Usar Links de Nuvem para Acesso a Dados Somente para Leitura no Autonomous AI Database
Os Cloud Links fornecem um método baseado na nuvem para acessar remotamente dados somente leitura em uma instância do Autonomous AI Database.
Sobre Links da Nuvem no Autonomous AI Database
Com o Cloud Links, um proprietário de dados registra uma tabela ou view para acesso remoto para um público selecionado, conforme definido pelo proprietário dos dados, e os dados ficam acessíveis àqueles com acesso concedido no momento do registro. Nenhuma outra ação é necessária para configurar os Cloud Links e quem deve ver e acessar seus dados pode descobrir e trabalhar com os dados.
A implementação do Cloud Links utiliza os mecanismos de acesso do Oracle Cloud Infrastructure para tornar os dados acessíveis dentro de um escopo específico. O escopo indica quem pode acessar remotamente os dados. O escopo pode ser definido para vários níveis, inclusive para a região onde o banco de dados reside, para tenancies individuais ou para compartimentos. Além disso, você pode especificar que a autorização para acessar um conjunto de dados seja limitada a uma ou mais instâncias do Autonomous AI Database.
Ao criar um ou mais clones atualizáveis entre regiões da instância do Autonomous AI Database de origem (proprietário do conjunto de dados), você pode usar os Links da Nuvem para compartilhar dados entre várias regiões.
Os Cloud Links simplificam muito o compartilhamento de tabelas ou views entre instâncias do Autonomous AI Database, em comparação com os mecanismos tradicionais de vinculação de banco de dados. Com os Cloud Links, você pode descobrir dados sem exigir uma configuração de link de banco de dados complexa. O Autonomous AI Database fornece acesso transparente usando SQL e implementa a aplicação de privilégios com o escopo Cloud Links e concedendo autorização a instâncias individuais do Autonomous AI Database.
Cloud Links apresentam os conceitos de namespaces regionais e nomes para dados que são tornados remotamente acessíveis. Isso é semelhante às tabelas Oracle existentes nas quais há uma tabela, por exemplo, "EMP" que reside em um namespace (esquema), por exemplo, "LWARD". Só pode haver um LWARD.EMP no seu banco de dados. Os Cloud Links fornecem um namespace e um nome semelhantes em um nível regional, que não estão vinculados a um único banco de dados, mas se aplicam a muitas instâncias do Autonomous AI Database, conforme especificado com o escopo e, opcionalmente, com a autorização do banco de dados.
Por exemplo, você pode registrar um conjunto de dados no namespace FOREST e, para fins de segurança ou para fins de nomeação, pode fornecer um namespace e um nome diferente do esquema original e dos nomes de objetos. Neste exemplo, TREE_DATA é o nome visível do conjunto de dados registrado e não é necessário que esse nome seja o nome da tabela de origem. Além do namespace e do nome, a palavra-chave cloud$link indica ao banco de dados que ele deve resolver a origem como um Link de Nuvem.
Para acessar um conjunto de dados registrado, inclua o namespace, o nome e a palavra-chave cloud$link na cláusula FROM de uma instrução SELECT:
SELECT county, species, height FROM FOREST.TREE_DATA@cloud$link;Opcionalmente, você pode especificar que o acesso a um conjunto de dados de um ou mais bancos de dados seja descarregado para um clone atualizável. Quando um Autonomous AI Database do consumidor é listado na lista de offload de um conjunto de dados, o acesso ao conjunto de dados é direcionado ao clone atualizável. Além disso, você pode usar o recurso de descarregamento de consulta unificada em que configura um líder de pool elástico ou membro como um provedor de links de nuvem e permite que o descarregamento de consulta ProxySQL descarregue consultas (leituras) para qualquer número de clones atualizáveis.
Observação
Observação: Os Vínculos de Nuvem fornecem acesso somente leitura a objetos remotos em uma instância do Autonomous AI Database. Se quiser usar links de banco de dados com outros bancos de dados Oracle ou com bancos de dados não Oracle ou se quiser usar seus dados remotos com operações DML, use links de banco de dados. Consulte Usar Links de Banco de Dados com o Autonomous AI Database para obter mais informações.
Os Cloud Links suportam sinônimos privados e públicos. Por exemplo, você pode definir e usar um sinônimo para FOREST.TREE_DATA@cloud$link:
CREATE SYNONYM S1 for FOREST.TREE_DATA@cloud$link;
SELECT county, species, height FROM S1;
CREATE PUBLIC SYNONYM S2 for FOREST.TREE_DATA@cloud$link;
SELECT * FROM S2;Consulte Visão Geral de Sinônimos para obter mais informações sobre sinônimos.
Termos do Cloud Links
Há vários conceitos e termos a serem usados quando você trabalha com Links da Nuvem:
-
Conjunto de Dados Registrado (Conjunto de Dados): Identifica uma tabela ou view que foi ativada para acesso remoto em um Autonomous AI Database. Um conjunto de dados registrado também indica quem tem permissão para acessar o conjunto de dados (seu escopo). O registro do conjunto de dados define um namespace e um nome para uso com os Links da Nuvem. Após o registro do conjunto de dados, esses valores juntos especificam o FQN (Nome Totalmente Qualificado) para acesso remoto e permitem que os Links da Nuvem gerenciem a acessibilidade do conjunto de dados.
-
Proprietário do Conjunto de Dados: Especifique um proprietário do conjunto de dados para fornecer um ponto de contato para perguntas sobre um conjunto de dados.
-
Escopo: Especifica quem e de onde um usuário tem permissão para acessar um conjunto de dados registrado. Consulte Escopo do Conjunto de Dados, Controle de Acesso e Autorização para obter mais detalhes sobre o escopo.
-
OCID (Oracle Cloud Identifier): Identifica uma Tenancy, um Compartimento ou um Banco de Dados específico. O escopo de um conjunto de dados registrado pode ser expresso em termos de OCIDs. Consulte Identificadores de Recursos para obter mais informações.
-
Registro de Dados: com o registro de dados, um usuário disponibiliza uma tabela ou view para acesso remoto, sujeito às restrições de acesso impostas pelo escopo e, opcionalmente, sujeito a uma etapa de autorização adicional. Você pode permitir o acesso remoto com Links de Nuvem em uma tabela ou view armazenada no banco de dados ou em dados armazenados no Object Store.
-
Descoberta de Dados: Um conjunto de dados registrado pode ser descoberto usando consultas textuais do banco de dados. A descoberta só mostrará um conjunto de dados se houver um privilégio para acessar o conjunto de dados. Você pode pesquisar para localizar um conjunto de dados registrado por nome ou por descrição.
-
Descrever Dados: Permite que um usuário recupere uma descrição ou metadados para uma tabela ou view disponibilizada como um conjunto de dados registrado.
-
Destinos de Offload: Opcionalmente, você pode especificar um ou mais destinos de offload. Os destinos de descarga são clones atualizáveis que fornecem conjuntos de dados do Cloud Links para instâncias especificadas do Autonomous AI Database. Ao especificar um destino de offload, você pode dedicar uma instância do Autonomous AI Database para fornecer conjuntos de dados a fim de separar a produção do desenvolvimento, do desempenho, para garantir a segurança ou por outros motivos. Consulte Usar Clones Atualizáveis com o Autonomous AI Database para obter mais informações.
Auditoria de Links da Nuvem
Qualquer acesso a um conjunto de dados registrado usando Links da Nuvem é registrado para fins de auditoria. O log inclui a tenancy, o compartimento ou o banco de dados que acessou o conjunto de dados, o volume de dados acessados e informações adicionais. As Views V$CLOUD_LINK_ACCESS_STATS e GV$CLOUD_LINK_ACCESS_STATS mostram informações de auditoria.
Metadados do Conjunto de Dados e Views de Auditoria
Cada instância do Autonomous AI Database fornece views que expõem metadados de conjuntos de dados e que permitem monitorar e auditar o uso de dados. Consulte Monitorar e Exibir Informações de Links da Nuvem para obter mais informações.
Escopo do Conjunto de Dados, Controle de Acesso e Autorização
Os Links da Nuvem aproveitam os mecanismos de acesso da Oracle Cloud Infrastructure para tornar os conjuntos de dados registrados acessíveis e para proteger seus dados com restrições de acesso.
O Autonomous AI Database determina a acessibilidade dos conjuntos de dados registrados da seguinte forma:
-
O usuário ADMIN especifica um escopo para um usuário que permite ao usuário registrar conjuntos de dados com base no escopo fornecido.
-
Um usuário que recebeu privilégios para registrar conjuntos de dados especifica um escopo quando registra um conjunto de dados.
-
Opcionalmente, quando você registra um conjunto de dados, um usuário que recebeu privilégios de autorização pode especificar que uma etapa de autorização é necessária para acessar um conjunto de dados. Esta etapa de autorização é adicional à autorização de acesso em nível de escopo.
