista completa dei parametri di configurazione per ogni tipo di sink, vedere Modelli di configurazione del lavandino. transformsconfigurazione trasformazioni N Definisce le trasformazioni da applicare ai dati nella pipe di migrazione. Per l'elenco completo delle trasformazioni supportate da NoSQL Data Migrator, vedere Modelli di configurazione della trasformazione. - migratorVersionN Versione di NoSQL Data Migrator - - abortOnErrorN Specifica se interrompere l'attività di migrazione in caso di errore o meno.
Il valore predefinito è true, che indica che la migrazione si interrompe ogni volta che si verifica un errore di migrazione.
Se si imposta questo valore su false, la migrazione continua anche in caso di record non riusciti o di altri errori di migrazione. I record con errori e gli errori di migrazione non riusciti verranno registrati come WARNING sul terminale CLI.true, false
Nota: poiché il file JSON fa distinzione tra maiuscole e minuscole, tutti i parametri definiti nel file di configurazione fanno distinzione tra maiuscole e minuscole, se non diversamente specificato.
Fonti e lavelli supportati
In questo argomento viene fornita la lista delle origini e dei sink supportati da Oracle NoSQL Database Migrator.
È possibile utilizzare qualsiasi combinazione di un'origine e un sink validi da questa tabella per l'attività di migrazione. Tuttavia, devi assicurarti che almeno una delle estremità, ovvero l'origine o il sink, sia un prodotto Oracle NoSQL. Non è possibile utilizzare NoSQL Database Migrator per spostare i dati della tabella NoSQL da un file all'altro.
| Tipo (valore) | Formato (valore) | Origine valida | Lavello valido |
|---|---|---|---|
Oracle NoSQL Database (nosqldb) |
ND | S | S |
Oracle NoSQL Database Cloud Service (nosqldb_cloud) |
ND | S | S |
File system (file) |
JSON (json) |
S | S |
File system (file) |
JSON MongoDB (mongodb_json) |
S | N |
File system (file) |
JSON DynamoDB (dynamodb_json) |
S | N |
File system (file) |
Parquet (parquet) |
N | S |
File system (file) |
CSV (csv) |
S | N |
Storage degli oggetti OCI (object_storage_oci) |
JSON (json) |
S | S |
Storage degli oggetti OCI (object_storage_oci) |
JSON MongoDB (mongodb_json) |
S | N |
Storage degli oggetti OCI (object_storage_oci) |
Parquet (parquet) |
N | S |
Storage degli oggetti OCI (object_storage_oci) |
CSV (csv) |
S | N |
| S3 AWS | JSON DynamoDB (dynamodb_json) |
S | N |
Nota: molti parametri di configurazione sono comuni nella configurazione di origine e sink. Per facilità di riferimento, la descrizione di tali parametri viene ripetuta per ogni sorgente e sink nelle sezioni di documentazione, che spiegano i formati dei file di configurazione per vari tipi di sorgenti e sink. In tutti i casi, la sintassi e la semantica dei parametri con lo stesso nome sono identiche.
Sicurezza fonte e lavandino
Alcuni tipi di origine e sink dispongono di informazioni di sicurezza facoltative o obbligatorie a scopo di autenticazione.
Tutte le origini e i sink che utilizzano i servizi in Oracle Cloud Infrastructure (OCI) possono utilizzare determinati parametri per fornire informazioni di sicurezza opzionali. Queste informazioni possono essere fornite utilizzando un file di configurazione OCI o un principal dell'istanza.
Le origini e gli sink di Oracle NoSQL Database richiedono informazioni di sicurezza obbligatorie se l'installazione è sicura e utilizza un'autenticazione basata su Oracle Wallet. Queste informazioni possono essere fornite aggiungendo un file jar alla directory <MIGRATOR_HOME>/lib.
Autenticazione con i principal delle istanze
I principal delle istanze sono una funzione del servizio IAM che consente alle istanze di essere attori (o principal) autorizzati in grado di eseguire azioni sulle risorse del servizio. Ogni istanza di computazione ha la propria identità e viene autenticata utilizzando i certificati aggiunti.
Oracle NoSQL Database Migrator offre un'opzione per connettersi a origini e sink di NoSQL cloud e OCI Object Storage utilizzando l'autenticazione del principal dell'istanza. È supportato solo quando lo strumento NoSQL Database Migrator viene utilizzato all'interno di un'istanza di computazione OCI, ad esempio lo strumento NoSQL Database Migrator in esecuzione in una VM ospitata su OCI. Per abilitare questa funzione, utilizzare l'attributo useInstancePrincipal del file di configurazione dell'origine e del sink cloud NoSQL. Per ulteriori informazioni sui parametri di configurazione per diversi tipi di origini e sink, vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Per ulteriori informazioni sui principal delle istanze, vedere Chiamata di servizi da un'istanza.
Autorizzazione nelle origini e negli sink di Oracle NoSQL Database Cloud Service
L'accesso alle risorse in Oracle NoSQL Database Cloud Service, ad esempio tabelle, tablespace e API, viene gestito tramite criteri IAM (Identity and Access Management). Ciò garantisce che solo gli utenti o le applicazioni con le autorizzazioni di ispezione, lettura, uso o gestione delle tabelle appropriate all'interno di un compartimento specifico possano interagire con queste risorse. Per ulteriori informazioni, vedere Gestione dell'accesso alle tabelle NDCS.
Quando si utilizza la utility Migrator per importare o esportare dati dalle tabelle di Oracle NoSQL Database Cloud Service, le autorizzazioni IAM effettive determinano le risorse da cui è possibile leggere o scrivere. Se un utente di un gruppo definito tenta di eseguire un'azione oltre i privilegi autorizzati, la utility Migrator restituisce l'errore di autorizzazione corrispondente fornito da OCI IAM.
Ad esempio, IAM OCI nega qualsiasi tentativo di importazione di dati in una tabella di Oracle NoSQL Database Cloud Service se il gruppo di utenti dispone solo dell'autorizzazione di "lettura" sulla tabella. Viene visualizzato un messaggio d'errore simile a quello visualizzato nei log:
[INSUFFICIENT_PERMISSION] Authorization failed or requested resource not foundWorkflow per Oracle NoSQL Database Migrator
Informazioni sui vari passi necessari per utilizzare la utility Oracle NoSQL Database Migrator per la migrazione dei dati NoSQL.
Il flusso di alto livello dei task coinvolti nell'utilizzo di NoSQL Database Migrator è illustrato nella figura riportata di seguito.
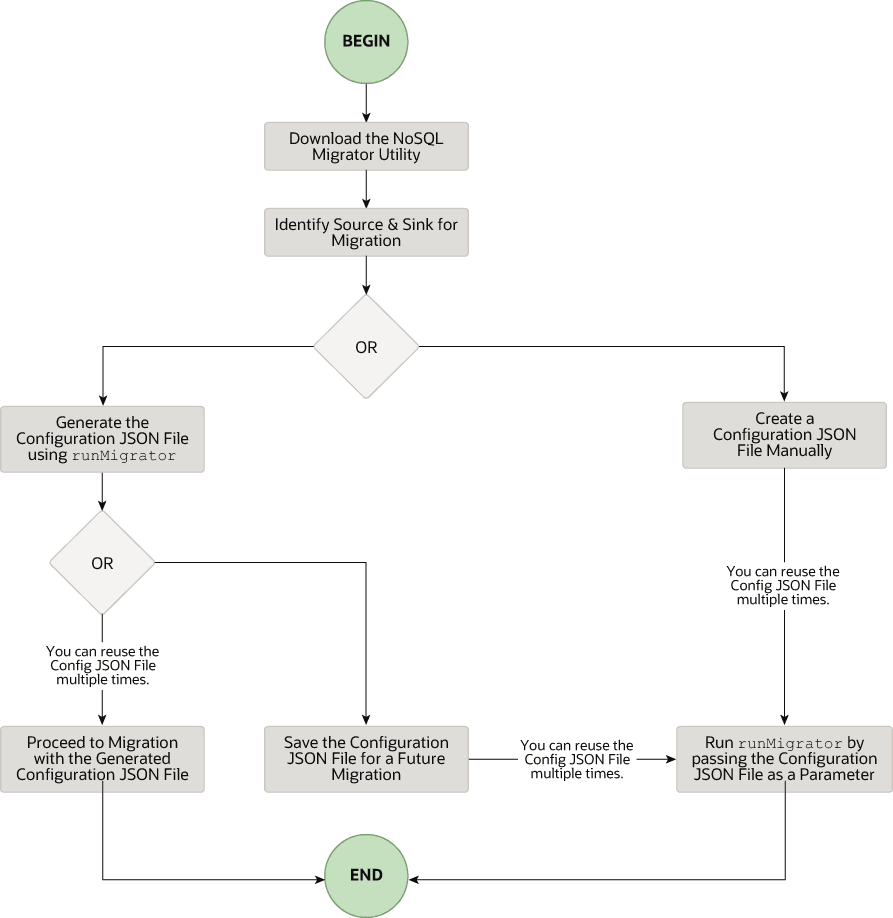
Descrizione dell'immagine migrator_flow.png
Scaricare la utility NoSQL Data Migrator
La utility Migrator di Oracle NoSQL Database è disponibile per il download dalla pagina Download Oracle NoSQL. Una volta scaricato e decompresso il file sul computer, è possibile accedere al comando runMigrator dall'interfaccia della riga di comando.
Nota: la utility Oracle NoSQL Database Migrator richiede l'esecuzione di Java 11 o versioni successive.
Identificare l'origine e il lavandino
Prima di utilizzare il migratore, è necessario identificare l'origine dati e il sink. Ad esempio, se si desidera eseguire la migrazione di una tabella NoSQL da Oracle NoSQL Database in locale a un file formattato JSON, l'origine sarà Oracle NoSQL Database e sink sarà un file JSON. Assicurarsi che l'origine e l' sink identificati siano supportati da Oracle NoSQL Database Migrator facendo riferimento alle origini e ai lavandini supportati. Questa è anche una fase appropriata per decidere lo schema per la tabella NoSQL nella destinazione o nel sink e crearli.
-
Identificare lo schema della tabella sink: se il sink è Oracle NoSQL Database in locale o nel cloud, è necessario identificare lo schema per la tabella sink e assicurarsi che i dati di origine corrispondano allo schema di destinazione. Se necessario, utilizzare le trasformazioni per mappare i dati di origine alla tabella sink.
-
Schema predefinito: NoSQL Database Migrator fornisce un'opzione per creare una tabella sink con lo schema predefinito senza dover predefinire lo schema per la tabella.
JSON in formato MongoDB:
Se l'origine è un file JSON in formato MongoDB, lo schema predefinito per la tabella sarà il seguente:
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id))dove:
-
tablename = valore fornito per l'attributo tabella nella configurazione.
-
id = _id valore di ogni documento del file di origine JSON esportato da MongoDB.
-
document = Per ogni documento nel file esportato MongoDB, il contenuto escluso il campo
_idviene aggregato nella colonna del documento.
Nota:
- Se il valore _id non viene fornito come stringa nel file JSON in formato MongoDB, NoSQL Database Migrator lo converte in una stringa prima di inserirlo nello schema predefinito.
- Se la tabella
<tablename>esiste già in Oracle NoSQL Database on premise o nel cloud e si desidera eseguire la migrazione dei dati alla tabella utilizzando la configurazionedefaultSchema, è necessario assicurarsi che la tabella esistente disponga della colonna ID in lettere minuscole (ID) e sia di tipo STRING.
JSON in formato DynamoDB:
Se l'origine è un file JSON in formato DynamoDB, lo schema predefinito per la tabella sarà il seguente:
CREATE TABLE IF NOT EXISTS <tablename>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type],DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))dove:
-
tablename = valore fornito per la tabella sink nella configurazione
-
DDBPartitionKey_name = valore fornito per la chiave di partizione nella configurazione
-
DDBPartitionKey_type = valore fornito per il tipo di dati della chiave di partizione nella configurazione
-
DDBSortKey_name = valore fornito per la chiave di ordinamento nella configurazione, se presente
-
DDBSortKey_type = valore fornito per il tipo di dati della chiave di ordinamento nella configurazione, se presente
-
DOCUMENT = Tutti gli attributi tranne la partizione e la chiave di ordinamento di un elemento di tabella DynamoDB aggregato in una colonna JSON NoSQL
Se il formato di origine è un file CSV, non è supportato uno schema predefinito per la tabella di destinazione. È possibile creare un file di schema con una definizione di tabella contenente lo stesso numero di colonne e tipi di dati del file CSV di origine. Per ulteriori dettagli sulla creazione del file di schema, vedere Fornitura dello schema di tabella.
Altre fonti valide:
Per tutte le altre origini, lo schema predefinito sarà il seguente:
CREATE TABLE IF NOT EXISTS <tablename> (id LONG GENERATED ALWAYS AS IDENTITY, document JSON, PRIMARY KEY(id))dove:
-
tablename = valore fornito per l'attributo tabella nella configurazione.
-
id = valore LONG generato automaticamente.
-
document = Il record JSON fornito dall'origine viene aggregato nella colonna del documento.
-
-
-
Fornitura dello schema di tabella: NoSQL Database Migrator consente all'origine di fornire definizioni di schema per i dati di tabella utilizzando l'attributo schemaInfo. L'attributo schemaInfo è disponibile in tutte le origini dati per le quali non è già stato definito uno schema implicito. I data store dei lavandini possono scegliere una delle seguenti opzioni.
-
Utilizzare lo schema predefinito definito da NoSQL Database Migrator.
-
Utilizzare lo schema fornito dall'origine.
-
Eseguire l'override dello schema fornito dall'origine definendone lo schema. Ad esempio, se si desidera trasformare i dati dallo schema di origine in un altro schema, è necessario sostituire lo schema fornito dall'origine e utilizzare la funzionalità di trasformazione dello strumento NoSQL Database Migrator.
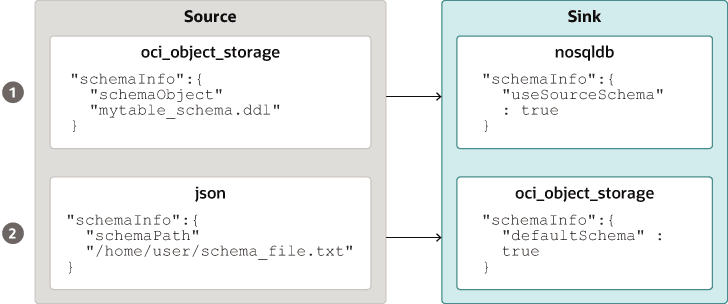
Descrizione dell'immagine source_sink_schema_example.png
Il file di schema della tabella, ad esempio
mytable_schema.ddl, può includere istruzioni DDL della tabella. Lo strumento NoSQL Database Migrator esegue questo file di schema di tabella prima di avviare la migrazione. Lo strumento di migrazione supporta non più di un'istruzione DDL per riga nel file di schema. Di seguito sono riportati alcuni esempi.CREATE TABLE IF NOT EXISTS(id INTEGER, name STRING, age INTEGER, PRIMARY KEY(SHARD(ID))) -
Nota: la migrazione non riuscirà se la tabella è presente nel sink e il DDL in schemaPath è diverso dalla tabella.
- Crea tabella di collegamento: una volta identificato lo schema della tabella di collegamento, creare la tabella di collegamento tramite l'interfaccia CLI di amministrazione oppure utilizzando l'attributo
schemaInfodel file di configurazione del sink. Vedere Modelli di configurazione del collegamento.
Nota: se l'origine è un file CSV, creare un file con i comandi DDL per lo schema della tabella di destinazione. Fornire il percorso del file nel parametro schemaInfo.schemaPath del file di configurazione del sink.
Eseguire il comando runMigrator
Il file eseguibile runMigrator è disponibile nei file NoSQL Database Migrator estratti. Per eseguire correttamente il comando runMigrator, è necessario installare Java 11 o versione successiva e bash sul sistema.
È possibile eseguire il comando runMigrator nei due modi indicati di seguito.
