Usando JupyterHub no Big Data Service 3.0.26 ou Anterior
Use JupyterHub para gerenciar notebooks ODH 1.x do Big Data Service 3.0.26 ou anterior para grupos de usuários.
Pré-requisitos
Para que JupyterHub possa ser acessado em um browser, um administrador deve:
- Disponibilizar o nó para conexões de entrada dos usuários. O endereço IP privado do nó precisa ser mapeado para um endereço IP público. Como alternativa, o cluster pode ser configurado para usar um bastion host ou o Oracle FastConnect. Consulte Estabelecendo Conexão a Nós de Cluster com Endereços IP Privados.
- Abra a porta
8000no nó configurando as regras de entrada na lista de segurança de rede. Consulte Definindo Regras de Segurança.
JupyterHub Credenciais Padrão
As credenciais de acesso do administrador padrão para JupyterHub no Big Data Service 3.0.21 e versões anteriores são:
- Nome de usuário:
jupyterhub - Senha: A senha de administrador do Apache Ambari. Esta é a senha admin do cluster especificada durante a criação do cluster.
- Nome principal do cluster HA:
jupyterhub - Keytab do cluster HA:
/etc/security/keytabs/jupyterhub.keytab
As credenciais de acesso do administrador padrão para JupyterHub no Big Data Service 3.0.22 a 3.0.26 são:
- Nome de usuário:
jupyterhub - Senha: A senha de administrador do Apache Ambari. Esta é a senha admin do cluster especificada durante a criação do cluster.
- Nome principal do cluster HA:
jupyterhub/<FQDN-OF-UN1-Hostname> - Keytab do cluster HA:
/etc/security/keytabs/jupyterhub.keytabPor exemplo:Principal name for HA cluster: jupyterhub/pkbdsv2un1.rgroverprdpub1.rgroverprd.oraclevcn.com Keytab for HA cluster: /etc/security/keytabs/jupyterhub.keytab
O administrador cria usuários adicionais e suas credenciais de acesso e fornece as credenciais de acesso a esses usuários. Para obter mais informações, consulte Gerenciar Usuários e Permissões.
A menos que seja explicitamente especificado como algum outro tipo de administrador, o uso de administrator ou admin em toda essa seção se refere ao administrador do JupyterHub, jupyterhub.
Acessando o JupyterHub
Como alternativa, você pode acessar o link JupyterHub na página de detalhes do Cluster em URLs do Cluster.
Você também pode criar um Balanceador de Carga para fornecer um front-end seguro para acessar serviços, incluindo JupyterHub. Consulte Conexão com Serviços em um Cluster Usando o Balanceador de Carga.
Criando Notebooks
Os pré-requisitos devem ser atendidos pelos usuários que estão tentando criar notebooks.
- Acesse JupyterHub.
- Acesse com credenciais administrativas. A autorização só funcionará se o usuário estiver presente no host do Linux. O JupyterHub procura o usuário no host do Linux enquanto tenta gerar o servidor de notebook.
- Você será redirecionado para uma página Opções do Servidor, na qual deverá solicitar um ticket do Kerberos. Esse ticket pode ser solicitado usando o principal do Kerberos e o arquivo keytab ou a senha do Kerberos. O administrador do cluster pode fornecer o principal do Kerberos e o arquivo keytab ou a senha do Kerberos.
O ticket do Kerberos é necessário para ter acesso nos diretórios HDFS e em outros serviços do big data que você deseja usar.
Os pré-requisitos devem ser atendidos pelos usuários que estão tentando criar notebooks.
- Acesse JupyterHub.
- Acesse com credenciais administrativas. A autorização só funcionará se o usuário estiver presente no host do Linux. O JupyterHub procura o usuário no host do Linux enquanto tenta gerar o servidor de notebook.
Gerenciar JupyterHub
Um usuário JupyterHub admin pode executar as seguintes tarefas para gerenciar notebooks em JupyterHub nos nós ODH 1.x do Big Data Service 3.0.26 ou anterior.
