Release 1 (9.0.1)
Part Number A89869-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Administration Release 1 (9.0.1) Part Number A89869-02 |
|
![]()
![]()
This chapter describes how to perform recovery in Real Application Clusters environments. This chapter contains the following topics:
See Also:
An instance failure occurs when software or hardware problems disable an instance. After instance failure, Oracle uses the online redo log files to perform database recovery. When instances accessing a database in shared mode fail, Oracle automatically performs online instance recovery. Instances that continue running on other nodes are not affected if they are reading from the buffer cache. If instances attempt to write, Oracle stops their transactions; Oracle suspends all operations to the database until cache recovery of the failed instance completes.
The following sections describe the recovery process as it is performed after an instance's failure to access a database in shared mode.
Instances in Real Application Clusters perform recovery through the SMON processes of the other running instances. If one instance fails, another instance's SMON process performs instance recovery for the failed instance.
Instance recovery does not include restarting the failed instance or the recovery of applications that were running on that instance. Applications that were running can continue by using failover as described in Oracle9i Real Application Clusters Installation and Configuration.
When one instance performs recovery for another instance, the surviving instance reads redo log entries generated by the failed instance and uses that information to ensure that committed transactions are reflected in the database. Data from committed transactions is not lost. The instance performing recovery rolls back transactions that were active at the time of the failure and releases resources used by those transactions.
|
See Also:
Oracle9i Real Application Clusters Concepts for conceptual information about application failover and high availability |
After multiple node failures, as long as one instance continues running, its SMON process performs instance recovery for any other instances that fail. If all instances of a Real Application Clusters database fail, instance recovery is performed automatically the next time an instance opens the database.
The instance performing recovery does not have to be one of the instances that failed. In addition, the instance performing recovery can mount the database in either shared or exclusive mode from any node of a Real Application Clusters database. This recovery procedure is the same for Oracle running in shared mode as it is for Oracle in exclusive mode, except that one instance performs instance recovery for all failed instances.
Fast-start checkpointing is the basis for Fast-start fault recovery in Oracle. Fast-start checkpointing occurs continuously, advancing the checkpoint while Oracle writes blocks to disk. You can limit the duration of the roll forward phase of Fast-start checkpointing. Oracle automatically adjusts the rate of checkpoint writes to meet the specified roll-forward limit while issuing a minimum number of writes.
Using the fast-start on-demand rollback feature, Oracle automatically allows new transactions to begin immediately after the roll forward phase of recovery completes.
An instance performing recovery for another instance must access all online data files that the failed instance accessed. When instance recovery fails because a data file fails verification, the instance that attempted to perform recovery does not fail but Oracle writes a message to the alert log file. In this case, the recovering instance needs access to the online archive log files.
After you correct the problem that prevented access to the database files, use the SQL statement ALTER SYSTEM CHECK DATAFILES to make the files available to the instance.
Figure 8-1 and the narrated steps following illustrate the degree of database availability during each step of Oracle instance recovery.
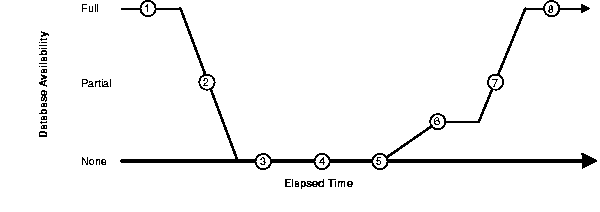
The steps in recovery are:
During step 6, forward application of the redo logs, database access is limited by the transitional state of the buffer cache. The following data access restrictions exist for all user data in all data files:
Oracle can read buffers already in the cache with the correct global resource because this does not involve any I/O or resource operations.
The transitional state of the buffer cache begins at the conclusion of the initial resource scan step when instance recovery is first started by scanning for dead redo threads. Subsequent resource scans are made if new dead threads are discovered. This state lasts while the redo log is applied (cache recovery) and ends when the redo logs have been applied and the file headers have been updated. Cache recovery operations conclude with validation of the invalid resources, which occurs after the buffer cache state is normalized.
Media failures occur when Oracle file storage mediums are damaged. This usually prevents Oracle from reading or writing data resulting in the loss of one or more database files. In these situations, you should restore backups of the data files to recover the database.
If you are using Recovery Manager (RMAN), you may also need to apply incremental backups and archived redo log files, and use a backup of the control file. If you are using operating system utilities, you might need to apply archived redo log files to the database and use a backup of the control file.