Escopo do Conjunto de Dados
O ADMIN define o escopo de um usuário com DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER para ser um dos seguintes:
-
'MY$REGION' -
'MY$TENANCY' -
'MY$COMPARTMENT' -
'MY$POOL'
O escopo de um usuário é hierárquico, o que significa que um usuário que recebe um desses escopos pode permitir o acesso da seguinte forma:
-
MY$REGION: Um usuário pode conceder acesso remoto a dados a outras tenancies na região da instância do Autonomous AI Database que está registrando o conjunto de dados. Este é o âmbito menos restritivo. -
MY$TENANCY: Um usuário pode conceder acesso remoto a dados para qualquer recurso, tenancy, compartimento ou banco de dados na tenancy da instância do Autonomous AI Database que está registrando o conjunto de dados. Esse escopo é mais restritivo que o escopoMY$REGION. -
MY$COMPARTMENT: Um usuário pode conceder acesso remoto a dados a qualquer recurso, compartimento ou banco de dados no compartimento da instância do Autonomous AI Database que está registrando o conjunto de dados. Este é o escopo mais restritivo que você pode definir para um usuário comGRANT_REGISTER. -
MY$POOL: Um usuário pode conceder acesso a dados remotos a qualquer Autonomous AI Database no mesmo Elastic Pool da instância do Autonomous AI Database que está registrando o conjunto de dados (incluindo tenancies mãe/filha). Esse escopo é mais restritivo que os escoposMY$TENANCYeMY$REGION, mas mais amplo queMY$COMPARTMENT, permitindo o compartilhamento seguro e sem cópia de dados no pool, com verificações de permissão feitas no banco de dados do usuário antes de se conectar remotamente.
Em seguida, o escopo definido quando você registra um conjunto de dados determina de onde os usuários têm permissão para acessar o conjunto de dados. O DBMS_CLOUD_LINK.REGISTER scope é uma lista separada por vírgulas que consiste em um ou mais dos seguintes itens:
-
OCID do Banco de Dados: O acesso ao conjuntos de dados é permitido para as instâncias específicas de Autonomous AI Database identificadas pelo OCID.
-
OCID do Compartimento: O acesso ao conjunto de dados é permitido para bancos de dados nos compartimentos identificados pelo OCID do compartimento.
-
OCID da Tenancy: O acesso ao conjunto de dados é permitido para bancos de dados nas tenancies identificadas pelo OCID das tenancies.
-
Nome da região: O acesso ao conjunto de dados é permitido para bancos de dados na região identificada pela região nomeada. Em todos os casos, o acesso aos Links da Nuvem é limitado a uma única região e não é entre regiões.
-
MY$COMPARTMENT: O acesso ao conjunto de dados é permitido para bancos de dados no mesmo compartimento do proprietário de conjunto de dados.
-
MY$TENANCY: O acesso ao conjunto de dados é permitido para bancos de dados na mesma TENANCY do proprietário de conjunto de dados.
-
MY$REGION: O acesso ao conjunto de dados é permitido para bancos de dados na mesma região que o proprietário.
-
MY$POOL: O acesso ao conjunto de dados é permitido para bancos de dados no mesmo Grupo Elástico que o proprietário.
Os valores de escopo, MY$REGION, MY$TENANCY, MY$COMPARTMENT e MY$POOL são variáveis que atuam como macros de conveniência e são resolvidas como OCIDs.
Observação: O escopo definido quando você registra um conjunto de dados só é respeitado quando ele corresponde ou é mais restritivo do que o conjunto de valores com DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER. Por exemplo, suponha que o ADMIN tenha concedido o escopo MY$TENANCY com GRANT_REGISTER e que o usuário especifique MY$REGION quando registrar um conjunto de dados com DBMS_CLOUD_LINK.REGISTER. Nesse caso, eles verão um erro como o seguinte:
ORA-20001: Share privileges are not enabled for current user or it is enabled but not for scope MY$REGIONVocê também pode usar um mecanismo de controle de acesso adicional baseado em um valor SYS_CONTEXT. Esse mecanismo usa a função DBMS_CLOUD_LINK.GET_DATABASE_ID que retorna um identificador disponível como um valor SYS_CONTEXT.
Quando você registra um conjunto de dados no DBMS_CLOUD_LINK.REGISTER, pode usar o valor SYS_CONTEXT nas políticas de segurança do Oracle Virtual Private Database (VPD) para controlar o acesso ao banco de dados para restringir e controlar ainda mais quais dados específicos podem ser acessados por instâncias individuais do Autonomous AI Database.
Consulte Definir uma Política de Banco de Dados Privado Virtual para Proteger um Conjunto de Dados Registrado para obter mais informações sobre o uso de políticas de VPD.
O valor do ID do banco de dados também está disponível nas Views V$CLOUD_LINK_ACCESS_STATS e GV$CLOUD_LINK_ACCESS_STATS que rastreiam estatísticas de acesso e informações de auditoria.
Consulte Usando o Oracle Virtual Private Database para Controlar o Acesso a Dados para obter mais informações.
Autorização do Conjunto de Dados
Quando você registra um conjunto de dados, se tiver recebido privilégios de autorização, poderá especificar que a autorização do OCID do banco de dados é necessária para acessar um conjunto de dados. Para fornecer autorização de OCID do banco de dados para um conjunto de dados, use o procedimento DBMS_CLOUD_LINK.GRANT_AUTHORIZATION para especificar as instâncias do Autonomous AI Database autorizadas a acessar o conjunto de dados. Antes de executar DBMS_CLOUD_LINK.GRANT_AUTHORIZATION, o ADMIN deve autorizá-lo a executar esse procedimento com DBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.
O registro do conjunto de dados com autorização necessária especifica o acesso em nível de banco de dados para um conjunto de dados, além do controle de acesso de escopo especificado para o conjunto de dados, da seguinte forma:
-
Os bancos de dados que estão dentro do
SCOPEespecificado e foram autorizados com oDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONpodem exibir linhas do conjunto de dados. -
Qualquer banco de dados que esteja dentro do
SCOPEespecificado, mas não tenha sido autorizado com oDBMS_CLOUD_LINK.GRANT_AUTHORIZATION, não poderá exibir linhas do conjunto de dados. Nesse caso, os consumidores sem autorização veem o conjunto de dados como vazio. -
Os bancos de dados que não estão no
SCOPEespecificado veem um erro ao tentar acessar o conjunto de dados.
Conceder Acesso de Links de Nuvem para Usuários do Banco de Dados
O usuário ADMIN concede privilégios aos usuários do banco de dados para registrar conjuntos de dados. O usuário ADMIN também concede privilégios aos usuários do banco de dados para acessar conjuntos de dados registrados.
Quando o usuário ADMIN concede privilégios de registro, ele fornece um escopo que especifica o escopo máximo que um usuário pode fornecer ao registrar um conjunto de dados (dentro da hierarquia de escopo). Os valores scope válidos para uso com DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER são:
-
'MY$REGION' -
'MY$TENANCY' -
'MY$COMPARTMENT' -
'MY$POOL'
Consulte Escopo do Conjunto de Dados, Controle de Acesso e Autorização para obter mais informações.
-
Como usuário ADMIN, permita que um usuário registre conjuntos de dados em um escopo especificado.
BEGIN DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER( username => 'DB_USER1', scope => 'MY$REGION'); END; /Especifica que o usuário
DB_USER1tem privilégios para registrar conjuntos de dados em um escopo especificado,'MY$REGION'.Um usuário pode consultar
SYS_CONTEXT('USERENV', 'CLOUD_LINK_REGISTER_ENABLED')para verificar se eles estão ativados para registrar conjuntos de dados.Por exemplo, a seguinte consulta:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_REGISTER_ENABLED') FROM DUAL;Retorna '
YES' ou 'NO'.Consulte Procedimento GRANT_REGISTER para obter mais informações.
-
Como usuário ADMIN, permita que um usuário acesse conjuntos de dados registrados.
EXEC DBMS_CLOUD_LINK_ADMIN.GRANT_READ('LWARD');Isso permite que o
LWARDacesse conjuntos de dados registrados que estão disponíveis para a instância do Autonomous AI Database.Um usuário pode consultar
SYS_CONTEXT('USERENV', 'CLOUD_LINK_READ_ENABLED')para verificar se eles estão ativados para acessoREADa um conjunto de dados.Por exemplo, a seguinte consulta:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_READ_ENABLED') FROM DUAL;Retorna '
YES' ou 'NO'.Consulte Procedimento GRANT_READ para obter mais informações.
-
Durante o registro de dados, você pode definir o parâmetro obrigatório de autorização como
TRUE. Quando a autorização necessária forTRUE, o usuário ADMIN deverá executarDBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZEpara fornecer autorização para chamarDBMS_CLOUD_LINK.GRANT_AUTHORIZATION. UseDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONpara especificar detalhes de autorização.Consulte Registrar um Conjunto de Dados com Autorização Obrigatória para obter mais informações.
-
Quando a instância do Autonomous AI Database tem o Database Vault ativado e a tabela ou view a ser registrada com os Links da Nuvem é protegida por um realm, o proprietário da tabela ou view deve ser autorizado para o realm como proprietário do realm antes do registro.
BEGIN DBMS_MACADM.ADD_AUTH_TO_REALM( realm_name => 'myrealm', grantee => '*object_owner*', auth_option => dbms_macutl.g_realm_auth_owner); END; /Se o realm que protege a tabela ou a view for um realm obrigatório, o esquema comum do Autonomous AI Database chamado
C##DATA$SHARE, que é usado internamente como o esquema de conexão, deverá ser autorizado ao realm como um participante do realm.Por exemplo:
BEGIN DBMS_MACADM.ADD_AUTH_TO_REALM( realm_name => 'myrealm', grantee => 'C##DATA$SHARE', auth_option => dbms_macutl.g_realm_auth_participant); END; /Consulte Usar o Oracle AI Database Vault com o Autonomous AI Database para obter mais informações.
Observações para conceder privilégios aos usuários do banco de dados para registrar conjuntos de dados:
-
Para registrar conjuntos de dados ou ver e acessar conjuntos de dados remotos, você deve ter concedido o privilégio apropriado para registrar com
DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTERou para ler conjuntos de dados comDBMS_CLOUD_LINK_ADMIN.GRANT_READ.Isso também se aplica ao usuário ADMIN; no entanto, o usuário ADMIN pode conceder privilégios a ele mesmo.