-
Creando il file di configurazione utilizzando le opzioni di runtime del comando
runMigratorcome mostrato di seguito.[~]$ ./runMigrator configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y ... ...-
Quando si richiama la utility
runMigrator, vengono fornite una serie di opzioni di runtime e viene creato il file di configurazione in base alle scelte effettuate per ciascuna opzione. -
Dopo aver creato il file di configurazione, è possibile scegliere se continuare l'attività di migrazione nella stessa esecuzione o salvare il file di configurazione per una migrazione futura.
-
Indipendentemente dalla decisione di procedere o differire l'attività di migrazione con il file di configurazione generato, il file sarà disponibile per le modifiche o la personalizzazione per soddisfare i requisiti futuri. È possibile utilizzare il file di configurazione personalizzato per la migrazione in un secondo momento.
-
-
Passando un file di configurazione creato manualmente (in formato JSON) come parametro di runtime utilizzando l'opzione
-co--config. È necessario creare il file di configurazione manualmente prima di eseguire il comandorunMigratorcon l'opzione-co--config. Per informazioni sui parametri di configurazione di origine e sink, vedere Oracle NoSQL Database Migrator Reference.[~]$ ./runMigrator -c </path/to/the/configuration/json/file>
Nota: NoSQL Database Migrator utilizza le unità di lettura durante l'esecuzione dell'esportazione dei dati dalla tabella Oracle NoSQL Cloud Service in qualsiasi sink valido.
Avanzamento migrazione log
Lo strumento NoSQL Database Migrator fornisce opzioni che consentono di stampare i messaggi di trace, debug e avanzamento nell'output standard o in un file. Questa opzione può essere utile per tenere traccia dell'avanzamento dell'operazione di migrazione, in particolare per tabelle o data set molto grandi.
-
Livelli di log
Per controllare il funzionamento del log mediante lo strumento NoSQL Database Migrator, passare il parametro di runtime -log-level o -l al comando
runMigrator. È possibile specificare la quantità di informazioni di log da scrivere passando il valore del livello di log appropriato.$./runMigrator --log-level <loglevel>Esempio:
$./runMigrator --log-level debugTabella - Livelli di log supportati per NoSQL Database Migrator
Livello di log Descrizione avvertenza Stampa errori e avvertenze. informazioni (predefinite) Stampa lo stato di avanzamento della migrazione dei dati, ad esempio la convalida dell'origine, la convalida del sink, la creazione di tabelle e il conteggio del numero di record di dati migrati. debug Stampa informazioni di debug aggiuntive. all Stampa tutto. Questo livello attiva tutti i livelli di registrazione. -
File di log:
È possibile specificare il nome del file di log utilizzando il parametro -log-file o -f. Se -log-file viene passato come parametro di runtime al comando
runMigrator, NoSQL Database Migrator scrive tutti i messaggi di log nel file in altro modo nell'output standard.$./runMigrator --log-file <log file name>Esempio:
$./runMigrator --log-file nosql_migrator.log
Limitazione
Oracle NoSQL Database Migrator non blocca il database durante il backup e blocca altri utenti. Pertanto, è consigliabile non eseguire le seguenti attività quando è in esecuzione un task di migrazione:
-
Qualsiasi operazione DML/DDL nella tabella di origine.
-
Qualsiasi modifica correlata alla topologia nel data store.
Migrazione dei metadati TTL per le righe tabella
Scopri come migrare i dati TTL dall'origine al sink.
Time to Live (TTL) è un meccanismo che consente di scadere automaticamente le righe della tabella. TTL è espresso come la quantità di tempo, i dati è consentito di vivere nel negozio. I dati che hanno raggiunto il valore di timeout di scadenza non possono più essere recuperati e non verranno visualizzati in alcuna statistica del negozio.
È possibile scegliere di includere i metadati TTL per le righe di tabella insieme ai dati effettivi durante l'esecuzione della migrazione delle tabelle di Oracle NoSQL Database. NoSQL Database Migrator fornisce parametri di configurazione per supportare l'esportazione e l'importazione dei metadati TTL delle righe di tabella per i tipi di origine seguenti:
Tabella - Migrazione dei metadati TTL
| Tipi di origine | Parametro di configurazione origine | Parametro di configurazione del lavandino |
|---|---|---|
| Oracle NoSQL Database | includeTTL |
includeTTL |
| Oracle NoSQL Database Cloud Service | includeTTL |
includeTTL |
| File JSON formattato DynamoDB | ttlAttributeName |
includeTTL |
| File JSON formattato DynamoDB memorizzato in AWS S3 | ttlAttributeName |
includeTTL |
Esportazione dei metadati TTL in Oracle NoSQL Database e Oracle NoSQL Database Cloud Service
NoSQL Database Migrator fornisce il parametro di configurazione includeTTL per supportare l'esportazione dei metadati TTL della riga della tabella.
Quando viene esportata una tabella, i dati TTL vengono esportati per le righe della tabella con un'ora di scadenza valida. Se una riga non scade, l'oggetto JSON _metadata non viene incluso in modo esplicito nei dati esportati perché il relativo valore di scadenza è sempre
- NoSQL Database Migrator esporta il tempo di scadenza per ogni riga come numero di millisecondi dall'epoca UNIX (1 gennaio 1970). Di seguito sono riportati alcuni esempi.
//Row 1
{
"id" : 1,
"name" : "xyz",
"age" : 45,
"_metadata" : {
"expiration" : 1629709200000 //Row Expiration time in milliseconds
}
}
//Row 2
{
"id" : 2,
"name" : "abc",
"age" : 52,
"_metadata" : {
"expiration" : 1629709400000 //Row Expiration time in milliseconds
}
}
//Row 3 No Metadata for below row as it will not expire
{
"id" : 3,
"name" : "def",
"age" : 15
}Importazione dei metadati TTL
Facoltativamente, è possibile importare i metadati TTL utilizzando il parametro di configurazione includeTTL nel modello di configurazione sink.
Il tempo di riferimento predefinito dell'operazione di importazione è il tempo corrente in millisecondi, ottenuto da System.currentTimeMillis(), del computer in cui è in esecuzione lo strumento NoSQL Database Migrator. Tuttavia, è anche possibile impostare un tempo di riferimento personalizzato utilizzando il parametro di configurazione ttlRelativeDate se si desidera estendere l'ora di scadenza e importare le righe che altrimenti scadrebbero immediatamente. L'estensione viene calcolata come segue e aggiunta all'ora di scadenza.
Extended time = expiration time - reference timeL'operazione di importazione gestisce i seguenti casi d'uso durante la migrazione delle righe di tabella contenenti metadati TTL. Questi casi d'uso sono applicabili solo quando il parametro di configurazione includeTTL è impostato su true.
-
Caso d'uso 1: non sono presenti informazioni sui metadati TTL nella riga della tabella di importazione.
Se la riga che si desidera importare non contiene informazioni TTL, NoSQL Database Migrator imposta TTL=0 per la riga.
-
Caso d'uso 2: il valore TTL della riga della tabella di origine è scaduto rispetto al tempo di riferimento quando la riga della tabella viene importata.
La riga della tabella scaduta viene ignorata e non viene scritta nel negozio.
-
Caso d'uso 3: il valore TTL della riga della tabella di origine non è scaduto rispetto al tempo di riferimento quando la riga della tabella viene importata.
La riga della tabella viene importata con un valore TTL. Tuttavia, il valore TTL importato potrebbe non corrispondere al valore TTL esportato originale a causa dei vincoli della finestra di ore e giorni interi nella classe TimeToLive. Di seguito sono riportati alcuni esempi.
Prendere in considerazione una riga di tabella esportata:
{ "id" : 8, "name" : "xyz", "_metadata" : { "expiration" : 1734566400000 //Thursday, December 19, 2024 12:00:00 AM in UTC } }Il tempo di riferimento durante l'importazione è 1734480000000, che è mercoledì 18 dicembre 2024 12:00:00 AM.
Riga tabella importata
{ "id" : 8, "name" : "xyz", "_metadata" : { "ttl" : 1734739200000 //Saturday, December 21, 2024 12:00:00 AM } }
Importazione di metadati TTL nel file JSON formattato DynamoDB e nel file JSON formattato DynamoDB memorizzato in AWS S3
NoSQL Database Migrator fornisce un parametro di configurazione aggiuntivo, ttlAttributeName, per supportare l'importazione dei metadati TTL dagli elementi di file JSON in formato DynamoDB.
I file JSON esportati da DynamoDB includono un attributo specifico in ogni elemento per memorizzare l'indicatore orario di scadenza TTL. Per importare facoltativamente i valori TTL dai file JSON esportati da DynamoDB, è necessario fornire il nome dell'attributo specifico come valore al parametro di configurazione ttlAttributeName nei file di configurazione di origine DynamoDB-Formatted JSON File o DynamoDB-Formatted JSON File memorizzati in AWS S3. Inoltre, è necessario impostare il parametro di configurazione includeTTL nel modello di configurazione sink. I sink validi sono Oracle NoSQL Database e Oracle NoSQL Database Cloud Service. NoSQL Database Migrator memorizza le informazioni TTL nell'oggetto JSON _metadata per l'elemento importato.
L'operazione di importazione gestisce i seguenti casi d'uso durante la migrazione degli elementi di tabella dei file JSON esportati da DynamoDB:
-
Caso d'uso 1: il valore del parametro di configurazione ttlAttributeName è impostato sul nome dell'attributo TTL specificato nel file JSON esportato da DynamoDB.
NoSQL Database Migrator importa il tempo di scadenza per questo elemento come numero di millisecondi dall'epoca UNIX (1 gennaio 1970).
Ad esempio, si consideri un elemento nel file JSON esportato DynamoDB:
{ "Item": { "DeptId": { "N": "1" }, "DeptName": { "S": "Engineering" }, "ttl": { "N": "1734616800" } } }L'attributo
ttlspecifica il valore time-to-live dell'articolo. Se si imposta il parametro di configurazione ttlAttributeName comettlnel file JSON in formato DynamoDB o nel file JSON in formato DynamoDB memorizzato nel file di configurazione di origine S3 AWS, NoSQL Database Migrator importa l'ora di scadenza dell'elemento come indicato di seguito.{ "DeptId": 1, "document": { "DeptName": "Engineering" } "_metadata": { "expiration": 1734616800000 } }
Nota: è possibile specificare il parametro di configurazione ttlRelativeDate nel modello di configurazione sink come tempo di riferimento per il calcolo dell'ora di scadenza.
-
Caso d'uso 2: il valore del parametro di configurazione ttlAttributeName è impostato, tuttavia il valore non esiste come attributo nell'elemento del file JSON esportato DynamoDB.
NoSQL Database Migrator non importa le informazioni dei metadati TTL per l'elemento specificato.
-
Caso d'uso 3: il valore del parametro di configurazione ttlAttributeName non corrisponde al nome dell'attributo nell'elemento del file JSON esportato DynamoDB. NoSQL Database Migrator gestisce l'importazione in uno dei modi seguenti in base alla configurazione del sink:
-
Copia l'attributo come campo normale se configurato per l'importazione utilizzando lo schema predefinito.
-
Salta l'attributo se configurato per l'importazione utilizzando uno schema definito dall'utente.
-
Importazione di dati in un sink con una colonna IDENTITY
Informazioni su come importare i dati in un sink che include una colonna IDENTITY.
È possibile importare i dati da un'origine valida a una tabella sink (Servizi in locale/Cloud) con una colonna IDENTITY. La colonna IDENTITY viene creata come GENERATA SEMPRE AS IDENTITY o GENERATA DA DEFAULT AS IDENTITY. Per ulteriori informazioni sulla creazione di tabelle con una colonna IDENTITY, vedere Creazione di tabelle con una colonna IDENTITY in SQL Reference Guide.
Prima di importare i dati, assicurarsi che la tabella Oracle NoSQL Database nel sink sia vuota se esiste. Se nella tabella sink sono presenti dati preesistenti, la migrazione può portare a problemi quali la sovrascrittura dei dati esistenti nella tabella sink o l'eliminazione dei dati di origine durante l'importazione.
Tavola lavello con colonna IDENTITY come GENERATA SEMPRE COME IDENTITÀ
Si consideri una tabella sink con la colonna IDENTITY creata come GENERATED ALWAYS AS IDENTITY. L'importazione dei dati dipende dal fatto che l'origine fornisca o meno i valori alla colonna IDENTITY e dal parametro di trasformazione ignoreFields nel file di configurazione.
Ad esempio, si desidera importare i dati da un'origine file JSON nella tabella Oracle NoSQL Database come sink. Lo schema della tabella sink è:
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED ALWAYS AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))La utility Migrator gestisce la migrazione dei dati come descritto nei casi riportati di seguito.
| Condizione di origine | Azione utente | Risultato migrazione |
|---|---|---|
|
CASO 1: i dati di origine non forniscono un valore per il campo IDENTITY della tabella sink. Esempio: file di origine JSON |
Creare/generare il file di configurazione. |
Migrazione dei dati riuscita. I valori della colonna IDENTITY vengono generati automaticamente. Dati migrati nella tabella sink di Oracle NoSQL Database |
|
CASE 2: i dati di origine forniscono i valori per il campo IDENTITY della tabella sink. Esempio: file di origine JSON |
Creare/generare il file di configurazione. È possibile fornire una trasformazione ignoreFields per la colonna ID nel modello di configurazione sink.
|
Migrazione dei dati riuscita. I valori ID forniti vengono ignorati e i valori della colonna IDENTITY vengono generati automaticamente. Dati migrati nella tabella sink di Oracle NoSQL Database |
|
Creare/generare il file di configurazione senza la trasformazione ignoreFields per la colonna IDENTITY. |
Migrazione dei dati non riuscita con il seguente messaggio di errore:
|
Per ulteriori dettagli sui parametri di configurazione della trasformazione, vedere l'argomento Modelli di configurazione della trasformazione.
Tabella lavello con colonna IDENTITY generata da IDENTITY predefinito
Si consideri una tabella sink con la colonna IDENTITY creata come GENERATED BY DEFAULT AS IDENTITY. L'importazione dei dati dipende dal fatto che l'origine fornisca o meno i valori alla colonna IDENTITY e dal parametro di trasformazione ignoreFields.
Ad esempio, si desidera importare i dati da un'origine file JSON nella tabella Oracle NoSQL Database come sink. Lo schema della tabella sink è:
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED BY DEFAULT AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))La utility Migrator gestisce la migrazione dei dati come descritto nei casi riportati di seguito.
| Condizione di origine | Azione utente | Risultato migrazione |
|---|---|---|
|
CASO 1: i dati di origine non forniscono un valore per il campo IDENTITY della tabella sink. Esempio: file di origine JSON |
Creare/generare il file di configurazione. |
Migrazione dei dati riuscita. I valori della colonna IDENTITY vengono generati automaticamente. Dati migrati nella tabella sink di Oracle NoSQL Database |
|
CASE 2: i dati di origine forniscono valori per il campo IDENTITY della tabella sink ed è un campo di chiave primaria. Esempio: file di origine JSON |
Creare/generare il file di configurazione. Fornire una trasformazione ignoreFields per la colonna ID nel modello di configurazione sink (consigliato).
|
Migrazione dei dati riuscita. I valori ID forniti vengono ignorati e i valori della colonna IDENTITY vengono generati automaticamente. Dati migrati nella tabella sink di Oracle NoSQL Database |
|
Creare/generare il file di configurazione senza la trasformazione ignoreFields per la colonna IDENTITY. |
Migrazione dei dati riuscita. I valori Quando si tenta di inserire una riga aggiuntiva nella tabella senza fornire un valore ID, il generatore di sequenze tenta di generare automaticamente il valore ID. Il valore iniziale del generatore di sequenze è 1. Di conseguenza, il valore ID generato può potenzialmente duplicare uno dei valori ID esistenti nella tabella sink. Poiché si tratta di una violazione del vincolo della chiave primaria, viene restituito un errore e la riga non viene inserita. Per ulteriori informazioni, vedere Generatore sequenze. Per evitare la violazione del vincolo di chiave primaria, il generatore di sequenze deve avviare la sequenza con un valore che non sia in conflitto con i valori ID esistenti nella tabella sink. Per utilizzare l'attributo START WITH per apportare questa modifica, vedere l'esempio riportato di seguito. Esempio: dati migrati nella tabella sink di Oracle NoSQL Database Per trovare il valore appropriato per il generatore di sequenze da inserire nella colonna ID, recuperare il valore massimo del campo Output: Il valore massimo della colonna La sequenza verrà avviata a 4. Ora, quando si inseriscono righe nella tabella sink senza fornire i valori ID, il generatore di sequenza genera automaticamente i valori ID da 4 in poi evitando la duplicazione degli ID. |
Per ulteriori dettagli sui parametri di configurazione della trasformazione, vedere l'argomento Modelli di configurazione della trasformazione.
