Release 1 (9.0.1)
Part Number A89867-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Concepts Release 1 (9.0.1) Part Number A89867-02 |
|
![]()
![]()
This appendix describes configuring locks to cover multiple blocks. This methodology has been superseded by the automated resource management capabilities provided by Cache Fusion in Real Application Clusters. However, overriding Cache Fusion to use locks could be desirable in rare cases. Topics in this appendix include:
The methodology described in this appendix has been largely superseded by Cache Fusion in Release 1 (9.0.1). Overriding Cache Fusion to do lock setting is only desirable in Real Application Clusters installations that have a large number of read-mostly blocks accessed by an application in a partitioned manner. In nearly all other cases, it is recommended that users do not override the automated Cache Fusion resources. This is because using locks, you lose the inherent advantages of Cache Fusion transfers. Without Cache Fusion, the Global Cache Service (GCS) is implemented with costly forced disk writes.
You can override Cache Fusion and assign locks-to-files by setting initialization parameters to allocate the number of locks desired. Automated Cache Fusion concurrency control is active by default unless you set the GC_FILES_TO_LOCKS parameter.
Locks can manage one or more blocks of any class: data blocks, undo blocks, segment headers, and so on. However, a given Global Cache Service (GCS) resource can manage only one block class.
With lock setting, cache coherency is ensured by forcing requesting instances to acquire locks from instances that hold locks on data blocks before modifying or reading the blocks. Lock setting also allows only one instance at a time to modify a block. If a block is modified by an instance, then the block must first be written to disk before another instance can acquire the lock and modify it.
Locks use a minimum amount of communication to ensure cache coherency. The amount of cross-instance activity--and the corresponding performance of Real Application Clusters--is evaluated in terms of forced writes. A forced write is when one instance requests a block that is held by another instance. To resolve this type of request, Oracle writes (or pings) the block to disk so the requesting instance can read it in its most current state. In Oracle9i, Cache Fusion allows reading of dirty past image (PI) blocks across instances.
Heavily loaded applications can experience significant enqueuing activity, but they do not necessarily have excessive forced writes. If data is well partitioned, then the enqueuing is local to each node, and therefore forced writing does not occur.
|
See Also:
Oracle9i Real Application Clusters Installation and Configuration for detailed information about allocating locks |
There are two levels of lock granularity discussed in this section:
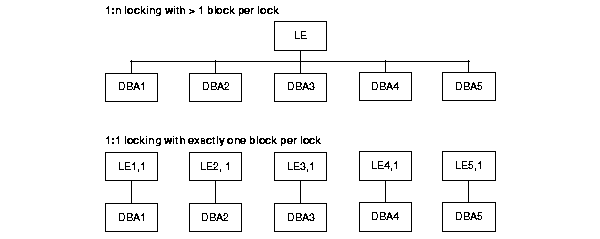
A 1:1 lock means one lock for each block.
1:n locks implies that a lock manages two or more data blocks as defined by the value for n. With 1:n locks, a few locks can manage many blocks and thus reduce lock operations. For read-only data, 1:n locks can perform faster than 1:1 locks during certain operations such as parallel execution. The GC_FILES_TO_LOCKS parameter is only useful to get 1:n lock granularity
If you partition data according to the nodes that are most likely to modify it, then you can implement disjoint lock sets, each set belonging to a specific node. This can significantly reduce lock operations. 1:n locks are also beneficial if you have a large amount of data that a relatively small number of instances modify. If a lock is already held by the instance that modifies the data, no lock activity is required for the operation.
|
See Also:
Oracle9i Real Application Clusters Deployment and Performance for detailed information about configuring Global Enqueue Service enqueues |
The number of locks assigned to datafiles and the number of data blocks in those datafiles determines the number of data blocks managed by a single lock.
When the GC_FILES_TO_LOCKS parameter is set for a file, then the number of blocks for each lock can be expressed as follows for each file level. This example assumes values of GC_FILES_TO_LOCKS = 1:300,2:200,3-5:100.
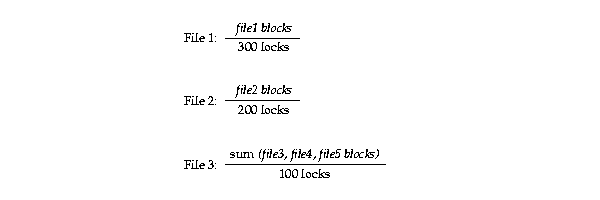
If the size of each file, in blocks, is a multiple of the number of locks assigned to it, then each 1:n lock manages exactly the number of data blocks given by the equation.