The media recovery topics discussed in this section are:
Oracle9i User-Managed Backup and Recovery Guide for procedures to recover from various types of media failure
See Also:
You can perform complete media recovery in either exclusive or shared mode. You can also recover multiple data files or tablespaces on multiple instances simultaneously. Table 8-1 shows the status of the database that is required to recover particular database objects.
Block media recovery is an RMAN feature in which Oracle applies archives from multiple instances to complete the recovery process. For online backups, however, you also have the option of using block media recovery.
Block media recovery reduces your system's mean time to recover (MTTR) and increases system availability. Block media recovery is intended primarily for data-specific data blocks cited in Oracle error messages. You cannot use Oracle block media recovery to recover complete files.
|
See Also:
The Oracle9i User-Managed Backup and Recovery Guide for more information about block media recovery |
You can perform incomplete media recovery of the entire database while the database is mounted in shared or exclusive mode if the database is not opened by an instance. Do this using the following database recovery options:
With RMAN use one of the following clauses with the SET statement before restoring and recovering:
With operating system utilities, restore your backups and then use one of the following clauses with the RECOVER DATABASE statement:
Incomplete media recovery of a tablespace is called Tablespace Point in Time Recovery (SPITR).
|
See Also:
Oracle9i User-Managed Backup and Recovery Guide for more information on the use of the |
Media recovery of a database accessed by Real Application Clusters may require the simultaneous opening of multiple archived log files. Because each instance writes redo log data to a separate redo thread, recovery may require at least one archived log file for each thread. However, if a thread's online redo log contains enough recovery information, restoring archived log files for that thread is unnecessary.
RMAN automatically restores and applies the required archive logs when processing the RMAN RECOVER command. By default, RMAN restores archive logs to the first local archivelog destination of the instance(s) that restore the archived logs. If you are using multiple nodes to restore and recover, this means that the archive logs may be restored to any node performing the restore/recover operation.
The node that reads the restored logs and performs the roll forward recovery is the target node to which the connection was initially made. You must ensure that the logs are readable from that node using the following platform-specific methods.
During recovery, Oracle displays messages that supply information about the files it requires and then prompts you for their complete filenames. For example, if the log history is enabled and the filename format is LOG_T%t_SEQ%s, where %t is the thread and %s is the log sequence number, you might receive messages similar to these to begin recovery with SCN 9523 in thread 8:
ORA-00279: Change 9523 generated at 27/09/91 11:42:54 needed for thread 8 ORA-00289: Suggestion : LOG_T8_SEQ438 ORA-00280: Change 9523 for thread 8 is in sequence 438 Specify log: {RET = suggested | filename | AUTO | FROM | CANCEL}
If you use the ALTER DATABASE statement with the RECOVER clause, you receive these messages but not the prompt. Redo log files may be required for each enabled thread in Real Application Clusters. Oracle issues a message when a log file is no longer needed. The next log file for that thread is then requested, unless the thread was disabled or recovery is complete.
If recovery reaches a time when an additional thread was enabled, Oracle requests the archived log file for that thread. Whenever an instance enables a thread, it writes a redo entry that records the change; therefore, all necessary information about threads is available from the control file during recovery.
If you are using a backup control file, when all archive log files are exhausted you may need to redirect the recovery process to the online redo log files to complete recovery. If recovery reaches a time when a thread was disabled, Oracle informs you that the log file for that thread is no longer needed and that Oracle does not need further log files for the thread.
This section describes disaster recovery using RMAN and operating system utilities. Implement disaster recovery, for example, when a failure makes an entire site unavailable. In this case, you can recover at an alternate site using open or closed database backups.
This section describes a recovery scenario using RMAN. The scenario assumes:
Before beginning the database recovery, you must:
If you are using a recovery catalog, the archive logs up to the logseq number being restored must be cataloged in the recovery catalog or RMAN will not know where to find them.
If you resynchronize the recovery catalog frequently there should not be many archive logs that need cataloging.
The following script restores and recovers the database to the most recently available archived log, which is log 124 thread 1. It does the following:
NOMOUNT and restricts connections to DBA-only users.
CONTROL_FILES initialization parameter.
If you cannot restore a data file to its original location due to a failed volume, use the SET NEWNAME command before the restore.
RMAN completes the recovery when it reaches the log sequence number specified.