Filtro dei dati mediante i predicati query
Informazioni su come specificare i predicati query per esportare solo le righe di tabella che corrispondono ai criteri di filtro.
Predicato query
NoSQL Database Migrator fornisce un'opzione per filtrare i dati durante l'esportazione specificando un predicato query. Il predicato query specifica le condizioni che devono essere soddisfatte affinché una riga venga esportata. La utility Migrator converte il predicato query in una clausola SQL WHERE e lo applica alla tabella specificata per fornire una condizione di filtro per esportare solo le righe corrispondenti alla condizione specificata. È possibile utilizzare le funzioni incorporate (modification_time(), expiration_time(), creation_time()) nel predicato query per creare opzioni di filtro avanzate.
È possibile utilizzare i predicati query solo sulle origini di Oracle NoSQL Database e Oracle NoSQL Database Cloud Service per tutti i sink supportati. Per ulteriori dettagli, consulta Oracle NoSQL Database e Oracle NoSQL Database Cloud Service.
Per una dimostrazione del caso d'uso, consulta la sezione relativa alla migrazione da Oracle NoSQL Database Cloud Service a un file JSON.
Filtro di dump
La utility Migrator fornisce un'opzione per eseguire l'eco della query SQL eseguita sul backend. Questa funzione consente di verificare la query generata e, se necessario, perfezionare il filtro prima di eseguire il task di migrazione.
È possibile eseguire la utility Migrator con l'opzione di filtro dump come indicato di seguito.
[~/nosqlMigrator]$./runMigrator --dump-filter|df [optional-config-file]-
Con il file di configurazione: la utility Migrator visualizza il file di configurazione fornito e la query generata, come mostrato nell'esempio riportato di seguito.
[~/nosqlMigrator]./runMigrator --dump-filter migrator-config.json[INFO] Configuration for migration: { "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "users", "queryFilter" : "$row.address.city='Houston'", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : false, "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "pretty" : true, "dataPath" : "<complete/path/to/directory>" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] Query for the migration: 'select $row, expiration_time($row) from users $row where $row.address.city='Houston'' -
Senza il file di configurazione: la utility Migrator raccoglie in modo interattivo tutti gli input necessari per generare il file di configurazione, incluso il predicato query. Visualizza quindi il file di configurazione e la query generati.
Nota:
L'opzione di filtro di dump visualizza solo il file di configurazione e la query. Non avvia la migrazione dei dati. Dopo la revisione, per eseguire la migrazione, eseguire la utility Migrator con il file di configurazione utilizzando l'opzione
--co--configcome indicato di seguito.$./runMigrator --config <complete/path/to/the/JSON/config/file>
Dimostrazioni dei casi d'uso per Oracle NoSQL Database Migrator
Scopri come eseguire la migrazione dei dati utilizzando Oracle NoSQL Database Migrator per casi d'uso specifici. È possibile trovare istruzioni dettagliate e sistematiche con esempi di codice per eseguire la migrazione in ciascuno dei casi d'uso.
Questo articolo contiene i seguenti argomenti:
Eseguire la migrazione da Oracle NoSQL Database Cloud Service a un file JSON
Questo esempio mostra come utilizzare Oracle NoSQL Database Migrator per copiare i dati e la definizione dello schema di una tabella NoSQL da Oracle NoSQL Database Cloud Service (NDCS) in un file JSON.
Caso d'uso
Un'organizzazione decide di addestrare un modello utilizzando i dati Oracle NoSQL Database Cloud Service (NDCS) per prevedere i comportamenti futuri e fornire suggerimenti personalizzati. Possono trasferire una copia periodica dei dati delle tabelle NDCS in un file JSON e applicarla al motore analitico per analizzare e addestrare il modello. In questo modo è possibile separare le query analitiche dai percorsi critici a bassa latenza.
Esempio
Per la dimostrazione, esaminiamo come eseguire la migrazione della definizione dei dati e dello schema di una tabella NoSQL denominata myTable da NDCS a un file JSON.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: Oracle NoSQL Database Cloud Service
-
Lavello: file JSON
-
-
Identificare le credenziali cloud OCI e acquisirle nel file di configurazione OCI. Salvare il file di configurazione in
/home/.oci/config. Vedere Acquisizione delle credenziali.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identificare l'endpoint dell'area e il nome del compartimento per Oracle NoSQL Database Cloud Service.
-
endpoint:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aa..rhsmq
-
Procedura
Per eseguire la migrazione della definizione dei dati e dello schema della tabella da Oracle NoSQL Database Cloud Service a un file JSON, è possibile utilizzare una delle opzioni riportate di seguito.
-
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Per generare il file di configurazione utilizzando NoSQL Database Migrator, eseguire il comando
runMigratorsenza alcun parametro di runtime.[~/nosqlMigrator]$./runMigrator -
Poiché il file di configurazione non è stato fornito come parametro di runtime, l'utility richiede se si desidera generare la configurazione ora. Digitare
**y**.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. -
In base ai prompt della utility, scegliere le opzioni per la configurazione di origine.
Enter a location for your config [./migrator-config.json]: /home/<user>/nosqlMigrator/NDCS2JSON Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 2 Configuration for source type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-phoenix-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: developers Enter table name: myTable Include TTL data? If you select 'yes' TTL of rows will also be included in the exported data.(y/n) [n]: Enter percentage of table read units to be used for migration operation. (1-100) [90]: Enter store operation timeout in milliseconds. (1-30000) [5000]: -
In base ai prompt dell'utility, scegliere le opzioni per la configurazione del lavandino.
Select the sink: 1) nosqldb 2) nosqldb_cloud 3) file #? 3 Configuration for sink type=file Enter path to a directory to store JSON data: /home/<user>/nosqlMigrator would you like to export data to multiple files for each source?(y/n) [y]: n Would you like to store JSON in pretty format? (y/n) [n]: y Would you like to migrate the table schema also? (y/n) [y]: y Enter path to a file to store table schema: /home/<user>/nosqlMigrator/myTableSchema -
In base ai prompt della utility, scegliere le opzioni per le trasformazioni dei dati di origine. Il valore predefinito è
n.Would you like to add transformations to source data? (y/n) [n]: -
Immettere la scelta per determinare se procedere con la migrazione nel caso in cui la migrazione di un record non riesca.
Would you like to continue migration in case of any record/row is failed to migrate?: (y/n) [n]: -
La utility visualizza la configurazione generata sullo schermo.
generated configuration is: { "source": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "myTable", "compartment": "ocid1.compartment.oc1..aa..rhsmq", "credentials": "/home/<user>/.oci/config", "credentialsProfile": "DEFAULT", "readUnitsPercent": 90, "requestTimeoutMs": 5000 }, "sink": { "type": "file", "format": "json", "useMultiFiles" : false, "schemaPath": "/home/<user>/nosqlMigrator/myTableSchema", "pretty": true, "dataPath": "/home/<user>/nosqlMigrator" }, "abortOnError": true, "migratorVersion": "1.8.0" } -
L'utility richiede la scelta dell'utente per decidere se procedere o meno con la migrazione con il file di configurazione generato. L'opzione predefinita è
y.Nota: se si seleziona
n, è possibile utilizzare il file di configurazione generato per eseguire la migrazione utilizzando l'opzione./runMigrator -co./runMigrator --config.Would you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config /home/<user>/nosqlMigrator/NDCS2JSON (y/n) [y]: -
NoSQL Database Migrator migra i dati e lo schema da NDCS al file JSON.
Records provided by source=10,Records written to sink=10,Records failed=0,Records skipped=0. Elapsed time: 0min 1sec 277ms Migration completed.Convalida
Per convalidare la migrazione, è possibile passare alla directory sink specificata e visualizzare lo schema e i dati.
-- Exported myTable Data. JSON files are created in the supplied data path
[~/nosqlMigrator]$cat myTable_1_5.json
{
"id" : 10,
"document" : {
"course" : "Computer Science",
"name" : "Neena",
"studentid" : 105
}
}
{
"id" : 3,
"document" : {
"course" : "Computer Science",
"name" : "John",
"studentid" : 107
}
}
{
"id" : 4,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 6,
"document" : {
"course" : "Bio-Technology",
"name" : "Rekha",
"studentid" : 104
}
}
{
"id" : 7,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 5,
"document" : {
"course" : "Journalism",
"name" : "Rani",
"studentid" : 106
}
}
{
"id" : 8,
"document" : {
"course" : "Computer Science",
"name" : "Tom",
"studentid" : 103
}
}
{
"id" : 9,
"document" : {
"course" : "Computer Science",
"name" : "Peter",
"studentid" : 109
}
}
{
"id" : 1,
"document" : {
"course" : "Journalism",
"name" : "Tracy",
"studentid" : 110
}
}
{
"id" : 2,
"document" : {
"course" : "Bio-Technology",
"name" : "Raja",
"studentid" : 108
}
}-- Exported myTable Schema
[~/nosqlMigrator]$cat myTableSchema
CREATE TABLE IF NOT EXISTS myTable (id INTEGER, document JSON, PRIMARY KEY(SHARD(id)))-
Preparare il file di configurazione (in formato JSON) con l'origine Oracle NoSQL Database Cloud Service (NDCS) e i dettagli dell' sink JSON. Vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
In questo esempio viene utilizzata una tabella
userscon i dati seguenti:{"id":10,"firstName":"John","lastName":"Smith","age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008}} {"id":20,"firstName":"Jane","lastName":"Smith","age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005}} {"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}} {"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}Assicurarsi di includere il parametro
queryFiltercon il predicato query appropriato nel modello di configurazione di origine per esportare solo le righe richieste dalla tabella. Per informazioni dettagliate sulla creazione dei predicati query, vedere la tabella Previsioni query di esempio nell'argomento Origine servizio NoSQL Database Cloud.In questo esempio, il predicato query esporta le righe con il campo
citynella colonna JSONaddress= 'Houston' dalla tabellausers.{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "queryFilter" : "$row.address.city='Houston'", "compartment" : "ocid1.compartment.oc1..aa..rhsmq", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : true, "chunkSize" : 32, "schemaPath" : "/scratch/<user>/nosqlMigrator/tableschema.ddl", "pretty" : false, "dataPath" : "/scratch/<user>/nosqlMigrator" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione. Utilizzare l'opzione--configo-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file>Nota:
È inoltre possibile eseguire il comando con
opzione per visualizzare e verificare la query generata prima di eseguire il task di migrazione, come indicato di seguito. Per ulteriori dettagli, vedere
.
[~/nosqlMigrator]$./runMigrator --dump-filter <complete/path/to/the/JSON/config/file>La utility procede con la migrazione dei dati come indicato di seguito.
[INFO] creating source from given configuration: [INFO] [cloud source] : query = 'SELECT $row,expiration_time_millis($row) AS expiration FROM users $row where $row.address.city='Houston'' [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [json file sink] : writing table schema to /scratch/raumesh/nosqlMigrator/tableschema.ddl [INFO] migration started [INFO] Migration success for source users. read=2,written=2,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 182ms Migration completed.
Verifica
Per verificare la migrazione, è possibile passare alla directory sink specificata e visualizzare lo schema e i dati. Vengono esportate solo le righe nella colonna JSON address con il valore del campo city 'Houston'.
-- Exported users data. Schema and JSON files are created in the supplied data paths.
[~/nosqlMigrator]: cat tableschema.ddl
CREATE TABLE IF NOT EXISTS users (id INTEGER, firstName STRING, lastName STRING, age INTEGER, income INTEGER, address JSON, PRIMARY KEY(SHARD(id)))[~/nosqlMigrator]: cat users_6_10.json
{"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}}
{"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}
bash-4.4$Eseguire la migrazione da Oracle NoSQL Database On-Premise a Oracle NoSQL Database Cloud Service
Questo esempio mostra come utilizzare Oracle NoSQL Database Migrator per copiare i dati e la definizione dello schema di una tabella NoSQL da Oracle NoSQL Database a Oracle NoSQL Database Cloud Service (NDCS).
Caso d'uso
In qualità di sviluppatore, vengono esplorate le opzioni per evitare il sovraccarico dovuto alla gestione di risorse, cluster e garbage collection per i carichi di lavoro NoSQL Database KVStore esistenti. Come soluzione, decidi di eseguire la migrazione dei carichi di lavoro KVStore on-premise esistenti a Oracle NoSQL Database Cloud Service perché NDCS li gestisce automaticamente.
Esempio
Per la dimostrazione, esaminiamo come eseguire la migrazione della definizione dei dati e dello schema di una tabella NoSQL denominata myTable dal database NoSQL KVStore a NDCS. Utilizzeremo anche questo caso d'uso per mostrare come eseguire la utility runMigrator passando un file di configurazione precreato.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: Oracle NoSQL Database
-
Lavello: Oracle NoSQL Database Cloud Service
-
-
Identificare le credenziali cloud OCI e acquisirle nel file di configurazione OCI. Salvare il file di configurazione in
/home/.oci/config. Vedere Acquisizione delle credenziali in Utilizzo di Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identificare l'endpoint dell'area e il nome del compartimento per Oracle NoSQL Database Cloud Service.
-
endpoint:
us-phoenix-1 -
compartimento:
developers
-
-
Identificare i seguenti dettagli per il KVStore in locale:
-
storeName:
kvstore -
helperHosts:
<hostname>:5000 -
tabella:
myTable
-
Procedura
Per eseguire la migrazione della definizione di dati e schema di myTable da NoSQL Database KVStore a NDCS:
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e collegamento identificati. Vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "myTable", "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "myTable", "compartment" : "developers", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "readUnits" : 100, "writeUnits" : 100, "storageSize" : 1 }, "credentials" : "<complete/path/to/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione utilizzando l'opzione--configo-c.[~/nosqlMigrator/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati, come mostrato di seguito.
Records provided by source=10, Records written to sink=10, Records failed=0. Elapsed time: 0min 10sec 426ms Migration completed.
Convalida
Per convalidare la migrazione, è possibile eseguire il login alla console NDCS e verificare che myTable venga creato con i dati di origine.
Esegui migrazione da origine file JSON a Oracle NoSQL Database Cloud Service
Questo esempio mostra l'uso di Oracle NoSQL Database Migrator per copiare i dati da un'origine file JSON a Oracle NoSQL Database Cloud Service.
Dopo aver valutato più opzioni, un'organizzazione finalizza Oracle NoSQL Database Cloud Service come piattaforma di database NoSQL. Poiché i contenuti di origine sono in formato file JSON, stanno cercando un modo per eseguirne la migrazione a Oracle NoSQL Database Cloud Service.
In questo esempio, verrà descritto come eseguire la migrazione dei dati da un file JSON denominato SampleData.json. Per eseguire la utility runMigrator, passare un file di configurazione creato in precedenza. Se il file di configurazione non viene fornito come parametro di runtime, la utility runMigrator richiede di generare la configurazione mediante una procedura interattiva.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: file di origine JSON.
SampleData.jsonè il file di origine. Contiene più documenti JSON con un documento per riga, delimitati da un nuovo carattere di riga.{"id":6,"val_json":{"array":["q","r","s"],"date":"2023-02-04T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-03-04T02:38:57.520Z","numfield":30,"strfield":"foo54"},{"datefield":"2023-02-04T02:38:57.520Z","numfield":56,"strfield":"bar23"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":3,"val_json":{"array":["g","h","i"],"date":"2023-02-02T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-02T02:38:57.520Z","numfield":28,"strfield":"foo3"},{"datefield":"2023-02-02T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":7,"val_json":{"array":["a","b","c"],"date":"2023-02-20T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-01-20T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-01-22T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":4,"val_json":{"array":["j","k","l"],"date":"2023-02-03T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-03T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-02-03T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} -
Lavello: Oracle NoSQL Database Cloud Service.