Como admin, você pode configurar JupyterHub.
Configure JupyterHub por meio do browser para clusters do Big Data Service 3.0.26 ou anteriores.
Interrompa ou inicie JupyterHub por meio do browser para clusters do Big Data Service 3.0.26 ou anteriores.
Como admin, você pode interromper ou desativar o aplicativo para que ele não consuma recursos, como memória. A reinicialização também pode ajudar com problemas ou comportamentos inesperados.
Como administrador, você pode limitar o número de servidores de notebook ativos no cluster do Big Data Service.
Por padrão, os notebooks são armazenados no diretório HDFS de um cluster.
Você deve ter acesso ao diretório HDFS hdfs:///user/<username>/. Os notebooks são salvos em hdfs:///user/<username>/notebooks/.
- Estabeleça conexão como usuário
opccom o nó do utilitário no qual JupyterHub está instalado (o segundo nó do utilitário de um cluster HA (altamente disponível) ou o primeiro e único nó do utilitário de um cluster não HA). - Use
sudopara gerenciar as configurações JupyterHub que são armazenadas em/opt/jupyterhub/jupyterhub_config.py.c.Spawner.args = ['--ServerApp.contents_manager_class="hdfscm.HDFSContentsManager"'] - Use
sudopara reiniciar JupyterHub.sudo systemctl restart jupyterhub.service
Como usuário administrador, você pode armazenar os notebooks de usuários individuais no Object Storage, em vez de no HDFS. Quando você altera o gerenciador de conteúdo do HDFS para o Object Storage, os notebooks existentes não são copiados para o Object Storage. Os novos notebooks são salvos no Object Storage.
- Estabeleça conexão como usuário
opccom o nó do utilitário no qual JupyterHub está instalado (o segundo nó do utilitário de um cluster HA (altamente disponível) ou o primeiro e único nó do utilitário de um cluster não HA). - Use
sudopara gerenciar as configurações JupyterHub que são armazenadas em/opt/jupyterhub/jupyterhub_config.py. Consulte gerar acesso e chave secreta para saber como gerar as chaves obrigatórias.c.Spawner.args = ['--ServerApp.contents_manager_class="s3contents.S3ContentsManager"', '--S3ContentsManager.bucket="<bucket-name>"', '--S3ContentsManager.access_key_id="<accesskey>"', '--S3ContentsManager.secret_access_key="<secret-key>"', '--S3ContentsManager.endpoint_url="https://<object-storage-endpoint>"', '--S3ContentsManager.region_name="<region>"','--ServerApp.root_dir=""'] - Use
sudopara reiniciar JupyterHub.sudo systemctl restart jupyterhub.service
Integrar com o Object Storage
Integre o Spark ao Object Storage para uso com clusters do Big Data Service.
Em JupyterHub, para que o Spark funcione com o Object Storage, defina algumas propriedades do sistema e preencha-as nas configurações do Spark spark.driver.extraJavaOption e spark.executor.extraJavaOptions.
Para poder integrar com sucesso JupyterHub com o Object Storage, você deverá:
- Criar um bucket no Object Store para armazenar dados.
- Criar uma chave de API do Object Storage.
As propriedades que você deve definir nas configurações do Spark são:
-
TenantID -
Userid -
Fingerprint -
PemFilePath -
PassPhrase -
Region
Para recuperar os valores dessas propriedades:
- Abra o menu de navegação e selecione Análise e IA. Em Data Lake, selecione Big Data Service.
- Na página da lista Clusters, selecione o cluster com o qual você deseja trabalhar. Se precisar de ajuda para localizar a página de lista ou o cluster, consulte Listando Clusters em um Compartimento.
-
Para exibir clusters em outro compartimento, alterne o Compartimento.
Você deve ter permissão para trabalhar em um compartimento para ver os recursos nele. Se você não tiver certeza sobre qual compartimento usar, entre em contato com um administrador. Para obter mais informações consulte Noções Básicas de Compartimentos.
