Diretrizes de Armazenamento de Objetos da Ferramenta RAG para Agentes de IA Generativa
Revise as seções a seguir para preparar dados do Object Storage para ferramentas RAG em Generative AI Agents.
Diretrizes Gerais
Siga estas diretrizes para preparar dados para origens de dados do Generative AI Agents antes de fazer upload para o Object Storage:
- Origens de Dados: Os dados para Agentes de IA Generativa devem ser submetidos a upload como arquivos para um bucket do Object Storage.
- Número de Buckets: Somente um bucket é permitido por origem de dados.
- Tipos de Arquivo Suportados: Arquivos
PDF,txt,JSON,HTMLe de Markdown (MD) são suportados. - Limite de Tamanho do Arquivo: Cada arquivo deve ter no máximo 100 MB. Todos os arquivos que excederem o limite serão ignorados. Para outros requisitos, consulte File Type Requirements and Support.
- URLs: Todos os hiperlinks presentes nos documentos são extraídos e exibidos como hiperlinks na resposta de chat.
- Dados Não Prontos: Se seus dados ainda não estiverem disponíveis, crie uma pasta vazia para a origem de dados e preencha-a posteriormente. Dessa forma, você pode ingerir dados na origem depois que a pasta for preenchida.
Configure as permissões do Object Storage a seguir antes de continuar.
- Acesso do usuário aos arquivos do Object Storage
- Acesso do job de ingestão de dados aos arquivos do Object Storage para jobs de longa execução
Consulte Obtendo Acesso para obter as permissões.
Requisitos e Suporte de Tipo de Arquivo
Os arquivos de origem de dados devem ser submetidos a upload para o Object Storage. Certifique-se de que os requisitos sejam atendidos para o tipo de arquivo a ser ingerido.
Os requisitos e o suporte para ingestão de arquivos PDF são os seguintes:
- Extensão de arquivo: Deve ser
.pdf - Tamanho do arquivo: Um único arquivo não deve exceder 100 MB.
- Senha do arquivo: Se um arquivo PDF for protegido por senha, uma falha no arquivo será registrada nos logs de status.
- Conteúdo: Um arquivo PDF pode incluir imagens, gráficos e tabelas de referência, mas não deve exceder 8 MB.
- Preparação de gráfico: nenhuma preparação especial é necessária para gráficos, desde que sejam bidimensionais com eixos rotulados. O modelo pode responder a perguntas sobre os gráficos sem explicações explícitas.
- Preparação de tabela: Use tabelas de referência com várias linhas e colunas. Por exemplo, o agente pode ler a tabela na página limites.
texto
Os requisitos e o suporte para ingestão de arquivos txt são os seguintes:
- Extensão de arquivo: Deve ser
.txt - Tamanho do arquivo: Um único arquivo não deve exceder 100 MB.
JSON
Os requisitos e o suporte para ingestão de arquivos JSON são os seguintes:
- Extensão de arquivo: Deve ser
.json - Tamanho do arquivo: Um único arquivo não deve exceder 100 MB.
- Codificação: Somente a codificação UTF-8 em inglês é suportada. Os dados estruturados JSON podem conter pares de chave/valor, matrizes e objetos aninhados.
- Profundidade do aninhamento: A profundidade da estrutura não deve exceder 50.
- Limite de lista: Uma lista dentro da estrutura JSON não deve ter mais de 10000 itens.
HTML
Os requisitos e o suporte para ingestão de arquivos HTML são os seguintes:
- Extensão de arquivo: Deve ser
.html - Tamanho do arquivo: Um único arquivo não deve exceder 100 MB.
- Conteúdo: Somente o conteúdo visível é ingerido. Qualquer conteúdo dinâmico não é ingerido e as tags de script são removidas.
- Imagens: As imagens que são referenciadas em um arquivo poderão ser processadas se a origem da imagem não for um
HTTPexterno ou um caminho absoluto. Todas as imagens que não atenderem aos requisitos a seguir serão ignoradas.- Somente imagens
JPEG(.jpgou.jpeg) são suportadas. - Uma única imagem não deve exceder 6 MB. Todas as imagens que excedam o limite são ignoradas.
- As imagens devem ser carregadas no Object Storage no mesmo nível do arquivo HTML carregado ou abaixo dele.
- O caminho de origem (atributo
src) para cada imagem deve ser um caminho relativo ao arquivo HTML pai. Por exemplo:<img src="./my-image.jpg"> <img src="./myfolder/my-imagetwo.jpg"> - O caminho de origem (atributo
src) para cada imagem não deve especificar URLs (http,httpsoudata)
- Somente imagens
MD (Markdown)
Os requisitos e o suporte para ingestão de arquivos MD (Markdown) são os seguintes:
- Extensão de arquivo: Deve ser
.md - Tamanho do arquivo: Um único arquivo não deve exceder 100 MB.
