Usando JupyterHub no Big Data Service 3.0.27 ou Mais Recente
Use JupyterHub para gerenciar notebooks ODH 2.x do Big Data Service 3.0.27 ou posterior para grupos de usuários.
Pré-requisitos
Acessando o JupyterHub
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione JupyterHub.
Gerenciar JupyterHub
Um usuário JupyterHub admin pode executar as seguintes tarefas para gerenciar notebooks em JupyterHub nos nós ODH 2.x do Big Data Service 3.0.27 ou posterior.
Para gerenciar os serviços do Oracle Linux 7 com o comando systemctl, consulte Como Trabalhar com Serviços do Sistema.
Para acessar uma instância do Oracle Cloud Infrastructure, consulte Conectando-se à sua Instância.
Como administrador, você pode interromper ou desativar JupyterHub para que ele não consuma recursos, como memória. A reinicialização também pode ajudar com problemas ou comportamentos inesperados.
Interrompa ou inicie JupyterHub por meio do Ambari para clusters do Big Data Service 3.0.27 ou mais recentes.
Como administrador, você pode adicionar o Servidor JupyterHub a um nó do Big Data Service.
Está disponível para clusters do Big Data Service 3.0.27 ou mais recentes.
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, selecione Hosts.
- Para adicionar o Servidor JupyterHub, selecione um host em que JupyterHub não esteja instalado.
- Selecione Adicionar.
- Selecione JupyterHub Server.
Como administrador, você pode mover o Servidor JupyterHub para outro nó do Big Data Service.
Está disponível para clusters do Big Data Service 3.0.27 ou mais recentes.
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione JupyterHub.
- Selecione Ações e, em seguida, Mover Servidor JupyterHub.
- Selecione Próximo.
- Selecione o host para o qual mover o Servidor JupyterHub.
- Conclua o assistente de movimentação.
Como administrador, você pode executar verificações de serviço/integridade JupyterHub por meio do Ambari.
Está disponível para clusters do Big Data Service 3.0.27 ou mais recentes.
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione JupyterHub.
- Selecione Ações e, em seguida, Executar Verificação de Serviço.
Gerenciar Usuários e Permissões
Use um dos dois métodos de autenticação para autenticar usuários em JupyterHub para que eles possam criar notebooks e, opcionalmente, administrar JupyterHub em clusters ODH 2.x do Big Data Service 3.0.27 ou posterior.
OS usuários JupyterHub devem ser adicionados como usuários do sistema operacional em todos OS nós de cluster do Big Data Service para clusters do Big Data Service não Active Directory (AD), nos quais OS usuários não são sincronizados automaticamente em todos OS nós de cluster. Os administradores podem usar o script de Gerenciamento de Usuários JupyterHub para adicionar usuários e grupos antes de acessar JupyterHub.
Pré-requisitos
Execute o seguinte antes de acessar JupyterHub:
- O acesso SSH ao nó em que JupyterHub está instalado.
- Navegue até
/usr/odh/current/jupyterhub/install. - Para fornecer os detalhes de todos os usuários e grupos no arquivo
sample_user_groups.json, execute:sudo python3 UserGroupManager.py sample_user_groups.json Verify user creation by executing the following command: id <any-user-name>
Tipos de Autenticação Suportados
- NativeAuthenticator: Este autenticador é usado para aplicativos JupyterHub de pequeno ou médio porte. Cadastre-se e a autenticação são implementadas como nativas de JupyterHub sem depender de serviços externos.
-
SSOAuthenticator: Esse autenticador fornece uma subclasse de
jupyterhub.auth.Authenticatorque atua como um Provedor de Serviços SAML2. Direcione-o para um Provedor de Identidades SAML2 configurado adequadamente e ele ativará o sign-on único para JupyterHub.
A autenticação nativa depende do banco de dados do usuário JupyterHub para autenticar usuários.
A autenticação nativa se aplica a clusters HA e não HA. Consulte autenticador nativo para obter detalhes sobre o autenticador nativo.
Esses pré-requisitos devem ser atendidos para autorizar um usuário em um cluster HA do Big Data Service usando a autenticação nativa.
Esses pré-requisitos devem ser atendidos para autorizar um usuário em um cluster não HA do Big Data Service usando a autenticação nativa.
Os usuários administradores são responsáveis por configurar e gerenciar JupyterHub. Os usuários administradores também são responsáveis por autorizar usuários recém-inscritos em JupyterHub.
Antes de adicionar um usuário administrador, os pré-requisitos devem ser atendidos para um cluster não HA.
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione JupyterHub.
- Selecione Configurações e, em seguida, Configurações Avançadas.
- Selecione Advanced jupyterhub-config.
-
Adicione o usuário administrador a
c.Authenticator.admin_users. - Selecione Salvar.