- Na página de detalhes do Cluster, selecione Chaves de API do serviço Object Storage.
- No menu da chave de API que você deseja exibir, selecione Exibir arquivo de configuração.
O arquivo de configuração tem todos os detalhes de propriedades do sistema, exceto a frase-senha. A frase-senha é especificada ao criar a chave da API do Object Storage e você deve lembrar e usar a mesma frase-senha.
- Acesse JupyterHub.
- Abra um novo notebook.
- Copie e cole os comandos a seguir para estabelecer conexão com o Spark.
import findspark findspark.init() import pyspark - Copie e cole os comandos a seguir para criar uma sessão no Spark com as configurações especificadas. Substitua as variáveis pelos valores de propriedades do sistema recuperados anteriormente.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("spark.driver.extraJavaOptions", "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .config("spark.executor.extraJavaOptions" , "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .appName("<appname>") \ .getOrCreate() - Copie e cole os comandos a seguir para criar os diretórios e o arquivo do Object Storage e armazenar dados no Formato Parquet.
demoUri = "oci://<BucketName>@<Tenancy>/<DirectoriesAndSubDirectories>/" parquetTableUri = demoUri + "<fileName>" spark.range(10).repartition(1).write.mode("overwrite").format("parquet").save(parquetTableUri) - Copie e cole o comando a seguir para ler os dados do Object Storage.
spark.read.format("parquet").load(parquetTableUri).show() - Execute o notebook com todos esses comandos.
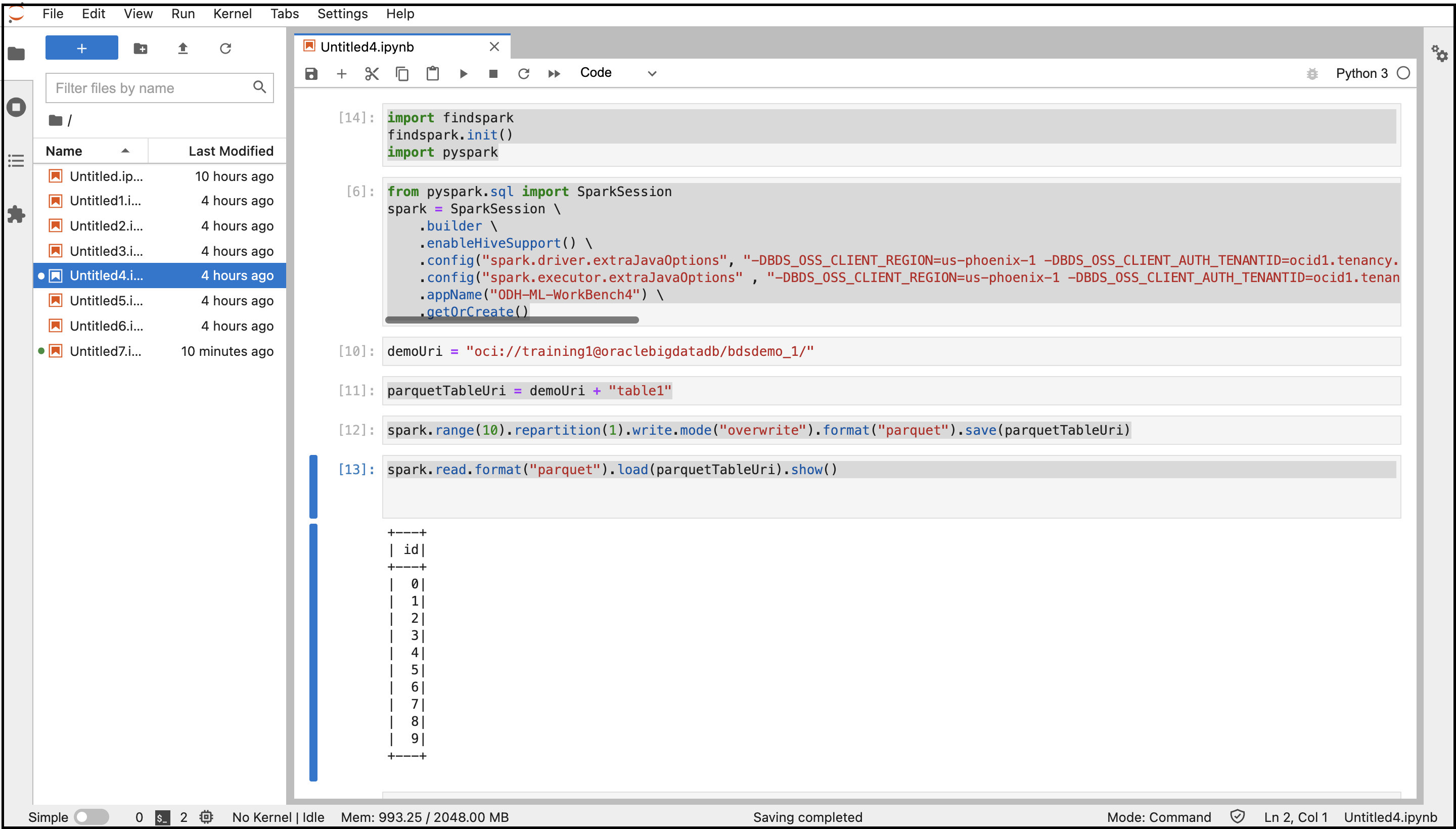
A saída do código é exibida. Você pode navegar até o bucket do Object Storage na Console e localizar o arquivo criado no bucket.
Gerenciar Usuários e Permissões
Use um dos dois métodos de autenticação para autenticar usuários em JupyterHub para que eles possam criar notebooks e, opcionalmente, administrar JupyterHub.
