Conceitos Básicos do Oracle Cloud Infrastructure Data Flow
Este tutorial apresenta o Oracle Cloud Infrastructure Data Flow, um serviço que permite executar qualquer Apache Aplicativo Spark em qualquer escala, sem infraestrutura para implantar ou gerenciar.
Se você já usou o Spark antes, vai aproveitar melhor este tutorial, mas nenhum conhecimento prévio do Spark é necessário. Todos os dados e aplicativos Spark foram fornecidos a você. Este tutorial mostra como o serviço Data Flow torna a execução de aplicativos Spark fácil, reproduzível, segura e simples de compartilhar na empresa.
- Como usar o Java para executar ETL em um Aplicativo Data Flow .
- Como usar o SparkSQL em um Aplicativo SQL.
- Como criar e executar um Aplicativo Python para executar uma tarefa simples de aprendizado de máquina.
Você também pode executar este tutorial usando o script spark-submit da CLI ou usando o script spark-submit e o Java SDK.
- Ele não tem servidor, o que significa que você não precisa de especialistas para provisionar, aplicar patch, fazer upgrade ou manter clusters Spark. Isso significa que você se concentra no código Spark e nada mais.
- Ele tem operações e ajustes simples. O acesso à interface do usuário do Spark é seletivo e é controlado pelas políticas de autorização do IAM. Se um usuário reclamar que um job está sendo executado muito devagar, qualquer pessoa com acesso ao comando Executar poderá abrir a interface do usuário do Spark e chegar à causa raiz. O acesso ao Spark History Server é igualmente simples para jobs que já foram concluídos.
- É ótimo para o processamento em lote. A saída do aplicativo é capturada automaticamente e disponibilizada pelas APIs REST. Você precisa executar um job Spark SQL de quatro horas e carregar os resultados no sistema de gerenciamento de pipeline? No serviço Data Flow, é apenas duas chamadas de API REST.
- Ele possui controle consolidado. O serviço Data Flow oferece uma view consolidada de todos os aplicativos Spark, quem os executa e quanto consomem. Deseja saber quais aplicativos estão gravando a maioria dos dados e quem os está executando? Basta classificar pela coluna Dados Gravados. Um job está sendo executado por muito tempo? Qualquer pessoa com as permissões corretas do IAM pode ver o job e interrompê-lo.

Antes de Começar
Para executar este tutorial com sucesso, é necessário ter Configurar Sua Tenancy e Acessar Fluxo de Dados.
Antes que o serviço Data Flow possa ser executado, você deve conceder permissões que permitam a captura de log efetiva e o gerenciamento de execução. Consulte a seção Set Up Administration do Data Flow Service Guide e siga as instruções fornecidas.
- Na Console, selecione o menu de navegação para exibir a lista de serviços disponíveis.
- Selecione Análise e IA.
- Em Big Data, selecione Data Flow.
- Selecione Aplicativos.
1. ETL com Java
Um exercício para aprender a criar um aplicativo Java no serviço Data Flow
As etapas aqui são para utilizar a IU da Console. Você pode concluir este exercício usando o script spark-submit da CLI ou o script spark-submit com Java SDK.
A primeira etapa mais comum em aplicativos de processamento de dados é obter dados de alguma origem e colocá-los em um formato adequado para relatórios e outras formas de análise. Em um banco de dados, você carregaria um arquivo simples no banco de dados e criaria índices. No Spark, sua primeira etapa é limpar e converter dados de um formato de texto no formato Parquet. Parquet é um formato binário otimizado que suporta leituras eficientes, tornando-o ideal para geração de relatórios e análises. Neste exercício, você pega dados de origem, converte-os em Parquet e depois faz algumas coisas interessantes com eles. O conjunto de dados é o Berlin Airbnb Data, baixado do site da Kaggle sob os termos da licença Creative Commons CC0 1.0 Universal (CC0 1.0) "Public Domain Dedication".

Os dados são fornecidos no formato CSV e a primeira etapa é converter esses dados em Parquet e armazená-los no armazenamento de objetos para processamento downstream. Um aplicativo Spark, chamado oow-lab-2019-java-etl-1.0-SNAPSHOT.jar, é fornecido para fazer essa conversão. O objetivo é criar um Aplicativo Data Flow que execute esse aplicativo Spark e execute-o com os parâmetros corretos. Porque você está começando, este exercício o guia passo a passo, e fornece os parâmetros que você precisa. Mais tarde, você mesmo precisará fornecer os parâmetros; portanto, deverá entender o que está digitando e por quê.
Crie um Aplicativo Java do serviço Data Flow na Console ou com o Spark-submit na linha de comando ou usando o SDK.
Crie um aplicativo Java no serviço Data Flow por meio da Console.
Criar um Aplicativo do Serviço Data Flow.
- Navegue até o serviço Data Flow na Console expandindo o menu de hambúrguer na parte superior esquerda e role até a parte inferior.
- Destaque Fluxo de Dados e selecione Aplicativos. Selecione um compartimento no qual você deseja que os aplicativos do serviço Data Flow sejam criados. Por fim, selecione Criar Aplicativo.
- Selecione Aplicativo Java e informe um nome para o Aplicativo, por exemplo,
Tutorial Example 1.
- Role para baixo até Configuração do Recurso. Deixe todos esses valores com seus respectivos padrões.