Start SQL*Plus and connect to the database. Then enter the following STARTUP command:
STARTUP NOMOUNT RESTRICT
Start RMAN and run the following script.
RMAN TARGET user/password@node1 RCVCAT RMAN/RMAN@RCAT RUN { SET AUTOLOCATE ON; SET UNTIL LOGSEQ 124 THREAD 1; ALLOCATE CHANNEL t1 TYPE 'SBT_TAPE' CONNECT 'user/password@node1'; ALLOCATE CHANNEL t2 TYPE 'SBT_TAPE' CONNECT 'user/knl@node1'; ALLOCATE CHANNEL t3 TYPE 'SBT_TAPE' CONNECT 'user/knl@node2'; ALLOCATE CHANNEL t4 TYPE 'SBT_TAPE' CONNECT 'user/knl@node2'; ALLOCATE CHANNEL d1 TYPE DISK; RESTORE CONTROLFILE; ALTER DATABASE MOUNT; CATALOG ARCHIVELOG '/oracle/db_files/node1/arch/arch_1_123.rdo'; CATALOG ARCHIVELOG '/oracle/db_files/node1/arch/arch_1_124.rdo'; RESTORE DATABASE; RECOVER DATABASE; ALTER DATABASE OPEN RESETLOGS; }
Parallel recovery uses multiple CPUs and I/O parallelism to reduce the time required to perform thread or media recovery. Parallel recovery is most effective at reducing recovery time while concurrently recovering several data files on several disks. You can use parallel instance and crash recovery as well as parallel media recovery in Real Application Clusters.
You can use two types of utilities for parallel recovery in Real Application Clusters:
With RMAN's RESTORE and RECOVER statements, Oracle automatically parallelizes all three stages of recovery. These stages are:
When restoring data files, the number of channels you allocate in the RMAN recover script effectively sets the parallelism RMAN uses. For example, if you allocate 5 channels, you can have up to 5 parallel streams restoring data files.
Similarly, when you are applying incremental backups, the number of channels you allocate determines the potential parallelism.
Oracle applies redo logs using a specific number of parallel processes as determined by the setting for the RECOVERY_PARALLELISM parameter. The RECOVERY_PARALLELISM initialization parameter specifies the number of redo application server processes participating in instance or media recovery.
During parallel recovery, one process reads the log files sequentially and dispatches redo information to several recovery processes that apply the changes from the log files to the data files. A value of 0 or 1 for RECOVERY_PARALLELISM indicates that Oracle performs recovery serially. The value of this parameter cannot exceed the value of the PARALLEL_MAX_SERVERS parameter. RMAN parallelizes the restore and application of incremental backups using channel allocation.
|
See Also:
The Oracle9i Recovery Manager User's Guide and Reference for more information about using RMAN |
You can parallelize instance and media recovery using either of the following methods:
Real Application Clusters can use one process to read the log files sequentially and dispatch redo information to several recovery processes to apply the changes from the log files to the data files. Oracle automatically starts the recovery processes, so you do not need to use more than one session to perform recovery.
The RECOVERY_PARALLELISM initialization parameter specifies the number of redo application server processes participating in instance or media recovery. One process reads the log files sequentially and dispatches redo information to several recovery processes. The recovery processes then apply the changes from the log files to the data files. A value of 0 or 1 indicates that Oracle reforms recovery serially by one process. The value of this parameter cannot exceed the value of the PARALLEL_MAX_SERVERS parameter.
When you use the RECOVER statement to parallelize instance and media recovery, the allocation of recovery processes to instances is operating system specific. The DEGREE keyword of the PARALLEL clause can either signify the number of processes on each instance of a Real Application Clusters database or the number of processes to spread across all instances.
|
See Also:
|
In Real Application Clusters, multiple parallel recovery processes are owned by and operated only within the instance that generated them. To determine an accurate setting for FAST_START_PARALLEL_ROLLBACK, examine the contents of V$FAST_START_SERVERS and V$FAST_START_TRANSACTIONS.
Fast-start parallel rollback does not perform cross-instance rollback. However, it can improve the processing of rollback segments for a single database with multiple instances since each instance can spawn its own group of recovery processes.
The following are RMAN recovery examples for use in Real Application Clusters.
If you share archive log directories, you can change the destination of the automatic restoration of archive logs with the SET clause to restore the files to a local directory of the node from where you start recovery. This step does not apply if you use HA-NFS because you have only one shared directory which is mounted from all nodes.