If the file size is not a multiple of the number of locks, then the number of data blocks for each 1:n lock can vary by one for that datafile. For example, if you assign 400 locks to a datafile that contains 2,500 data blocks, then 100 locks manage 7 data blocks each and 300 locks manage 6 blocks. Any datafiles not specified in the GC_FILES_TO_LOCKS initialization parameter use the remaining locks.
If n files share the same 1:n locks, then the number of blocks for each lock can vary by as much as n. If you assign locks to individual files, either with separate clauses of GC_FILES_TO_LOCKS or by using the keyword EACH, then the number of blocks for each lock does not vary by more than one.
If you assign 1:n locks to a set of datafiles collectively, then each lock usually manages one or more blocks in each file. Exceptions can occur when you specify contiguous blocks (by using the !blocks option) or when a file contains fewer blocks than the number of locks assigned to the set of files.
|
See Also:
Oracle9i Real Application Clusters Deployment and Performance for details on how to use the |
The following illustrates how 1:n locks can manage multiple blocks in different files. Figure B-1 assumes 44 locks assigned to two files that have a total of 44 blocks. GC_FILES_TO_LOCKS is set to A,B:44
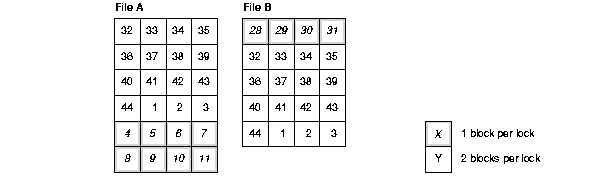
Block 1 of a file does not necessarily begin with lock 1. A hashing function determines which lock a file begins with. In file A that has 24 blocks, block 1 hashes to lock 32. In file B that has 20 blocks, block 1 hashes to lock 28.
In Figure B-1, locks 32 through 44 and 1 through 3 are used to manage two blocks each. Locks 4 through 11 and 28 through 31 manage one block each; and locks 12 through 27 manage no blocks at all.
In a worst case scenario, if two files hash to the same lock as a starting point, then all the common locks will manage two blocks each. If your files are large and have multiple blocks for each lock (about 100 blocks for each lock), then this is not an important issue.
Figure B-2 illustrates the correspondence of a global cache element to blocks. A global cache element is an Oracle-specific data structure representing a lock. There is a one-to-one correspondence between a global cache element and a lock.
You should also consider the periodicity of locks. Figure B-3 shows a file of 30 blocks that is managed by six locks. The example file shown has 1:n locks set to begin with lock number 5. As suggested by the shaded blocks managed by lock number 4, use of each lock forms a pattern over the blocks of the file.

In Real Application Clusters, a particular data block can only be modified by one instance at a time. If one instance modifies a data block that another instance needs, whether forced writing is required depends on the type of request submitted for the block.
If the requesting instance needs the block for modification, then the holding instance's locks on the data block must be converted accordingly. The first instance must accomplish a forced disk write before the requesting instance can read it.
The LCK process signals a need between the two instances. If the requesting instance only needs the block in consistent read (CR) mode, the lock process of the holding instance transmits a CR version of the block to the requesting instance by way of the interconnect. In this scenario, forced writing is much faster.
Data blocks are only force-written when a block held in exclusive current (XCUR) state in the buffer cache of one instance is needed by a different instance for modification. In some cases, therefore, the number of locks covering data blocks might have little effect on whether a block gets force-written.
An instance can relinquish an exclusive lock on a block and still have a row lock on rows in it: forced writing is independent of whether a commit has occurred. You can modify a block, but whether it is force-written is independent of whether you have made the commit.
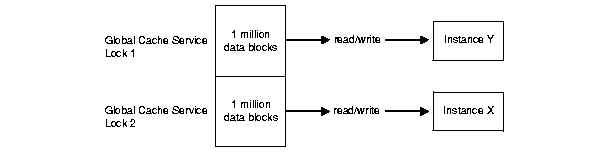
If you have partitioned data across instances and are doing updates, then your application can have, for example, one million blocks on each instance. Each block is managed by one lock yet there are no forced reads or forced writes.
As shown in Figure B-4, assume a single lock manages one million data blocks in a table and the blocks in that table are read from or written into the System Global Area (SGA) of instance X. Assume another single lock manages another million data blocks in the table that are read or written to the SGA of instance Y. Regardless of the number of updates, there will be no forced reads or forced writes on data blocks between instance X and instance Y.
|
See Also:
Oracle9i Real Application Clusters Deployment and Performance for more information about partitioning applications to avoid forced writing |
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|