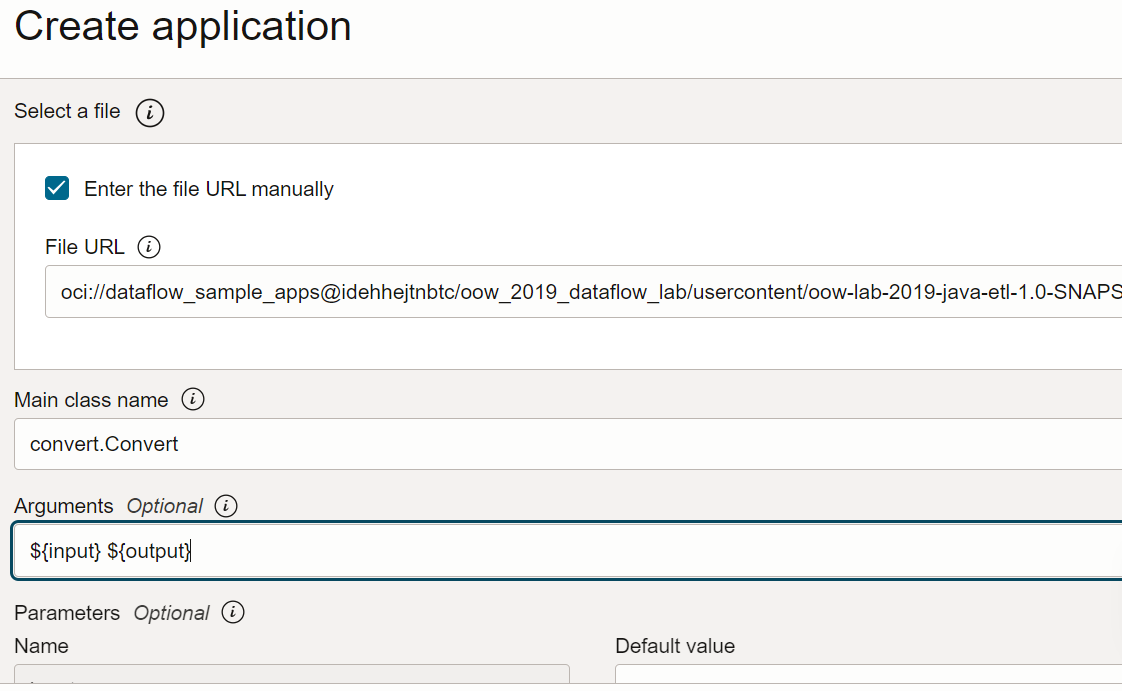
- Role para baixo até Configuração do Aplicativo. Configure o aplicativo da seguinte maneira:
-
URL do Arquivo: é o local do arquivo JAR no armazenamento de objetos. O local deste aplicativo é:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar -
Nome da Classe Principal: Os aplicativos Java precisam de um Nome de Classe Principal, que depende do aplicativo. Para este exercício, informe
convert.Convert -
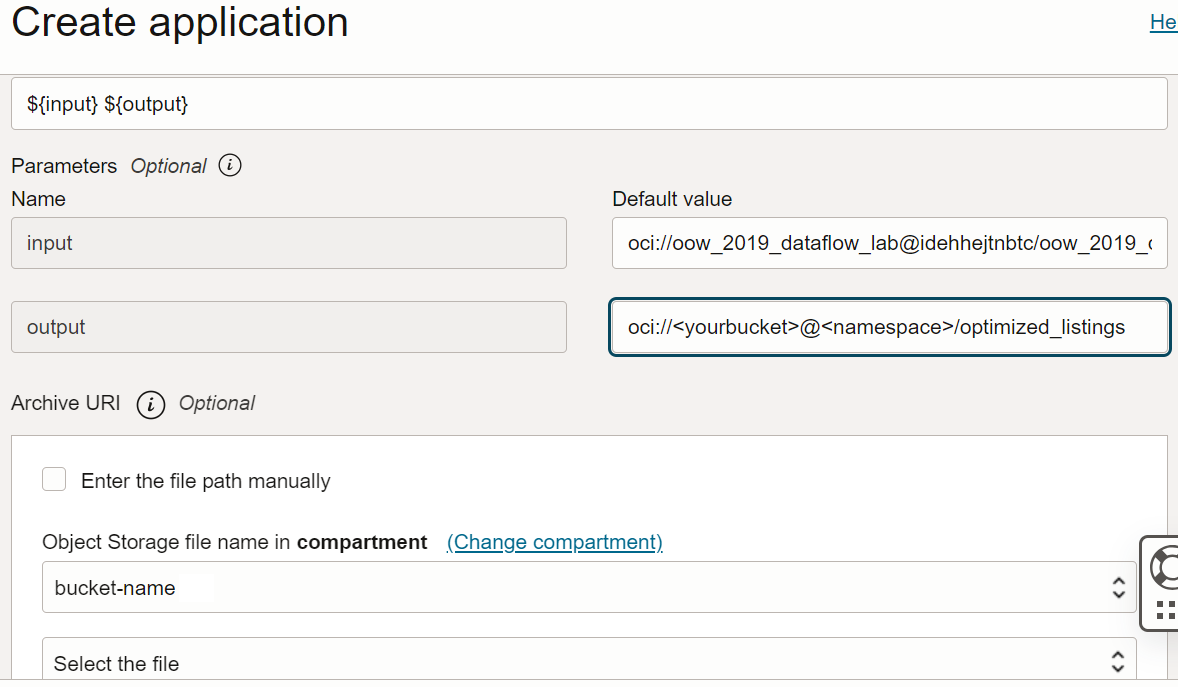
Argumentos: O aplicativo Spark espera dois parâmetros de linha de comando, um para entrada e outro para saída. No campo Argumentos, digite. Você será solicitado a informar valores padrão, e é uma boa ideia inseri-los agora.
${input} ${output}
-
URL do Arquivo: é o local do arquivo JAR no armazenamento de objetos. O local deste aplicativo é:
- Os argumentos de entrada e saída são:
-
Entrada:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv -
Saída:
oci://<yourbucket>@<namespace>/optimized_listings
Verifique novamente a configuração do Aplicativo para confirmar se ela é semelhante à seguinte:
 Observação
Observação
Personalize o caminho de saída para apontar para um bucket no tenant. -
Entrada:
- Quando terminar, selecione Criar. Quando o Aplicativo for criado, você o verá na lista Aplicativo.