- Imagens: As imagens são ignoradas e não processadas.
Garantindo uma melhor compreensão da tabela
A compreensão aprimorada da tabela, um recurso das ferramentas RAG, visa melhorar a precisão das respostas às consultas com respostas incorporadas nos dados da tabela PDF. Ele processa essas tabelas para gerar respostas mais precisas e relevantes alinhadas com as informações que elas contêm. Em geral, as ferramentas RAG podem ler as tabelas. Para que a ferramenta RAG leia as tabelas com melhor compreensão de tabelas, certifique-se de que elas tenham os seguintes recursos:
- Todas as células da tabela são separadas por linhas visíveis ou limites de objetos de outras células, incluindo os nomes de cabeçalho na primeira linha.
- Todas as colunas, incluindo a primeira coluna, têm um nome de cabeçalho.
- Cada tabela tem mais de uma coluna e mais de uma linha, excluindo a linha com nomes de cabeçalho.
Count of tables that support enhanced table understanding in following PDFs:
- enhanced_table_test_data/2025_Report1.pdf has 4 tables processed successfully
- enhanced_table_test_data/2025_Report2.pdf has 3 tables processed successfully
- enhanced_table_test_data/2025_Report3.pdf has 3 tables processed successfully
Aprimorando Respostas com Filtragem de Metadados
Use metadados predefinidos para aplicar filtros durante um chat. Quando os filtros são aplicados, as pesquisas de um agente em uma sessão de chat são limitadas a arquivos de dados associados aos metadados, ajudando o modelo a gerar respostas relevantes ao escopo do conteúdo, aumentando assim a precisão e a relevância da resposta do agente.
As etapas a seguir descrevem uma visão geral de como usar o recurso de filtragem de metadados. Depois de entender a visão geral do workflow, revise os detalhes do seu caso de uso nas seções fornecidas após as etapas de visão geral.
- Em um editor de texto, crie o esquema de metadados, que é necessário para os filtros que você deseja disponibilizar. Grave o esquema no formato JSON. Nomeie o arquivo como
_metadata_schema.json.Exemplo:
{ "metadataSchema": [ { "name": "publication_year", "type": "integer" }, { "name": "title", "type": "string" } ] } - Faça upload do arquivo
_metadata_schema.jsoncriado na etapa 1 para o nível raiz do bucket do Object Storage que contém os arquivos de dados de uma base de conhecimento. - Crie arquivos JSON para associar arquivos de dados aos metadados predefinidos e fornecer os valores de metadados.
Exemplo:
{ "metadataAttributes": { "publication_year": 2020 } }Você pode associar um ou mais arquivos de dados ou todos os arquivos de um bucket aos metadados. Para obter detalhes sobre as convenções de nome de arquivo JSON a serem usadas para as opções escolhidas, consulte Opções de Filtro de Metadados (Nome e Local do Arquivo).
- Faça upload dos arquivos JSON criados na etapa 3 para o bucket do Object Storage que contém os arquivos de dados de uma base de conhecimento. Para cada opção, certifique-se de salvar o arquivo no local correto na hierarquia.
- Criar uma base de conhecimento. Selecione Object Storage como o tipo de armazenamento de dados e a opção para iniciar automaticamente o job de ingestão.
Quando os arquivos de dados são ingeridos, os Agentes de IA Generativa criam uma lista dos nomes de metadados e dos valores que podem ser selecionados em um chat. Para exibir os nomes e valores de metadados ingeridos, consulte Obtendo Detalhes de uma Base de Conhecimento em Agentes de IA Generativa.
- Crie um agente com uma ferramenta RAG, selecionando a base de conhecimento criada na etapa 5. No agente, selecione a opção para criar automaticamente um ponto final. Se precisar de ajuda, consulte Criando um Agente e Criando uma ferramenta RAG.
- Em uma janela de chat, adicione um ou mais filtros de metadados predefinidos e selecione os valores a serem aplicados. Consulte Usar Filtros de Metadados em um Chat.
Analise as seções a seguir para saber mais sobre como preparar arquivos JSON de metadados para seu caso de uso e como adicionar e aplicar filtros de metadados em uma sessão de chat.