-
As views
DBA_CLOUD_LINK_PRIVSeUSER_CLOUD_LINK_PRIVSfornecem informações sobre privilégios de usuário. Consulte Monitorar e Exibir Informações de Links da Nuvem para obter mais informações. -
Um usuário pode executar a seguinte consulta para verificar se eles estão ativados para autenticação de conjuntos de dados registrados e protegidos:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_AUTH_ENABLED') FROM DUAL;
-
Revogar Acesso de Links de Nuvem para Usuários do Banco de Dados
O usuário ADMIN pode revogar o registro para não permitir que um usuário registre conjuntos de dados para acesso remoto. O usuário ADMIN também pode revogar privilégios ou usuários de banco de dados para acessar conjuntos de dados registrados.
-
Como usuário ADMIN, revogue os privilégios de um usuário para registrar conjuntos de dados.
Por exemplo:
EXEC DBMS_CLOUD_LINK_ADMIN.REVOKE_REGISTER('DB_USER1');Isso revoga os privilégios para registrar conjuntos de dados para o usuário,
DB_USER1.A execução de
DBMS_CLOUD_LINK_ADMIN.REVOKE_REGISTERnão afeta os conjuntos de dados que já estão registrados. UseDBMS_CLOUD_LINK.UNREGISTERpara remover o acesso de um conjunto de dados registrado.Consulte os procedimentos REVOKE_REGISTER e UNREGISTER para obter mais informações.
-
Como usuário ADMIN, revogue o acesso aos conjuntos de dados registrados.
Por exemplo:
EXEC DBMS_CLOUD_LINK_ADMIN.REVOKE_READ('LWARD');Isso revoga o acesso aos conjuntos de dados do Cloud Links para o usuário
LWARD.Consulte Procedimento REVOKE_READ para obter mais informações.
Registrar um Conjunto de Dados
Descreve as opções e etapas para registrar uma tabela ou view que você possui como um conjunto de dados registrado para compartilhar com os Cloud Links.
Registrar ou Cancelar Registro de um Conjunto de Dados
Você pode registrar uma tabela ou view de sua propriedade como um conjunto de dados registrado. Para remover ou substituir o conjunto de dados, é necessário cancelar o registro. Depois de registrar um conjunto de dados, você poderá alterar os valores dos atributos de um conjunto de dados.
O registro do conjunto de dados define um namespace e um nome para uso com os Links da Nuvem. Após o registro do conjunto de dados, esses valores juntos especificam o FQN (Nome Totalmente Qualificado) para acesso remoto e permitem que os Links da Nuvem gerenciem a acessibilidade do conjunto de dados.
Para registrar um conjunto de dados:
-
Obtenha privilégios de registro de concessão do usuário ADMIN.
Consulte Conceder Acesso de Links de Nuvem para Usuários do Banco de Dados para obter mais informações.
-
Registre um ou mais conjuntos de dados.
Por exemplo, supondo que haja um esquema
CLOUDLINKna sua instância do Autonomous AI Database, você pode registrar dois objetos,SALES_VIEW_AGGeSALES_ALL, e fornecer diferentes parâmetrosscopepara determinar como os objetos são acessados.BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_ALL', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES', description => 'Trusted Compartment, only accessible within my compartment. Early sales data.', scope => 'MY$COMPARTMENT', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /Os parâmetros são:
-
schema_name: é o nome do esquema (o proprietário do objeto). -
schema_object: é o nome do objecto. Os objetos válidos são:-
Tabelas (incluindo Heap, Externa ou Híbrida)
-
Exibições
-
Views Materializadas
-
Tabelas de Nuvem (Consulte Usar Tabelas de Nuvem para Armazenar Informações de Log e Diagnóstico para obter mais informações.)
Observação
Observação: Outros objetos, como views analíticas ou sinônimos, não são suportados.
-
-
namespace: é o namespace que você fornece como nome para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem).Um valor
NULLespecifica um valornamespacegerado pelo sistema, exclusivo da instância do Autonomous AI Database. -
name: é o nome que você fornece para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem). -
description: Especifica o texto para descrever os dados. -
scope: Especifica o escopo. Você pode usar uma das variáveis:MY$REGION,MY$TENANCY,MY$COMPARTMENTouMY$POOLou especificar um ou mais OCIDs.Consulte Escopo do Conjunto de Dados, Controle de Acesso e Autorização para obter mais informações.
-
auth_required: Um valor booliano que especifica se a autorização no nível do banco de dados é necessária para o conjunto de dados, além do controle de acesso do escopo. Quando definido comoTRUE, o conjunto de dados impõe uma etapa de autorização adicional. Consulte Registrar um Conjunto de Dados com Autorização Obrigatória para obter mais informações. -
data_set_owner: O valor de texto especifica informações sobre o indivíduo responsável pelo conjunto de dados ou um contato para perguntas sobre o conjunto de dados. Por exemplo, você pode fornecer um endereço de e-mail para o proprietário do conjunto de dados.
Consulte Procedimento REGISTER para obter mais informações.
Para este exemplo, após a conclusão do registro, o escopo dos dois objetos registrados é diferente, com base no parâmetro de escopo fornecido com
DBMS_CLOUD_LINK.REGISTER:-
MY$TENANCY: Especifica o escopo do nível da tenancy paraREGIONAL_SALES.SALES_AGG. -
MY$COMPARTMENT: Especifica o escopo de nível de compartimento mais restritivo na tenancy paraTRUSTED_COMPARTMENT.SALES.
-
Você pode atualizar alguns dos valores dos atributos de um conjunto de dados depois de registrar um conjunto de dados. Consulte Atualizar Atributos de Registro do Conjunto de Dados para obter mais informações.
Se quiser revogar o acesso remoto a um conjunto de dados registrado, cancele o registro do conjunto de dados.
Por exemplo:
BEGIN
DBMS_CLOUD_LINK.UNREGISTER(
namespace => 'TRUSTED_COMPARTMENT',
name => 'SALES');
END;
/Consulte Procedimento UNREGISTER para obter mais informações.
Observações para Registrar ou Cancelar o Registro de um Conjunto de Dados
Fornece observações para registrar um conjunto de dados no DBMS_CLOUD_LINK.REGISTER e cancelar o registro de um conjunto de dados no DBMS_CLOUD_LINK.UNREGISTER.
-
Depois de registrar um objeto, os usuários talvez precisem aguardar até dez (10) minutos para acessar o objeto com o Cloud Links.
-
Quando você registra um conjunto de dados e deseja que os consumidores de uma região remota acessem o conjunto de dados, execute etapas adicionais para disponibilizar o conjunto de dados em uma região remota. Consulte Registrar ou Cancelar o Registro de um Conjunto de Dados em Outra Região para obter mais informações.
-
Use o procedimento
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONpara alterar os atributos de um conjunto de dados existente.O tempo de espera para a conclusão da atualização pode ser de até 10 minutos para que uma alteração de registro seja propagada e acessível por meio dos Links da Nuvem. Esse atraso pode afetar a precisão dos dados nas exibições
DBA_CLOUD_LINK_REGISTRATIONSeDBA_CLOUD_LINK_ACCESS. -
Você pode registrar uma tabela ou view que reside no esquema de outro usuário quando tiver privilégios
READ WITH GRANT OPTIONpara a tabela ou view. -
O Autonomous AI Database não executa verificações de validade hierárquica no momento do registro e os registros que estão fora do escopo nunca estarão visíveis ou acessíveis.
Por exemplo, considere a seguinte sequência:
-
Um usuário com o escopo
MY$COMPARTMENTregistra um objeto com um escopo que especifica um OCID de banco de dados individual. -
Quando um usuário solicita acesso ao conjunto de dados registrado, o Autonomous AI Database executa a verificação para ver se o OCID do banco de dados no qual a solicitação se origina está na lista de OCID especificados com o
scopequando o conjunto de dados foi registrado. -
Depois disso, o objeto
namespace.nameserá detectável, visível e utilizável no banco de dados em que a solicitação se originou.
-
-
O
DBMS_CLOUD_LINK.UNREGISTERpode levar até dez (10) minutos para ser totalmente propagado, após o qual os dados podem ser acessados remotamente por mais tempo.
Registrar ou Cancelar Registro de um Conjunto de Dados em Outra Região
Você pode usar os Links da Nuvem em várias regiões, nas quais a região de origem contém o banco de dados de origem do conjunto de dados e uma ou mais regiões remotas contêm clones atualizáveis do banco de dados de origem.
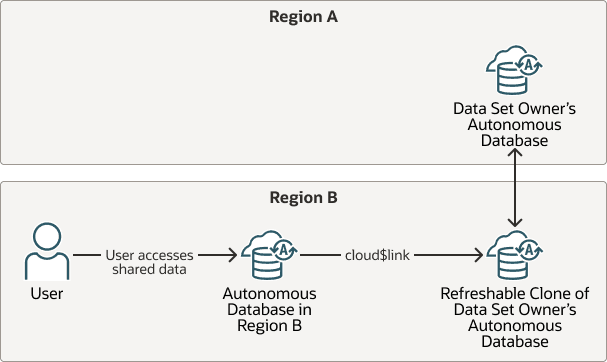
Descrição da ilustração cloud-links-cross-region-refreshable-clone.png
Para usar Links da Nuvem com um conjunto de dados em outra região:
-
Crie um Clone Atualizável entre regiões do banco de dados de origem em uma região remota.