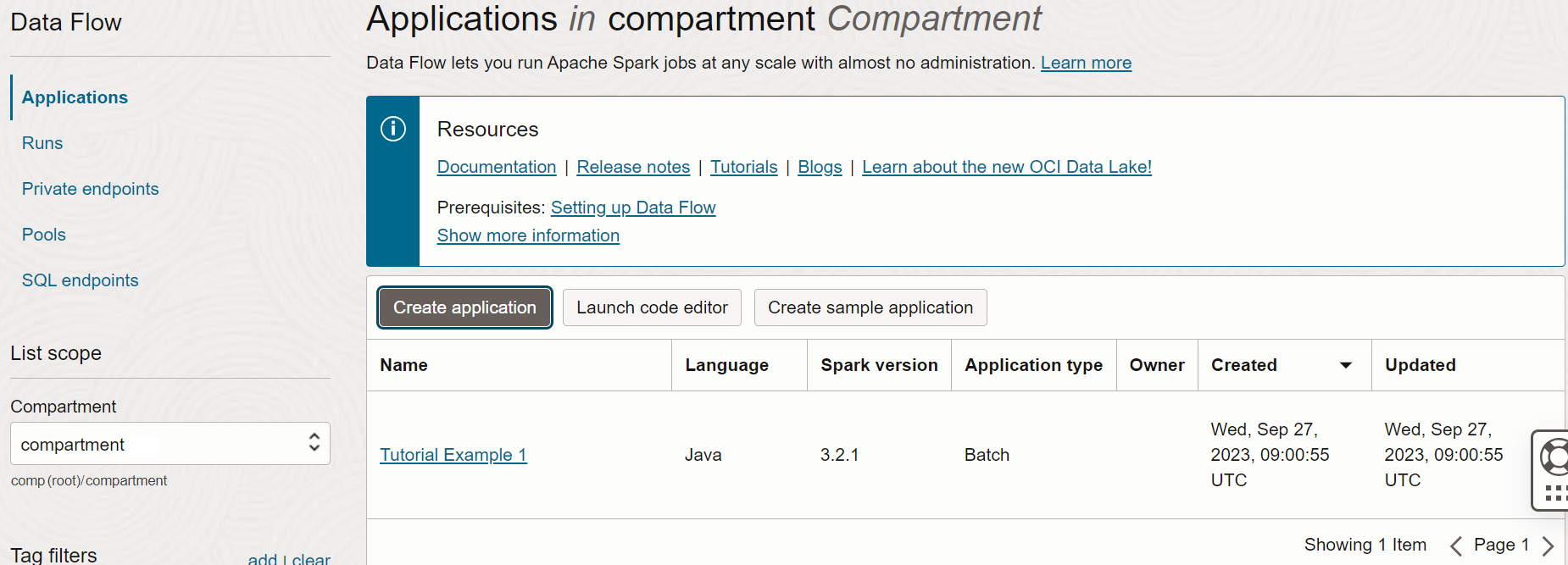
Parabéns! Você criou seu primeiro Aplicativo Data Flow. Agora você pode executá-lo.
Use o script spark-submit e a CLI para criar um Aplicativo Java.
Conclua o exercício para criar um aplicativo Java no serviço Data Flow usando o script spark-submit e o Java SDK.
Estes são os arquivos para executar este exercício e estão disponíveis nos seguintes URIs públicos do serviço Object Storage:
- Arquivos de entrada no formato CSV:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - Arquivo Jar:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Após a criação de um aplicativo Java, você pode executá-lo.
- Se você seguiu as etapas com precisão, tudo o que precisa fazer é destacar seu Aplicativo na lista, selecionar o menu Ações e selecionar Executar.
- Você pode personalizar os parâmetros antes de executar o Aplicativo. No seu caso, você digita os valores exatos previamente e pode começar a executar, clicando em Executar.
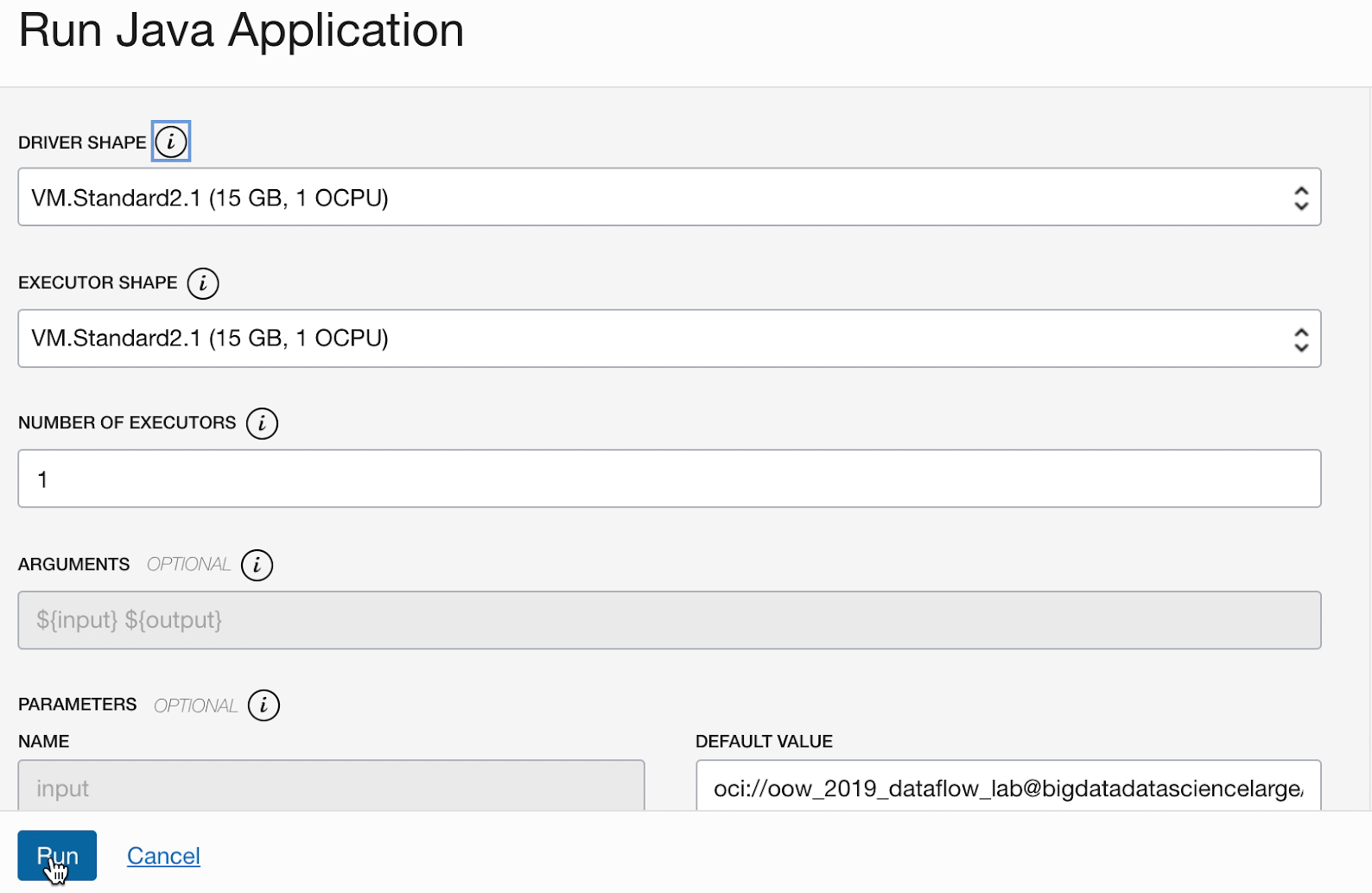
-
Enquanto o Aplicativo está sendo executado, você pode opcionalmente carregar a interface do usuário do Spark para monitorar o andamento. No menu Ações para a execução em questão, selecione UI do Spark.