Por padrão, os clusters ODH 1.x suportam autenticação nativa. Mas a autenticação para JupyterHub e outros serviços big data deve ser tratada de forma diferente. Para gerar notebooks de usuário único, o usuário que faz log-in em JupyterHub precisa estar presente no host do Linux e precisa ter permissões para gravar no diretório raiz do HDFS. Caso contrário, o criador falhará porque o processo de notebook é acionado como usuário do Linux.
Para obter informações sobre autenticação nativa, consulte Autenticação Nativa.
Para obter informações sobre autenticação LDAP para o Big Data Service 3.0.26 ou anterior, consulte Autenticação LDAP.
A autenticação nativa depende do banco de dados do usuário JupyterHub para autenticar usuários.
A autenticação nativa se aplica a clusters HA e não HA. Consulte autenticador nativo para obter detalhes sobre o autenticador nativo.
Esses pré-requisitos devem ser atendidos para autorizar um usuário em um cluster HA do Big Data Service usando a autenticação nativa.
Esses pré-requisitos devem ser atendidos para autorizar um usuário em um cluster não HA do Big Data Service usando a autenticação nativa.
Os usuários administradores são responsáveis por configurar e gerenciar JupyterHub. Os usuários administradores também são responsáveis por autorizar usuários recém-inscritos em JupyterHub.
Antes de adicionar um usuário administrador, os pré-requisitos devem ser atendidos para um cluster não HA.
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione JupyterHub.
- Selecione Configurações e, em seguida, Configurações Avançadas.
- Selecione Advanced jupyterhub-config.
-
Adicione o usuário administrador a
c.Authenticator.admin_users. - Selecione Salvar.
Antes de adicionar outros usuários, os pré-requisitos devem ser atendidos para um cluster do Big Data Service.
-
O usuário administrador deve acessar JupyterHub e na nova opção de menu para autorizar usuários conectados e o novo usuário.