-
-
Identificare le credenziali cloud OCI e acquisirle nel file di configurazione OCI. Salvare il file di configurazione nella directory
/home/<user>/.oci/config. Per ulteriori dettagli, vedere Acquisizione delle credenziali in Uso di Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identificare l'endpoint dell'area e il nome del compartimento per Oracle NoSQL Database Cloud Service.
-
endpoint:
us-ashburn-1 -
compartimento:
Training-NoSQL
-
-
Identificare i seguenti dettagli per il file di origine JSON:
-
schemaPath:
<absolute path to the schema definition file containing DDL statements for the NoSQL table at the sink>.In questo esempio, il file DDL è
schema_json.ddl.create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id));Oracle NoSQL Database Migrator fornisce un'opzione per creare una tabella con lo schema predefinito se
schemaPathnon viene fornito. Per ulteriori dettagli, vedere l'argomento Identificare l'origine e ilink in Workflow per Oracle NoSQL Database Migrator. -
Percorso dati:
<absolute path to a file or directory containing the JSON data for migration>.
-
Procedura
Per eseguire la migrazione del file di origine JSON da SampleData.json a Oracle NoSQL Database Cloud Service, effettuare le operazioni riportate di seguito.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e sink identificati. Vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
{ "source" : { "type" : "file", "format" : "json", "schemaInfo" : { "schemaPath" : "[~/nosql-migrator-1.8.0]/schema_json.ddl" }, "dataPath" : "[~/nosql-migrator-1.8.0]/SampleData.json" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "Migrate_JSON", "compartment" : "Training-NoSQL", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Aprire il prompt dei comandi e andare alla directory in cui è stata estratta la utility Migrator di Oracle NoSQL Database.
-
Eseguire il comando
runMigratorpassando il file di configurazione utilizzando l'opzione--configo-c.[~/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/config/file> -
La utility procede con la migrazione dei dati, come mostrato di seguito. La tabella
Migrate_JSONviene creata nel sink con lo schema fornito nel fileschemaPath.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records [json file source] : start parsing JSON records from file: SampleData.json [INFO] migration completed. Records provided by source=4, Records written to sink=4, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 778ms Migration completed.
Convalida
Per convalidare la migrazione, è possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la tabella Migrate_JSON venga creata con i dati di origine. Per la procedura di accesso alla console, vedere l'articolo Accesso al servizio dalla console dell'infrastruttura nel documento Oracle NoSQL Database Cloud Service.
Figura - Tabelle della console di Oracle NoSQL Database Cloud Service
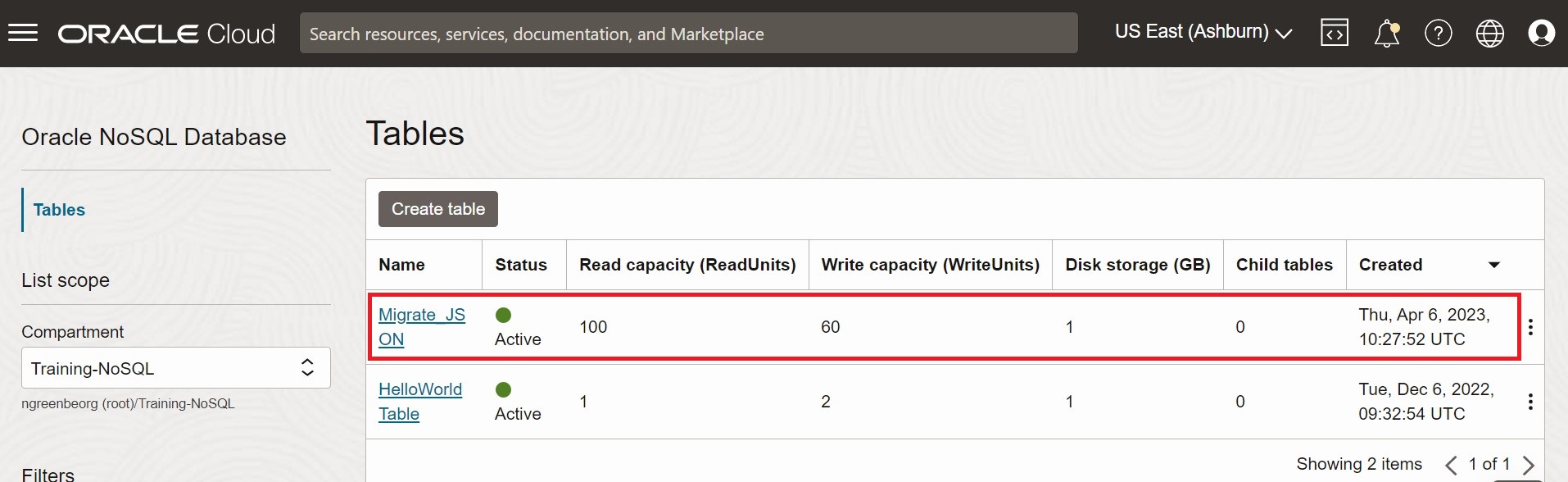
Descrizione dell'illustrazione migrate_json1.png
Figura - Dati della tabella della console di Oracle NoSQL Database Cloud Service
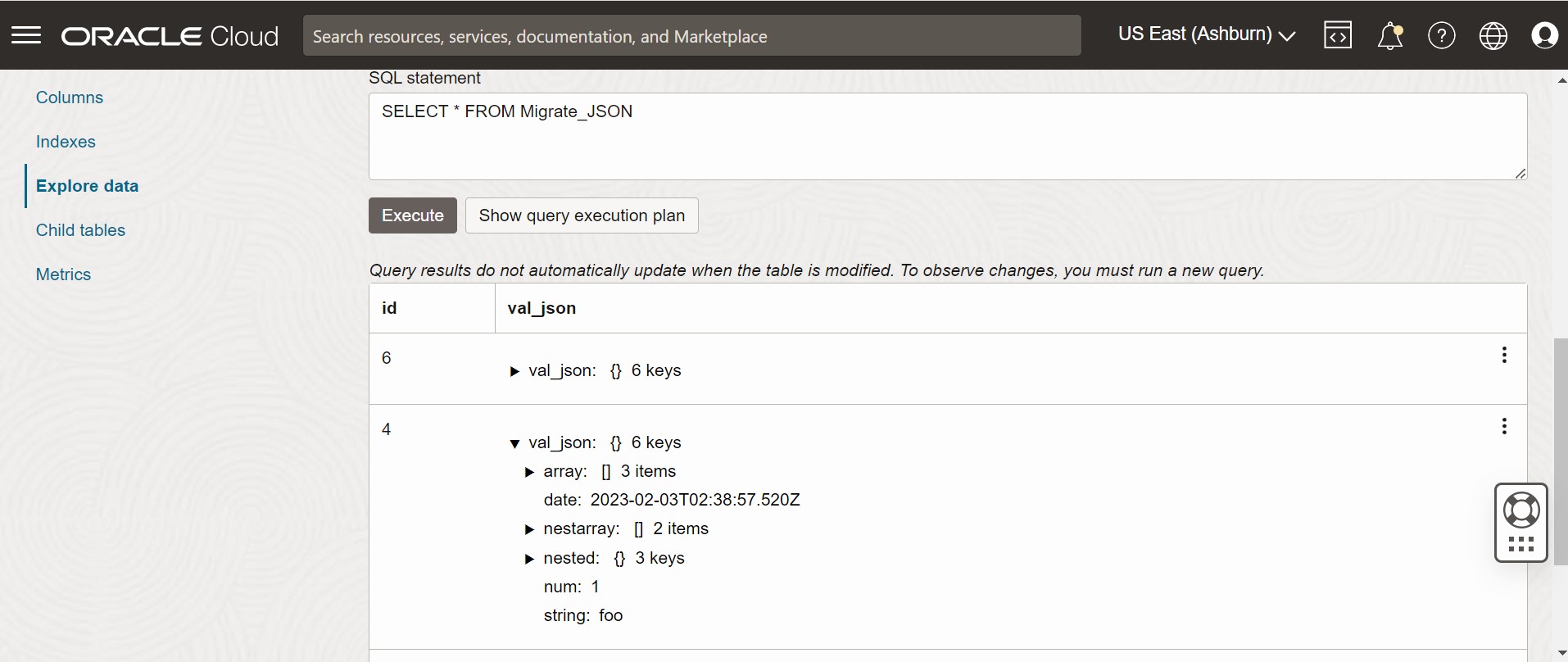
Descrizione dell'illustrazione migrate_json2.png
Eseguire la migrazione dal file JSON MongoDB a Oracle NoSQL Database Cloud Service
Questo esempio mostra come utilizzare Oracle NoSQL Database Migrator per copiare i dati in formato MongoDB in Oracle NoSQL Database Cloud Service (NDCS).
Caso d'uso
Dopo aver valutato più opzioni, un'organizzazione finalizza Oracle NoSQL Database Cloud Service come piattaforma di database NoSQL. Le tabelle e i dati si trovano in MongoDB e l'organizzazione desidera eseguire la migrazione sia a Oracle NDCS.
È possibile copiare un file o una directory contenente i dati JSON esportati da MongoDB per la migrazione specificando il file o la directory nel modello di configurazione di origine.
Consideriamo i seguenti due file JSON di esempio esportati da MongoDB per dimostrare il nostro caso d'uso.
Di seguito è riportato un esempio di file JSON in formato MongoDB.
{"_id":0,"name":"Aimee Zank","scores":[{"score":1.463179736705023,"type":"exam"},{"score":11.78273309957772,"type":"quiz"},{"score":35.8740349954354,"type":"homework"}]}
{"_id":1,"name":"Aurelia Menendez","scores":[{"score":60.06045071030959,"type":"exam"},{"score":52.79790691903873,"type":"quiz"},{"score":71.76133439165544,"type":"homework"}]}
{"_id":2,"name":"Corliss Zuk","scores":[{"score":67.03077096065002,"type":"exam"},{"score":6.301851677835235,"type":"quiz"},{"score":66.28344683278382,"type":"homework"}]}
{"_id":3,"name":"Bao Ziglar","scores":[{"score":71.64343899778332,"type":"exam"},{"score":24.80221293650313,"type":"quiz"},{"score":42.26147058804812,"type":"homework"}]}
{"_id":4,"name":"Zachary Langlais","scores":[{"score":78.68385091304332,"type":"exam"},{"score":90.2963101368042,"type":"quiz"},{"score":34.41620148042529,"type":"homework"}]}Di seguito è riportato un esempio di file JSON in formato MongoDB esportato da un'applicazione Spring.
{"_id":{"$oid":"63d3a87cf564fc21dac3838d"},"firstName":"John","lastName":"Smith","address":{"Country":"France"},"_class":"com.example.demo.Customer"}
{"_id":{"$oid":"63d3a87cf564fc21dac3838e"},"firstName":"Sam","lastName":"David","address":{"Country":"USA"},"_class":"com.example.demo.Customer"}
{"_id":"3","firstName":"Dona","lastName":"William","address":{"Country":"England"},"_class":"com.example.demo.Customer"}MongoDB supporta due tipi di estensioni per i file JSON formattati, come Modalità canonica e Modalità rilassata. È possibile fornire il file JSON in formato MongoDB generato utilizzando lo strumento mongoexport in modalità Canonica o Rilassata. NoSQL Database Migrator supporta entrambe le modalità.
Per ulteriori informazioni sul file MongoDB Extended JSON (v2), vedere mongoexport_formats.
Per ulteriori informazioni sulla generazione del file JSON in formato MongoDB, vedere mongoexport.
Esempio
Per la dimostrazione, esaminiamo come eseguire la migrazione di un file JSON in formato MongoDB a NDCS. Per questo esempio verrà utilizzato un file di configurazione creato manualmente.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: file JSON in formato MongoDB
-
Lavello: Oracle NoSQL Database Cloud Service
-
- Estrarre i dati da MongoDB utilizzando la utility mongoexport. Vedere mongoexport.
-
Identificare le credenziali cloud OCI e acquisirle nel file di configurazione OCI. Salvare il file di configurazione nella directory
/home/<user>/.oci/config. Per i dettagli, vedere Acquisizione delle credenziali.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identificare l'endpoint dell'area e il nome del compartimento per Oracle NoSQL Database Cloud Service.
-
endpoint:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza
-
Procedura
Per eseguire la migrazione dei dati JSON in formato MongoDB a Oracle NoSQL Database Cloud Service, puoi scegliere una delle opzioni riportate di seguito.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e collegamento identificati. Vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Qui è possibile impostare il parametro di configurazione
defaultSchemasu true. Pertanto, NoSQL Database Migrator crea una tabella con lo schema predefinito nel sink.{ "source" : { "type" : "file", "format" : "mongodb_json", "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "mongoImport", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "defaultSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Lo schema predefinito per l'origine file JSON in formato MongoDB è il seguente:
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id));dove:
-
tablename= valore fornito per l'attributotablenella configurazione. -
id= Il valore_iddi ogni documento del file di origine JSON esportato da MongoDB. -
document= Per ogni documento nel file esportato MongoDB, il contenuto escluso il campo_idviene aggregato nella colonnadocument.
Nota: se la tabella
<tablename>esiste già in Oracle NoSQL Database Cloud Service e si desidera eseguire la migrazione dei dati alla tabella utilizzando la configurazionedefaultSchema, è necessario assicurarsi che la tabella esistente contenga la colonna ID in lettere minuscole (id) e sia di tipo STRING. -
-
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione. Utilizzare l'opzione--configo-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati, come mostrato di seguito.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS mongoImport (id STRING, document JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 448ms Migration completed.
Verifica
Per verificare la migrazione, è possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la tabella mongoImport venga creata con i dati di origine. Per la procedura di accesso alla console, vedere l'articolo Accesso al servizio dalla console dell'infrastruttura.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e collegamento identificati. Vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Qui è possibile specificare il file contenente l'istruzione DDL della tabella sink nel parametro
schemaPathdel modello di configurazione di origine. Impostare il parametro di configurazioneuseSourceSchemasu true nel modello di configurazione sink.È possibile generare uno schema personalizzato come indicato di seguito.
-
Prendere nota dei nomi e dei tipi di dati per ogni colonna dai dati JSON in formato MongoDB. Utilizzare queste informazioni per creare un file DDL di schema per la tabella di Oracle NoSQL Database Cloud Service.
-
Nel file dello schema, denominare la prima colonna (chiave primaria) come
iddi tipo STRING. Includere gli stessi nomi e tipi per le colonne rimanenti registrati nel file JSON in formato MongoDB. -
Salvare il file di schema e annotare il percorso completo.
In questo esempio viene utilizzato lo schema definito dall'utente riportato di seguito.
CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id STRING, name STRING, scores JSON, PRIMARY KEY(SHARD(id)));È necessario includere una trasformazione
renameFieldsche indichi a NoSQL Database Migrator di convertire la colonna_idiniddurante la creazione della tabella. Per i dettagli dei parametri, vedere Modelli di configurazione della trasformazione. NoSQL Database Migrator crea una tabella con lo schema personalizzato nel sink.{ "source" : { "type" : "file", "format" : "mongodb_json", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/schema/file>" }, "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "sampleMongoDBImp", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : false, "requestTimeoutMs" : 5000 }, "transforms": { "renameFields" : { "_id":"id" } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione. Utilizzare l'opzione--configo-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati, come mostrato di seguito.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id INTEGER, name STRING, scores JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 438ms Migration completed.
Verifica
Per verificare la migrazione, è possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la tabella sampleMongoDBImp venga creata con i dati di origine. Per la procedura di accesso alla console, vedere l'articolo Accesso al servizio dalla console dell'infrastruttura.
-
Per questo caso d'uso, come origine verrà utilizzato il file JSON in formato MongoDB di esempio esportato da un'applicazione Spring. Per ulteriori dettagli su questo formato, vedere Dati sorgente.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e collegamento identificati. Vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Qui è possibile specificare il file contenente l'istruzione DDL della tabella sink nel parametro
schemaPathdel modello di configurazione di origine. Impostare il parametro di configurazioneuseSourceSchemasu true nel modello di configurazione sink.È possibile generare uno schema personalizzato come indicato di seguito.