Antes de adicionar outros usuários, os pré-requisitos devem ser atendidos para um cluster do Big Data Service.
-
O usuário administrador deve acessar JupyterHub e na nova opção de menu para autorizar usuários conectados e o novo usuário.
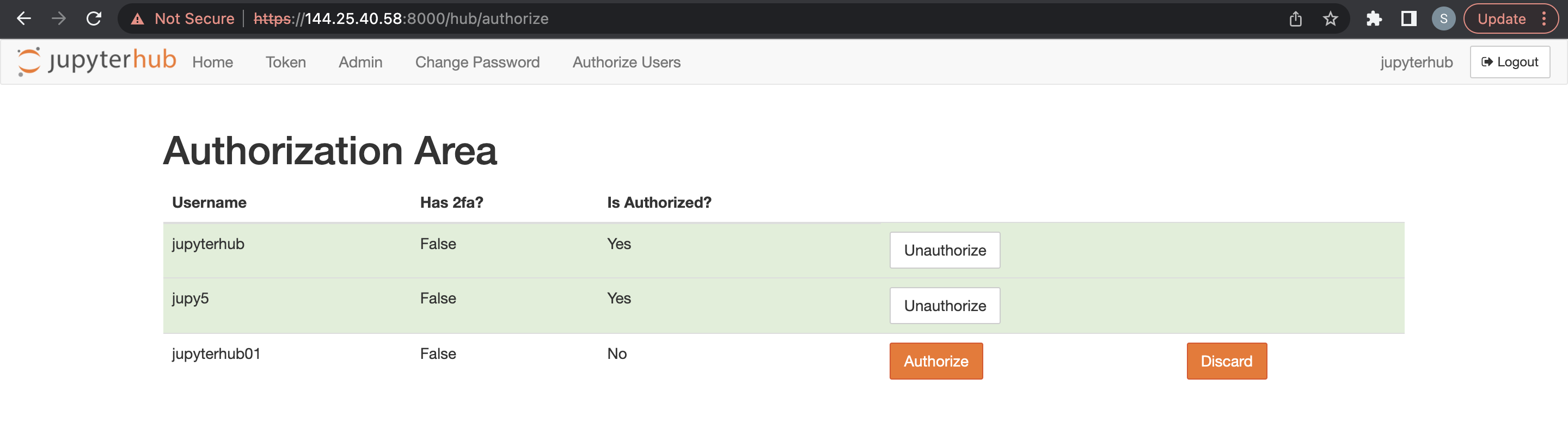
Um usuário administrador pode excluir usuários JupyterHub.
- Acesse o JupyterHub.
- Abra Arquivo > HubControlPanel.
- Navegue até a página Autorizar Usuários.
- Exclua os usuários que você deseja remover.
Você pode usar a autenticação LDAP por meio do Ambari para clusters ODH 2.x do Big Data Service 3.0.27 ou posterior.
Usando Autenticação LDAP Usando Ambari
Para usar o autenticador LDAP, atualize o arquivo de configuração JupyterHub com os detalhes da conexão LDAP.
Use o Ambari para autenticação LDAP em clusters do Big Data Service 3.0.27 ou mais recentes.
Consulte Autenticador LDAP para obter detalhes sobre o autenticador LDAP.
pConfigure Autenticação SSO no serviço ODH 2.x JupyterHub do Big Data Service 3.0.27 ou posterior.
Você pode usar o Oracle Identity Domain para configurar a Autenticação SSO nos clusters ODH 2.x JupyterHub do Big Data Service 3.0.27 ou posterior.
Você pode usar o OKTA para configurar a Autenticação SSO nos clusters ODH 2.x JupyterHub do Big Data Service 3.0.27 ou posterior.
Como administrador, você pode gerenciar configurações JupyterHub por meio do Ambari para clusters ODH 2.x do Big Data Service 3.0.27 ou posterior.
Criando Notebooks
As configurações do Spawner a seguir são suportadas nos clusters ODH 2.x do Big Data Service 3.0.27 e posterior.
Preencha as seguintes informações:
- Autenticação Nativa:
- Acessar usando credenciais de usuário conectado
- Inserir nome do usuário.
- Informe a senha.
- Usando SamlSSOAuthenticator:
- Faça login com SSO.
- Conclua o sign-in com o aplicativo SSO configurado.
Criando Notebooks em um Cluster HA
Para cluster integrado do AD:
- Efetue sign-in usando um dos métodos anteriores. A autorização só funcionará se o usuário estiver presente no host do Linux. O JupyterHub procura o usuário no host do Linux enquanto tenta gerar o servidor de notebook.