Consulte Criar uma Tenancy Cruzada ou um Clone Atualizável entre Regiões para obter informações sobre como adicionar um clone atualizável entre regiões.
-
No banco de dados de origem, registre o conjunto de dados.
Consulte Registrar ou Cancelar o Registro de um Conjunto de Dados para obter mais informações.
-
Atualize o clone atualizável.
Consulte Atualizar um Clone Atualizável no Autonomous AI Database para mais informações.
-
No Clone Atualizável remoto, registre o conjunto de dados usando os mesmos argumentos usados para registrar o conjunto de dados na região de origem.
Por exemplo, supondo que haja um esquema
CLOUDLINKna sua instância do Autonomous AI Database, depois que você registrarSALES_ALLno banco de dados de origem, registreSALES_ALLno clone atualizável:BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_ALL', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES', description => 'Trusted Compartment, only accessible within my compartment. Early sales data.', scope => 'MY$COMPARTMENT', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /Os parâmetros são:
-
schema_name: é o nome do esquema (o proprietário do objeto). -
schema_object: é o nome do objecto. Os objetos válidos são:-
Tabelas (incluindo Heap, Externa ou Híbrida)
-
Exibições
-
Views Materializadas
Observação
Observação: outros objetos, como views analíticas ou sinônimos, não são suportados.
-
-
-
namespace: é o namespace que você fornece como nome para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem).Um valor
NULLespecifica um valornamespacegerado pelo sistema, exclusivo da instância do Autonomous AI Database.-
name: é o nome que você fornece para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem). -
description: Especifica o texto para descrever os dados. -
scope: Especifica o escopo. Você pode usar uma das variáveis:MY$REGION,MY$TENANCY,MY$COMPARTMENTouMY$POOLou especificar um ou mais OCIDs.Consulte Escopo do Conjunto de Dados, Controle de Acesso e Autorização para obter mais informações.
-
auth_required: Um valor booliano que especifica se a autorização no nível do banco de dados é necessária para o conjunto de dados, além do controle de acesso do escopo. Quando definido comoTRUE, o conjunto de dados impõe uma etapa de autorização adicional. Consulte Registrar um Conjunto de Dados com Autorização Obrigatória para obter mais informações. -
data_set_owner: O valor de texto especifica informações sobre o indivíduo responsável pelo conjunto de dados ou um contato para perguntas sobre o conjunto de dados. Por exemplo, você pode fornecer um endereço de e-mail para o proprietário do conjunto de dados.
Consulte Procedimento REGISTER para obter mais informações.
Após a conclusão do registro no clone atualizável, o escopo do objeto registrado é
MY$COMPARTMENT: Especifica o escopo mais restritivo no nível do compartimento do meu compartimento na minha tenancy paraTRUSTED_COMPARTMENT.SALES. -
Você só pode cancelar o registro de um conjunto de dados remoto nas regiões remotas ou nas regiões remotas e na região de origem:
Para cancelar o registro de um conjunto de dados em uma região remota e desativar o acesso remoto ao conjunto de dados:
-
No clone atualizável, cancele o registro do conjunto de dados.
Por exemplo:
BEGIN DBMS_CLOUD_LINK.UNREGISTER( namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; / -
Atualize o clone atualizável.
Consulte Atualizar um Clone Atualizável no Autonomous AI Database para mais informações.
Para cancelar o registro de um conjunto de dados no banco de dados de origem e cancelar o registro do conjunto de dados em clones atualizáveis da região remota:
-
No clone atualizável remoto, se houver apenas um, ou em vários clones atualizáveis em regiões remotas, se houver mais de um, cancele o registro do conjunto de dados.
Por exemplo:
BEGIN DBMS_CLOUD_LINK.UNREGISTER( namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; / -
No banco de dados de origem, cancele o registro do conjunto de dados.
Consulte Registrar ou Cancelar o Registro de um Conjunto de Dados para obter mais informações.
-
Atualize os clones atualizáveis.
Consulte Atualizar um Clone Atualizável no Autonomous AI Database para mais informações.
Observações para Registrar ou Cancelar o Registro de um Conjunto de Dados em uma Região Remota
Fornece observações para registrar um conjunto de dados em uma região remota.
-
Quando você registra um conjunto de dados em um clone atualizável em uma região remota, a chamada de
DBMS_CLOUD_LINK.REGISTERno clone da região remota deve usar os mesmos parâmetros com os mesmos valores do banco de dados de origem, com exceção do parâmetrooffload_targets.Por exemplo, quando você executar
DBMS_CLOUD_LINK.REGISTERcom o escopo definido comoMY$COMPARTMENTna instância do Autonomous AI Database de origem, execute o procedimento novamente no clone atualizável entre regiões com o mesmo valor de parâmetro de escopo (MY$COMPARTMENT). -
Se você especificar o parâmetro
offload_targetscomDBMS_CLOUD_LINK.REGISTERna origem, omita esse parâmetro ao registrar o conjunto de dados no clone atualizável. -
Depois de registrar um objeto, os usuários talvez precisem aguardar até dez (10) minutos para acessar o objeto com o Cloud Links.
-
As seguintes ações exigem que você atualize o clone atualizável:
-
Se você adicionar uma política de VPD ao conjunto de dados na origem, deverá atualizar o clone atualizável.
-
Se você executar uma concessão ou uma revogação para o conjunto de dados no banco de dados de origem, deverá atualizar o clone atualizável.
Consulte Atualizar um Clone Atualizável no Autonomous AI Database para mais informações.
-
Registrar um Conjunto de Dados com Autorização Obrigatória
Opcionalmente, ao registrar um conjunto de dados, além do escopo, você pode especificar que a autorização no nível do banco de dados é necessária para acessar um conjunto de dados.
Em comparação com o exemplo anterior em que você definiu auth_required como FALSE, neste exemplo, você definiu auth_required como TRUE. Quando auth_required é TRUE, são necessárias etapas adicionais para especificar um ou mais bancos de dados dos quais o acesso ao conjunto de dados é autorizado.
Observação
Observação: Você só poderá conceder autorização, conforme mostrado nestas etapas, se estiver autorizado. O ADMIN concede privilégios de autorização com DBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.
-
Use
DBMS_CLOUD_LINK.REGISTERpara registrar dados com autorização necessária.Supondo que haja um esquema
CLOUDLINKem sua instância do Autonomous AI Database e você registre o objetoSALES_VIEW_AGGe definaauth_requiredcomoTRUE. Em seguida, além de definir o escopo, você deverá executar etapas adicionais para determinar como o objeto é acessado.BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => TRUE, data_set_owner => 'amit@example.com' ); END; /Os parâmetros são:
-
schema_name: é o nome do esquema (o proprietário do objeto). -
schema_object: é o nome do objecto. Os objetos válidos são:-
Tabelas (incluindo Heap, Externa ou Híbrida)
-
Exibições
-
Views Materializadas
Observação
Observação: Outros objetos, como views analíticas ou sinônimos, não são suportados.
-
-
namespace: é o namespace que você fornece como nome para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem).Um valor
NULLespecifica um valornamespacegerado pelo sistema, exclusivo da instância do Autonomous AI Database. -
name: é o nome que você fornece para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem). -
scope: Especifica o escopo. Você pode usar uma das variáveis:MY$REGION,MY$TENANCY,MY$COMPARTMENTouMY$POOLou especificar um ou mais OCIDs.Consulte Escopo do Conjunto de Dados, Controle de Acesso e Autorização para obter mais informações.
-
auth_required: Um valor booliano que especifica se a autorização no nível do banco de dados é necessária para o conjunto de dados, além do controle de acesso do escopo. Quando definido comoTRUE, o conjunto de dados impõe uma etapa de autorização adicional. -
data_set_owner: O valor de texto especifica informações sobre o indivíduo responsável pelo conjunto de dados ou um contato para perguntas sobre o conjunto de dados. Por exemplo, você pode fornecer um endereço de e-mail para o proprietário do conjunto de dados.
-
-
Obtenha o ID do banco de dados para o qual deseja conceder autorização (para permitir que o banco de dados acesse o conjunto de dados).
No sistema, você deseja conceder acesso ao conjunto de dados:
SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL: -
Use o ID do banco de dados obtido para conceder autorização a um conjunto de dados especificado.
Você só poderá conceder autorização e executar o
DBMS_CLOUD_LINK.GRANT_AUTHORIZATION, conforme mostrado nesta etapa, se estiver autorizado. O ADMIN concede autorização comDBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.BEGIN DBMS_CLOUD_LINK.GRANT_AUTHORIZATION( database_id => '120xxxxxxx8506029999', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; /Execute essas etapas várias vezes se quiser autorizar bancos de dados adicionais.
Você pode atualizar o valor do parâmetro auth_required depois de registrar um conjunto de dados. Consulte Atualizar Atributos de Registro do Conjunto de Dados para obter mais informações.
Se você quiser revogar a autorização de um banco de dados:
BEGIN
DBMS_CLOUD_LINK.REVOKE_AUTHORIZATION(
database_id => '120xxxxxxx8506029999',
namespace => 'TRUSTED_COMPARTMENT',
name => 'SALES');
END;
/Para obter mais informações, consulte:
Registrar um Conjunto de Dados com Alvos de Descarregamento para Acesso ao Conjunto de Dados
Opcionalmente, quando você registra um conjunto de dados, pode descarregar o acesso ao conjunto de dados para uma ou mais instâncias do Autonomous AI Database que sejam clones atualizáveis.