-
Prendere nota dei nomi e dei tipi di dati per ogni colonna dai dati JSON in formato MongoDB.
-
Nel file dello schema, denominare la prima colonna (chiave primaria) come
iddi tipo STRING. Aggrega i campi rimanenti a un campo denominatokv_json_di tipo JSON, aderendo al formato dati Spring. Per ulteriori dettagli, vedere Modello di persistenza del framework Spring Data. -
Salvare il file di schema e annotare il percorso completo.
In questo esempio viene utilizzato lo schema definito dall'utente riportato di seguito.
CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp(id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id)))Per l'esempio di dati Spring sopra riportato, è necessario includere le seguenti trasformazioni:
-
Trasformazione
renameFieldsper convertire la colonna_idinid -
Trasformazione
ignoreFieldsper ignorare la colonna_classe non includerla nella tabella sink -
Trasformazione
aggregateFieldsper aggregare i campi rimanenti (diversi daid) in un campo di tipo JSON
Per i dettagli dei parametri, vedere Modelli di configurazione della trasformazione. NoSQL Database Migrator crea una tabella con lo schema personalizzato nel sink.
{ "source": { "type": "file", "format": "mongodb_json", "schemaInfo": { "schemaPath": "<complete/path/to/the/schema/file>" }, "dataPath": "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "sampleMongoDBSpringImp", "compartment": "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL": true, "schemaInfo": { "readUnits": 100, "writeUnits": 60, "storageSize": 1, "useSourceSchema": true }, "credentials": "<complete/path/to/the/oci/config/file>", "credentialsProfile": "DEFAULT", "writeUnitsPercent": 90, "overwrite": false, "requestTimeoutMs": 5000 }, "transforms": { "renameFields": { "_id": "id" }, "ignoreFields": ["_class"], "aggregateFields": { "fieldName": "kv_json_", "skipFields": ["id"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione. Utilizzare l'opzione--configo-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati, come mostrato di seguito.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp (id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [mongo file source] : start parsing MongoDB JSON records from file: mongodbspring.json Migration success for source mongodbspring. read=3,written=3,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=3, Records written to sink=3, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 393ms Migration completed.
Verifica
Per verificare la migrazione, è possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la tabella sampleMongoDBImp venga creata con i dati di origine. Per la procedura di accesso alla console, vedere l'articolo Accesso al servizio dalla console dell'infrastruttura.
Esegui migrazione da file JSON DynamoDB a Oracle NoSQL Database Cloud Service
Questo esempio mostra come utilizzare Oracle NoSQL Database Migrator per copiare il file JSON DynamoDB in NoSQL Database Cloud Service.
Caso d'uso
Dopo aver valutato più opzioni, un'organizzazione finalizza Oracle NoSQL Database Cloud Service rispetto al database DynamoDB. L'organizzazione desidera eseguire la migrazione delle tabelle e dei dati da DynamoDB a Oracle NoSQL Database Cloud Service.
Per ulteriori dettagli, vedere Mapping della tabella DynamoDB alla tabella Oracle NoSQL.
È possibile eseguire la migrazione di un file o di una directory contenente i dati JSON esportati da DynamoDB da un file system specificando il percorso nel modello di configurazione di origine.
Di seguito è riportato un esempio di file JSON in formato DynamoDB.
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"},"ttl": {"N": "1734616800"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"},"ttl": {"N": "1734616800"}}}La tabella DynamoDB viene esportata nello storage AWS S3 come specificato in Esportazione dei dati della tabella DynamoDB in Amazon S3.
Esempio
Per questa dimostrazione, imparerai come eseguire la migrazione di un file JSON DynamoDB a Oracle NoSQL Database Cloud Service. Per questo esempio verrà utilizzato un file di configurazione creato manualmente.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: file JSON DynamoDB
-
Lavello: Oracle NoSQL Database Cloud Service
-
-
Per importare i dati della tabella DynamoDB in Oracle NoSQL Database, è necessario prima esportare la tabella DynamoDB in S3. Per esportare la tabella, vedere la procedura descritta in Esportazione dei dati della tabella DynamoDB in Amazon S3. Durante l'esportazione, selezionare il formato come JSON DynamoDB. I dati esportati contengono i dati della tabella DynamoDB in più file
gzip, come mostrato di seguito./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
È necessario scaricare i file da AWS S3. La struttura dei file dopo il download sarà come mostrato di seguito.
download-dir/01639372501551-bb4dd8c3 |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Identificare le credenziali cloud OCI e acquisirle nel file di configurazione OCI. Salvare il file di configurazione nella directory
/home/<user>/.oci/config. Per ulteriori dettagli, vedere Acquisizione delle credenziali in Uso di Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identificare l'endpoint dell'area e il nome del compartimento per Oracle NoSQL Database Cloud Service.
-
endpoint:
us-ashburn-1 -
compartimento:
Training-NoSQL
-
Procedura
Per eseguire la migrazione dei dati JSON DynamoDB a Oracle NoSQL Database:
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e sink identificati. Per informazioni dettagliate, vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Nota: se gli elementi di tabella JSON esportati da DynamoDB contengono un attributo TTL, per importare facoltativamente i valori TTL, specificare l'attributo nel parametro di configurazione
ttlAttributeNamedel modello di configurazione di origine e impostare il parametro di configurazioneincludeTTLsu true nel modello di configurazione sink. Per ulteriori dettagli, vedere Migrazione dei metadati TTL per le righe tabella.Qui è possibile impostare il parametro di configurazione
defaultSchemasu true. Pertanto, NoSQL Database Migrator crea lo schema predefinito nel sink. È necessario specificareDDBPartitionKeye il tipo di colonna NoSQL corrispondente. In caso contrario, viene visualizzato un errore.Per i dettagli sullo schema predefinito per un'origine JSON esportata da DynamoDB, vedere l'argomento Identifica origine e collegamento in Workflow per Oracle NoSQL Data Migrator.
{ "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }In questo esempio viene utilizzato il seguente schema predefinito:
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) -
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando file di configurazione separati. Utilizzare l'opzione--configo-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati come illustrato nel seguente esempio:
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Verifica
Per convalidare la migrazione, è possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la tabella sampledynDBImp venga creata con i dati di origine.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e sink identificati. Per informazioni dettagliate, vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Nota: se gli elementi di tabella JSON esportati da DynamoDB contengono un attributo TTL, per importare facoltativamente i valori TTL, specificare l'attributo nel parametro di configurazione
ttlAttributeNamedel modello di configurazione di origine e impostare il parametro di configurazioneincludeTTLsu true nel modello di configurazione sink.In questo caso, impostare il parametro di configurazione
defaultSchemasu false. Pertanto, è possibile specificare il file contenente l'istruzione DDL della tabella sink nel parametroschemaPath. Per ulteriori dettagli, vedere Mapping dei tipi DynamoDB ai tipi Oracle NoSQL.In questo esempio viene utilizzato lo schema definito dall'utente riportato di seguito.
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id)))NoSQL Database Migrator utilizza il file di schema per creare la tabella nel sink nell'ambito della migrazione. Finché vengono forniti i dati della chiave primaria, il record JSON di input verrà inserito. In caso contrario, viene visualizzato un errore.
Nota:
-
Se la tabella DB Dynamo dispone di un tipo di dati non supportato nel database NoSQL, la migrazione non riesce.
-
Se i dati di input non contengono un valore per una determinata colonna (diversa dalla chiave primaria), verrà utilizzato il valore predefinito della colonna. Il valore predefinito deve far parte della definizione di colonna durante la creazione della tabella. Ad esempio,
id INTEGER not null default 0. Se la colonna non dispone di una definizione predefinita, viene inserito SQL NULL se non vengono forniti valori per la colonna. -
Se si sta modellando la tabella DynamoDB come documento JSON, assicurarsi di utilizzare la trasformazione
AggregateFieldsper aggregare i dati della chiave non primaria in una colonna JSON. Per ragioni di sicurezza, vedere aggregateFields
Generated configuration is { "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando file di configurazione separati. Utilizzare l'opzione--configo-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati come illustrato nel seguente esempio:
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Verifica
Per convalidare la migrazione, è possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la tabella sampledynDBImp venga creata con i dati di origine.
Eseguire la migrazione dal file JSON DynamoDB in AWS S3 a Oracle NoSQL Database Cloud Service
Questo esempio mostra come utilizzare Oracle NoSQL Database Migrator per copiare il file JSON DynamoDB memorizzato in un'area di memorizzazione S3 AWS in Oracle NoSQL Database Cloud Service (NDCS).
Caso d'uso:
Dopo aver valutato più opzioni, un'organizzazione finalizza Oracle NoSQL Database Cloud Service rispetto al database DynamoDB. L'organizzazione desidera eseguire la migrazione delle tabelle e dei dati da DynamoDB a Oracle NoSQL Database Cloud Service.
Per ulteriori dettagli, vedere Mapping della tabella DynamoDB alla tabella Oracle NoSQL.
È possibile eseguire la migrazione di un file contenente i dati JSON esportati da DynamoDB dallo storage S3 AWS specificando il percorso nel modello di configurazione di origine.
Di seguito è riportato un esempio di file JSON in formato DynamoDB.
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"}}}La tabella DynamoDB viene esportata nello storage AWS S3 come specificato in Esportazione dei dati della tabella DynamoDB in Amazon S3.
Esempio:
Per questa dimostrazione, imparerai come eseguire la migrazione di un file JSON DynamoDB in un'origine S3 AWS in NDCS. Per questo esempio verrà utilizzato un file di configurazione creato manualmente.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Fonte:DynamoDB JSON File in AWS S3
-
ink: Oracle NoSQL Database Cloud Service
-
-
Identificare la tabella in AWS DynamoDB di cui è necessario eseguire la migrazione in NDCS. Eseguire il login alla console AWS utilizzando le credenziali. Andare a DynamoDB. In Tabelle scegliere la tabella di cui eseguire la migrazione.
-
Creare un bucket degli oggetti ed esportare la tabella in S3. Dalla console AWS, vai a S3. In Bucket, creare un nuovo bucket degli oggetti. Tornare a DynamoDB e fare clic su Esporta in S3. Fornire la tabella di origine e il bucket S3 di destinazione e fare clic su Esporta.
Fare riferimento ai passi forniti in Esportazione dei dati della tabella DynamoDB in Amazon S3 per esportare la tabella. Durante l'esportazione, selezionare il formato JSON DinamoDB. I dati esportati contengono i dati della tabella DynamoDB in più file
gzip, come mostrato di seguito./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Hai bisogno di credenziali AWS (inclusi ID chiave di accesso e chiave di accesso segreta) e file di configurazione (credenziali e facoltativamente configurazione) per accedere ad AWS S3 da NoSQL Database Migrator. Per ulteriori dettagli sui file di configurazione, vedere Imposta e visualizza impostazioni di configurazione. Per ulteriori informazioni sulla creazione delle chiavi di accesso, vedere Creazione di una coppia di chiavi.
-
Identificare le credenziali cloud OCI e acquisirle nel file di configurazione OCI. Salvare il file di configurazione in una directory
.ocinella directory home (~/.oci/config). Per ulteriori dettagli, vedere Acquisizione delle credenziali.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identificare l'endpoint dell'area e il nome del compartimento per Oracle NoSQL Database Cloud Service. Di seguito sono riportati alcuni esempi.
-
endpoint:us-phoenix-1
-
compartimento: sviluppatori
-
Procedura
Per eseguire la migrazione dei dati JSON DynamoDB a Oracle NoSQL Database Cloud Service, utilizzare una delle opzioni riportate di seguito.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e sink identificati. Per informazioni dettagliate, vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Nota: se gli elementi nel file JSON DynamoDB in AWS S3 contengono un attributo TTL, per importare facoltativamente i valori TTL, specificare l'attributo nel parametro di configurazione
ttlAttributeNamedel modello di configurazione di origine e impostare il parametro di configurazioneincludeTTLsu true nel modello di configurazione del sink. Per ulteriori dettagli, vedere Migrazione dei metadati TTL per le righe tabella.Impostare
defaultSchemasuTRUEe quindi la utility Migrator crea lo schema predefinito nel sink. È necessario specificareDDBPartitionKeye il tipo di colonna NoSQL corrispondente. In caso contrario, viene restituito un errore.{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : true, "readUnits" : 100, "writeUnits" : 60, "DDBPartitionKey" : "<PrimaryKey:Datatype>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Per un'origine JSON DynamoDB, lo schema predefinito per la tabella sarà come mostrato di seguito:
CREATE TABLE IF NOT EXISTS <TABLE_NAME>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type], DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))dove:
TABLE_NAME = valore fornito per la 'tabella' del sink nella configurazione
DDBPartitionKey_name = valore fornito per la chiave di partizione nella configurazione
DDBPartitionKey_type = valore fornito per il tipo di dati della chiave di partizione nella configurazione
DDBSortKey_name = valore fornito per la chiave di ordinamento nella configurazione, se presente
DDBSortKey_type = valore fornito per il tipo di dati della chiave di ordinamento nella configurazione, se presente
DOCUMENT = Tutti gli attributi tranne la partizione e la chiave di ordinamento di un elemento di tabella DB Dynamo aggregato in una colonna JSON NoSQL
-
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione. Utilizzare l'opzione--configo-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati, come mostrato di seguito.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Verifica
È possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la nuova tabella venga creata con i dati di origine.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e sink identificati. Per informazioni dettagliate, vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Nota: se gli elementi nel file JSON DynamoDB in AWS S3 contengono l'attributo TTL, per importare facoltativamente i valori TTL, specificare l'attributo nel parametro di configurazione ttlAttributeName del modello di configurazione di origine e impostare il parametro di configurazione includeTTL su true nel modello di configurazione sink. Per ulteriori dettagli, vedere Migrazione dei metadati TTL per le righe tabella.
Per specificare un file di schema definito dall'utente nel modello di configurazione del sink, impostare defaultSchema su
FALSEe specificare schemaPath come file contenente l'istruzione DDL. Per i dettagli, vedere Mappatura dei tipi DynamoDB ai tipi Oracle NoSQL.Nota: se la tabella DB Dynamo ha un tipo di dati non supportato in NoSQL, la migrazione non riesce.
Di seguito è riportato un file di schema di esempio.
CREATE TABLE IF NOT EXISTS sampledynDBImp (AccountId INTEGER,document JSON, PRIMARY KEY(SHARD(AccountId)));Il file di schema viene utilizzato per creare la tabella nel sink come parte della migrazione. Finché vengono forniti i dati della chiave primaria, il record JSON di input verrà inserito, altrimenti restituisce un errore.
Nota:
- Se i dati di input non contengono un valore per una determinata colonna (diversa dalla chiave primaria), verrà utilizzato il valore predefinito della colonna. Il valore predefinito deve far parte della definizione della colonna durante la creazione della tabella. Ad esempio,
id INTEGER not null default 0. Se la colonna non dispone di una definizione predefinita, viene inserito SQL NULL se non vengono forniti valori per la colonna. - Se si sta modellando la tabella DynamoDB come documento JSON, assicurarsi di utilizzare la trasformazione
AggregateFieldsper aggregare i dati della chiave non primaria in una colonna JSON. Per informazioni dettagliate, vedere aggregateFields.
{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : false, "readUnits" : 100, "writeUnits" : 60, "schemaPath" : "<full path of the schema file with the DDL statement>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "transforms": { "aggregateFields" : { "fieldName" : "document", "skipFields" : ["AccountId"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } - Se i dati di input non contengono un valore per una determinata colonna (diversa dalla chiave primaria), verrà utilizzato il valore predefinito della colonna. Il valore predefinito deve far parte della definizione della colonna durante la creazione della tabella. Ad esempio,
-
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione. Utilizzare l'opzione--configo-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
La utility procede con la migrazione dei dati, come mostrato di seguito.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Verifica
È possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e verificare che la nuova tabella venga creata con i dati di origine.