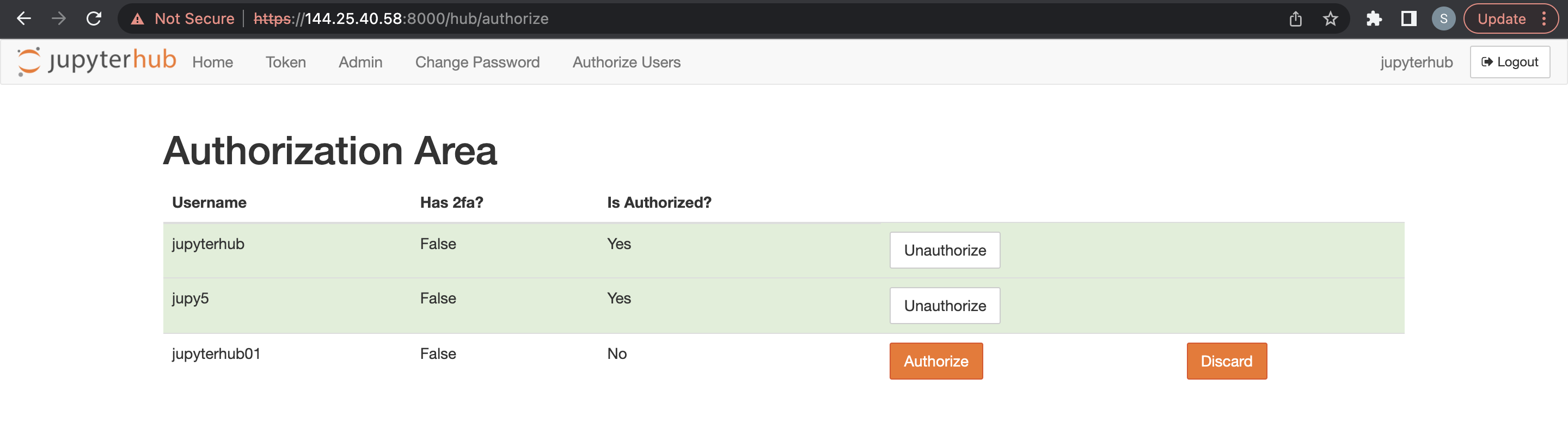
Um usuário administrador pode excluir usuários JupyterHub.
- Acesse o JupyterHub.
- Abra Arquivo > HubControlPanel.
- Navegue até a página Autorizar Usuários.
- Exclua os usuários que você deseja remover.
Você pode usar a autenticação LDAP por meio de um browser para clusters ODH 1.x do Big Data Service 3.0.26 ou anteriores.
Integre com o Trino
- O Trino deve ser instalado e configurado no cluster do Big Data Service.
- Instale o seguinte módulo Python no nó JupyterHub (un1 para HA / un0 para cluster não HA) Observação
Ignore esta etapa se o módulo Trino-Python já estiver presente no nó.python3.6 -m pip install trino[sqlalchemy] Offline Installation: Download the required python module in any machine where we have internet access Example: python3 -m pip download trino[sqlalchemy] -d /tmp/package Copy the above folder content to the offline node & install the package python3 -m pip install ./package/* Note : trino.sqlalchemy is compatible with the latest 1.3.x and 1.4.x SQLAlchemy versions. BDS cluster node comes with python3.6 and SQLAlchemy-1.4.46 by default.
Se o Trino-Ranger-Plugin estiver ativado, certifique-se de adicionar o usuário do keytab fornecido nas respectivas políticas do Trino Ranger. Consulte Integrando o Trino ao Ranger.
Por padrão, o Trino usa o nome principal completo do Kerberos como usuário. Portanto, ao adicionar/atualizar políticas de trino-ranger, você deve usar o nome principal completo do Kerberos como nome de usuário.
Para a amostra de código a seguir, use jupyterhub@BDSCLOUDSERVICE.ORACLE.COM como usuário nas políticas trino-ranger.
Se o Trino-Ranger-Plugin estiver ativado, certifique-se de adicionar o usuário do keytab fornecido nas respectivas políticas do Trino Ranger. Para obter mais detalhes, consulte Ativando o Ranger para Trino.
Forneça permissões do Ranger para JupyterHub às seguintes políticas:
-
all - catalog, schema, table, column -
all - function