Use o parâmetro offload_targets opcional com DBMS_CLOUD_LINK.REGISTER para especificar que o acesso é descarregado para clones atualizáveis. O banco de dados de origem de cada clone atualizável é a instância do Autonomous AI Database na qual você registra o conjunto de dados (editor de dados).
O valor offload_targets é um documento JSON que define um ou mais pares de chave/valor CLOUD_LINK_DATABASE_ID e OFFLOAD_TARGET:
-
CLOUD_LINK_DATABASE_IDé uma destas:-
Um ID de banco de dados: Especifica um ID de banco de dados para o consumidor do conjunto de dados cuja solicitação é descarregada para o clone atualizável correspondente especificado com o valor
OFFLOAD_TARGET.Obtenha o ID do banco de dados executando
DBMS_CLOUD_LINK.GET_DATABASE_ID. Consulte Função GET_DATABASE_ID para obter mais informações. -
ANY: Especifica que qualquer solicitação do consumidor do conjunto de dados é descarregada para o destino de descarregamento correspondente. Uma solicitação de conjunto de dados do consumidor será roteada para o destino de descarregamento correspondente.Se você especificar
ANYsem especificar IDs de banco de dados, todas as solicitações de conjunto de dados dos consumidores serão descarregadas para o clone atualizável especificado com o valorOFFLOAD_TARGET.Se você especificar IDs de banco de dados e
ANY, as solicitações de conjunto de dados dos consumidores que não correspondem a um ID de banco de dados serão descarregadas para o clone atualizável especificado com o valorOFFLOAD_TARGET.
-
-
OFFLOAD_TARGETé o OCID de uma instância do Autonomous AI Database que é um clone atualizável.
A figura a seguir ilustra o uso de alvos offload.
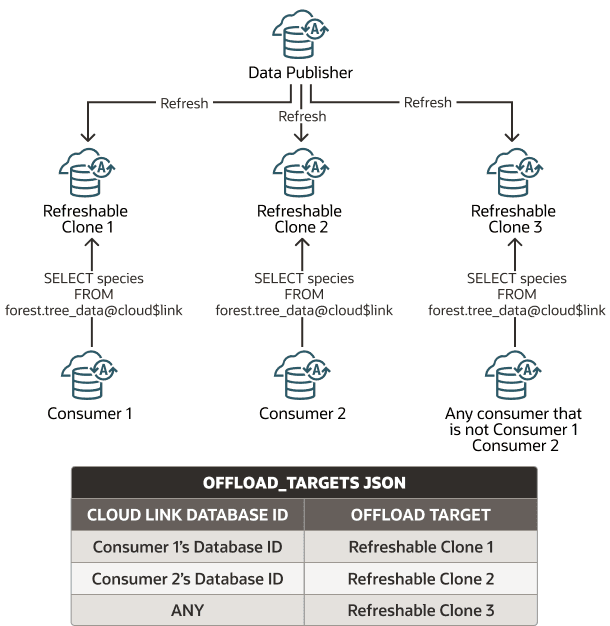
Descrição da ilustração cloud-links-offload-targets-any-keyword.png
Quando um consumidor de conjunto de dados solicita acesso a um conjunto de dados que você registra no offload_targets e o ID do banco de dados da instância do Autonomous AI Database corresponde ao valor especificado no CLOUD_LINK_DATABASE_ID, o acesso é descarregado para o clone atualizável identificado com OFFLOAD_TARGET no JSON fornecido.
Por exemplo, o seguinte mostra uma amostra JSON com três pares de valores OFFLOAD_TARGET/CLOUD_LINK_DATABASE_ID:
{
"OFFLOAD_TARGETS": [
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx69708978",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfabc"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx89898978",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfdef"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx4755680",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi"
}
]
}Quando um consumidor de conjunto de dados solicita acesso a um conjunto de dados que você registra no offload_targets que inclui a palavra-chave ANY, o acesso é descarregado para o clone atualizável identificado com OFFLOAD_TARGET no JSON fornecido (exceto para solicitações de consumidores que têm uma entrada de ID de banco de dados correspondente no JSON fornecido).
Por exemplo, o seguinte mostra uma amostra JSON com um par de valores OFFLOAD_TARGET/CLOUD_LINK_DATABASE_ID explícito e um valor ANY com um OFFLOAD_TARGET correspondente:
{
"OFFLOAD_TARGETS": [
{
"CLOUD_LINK_DATABASE_ID": "ANY",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfdef"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx4755680",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi"
}
]
}Para registrar um conjunto de dados e especificar destinos de descarregamento, faça o seguinte:
-
Obtenha o OCID de um ou mais clones atualizáveis nos quais você deseja descarregar o acesso ao conjunto de dados. Os OCIDs de clone atualizáveis estão disponíveis na Console do Oracle Cloud Infrastructure em um clone atualizável.
Observação
Observação: pode levar até 10 minutos após a criação de um clone atualizável para que o clone atualizável fique visível como um destino de offload. Isso significa que talvez você precise aguardar até 10 minutos depois de criar um clone atualizável para que o clone atualizável esteja disponível para o registro de descarregamento do Cloud Links. -
Obtenha o ID do banco de dados para uma ou mais instâncias do Autonomous AI Database que você deseja acessar o conjunto de dados usando os dados fornecidos pelo clone atualizável.
No sistema que você deseja acessar o conjunto de dados de um clone atualizável, execute o comando:
SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL: -
Registre um conjunto de dados e especifique o parâmetro
offload_targets.Por exemplo, supondo que haja um esquema
CLOUDLINKna sua instância do Autonomous AI Database, você pode registrarSALES_VIEW_AGGe especificar os clones atualizáveis que fornecem acesso ao conjunto de dados:BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => FALSE, data_set_owner => 'amit@example.com', offload_targets => '{ "OFFLOAD_TARGETS": [ { "CLOUD_LINK_DATABASE_ID": "34xxxx754755680", "OFFLOAD_TARGET": "ocid1.autonomousdatabase.oc1..xxxxxaaba3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi" } ] }'); END; /Os parâmetros são:
-
schema_name: é o nome do esquema (o proprietário do objeto). -
schema_object: é o nome do objecto. Os objetos válidos são:-
Tabelas (incluindo Heap, Externa ou Híbrida)
-
Exibições
-
Views Materializadas
Observação
Observação: Outros objetos, como views analíticas ou sinônimos, não são suportados.
-
-
namespace: é o namespace que você fornece como nome para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem).Um valor
NULLespecifica um valornamespacegerado pelo sistema, exclusivo da instância do Autonomous AI Database. -
name: é o nome que você fornece para acesso com Links da Nuvem (uma parte do FQN do Link da Nuvem). -
scope: Especifica o escopo. Você pode usar uma das variáveis:MY$REGION,MY$TENANCY,MY$COMPARTMENTouMY$POOLou especificar um ou mais OCIDs.Consulte Escopo do Conjunto de Dados, Controle de Acesso e Autorização para obter mais informações.
-
auth_required: Um valor booliano que especifica se a autorização no nível do banco de dados é necessária para o conjunto de dados, além do controle de acesso do escopo. Quando definido comoTRUE, o conjunto de dados impõe uma etapa de autorização adicional. Consulte Registrar um Conjunto de Dados com Autorização Obrigatória para obter mais informações. -
data_set_owner: O valor de texto especifica informações sobre o indivíduo responsável pelo conjunto de dados ou um contato para perguntas sobre o conjunto de dados. Por exemplo, você pode fornecer um endereço de e-mail para o proprietário do conjunto de dados. -
offload_targets: Especifica um ou mais OCIDs do Autonomous AI Database de clones atualizáveis nos quais o acesso aos conjuntos de dados é descarregado, no Autonomous AI Database no qual o conjunto de dados é registrado.Para cada consumidor de conjunto de dados, uma das seguintes opções pode corresponder para descarregar a solicitação em um clone atualizável:
-
Quando há correspondência entre o valor do
cloud_link_database_idespecificado, ou seja, os valores correspondem ao ID do banco de dados do consumidor, o acesso é descarregado no clone atualizável identificado pelo OCID especificado emoffload_target. -
Quando a palavra-chave
ANYé especificada, se não houver uma correspondência com o valor de umacloud_link_database_idespecificada, o acesso será descarregado para o clone atualizável identificado com a entrada ANY pelo OCID especificado naoffload_targetcorrespondente.
-
Observação
Observação: Se o editor de dados for um líder de pool elástico ou um membro de pool elástico, como alternativa à configuração dos detalhes do destino de offload com ooffload_targets, você poderá usar o recurso de offload de consulta unificada. Nesse caso, o editor permite que o descarregamento de consultas ProxySQL descarregue consultas (leituras) para qualquer número de clones atualizáveis sem a necessidade de configurar os destinos. Consulte Usar Offload de Consulta Unificada com Links da Nuvem para obter mais informações.Para obter mais informações, consulte:
-
Atualizar Atributos de Registro do Conjunto de Dados
Depois de registrar um conjunto de dados, você poderá atualizar alguns atributos do conjunto de dados. Não é possível atualizar o nome do esquema, o objeto do esquema, o namespace ou os atributos de nome.
Para atualizar os atributos do conjunto de dados:
-
O usuário que registrou um conjunto de dados pode atualizar seus atributos com o
DBMS_CLOUD_LINK.UPDATE_REGISTRATION.Se você não tiver privilégios para atualizar atributos do conjunto de dados, será necessário obter privilégios de registro de concessão do usuário ADMIN.
Consulte Conceder Acesso de Links de Nuvem para Usuários do Banco de Dados para obter mais informações.
-
Atualize um ou mais atributos para um conjunto de dados.