Eseguire la migrazione tra le aree di Oracle NoSQL Database Cloud Service
Questo esempio mostra l'uso di Oracle NoSQL Database Migrator per eseguire la migrazione tra più aree.
Caso d'uso
Un'organizzazione utilizza Oracle NoSQL Database Cloud Service per memorizzare e gestire i propri dati. Decide di replicare i dati da un'area esistente a un'area più recente a scopo di test prima di poter avviare la nuova area per l'ambiente di produzione.
In questo caso d'uso, verrà descritto come utilizzare NoSQL Database Migrator per copiare i dati dalla tabella user_data nell'area Ashburn nell'area Phoenix.
Per eseguire la utility runMigrator, passare un file di configurazione creato in precedenza. Se non si fornisce il file di configurazione come parametro di runtime, la utility runMigrator richiede di generare la configurazione mediante una procedura interattiva.
Prerequisiti
-
Scarica Oracle NoSQL Database Migrator dalla pagina Oracle NoSQL Downloads ed estrai i contenuti sul tuo computer. Per i dettagli, vedere Workflow per Oracle NoSQL Database Migrator.
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: la tabella
user_datanell'area Ashburn.La tabella
user_datainclude i dati riportati di seguito.{"id":40,"firstName":"Joanna","lastName":"Smith","otherNames":[{"first":"Joanna","last":"Smart"}],"age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085},"connections":[70,30,40],"email":"joanna.smith123@reachmail.com","communityService":"**"} {"id":10,"firstName":"John","lastName":"Smith","otherNames":[{"first":"Johny","last":"Good"},{"first":"Johny2","last":"Brave"},{"first":"Johny3","last":"Kind"},{"first":"Johny4","last":"Humble"}],"age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008},"connections":[30,55,43],"email":"john.smith@reachmail.com","communityService":"****"} {"id":20,"firstName":"Jane","lastName":"Smith","otherNames":[{"first":"Jane","last":"BeGood"}],"age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005},"connections":[40,75,63],"email":"jane.smith201@reachmail.com","communityService":"*****"} {"id":30,"firstName":"Adam","lastName":"Smith","otherNames":[{"first":"Adam","last":"BeGood"}],"age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075},"connections":[60,45,73],"email":"adam.smith201reachmail.com","communityService":"***"}Identificare l'endpoint dell'area o l'endpoint del servizio e il nome del compartimento per l'origine.
-
endpoint:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Lavello: la tabella
user_datanell'area Phoenix.Identificare l'endpoint dell'area o l'endpoint del servizio e il nome del compartimento per il sink.
-
endpoint:
us-phoenix-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Identificare lo schema della tabella sink.
È possibile utilizzare lo stesso nome tabella e lo stesso schema della tabella di origine. Per informazioni su altre opzioni di schema, vedere l'argomento Identificare l'origine e il lavandino in Workflow per Oracle NoSQL Database Migrator.
-
-
-
Identificare le credenziali cloud OCI per entrambe le aree e acquisirle nel file di configurazione. Salvare il file di configurazione sul computer nella posizione
/home/<user>/.oci/config. Per ulteriori dettagli, vedere Acquisizione delle credenziali.Nota:
-
Se le aree si trovano in tenancy diverse, è necessario fornire profili diversi nel file
/home//.oci/configcon le credenziali cloud OCI appropriate per ognuna di esse. -
Se le aree si trovano nella stessa tenancy, è possibile avere un singolo profilo nel file
/home//.oci/config.
-
In questo esempio, le aree si trovano in tenancy diverse. Il profilo DEFAULT include le credenziali OCI per l'area Ashburn e DEFAULT2 include le credenziali OCI per l'area Phoenix.
Nel parametro endpoint del file di configurazione del migratore (sia i modelli di configurazione dell'origine che del sink), è possibile fornire l'URL dell'endpoint del servizio o l'ID area delle aree. Per la lista delle aree dati supportate per Oracle NoSQL Database Cloud Service e i relativi URL degli endpoint del servizio, vedere Aree dati e URL del servizio associato nel documento Oracle NoSQL Database Cloud Service.
[DEFAULT]
user=ocid1.user.oc1....
fingerprint=fd:96:....
tenancy=ocid1.tenancy.oc1....
region=us-ashburn-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=abcd
[DEFAULT2]
user=ocid1.user.oc1....
fingerprint=1b:68:....
tenancy=ocid1.tenancy.oc1....
region=us-phoenix-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=23456Procedura
Per eseguire la migrazione della tabella user_data dall'area Ashburn all'area Phoenix, effettuare le operazioni riportate di seguito.
-
Preparare il file di configurazione (in formato JSON) con i dettagli di origine e sink identificati. Vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 100, "includeTTL" : false, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT2", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Sul computer, andare alla directory in cui è stata estratta la utility NoSQL Database Migrator. È possibile accedere al comando
runMigratordall'interfaccia a riga di comando. -
Eseguire il comando
runMigratorpassando il file di configurazione con l'opzione -config o -c.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
La utility procede con la migrazione dei dati come mostrato di seguito. La tabella
user_dataviene creata nel sink con lo stesso schema della tabella di origine configurato con il parametro useSourceSchema true nel modello di configurazione del sink.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS user_data (id INTEGER, firstName STRING, lastName STRING, otherNames ARRAY(RECORD(first STRING, last STRING)), age INTEGER, income INTEGER, address JSON, connections ARRAY(INTEGER), email STRING, communityService STRING, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 603ms Migration completed.Nota:
-
Se la tabella esiste già nel sink con lo stesso schema della tabella di origine, le righe con le stesse chiavi primarie vengono sovrascritte in quanto è stato fornito il parametro di sovrascrittura true nel template di configurazione.
-
Se la tabella esiste già nel sink con uno schema diverso da quello della tabella di origine, la migrazione non riuscirà.
-
Convalida
Per convalidare la migrazione, puoi eseguire il login alla console di Oracle NoSQL Database Cloud Service nell'area Phoenix. Verificare che i dati di origine della tabella user_data nell'area Ashburn vengano copiati nella tabella user_data di quest'area. Per la procedura di accesso alla console, vedere l'articolo Accesso al servizio dalla console dell'infrastruttura.
Eseguire la migrazione da Oracle NoSQL Database Cloud Service allo storage degli oggetti OCI
Questo esempio mostra l'uso di Oracle NoSQL Database Migrator da una Cloud Shell.
Caso d'uso
Un'impresa start-up prevede di utilizzare Oracle NoSQL Database Cloud Service come soluzione di storage dei dati. L'azienda desidera utilizzare Oracle NoSQL Database Migrator per copiare i dati da una tabella in Oracle NoSQL Database Cloud Service nello storage degli oggetti OCI per eseguire backup periodici dei propri dati. Come misura conveniente, desiderano eseguire la utility NoSQL Database Migrator da Cloud Shell, accessibile a tutti gli utenti OCI.
In questo caso d'uso, verrà descritto come copiare la utility NoSQL Database Migrator in una Cloud Shell nell'area sottoscritta ed eseguire una migrazione dei dati. Eseguire la migrazione dei dati di origine dalla tabella Oracle NoSQL Database Cloud Service a un file JSON nello storage degli oggetti OCI.
Per eseguire la utility runMigrator, passare un file di configurazione creato in precedenza. Se non si fornisce il file di configurazione come parametro di runtime, la utility runMigrator richiede di generare la configurazione mediante una procedura interattiva.
Prerequisiti
-
Scaricare Oracle NoSQL Database Migrator dalla pagina Download Oracle NoSQL nel computer locale.
-
Avvia Cloud Shell dal menu Strumenti Developer nella console cloud. Il browser Web apre la directory home. Fare clic sul menu Cloud Shell nell'angolo superiore destro della finestra Cloud Shell e selezionare l'opzione Carica dall'elenco a discesa. Nella finestra popup trascinare il package Migrator di Oracle NoSQL Database dal computer locale oppure fare clic sull'opzione Seleziona dal computer, selezionare il package dal computer locale e fare clic sul pulsante Carica. È inoltre possibile trascinare e rilasciare il package Oracle NoSQL Database Migrator direttamente dal computer locale alla directory home in Cloud Shell. Estrazione del contenuto del package.
-
Identificare l'origine e il sink per il backup.
-
Origine: tabella
NDCSuploadnell'area Ashburn di Oracle NoSQL Database Cloud Service.Per una dimostrazione, considerare i dati riportati di seguito nella tabella
NDCSupload.{"id":1,"name":"Jane Smith","email":"iamjane@somemail.co.us","age":30,"income":30000.0} {"id":2,"name":"Adam Smith","email":"adam.smith@mymail.com","age":25,"income":25000.0} {"id":3,"name":"Jennifer Smith","email":"jenny1_smith@mymail.com","age":35,"income":35000.0} {"id":4,"name":"Noelle Smith","email":"noel21@somemail.co.us","age":40,"income":40000.0}Identificare l'endpoint e l'ID compartimento per l'origine. Per l'endpoint, è possibile fornire l'identificativo dell'area o l'endpoint del servizio. Per la lista delle aree dati supportate in Oracle NoSQL Database Cloud Service, vedere Aree dati e URL del servizio associato.
-
endpoint:
us-ashburn-1 -
ID compartimento:
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Lavello: file JSON nel bucket di storage degli oggetti OCI.
Identifica l'endpoint dell'area, lo spazio di nomi, il bucket e il prefisso per OCI Object Storage. Per ulteriori dettagli, vedere Accesso allo storage degli oggetti Oracle Cloud. Per la lista degli endpoint del servizio di storage degli oggetti OCI, vedere Endpoint di storage degli oggetti.
-
endpoint:
us-ashburn-1 -
bucket:
Migrate_oci -
prefisso:
Delegation -
namespace: <> Se non si fornisce uno spazio di nomi, la utility utilizza lo spazio di nomi predefinito della tenancy.
Nota: se il bucket di storage degli oggetti si trova in un compartimento diverso, assicurarsi di disporre dei privilegi per scrivere gli oggetti nel bucket. Per ulteriori dettagli sull'impostazione dei criteri, vedere Scrivere gli oggetti nello storage degli oggetti.
-
-
Procedura
Per eseguire la migrazione da Oracle NoSQL Database Cloud Service allo storage degli oggetti OCI, effettuare le operazioni riportate di seguito dalla finestra Cloud Shell.
-
Preparare un file di configurazione Migrator,
migrator-config.json, con l'origine Oracle NoSQL Database Cloud Service e l'affondamento dello storage degli oggetti OCI. Per i modelli, vedere Modelli di configurazione origine e Modelli di configurazione del collegamento. Assicurarsi di impostare il parametrouseDelegationTokensutruenei modelli di configurazione di origine e sink.In questo caso d'uso viene utilizzato il seguente modello di configurazione:
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "NDCSupload", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "useDelegationToken" : true, "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "Delegation", "chunkSize" : 32, "compression" : "", "useDelegationToken" : true }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Da Cloud Shell, andare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando
runMigratorpassando il file di configurazione utilizzando l'opzione--configo-c.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
La utility NoSQL Database Migrator procede con la migrazione dei dati. Poiché il parametro useDelegationToken è stato impostato su true, Cloud Shell esegue automaticamente l'autenticazione utilizzando il token di delega durante l'esecuzione della utility NoSQL Database Migrator. NoSQL Database Migrator copia i dati dalla tabella
NDCSuploadin un file JSON nel bucket di storage degli oggettiMigrate_oci. Controllare i log per il backup dei dati riuscito.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [OCI OS sink] : writing table schema to Delegation/Schema/schema.ddl [INFO] [OCI OS sink] : start writing records with prefix Delegation [INFO] migration completed. Records provided by source=4,Records written to sink=4,Records failed=0. Elapsed time: 0min 0sec 486ms Migration completed.Nota:
I dati vengono copiati nel file:
Migrate_oci/NDCSupload/Delegation/Data/000000.jsonA seconda del parametro chunkSize nel modello di configurazione del sink, i dati di origine possono essere suddivisi in diversi file JSON nella stessa directory.
Lo schema viene copiato nel file:
Migrate_oci/NDCStable1/Delegation/Schema/schema.ddl
Convalida
Per convalidare il backup dei dati, eseguire il login alla console di Oracle NoSQL Database Cloud Service. Navigare tra i menu, Storage > Object Storage & Archive Storage > Buckets. Accedere ai file dalla directory NDCSupload/Delegation nel bucket Migrate_oci. Per la procedura di accesso alla console, vedere l'articolo Accesso al servizio dalla console dell'infrastruttura.
Eseguire la migrazione dallo storage degli oggetti OCI a Oracle NoSQL Database Cloud Service mediante l'autenticazione OKE
Questo esempio mostra come utilizzare Oracle NoSQL Database Migrator con OKE Workload Identity Authentication per copiare i dati da un file JSON nello storage degli oggetti OCI nella tabella Oracle NoSQL Database Cloud Service.
Caso d'uso
Come sviluppatore, stai esplorando un'opzione per ripristinare i dati da un file JSON nel bucket di OCI Object Storage (OCI OS) alla tabella Oracle NoSQL Database Cloud Service (NDCS) utilizzando NoSQL Database Migrator in un'applicazione containerizzata. Un'applicazione containerizzata è un ambiente virtualizzato che raggruppa l'applicazione e tutte le sue dipendenze (come librerie, file binari e file di configurazione) in un pacchetto. Ciò consente all'applicazione di essere eseguita in modo coerente in ambienti diversi, indipendentemente dall'infrastruttura sottostante.
Si desidera eseguire NoSQL Database Migrator all'interno di un pod Oracle Cloud Infrastructure Container Engine for Kubernetes (OKE). Per accedere in modo sicuro al sistema operativo OCI e ai servizi NDCS dal pod OKE, utilizzerai il metodo WIA (Workload Identity Authentication).
In questa dimostrazione, si creerà un'immagine docker per NoSQL Database Migrator, si copierà l'immagine in un repository nel Container Registry, si creerà un cluster OKE e si distribuirà l'immagine Migrator nel pod cluster OKE per eseguire la utility Migrator. Qui verrà fornito un file di configurazione NoSQL Database Migrator creato manualmente per eseguire la utility Migrator come applicazione containerizzata.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: file JSON e file di schema nel bucket del sistema operativo OCI.
Identifica l'endpoint dell'area, lo spazio di nomi, il bucket e il prefisso per il bucket del sistema operativo OCI in cui sono disponibili i file e lo schema JSON di origine. Per ulteriori dettagli, vedere Accesso allo storage degli oggetti Oracle Cloud. Per la lista degli endpoint del servizio del sistema operativo OCI, vedere Endpoint di storage degli oggetti.
-
endpoint:
us-ashburn-1 -
bucket:
Migrate_oci -
prefisso:
userSession -
spazio di nomi:
idhkv1iewjzj
Il nome dello spazio di nomi per un bucket è uguale allo spazio di nomi della tenancy e viene generato automaticamente quando viene creata la tenancy. È possibile ottenere il nome dello spazio di nomi come indicato di seguito.
-
Dalla console di Oracle NoSQL Database Cloud Service, passare a Memorizzazione > Bucket.
-
Selezionare il compartimento da Ambito lista e selezionare il bucket. La pagina Dettagli bucket visualizza il nome nel parametro Spazio di nomi.
Se non si fornisce un nome per lo spazio di nomi del sistema operativo OCI, la utility Migrator utilizza lo spazio di nomi predefinito della tenancy.
-
-
Lavello: tabella
usersin Oracle NoSQL Database Cloud Service.Identificare l'endpoint dell'area o l'endpoint del servizio e il nome del compartimento per il sink:
-
endpoint:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Identificare lo schema della tabella sink.
Per utilizzare il nome tabella e lo schema memorizzati nel bucket del sistema operativo OCI, impostare il parametro
useSourceSchemasu true. Per informazioni su altre opzioni di schema, vedere l'argomento Identifica origine e collegamento in Workflow per Oracle NoSQL Database Migrator.Nota: assicurarsi di disporre dei privilegi di scrittura nel compartimento in cui si stanno ripristinando i dati nella tabella NDCS. Per ulteriori dettagli, vedere Gestione dei compartimenti.