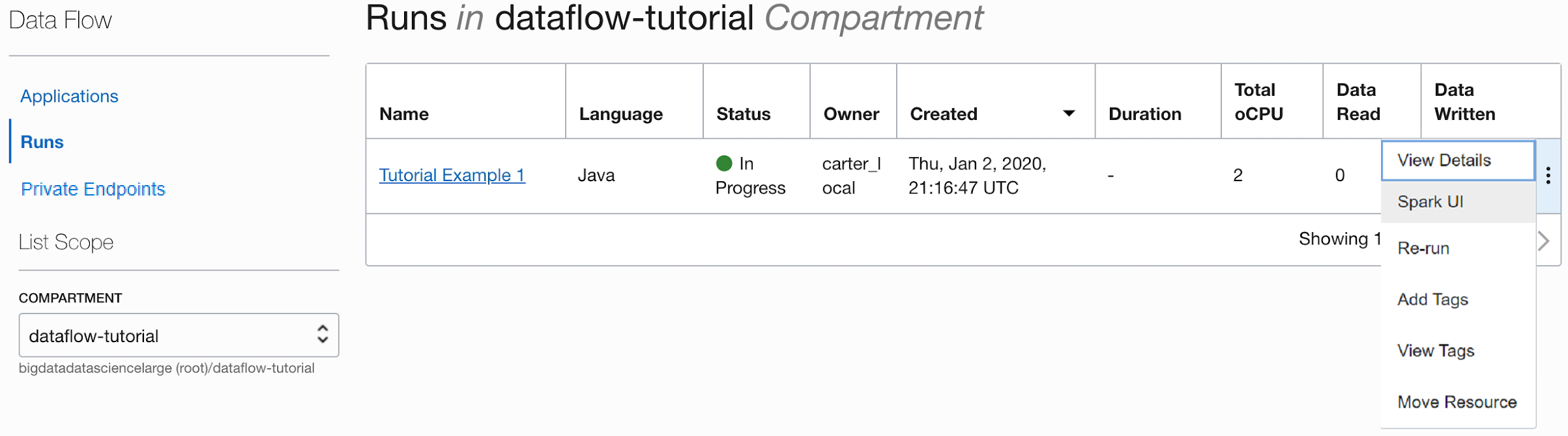
- Você é automaticamente redirecionado para a interface do usuário do Apache Spark, que é útil para depuração e ajuste de desempenho.

-
Depois de cerca de um minuto, sua Execução mostra a conclusão bem-sucedida com o Estado
Succeeded:
-
Faça drill na Execução para ver detalhes adicionais e role até a parte inferior para ver uma listagem de logs.

-
Ao selecionar o arquivo spark_application_stdout.log.gz, você vê a saída de log,
Conversion was successful:
- Você também pode navegar até seu bucket de armazenamento de objetos de saída para confirmar que novos arquivos foram criados.
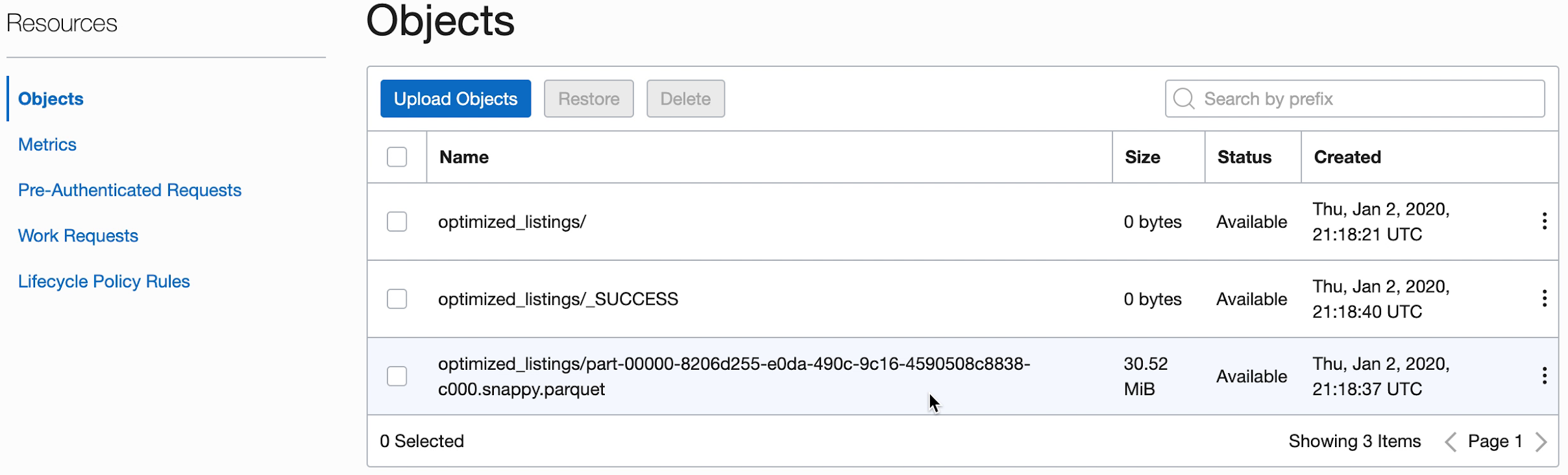
Esses novos arquivos são usados pelos aplicativos posteriores. Certifique-se de vê-los em seu bucket antes de passar para os próximos exercícios.