- Você será redirecionado para uma página Opções do Servidor, na qual deverá solicitar um ticket do Kerberos. Esse ticket pode ser solicitado usando o principal do Kerberos e o arquivo keytab ou a senha do Kerberos. O administrador do cluster pode fornecer o principal do Kerberos e o arquivo keytab ou a senha do Kerberos. O ticket do Kerberos é necessário para ter acesso nos diretórios HDFS e em outros serviços do big data que você deseja usar.
Criando Notebooks em um Cluster não HA
Para cluster integrado do AD:
Efetue sign-in usando um dos métodos anteriores. A autorização só funcionará se o usuário estiver presente no host do Linux. O JupyterHub procura o usuário no host do Linux enquanto tenta gerar o servidor de notebook.
- Configure chaves SSH/Tokens de acesso para o nó do cluster do Big Data Service.
- Selecione o modo de persistência do notebook como Git.
Para configurar a conexão Git para JupyterHub, faça o seguinte:
- Tokens de acesso para o nó do cluster do Big Data Service.
- Selecionar modo de persistência de notebook como Git
Gerando Par de Chaves SSH
Usando Tokens de Acesso
Você pode usar tokens de acesso das seguintes formas:
- GitHub:
- Acesse sua conta do GitHub.
- Navegue até Definições > Configurações do desenvolvedor > Tokens de acesso pessoal.
- Gere um novo token de acesso com as permissões apropriadas.
- Use o token de acesso como sua senha quando for solicitada a autenticação.
- GitLab:
- Acesse sua conta do GitHub.
- Navegue até Definições > Tokens de Acesso.
- Gere um novo token de acesso com as permissões apropriadas.
- Use o token de acesso como sua senha quando for solicitada a autenticação.
- BitBucket:
- Acesse sua conta do BitBucket.
- Navegue até Configurações > Senhas do aplicativo.
- Gere um novo token de senha de aplicativo com as permissões apropriadas.
- Use a nova senha do aplicativo como senha quando for solicitada a autenticação.
Selecionando o Modo de Persistência como Git
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione JupyterHub.
- Selecione Configurações e, em seguida, Configurações.
- Procure o modo de persistência de notebook e selecione Git na lista drop-down.
- Selecione Ações e, em seguida, Reiniciar Tudo.
- Acesse o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione JupyterHub.
- Selecione Configurações e, em seguida, Configurações.
- Procure o modo de persistência de notebook e selecione HDFS na lista drop-down.
- Selecione Ações e, em seguida, Reiniciar Tudo.
Como usuário administrador, você pode armazenar os notebooks de usuários individuais no Object Storage, em vez de no HDFS. Quando você altera o gerenciador de conteúdo do HDFS para o Object Storage, os notebooks existentes não são copiados para o Object Storage. Os novos notebooks são salvos no Object Storage.
Montando o Bucket do Oracle Object Storage Usando rclone com Autenticação do Controlador de Usuários
Você pode montar o Oracle Object Storage usando rclone com Autenticação Principal do Usuário (Chaves de API) em um nó de cluster do Big Data Service usando rclone e fuse3, personalizados para usuários do JupyterHub.
Gerenciar Ambientes Conda em JupyterHub
Você pode gerenciar ambientes Conda em clusters ODH 2.x do Big Data Service 3.0.28 ou posterior.
- Crie um ambiente conda com dependências específicas e crie quatro kernels (Python/PySpark/Spark/SparkR) que apontam para o ambiente conda criado.
- Os ambientes conda e os kernels criados usando esta operação estão disponíveis para todos os usuários do servidor de notebook.
- A operação de criação separada do ambiente conda é desacoplar a operação com a reinicialização do serviço.
- O JupyterHub é instalado por meio da IU do Ambari.
- Verifique o acesso à Internet ao cluster para fazer download de dependências durante a criação do conda.
- Os ambientes conda e os kernels criados usando esta operação estão disponíveis para todos os usuários do servidor de notebook."
- Forneça:
- Configurações adicionais do conda para evitar falha na criação do conda. Para obter mais informações, consulte conda create
- Dependências no formato de requisitos padrão
.txt. - Um nome de ambiente conda que não existe.
- Exclua manualmente ambientes conda ou kernels.
Esta operação cria um ambiente conda com dependências especificadas e cria o kernel especificado (Python/PySpark/Spark/SparkR) apontando para o ambiente conda criado.
- Se o ambiente conda especificado já existir, a operação passará diretamente para a etapa de criação do kernel
- Os ambientes ou kernels conda criados usando esta operação estão disponíveis apenas para um usuário específico
- Execute manualmente o script python
kernel_install_script.pyno modo sudo:'/var/lib/ambari-server/resources/mpacks/odh-ambari-mpack-2.0.8/stacks/ODH/1.1.12/services/JUPYTER/package/scripts/'Por exemplo:
sudo python kernel_install_script.py --conda_env_name conda_jupy_env_1 --conda_additional_configs '--override-channels --no-default-packages --no-pin -c pytorch' --custom_requirements_txt_file_path ./req.txt --kernel_type spark --kernel_name spark_jupyterhub_1 --user jupyterhub
Pré-requisitos
- Verifique o acesso à Internet ao cluster para fazer download de dependências durante a criação do conda. Caso contrário, a criação falhará.