-
-
-
Preparare un'immagine Docker per NoSQL Database Migrator e spostarla in Container Registry.
-
Recupera lo spazio di nomi della tenancy dalla console OCI.
Eseguire il login alla console di Oracle NoSQL Database Cloud Service. Nella barra di navigazione selezionare il menu Profilo, quindi selezionare Tenancy: <Nome tenany>.
Copiare il nome dello spazio di nomi dello storage degli oggetti, ovvero lo spazio di nomi della tenancy, negli appunti.
-
Creare un'immagine Docker per la utility Migrator.
Passare alla directory in cui è stata estratta la utility NoSQL Database Migrator. Il pacchetto Migrator include un file docker denominato Dockerfile. Da un'interfaccia di comando, utilizzare il comando seguente per creare un'immagine Docker della utility Migrator:
#Command: docker build -t nosqlmigrator:<tag> .#Example: docker build -t nosqlmigrator:1.0 .È possibile specificare un identificativo di versione per l'immagine Docker nell'opzione
tag. Controllare l'immagine Docker utilizzando il comando:#Command: Docker images#Example output ------------------------------------------------------------------------------------------ REPOSITORY TAG IMAGE ID CREATED SIZE localhost/nosqlmigrator 1.0 e1dcec27a5cc 10 seconds ago 487 MB quay.io/podman/hello latest 83fc7ce1224f 10 months ago 580 kB docker.io/library/openjdk 17-jdk-slim 8a3a2ffec52a 2 years ago 406 MB ------------------------------------------------------------------------------------------ -
Generare un token autenticazione.
È necessario un token di autenticazione per eseguire il login al Container Registry e memorizzare l'immagine Docker di Migrator. Se non si dispone già di un token di autenticazione, è necessario generarne uno. Per i dettagli, vedere Come ottenere un token di autenticazione.
-
Memorizzare l'immagine Docker Migrator in Container Registry.
Per accedere all'immagine Docker Migrator dal pod Kubernetes, è necessario memorizzare l'immagine in qualsiasi registro pubblico o privato. Ad esempio, Docker, Artifact Hub, OCI Container Registry e così via sono alcuni registri. In questa dimostrazione, utilizziamo Container Registry. Per informazioni dettagliate, vedere Panoramica del registro container.
-
Dalla console OCI, creare un repository nel Container Registry. Per informazioni dettagliate, vedere Creazione di un repository.
Per questa dimostrazione, creare il repository
okemigrator.Figura - Repository nel registro contenitori
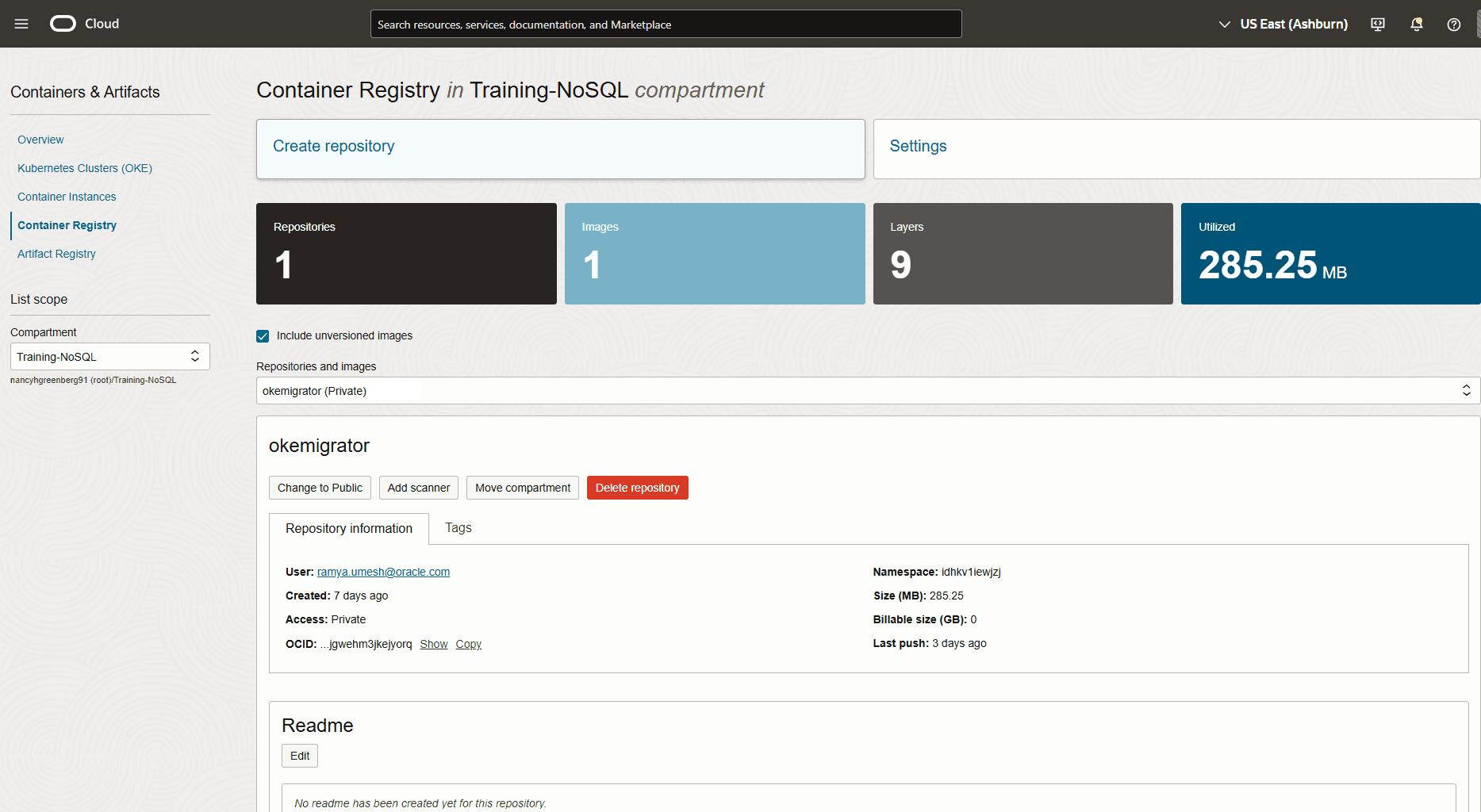
-
Eseguire il login al Container Registry dall'interfaccia a comandi utilizzando il seguente comando:
#Command: docker login <region-key>.ocir.io -u <tenancy-namespace>/<user name>password: <Auth token>#Example: docker login iad.ocir.io -u idhx..xxwjzj/rx..xxxxh@oracle.com password: <Auth token>#Output: Login Succeeded!Nel comando precedente,
region-key: specifica la chiave per l'area in cui si utilizza Container Registry. Per informazioni dettagliate, vedere Disponibilità per area.tenancy-namespace: specifica lo spazio di nomi della tenancy copiato dalla console OCI.user name: specifica il nome utente della console OCI.password: specifica il token di autenticazione. -
Contrassegnare e inviare l'immagine Docker di Migrator a Container Registry utilizzando i comandi seguenti:
#Command: docker tag <Migrator Docker image> <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag> docker push <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag>#Example: docker tag localhost/nosqlmigrator:1.0 iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 docker push iad.ocir.io/idhx..xxwjzj/okemigrator:1.0Nel comando precedente,
repo: specifica il nome del repository creato in Container Registry.tag: specifica l'identificativo della versione per l'immagine Docker.#Output: Getting image source signatures Copying blob 0994dbbf9a1b done | Copying blob 37849399aca1 done | Copying blob 5f70bf18a086 done | Copying blob 2f263e87cb11 done | Copying blob f941f90e71a8 done | Copying blob c82e5bf37b8a done | Copying blob 2ad58b3543c5 done | Copying blob 409bec9cdb8b done | Copying config e1dcec27a5 done | Writing manifest to image destination
-
-
-
Configurare un cluster OKE con WIA a NDCS e sistema operativo OCI.
-
Creare un cluster Kubernetes utilizzando OKE.
Dalla console OCI, definire e creare un cluster Kubernetes in base alla disponibilità delle risorse di rete utilizzando OKE. È necessario un cluster Kubernetes per eseguire la utility Migrator come applicazione containerizzata. Per i dettagli sulla creazione del cluster, vedere Creazione di cluster Kubernetes mediante i workflow della console.
Per questa dimostrazione, è possibile creare un cluster gestito a nodo singolo utilizzando il flusso di lavoro Creazione rapida dettagliato nel collegamento sopra riportato.
Figura - Cluster Kubernetes per il contenitore Migrator
-
Imposta WIA dalla console OCI per accedere ad altre risorse OCI dal cluster Kubernetes.
Per concedere alla utility Migrator l'accesso al bucket del sistema operativo NDCS e OCI durante l'esecuzione dai pod del cluster Kubernetes, è necessario impostare WIA. Attenersi alla procedura riportata di seguito.
-
Impostare il file di configurazione kubeconfig del cluster.
-
Dalla console OCI, aprire il cluster Kubernetes creato e fare clic sul pulsante Accedi al cluster.
-
Nella finestra di dialogo Accedi al cluster, fare clic su Accesso a Cloud Shell.
-
Fare clic su Avvia Cloud Shell per visualizzare la finestra Cloud Shell.
-
Eseguire il comando CLI di Oracle Cloud Infrastructure per impostare il file kubeconfig. È possibile copiare il comando dalla finestra di dialogo Accedi al cluster. Potete aspettarvi il seguente output:
#Example: oci ce cluster create-kubeconfig --cluster-id ocid1.cluster.oc1.iad.aaa...muqzq --file $HOME/.kube/config --region us-ashburn-1 --token-version 2.0.0 --kube-endpoint PUBLIC_ENDPOINT#Output: New config written to the Kubeconfig file /home/<user>/.kube/config
-
-
Copiare l'OCID del cluster dall'opzione
cluster-idnel comando precedente e salvarlo per utilizzarlo nei passi successivi.ocid1.cluster.oc1.iad.aaa...muqzq -
Creare uno spazio di nomi per l'account del servizio Kubernetes utilizzando il comando seguente nella finestra della shell cloud:
#Command: kubectl create namespace <namespace-name>#Example: kubectl create namespace migrator#Output: namespace/migrator created -
Creare un account di servizio Kubernetes per l'applicazione Migrator in uno spazio di nomi utilizzando il comando seguente nella finestra della shell cloud:
#Command: kubectl create serviceaccount <service-account-name> --namespace <namespace-name>#Example: kubectl create serviceaccount migratorsa --namespace migrator#Output: serviceaccount/migratorsa created -
Definisci un criterio IAM dalla console OCI per consentire al carico di lavoro di accedere alle risorse OCI dal cluster Kubernetes.
Dalla console OCI, spostarsi tra i menu Identità e sicurezza > Identità > Criteri. Creare i criteri riportati di seguito per consentire l'accesso alle risorse
nosql-familyeobject-family. Usare l'OCID del cluster, dello spazio di nomi e dei valori dell'account di servizio dai passi precedenti.#Command: Allow <subject> to <verb> <resource-type> in <location> where <conditions>#Example: Allow any-user to manage nosql-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'} Allow any-user to manage object-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'}Per ulteriori dettagli sulla creazione dei criteri, vedere Utilizzo della console per creare i criteri.
-
-
Procedura
Per eseguire la migrazione dal file JSON nel bucket del sistema operativo OCI alla tabella NDCS, eseguire le operazioni riportate di seguito dalla finestra Cloud Shell.
-
Prepara un file di configurazione Migrator,
migrator-config.json, con origine del sistema operativo OCI e sink NDCS. Per i modelli, vedere Modelli di configurazione origine e Modelli di configurazione del collegamento.Per utilizzare OKE WIA per accedere al bucket del sistema operativo OCI e a NDCS, impostare il parametro
useOKEWorkloadIdentitysu true nei modelli di configurazione di origine e sink. Qui, utilizzerai lo schema di origine dal file DDL dello schema nel bucket del sistema operativo OCI. Impostare pertanto il parametrouseSourceSchemasu true nel modello di configurazione sink.Nota: quando si utilizza OKE WIA, non è possibile generare il file di configurazione Migrator in modo interattivo. È necessario preparare il file di configurazione manualmente facendo riferimento ai modelli di configurazione di origine e sink.
{ "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Creare una risorsa di mappa di configurazione (configmap) per passare il file di input della configurazione
migrator-config.jsonal contenitore Migrator in fase di esecuzione nel pod Kubernetes. La mappa di configurazione attiva il file di configurazione Migrator nel file system del contenitore come volume di MOUNT.#Command: kubectl create configmap oci-migrator-config --from-file=<Migrator configuration file> -n <namespace-name>#Example: kubectl create configmap oci-migrator-config --from-file=migrator-config.json -n migrator#Output: configmap/oci-migrator-config created -
Creare un segreto del registro Docker che includa le credenziali OCI da utilizzare durante il pull dell'immagine Docker Migrator da Container Registry nel pod Kubernetes.
#Command: kubectl create secret docker-registry ocirsecret --docker-server=<region-key>.ocir.io --docker-username='tenancy-namespace/username' --docker-password='auth token' --docker-email='<user Email>' -n <namespace-name>#Example: kubectl create secret docker-registry ocirsecret --docker-server=iad.ocir.io --docker-username='idhx..xxwjzj/rx..xxxxh@oracle.com' --docker-password='<Auth token>' --docker-email='rx..xxxxh@oracle.com' -n migrator#Output: secret/ocirsecret created -
Creare un file manifesto che verrà utilizzato per specificare l'immagine Docker Migrator. Assicurarsi di fornire i valori dei passi precedenti per lo spazio di nomi, il nome dell'account del servizio Kubernetes, il nome dell'immagine Docker, il segreto del registro Docker e la mappa di configurazione. È possibile fare riferimento al seguente file manifesto di esempio:
#migrator-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nosql-migrator spec: replicas: 1 selector: matchLabels: app: nosql-migrator template: metadata: labels: app: nosql-migrator spec: serviceAccountName: migratorsa automountServiceAccountToken: true containers: - name: nosqlmigrator image: iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 imagePullPolicy: Always args: ["--config", "/config/migrator-config.json", "--log-level", "DEBUG"] volumeMounts: - name: config-volume mountPath: /config # Mount the file here imagePullSecrets: - name: ocirsecret volumes: - name: config-volume configMap: name: oci-migrator-config -
Distribuire l'immagine Docker Migrator nel pod Kubernetes utilizzando il comando seguente. OKE esegue la utility Migrator in un contenitore su uno dei nodi del cluster Kubernetes.
#Command: kubectl create -f <manifest file> -n <namespace-name>#Example: kubectl create -f migrator-deployment.yaml -n migrator#Output: deployment.apps/nosql-migrator created -
È possibile controllare i log utilizzando i comandi riportati di seguito.
-
Recuperare il nome del pod su cui è in esecuzione l'utility Migrator.
#Command: kubectl get pods -n <namespace-name>#Example: kubectl get pods -n migrator#Output: NAME READY STATUS RESTARTS AGE nosql-migrator-ccdbf549-6sjjg 1/1 Running 0 56s -
Utilizzare il nome del pod per recuperare i log di Migrator.
#Command: kubectl logs -f <kubernetes cluster pod name> -n <namespace-name>#Example: kubectl logs -f nosql-migrator-ccdbf549-6sjjg -n migrator#Output: SLF4J(I): Connected with provider of type [org.apache.logging.slf4j.SLF4JServiceProvider] [INFO] Configuration for migration: { "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : completed loading DDLs [INFO] [cloud sink] : start loading records [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_1_5_0.json [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_6_10_0.json [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 1sec 15ms Migration completed.
Nota:
È possibile eseguire la migrazione dei dati in modo iterativo come indicato di seguito.
-
Eliminare il contenitore
nosql-migratorutilizzando il comando seguente:#Command: kubectl delete -f <manifest file> -n <namespace-name>#Example: kubectl delete -f migrator-deployment.yaml -n migrator#Output: deployment.apps "nosql-migrator" deleted -
Aggiornare il file di input della configurazione
migrator-config.json. -
Eliminare e ricreare la mappa di configurazione utilizzando i comandi del Passo 2.