2. SparkSQL Simplificado
Neste exercício, você executa um script SQL para definir o perfil básico de um conjunto de dados.
Este exercício usa a saída que você gerou em 1. ETL com Java. Você deve tê-lo concluído com sucesso antes de tentar este.
As etapas aqui são para utilizar a IU da Console. Você pode concluir este exercício usando o script spark-submit da CLI ou o script spark-submit com Java SDK.
Assim como em outros aplicativos do serviço Data Flow, os arquivos SQL são armazenados no armazenamento de objetos e podem ser compartilhados entre muitos usuários SQL. Para ajudar nisso, o Data Flow permite parametrizar scripts SQL e personalizá-los no runtime. Assim como em outros aplicativos, você pode fornecer valores padrão para parâmetros que geralmente servem como dicas valiosas para as pessoas que executam esses scripts.
O script SQL está disponível para uso diretamente no Aplicativo do serviço Data Flow; não é necessário criar uma cópia dele. O script é reproduzido aqui para ilustrar alguns pontos.
Texto de referência do Script SparkSQL:
- O script começa criando as tabelas SQL necessárias. Atualmente, o serviço Data Flow não possui um catálogo SQL persistente, portanto, todos os scripts devem começar definindo as tabelas necessárias.
- O local da tabela é definido como
${location}. Este é um parâmetro que o usuário precisa fornecer no runtime. Isso dá ao serviço Data Flow a flexibilidade de usar um script para processar vários locais diferentes e compartilhar o código entre diferentes usuários. Para este laboratório, devemos personalizar${location}para apontar para o local de saída que usamos no Exercício 1 - Como veremos, a saída do script SQL é capturada e disponibilizada para nós na Execução.
- No serviço Data Flow, crie um Aplicativo SQL, selecione SQL como tipo e aceite os recursos padrão.
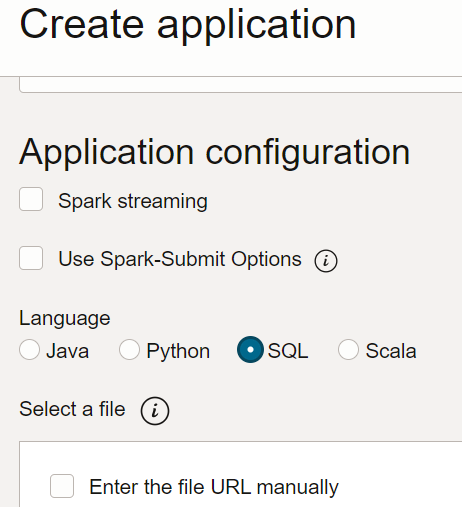
- Em Configuração do Aplicativo, configure o Aplicativo SQL da seguinte forma:
-
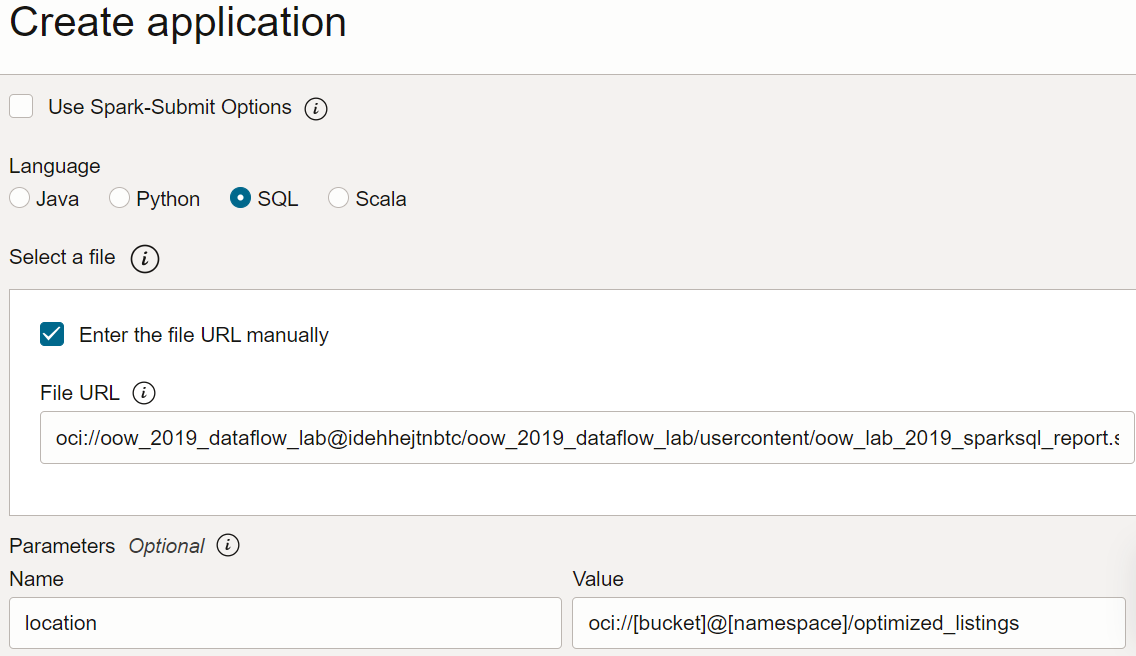
URL do Arquivo: é o local do arquivo SQL no armazenamento de objetos. O local deste aplicativo é:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql -
Argumentos: O script SQL espera um parâmetro, o local de saída da etapa anterior. Selecione Adicionar Parâmetro e digite um parâmetro chamado
locationcom o valor que você usou como caminho de saída na etapa a, com base no modelooci://[bucket]@[namespace]/optimized_listings
Quando terminar, certifique-se de que a configuração do Aplicativo seja semelhante à seguinte:
-
URL do Arquivo: é o local do arquivo SQL no armazenamento de objetos. O local deste aplicativo é:
- Personalize o valor do local com um caminho válido em sua tenancy.
- Salve o Aplicativo e execute-o na lista Aplicativos.