Por exemplo, use
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONpara atualizar os atributosdescription,scopeeauth_requireddo conjunto de dados no namespaceREGIONAL_SALEScom o nomeSALES_AGG:BEGIN DBMS_CLOUD_LINK.UPDATE_REGISTRATION( namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Updated description for aggregated regional sales information.', scope => 'MY$COMPARTMENT', auth_required => TRUE ); END; /Os parâmetros necessários são:
-
namespace: é o namespace do conjunto de dados fornecido quando você registrou o conjunto de dados. -
name: é o nome do conjunto de dados que você forneceu quando registrou o conjunto de dados.
Veja a seguir uma lista dos parâmetros opcionais. Se
NULLfor informado para um valor de parâmetro opcional, o atributo não será modificado.-
description: Especifica o texto atualizado para descrever os dados. -
scope: Especifica o escopo. Você pode usar uma das variáveis:MY$REGION,MY$TENANCY,MY$COMPARTMENTouMY$POOLou especificar um ou mais OCIDs.Consulte Escopo do Conjunto de Dados, Controle de Acesso e Autorização para obter mais informações.
-
auth_required: Um valor booliano que especifica se a autorização no nível do banco de dados é necessária para o conjunto de dados, além do controle de acesso do escopo. Quando definido comoTRUE, o conjunto de dados impõe uma etapa de autorização adicional. Consulte Registrar um Conjunto de Dados com Autorização Obrigatória para obter mais informações. -
data_set_owner: O valor de texto especifica informações sobre o indivíduo responsável pelo conjunto de dados ou um contato para perguntas sobre o conjunto de dados. Por exemplo, você pode fornecer um endereço de e-mail para o proprietário do conjunto de dados. -
offload_targets: Especifica um ou mais OCIDs do Autonomous AI Database de clones atualizáveis nos quais o acesso aos conjuntos de dados é descarregado, no Autonomous AI Database no qual o conjunto de dados é registrado. Consulte Registrar um Conjunto de Dados com Destinos de Offload para Acesso ao Conjunto de Dados para obter mais informações.
Não é possível atualizar os atributos
schema_nameouschema_object.Consulte Procedimento UPDATE_REGISTRATION para obter mais informações.
-
Quando um conjunto de dados é registrado em um ou mais Clones Atualizáveis entre regiões, qualquer alteração no registro no banco de dados de origem deve ser propagada para as regiões remotas.
Observe o seguinte para propagar alterações para Clones Atualizáveis entre regiões:
-
Se um Produtor tiver N Clones Atualizáveis entre regiões em uma região, por exemplo, na região A, execute
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONem exatamente um Clone Atualizável na região A. -
Se o mesmo Produtor tiver M Clones Atualizáveis entre regiões em outra região remota, por exemplo, na região B, execute
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONem exatamente um Clone Atualizável na região B.
Para atualizar atributos quando um conjunto de dados for registrado em um ou mais Clones Atualizáveis entre regiões:
-
No banco de dados de origem, atualize o registro do conjunto de dados.
-
Em um Clone Atualizável remoto na região remota, se houver apenas uma região remota, ou em um Clone Atualizável remoto em cada região remota, se houver Clones Atualizáveis replicados em várias regiões, atualize o registro do conjunto de dados com os mesmos valores usados para atualizar o banco de dados de origem, com exceção do parâmetro
offload_targets.Em uma determinada região remota, você só precisa executar
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONem exatamente um Clone Atualizável nessa região (se a região tiver mais de um Clone Atualizável associado ao mesmo conjunto de dados, você só precisará executar o procedimento uma vez para propagar as alterações em todos os Clones Atualizáveis em uma região remota individual). -
Atualize os clones atualizáveis.
Consulte Atualizar um Clone Atualizável no Autonomous AI Database para mais informações.
Localizar Conjuntos de Dados e Usar Links da Nuvem
Um usuário que tem acesso para ler Links da Nuvem pode procurar conjuntos de dados disponíveis para uma instância do Autonomous AI Database e pode acessar e usar conjuntos de dados registrados com suas consultas.
Depois que o usuário ADMIN executar GRANT_READ, um usuário poderá procurar e usar Links da Nuvem.
-
Localize os conjuntos de dados disponíveis em sua instância do Autonomous AI Database.
Por exemplo, procure todos os conjuntos de dados que contenham a string "TREE":
DECLARE result CLOB DEFAULT NULL; BEGIN DBMS_CLOUD_LINK.FIND('TREE', result); DBMS_OUTPUT.PUT_LINE(result); END; / [{"name":"TREE_DATA","namespace":"FOREST","description":"Urban tree data including county, species and height"}]Os parâmetros são:
-
search_string: A string a ser pesquisada. A string de pesquisa não diferencia maiúsculas de minúsculas. -
search_result: Um documento JSON que inclui os valores de namespace, nome e descrição do conjunto de dados.
Consulte Procedimento FIND para obter mais informações.
O procedimento
DBMS_CLOUD_LINK.FINDfornece o FQN que você pode usar com os Links da Nuvem. Nesse caso,FOREST.TREE_DATA. -
-
Use a view
DBA_CLOUD_LINK_ACCESSpara listar os conjuntos de dados disponíveis:SELECT * FROM DBA_CLOUD_LINK_ACCESS;NAMESPACE NAME --------- -------------- FOREST TREE_DATA REGIONAL_SALES SALES_AGG TRUSTED_COMPARTMENT SALES -
Use o procedimento
DBMS_CLOUD_LINK.DESCRIBEpara saber mais detalhes sobre um conjunto de dados registrado.SELECT DBMS_CLOUD_LINK.DESCRIBE('FOREST','TREE_DATA') FROM DUAL;DBMS_CLOUD_LINK.DESCRIBE('FOREST','TREE_DATA') --------------------------------------------------- Urban tree data including county, species and height -
Use o conjunto de dados registrado em uma consulta.
SELECT * FROM FOREST.TREE_DATA@cloud$link;
Observação
Observação: pode levar até 10 minutos após o registro de um conjunto de dados com DBMS_CLOUD_LINK.REGISTER para que o conjunto de dados fique visível e acessível.
Os Cloud Links suportam sinônimos privados e públicos. Por exemplo, você pode definir e usar um sinônimo para FOREST.TREE_DATA@cloud$link:
CREATE SYNONYM S1 for FOREST.TREE_DATA@cloud$link;
CREATE PUBLIC SYNONYM S2 for FOREST.TREE_DATA@cloud$link;
SELECT * FROM S1;
SELECT * FROM S2;Consulte CREATE SYNONYM para obter mais informações.
Usar Opções do Consumidor de Links da Nuvem
Você pode definir o mapeamento de nome de serviço a ser usado para acessar dados de um banco de dados de consumidor e pode ativar o armazenamento em cache em um consumidor de conjunto de dados para os resultados de uma consulta ou para um fragmento de consulta que acessa dados do Cloud Link.
Definir Mapeamento de Nome do Serviço de Banco de Dados para Consumidores de Links de Nuvem
Você pode definir o mapeamento de nome do serviço para usar quando os consumidores do Cloud Links acessarem dados de um proprietário de conjunto de dados.
Os Links da Nuvem dependem dos recursos do banco de dados na instância do Autonomous AI Database que é o produtor do conjunto de dados ou os recursos de um clone atualizável para acessar dados compartilhados. Por padrão, a conectividade remota para que os consumidores acessem dados do Cloud Links usa o serviço de banco de dados MEDIUM.
Use DBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING para definir o mapeamento do serviço de banco de dados para um consumidor. Neste procedimento, você fornece um ID de banco de dados ou a palavra-chave ANY para especificar o mapeamento de serviço ao consumidor. Por exemplo, a figura a seguir mostra um mapeamento para o Consumidor A para o serviço ALTO, o Consumidor B para o serviço MÉDIO, o Consumidor C para o serviço BAIXO e um mapeamento para QUALQUER para o serviço TP, o que significa que todos os outros consumidores acessam Links da Nuvem usando o serviço TP.
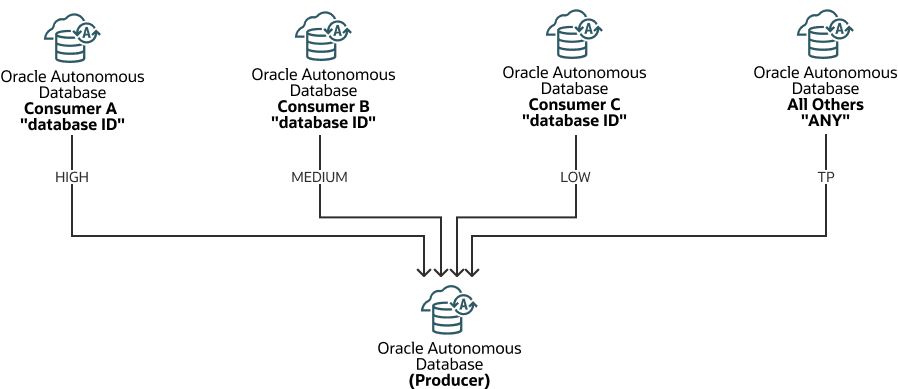
Descrição da ilustração autonomous-cloud-links-service-mapping.png
Consulte Nomes de Serviço de Banco de Dados para o Autonomous AI Database para obter mais informações sobre as características dos serviços de banco de dados.
Execute as seguintes etapas para definir o serviço de banco de dados a ser usado para um consumidor do Cloud Links:
-
Obtenha o ID do banco de dados para o qual deseja definir um mapeamento de serviço.