- Se existir um kernel com o nome
--kernel_name, uma exceção será gerada. - Forneça as seguintes informações:
- Configurações Conda para evitar falha na criação. Para obter mais informações, consulte https://conda.io/projects/conda/en/latest/commands/create.html.
- Dependências fornecidas no formato
.txtdos requisitos padrão.
- Exclua manualmente ambientes conda ou kernels para qualquer usuário.
Configurações Disponíveis para Personalização
-
--user(obrigatório): SO e usuário JupyterHub para quem o ambiente conda e kernel é criado. -
--conda_env_name(obrigatório): Forneça um nome exclusivo para o ambiente conda toda vez que uma nova en for criada para--user. -
--kernel_name: (obrigatório) Forneça um nome de kernel exclusivo. -
--kernel_type: (obrigatório) Deve ser um dos seguintes (python / PysPark / Spark / SparkR) -
--custom_requirements_txt_file_path: (opcional) Se qualquer Python/R/Ruby/Lua/Scala/Java/JavaScript/C/C++/FORTRAN e assim por diante, as dependências forem instaladas usando canais conda, você deverá especificar essas bibliotecas em um arquivo.txtde requisitos e fornecer o caminho completo.Para obter mais informações sobre um formato padrão para definir o arquivo
.txtde requisitos, consulte https://pip.pypa.io/en/stable/reference/requirements-file-format/. -
--conda_additional_configs: (opcional)- Este campo fornece parâmetros adicionais a serem anexados ao comando de criação de conda padrão.
- O comando de criação conda padrão é:
'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8'. - Se
--conda_additional_configsfor fornecido como'--override-channels --no-default-packages --no-pin -c pytorch', a execução do comando final de criação de conda será'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8 --override-channels --no-default-packages --no-pin -c pytorch'.
Configurando o Ambiente Conda Específico do Usuário
Criar um Balanceador de Carga e um Conjunto de Backend
Para obter mais informações sobre a criação de conjuntos de backend, consulte Criando um Conjunto de Backend do Balanceador de Carga.
Para obter mais informações sobre como criar um Balanceador de Carga público, consulte Criando um Balanceador de Carga e conclua os detalhes a seguir.
Para obter mais informações sobre como criar um Balanceador de Carga público, consulte Criando um Balanceador de Carga e conclua os detalhes a seguir.
- Abra o menu de navegação, selecione Rede e Balanceadores de carga. Selecione Balanceador de carga. A página Balanceadores de carga é exibida.
- Selecione o Compartimento na lista. Todos os balanceadores de carga desse compartimento são listados em formato tabular.
- Selecione o balanceador de carga ao qual deseja adicionar um back-end. A página de detalhes do balanceador de carga é exibida.
- Selecione Conjuntos de backend e, em seguida, selecione o conjunto de backend criado em Criando o Balanceador de Carga.
- Selecione endereços IP e, em seguida, informe o endereço IP privado necessário do cluster.
- Informe 8000 para a Porta.
- Selecione Adicionar.
Para obter mais informações sobre como criar um Balanceador de Carga público, consulte Criando um Balanceador de Carga e conclua os detalhes a seguir.
-
Abra um navegador e digite
https://<loadbalancer ip>:8000. - Selecione o Compartimento na lista. Todos os balanceadores de carga desse compartimento são listados em formato tabular.
- Certifique-se de que ele redirecione para um dos servidores JupyterHub. Para verificar, abra uma sessão de terminal em JupyterHub para localizar qual nó foi atingido.
- Após a operação de adição de nó, o administrador do cluster deve atualizar manualmente a entrada do host do Balanceador de Carga nos nós recém-adicionados. Aplicável a todas as adições de nó ao cluster. Por exemplo, nó de trabalho, somente computação e nós.
- O certificado deve ser atualizado manualmente para o Balanceador de Carga em caso de expiração. Esta etapa garante que o Balanceador de Carga não esteja usando certificados desatualizados e evita falhas de verificação/comunicação de integridade em conjuntos de backend. Para obter mais informações, consulte Atualizando um Certificado do Balanceador de Carga a Expirar para atualizar o certificado expirado.
Iniciar Kernels Trino-SQL
O kernel JupyterHub PyTrino fornece uma interface SQL que permite executar consultas Trino usando o SQL JupyterHub. Isso está disponível para clusters ODH 2.x do Big Data Service 3.0.28 ou posterior.
Para obter mais informações sobre parâmetros SqlMagic, consulte https://jupysql.ploomber.io/en/latest/api/configuration.html#changing-configuration.