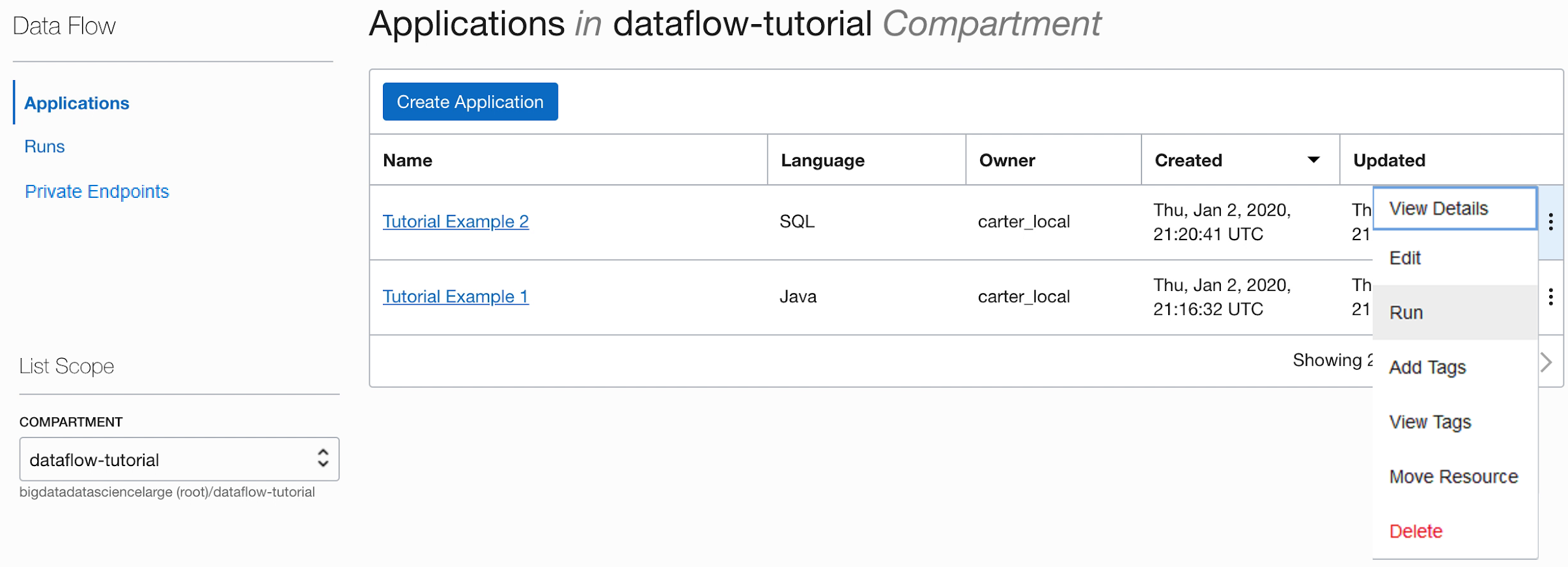
- Após a conclusão da Execução, abra-a:
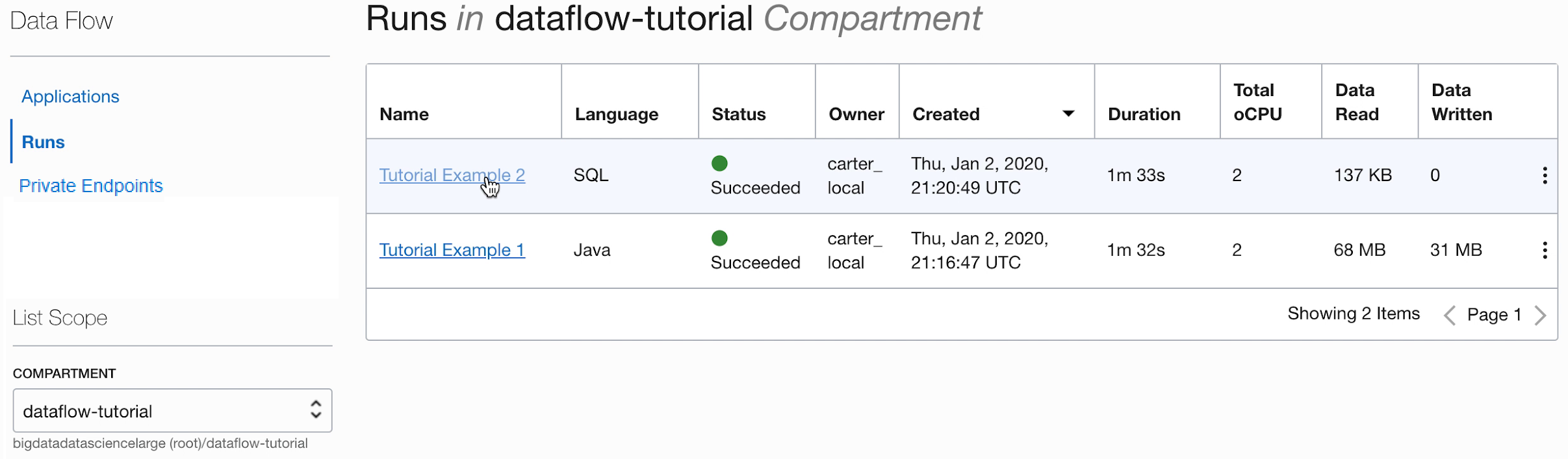
- Navegue até os logs da execução:

- Abra spark_application_stdout.log.gz e confirme se a saída concorda com a saída abaixo. Observação
Suas linhas podem estar em uma ordem diferente da imagem, mas os valores devem coincidir.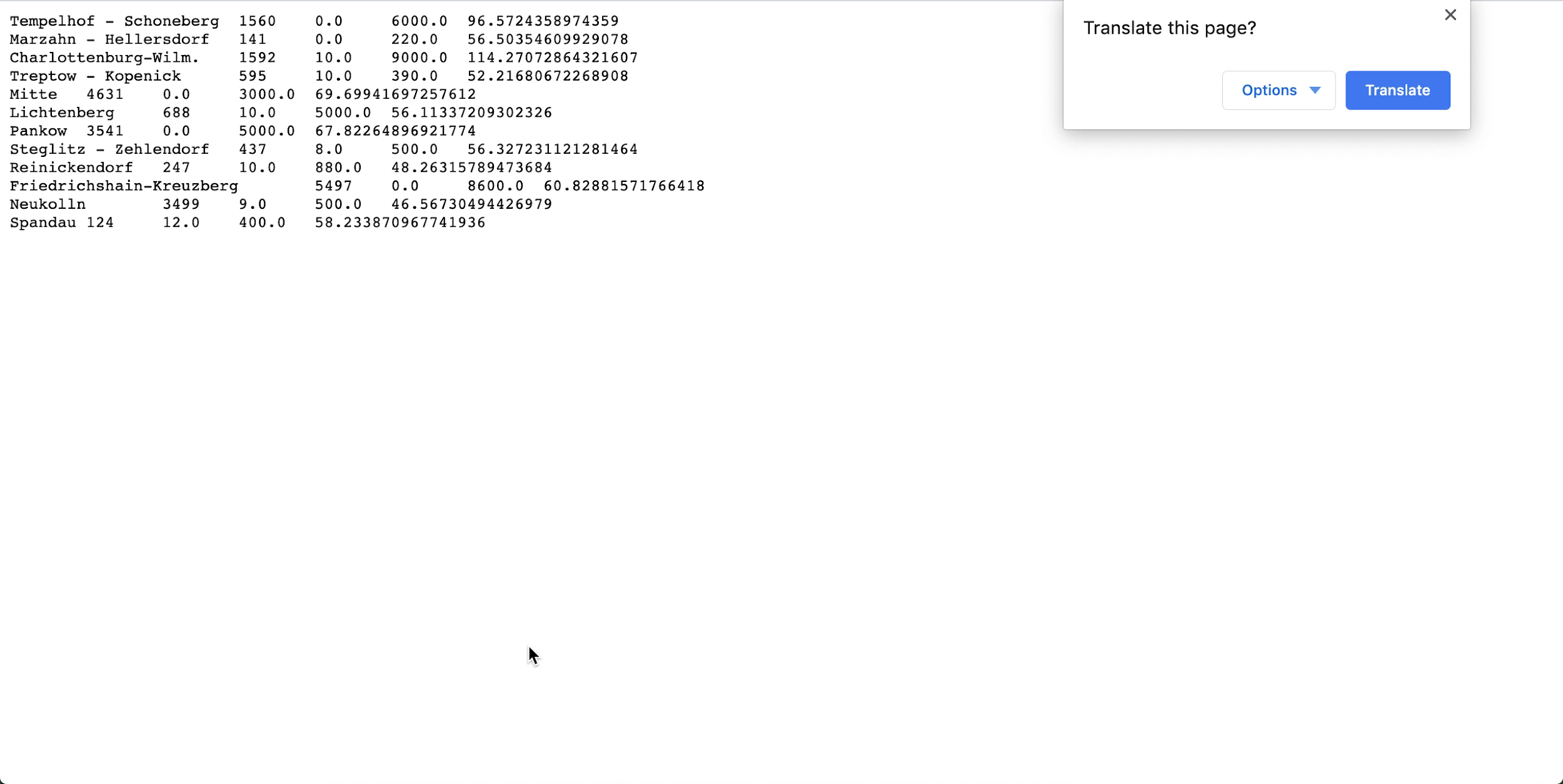
- Com base na definição do perfil SQL você pode concluir, neste conjunto de dados, Neukolln tem o menor preço médio de listagem em $ 46,57, enquanto Charlottenburg-Wilmersdorf tem a média mais alta em $ 114,27 (Observação: o conjunto de dados de origem tem preços em USD, em vez de EUR.)
Este exercício mostrou alguns aspectos importantes do serviço Data Flow. Quando um aplicativo SQL está instalado, qualquer pessoa pode executá-lo facilmente sem se preocupar com a capacidade do cluster, acesso e retenção de dados, gerenciamento de credenciais ou outras considerações de segurança. Por exemplo, um analista de negócios pode facilmente usar relatórios baseados no Spark com o serviço Data Flow.
3. Aprendizado de Máquina com o PySpark
Use o PySpark para executar uma tarefa simples de aprendizado de máquina sobre os dados de entrada.