No banco de dados do consumidor, execute
GET_DATABASE_IDpara obter o ID do banco de dados do consumidor. Por exemplo:SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL:Consulte Função GET_DATABASE_ID para obter mais informações.
-
Na instância do Autonomous AI Database do proprietário do conjunto de dados, especifique um mapeamento de serviço.
Execute esta etapa na instância do Autonomous AI Database do proprietário do conjunto de dados (ou seja, no banco de dados do produtor).
BEGIN DBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING( database_id => '*database_id*', service_name => 'HIGH'); END; /Onde o valor do parâmetro
database_idé o ID do banco de dados que você obteve na etapa 1.Especifique o valor
ANYpara odatabase_idusar oservice_nameespecificado com todos os bancos de dados do consumidor que não têm umservice_nameassociado ao seudatabase_id. Ou seja, qualquerdatabase_idcujoservice_namenão tenha sido definido comDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING.Consulte Procedimento ADD_SERVICE_MAPPING para obter mais informações.
Somente o usuário ADMIN e os esquemas com a atribuição
PDB_DBApodem executarDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING. -
Verifique os IDs de banco de dados e o mapeamento de serviço listando os mapeamentos de serviço do Cloud Links.
Por exemplo:
SELECT * FROM DBA_CLOUD_LINK_SERVICE_MAPPINGS;Consulte View DBA_CLOUD_LINK_SERVICE_MAPPINGS para obter mais informações.
Observações para definir e alterar mapeamentos de serviço:
-
Os mapeamentos de serviço entram em vigor no momento em que as conexões são estabelecidas. Se os mapeamentos de serviço de um consumidor específico forem alterados, os novos mapeamentos terão efeito somente para novas sessões do consumidor.
-
Qualquer mapeamento de serviço configurado em um proprietário de conjunto de dados para um Consumidor específico é respeitado mesmo que o acesso do Consumidor seja descarregado para um Clone Atualizável. O Clone Atualizável deve ser atualizado para um ponto no tempo após o momento em que os mapeamentos de serviço foram configurados no proprietário do conjunto de dados. Observe que o offload para um Clone Atualizável é configurado com o argumento
offload_targetsdurante o registro do conjunto de dados.Consulte Registrar um Conjunto de Dados com Destinos de Offload para Acesso ao Conjunto de Dados para obter mais informações.
-
Use o procedimento
DBMS_CLOUD_LINK_ADMIN.REMOVE_SERVICE_MAPPINGpara remover um mapeamento de serviço de umdatabase_idespecificado.Após a execução de
DBMS_CLOUD_LINK_ADMIN.REMOVE_SERVICE_MAPPING, um consumidor usará o serviço de banco de dadosMEDIUMpadrão ou oservice_nameespecificado se você executarDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGcom o valordatabase_idANY. Consulte Procedimento REMOVE_SERVICE_MAPPING para obter mais informações. -
Um conjunto de dados registrado em uma região de origem pode ser acessado com os Links da Nuvem de uma região remota quando você cria um Clone Atualizável entre regiões na região remota.
Definir Mapeamento de Nome do Serviço de Banco de Dados para Consumidores de Links da Nuvem em Região Remota
Um conjunto de dados registrado em uma região de origem pode ser acessado com os Links da Nuvem de uma região remota quando você cria um Clone Atualizável entre regiões na região remota.
Nesse caso, os mapeamentos de serviço para consumidores na região remota devem ser adicionados duas vezes, no banco de dados de origem e no clone atualizável na região remota.
Execute as etapas a seguir para definir os mapeamentos de serviço para consumidores do Cloud Links em uma região remota.
-
Crie um Clone Atualizável entre regiões do banco de dados de origem (o Clone Atualizável é um clone do proprietário do conjunto de dados do Cloud Links na região remota).
Consulte Criar uma Tenancy Cruzada ou um Clone Atualizável entre Regiões para obter mais informações.
-
Registre o conjunto de dados.
Consulte Registrar um Conjunto de Dados para obter mais informações.
-
Adicione os mapeamentos de serviço no proprietário do conjunto de dados.
Consulte Definir Mapeamento de Nome do Serviço de Banco de Dados para Consumidores de Links da Nuvem para obter mais informações.
-
Atualize o Clone Atualizável.
Consulte Atualizar um Clone Atualizável no Autonomous AI Database para mais informações.
-
No Clone Atualizável remoto, registre o conjunto de dados usando os mesmos argumentos usados para registrar o conjunto de dados na região de origem (ou seja, use os mesmos argumentos usados na Etapa 2).
-
No Clone Atualizável remoto, adicione os mapeamentos de serviço usando os mesmos argumentos usados na região de origem (ou seja, use os mesmos argumentos usados na Etapa 3).
Quando um consumidor na região remota acessar os dados do Cloud Links, o acesso usará os mesmos mapeamentos de serviço que você adicionou ao banco de dados proprietário do conjunto de dados da região de origem.
Ativar Armazenamento em Cache para um Consumidor de Link de Nuvem
Você pode ativar o armazenamento em cache em um consumidor de conjunto de dados para os resultados de uma consulta ou para um fragmento de consulta que acessa dados do Cloud Link.
Para ativar o armazenamento em cache em um consumidor de conjunto de dados, use a dica RESULT_CACHE com a opção SHELFLIFE. Com a opção SHELFLIFE, você fornece um valor que indica a duração, em segundos, que um resultado de consulta é armazenado em cache. Após o intervalo SHELFLIFE ter passado, o resultado armazenado em cache será marcado como inválido. Desde que o resultado armazenado em cache seja válido, uma consulta recupera os dados armazenados em cache do banco de dados do consumidor, o que evita uma ida e volta para o banco de dados do proprietário do conjunto de dados.
Use a dica RESULT_CACHE com a opção SHELFLIFE quando o conjunto de dados estiver estático ou quando o consumidor puder tolerar resultados desatualizados. O valor de SHELFLIFE permite que o consumidor do conjunto de dados do Cloud Link controle o tempo, em segundos, em que os dados no cache são válidos (o grau aceitável de paralisação).
Se o resultado da consulta for grande e não caber na memória, você poderá usar a dica RESULT_CACHE com a opção SHELFLIFE e a opção TEMP para indicar que o resultado deve ser gravado no disco no tablespace temporário.
Para armazenar em cache os dados do Link do Cloud com a dica RESULT_CACHE:
-
Em uma consulta, especifique a dica
RESULT_CACHEcom a opçãoSHELFLIFE.Por exemplo:
SELECT /*+ RESULT_CACHE (SHELFLIFE=120) */ * FROM FOREST.TREE_DATA@cloud$link;Esse
RESULT_CACHEespecifica um valorSHELFLIFEde 120. Isso indica que o resultado deve ser armazenado em cache na memória por 120 segundos. Após 120 segundos, o resultado armazenado em cache é marcado como inválido.O valor
SHELFLIFEdeve ser um número inteiro positivo. O valor máximo deSHELFLIFEé 4294967295. -
Se o resultado da consulta for grande e não caber na memória, use as opções
SHELFLIFEeTEMPpara indicar que o resultado deve ser gravado no disco do tablespace temporário.SELECT /*+ RESULT_CACHE (TEMP=true SHELFLIFE=360) */ * FROM FOREST.TREE_DATA@cloud$link;
Consulte RESULT_CACHE_MODE para obter detalhes sobre como usar o cache de resultados com o Autonomous AI Database.
Consulte Dica RESULT_CACHE para obter mais informações sobre RESULT_CACHE com SHELFLIFE.
Consulte DBMS_RESULT_CACHE para obter informações sobre procedimentos para gerenciar o cache de resultados e para invalidar objetos no cache de resultados.
Monitorar e Exibir Informações de Links de Nuvem
O Autonomous AI Database fornece views que permitem monitorar e auditar Links da Nuvem.
| Exibir | Descrição |
|---|---|
| Visualizações V$CLOUD_LINK_ACCESS_STATS e GV$CLOUD_LINK_ACCESS_STATS | Use para rastrear o acesso a cada conjunto de dados registrado na instância do Autonomous AI Database. Essas visualizações rastreiam o tempo decorrido, o tempo de CPU, o número de linhas recuperadas e informações adicionais sobre conjuntos de dados registrados. Você pode usar as informações nessas exibições para auditar o acesso e o uso do conjunto de dados dos Links da Nuvem. |
| Visualizações DBA_CLOUD_LINK_REGISTRATIONS e ALL_CLOUD_LINK_REGISTRATIONS | Use para listar detalhes dos conjuntos de dados registrados em uma instância do Autonomous AI Database. |
| Visualizações DBA_CLOUD_LINK_ACCESS e ALL_CLOUD_LINK_ACCESS | Use para recuperar detalhes de conjuntos de dados registrados que um banco de dados tem permissão para acessar. |
| Visualização DBA_CLOUD_LINK_AUTHORIZATIONS | Fornece informações sobre quais bancos de dados estão autorizados a acessar quais conjuntos de dados. Isso se aplica a conjuntos de dados em que o parâmetro auth_required é TRUE. |
| Visualizações DBA_CLOUD_LINK_PRIVS e USER_CLOUD_LINK_PRIVS | Fornece informações sobre os privilégios específicos do Cloud Link, REGISTER, READ ou AUTHORIZE, concedidos a todos os usuários ou ao usuário atual. |
| Exibição DBA_CLOUD_LINK_SERVICE_MAPPINGS | Exibe detalhes de todos os mapeamentos de serviço para bancos de dados do consumidor do Cloud Links. Cada mapeamento de serviço consiste em um ID de banco de dados do Cloud Link e um serviço de banco de dados. |
Definir uma Política de Banco de Dados Privado Virtual para Proteger um Conjunto de Dados Registrado
Ao definir políticas de VPD (Virtual Private Database) para um conjunto de dados registrado, você pode fornecer um controle de acesso detalhado do Cloud Link para que apenas um subconjunto de dados (linhas) fique visível para sites remotos específicos.