Selecione um ou mais dos seguintes métodos que funcionem melhor para você.
| Método | Nome e Localização do Arquivo | Uso |
|---|---|---|
| Inclua metadados para todos os arquivos em um bucket sem mencionar os nomes dos arquivos. | Crie um arquivo _common.metadata.json no nível raiz do Object Storage. |
Use esse arquivo para metadados comuns a todos os arquivos do bucket. Esse método ajuda a evitar a inserção de duplicatas de metadados entre objetos. |
| Em um arquivo, crie uma entrada de metadados para cada arquivo em um bucket e inclua os nomes dos arquivos. | Crie um arquivo _all.metadata.json no nível raiz do Object Storage. |
Use este método se você tiver muitos arquivos e criar um arquivo que inclua todos os nomes de arquivo é mais conveniente para você do que criar um arquivo de metadados por arquivo. |
| Crie um arquivo de metadados para cada arquivo em um bucket. | Crie um arquivo <file-name>.metadata.json para cada arquivo, no nível do arquivo.
|
Use esse método quando os metadados forem diferentes para cada arquivo e não houver muitos arquivos para criar um arquivo de metadados ou se você estiver automatizando a criação dos arquivos de metadados. |
| Adicione cabeçalhos de metadados do Object Storage a cada arquivo. | Adicione o cabeçalho de metadados por meio da propriedade de metadados do Object Storage de cada arquivo. | Use este método, se você tiver poucas propriedades de metadados a serem incluídas. Recomendamos que você use os outros métodos com arquivos JSON, porque os arquivos são mais fáceis de atualizar e gerenciar e os cabeçalhos de metadados são difíceis de atualizar. |
Para todos os métodos, você deve definir um arquivo de esquema de metadados chamado _metadata_schema.json no nível raiz do bucket do Object Storage.
Aqui está um exemplo de hierarquia de onde você salva os arquivos de metadados necessários.
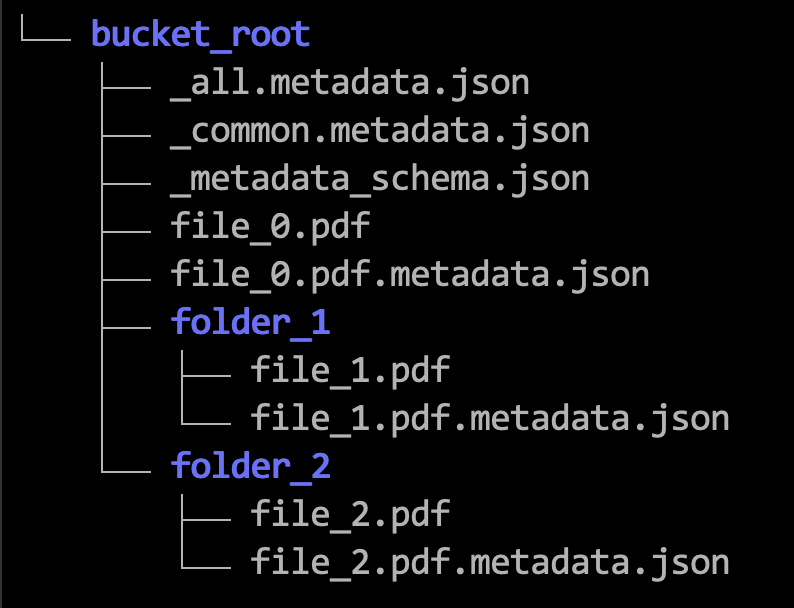
As etapas a seguir usam exemplos para mostrar como formatar os arquivos JSON de metadados. Consulte também Limites para Filtragem de Metadados.
Não é possível alterar ou remover os campos de metadados após a ingestão dos dados da base de conhecimento. Você pode adicionar novos campos ao limite permitido. Para remover ou atualizar um campo, recrie a base de conhecimento.
O procedimento a seguir pressupõe que você tenha criado o esquema de metadados necessário e os arquivos JSON de filtro de metadados opcionais, uma base de conhecimento e um agente com uma ferramenta RAG e um ponto final.
| Descrição: | Limite |
|---|---|
Número máximo de entradas em _all.metadata.json |
10,000 |
| Número máximo de campos de metadados que podem ser especificados para cada arquivo | 20 |
Número máximo de itens em um list_of_string type |
10 |
Tamanho máximo de item individual em um tipo list_of_string |
50 |
| Tamanho máximo de uma chave de metadados em caracteres | 25 |
| Tamanho máximo do valor de metadados em caracteres | 50 |
Adicionando Metadados a um Cabeçalho de Metadados do Serviço Object Storage
Adicionando Dados com URL Personalizado a um Bucket do Object Storage
Clientes beta:
Se você criou uma base de conhecimento na fase Beta, talvez seja necessário excluir e recriar a origem de dados para que o recurso de tratamento de URL funcione.
Atribuindo um URL Personalizado a uma Citação
metadata desse arquivo.Este tópico mostra como adicionar ou atualizar o objeto metadata por meio da CLI do OCI.
- O objeto
metadataque substitui a citação padrão deve ter o nomecustomized_url_source. - Você pode ter um objeto
metadatacom o nome,customized_url_source - Cada
customized_url_sourcepode ter apenas um URL. - Os comandos na etapa 5 funcionam tanto para adicionar quanto para atualizar o objeto
metadata, porque substituem o valor do objetometadataatual. - Certifique-se de informar os valores do objeto
--metadatacom o formato mostrado nos comandos na etapa 5.