Este exercício usa a saída de 1. ETL com Java como seus dados de entrada. Você deve ter concluído com sucesso o primeiro exercício antes de tentar este. Desta vez, seu objetivo é identificar as melhores ofertas entre as várias listagens do Airbnb usando algoritmos de aprendizado de máquina do Spark.
As etapas aqui são para utilizar a IU da Console. Você pode concluir este exercício usando o script spark-submit da CLI ou o script spark-submit com Java SDK.
Um aplicativo PySpark está disponível para você usar diretamente em seus Aplicativos Data Flow. Você não precisa criar uma cópia.
O texto de referência do script PySpark é fornecido aqui para ilustrar alguns pontos: 
- O script Python espera um argumento de linha de comando (destacado de vermelho). Quando você cria o Aplicativo Data Flow, precisa criar um parâmetro com o qual o usuário define como caminho de entrada.
- O script usa a regressão linear para prever um preço por listagem e encontra as melhores ofertas, subtraindo o preço da lista da previsão. O valor mais negativo indica o melhor valor, de acordo com o modelo.
- O modelo neste script é simplificado e só considera a metragem quadrada. Em um cenário real, você usaria mais variáveis, como o bairro e outras variáveis de previsão importantes.
Crie um Aplicativo PySpark na Console ou com o script Spark-submit na linha de comando ou usando o SDK.
Crie um aplicativo PySpark no serviço Data Flow usando a Console.
-
Crie um Aplicativo e selecione o tipo Python.