Non è necessario creare di nuovo il segreto del registro Docker e il file manifest.
-
Distribuire l'immagine Docker Migrator nel pod Kubernetes utilizzando il file manifest (passo 5).
-
Verifica
Per verificare il ripristino dei dati, eseguire il login alla console di Oracle NoSQL Database Cloud Service. Dalla barra di navigazione, andare a Database > NoSQL Database. Selezionare il compartimento dall'elenco a discesa per visualizzare la tabella users. Per la procedura di accesso alla console, vedere Accesso al servizio dalla console dell'infrastruttura.
Esegui la migrazione da Oracle NoSQL Database a OCI Object Storage utilizzando l'autenticazione del token di sessione
Questo esempio mostra come utilizzare Oracle NoSQL Database Migrator con l'autenticazione del token di sessione per copiare i dati dalla tabella Oracle NoSQL Database in un file JSON in un bucket di storage degli oggetti OCI.
Caso d'uso
Come sviluppatore, stai esplorando un'opzione per eseguire il backup dei dati della tabella di Oracle NoSQL Database nello storage degli oggetti OCI (OCI OS). Si desidera utilizzare l'autenticazione basata su token di sessione.
In questa dimostrazione, si utilizzeranno i comandi CLI (Command Line Interface) OCI per creare un token di sessione. Sarà possibile creare manualmente un file di configurazione Migrator ed eseguire la migrazione dei dati.
Prerequisiti
-
Identifica l'origine e il flusso per la migrazione.
-
Origine: tabella
usersin Oracle NoSQL Database. -
Lavello: file JSON nel bucket del sistema operativo OCI
Identifica endpoint, spazio di nomi, bucket e prefisso dell'area per il sistema operativo OCI. Per ulteriori dettagli, vedere Accesso allo storage degli oggetti Oracle Cloud. Per la lista degli endpoint del servizio del sistema operativo OCI, vedere Endpoint di storage degli oggetti.
-
endpoint:
us-ashburn-1 -
bucket:
Migrate_oci -
prefisso:
userSession -
spazio di nomi:
idhkv1iewjzjIl nome dello spazio di nomi per un bucket è lo stesso dello spazio di nomi della tenancy e viene generato automaticamente quando viene creata la tenancy. È possibile ottenere il nome dello spazio di nomi come indicato di seguito.
-
Dalla console di Oracle NoSQL Database Cloud Service, vai a Memorizzazione> Bucket.
-
Selezionare un valore per Compartimento dal campo Ambito lista e selezionare il bucket. La pagina Dettagli bucket visualizza il nome nel parametro Spazio di nomi.
Se non si fornisce un nome per lo spazio di nomi del sistema operativo OCI, la utility Migrator utilizza lo spazio di nomi predefinito della tenancy.
-
-
Nota: assicurarsi di disporre dei privilegi per scrivere gli oggetti nel bucket del sistema operativo OCI. Per ulteriori dettagli sull'impostazione dei criteri, vedere Scrivi nello storage degli oggetti.
-
Generare un token di sessione effettuando le operazioni riportate di seguito.
-
Installare e configurare l'interfaccia CLI OCI. Vedere Avvio rapido.
-
Utilizzare uno dei comandi CLI OCI riportati di seguito per generare un token di sessione. Per ulteriori informazioni sulle opzioni disponibili, vedere Autenticazione basata su token per l'interfaccia CLI.
# Create a session token using OCI CLI from a web browser: oci session authenticate --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --region us-ashburn-1 --profile-name SESSIONPROFILEo
# Create a session token using OCI CLI without a web browser: oci session authenticate --no-browser --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --no-browser --region us-ashburn-1 --profile-name SESSIONPROFILENel comando riportato di seguito:
region_name: specifica l'endpoint dell'area per il sistema operativo OCI. Per una lista di aree dati supportate in Oracle NoSQL Database Cloud Service, vedere Aree dati e URL del servizio associato.profile_name: specifica il profilo utilizzato dal comando CLI OCI per generare un token di sessione.Il comando CLI OCI crea una voce nel file di configurazione OCI nel percorso
$HOME/.oci/config, come mostrato nell'esempio riportato di seguito.[SESSIONPROFILE] fingerprint=f1:e9:b7:e6:25:ff:fe:05:71:be:e8:aa:cc:3d:0d:23 key_file=$HOME/.oci/sessions/SESSIONPROFILE/oci_api_key.pem tenancy=ocid1.tenancy.oc1..aaaaa ... d6zjq region=us-ashburn-1 security_token_file=$HOME/.oci/sessions/SESSIONPROFILE/tokenIl comando
security_token_filepunta al percorso del token di sessione generato utilizzando il comando CLI OCI sopra riportato.Nota:
-
Se il profilo esiste già nel file di configurazione OCI, il comando CLI OCI sovrascrive il profilo con una configurazione correlata alla sessione durante la generazione del token di sessione.
-
Specificare quanto segue nel modello di configurazione sink:
-
Percorso del file di configurazione OCI nel parametro delle credenziali.
-
Profilo utilizzato durante la generazione del token di sessione nel parametro credentialProfile.
"credentials" : "$HOME/.oci/config" "credentialsProfile" : "SESSIONPROFILE"La utility Migrator recupera automaticamente i dettagli del token di sessione generato utilizzando i parametri precedenti. Se non si specifica il parametro delle credenziali, la utility Migrator cerca il file delle credenziali nel percorso
$HOME/.oci. Se non si specifica il parametro credentialProfile, la utility Migrator utilizza il nome di profilo predefinito (DEFAULT) dal file di configurazione OCI.- Il token di sessione è valido per 60 minuti. Per estendere la durata della sessione, è possibile aggiornare la sessione. Per informazioni dettagliate, vedere Aggiornamento di un token.
-
-
Procedura
Per eseguire la migrazione dalla tabella Oracle NoSQL Database a un file JSON nel bucket del sistema operativo OCI, effettuare le operazioni riportate di seguito.
-
Preparare il file di configurazione (in formato JSON) con l'origine Oracle NoSQL Database e il file JSON nell' sink del bucket del sistema operativo OCI. Per i modelli, vedere Modelli di configurazione di origine e Modelli di configurazione del collegamento.
Per utilizzare l'autenticazione del token di sessione per accedere al bucket del sistema operativo OCI, impostare il parametro useSessionToken su true nel modello di configurazione del sink. Specificare di conseguenza il percorso di configurazione nel parametro delle credenziali e il nome del profilo nel parametro credenzialiProfile.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:<port>"], "table" : "users", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "chunkSize" : 32, "compression" : "", "useSessionToken" : true, "credentials" : "$/home/.oci/config", "credentialsProfile" : "SESSIONPROFILE" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Aprire il prompt dei comandi e passare alla directory in cui è stata estratta la utility NoSQL Database Migrator.
-
Eseguire il comando runMigrator passando l'opzione del file di configurazione. Utilizzare l'opzione
--configo-cper passare il file di configurazione come indicato di seguito../runMigrator --config ./migrator-config.json -
La utility Migrator procede con la migrazione dei dati. Di seguito è riportato un esempio di output.
Se il parametro useSessionToken è impostato su true, l'utility Migrator esegue automaticamente l'autenticazione utilizzando il token di sessione. La utility Migrator copia i dati dalla tabella
usersin un file JSON nel bucket del sistema operativo OCI denominatoMigrate_oci. Controllare i log per il backup dei dati riuscito.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [OCI OS sink] : writing table schema to userSession/Schema/schema.ddl [INFO] migration started [INFO] Migration success for source users_6_10. read=2,written=2,failed=0 [INFO] Migration success for source users_1_5. read=3,written=3,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 982ms Migration completed.Nota:
A seconda del parametro chunkSize nel modello di configurazione del sink, la utility Migrator divide i dati di origine in diversi file JSON nella stessa directory. In questo esempio, la utility Migrator copia i dati in file
users_1_5_0.jsoneusers_6_10_0.jsonnella directoryMigrate_oci/userSession/Data.Lo schema della tabella di origine viene copiato nel file
schema.ddlnella directoryMigrate_oci/userSession/Schema.
Verifica
Per verificare il backup dei dati, eseguire il login alla console di Oracle NoSQL Database Cloud Service. Navigare tra i menu, Storage > Object Storage & Archive Storage > Buckets. Accedere ai file dalla directory userSession nel bucket Migrate_oci. Per la procedura di accesso alla console, vedere Accesso al servizio dalla console dell'infrastruttura.
Esegui migrazione da file CSV a Oracle NoSQL Database Cloud Service
Questo esempio mostra l'uso di Oracle NoSQL Database Migrator per copiare i dati da un file CSV a Oracle NoSQL Database Cloud Service.
Esempio
Dopo aver valutato più opzioni, un'organizzazione finalizza Oracle NoSQL Database Cloud Service come piattaforma di database NoSQL. Poiché i contenuti di origine sono in formato file CSV, stanno cercando un modo per eseguirne la migrazione a Oracle NoSQL Database Cloud Service.
In questo esempio, verrà descritto come eseguire la migrazione dei dati da un file CSV denominato course.csv, che contiene informazioni sui vari corsi offerti da un'università. Il file di configurazione viene generato in modo interattivo dalla utility runMigrator.
È inoltre possibile preparare il file di configurazione con i dettagli di origine e sink identificati. Vedere Oracle NoSQL Database Migrator Reference.
Prerequisiti
-
Identificare l'origine per la migrazione.
-
Origine: file CSV
In questo esempio, il file di origine è
course.csv1,"Computer Science", "San Francisco", "2500" 2,"Bio-Technology", "Los Angeles", "1200" 3,"Journalism", "Las Vegas", "1500" 4,"Telecommunication", "San Francisco", "2500" -
Il file CSV deve essere conforme al formato
RFC4180. -
Creare un file contenente i comandi DDL per lo schema della tabella di destinazione,
course. La definizione della tabella deve corrispondere al file di dati CSV relativo al numero di colonne e ai relativi tipi.In questo esempio, il file DDL è
mytable_schema.ddlcreate table course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id));
-
-
Identificare il sink per la migrazione.
-
Lavello: Oracle NoSQL Database Cloud Service
-
Identificare le credenziali cloud OCI e acquisirle nel file di configurazione. Salvare il file di configurazione in
/home/<user>/.oci/config. Per ulteriori dettagli, vedere Acquisizione delle credenziali.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identificare l'endpoint dell'area e il nome del compartimento per Oracle NoSQL Database Cloud Service.
-
endpoint:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaavjikiwmylfnpofefbdaleg6rqyf7cdnr5o6vozg4lyajeunrhsmq
-
-
Procedura
Per eseguire la migrazione dei dati dal file course.csv a Oracle NoSQL Database Cloud Service, effettuare le operazioni riportate di seguito.
-
Aprire il prompt dei comandi e andare alla directory in cui è stata estratta la utility Migrator di Oracle NoSQL Database.
-
Per generare il file di configurazione utilizzando Oracle NoSQL Database Migrator, eseguire il comando
runMigratorsenza alcun parametro runtime.[~/nosql-migrator-1.8.0]$./runMigrator -
Poiché il file di configurazione non è stato fornito come parametro di runtime, l'utility richiede se si desidera generare la configurazione ora. Digitare
y.È possibile scegliere una posizione per il file di configurazione o mantenere la posizione predefinita premendo
Enter key.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. Enter a location for your config [./migrator-config.json]: ./migrator-config.json already exist. Do you want to overwrite?(y/n) [n]: y -
In base ai prompt della utility, scegliere le opzioni per la configurazione di origine.
Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 3 Configuration for source type=file Select the source file format: 1) json 2) mongodb_json 3) dynamodb_json 4) csv #? 4 -
Fornire il percorso del file CSV di origine. Inoltre, in base ai prompt dell'utility, è possibile scegliere di riordinare i nomi delle colonne, selezionare il metodo di codifica e tagliare gli spazi di adattamento dalla tabella di destinazione.
Enter path to a file or directory containing csv data: [~/nosql-migrator]/course.csv Does the CSV file contain a headerLine? (y/n) [n]: n Do you want to reorder the column names of NoSQL table with respect to CSV file columns? (y/n) [n]: n Provide the CSV file encoding. The supported encodings are: UTF-8,UTF-16,US-ASCII,ISO-8859-1. [UTF-8]: Do you want to trim the tailing spaces? (y/n) [n]: n -
In base ai prompt della utility, scegliere l'opzione
nosqldb_cloudper la configurazione del lavandino.Select the sink: 1) nosqldb 2) nosqldb_cloud #? 2 -
Fornire l'URL dell'endpoint o l'ID area della tenancy e selezionare il tipo di autenticazione per la utility Migrator per accedere a Oracle NoSQL Database Cloud Service.
Configuration for sink type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-ashburn-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 -
In base ai prompt della utility, fornire il nome del file delle credenziali da utilizzare per l'autenticazione, il profilo delle credenziali, l'ID compartimento e il nome della tabella in cui si desidera copiare i dati nel sink.
Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: ua_nosql Enter table name: course -
Immettere la scelta per impostare il valore TTL. Il valore predefinito è
n.Include TTL data? If you select 'yes' TTL value provided by the source will be set on imported rows. (y/n) [n]: y Would you like to provide TTL reference time?(y/n) [n]: n -
In base ai prompt della utility, specificare se la tabella di destinazione deve essere creata o meno tramite lo strumento Migratore di Oracle NoSQL Database. Se la tabella è già stata creata, si consiglia di fornire
n. Se la tabella non viene creata, l'utility richiederà il percorso per il file contenente i comandi DDL per lo schema della tabella di destinazione.Would you like to create table as part of migration process? Use this option if you want to create table through the migration tool. If you select yes, you will be asked to provide a file that contains table DDL or to use schema provided by the source or default schema. (y/n) [n]: y Enter path to a file containing table DDL: [~/nosql-migrator]/mytable_schema.ddl -
Immettere i valori di throughput e l'allocazione di storage per la tabella sink.
Would you like to use on demand read and write units? (y/n) [n]: n Enter read throughput in KB of new table: 100 Enter write throughput in KB of new table: 60 Enter storage size in GB of new table: 1 Enter percentage of table write units to be used for migration operation. (1-100) [90]: 90 -
Immettere le opzioni desiderate per determinare se sovrascrivere i record se la tabella è già disponibile nel sink. È inoltre possibile aggiungere trasformazioni ai dati di origine.
would you like to overwrite records which are already present? If you select 'no' records with same primary key will be skipped [y/n] [y]: y Enter store operation timeout in milliseconds. [5000]: Would you like to add transformations to source data? (y/n) [n]: n Would you like to continue migration if any data fails to be migrated? (y/n) [n]: n -
La utility visualizza la configurazione generata sullo schermo.
{ "source" : { "type" : "file", "format" : "csv", "dataPath" : "[~/nosql-migrator]/course.csv", "hasHeader" : false, "csvOptions" : { "encoding" : "UTF-8", "trim" : false } }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "course", "compartment" : "ua_nosql", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "schemaPath" : "[~/nosql-migrator]/mytable_schema.ddl" }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Infine, l'utility richiede di specificare se procedere o meno con la migrazione utilizzando il file di configurazione generato. L'opzione predefinita è
y.Nota:
Se si seleziona
n, la migrazione dei dati non viene avviata. Il file di configurazione generato viene salvato nella directory Migrator. Utilizzare uno dei comandi seguenti per eseguire la utility di migrazione con l'opzione del file di configurazione../runMigrator -c ./migrator-config.json./runMigrator --config ./migrator-config.jsonWould you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config ./migrator-config.json (y/n) [y]: y -
NoSQL Database Migrator copia i dati dal file CSV in Oracle NoSQL Database Cloud Service.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table if not exists course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [csv file source] : start parsing CSV records from file: course.csv Migration success for source course. read=4,written=4,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=4, Records written to sink=4, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 395ms Migration completed.
Verifica
Per verificare la migrazione, è possibile eseguire il login alla console di Oracle NoSQL Database Cloud Service e accedere alla tabella course. La tabella contiene i dati di origine. Per la procedura di accesso alla console, vedere l'articolo Accesso al servizio dalla console dell'infrastruttura nel documento Oracle NoSQL Database Cloud Service.