To restore the USERS tablespace from node 1, use an RMAN command similar to the following:
RMAN TARGET connect /as sys@node1 CATALOG rmanuser/rmanpass@rmancat RUN { ALLOCATE CHANNEL t1 type 'sbt_tape'; # set archivelog destination to '/u01/app/oracle/product/901/admin/db/arch1'; RECOVER TABLESPACE users; SQL 'alter tablespace users online'; RELEASE CHANNEL t1; }
If RMAN has concurrent access to all backups, it automatically restores all necessary archive logs from previous backups for recovery. In Real Application Clusters environments, the restore procedure varies depending on the option you used to back up the archive logs.
If you share archive log directories, you can change the destination of the automatic restoration of archive logs with the SET clause to restore the files to a local directory of the node from where you begin recovery.
To restore the USERS tablespace from node 1, use an RMAN script similar to the following:
RMAN TARGET user/password@node1 catalog rman/rman@rman RUN { ALLOCATE CHANNEL t1 type 'sbt_tape'; SET ARCHIVELOG DESTINATION TO '/u01/app/oracle/product/901/admin/db/arch1'; RESTORE TABLESPACE users; RECOVER TABLESPACE users; SQL 'alter tablespace users online'; RELEASE CHANNEL t1; }
If you backed up each node's log files using a central media management system, you can use the RMAN SET AUTOLOCATE command. If you use several channels for recovery, RMAN asks every channel for the required file if it does not find it in the first one. This feature enables you to recover a database using the local tape drive on the remote node:
RMAN TARGET user/password catalog rman/rman@rman RUN { ALLOCATE CHANNEL t1 type 'sbt_tape' parms 'ENV=(NSR_CLIENT=node1)'; ALLOCATE CHANNEL t2 type 'sbt_tape' parms 'ENV=(NSR_CLIENT=node2)'; ALLOCATE CHANNEL t3 type 'sbt_tape' parms 'ENV=(NSR_CLIENT=node3)'; SET AUTOLOCATE ON; RECOVER TABLESPACE users; SQL 'ALTER TABLESPACE users ONLINE'; RELEASE CHANNEL t1; }
If you backed up the logs from each node without using a central media management system, you must first restore all the log files from the remote nodes and move them to the host from which you will start recovery. This means you must perform recovery in three steps:
RMAN TARGET user/password CATALOG rman/rman@rman RUN { ALLOCATE CHANNEL t1 TYPE 'sbt_tape' CONNECT SYS/sys@node1; RESTORE TABLESPACE users; RELEASE CHANNEL t1; } RUN { ALLOCATE CHANNEL t1 TYPE 'sbt_tape' CONNECT SYS/sys@node2; RESTORE ARCHIVELOG # this line is optional if you don't want to restore ALL archive logs: FROM TIME "to_date('05.09.1999 00:00:00','DD.MM.YYYY HH24:Mi:SS')" LIKE '%/2_%'; RELEASE CHANNEL t1; } RUN { ALLOCATE CHANNEL t1 TYPE 'sbt_tape' CONNECT SYS/sys@node3; RESTORE ARCHIVELOG # this line is optional if you don't want to restore ALL archive logs: FROM TIME "to_date('05.09.1999 00:00:00','DD.MM.YYYY HH24:Mi:SS')" like '%/3_%'; RELEASE CHANNEL t1; } EXIT rcp node2:/u01/app/oracle/product/901/admin/db/arch2 /u01/app/oracle/product/901/admin/db/arch2 rcp node3:/u01/app/oracle/product/901/admin/db/arch2 /u01/app/oracle/product/901/admin/db/arch2 RMAN TARGET user/password catalog rman/rman@rman RUN { ALLOCATE CHANNEL t1 TYPE 'sbt_tape'; ALLOCATE CHANNEL d1 type disk; RECOVER TABLESPACE users; SQL 'ALTER TABLESPACE USERS ONLINE'; }
If you moved all archive logs to one node to back them up, recovery is as easy as recovery using shared directories. To make sure you have all the log files, copy all remote log files with your shell script as in this example:
/rcp_all_logs.sh RMAN TARGET internal/sys@node1 catalog rman/rman@rman RUN { ALLOCATE CHANNEL t1 type 'sbt_tape' format 'al_t%t_s%s_p%p'; BACKUP ARCHIVELOG ALL DELETE INPUT; RELEASE CHANNEL t1; }
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|