-
Verifique novamente a configuração do Aplicativo e confirme que ela é semelhante à seguinte:
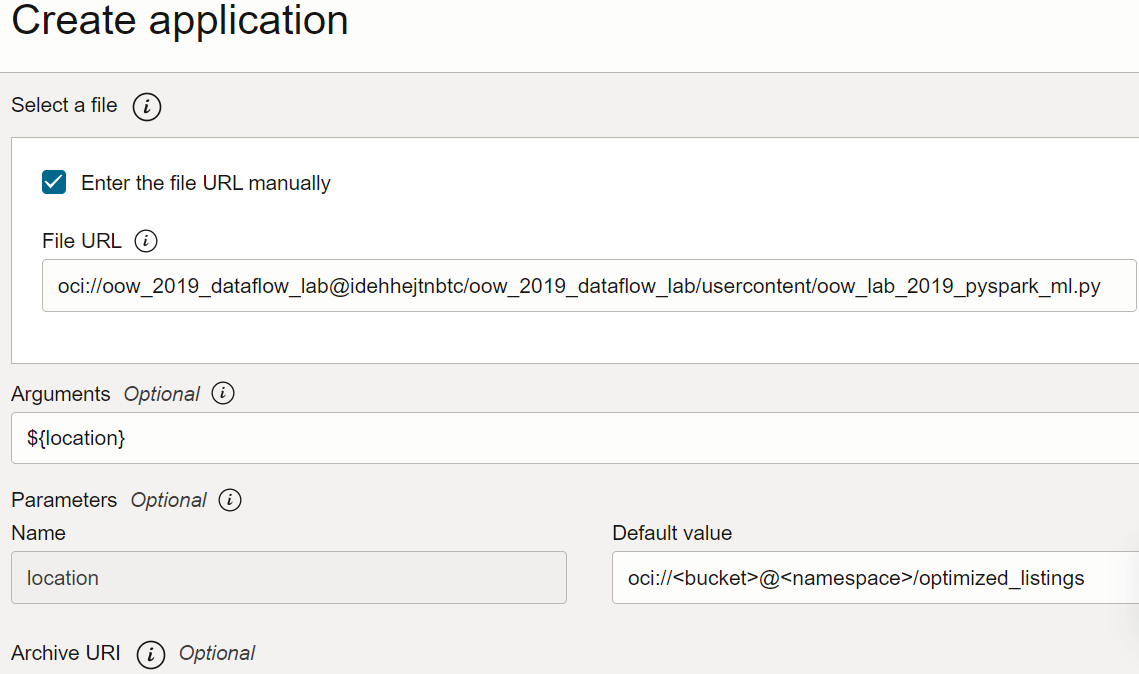
Crie um aplicativo PySpark no serviço Data Flow usando o script Spark-submit e a CLI.
Crie um aplicativo PySpark no serviço Data Flow usando o script Spark-submit e o SDK.
- Execute o Aplicativo na lista Aplicativo.
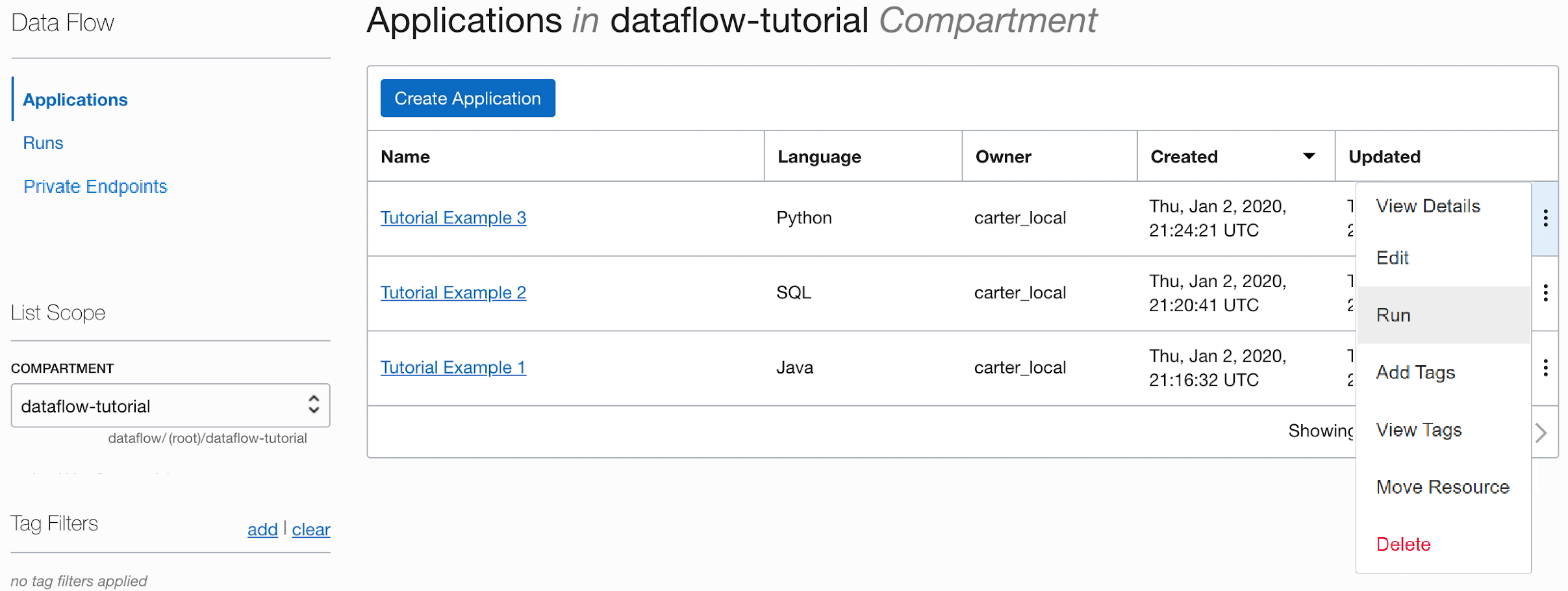
-
Quando a opção Executar for concluída, abra-a e navegue até os logs.

- Abra o arquivo spark_application_stdout.log.gz. Sua saída deve ser idêntica à seguinte:

-
Nessa saída, você vê que o ID 690578 da listagem é a melhor oferta, com um preço previsto de $ 313,70, em comparação com o preço de lista de $ 35,00 com a metragem quadrada listada de 4639 pés quadrados. Se parecer bom demais para ser verdade, o ID exclusivo significa que você pode fazer drill nos dados para entender melhor se esse é realmente o negócio do século. Novamente, um analista de negócios pode consumir facilmente a saída desse algoritmo de aprendizado de máquina para aprofundar a análise.
O Que Vem a Seguir
Agora você pode criar e executar aplicativos Java, Python ou SQL com o Data Flow, e explorar os resultados.
O serviço Data Flow trata de todos os detalhes de implantação, shutdown, gerenciamento de logs, segurança e acesso à interface do usuário. Com o serviço Data Flow, você se concentra no desenvolvimento de aplicativos Spark sem se preocupar com a infraestrutura.