O Oracle Virtual Private Database (VPD) é um recurso de segurança que permite controlar o acesso aos dados dinamicamente em nível de linha para usuários e aplicativos aplicando filtros no mesmo conjunto de dados.
Qualquer usuário que tenha acesso para ler Links da Nuvem poderá acessar e usar conjuntos de dados registrados se eles estiverem dentro do escopo especificado quando o conjunto de dados for registrado e se o parâmetro obrigatório de autorização extra for definido para o conjunto de dados, o acesso será de um banco de dados autorizado. Cada acesso remoto é feito no contexto da instância remota do Autonomous AI Database que acessa o conjunto de dados registrado (no banco de dados em que o conjunto de dados foi registrado).
Você usa a função DBMS_CLOUD_LINK.GET_DATABASE_ID no sistema remoto para obter o ID exclusivo do banco de dados. Ao definir uma política de VPD no banco de dados que registrou um conjunto de dados, agora você pode usar o identificador do banco de dados remoto como regra SYS_CONTEXT para fornecer controle mais detalhado. Você pode definir regras para bancos de dados remotos que acessam seu conjunto de dados registrado e limitar o acesso além do que é possível especificando um escopo do Cloud Link.
Considere um exemplo em que o REGIONAL_SALES.SALES_AGG é disponibilizado no nível da tenancy. Se quiser restringir o acesso a todos os bancos de dados, exceto um banco de dados específico, permitindo apenas acesso total ao banco de dados especificado, você poderá adicionar uma política de VPD ao conjunto de dados registrado.
Por exemplo:
-
Obtenha o ID exclusivo do banco de dados do Cloud Link para a instância do Autonomous AI Database na qual você deseja fornecer acesso total.
DECLARE DB_ID NUMBER; BEGIN DB_ID := DBMS_CLOUD_LINK.GET_DATABASE_ID; DBMS_OUTPUT.PUT_LINE('Database ID:' || DB_ID); END; / -
Crie uma política de VPD no banco de dados que registrou o conjunto de dados permitindo apenas acesso total ao banco de dados específico cujo identificador você obteve no banco de dados em questão na Etapa 1.
CREATE OR REPLACE FUNCTION vpd_policy_sales( owner IN VARCHAR2, object IN VARCHAR2) RETURN VARCHAR2 IS BEGIN IF SYS_CONTEXT('USERENV', 'CLOUD_LINK_DATABASE_ID') <> '12121212163948244901' THEN RETURN 'time_id >= trunc(sysdate,''year'')'; ELSE RETURN ''; END IF; END; /Para obter mais informações, consulte DBMS_RLS
-
Registre a política de VPD do seu conjunto de dados registrado para limitar o acesso total apenas ao banco de dados identificado na etapa 1.
BEGIN DBMS_RLS.ADD_POLICY(object_schema => 'CLOUDLINK', object_name => 'SALES_VIEW_AGG', policy_name => 'THIS_YEAR', function_schema => 'ADMIN', policy_function => 'VPD_POLICY_SALES', statement_types => 'SELECT', policy_type => DBMS_RLS.SHARED_CONTEXT_SENSITIVE); END; /Para obter mais informações, consulte DBMS_RLS
Consulte Usando o Oracle Virtual Private Database para Controlar o Acesso a Dados para obter mais informações.
Usar Links da Nuvem de uma Instância do Autonomous AI Database Somente para Leitura
Você pode compartilhar Links da Nuvem quando um conjunto de dados reside em uma instância do Autonomous AI Database Somente para Leitura.
Para compartilhar Links da Nuvem de uma instância do Autonomous AI Database que esteja no modo Somente Leitura:
-
Altere o modo de banco de dados para o modo Leitura/Gravação.
Consulte Alterar o Modo de Operação do Autonomous AI Database para Somente Leitura/Gravação ou Restrito para obter mais informações.
-
Com o banco de dados no modo Leitura/Gravação, execute as etapas para registrar um conjunto de dados.
-
Depois de registrar um ou mais conjuntos de dados, altere o banco de dados para o modo somente leitura.
Consulte Alterar o Modo de Operação do Autonomous AI Database para Somente Leitura/Gravação ou Restrito para obter mais informações.
Observações para Links da Nuvem
Fornece observações e restrições para usar Links da Nuvem.
-
Existe um limite de 4096 para o número de conjuntos de dados que você pode registrar.
Cada instância do Autonomous AI Database não pode registrar mais de 4096 conjuntos de dados. Esse limite se aplica a todas as instâncias do Autonomous AI Database, independentemente do número de ECPUs (OCPUs se o banco de dados usar OCPUs) ou do tamanho do armazenamento da instância. O limite é um valor fixo e a definição da contagem de ECPUs para um valor maior não permite registrar mais conjuntos de dados.
-
Você poderá registrar um objeto em outro esquema se tiver o privilégio
READ WITH GRANT OPTIONno objeto. -
Para registrar conjuntos de dados ou visualizar e acessar conjuntos de dados remotos, você deve ter concedido o privilégio apropriado para registrar ou ler conjuntos de dados. Isso também é verdade para ADMIN; no entanto, ADMIN pode conceder esse privilégio a si mesmo.
-
Para usar
DBMS_CLOUD_LINK.REGISTERouDBMS_CLOUD_LINK.UPDATE_REGISTRATION, você deve ter o privilégio de execução no pacoteDBMS_CLOUD_LINK, além do privilégio de registro atribuído aDBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER. Somente o usuário ADMIN e os esquemas comPDB_DBAtêm esse privilégio por padrão. -
Se você eliminar e recriar uma tabela que foi registrada, precisará registrar novamente a tabela para acesso remoto.
-
Somente o usuário ADMIN e os usuários com a atribuição
PDB_DBAtêm privilégios para acessar as seguintes views:-
DBA_CLOUD_LINK_ACCESS -
DBA_CLOUD_LINK_REGISTRATIONS -
DBA_CLOUD_LINK_AUTHORIZATIONS -
DBA_CLOUD_LINK_PRIVS
Consulte Views DBMS_CLOUD_LINK para obter mais informações.
-
-
O acesso a dados registrados e remotos requer que o banco de dados remoto seja aberto. Se o banco de dados remoto estiver fechado ou em modo restrito, você não poderá acessar os dados e um erro da Oracle será retornado.
-
Há um limite máximo de quatro links de banco de dados abertos por sessão. Exceder esse limite pode levar a
ORA-02020ouORA-12545. -
Se o cache de resultados estiver ativado, como o comportamento padrão no Autonomous AI Database com carga de trabalho Lakehouse, você precisará garantir que o cache de resultados não seja usado quando os dados em tempo real forem necessários.
-
Ao atualizar seu tipo de licença de Gratuito para Pago, você deve registrar novamente os conjuntos de dados do Cloud Links. Consulte Atualizar Instância Always Free para Pagamento com o Autonomous AI Database para obter mais informações.
-
A conectividade remota do Cloud Links por padrão usa o serviço de banco de dados
MEDIUM. Você pode alterar o padrão comDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGusandoANYcomo o valor deDATABASE_ID. Você pode alterar o serviço de banco de dados de um consumidor comDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGespecificando oDATABASE_IDdo consumidor. Consulte Definir Mapeamento de Nome do Serviço de Banco de Dados para Consumidores de Links da Nuvem para obter mais informações.Você pode ver as conexões remotas como usuário
C##DATA$SHAREemV$SESSIONe as views de Links da NuvemViews V$CLOUD_LINK_ACCESS_STATS e GV$CLOUD_LINK_ACCESS_STATS fornecem mais detalhes sobre conexões remotas. -
Todas as interfaces diferenciam maiúsculas de minúsculas, salvo indicação em contrário, da seguinte forma:
-
Tudo o que você informar existente no banco de dados, por exemplo, nomes de usuário e nomes de tabela, é significativo e deve ser informado com letras maiúsculas.
-
Variáveis predefinidas, por exemplo, os valores de escopo predefinidos devem ser inseridos em letras maiúsculas.
-
Qualquer coisa que você especificar para a configuração de Links da Nuvem, por exemplo, namespaces ou nomes de tabelas em um namespace, deverá ser especificada conforme informado. Por exemplo, se você definir um namespace como
trees, deverá colocar o namespace entre aspas duplas, como"trees", ao acessá-lo com SQL.
-
-
Você pode compartilhar Links do Cloud quando um conjunto de dados reside em uma instância do Autonomous AI Database no modo Somente Leitura. Consulte Usar Links de Nuvem de uma Instância do Autonomous AI Database Somente para Leitura para obter mais informações.
-
Pode levar até 10 minutos após a criação de um clone atualizável para que o clone atualizável fique visível como um destino de offload. Isso significa que talvez você precise aguardar até 10 minutos depois de criar um clone atualizável para que o clone atualizável esteja disponível para o registro de descarregamento do Cloud Links.
Consulte Registrar um Conjunto de Dados com Destinos de Offload para Acesso ao Conjunto de Dados e Criar um Clone Atualizável para uma Instância do Autonomous AI Database para obter mais informações.
-
Usar Links da Nuvem de uma Instância do Autonomous AI Database Somente para Leitura
Você pode compartilhar Links da Nuvem quando um conjunto de dados reside em uma instância do Autonomous AI Database Somente para Leitura.